Transformar dados executando um notebook do Synapse
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
A atividade do notebook do Azure Synapse em um pipeline do Synapse executa um notebook do Synapse. Este artigo se baseia no artigo sobre atividades de transformação de dados que apresenta uma visão geral da transformação de dados e as atividades de transformação permitidas.
Criar uma atividade de notebook do Synapse
Você pode criar uma atividade de notebook do Synapse diretamente na tela do pipeline do Synapse ou no editor de notebook. A atividade de notebook do Synapse é executada no pool do Spark que é escolhido no notebook do Synapse.
Adicionar uma atividade de notebook do Synapse à tela do pipeline
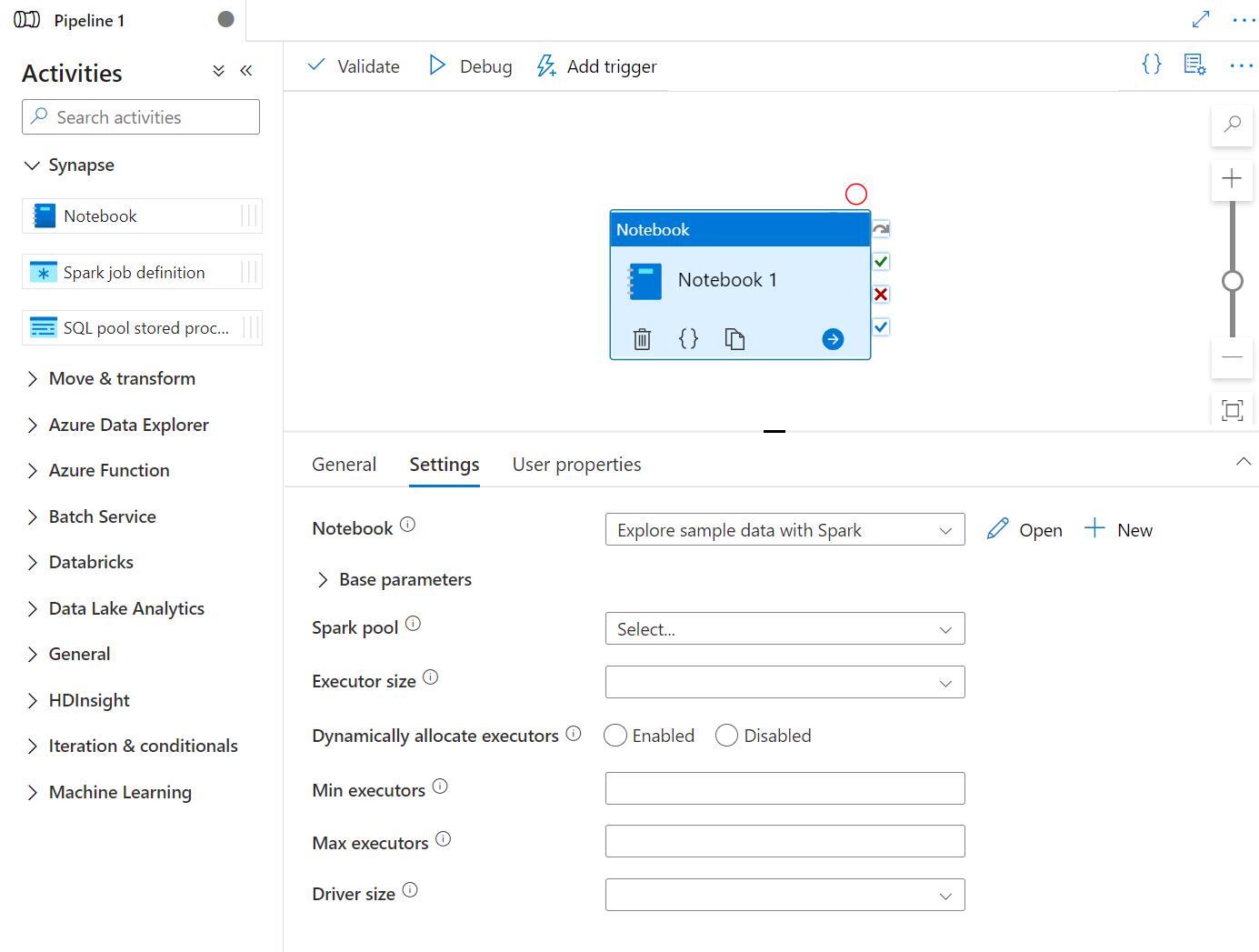
Arraste e solte o notebook do Synapse em Atividades até a tela do pipeline do Synapse. Selecione na caixa de atividade de notebook do Synapse e configure o conteúdo do notebook para a atividade atual nas configurações. Você pode selecionar um notebook existente no workspace atual ou adicionar um novo.
