System.IO.Pipelines no .NET
System.IO.Pipelines é uma biblioteca projetada para facilitar a execução de E/S de alto desempenho no .NET. É uma biblioteca direcionada ao .NET Standard que funciona em todas as implementações do .NET.
A biblioteca está disponível no pacote Nuget System.IO.Pipelines.
Qual problema resolvido pelo System.IO.Pipelines
Os aplicativos que analisam dados de streaming são compostos de código clichê com muitos fluxos de código especializados e incomuns. A clichê e o código de maiúsculas e minúsculas especiais são complexos e difíceis de manter.
System.IO.Pipelines foi arquitetado para:
- Ter dados de streaming de análise de alto desempenho.
- Reduzir a complexidade do código.
O código a seguir é típico para um servidor TCP que recebe mensagens delimitadas por linha (delimitadas por '\n') de um cliente:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
O código anterior tem vários problemas:
- A mensagem inteira (fim de linha) pode não ser recebida em uma única chamada para
ReadAsync. - Está ignorando o resultado de
stream.ReadAsync.stream.ReadAsyncretorna quantos dados foram lidos. - Ele não lida com o caso em que várias linhas são lidas em uma única chamada
ReadAsync. - Ele aloca uma matriz
bytecom cada leitura.
Para corrigir os problemas anteriores, as seguintes alterações são necessárias:
Buffer dos dados de entrada até que uma nova linha seja encontrada.
Analise todas as linhas retornadas no buffer.
É possível que a linha seja maior que 1 KB (1024 bytes). O código precisa redimensionar o buffer de entrada até que o delimitador seja encontrado para ajustar a linha completa dentro do buffer.
- Se o buffer for redimensionado, mais cópias de buffer serão feitas à medida que linhas mais longas aparecerem na entrada.
- Para reduzir o espaço desperdiçado, compacte o buffer usado para ler linhas.
Considere usar o pool de buffers para evitar alocar memória repetidamente.
O código a seguir resolve alguns desses problemas:
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
O código anterior é complexo e não resolve todos os problemas identificados. A rede de alto desempenho geralmente significa escrever código complexo para maximizar o desempenho. System.IO.Pipelines foi projetado para facilitar a gravação desse tipo de código.
Pipe
A classe Pipe pode ser usada para criar um par PipeWriter/PipeReader. Todos os dados gravados no PipeWriter estão disponíveis no PipeReader:
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
Uso básico do pipe
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
Há dois loops:
FillPipeAsynclê deSockete grava paraPipeWriter.ReadPipeAsynclê dePipeReadere analisa as linhas de chegada.
Não há buffers explícitos alocados. Todo o gerenciamento de buffers é delegado às implementações PipeReader e PipeWriter. Delegar o gerenciamento de buffer facilita o consumo de código para se concentrar apenas na lógica de negócios.
No primeiro loop:
- PipeWriter.GetMemory(Int32) é chamado para obter memória do gravador subjacente.
- PipeWriter.Advance(Int32) é chamado para informar quantos dados
PipeWriterforam gravados no buffer. - PipeWriter.FlushAsync é chamado para disponibilizar os dados para o
PipeReader.
No segundo loop, PipeReader consome os buffers gravados por PipeWriter. Os buffers vêm do soquete. A chamada para PipeReader.ReadAsync:
Retorna ReadResult que contém duas informações importantes:
- Os dados que foram lidos na forma de
ReadOnlySequence<byte>. - Um booleano
IsCompletedque indica se o fim dos dados (EOF) foi atingido.
- Os dados que foram lidos na forma de
Depois de encontrar o delimitador de fim de linha (EOL) e analisar a linha:
- A lógica processa o buffer para ignorar o que já está processado.
PipeReader.AdvanceToé chamado para informar aPipeReaderquantos dados foram consumidos e examinados.
Os loops de leitor e gravador terminam chamando Complete. Complete permite que o Pipe subjacente libere a memória alocada.
Backpressure e controle de fluxo
O ideal é que a leitura e a análise trabalhem juntas:
- O thread de leitura consome dados da rede e os coloca em buffers.
- O thread de análise é responsável por construir as estruturas de dados apropriadas.
Normalmente, a análise leva mais tempo do que apenas copiar blocos de dados da rede:
- O thread de leitura fica à frente do thread de análise.
- O thread de leitura precisa diminuir ou alocar mais memória para armazenar os dados para o thread de análise.
Para um desempenho ideal, há um equilíbrio entre pausas frequentes e alocação de mais memória.
