Fazer backup e recuperar o Oracle Database em uma VM Linux do Azure utilizando o Backup do Azure
Aplica-se a: ✔️ VMs do Linux
Esse artigo demonstra o uso do Backup do Azure para tirar instantâneos de discos de máquinas virtuais (VMs), que incluem os arquivos do Oracle Database e a área de recuperação rápida do Oracle. Ao usar o Backup do Azure, você pode tirar instantâneos completos do disco que são adequados como backups e são armazenados em um Cofre dos Serviços de Recuperação.
O Backup do Azure também fornece backups consistentes com o aplicativo, o que garante que mais correções não sejam necessárias para restaurar os dados. Os backups consistentes com aplicativos funcionam tanto com sistemas de arquivos quanto com bancos de dados Oracle Automatic Storage Management (ASM).
Restaurar dados consistentes com o aplicativo reduz o tempo de restauração, para que você possa retornar rapidamente a um estado de execução. A recuperação do Oracle Database ainda é necessária após a restauração. Você facilita a recuperação usando arquivos de log de redo arquivados da Oracle que são capturados e armazenados em um compartilhamento de arquivos separado do Azure.
Esse artigo orienta você nas seguintes tarefas:
- Faça backup do banco de dados com backup consistente com o aplicativo.
- Restaure e recupere o banco de dados de um ponto de recuperação.
- Restaure a VM a partir de um ponto de recuperação.
Pré-requisitos
Use o ambiente Bash no Azure Cloud Shell. Para obter mais informações, confira Início Rápido para Bash no Azure Cloud Shell.

Se preferir executar os comandos de referência da CLI localmente, instale a CLI do Azure. Para execuções no Windows ou no macOS, considere executar a CLI do Azure em um contêiner do Docker. Para obter mais informações, confira Como executar a CLI do Azure em um contêiner do Docker.
Se estiver usando uma instalação local, entre com a CLI do Azure usando o comando az login. Para concluir o processo de autenticação, siga as etapas exibidas no terminal. Para ver outras opções de entrada, confira Conectar-se com a CLI do Azure.
Quando solicitado, instale a extensão da CLI do Azure no primeiro uso. Para obter mais informações sobre extensões, confira Usar extensões com a CLI do Azure.
Execute az version para localizar a versão e as bibliotecas dependentes que estão instaladas. Para fazer a atualização para a versão mais recente, execute az upgrade.
Para executar o processo de backup e recuperação, você deve primeiro criar uma VM Linux que tenha uma instância instalada do Oracle Database 12.1 ou posterior.
Crie uma instância do Oracle Database seguindo as etapas em Criar uma instância do Oracle Database em uma VM do Azure.
Preparar o ambiente
Para preparar o ambiente, conclua estas etapas:
Conectar-se à VM
Para criar uma sessão SSH (Secure Shell) com a VM, use o comando a seguir. Substitua
<publicIpAddress>pelo valor do endereço público de sua VM.ssh azureuser@<publicIpAddress>Mude para o usuário raiz:
sudo su -Adicione o usuário
oracleao arquivo /etc/sudoers:echo "oracle ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
Configurar o armazenamento de Arquivos do Azure para os arquivos de log de redo arquivados do Oracle
Os arquivos de log de redo arquivados da instância do Oracle Database desempenham um papel crucial na recuperação do banco de dados. Eles armazenam as transações confirmadas necessárias para avançar a partir de um instantâneo de banco de dados obtido no passado.
Quando o banco de dados está no modo ARCHIVELOG, ele arquiva o conteúdo dos arquivos de log de refazer online quando eles ficam cheios e alternam. Junto com um backup, eles são necessários para obter a recuperação em um momento específico quando o banco de dados é perdido.
O Oracle oferece a capacidade de arquivar arquivos de log de redo em diferentes locais. A prática recomendada do setor é que pelo menos um desses destinos esteja no armazenamento remoto, de modo que seja separado do armazenamento do host e protegido com instantâneos independentes. O Arquivos do Azure atende a esses requisitos.
Um compartilhamento de arquivos do Azure é um armazenamento que você pode anexar a uma VM Linux ou Windows como um componente regular do sistema de arquivos, usando o protocolo Server Message Block (SMB) ou Network File System (NFS). Para configurar um compartilhamento de arquivos do Azure no Linux (usando o protocolo SMB 3.0) para uso como armazenamento de log de arquivamento, consulte Montar um compartilhamento de arquivos do Azure SMB no Linux. Quando concluir a configuração, retorne a este guia e conclua todas as etapas restantes.
Preparar os bancos de dados
Essa parte do processo pressupõe que você seguiu Crie uma instância do Oracle Database em uma VM do Azure. Como resultado:
- Você tem uma instância Oracle chamada
oratest1que está sendo executada em uma VM chamadavmoracle19c. - Você está usando o script padrão do Oracle
oraenvcom sua dependência no arquivo de configuração padrão do Oracle /etc/oratab para configurar variáveis de ambiente em uma sessão de shell.
Execute as seguintes etapas para cada banco de dados na VM:
Alterne para o usuário
oracle:sudo su - oracleDefina a variável de ambiente
ORACLE_SIDexecutando o scriptoraenv. Ele solicita que você insira o nome doORACLE_SID.. oraenvAdicione o compartilhamento de arquivos do Azure como outro destino para arquivos de log de arquivamento de banco de dados.
Essa etapa pressupõe que você configurou e montou um compartilhamento de arquivos do Azure na VM Linux. Para cada banco de dados instalado na VM, crie um subdiretório com o nome do seu identificador de segurança (SID) do banco de dados.
Nesse exemplo, o nome do ponto de montagem é
/backupe o SID éoratest1. Então você cria o subdiretório/backup/oratest1e muda a propriedade para o usuáriooracle. Substitua/backup/SIDpelo nome do seu ponto de montagem e pelo SID do banco de dados.sudo mkdir /backup/oratest1 sudo chown oracle:oinstall /backup/oratest1Conecte-se ao banco de dados:
sqlplus / as sysdbaInicie o banco de dados se ainda não estiver em execução:
SQL> startupDefina o primeiro destino de log de arquivamento do banco de dados para o diretório de compartilhamento de arquivos que você criou anteriormente:
SQL> alter system set log_archive_dest_1='LOCATION=/backup/oratest1' scope=both;Defina o RPO (objetivo de ponto de recuperação) para o banco de dados.
Para obter um RPO consistente, considere a frequência com que os arquivos de log de redo online são arquivados. Esses fatores controlam a frequência:
- O tamanho dos arquivos de log de refazer online. À medida que um arquivo de log online fica cheio, ele é alternado e arquivado. Quanto maior o arquivo de log online, mais tempo levará para ser preenchido. O tempo adicional diminui a frequência de geração de arquivo.
- A configuração do parâmetro
ARCHIVE_LAG_TARGETcontrola o número máximo de segundos permitidos antes que o arquivo de log online atual precise ser alternado e arquivado.
Para minimizar a frequência de alternância e arquivamento, juntamente com a operação de ponto de verificação que a acompanha, os arquivos de log de refazer online do Oracle geralmente têm um tamanho grande (por exemplo, 1.024M, 4.096M ou 8.192M). Em um ambiente de banco de dados movimentado, ainda é provável que os logs sejam alternados e arquivados a cada poucos segundos ou minutos. Em um banco de dados menos ativo, eles podem passar horas ou dias antes de as transações mais recentes serem arquivadas, o que diminuiria drasticamente a frequência de arquivamento.
Recomendamos que você defina
ARCHIVE_LAG_TARGETpara garantir um RPO consistente. Uma configuração de 5 minutos (300 segundos) é um valor prudente paraARCHIVE_LAG_TARGET. Ele garante que qualquer operação de recuperação de banco de dados possa ser recuperada em até 5 minutos a partir do momento da falha.Para definir
ARCHIVE_LAG_TARGET, execute esse comando:SQL> alter system set archive_lag_target=300 scope=both;Para entender melhor como implantar instâncias do Oracle Database de alta disponibilidade no Azure com RPO zero, veja Arquiteturas de referência para o Oracle Database.
Verifique se o banco de dados está no modo de log de arquivos para habilitar backups online.
Verifique o status do arquivo de log primeiro:
SQL> SELECT log_mode FROM v$database; LOG_MODE ------------ NOARCHIVELOGSe estiver no modo
NOARCHIVELOG, execute os seguintes comandos:SQL> SHUTDOWN IMMEDIATE; SQL> STARTUP MOUNT; SQL> ALTER DATABASE ARCHIVELOG; SQL> ALTER DATABASE OPEN; SQL> ALTER SYSTEM SWITCH LOGFILE;Crie uma tabela para testar as operações de backup e restauração:
SQL> create user scott identified by tiger quota 100M on users; SQL> grant create session, create table to scott; SQL> connect scott/tiger SQL> create table scott_table(col1 number, col2 varchar2(50)); SQL> insert into scott_table VALUES(1,'Line 1'); SQL> commit; SQL> quit
Faça backup dos seus dados usando o Backup do Azure
O serviço de Backup do Azure fornece soluções para fazer backup dos seus dados e recuperá-los da nuvem do Microsoft Azure. O Backup do Azure fornece backups independentes e isolados para proteger contra a destruição acidental de dados originais. Os backups são armazenados em um cofre dos Serviços de Recuperação com gerenciamento integrado de pontos de recuperação, para que você possa restaurar conforme necessário.
Nessa seção, você usará o Backup do Azure para tirar instantâneos consistentes do aplicativo de suas instâncias de VM e Oracle Database em execução. Os bancos de dados são colocados no modo de backup, o que permite que um backup online transacionalmente consistente ocorra enquanto o Backup do Azure tira um instantâneo dos discos da VM. O snapshot é uma cópia completa do armazenamento e não um snapshot incremental ou de cópia na gravação. É um meio eficaz para restaurar seu banco de dados.
A vantagem de usar instantâneos consistentes com o aplicativo do Azure Backup é que eles são rápidos de tirar, não importa o tamanho do seu banco de dados. Você pode usar um snapshot para operações de restauração assim que o tirar, sem precisar esperar que ele seja transferido para o cofre dos Serviços de Recuperação.
Para usar o Backup do Azure para fazer backup do banco de dados, conclua estas etapas:
- Entenda a estrutura do Backup do Azure.
- Preparar o ambiente para um backup consistente com o aplicativo.
- Configurar os backups consistentes com o aplicativo.
- Disparar um backup consistente com o aplicativo da VM.
Entenda a estrutura do Backup do Azure
O serviço de Backup do Azure fornece uma estrutura para obter consistência de aplicativos durante backups de VMs Windows e Linux para vários aplicativos. Essa estrutura envolve invocar um pré-script para fechar os aplicativos para novas sessões antes de tirar um instantâneo dos discos. Ele chama um pós-script para descongelar os aplicativos após a conclusão do instantâneo.
A Microsoft aprimorou a estrutura para que o serviço de Backup do Azure forneça pré-scripts e pós-scripts empacotados para aplicativos selecionados. Esses pré-scripts e pós-scripts já estão carregados na imagem do Linux, então não há nada para você instalar. Basta nomear o aplicativo e o Backup do Azure invoca automaticamente os scripts relevantes. A Microsoft gerencia os pré-scripts e pós-scripts empacotados, então você pode ter certeza do suporte, propriedade e validade desses scripts.
Atualmente, os aplicativos suportados pela estrutura aprimorada são Oracle 12.x ou posterior e MySQL. Para obter detalhes, veja Matriz de suporte para backups gerenciados de VM do Azure.
Você pode criar seus próprios scripts para o Backup do Azure para usar com bancos de dados anteriores à versão 12.x. Exemplos de scripts estão disponíveis em GitHub.
Cada vez que você faz um backup, a estrutura aprimorada executa os pré-scripts e pós-scripts em todas as instâncias do Oracle Database instaladas na VM. O parâmetro configuration_path no arquivo workload.conf aponta para o local do arquivo Oracle /etc/oratab (ou um arquivo definido pelo usuário que segue a sintaxe oratab). Para obter detalhes, veja Configurar backups consistentes com o aplicativo.
O Backup do Azure executa os pré-scripts e pós-scripts para cada banco de dados listado no arquivo que configuration_path aponta. Exceções são linhas que começam com # (tratadas como comentário) ou +ASM (uma instância do Oracle ASM).
A estrutura aprimorada do Backup do Azure faz backups online de instâncias do Oracle Database que operam no modo ARCHIVELOG. Os pré-scripts e pós-scripts usam os comandos ALTER DATABASE BEGIN e END BACKUP para obter consistência no aplicativo.
Para que o backup do banco de dados seja consistente, os bancos de dados no modo NOARCHIVELOG devem ser desligados corretamente antes do início do snapshot.
Preparar o ambiente para um backup consistente com o aplicativo
O Oracle Database emprega a separação de funções de trabalho para fornecer separação de tarefas usando o menor privilégio. Ele associa grupos separados de sistemas operacionais (SO) a funções administrativas de banco de dados separadas. Os usuários podem então ter diferentes privilégios de banco de dados concedidos a eles, dependendo de sua associação em grupos de sistemas operacionais.
A função SYSBACKUP database (nome genérico OSBACKUPDBA) fornece privilégios limitados para executar operações de backup no banco de dados. O Backup do Azure exige isso.
Durante a instalação do Oracle, recomendamos que você use backupdba como o nome do grupo de SO para associar à função SYSBACKUP. Mas você pode usar qualquer nome, então você precisa determinar primeiro o nome do grupo de SO que representa a função Oracle SYSBACKUP.
Alterne para o usuário
oracle:sudo su - oracleDefina o ambiente Oracle:
export ORACLE_SID=oratest1 export ORAENV_ASK=NO . oraenvDetermine o nome do grupo de SO que representa a função Oracle
SYSBACKUP:grep "define SS_BKP" $ORACLE_HOME/rdbms/lib/config.cA saída deve ser semelhante ao seguinte exemplo:
#define SS_BKP_GRP "backupdba"Na saída, o valor entre aspas duplas é o nome do grupo do sistema operacional Linux no qual a função Oracle
SYSBACKUPé autenticada externamente. Neste exemplo, ébackupdba. Anote o valor real.Verifique se o grupo de SO existe executando o seguinte comando. Substitua
<group name>pelo valor que o comando anterior retornou (sem as aspas).grep <group name> /etc/groupA saída deve ser semelhante ao seguinte exemplo:
backupdba:x:54324:oracleImportante
Se a saída não corresponder ao valor do grupo do sistema operacional Oracle recuperado na etapa 3, use o comando a seguir para criar o grupo do sistema operacional que representa a função Oracle
SYSBACKUP. Substitua<group name>pelo nome do grupo que você recuperou na etapa 3.sudo groupadd <group name>Crie um novo usuário de backup chamado
azbackupque pertença ao grupo de sistemas operacionais que você verificou ou criou nas etapas anteriores. Substitua<group name>pelo nome do grupo verificado. O usuário também é adicionado ao grupooinstallpara permitir a abertura de discos ASM.sudo useradd -g <group name> -G oinstall azbackupConfigure a autenticação externa para o novo usuário de backup.
O usuário de backup
azbackupprecisa conseguir acessar o banco de dados usando autenticação externa, para que não seja desafiado por uma senha. Para habilitar esse acesso, você deve criar um usuário de banco de dados que se autentique externamente por meio deazbackup. O banco de dados usa um prefixo para o nome de usuário, que você precisa encontrar.Execute as seguintes etapas em cada banco de dados instalado na VM:
Entre no banco de dados usando o SQL Plus e verifique as configurações padrão para autenticação externa:
sqlplus / as sysdba SQL> show parameter os_authent_prefix SQL> show parameter remote_os_authentA saída deve ser semelhante a este exemplo, que mostra
ops$como prefixo de nome de usuário do banco de dados:NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ os_authent_prefix string ops$ remote_os_authent boolean FALSECrie um usuário de banco de dados chamado
ops$azbackuppara autenticação externa aoazbackupusuário e concedaSYSBACKUPprivilégios:SQL> CREATE USER ops$azbackup IDENTIFIED EXTERNALLY; SQL> GRANT CREATE SESSION, ALTER SESSION, SYSBACKUP TO ops$azbackup;
Se você receber o erro
ORA-46953: The password file is not in the 12.2 formatao executar a instruçãoGRANT, siga essas etapas para migrar o arquivo orapwdpara o formato 12.2. Execute essas etapas para cada instância do Oracle Database na VM.Saia do SQL Plus.
Mude o arquivo de senha com o formato antigo para um novo nome.
Migre o arquivo de senha.
Exclua o arquivo antigo.
Execute os seguintes comandos:
mv $ORACLE_HOME/dbs/orapworatest1 $ORACLE_HOME/dbs/orapworatest1.tmp orapwd file=$ORACLE_HOME/dbs/orapworatest1 input_file=$ORACLE_HOME/dbs/orapworatest1.tmp rm $ORACLE_HOME/dbs/orapworatest1.tmpExecute novamente a operação
GRANTno SQL Plus.
