Ingerir dados no OneLake e analisar com o Azure Databricks
Neste guia, você vai:
Crie um pipeline em um espaço de trabalho e ingerir dados no OneLake no formato Delta.
Leia e modifique uma tabela Delta no OneLake com o Azure Databricks.
Pré-requisitos
Antes de começar, você deve ter:
Um workspace com um item Lakehouse.
Um workspace premium do Azure Databricks. Somente os workspaces premium do Azure Databricks suportam a passagem de credenciais do Microsoft Entra. Ao criar o cluster, habilite a passagem de credencial no Azure Data Lake Storage nas Opções Avançadas.
Um conjunto de dados de exemplo
Ingerir dados e modificar a tabela Delta
Navegue até seu lakehouse no serviço do Power BI, selecione Obter dados e selecione Novo pipeline de dados.
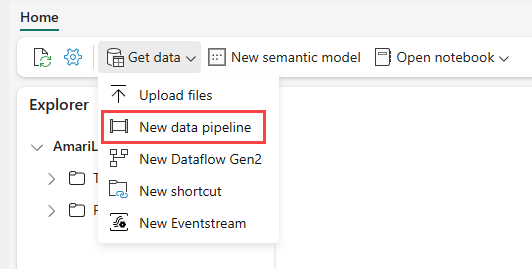
No prompt do Novo Pipeline, insira um nome no novo pipeline e selecione Criar.
Para este exercício, selecione o Táxi de NOVA YORK – Dados de exemplo verdes, como a fonte de dados e selecione Avançar.
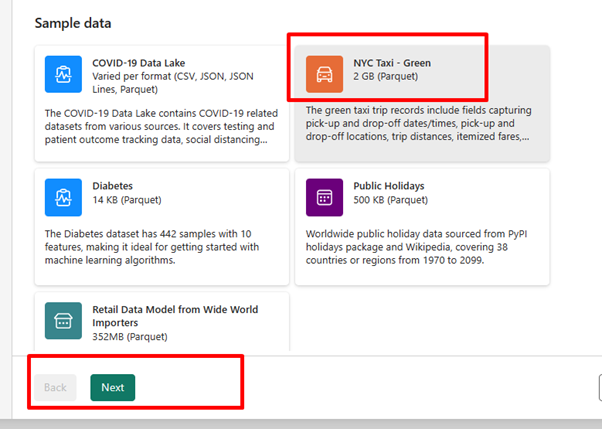
Na tela de visualização, selecione Avançar.
Quanto ao destino dos dados, selecione o nome do lakehouse que deseja usar para armazenar os dados na tabela Delta do OneLake. Escolha um lakehouse existente ou criar um.
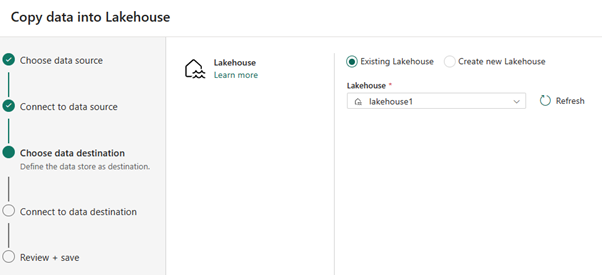
Selecione onde você quer armazenar a saída. Escolha Tabelas como a pasta Raiz e insira “nycsample” como o nome da tabela.
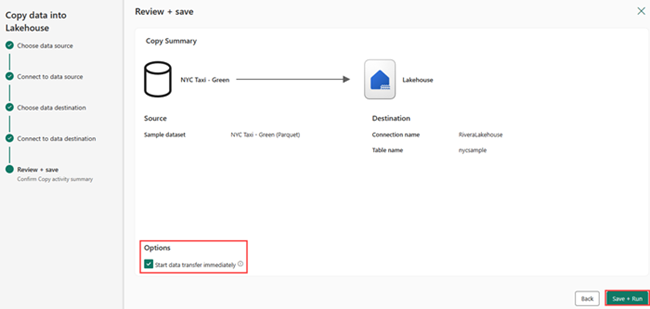
Na tela Examinar + Salvar, selecione Iniciar transferência de dados imediatamente e selecioneSalvar + Executar.
Após o trabalho ser concluído, navegue até o lakehouse e veja a tabela delta listada na pasta /Tables.
Clique com o botão direito do mouse no nome da tabela criada, selecione Propriedades e copie o caminho do ABFS (Azure Blob Filesystem).
Abra o notebook do seu Azure Databricks. Leia a tabela Delta no OneLake.
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)Atualize os dados da tabela Delta alterando um valor de campo.
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;