Para resolver o problema anterior, Pipe tem duas configurações para controlar o fluxo de dados:
- PauseWriterThreshold: determina quantos dados devem ser armazenados em buffer antes das chamadas para FlushAsync pausar.
- ResumeWriterThreshold: determina a quantidade de dados que o leitor deve observar antes que as chamadas para
PipeWriter.FlushAsyncsejam retomadas.
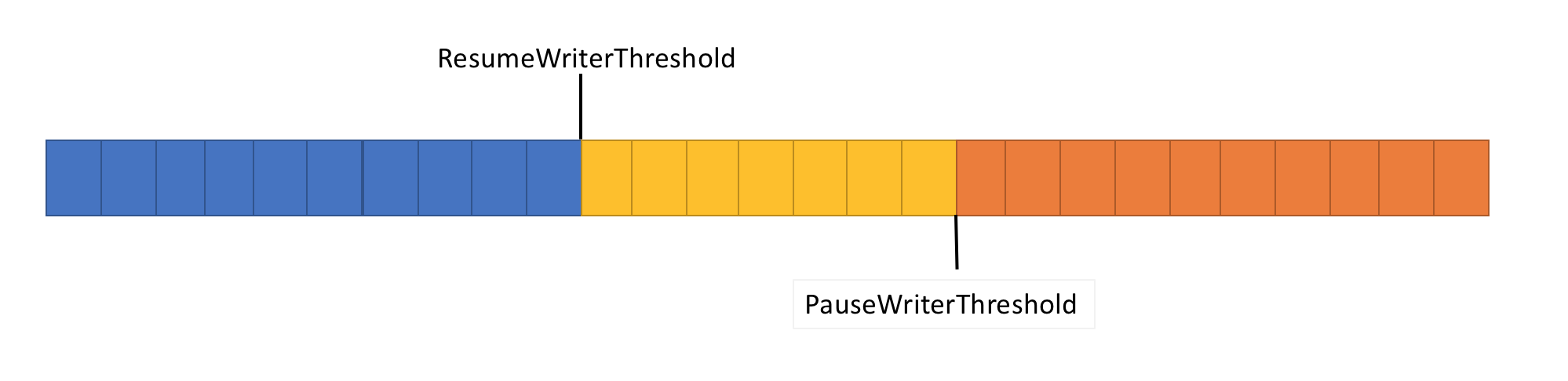
- Retorna um
ValueTask<FlushResult>incompleto quando a quantidade de dados emPipecruzaPauseWriterThreshold. ValueTask<FlushResult>é concluído quando ele se torna menor queResumeWriterThreshold.
Dois valores são usados para evitar o ciclismo rápido, que pode ocorrer se um valor for usado.
Exemplos
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
PipeScheduler
Normalmente, ao usar async e await, o código assíncrono é retomado em TaskScheduler ou no código atual SynchronizationContext.
Ao fazer E/S, é importante ter controle refinado sobre onde ela é executada. Esse controle permite aproveitar os caches de CPU com eficiência. O cache eficiente é essencial para aplicativos de alto desempenho, como servidores Web. PipeScheduler fornece controle sobre onde os retornos de chamada assíncronos são executados. Por padrão:
- A corrente SynchronizationContext é usada.
- Se não houver
SynchronizationContext, ele usará o pool de encadeamentos para executar retornos de chamada.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool é a implementação PipeScheduler que enfileira retornos de chamada para o pool de encadeamentos. PipeScheduler.ThreadPool é o padrão e geralmente a melhor opção. PipeScheduler.Inline pode causar consequências não intencionais, como deadlocks.
Redefinição de pipe
É frequentemente eficiente reutilizar o objeto Pipe. Para redefinir o pipe, chame PipeReaderReset quando PipeReader e PipeWriter estiverem concluídos.
PipeReader
PipeReader gerencia a memória em nome do chamador. Sempre chame PipeReader.AdvanceTo após chamar PipeReader.ReadAsync. Isso informa PipeReader quando o chamador é feito com a memória para que ele possa ser rastreado. O ReadOnlySequence<byte> retornado de PipeReader.ReadAsync só é válido até a chamada de PipeReader.AdvanceTo. É ilegal usar ReadOnlySequence<byte> após chamar PipeReader.AdvanceTo.
PipeReader.AdvanceTo usa dois argumentos SequencePosition:
- O primeiro argumento determina a quantidade de memória consumida.
- O segundo argumento determina quanto do buffer foi observado.
