Tutorial: Análise de Texto com os serviços de IA do Azure
Nesse tutorial, você aprenderá a usar o Text Analytics para analisar texto não estruturado no Azure Synapse Analytics. Análise de Texto é um Serviço de IA do Azure que permite executar a mineração e a análise de texto com recursos de Processamento de Linguagem Natural (NLP).
Este tutorial demonstra como usar a Análise de Texto com o SynapseML para:
- Detectar rótulos de sentimento no nível da frase ou do documento
- Identificar o idioma de uma determinada entrada de texto
- Reconhecer entidades de um texto com links para uma base de dados de conhecimento conhecida
- Extrair frases-chave de um texto
- Identificar entidades diferentes no texto e categorizá-las em classes ou tipos pré-definidos
- Identificar e remover entidades confidenciais em um determinado texto
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Workspace do Azure Synapse Analytics com uma conta de armazenamento do Azure Data Lake Storage Gen2 configurada como o armazenamento padrão. Você precisa ser Colaborador de Dados do Storage Blob do sistema de arquivos Data Lake Storage Gen2 com o qual você trabalha.
- Pool do Spark no workspace do Azure Synapse Analytics. Para obter detalhes, confira Criar um Pool do Spark no Azure Synapse.
- Etapas de pré-configuração descritas no tutorial Configurar serviços de IA do Azure no Azure Synapse.
Introdução
Abra o Synapse Studio e crie um notebook. Para começar, importe o SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Configurar a Análise de Texto
Use a análise de texto vinculado que você configurou nas etapas de pré-configuração.
linked_service_name = "<Your linked service for text analytics>"
Sentimento do texto
A Análise de Sentimento de Texto fornece uma maneira de detectar rótulos de sentimento (como "negativo", "neutro" e "positivo") e pontuações de confiança no nível da frase e do documento. Confira Idiomas compatíveis na API de Análise de Texto para obter a lista dos idiomas habilitados.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Resultados esperados
| text | sentimento |
|---|---|
| Estou tão feliz hoje, está ensolarado! | positivo |
| Estou frustrado com esse trânsito da hora do rush | negativo |
| Os serviços de IA do Azure no Spark funcionam bem | neutro |
Detector de Idioma
O Detector de Idioma avalia o texto de entrada para cada documento e retorna os identificadores de idioma com uma pontuação que indica a intensidade da análise. Esse recurso é útil para conteúdo armazena esse texto arbitrário de coleção, onde o idioma é desconhecido. Confira Idiomas compatíveis na API de Análise de Texto para obter a lista dos idiomas habilitados.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Resultados esperados
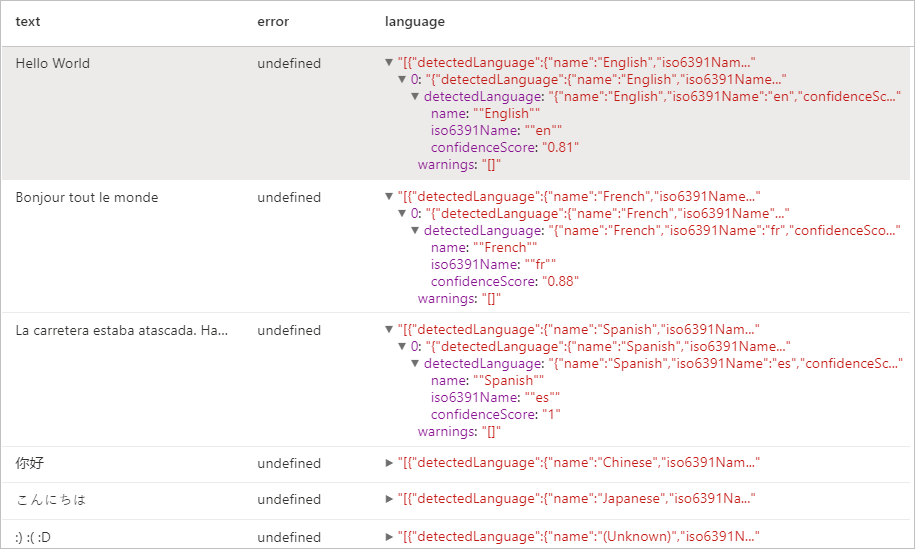
Detector de Entidade
O Detector de Entidade retorna uma lista de entidades reconhecidas com links para uma base de conhecimento bem conhecida. Confira Idiomas compatíveis na API de Análise de Texto para obter a lista dos idiomas habilitados.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Resultados esperados
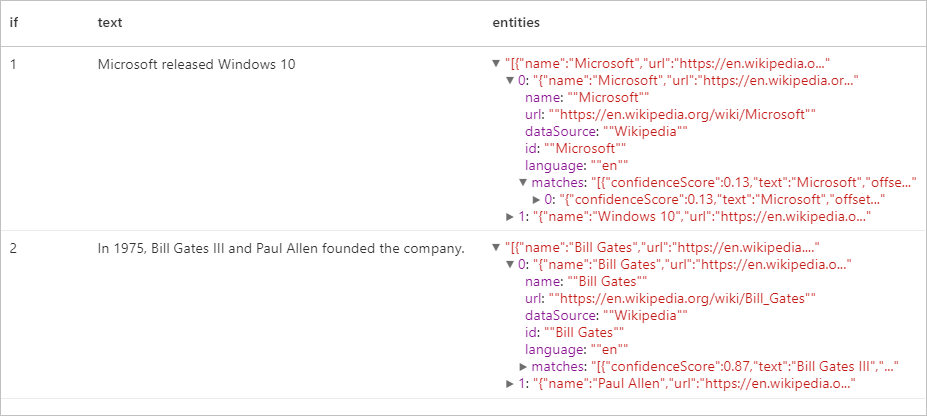
Extrator de Frases-chave
A Extração de Frases-chave avalia o texto não estruturado e retorna uma lista de frases-chave. Esse recurso é útil se você precisar identificar rapidamente os principais pontos de estratégias em uma coleção de documentos. Confira Idiomas compatíveis na API de Análise de Texto para obter a lista dos idiomas habilitados.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Resultados esperados
| text | keyPhrases |
|---|---|
| Olá, mundo. Este é um texto de entrada que eu amo. | "["Olá mundo","texto de entrada"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Iaia mucho sempre será adídia de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
NER (Reconhecimento de Entidade Nomeada)
O NER (Reconhecimento de Entidade Nomeada) é a capacidade de identificar diferentes entidades no texto e categorizá-las em classes ou tipos predefinidos, como: pessoa, local, evento, produto e organização. Confira Idiomas compatíveis na API de Análise de Texto para obter a lista dos idiomas habilitados.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Resultados esperados
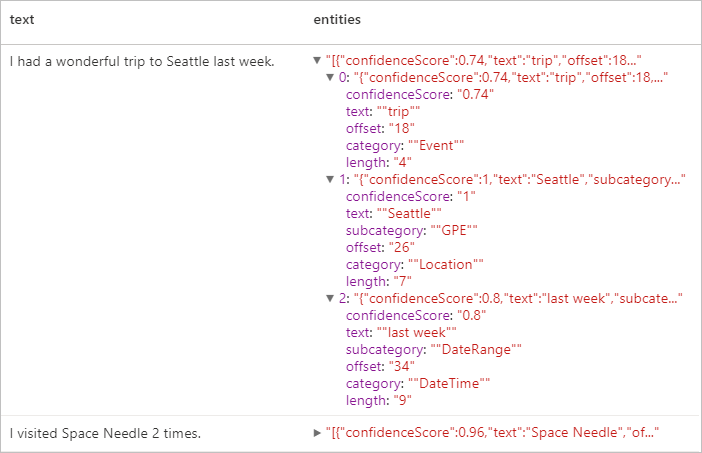
PII (Informações de Identificação Pessoal) v3.1
O recurso de PII faz parte do NER e pode identificar e editar entidades confidenciais no texto associadas a uma pessoa individual, como: número de telefone, endereço de email, endereço para correspondência, número do passaporte. Confira Idiomas compatíveis na API de Análise de Texto para obter a lista dos idiomas habilitados.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Resultados esperados
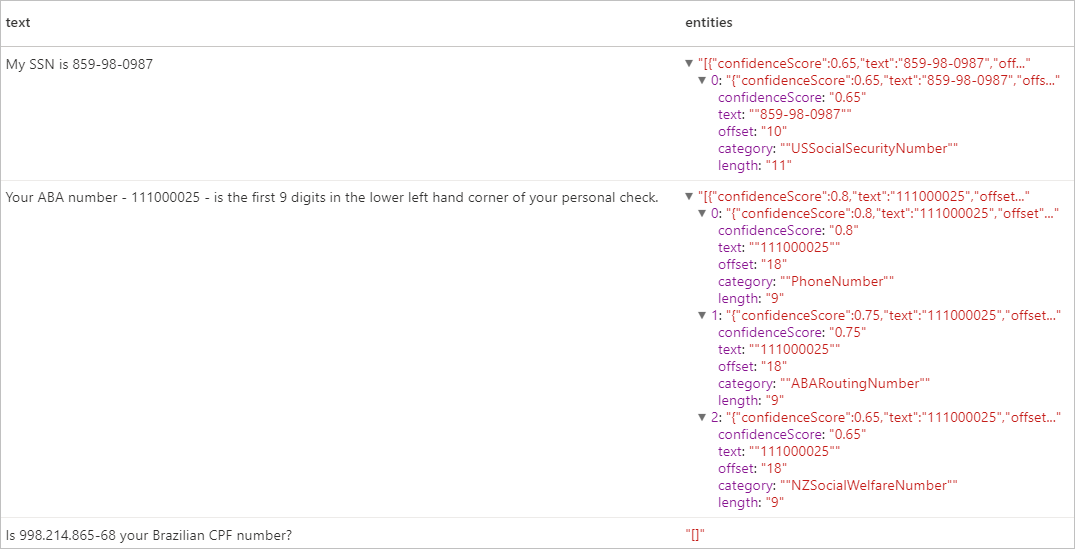
Limpar os recursos
Para garantir que a instância do Spark seja desligada, encerre todas as sessões conectadas (notebooks). O pool é desligado quando o tempo ocioso especificado no Pool do Apache Spark é atingido. Você também pode selecionar encerrar sessão na barra de status na parte superior direita do notebook.