Crie um procedimento armazenado para registrar mensagens de backup no log de alertas do banco de dados. Use o seguinte código para cada banco de dados instalado na VM:
sqlplus / as sysdba SQL> GRANT EXECUTE ON DBMS_SYSTEM TO SYSBACKUP; SQL> CREATE PROCEDURE sysbackup.azmessage(in_msg IN VARCHAR2) AS v_timestamp VARCHAR2(32); BEGIN SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') INTO v_timestamp FROM DUAL; DBMS_OUTPUT.PUT_LINE(v_timestamp || ' - ' || in_msg); SYS.DBMS_SYSTEM.KSDWRT(SYS.DBMS_SYSTEM.ALERT_FILE, in_msg); END azmessage; / SQL> SHOW ERRORS SQL> QUIT
Configure os backup consistente com o aplicativo
Mude para o usuário raiz:
sudo su -Verifique a pasta /etc/azure. Se não estiver presente, crie o diretório de trabalho para o backup consistente com o aplicativo:
if [ ! -d "/etc/azure" ]; then mkdir /etc/azure fiVerifique o arquivo workload.conf dentro da pasta. Se não estiver presente, crie-o no diretório /etc/azure e dê a ele o seguinte conteúdo. Os comentários devem começar com
[workload]. Se o arquivo já estiver presente, basta editar os campos para que correspondam ao conteúdo a seguir. Caso contrário, o comando a seguir cria o arquivo e preenche o conteúdo:echo "[workload] workload_name = oracle configuration_path = /etc/oratab timeout = 90 linux_user = azbackup" > /etc/azure/workload.confO arquivo workload.conf usa o seguinte formato:
- O parâmetro
workload_nameindica o tipo de carga de trabalho do banco de dados. Nesse caso, definir o parâmetro comoOraclepermite que o Backup do Azure execute os pré-scripts e pós-scripts corretos (comandos de consistência) para instâncias do Oracle Database. - O parâmetro
timeoutindica o tempo máximo, em segundos, que cada banco de dados deve concluir instantâneos de armazenamento. - O parâmetro
linux_userindica a conta de usuário do Linux que o Backup do Azure usa para executar operações de inatividade do banco de dados. Você criou esse usuário,azbackup, anteriormente. - O parâmetro
configuration_pathindica o nome do caminho absoluto para um arquivo de texto na VM. Cada linha lista uma instância de banco de dados em execução na VM. Normalmente, esse é o arquivo /etc/oratab que o Oracle gera durante a instalação do banco de dados, mas pode ser qualquer arquivo com qualquer nome que você escolher. Deve seguir essas regras de formato:- O arquivo é um arquivo de texto. Cada campo é delimitado pelo caractere dois pontos (
:). - O primeiro campo em cada linha é o nome de uma
ORACLE_SIDinstância. - O segundo campo em cada linha é o nome do caminho absoluto para
ORACLE_HOMEpara aquelaORACLE_SIDinstância. - Todo o texto após os dois primeiros campos será ignorado.
- Se a linha começar com um sinal de cerquilha (
#), a linha inteira será ignorada como um comentário. - Se o primeiro campo tiver o valor
+ASM, denotando uma instância do Oracle ASM, ele será ignorado.
- O arquivo é um arquivo de texto. Cada campo é delimitado pelo caractere dois pontos (
- O parâmetro
Dispare um backup consistente com o aplicativo da VM
No portal do Azure, acesse seu grupo de recursos rg-oracle e selecione sua máquina virtual vmoracle19c.
No painel Backup:
- Em Cofre de serviços de recuperação, selecione Criar novo.
- Para o nome do cofre, use myVault.
- Para Grupo de recursos, selecione rg-oracle.
- Em Escolher política de backup, use (new) DailyPolicy. Se você quiser alterar a frequência de backup ou o intervalo de retenção, selecione Criar uma nova política.
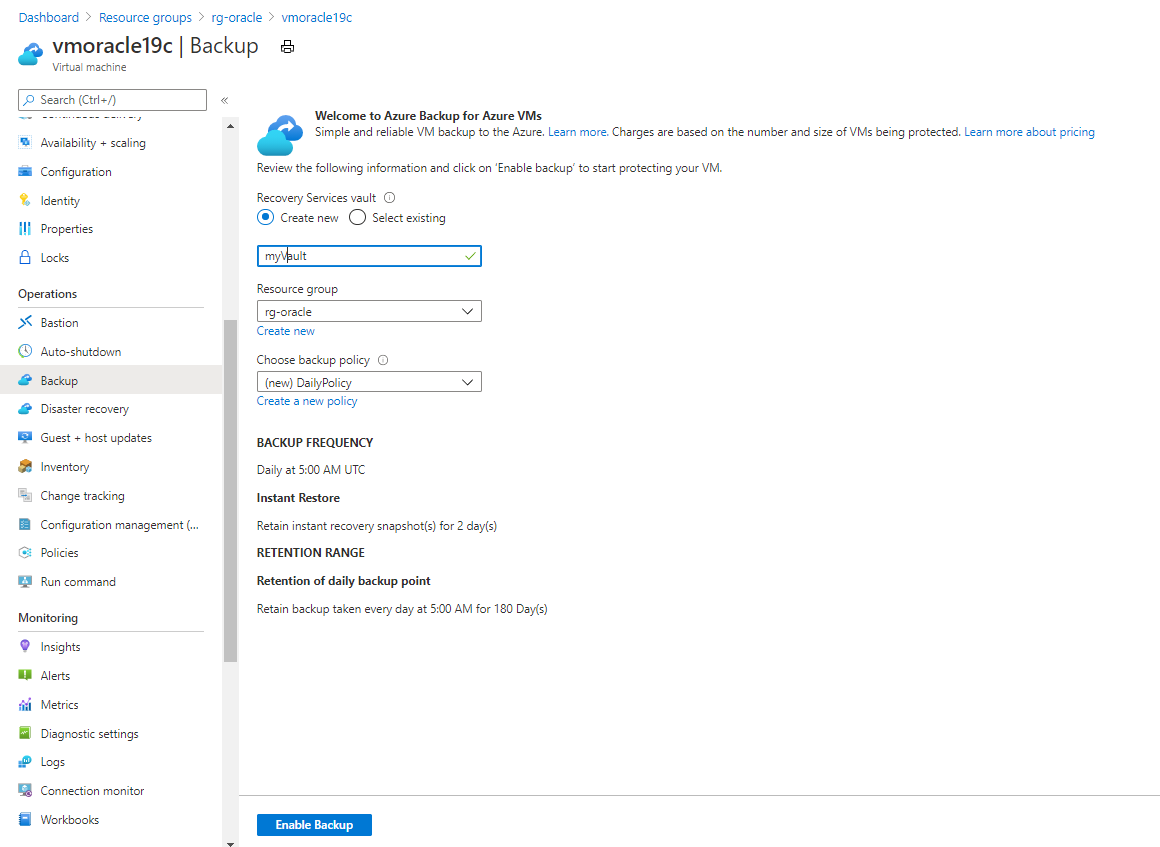
Selecione Habilitar Backup.
O processo de backup não inicia até que o tempo agendado expire. Para configurar um backup imediato, conclua a próxima etapa.
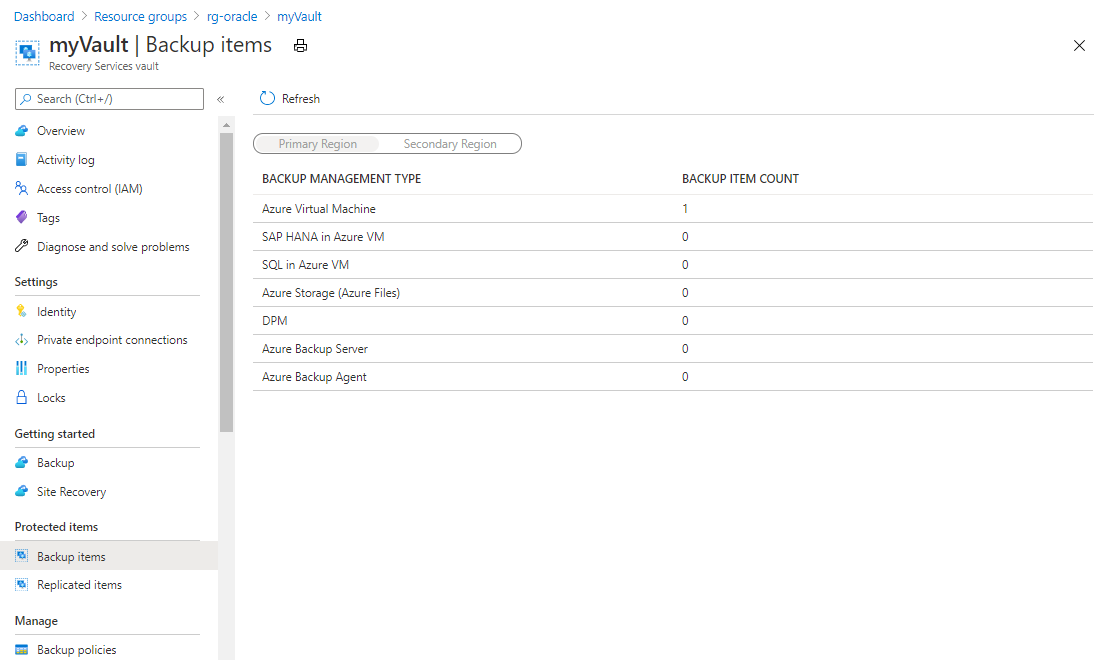
No painel do grupo de recursos, selecione seu cofre de Serviços de Recuperação recém-criado chamado myVault. Talvez seja necessário atualizar a página para vê-lo.
No painel myVault - Itens de backup, em BACKUP ITEM COUNT, selecione a contagem de itens de backup.
No painel Itens de backup (Máquina virtual do Azure), selecione o botão de reticências (...) e, em seguida, selecione Fazer backup agora.