Se você selecionar um bloco de anotações existente no workspace atual, poderá clicar no botão Abrir para abrir diretamente a página do bloco de anotações.
(Opcional) Você também pode reconfigurar o pool do Spark\Tamanho do executor\Alocar executores dinamicamente\Mínimo de executores\Máximo de executores\Tamanho do driver nas configurações. Observe que as configurações redefinidas aqui substituirão as definições da sessão de configuração no Notebook. Se não houver nada definido nas configurações da atividade atual do notebook, ele será executado com as definições da sessão de configuração nesse notebook.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| Pool do Spark | Referência ao Pool do Spark. Você pode selecionar o pool do Apache Spark na lista. Se essa configuração estiver vazia, ela será executada no Pool do Spark do próprio notebook. | No |
| Tamanho do executor | O número de núcleos e a memória a serem usados para os executores alocados no Pool do Apache Spark especificado para a sessão. | No |
| Alocar executores dinamicamente | Esta configuração é mapeada para a propriedade de alocação dinâmica na configuração do Spark para a alocação de executores do Aplicativo Spark. | No |
| Mínimo de executores | Número mínimo de executores a serem alocados no Pool do Spark especificado para o trabalho. | No |
| Máximo de executores | Número máximo de executores a serem alocados no Pool do Spark especificado para o trabalho. | No |
| Tamanho do driver | Número de núcleos e memória a serem usados para o driver fornecido no pool do Apache Spark especificado para o trabalho. | No |
Observação
A execução de notebooks Spark paralelos em pipelines do Azure Synapse é colocada na fila e executada de modo PEPS, a ordem dos trabalhos na fila segue a sequência de tempo e o tempo de expiração de um trabalho na fila é de três dias. Observe que a fila de notebooks só funciona no pipeline do Azure Synapse.
Adicionar um notebook a um pipeline do Synapse
Selecione o botão Adicionar ao pipeline no canto superior direito para adicionar um notebook a um pipeline existente ou criar um novo pipeline.

Passando parâmetros
Designar uma célula de parâmetros
Para parametrizar o seu notebook, selecione as reticências (...) para acessar mais comandos na barra de ferramentas da célula. Em seguida, selecione Alternar célula de parâmetro para designar a célula como a célula de parâmetros.

Defina seus parâmetros nesta célula. Pode ser algo tão simples quanto:
a = 1
b = 3
c = "Default Value"
Você pode referenciar esses parâmetros em outras células e quando executar o notebook para usar os valores padrão especificados na célula de parâmetros.
Quando você executa esse notebook de um pipeline, o Azure Data Factory procura a célula de parâmetros e usa os valores fornecidos como padrão para os parâmetros passados no momento da execução. Se você atribuir valores de parâmetros de um pipeline, o mecanismo de execução adicionará uma nova célula abaixo da célula de parâmetros com parâmetros de entrada para substituir os valores padrão.
Atribuir valores de parâmetros de um pipeline
Depois de criar um notebook com parâmetros, você pode executá-lo a partir de um pipeline com a atividade do notebook do Synapse. Depois de adicionar a atividade à tela do pipeline, você poderá definir os valores dos parâmetros na seção Parâmetros de base na guia Configurações.

Dica
O Data Factory não preencherá automaticamente os parâmetros. Você precisará adicioná-los manualmente. Certifique-se de usar exatamente o mesmo nome em sua célula de parâmetros no notebook e no parâmetro base no pipeline.
Depois de adicionar seus parâmetros à sua atividade, o Data Factory passará os valores especificados em sua atividade para o bloco de anotações e o bloco de anotações será executado com esses novos valores de parâmetro, em vez dos padrões especificados na célula de parâmetros.
Ao atribuir valores de parâmetro, você pode usar a linguagem de expressão de pipeline ou variáveis do sistema.
