Usar um AG distribuído para migrar bancos de dados de uma instância autônoma
Use um AG (grupo de disponibilidade) distribuídopara migrar um banco de dados (ou vários) de uma instância autônoma do SQL Server para o SQL Server em VMs (máquinas virtuais) do Azure.
Depois de validar que sua instância de origem do SQL Server atende aos pré-requisitos, siga as etapas deste artigo para criar um grupo de disponibilidade em sua instância autônoma do SQL Server e migrar seu banco de dados (ou grupo de bancos de dados) para sua VM do SQL Server no Azure.
Este artigo destina-se a bancos de dados em uma instância autônoma do SQL Server. Esta solução não requer um WSFC (cluster de failover do Windows Server) ou um ouvinte do grupo de disponibilidade. Também é possível migrar bancos de dados em um grupo de disponibilidade.
Instalação inicial
A primeira etapa é criar sua VM do SQL Server no Azure. É possível fazer isso usando o portal do Azure, o Azure PowerShell ou um modelo do ARM.
Certifique-se de configurar sua VM do SQL Server de acordo com os pré-requisitos.
Para simplificar, junte sua VM de destino do SQL Server ao mesmo domínio de seu SQL Server de origem. Caso contrário, conecte sua VM de destino do SQL Server a um domínio que seja federado ao domínio do SQL Server de origem.
Para usar a propagação automática a fim de criar seu DAG (grupo de disponibilidade distribuído), é preciso que o nome da instância do primário global (origem) do DAG corresponda ao nome da instância do encaminhador (destino) do DAG. Quando há uma incompatibilidade de nome de instância entre o primário global e o encaminhador, você deve usar a propagação manual para criar o DAG e adicionar manualmente quaisquer arquivos de banco de dados adicionais no futuro.
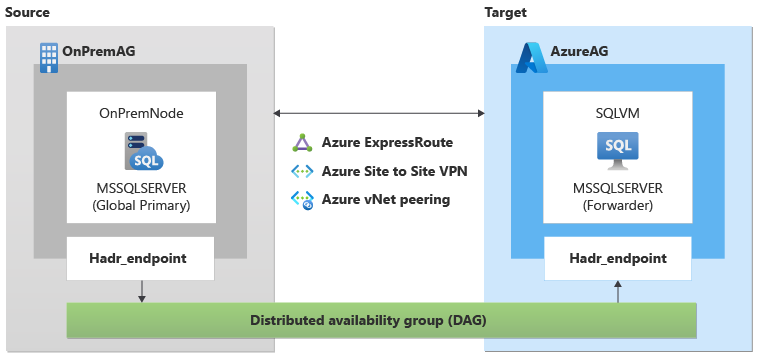
Este artigo usa os seguintes parâmetros de exemplo:
- Nome do banco de dados:
Adventureworks2022 - Nomes da máquina de origem (primário global no DAG):
OnPremNode - Nome da instância do SQL Server de origem:
MSSQLSERVER - Nome do grupo de disponibilidade de origem:
OnPremAg - Nome da VM de destino do SQL Server (encaminhador no DAG):
SQLVM - Nome do SQL Server de destino na instância da VM do Azure:
MSSQLSERVER - Nome do grupo de disponibilidade de destino:
AzureAG - Nome do ponto de extremidade:
Hadr_endpoint - Nome do grupo de disponibilidade distribuído:
DAG - Nome de domínio:
Contoso
Criar pontos de extremidade
Use T-SQL (Transact-SQL) para criar pontos de extremidade em instâncias de origem (OnPremNode) e de destino (SQLVM) do SQL Server.
Para criar os pontos de extremidade, execute este script T-SQL nos servidores de origem e de destino:
CREATE ENDPOINT [Hadr_endpoint] STATE = STARTED
AS TCP (
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATA_MIRRORING(ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES);
GO
As contas de domínio têm acesso automaticamente aos pontos de extremidade, mas as contas de serviço podem não fazer parte automaticamente do grupo sysadmin e podem não ter permissão para a conexão. Para conceder manualmente à conta de serviço do SQL Server permissão de conexão com o ponto de extremidade, execute o seguinte script T-SQL em ambos os servidores:
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [<your account>];
Criar o AG de origem
Como um grupo de disponibilidade distribuído é especial e abrange dois grupos de disponibilidade individuais, é necessário criar primeiro um grupo de disponibilidade na instância de origem do SQL Server. Se você já tiver um grupo de disponibilidade que gostaria de manter no Azure, migre seu grupo de disponibilidade.