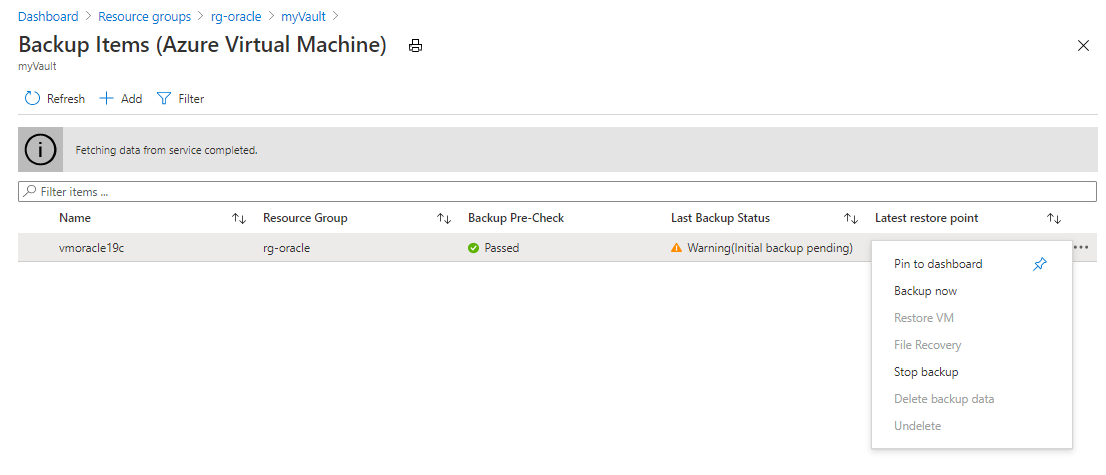
Aceite o valor padrão Manter backup até e selecione OK. Aguarde o processo de backup ser concluído.
Para visualizar o status do trabalho de backup, selecione Trabalhos de backup.
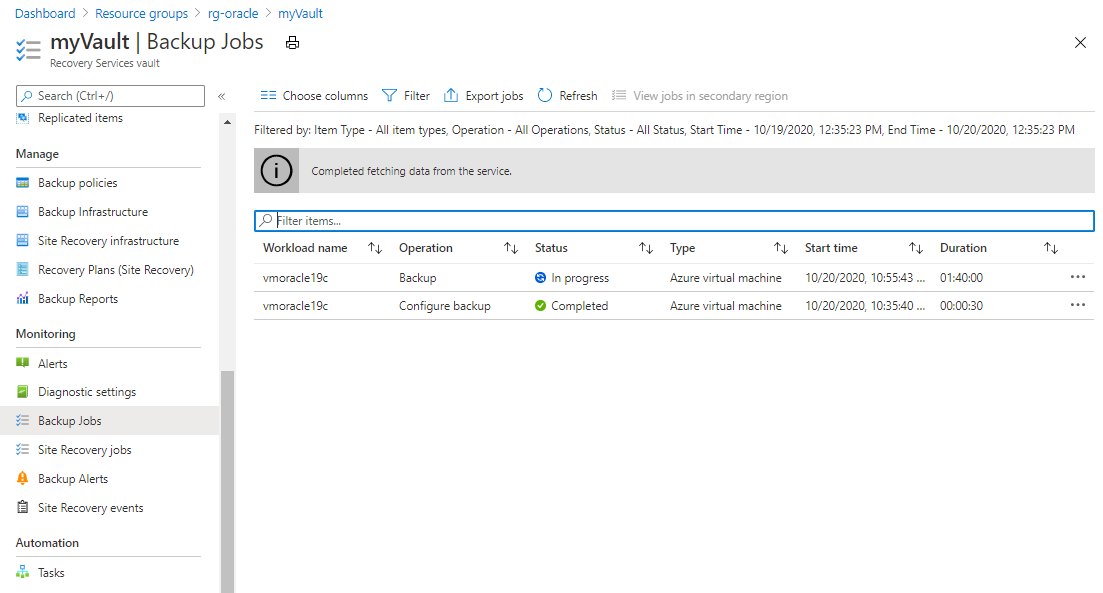
Selecione o trabalho de backup para ver detalhes sobre seu status.
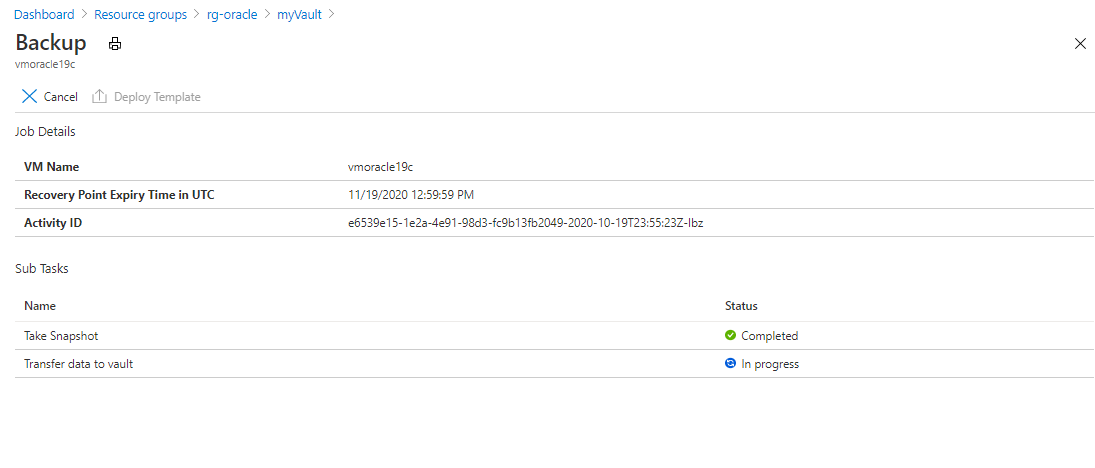
Embora leve alguns segundos para executar o instantâneo, pode levar mais tempo para transferi-lo para o cofre. O trabalho de backup não será concluído até que a transferência seja concluída.
Para um backup consistente com o aplicativo, resolva quaisquer erros no arquivo de log em /var/log/azure/Microsoft.Azure.RecoveryServices.VMSnapshotLinux/extension.log.
Restaurar a VM
Restaurar uma VM inteira significa restaurar a VM e seus discos anexados para uma nova VM a partir de um ponto de restauração selecionado. Essa ação também restaura todos os bancos de dados executados na VM. Depois, você precisa recuperar cada banco de dados.
Para restaurar uma VM inteira, conclua essas etapas:
Há duas opções principais ao restaurar uma VM:
- Restaure a VM da qual os backups foram originalmente feitos.
- Restaurar (clonar) uma nova VM sem afetar a VM da qual os backups foram originalmente feitos.
Os primeiros passos nesse exercício (parar, excluir e recuperar a VM) simulam o primeiro caso de uso.
Parar e excluir a VM
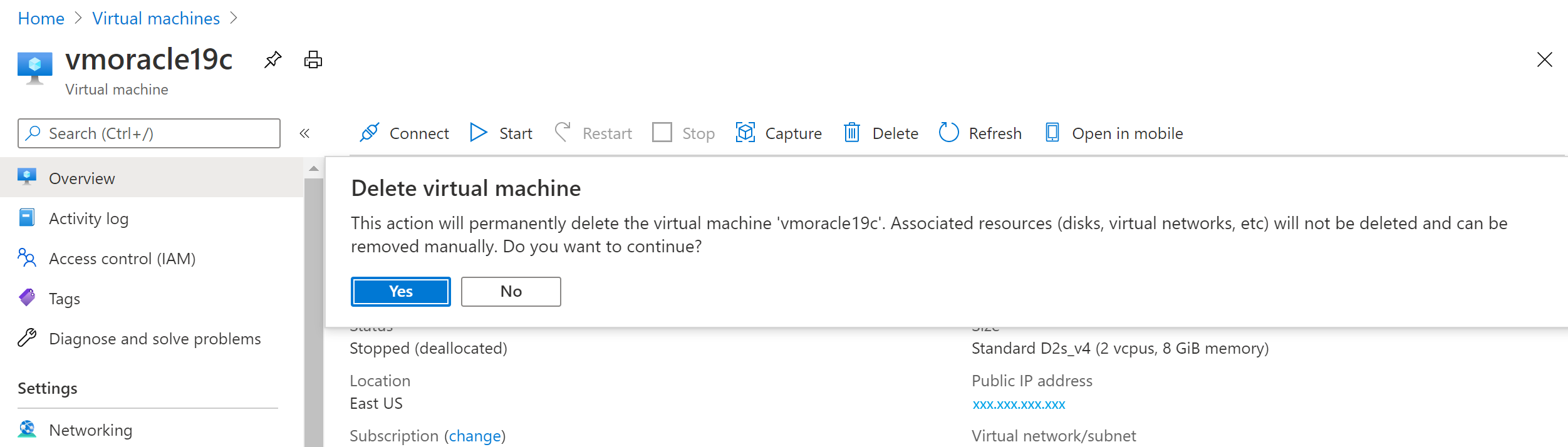
No portal do Azure, vá para a máquina virtual vmoracle19c e selecione Parar.
Quando a máquina virtual não estiver mais em execução, selecione Excluir e depois Sim.
Recuperar a VM
Crie uma conta de armazenamento para preparação no portal do Azure:
No portal do Azure, selecione + Criar um recurso e, em seguida, pesquise e selecione Conta de armazenamento.
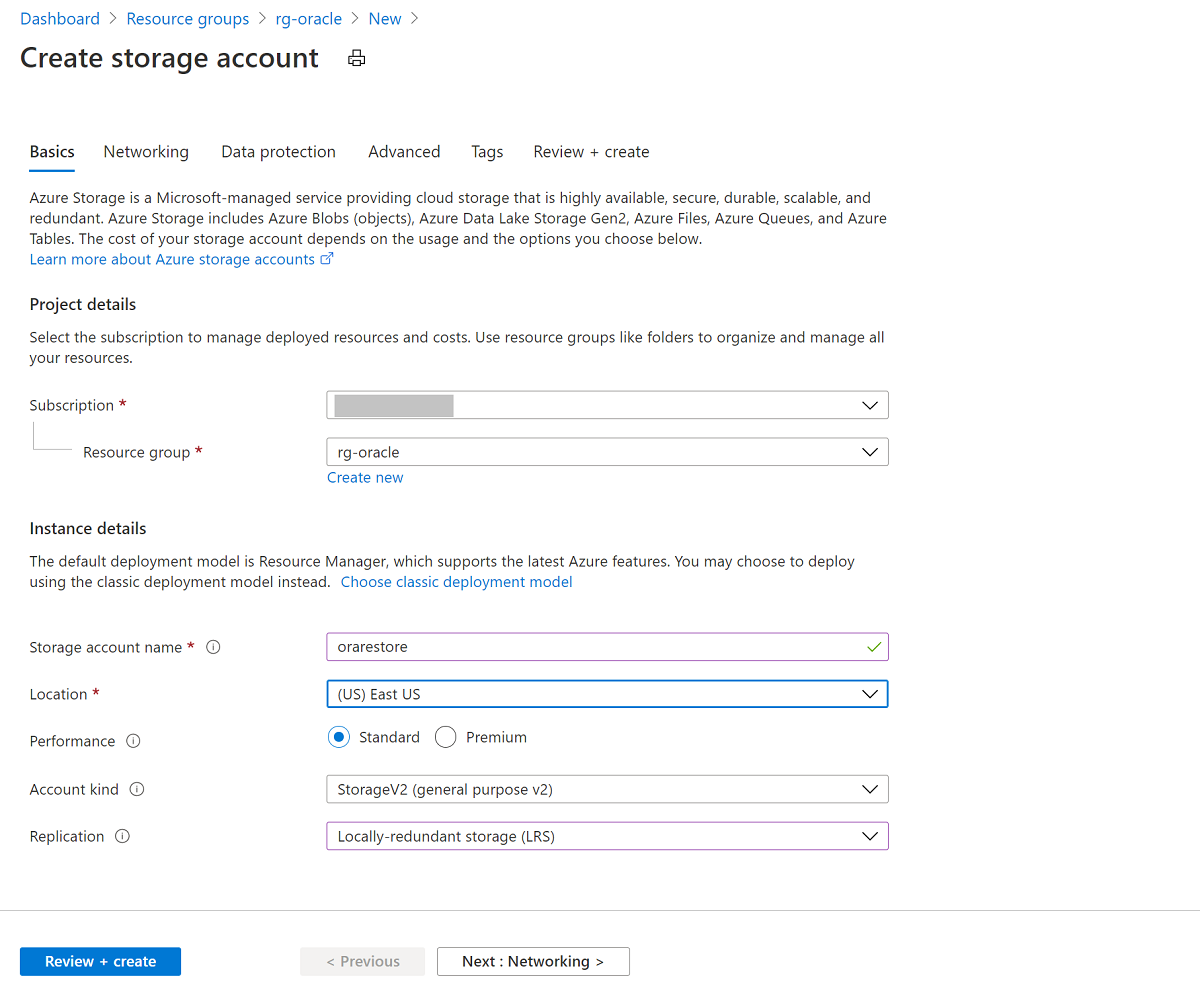
No painel Criar conta de armazenamento:
- Para Grupo de recursos, selecione seu grupo de recursos existente, rg-oracle.
- Para Nome da conta de armazenamento, insira oracrestore.
- Assegure-se de que Local esteja configurado para a mesma região de todos os outros recursos no grupo de recursos.
- Alto Desempenho para Standard.
- Para Tipo de conta, selecione StorageV2 (uso geral v2).
- Em Replicação, selecione Armazenamento com redundância local (LRS) .
Clique em Examinar + Criar, depois em Criar.
No portal do Azure, procure o cofre myVault Recovery Services e selecione-o.
No painel Visão geral, selecione Itens de backup. Em seguida, selecione Azure Virtual Machine, que deve ter um número diferente de zero para BACKUP ITEM COUNT.
No painel Itens de backup (máquina virtual do Azure), selecione a VM vmoracle19c.
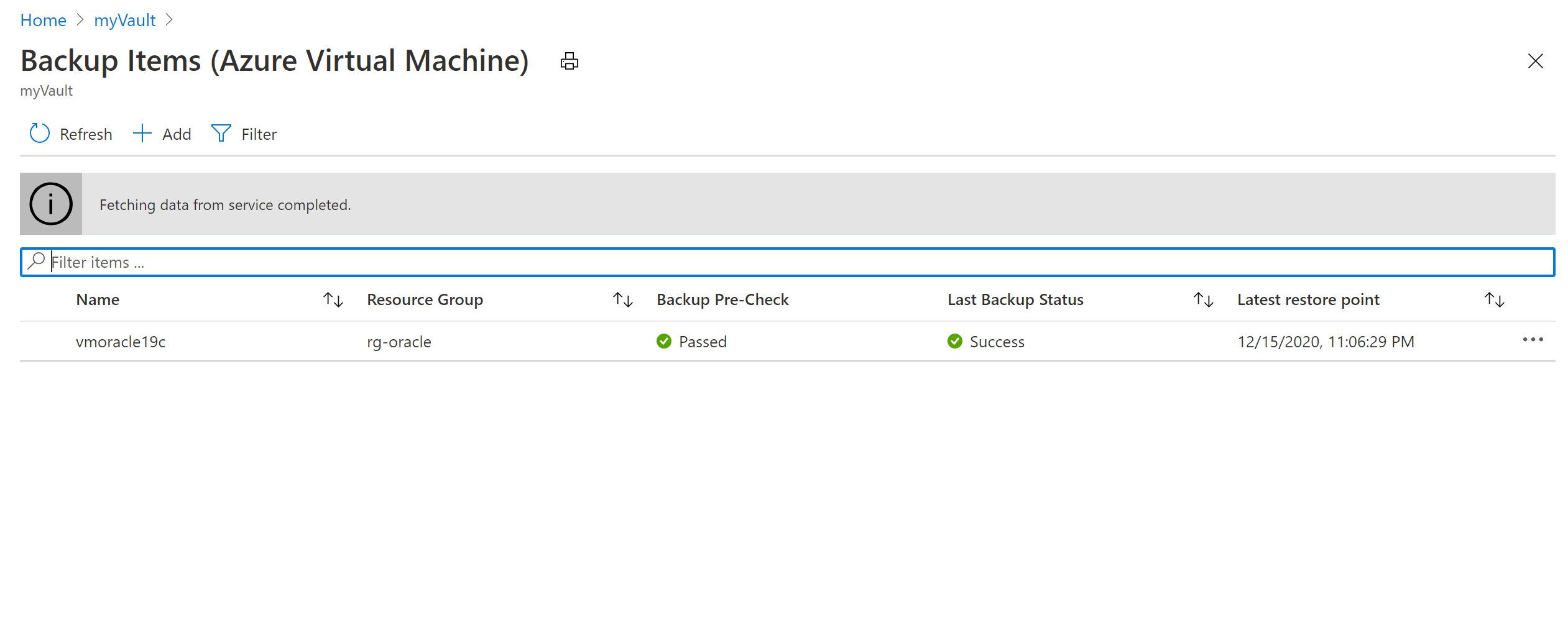
No painel vmoracle19c, escolha um ponto de restauração que tenha um tipo de consistência de Application Consistent. Selecione as reticências (...) e, em seguida, selecione Restaurar VM.
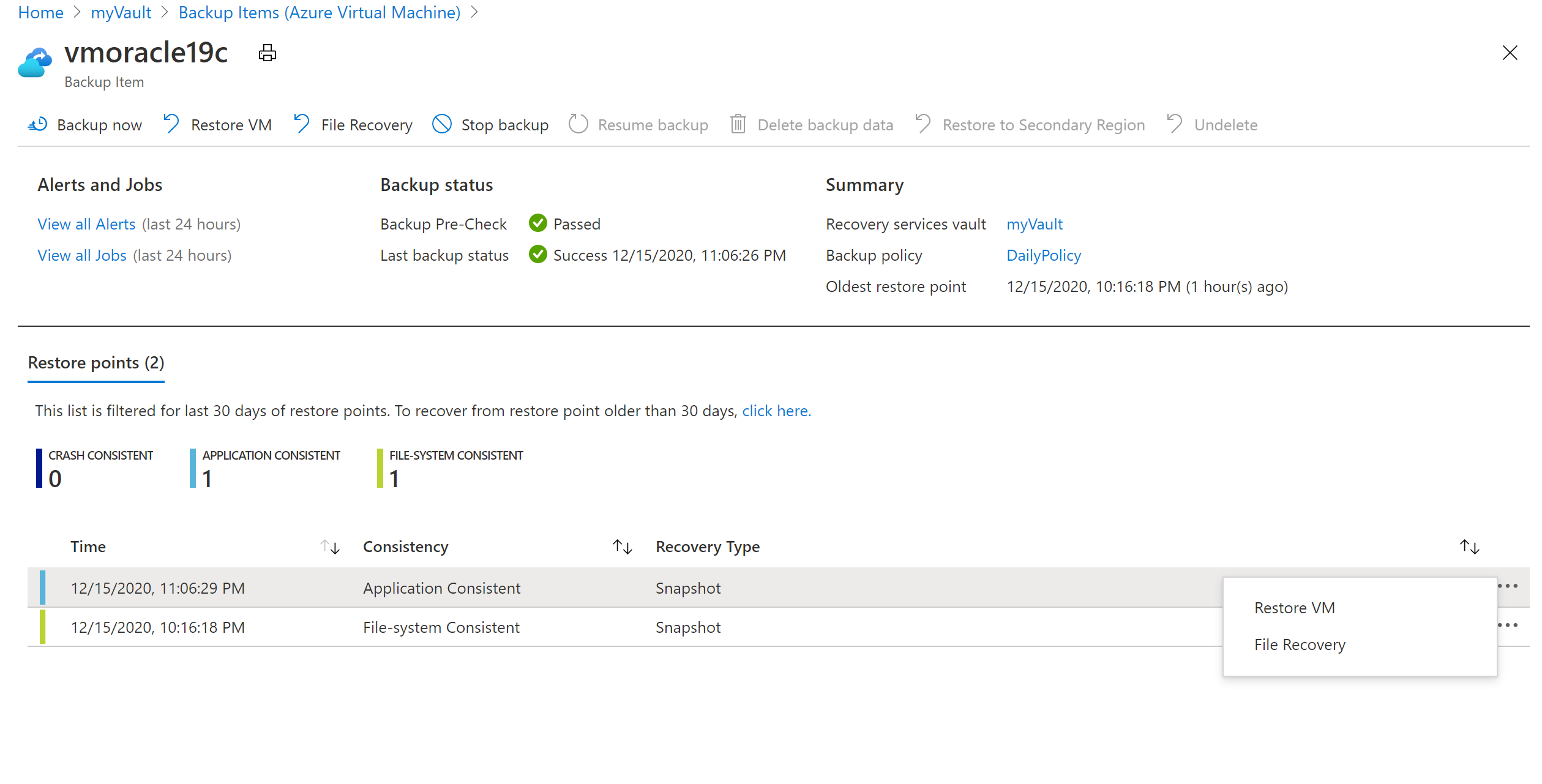
No painel Restaurar Máquina Virtual:
Selecione Criar.
Para Tipo de restauração, selecione Criar nova máquina virtual.
Para Nome da máquina virtual, digite vmoracle19c.
Para Rede virtual, selecione vmoracle19cVNET.
A sub-rede é preenchida automaticamente com base na sua seleção para a rede virtual.
Para Local de preparação, o processo de restauração de uma VM requer uma conta de armazenamento do Azure no mesmo grupo de recursos e região. Você pode escolher uma conta de armazenamento ou uma tarefa de restauração configurada anteriormente.
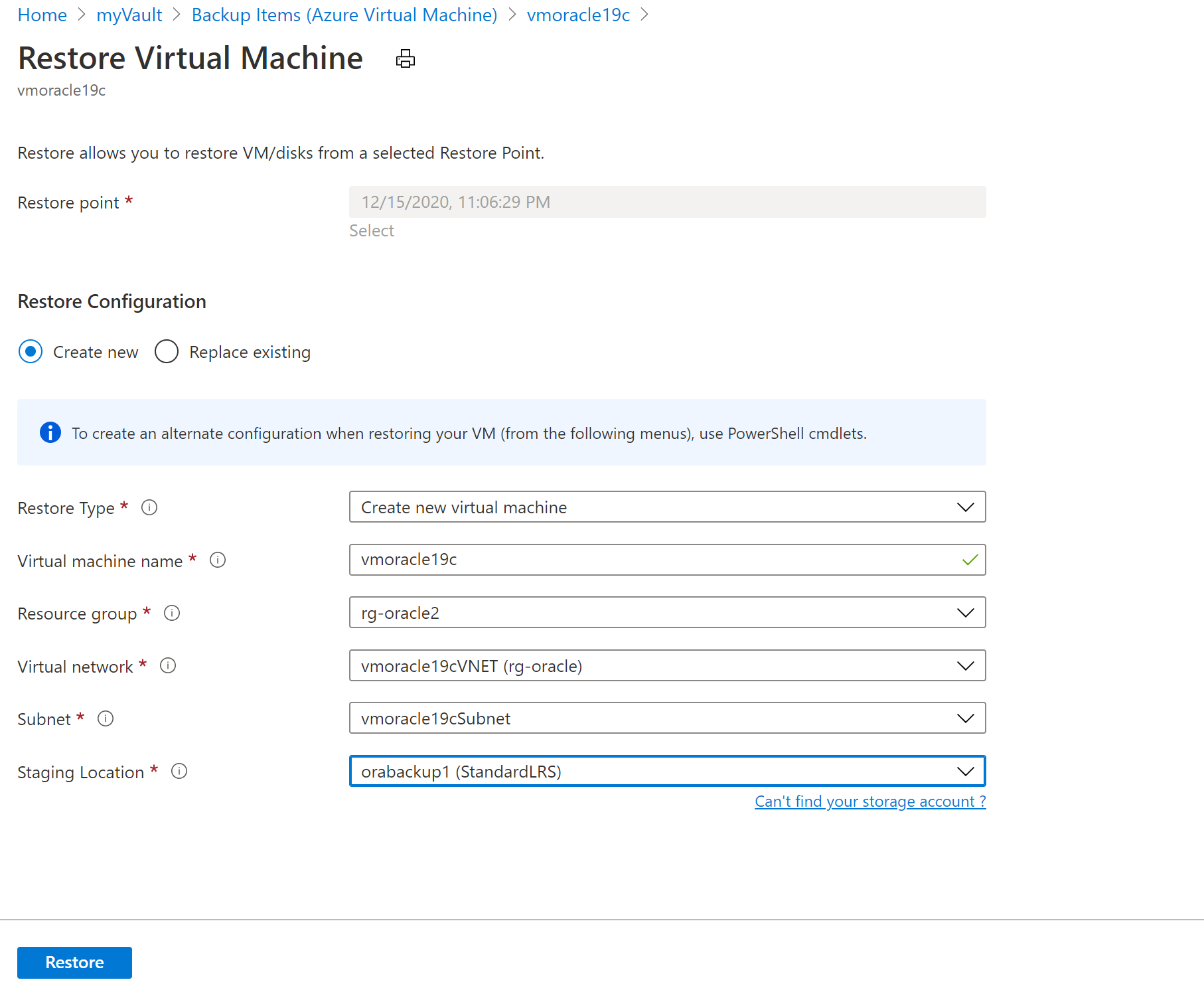
Para restaurar a VM, selecione o botão Restaurar.
Para visualizar o status do processo de restauração, selecione Trabalhos e, em seguida, selecione Trabalhos de backup.
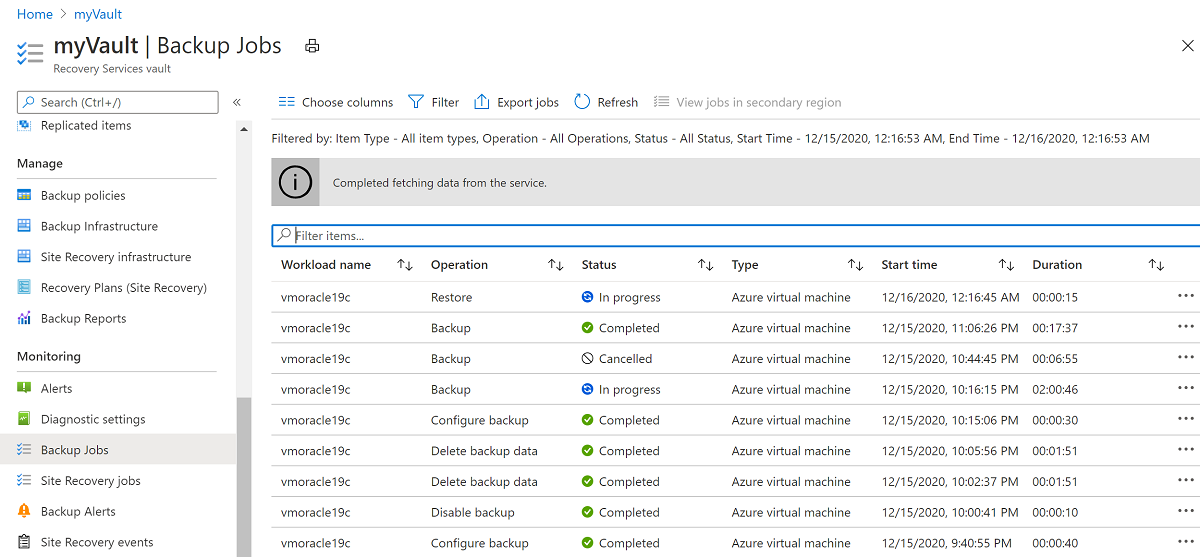
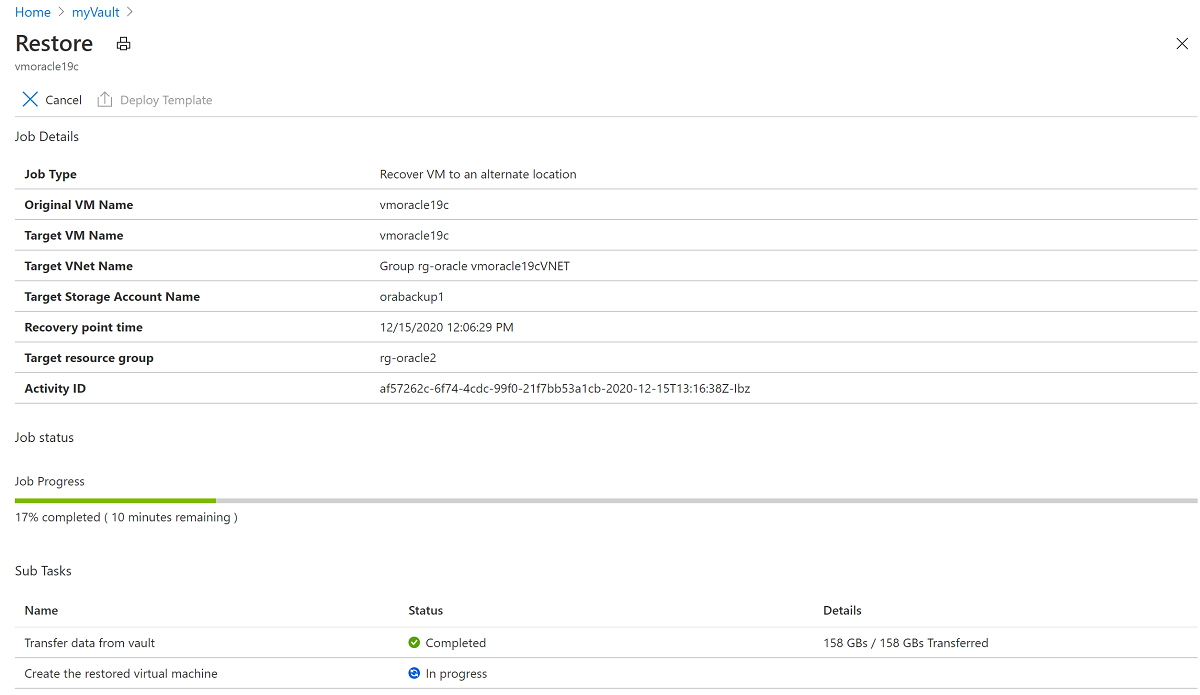
Selecione a operação de restauração Em andamento para mostrar detalhes sobre o status do processo de restauração.
Definir o endereço IP público
Depois que a VM for restaurada, você precisa reatribuir o endereço IP original para a nova VM.
No portal do Azure, acesse sua máquina virtual chamada vmoracle19c. É atribuído a ele um novo IP público e NIC semelhante a vmoracle19c-nic-XXXXXXXXXXXX, mas não tem um endereço DNS. Quando a VM original foi excluída, seu IP público e NIC foram mantidos. Os próximos passos são reconectá-los à nova VM.
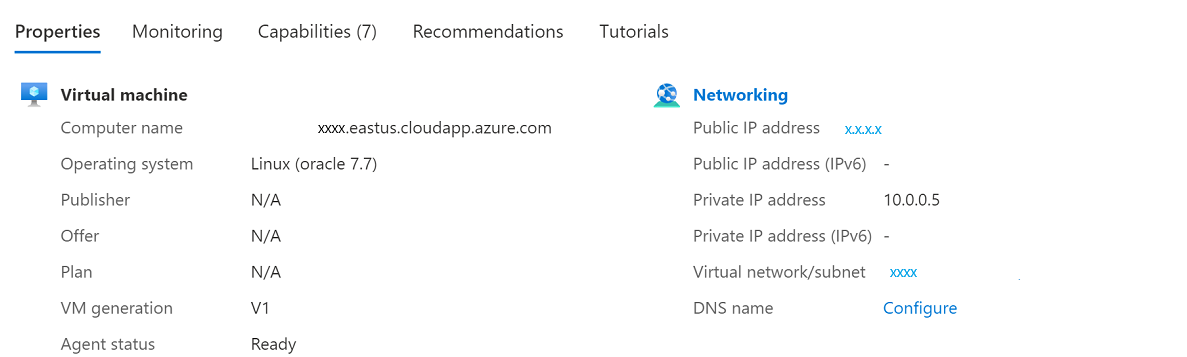
Pare a VM.
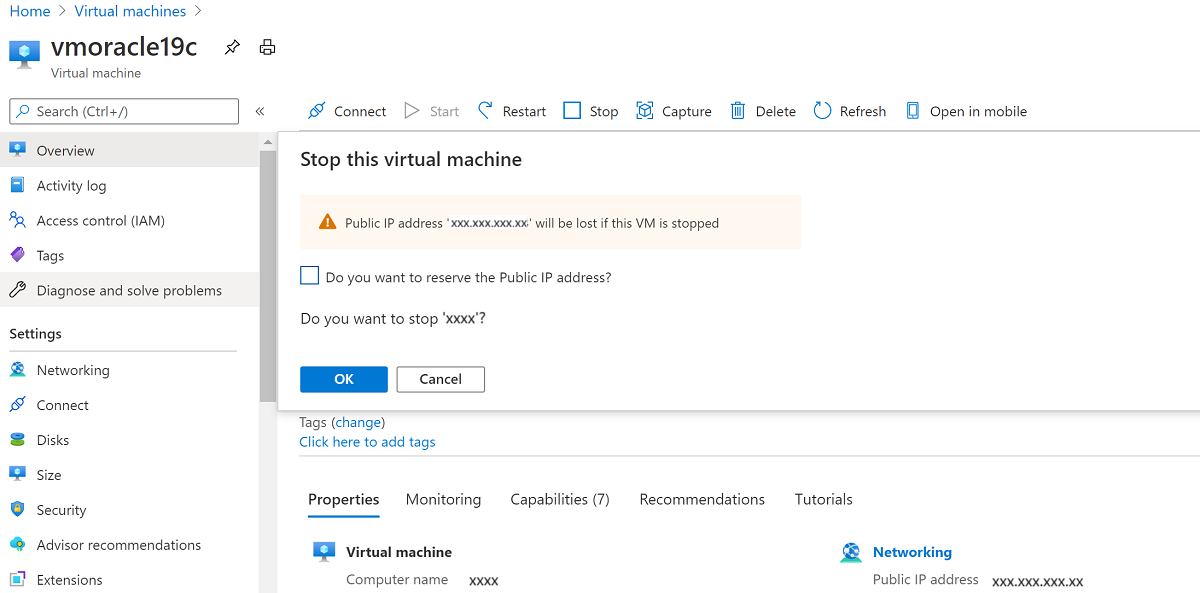
Vá para Rede.
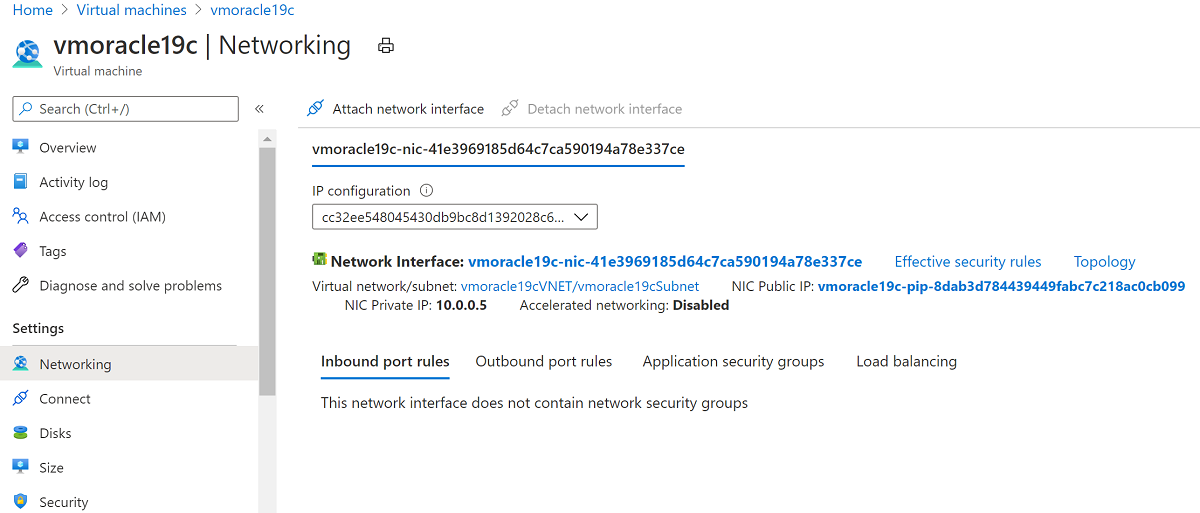
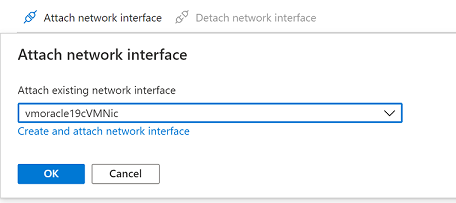
Selecione Anexar o adaptador de rede. Selecione a NIC original vmoracle19cVMNic, à qual o endereço IP público original ainda está associado. Em seguida, selecione OK.