Ler o valor de saída da célula do notebook do Synapse
Você pode ler o valor de saída da célula do notebook nas próximas atividades seguindo as etapas abaixo:
Chame a API mssparkutils.notebook.exit na atividade do seu notebook do Synapse para retornar o valor que você deseja mostrar na saída da atividade, por exemplo:
mssparkutils.notebook.exit("hello world")Ao salvar o conteúdo do notebook e disparar novamente o pipeline, a saída da atividade do notebook conterá o exitValue que poderá ser consumido para as atividades a seguir na etapa 2.
Leia a propriedade exitValue da saída da atividade do notebook. A seguir, apresentamos um exemplo de expressão usada para verificar se o exitValue buscado da saída da atividade do notebook é igual a "hello world":


Executar outro notebook do Synapse
Você pode fazer referência a outros notebooks em uma atividade de notebook do Synapse ao chamar %run magic ou mssparkutils notebook utilities. Ambos dão suporte a chamadas de função aninhadas. As principais diferenças desses dois métodos que você deve considerar com base em seu cenário são:
- %run magic copia todas as células do notebook referenciado para a célula %run e compartilha o contexto da variável. Quando o notebook1 referenciar o notebook2 via
%run notebook2e o notebook2 chamar uma função mssparkutils.notebook.exit, a execução da célula no notebook1 será interrompida. Recomendamos que você use %run magic quando quiser "incluir" um arquivo de notebook. - mssparkutils notebook utilities chama o notebook referenciado como um método ou uma função. O contexto da variável não é compartilhado. Quando o notebook1 referenciar o notebook2 via
mssparkutils.notebook.run("notebook2")e o notebook2 chamar uma função mssparkutils.notebook.exit, a execução da célula no notebook1 continuará. Recomendamos que você use mssparkutils notebook utilities quando quiser "importar" um notebook.
Confira o histórico de execuções de atividades do notebook
Vá até Execuções de pipeline na guia Monitor para ver o pipeline acionado. Abra o pipeline que contém a atividade do notebook para ver o histórico de execuções.
Você pode ver o instantâneo de execuções mais recente do notebook, incluindo as células de entrada e saída, selecionando o botão abrir notebook.
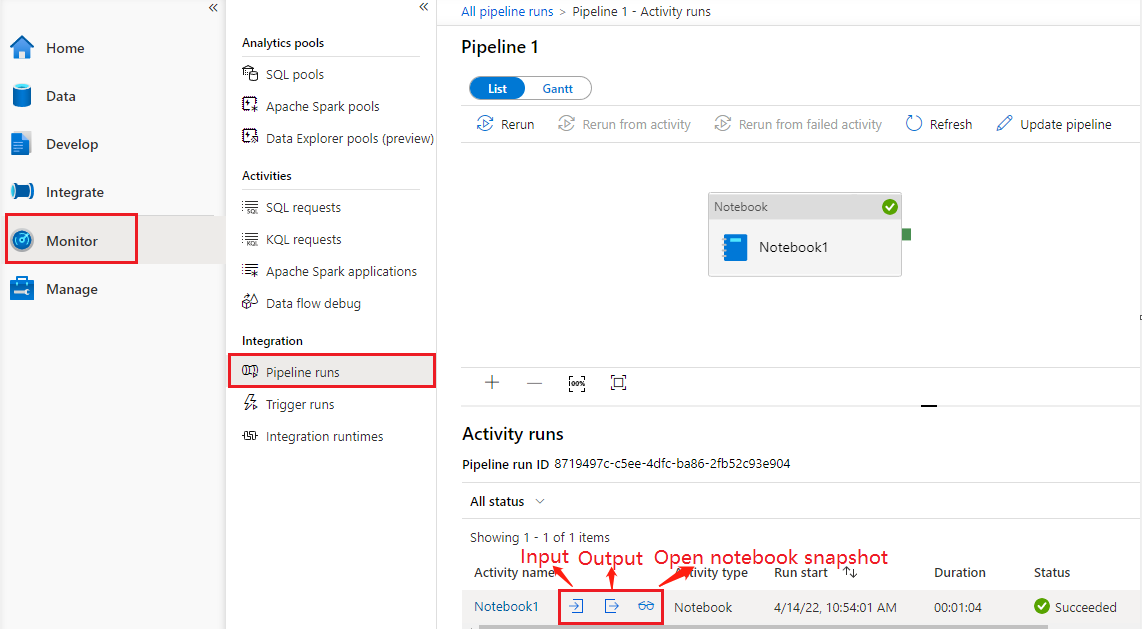
Abrir instantâneo do notebook:
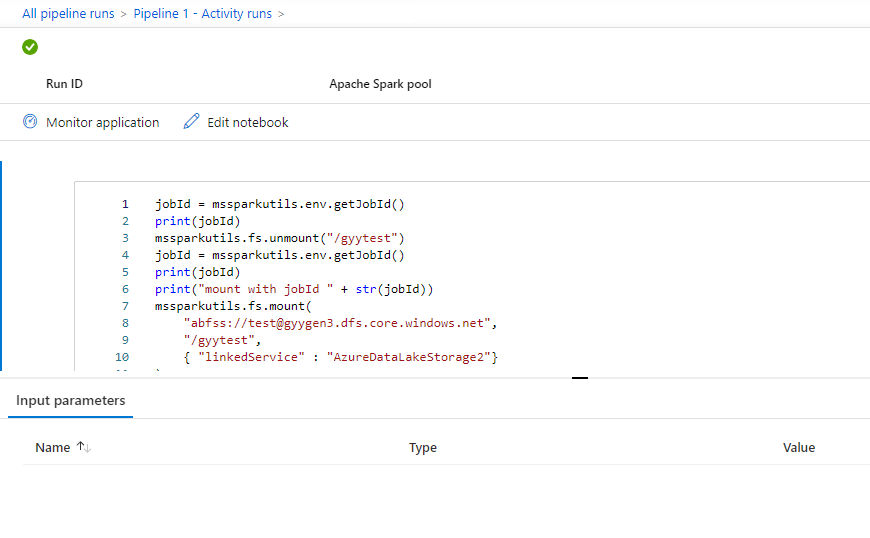
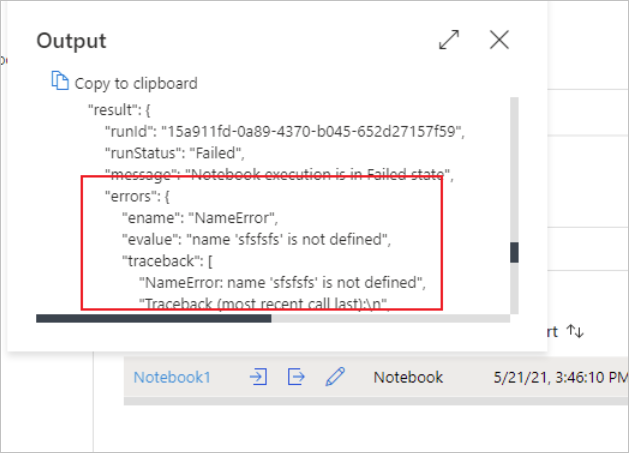
Você pode ver as entradas ou saídas de atividades do notebook ao selecionar o botão Entrada ou Saída. Se o seu pipeline falhar com um erro de usuário, selecione a saída para verificar o campo resultado e ver o detalhamento do erro de usuário.
Definição de atividade do notebook do Synapse
Confira um exemplo de definição JSON de uma atividade do notebook do Synapse:
{
"name": "parameter_test",
"type": "SynapseNotebook",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"notebook": {
"referenceName": "parameter_test",
"type": "NotebookReference"
},
"parameters": {
"input": {
"value": {
"value": "@pipeline().parameters.input",
"type": "Expression"
}
}
}
}
}
Saída de atividade do notebook do Synapse
Confira um exemplo de JSON de uma saída de atividade de notebook do Synapse:
{
{
"status": {
"Status": 1,
"Output": {
"status": <livySessionInfo>
},
"result": {
"runId": "<GUID>",
"runStatus": "Succeed",
"message": "Notebook execution is in Succeeded state",
"lastCheckedOn": "2021-03-23T00:40:10.6033333Z",
"errors": {
"ename": "",
"evalue": ""
},
"sessionId": 4,
"sparkpool": "sparkpool",
"snapshotUrl": "https://myworkspace.dev.azuresynapse.net/notebooksnapshot/{guid}",
"exitCode": "abc" // return value from user notebook via mssparkutils.notebook.exit("abc")
}
},
"Error": null,
"ExecutionDetails": {}
},
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (West US 2)",
"executionDuration": 234,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "ExternalActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "Hours"
}
]
}
}
Problemas conhecidos
Se o nome do notebook for parametrizado na atividade do Pipeline Notebook, a versão do notebook em status não publicado não poderá ser referenciada nas execuções de depuração.