Use T-SQL (Transact-SQL) para criar um grupo de disponibilidade (OnPremAg) na instância de origem (OnPremNode) para o banco de dados de exemplo Adventureworks2022.
Para criar o grupo de disponibilidade, execute este script na origem:
CREATE AVAILABILITY GROUP [OnPremAG]
WITH (
AUTOMATED_BACKUP_PREFERENCE = PRIMARY,
DB_FAILOVER = OFF,
DTC_SUPPORT = NONE,
CLUSTER_TYPE = NONE
)
FOR DATABASE [Adventureworks2022] REPLICA ON N'OnPremNode'
WITH (
ENDPOINT_URL = N'TCP://OnPremNode.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)
);
GO
Criar o AG de destino
Você também precisa criar um grupo de disponibilidade nas VMs de destino do SQL Server.
Use T-SQL (Transact-SQL) para criar um grupo de disponibilidade (AzureAG) na instância de destino (SQLVM).
Para criar o grupo de disponibilidade, execute este script no destino:
CREATE AVAILABILITY GROUP [AzureAG]
WITH (
AUTOMATED_BACKUP_PREFERENCE = PRIMARY,
DB_FAILOVER = OFF,
DTC_SUPPORT = NONE,
CLUSTER_TYPE = NONE,
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0
)
FOR REPLICA ON N'SQLVM'
WITH (
ENDPOINT_URL = N'TCP://SQLVM.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)
);
GO
Criar AG distribuído
Depois de configurar seus grupos de disponibilidade de origem (OnPremAG) e de destino (AzureAG), crie seu grupo de disponibilidade distribuído para abranger ambos os grupos individuais.
Use Transact-SQL na instância de origem do SQL Server (OnPremNode) e no AG (OnPremAG) para criar o grupo de disponibilidade distribuído (DAG).
Para criar o AG distribuído, execute este script na origem:
CREATE AVAILABILITY GROUP [DAG]
WITH (DISTRIBUTED) AVAILABILITY GROUP
ON 'OnPremAG' WITH (
LISTENER_URL = 'tcp://OnPremNode.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'AzureAG' WITH (
LISTENER_URL = 'tcp://SQLVM.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
O modo de propagação é definido como AUTOMATIC, pois as versões do SQL Server no destino e na origem são iguais. Se a versão do SQL Server de destino for superior ou o primário global e o encaminhador tiverem nomes de instâncias diferentes, crie o AG distribuído e conecte o AG secundário ao AG distribuído com SEEDING_MODE definido como MANUAL. Em seguida, restaure manualmente os bancos de dados da origem para a instância de destino do SQL Server. Para obter mais informações, confira Atualizar versões durante a migração.
Depois que o AG distribuído for criado, conecte o AG de destino (AzureAG) na instância de destino (SQLVM) ao AG distribuído (DAG).
Para conectar o AG de destino ao AG distribuído, execute este script no destino:
ALTER AVAILABILITY GROUP [DAG]
JOIN AVAILABILITY GROUP
ON 'OnPremAG' WITH (
LISTENER_URL = 'tcp://OnPremNode.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'AzureAG' WITH (
LISTENER_URL = 'tcp://SQLVM.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Para cancelar, pausar ou atrasar a sincronização entre os grupos de disponibilidade de origem e de destino (como, por exemplo, no caso de problemas de desempenho), execute este script na instância do primário global de origem (OnPremNode):
ALTER AVAILABILITY GROUP [DAG]
MODIFY AVAILABILITY GROUP
ON 'AzureAG' WITH (SEEDING_MODE = MANUAL);
Para obter mais informações, confira Cancelar a propagação automática para o encaminhador.