Desanexe a NIC que você criou com a operação de restauração da VM, pois ela está configurada como a interface primária. Selecione Desanexar interface de rede, selecione a NIC semelhante a vmoracle19c-nic-XXXXXXXXXXXX e selecione OK.
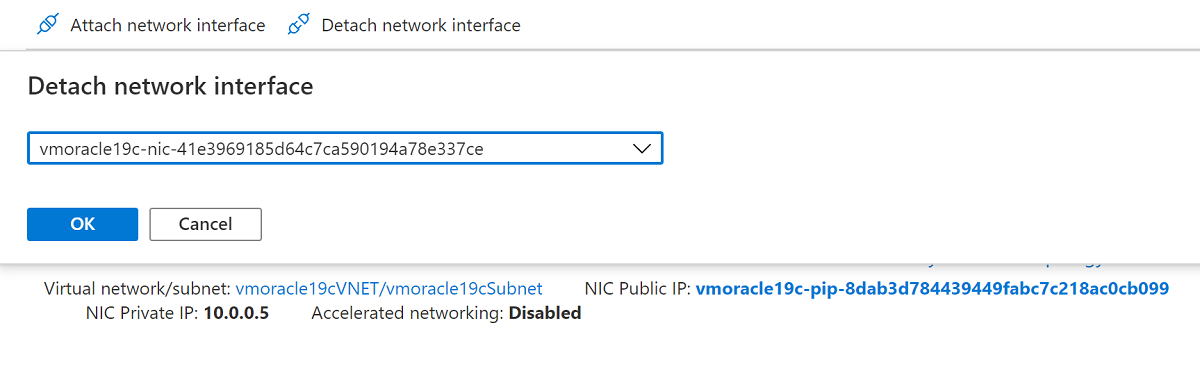
Sua VM recriada agora tem a NIC original, que está associada ao endereço IP original e às regras do grupo de segurança de rede.
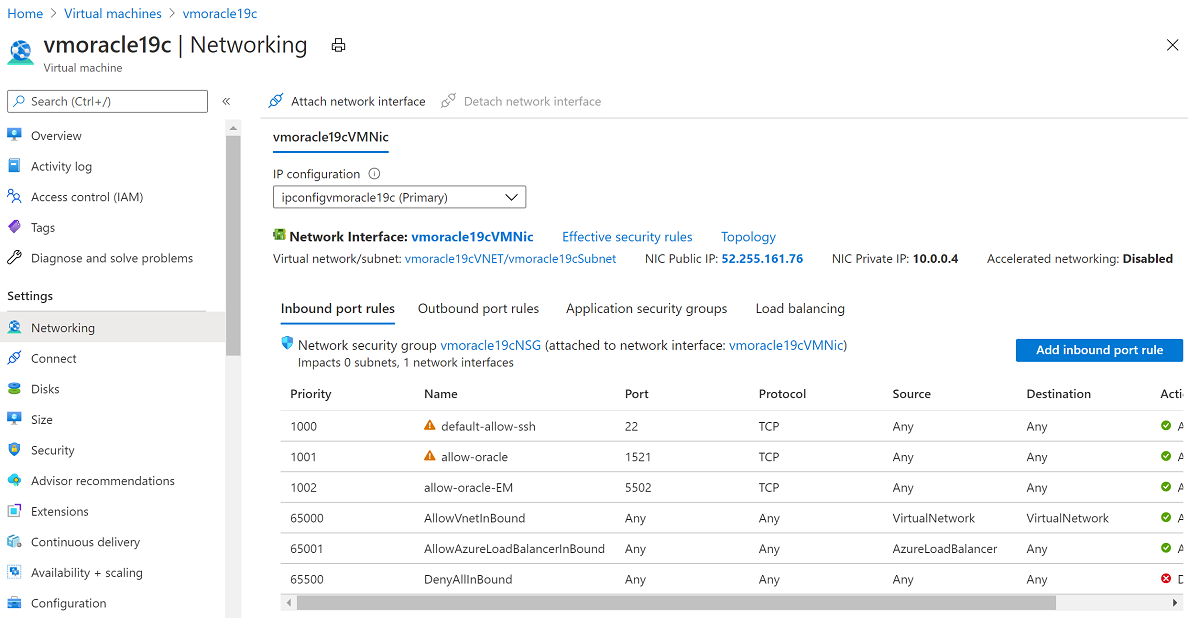
Volte para o painel Visão geral e selecione Iniciar.
Recuperar o banco de dados
Para recuperar um banco de dados após uma restauração completa da VM:
Reconecte-se à VM:
ssh azureuser@<publicIpAddress>Quando toda a VM for restaurada, é importante recuperar os bancos de dados na VM executando as seguintes etapas em cada banco de dados.
Você pode descobrir que a instância está em execução porque a inicialização automática tentou iniciar o banco de dados na inicialização da VM. Entretanto, o banco de dados requer recuperação e provavelmente está somente no estágio de montagem. Execute um desligamento preparatório antes de iniciar o estágio de montagem:
sudo su - oracle sqlplus / as sysdba SQL> shutdown immediate SQL> startup mountExecutar recuperação de banco de dados.
É importante especificar a
USING BACKUP CONTROLFILEsintaxe para informar ao comandoRECOVER AUTOMATIC DATABASEque a recuperação não deve parar no número de alteração do sistema Oracle (SCN) registrado no arquivo de controle do banco de dados restaurado.O arquivo de controle do banco de dados restaurado era um instantâneo, junto com o restante do banco de dados. O SCN armazenado nele é do ponto no tempo do instantâneo. Pode haver transações registradas após esse ponto, e você deseja recuperar até o ponto da última transação confirmada no banco de dados.
SQL> recover automatic database using backup controlfile until cancel;Quando o último arquivo de log de arquivamento disponível for aplicado, digite
CANCELpara finalizar a recuperação.Quando a recuperação for concluída com sucesso, a mensagem
Media recovery completeaparecerá.Entretanto, quando você usa a cláusula
BACKUP CONTROLFILE, o comando recover ignora os arquivos de log online. É possível que sejam necessárias alterações no log de refazer online atual para concluir a recuperação em um determinado momento. Nessa situação, você poderá ver mensagens semelhantes a estes exemplos:SQL> recover automatic database until cancel using backup controlfile; ORA-00279: change 2172930 generated at 04/08/2021 12:27:06 needed for thread 1 ORA-00289: suggestion : /u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc ORA-00280: change 2172930 for thread 1 is in sequence #13 ORA-00278: log file '/u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc' no longer needed for this recovery ORA-00308: cannot open archived log '/u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc' ORA-27037: unable to obtain file status Linux-x86_64 Error: 2: No such file or directory Additional information: 7 Specify log: {<RET>=suggested | filename | AUTO | CANCEL}Importante
Se o log de refazer online atual for perdido ou corrompido e você não puder usá-lo, você pode cancelar a recuperação neste momento.
Para corrigir essa situação, você pode identificar qual log online não foi arquivado e fornecer o nome do arquivo totalmente qualificado ao prompt.
Abra o banco de dados.
A opção
RESETLOGSé necessária quando o comandoRECOVERusa a opçãoUSING BACKUP CONTROLFILE.RESETLOGScria uma nova encarnação do banco de dados redefinindo o histórico de volta ao início, porque não há como determinar quanto da encarnação anterior do banco de dados foi ignorada na recuperação.SQL> alter database open resetlogs;Verifique se o conteúdo do banco de dados foi recuperado:
SQL> select * from scott.scott_table;
O backup e a recuperação do Oracle Database em uma VM Linux do Azure foram concluídos.
Você pode encontrar mais informações sobre comandos e conceitos do Oracle na documentação do Oracle, incluindo:
- Executar backups gerenciados pelo usuário Oracle de todo o banco de dados
- Executar a recuperação completa de banco de dados gerenciado pelo usuário
- Comando do Oracle STARTUP
- Comando do Oracle RECOVER
- Comando do Oracle ALTER DATABASE
- Parâmetro do Oracle LOG_ARCHIVE_DEST_n
- Parâmetro do Oracle ARCHIVE_LAG_TARGET
Excluir a VM
Quando a VM não for mais necessária, use o comando a seguir para remover o grupo de recursos, a VM e todos os recursos relacionados:
Desabilite a exclusão reversível de backups no cofre:
az backup vault backup-properties set --name myVault --resource-group rg-oracle --soft-delete-feature-state disablePare a proteção da VM e exclua os backups:
az backup protection disable --resource-group rg-oracle --vault-name myVault --container-name vmoracle19c --item-name vmoracle19c --delete-backup-data true --yesRemova o grupo de recursos, incluindo todos os recursos:
az group delete --name rg-oracle