Usar o servidor de histórico do Apache Spark estendido para depurar e diagnosticar aplicativos Apache Spark
Este artigo fornece diretrizes sobre como usar o servidor de histórico do Apache Spark estendido para depurar e diagnosticar aplicativos Apache Spark concluídos e em execução.
Acesse o servidor de histórico do Apache Spark
O servidor de histórico do Apache Spark é a interface do usuário da Web para aplicativos Spark concluídos e em execução. Você pode abrir a interface do usuário da Web do Apache Spark no Notebook do indicador de progresso ou na página de detalhes do aplicativo Apache Spark.
Abrir a interface do usuário da Web do Spark no notebook do indicador de progresso
Quando um trabalho do Apache Spark é disparado, o botão para abrir a Interface do usuário da Web do Spark está dentro da opção Mais ações no indicador de progresso. Selecione a Interface do usuário da Web do Spark e aguarde alguns segundos e, em seguida, a página interface do usuário do Spark será exibida.

Como abrir a interface do usuário da Web do Spark na página de detalhes do aplicativo Apache Spark
A interface do usuário da Web do Spark também pode ser aberta por meio da página de detalhes do aplicativo Apache Spark. Selecione Hub de monitoramento no lado esquerdo da página e, em seguida, selecione um aplicativo Apache Spark. A página de detalhes do aplicativo é exibida.

Para um aplicativo Apache Spark cujo status está como em execução, o botão mostra a interface do usuário do Spark. Selecione Interface do Usuário do Spark e a página interface do usuário do Spark é exibida.

Para um aplicativo Apache Spark cuja status foi encerrada, o status de encerramento pode ser Interrompido, Com Falha, Cancelado ou Concluído. O botão mostra o Servidor de histórico do Spark. Selecione Servidor de histórico do Spark e a página interface do usuário do Spark é exibida.

Guia Grafo no servidor de histórico do Apache Spark
Selecione a ID do trabalho que deseja ver. Em seguida, selecione Grafo no menu de ferramentas para acessar a exibição de grafo do trabalho.
Visão geral
Você pode ter uma visão geral do trabalho no grafo do trabalho gerado. Por padrão, o grafo mostra todos os trabalhos. Você pode filtrar a exibição por ID do Trabalho.

Monitor
Por padrão, a exibição de Progresso é selecionada. Você pode verificar o fluxo de dados selecionando Lido ou Gravado na lista suspensa Exibir.

O nó do grafo exibe as cores mostradas na legenda do mapa de calor.

Reprodução
Para reproduzir o trabalho, selecione Reprodução. Selecione Parar a qualquer momento para parar. As cores da tarefa mostram status diferentes durante a reprodução:
| Cor | Significado |
|---|---|
| Verde | Bem-sucedido: o trabalho foi concluído com êxito. |
| Laranja | Repetido: instâncias de tarefas que falharam, mas não afetam o resultado final do trabalho. Essas tarefas tiveram instâncias duplicadas ou repetidas que poderão ser bem-sucedidas mais tarde. |
| Azul | Em execução: a tarefa está em execução. |
| Branca | Aguardando ou ignorado: a tarefa está esperando para ser executada ou a fase foi ignorada. |
| Vermelho | Falha: a tarefa falhou. |
A imagem a seguir mostra as cores de status verde, laranja e azul.

A imagem a seguir mostra as cores de status verde e branco.

A imagem a seguir mostra as cores de status vermelho e verde.

Observação
O servidor de histórico do Apache Spark permite a reprodução de cada trabalho concluído (mas não permite a reprodução para trabalhos incompletos).
Zoom
Use a rolagem do mouse para ampliar e reduzir o grafo do trabalho ou selecione Aplicar Zoom para Ajustar para fazer com que ele se ajuste à tela.

Dicas de ferramenta
Focalize o nó do grafo para ver a dica de ferramenta quando houver tarefas com falha e selecione uma fase para abrir a página referente a ela.

Na guia do grafo do trabalho, as fases têm uma dica de ferramenta e um pequeno ícone exibido se houver tarefas que atendam às seguintes condições:
| Condição | Descrição |
|---|---|
| Distorção de dados | Tamanho de leitura de dados > tamanho médio de leitura de dados de todas as tarefas dentro deste estágio * 2 e tamanho de leitura de dados > 10 MB. |
| Distorção de tempo | tempo de execução > tempo médio de execução de todas as tarefas dentro desta fase * 2 e tempo de execução > 2 minutos. |
![]()
Descrição do nó do grafo
O nó do grafo do trabalho exibe as seguintes informações de cada fase:
- ID
- Nome ou descrição
- Número total de tarefas
- Leitura de dados: a soma do tamanho de entrada e o tamanho de leitura em ordem aleatória
- Gravação de dados: a soma do tamanho de saída e do tamanho das gravações em ordem aleatória
- Tempo de execução: o tempo entre a hora de início da primeira tentativa e a hora de conclusão da última tentativa
- Contagem de linhas: a soma dos registros de entrada, registros de saída, registros de leitura aleatória e registros de gravação aleatória
- Progresso
Observação
Por padrão, o nó do grafo do trabalho exibe informações da última tentativa de cada fase (exceto pelo tempo de execução da fase). No entanto, durante a reprodução, o nó do grafo mostra informações sobre cada tentativa.
O tamanho dos dados de leitura e gravação é de 1 MB = 1000 KB = 1000 * 1000 bytes.
Fornecer comentários
Envie comentários sobre problemas selecionando Fornecer comentários.