Marcar dados como consumidos significa que o pipe pode retornar a memória para o pool de buffers subjacente. Marcar dados como observado controla o que fará a próxima chamada para PipeReader.ReadAsync. Marcar tudo como observado significa que a próxima chamada para PipeReader.ReadAsync não retornará até que haja mais dados gravados no pipe. Qualquer outro valor fará a próxima chamada para PipeReader.ReadAsync retornar imediatamente com os dados observados e não observados, mas não os dados que já foram consumidos.
Ler cenários de dados de streaming
Há alguns padrões típicos que surgem ao tentar ler dados de streaming:
- Dado um fluxo de dados, analise uma única mensagem.
- Dado um fluxo de dados, analise uma única mensagem.
Os exemplos a seguir usam o método TryParseLines para analisar mensagens de um ReadOnlySequence<byte>. TryParseLines analisa uma única mensagem e atualiza o buffer de entrada para cortar a mensagem analisada do buffer. TryParseLines não faz parte do .NET, é um método escrito pelo usuário usado nas seções a seguir.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
Lê uma única mensagem
O código a seguir lê uma única mensagem de PipeReader e a retorna ao chamador.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
O código anterior:
- Analisa uma única mensagem.
- Atualizações o
SequencePositionconsumido eSequencePositionexaminado para apontar para o início do buffer de entrada cortado.
Os dois argumentos SequencePosition são atualizados porque TryParseLines remove a mensagem analisada do buffer de entrada. Em geral, ao analisar uma única mensagem do buffer, a posição examinada deve ser uma das seguintes:
- O final da mensagem.
- O final do buffer recebido se nenhuma mensagem foi encontrada.
O caso de mensagem única tem o maior potencial de erros. Passar os valores errados para examinados pode resultar em uma exceção de memória insuficiente ou um loop infinito. Para obter mais informações, consulte a seção Problemas comuns do PipeReader neste artigo.
Lendo várias mensagens
O código a seguir lê todas as mensagens de um PipeReader e chama ProcessMessageAsync em cada um.
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Cancelamento
PipeReader.ReadAsync:
- Dá suporte à passagem de CancellationToken.
- Gerará OperationCanceledException se
CancellationTokenestiver cancelado enquanto houver uma leitura pendente. - Dá suporte a uma maneira de cancelar a operação de leitura atual por meio de PipeReader.CancelPendingRead, o que evita a criação de uma exceção. A chamada
PipeReader.CancelPendingReadfaz com que a chamada atual ou próxima paraPipeReader.ReadAsyncretorne ReadResult comIsCanceleddefinido comotrue. Isso pode ser útil para interromper o loop de leitura existente de forma não destrutiva e não excepcional.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Problemas comuns do PipeReader
Passar os valores errados para
consumedouexaminedpode resultar na leitura de dados já lidos.Passar
buffer.Endconforme examinado pode resultar em:- Dados paralisados
- Possivelmente uma eventual exceção de OOM (Memória Insuficiente) se os dados não forem consumidos. Por exemplo,
PipeReader.AdvanceTo(position, buffer.End)ao processar uma única mensagem por vez do buffer.
Passar os valores errados para
consumedouexaminedpode resultar em um loop infinito. Por exemplo,PipeReader.AdvanceTo(buffer.Start)sebuffer.Startnão tiver sido alterado fará com que a próxima chamadaPipeReader.ReadAsyncretorne imediatamente antes da chegada de novos dados.Passar os valores errados para
consumedouexaminedpode resultar em um buffering infinito (eventual OOM).Usar o
ReadOnlySequence<byte>após chamarPipeReader.AdvanceTopode resultar em memória corrompida (use depois de liberar).A falha na chamada
PipeReader.Complete/CompleteAsyncpode resultar em um vazamento de memória.Verificar ReadResult.IsCompleted e sair da lógica de leitura antes de processar o buffer resulta em perda de dados. A condição de saída do loop deve ser baseada em
ReadResult.Buffer.IsEmptyeReadResult.IsCompleted. Fazer isso incorretamente pode resultar em um loop infinito.
Código problemático
❌Perda de dados
O ReadResult pode retornar o segmento final de dados quando IsCompleted é definido como true. Não ler esses dados antes de sair do loop de leitura resultará em perda de dados.
Aviso
NÃO use o código a seguir. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo a seguir é fornecido para explicar Problemas comuns do PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
Aviso
NÃO use o código anterior. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo anterior é fornecido para explicar Problemas comuns do PipeReader.
❌Loop infinito
A lógica a seguir pode resultar em um loop infinito se o Result.IsCompleted é true, mas nunca há uma mensagem completa no buffer.
Aviso
NÃO use o código a seguir. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo a seguir é fornecido para explicar Problemas comuns do PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Aviso
NÃO use o código anterior. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo anterior é fornecido para explicar Problemas comuns do PipeReader.
Aqui está outro código com o mesmo problema. Ele está verificando se há um buffer não vazio antes de verificar ReadResult.IsCompleted. Como ele está em um else if, ele ficará em loop para sempre se nunca houver uma mensagem completa no buffer.
Aviso
NÃO use o código a seguir. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo a seguir é fornecido para explicar Problemas comuns do PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Aviso
NÃO use o código anterior. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo anterior é fornecido para explicar Problemas comuns do PipeReader.
❌Aplicativo sem resposta
Chamar incondicionalmente PipeReader.AdvanceTo com buffer.End na posição examined pode fazer com que o aplicativo não responda ao analisar uma única mensagem. A próxima chamada para PipeReader.AdvanceTo não retornará até:
- Há mais dados gravados no pipe.
- E os novos dados não foram examinados anteriormente.
Aviso
NÃO use o código a seguir. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo a seguir é fornecido para explicar Problemas comuns do PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
Aviso
NÃO use o código anterior. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo anterior é fornecido para explicar Problemas comuns do PipeReader.
❌Memória insuficiente (OOM)
Com as seguintes condições, o código a seguir mantém o buffer até que um OutOfMemoryException ocorra:
- Não há tamanho máximo de mensagem.
- Os dados retornados de
PipeReadernão fazem uma mensagem completa. Por exemplo, ele não faz uma mensagem completa porque o outro lado está escrevendo uma mensagem grande (por exemplo, uma mensagem de 4 GB).
Aviso
NÃO use o código a seguir. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo a seguir é fornecido para explicar Problemas comuns do PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
Aviso
NÃO use o código anterior. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo anterior é fornecido para explicar Problemas comuns do PipeReader.
❌Memória corrompida
Ao escrever auxiliares que lêem o buffer, qualquer carga retornada deve ser copiada antes de chamar Advance. O exemplo a seguir retornará a memória que Pipe descartou e poderá reutilizá-la para a próxima operação (leitura/gravação).
Aviso
NÃO use o código a seguir. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo a seguir é fornecido para explicar Problemas comuns do PipeReader.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
Aviso
NÃO use o código anterior. O uso desse exemplo resultará em perda de dados, travamentos, problemas de segurança e NÃO deve ser copiado. O exemplo anterior é fornecido para explicar Problemas comuns do PipeReader.
PipeWriter
O PipeWriter gerencia buffers para gravação em nome do chamador. PipeWriter implementa IBufferWriter<byte>. IBufferWriter<byte> possibilita obter acesso a buffers para executar gravações sem cópias de buffer extras.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
O código anterior:
- Solicita um buffer de pelo menos 5 bytes do
PipeWriterusando GetMemory. - Grava bytes para a cadeia de caracteres ASCII
"Hello"noMemory<byte>retornado. - Chamadas Advance para indicar quantos bytes foram gravados no buffer.
- Libera o
PipeWriter, que envia os bytes para o dispositivo subjacente.
O método anterior de gravação usa os buffers fornecidos pelo PipeWriter. Ele também poderia ter usado PipeWriter.WriteAsync, o que:
- Copia o buffer existente para
PipeWriter. - Chamadas
GetSpan,Advanceconforme apropriado e chamadas FlushAsync.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
Cancelamento
FlushAsync dá suporte à passagem de CancellationToken. Passar CancellationToken resulta em OperationCanceledException se o token for cancelado enquanto houver um flush pendente. PipeWriter.FlushAsync oferece suporte a uma maneira de cancelar a operação de liberação atual por meio de PipeWriter.CancelPendingFlush sem gerar uma exceção. A chamada PipeWriter.CancelPendingFlush faz com que a chamada atual ou próxima para PipeWriter.FlushAsync ou PipeWriter.WriteAsync retorne FlushResult com IsCanceled definido como true. Isso pode ser útil para interromper a liberação de rendimento de maneira não destrutiva e não excepcional.
Problemas comuns do PipeWriter
- GetSpan e GetMemory retornam um buffer com pelo menos a quantidade de memória solicitada. Não suponha tamanhos exatos do buffer.
- Não há garantia de que chamadas sucessivas retornarão o mesmo buffer ou o mesmo tamanho de buffer.
- Um novo buffer deve ser solicitado após a chamada Advance para continuar gravando mais dados. O buffer adquirido anteriormente não pode ser gravado.
- Chamar
GetMemoryouGetSpanenquanto houver uma chamada paraFlushAsyncincompleta não é seguro. - Chamar
CompleteouCompleteAsync, embora haja dados não corrompidos, pode resultar em memória corrompida.
Dicas para usar PipeReader e PipeWriter
As dicas a seguir ajudarão você a usar as classes System.IO.Pipelines com êxito:
- Preencha sempre o PipeReader e o PipeWriter, incluindo uma exceção, quando aplicável.
- Sempre chame PipeReader.AdvanceTo após chamar PipeReader.ReadAsync.
- Periodicamente
awaitPipeWriter.FlushAsync enquanto grava e sempre verifique FlushResult.IsCompleted. Abortar a gravação seIsCompletedfortrue, pois isso indica que o leitor está preenchido e não se importa mais com o que está gravado. - Chame PipeWriter.FlushAsync depois de escrever algo que você deseja que o
PipeReadertenha acesso. - Não chame
FlushAsyncse o leitor não puder iniciar até queFlushAsynctermine, pois isso pode causar um impasse. - Verifique se apenas um contexto "possui"
PipeReaderouPipeWriterou acessa-os. Esses tipos não são thread-safe. - Nunca acesse um ReadResult.Buffer após a chamada
AdvanceToou a conclusão dePipeReader.
IDuplexPipe
IDuplexPipe é um contrato para tipos que dão suporte à leitura e à gravação. Por exemplo, uma conexão de rede seria representada por IDuplexPipe.
Ao contrário de Pipe, que contém PipeReader e PipeWriter, IDuplexPipe representa um único lado de uma conexão full duplex. Isso significa que o que está escrito em PipeWriter não será lido no PipeReader.
Fluxos
Ao ler ou gravar dados de fluxo, você normalmente lê dados usando um desserializador e grava dados usando um serializador. A maioria dessas APIs de fluxo de leitura e gravação tem um parâmetro Stream. Para facilitar a integração com essas APIs existentes, PipeReader e PipeWriter expõem um método AsStream. AsStream retorna uma implementação Stream em torno de PipeReader ou PipeWriter.
Exemplo de fluxo
As instâncias PipeReader e PipeWriter podem ser criadas usando os métodos estáticos Create com um objeto Stream e opções de criação correspondentes opcionais.
StreamPipeReaderOptions permite o controle sobre a criação da instância PipeReader com os seguintes parâmetros:
- StreamPipeReaderOptions.BufferSize é o tamanho mínimo do buffer em bytes usado ao alugar memória do pool e o padrão é
4096. - O sinalizador StreamPipeReaderOptions.LeaveOpen determina se o fluxo subjacente é deixado aberto após a conclusão de
PipeReadere o padrão éfalse. - StreamPipeReaderOptions.MinimumReadSize representa o limite de bytes restantes no buffer antes que um novo buffer seja alocado e o padrão é
1024. - StreamPipeReaderOptions.Pool é o
MemoryPool<byte>usado ao alocar memória e o padrão énull.
StreamPipeWriterOptions permite o controle sobre a criação da instância PipeWriter com os seguintes parâmetros:
- O sinalizador StreamPipeWriterOptions.LeaveOpen determina se o fluxo subjacente é deixado aberto após a conclusão de
PipeWritere o padrão éfalse. - StreamPipeWriterOptions.MinimumBufferSize representa o tamanho mínimo do buffer a ser usado ao alugar memória do Pool e o padrão é
4096. - StreamPipeWriterOptions.Pool é o
MemoryPool<byte>usado ao alocar memória e o padrão énull.
Importante
Ao criar instâncias PipeReader e PipeWriter usando os métodos Create, você precisa considerar a vida útil do objeto Stream. Se você precisar de acesso ao fluxo depois que o leitor ou gravador terminar, você precisará definir o sinalizador LeaveOpen como true nas opções de criação. Caso contrário, o fluxo será fechado.
O código a seguir demonstra a criação de instâncias PipeReader e PipeWriter usando os métodos Create de um fluxo.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
O aplicativo usa StreamReader para ler o arquivo lorem-ipsum.txt como um fluxo e deve terminar com uma linha em branco. O FileStream é passado para PipeReader.Create, o que instancia um objeto PipeReader. Em seguida, o aplicativo de console passa seu fluxo de saída padrão para PipeWriter.Create usando Console.OpenStandardOutput(). O exemplo dá suporte ao cancelamento.