Limite de número de estágio
Para consideração de desempenho, por padrão, o grafo só estará disponível quando o aplicativo Spark tiver menos de 500 estágios. Se houver muitos estágios, ele falhará com um erro como este:
The number of stages in this application exceeds limit (500), graph page is disabled in this case.
Como solução alternativa, antes de iniciar um aplicativo Spark, aplique esta configuração do Spark para aumentar o limite:
spark.ui.enhancement.maxGraphStages 1000
Mas observe que isso pode causar um desempenho ruim da página e da API, pois o conteúdo pode ser muito grande para o navegador buscar e renderizar.
Explorar a guia Diagnóstico no servidor de histórico do Apache Spark
Para acessar a guia Diagnóstico, selecione uma ID de trabalho. Em seguida, selecione Diagnóstico no menu de ferramentas para acessar a exibição de Diagnóstico do trabalho. A guia de diagnóstico inclui Distorção de dados, Distorção de tempo e Análise de uso do executor.
Confira as informações de Distorção de dados, Distorção de tempo e Análise de uso do executor selecionando as respectivas guias.

Distorção de dados
Quando você seleciona a guia Distorção de Dados, as tarefas distorcidas correspondentes são exibidas com base nos parâmetros especificados.
Especificar Parâmetros – a primeira seção exibe os parâmetros, que são usados para detectar a Distorção de dados. A regra padrão é: a leitura de dados da tarefa é maior que três vezes a média da leitura de dados da tarefa e a leitura de dados da tarefa é maior do que 10 MB. Se quiser definir sua regra para tarefas com distorção, você poderá escolher seus parâmetros. As seções de Fase Distorcida e Gráfico de Distorção são atualizadas de acordo.
Estágio Distorcido: a segunda seção exibe as fases que têm tarefas distorcidas que atendem aos critérios especificados acima. Se houver mais de uma tarefa distorcida em uma fase, a tabela de fase distorcida exibirá apenas a tarefa mais distorcida (por exemplo, com os maiores dados para distorção de dados).

Gráfico de Distorção: quando uma linha na tabela da fase com distorção é selecionada, o gráfico de distorção exibe mais detalhes de distribuições da tarefa com base na leitura de dados e no tempo de execução. As tarefas distorcidas são marcadas em vermelho e as normais são marcadas em azul. O gráfico exibe até 100 tarefas de exemplo e os detalhes da tarefa são exibidos no painel inferior direito.



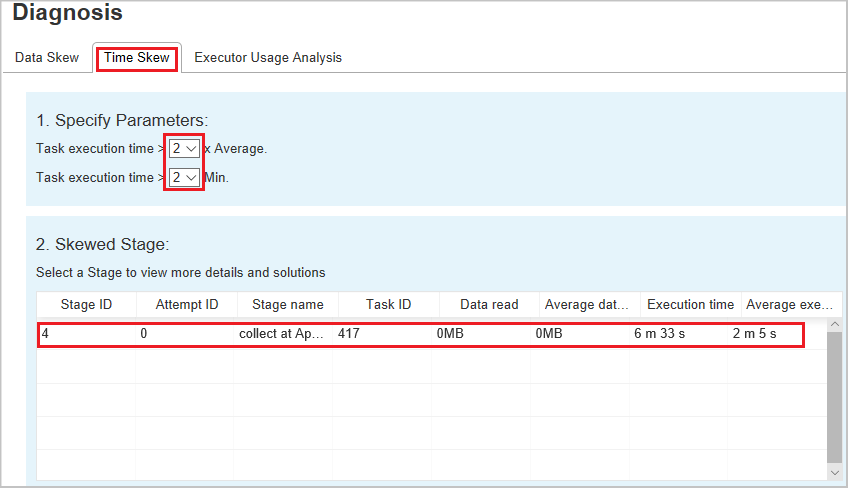
Distorção de tempo
A guia Distorção de Tempo exibe tarefas distorcidas com base no tempo de execução da tarefa.
Especificar Parâmetros: a primeira seção exibe os parâmetros, que são usados para detectar a distorção de tempo. Os critérios padrão para detectar a distorção de tempo são: o tempo de execução da tarefa é maior do que três vezes o tempo médio de execução e o tempo de execução da tarefa é maior que 30 segundos. Você pode alterar os parâmetros com base em suas necessidades. O Estágio Distorcido e o Gráfico de Distorção exibem as informações sobre as fases e as tarefas correspondentes, assim como a guia Distorção de Dados acima.
Selecione Distorção de Tempo e o resultado filtrado será exibido na seção Fase Distorcida de acordo com os parâmetros definidos na seção Especificar Parâmetros. Ao selecionar um item na seção Estágio Distorcido, o gráfico correspondente será exibido na seção 3 e os detalhes da tarefa serão exibidos no painel inferior direito.

Análise de uso do executor
Esse recurso foi preterido no Fabric. Se você ainda quiser usar como solução alternativa, acesse a página adicionando expressamente "/executorusage" atrás do caminho "/diagnostic" na URL, dessa forma:
