Tutorial: Como usar um notebook com o Apache Spark para consultar um banco de dados KQL
Notebooks são documentos legíveis que contêm descrições e resultados de análise de dados, além de documentos executáveis que podem ser executados para realizar a análise de dados. Neste artigo, você aprenderá a usar um notebook do Microsoft Fabric para ler e gravar dados em um banco de dados KQL usando o Apache Spark. Este tutorial usa conjuntos de dados e notebooks pré-criado na Inteligência em Tempo Real e nos ambientes de Engenharia de Dados no Microsoft Fabric. Para obter mais informações sobre notebooks, confira Como usar notebooks do Microsoft Fabric.
Especificamente, você aprenderá a:
- Criar um banco de dados KQL
- Importar um notebook
- Gravar dados em um banco de dados KQL usando o Apache Spark
- Consultar dados de um banco de dados KQL
Pré-requisitos
- Um espaço de trabalho com uma capacidade habilitada para o Microsoft Fabric
1 - Criar um banco de dados KQL
Abra o comutador de experiência na parte inferior do painel de navegação e selecione Inteligência em Tempo Real.
Selecione o título Banco de dados KQL.
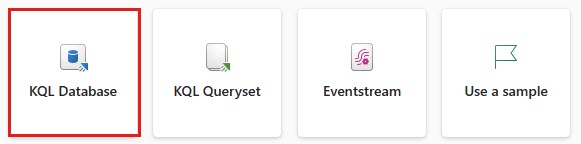
No campo Nome do Banco de Dados KQL , insira nycGreenTaxi e selecione Criar.
O banco de dados KQL foi criado dentro do contexto do workspace selecionado.
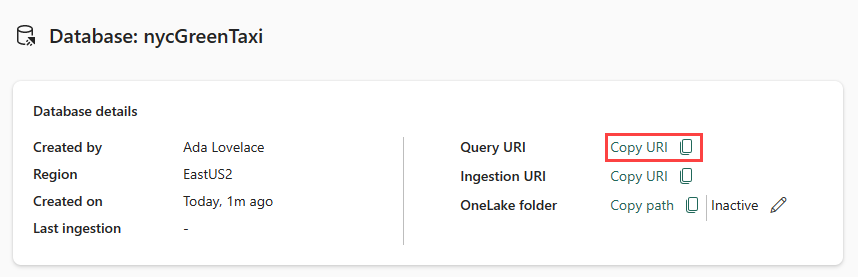
Copie o URI da consulta do cartão de detalhes do banco de dados no painel do banco de dados e cole-o em algum lugar, como em um bloco de notas, para usar em uma etapa posterior.
2- Baixar o notebook NYC GreenTaxi
Criamos um notebook de amostra que leva você por todas as etapas necessárias para carregar dados em seu banco de dados usando o conector spark.
Abra o repositório de exemplos do Fabric no GitHub para baixar o Notebook KQL NYC Taxi.

Salve o notebook localmente em seu dispositivo.
Observação
O notebook deve ser salvo no formato de arquivo
.ipynb.

3- Importar o notebook
O restante desse fluxo de trabalho ocorre na seção Engenharia de Dados do produto e usa um notebook Spark para carregar e consultar dados no banco de dados KQL.
Abra o comutador de experiências na parte inferior do painel de navegação, selecione Desenvolver e, em seguida, seu workspace.
Selecione Importar>Notebook>Deste computador>Carregar e, a seguir, escolha o notebook NYC GreenTaxi que você baixou em uma etapa anterior.
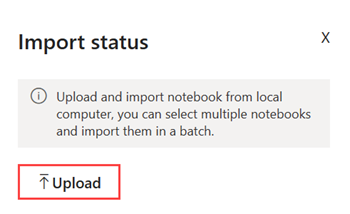
Após a importação ser concluída, abra o notebook no seu workspace.
4 - Obter dados
Para consultar seu banco de dados usando o conector do Spark, você precisa conceder acesso de leitura e gravação ao contêiner de blob do NYC GreenTaxi.
Selecione o botão Executar para executar cada célula sequencialmente ou selecione a célula e pressione Shift+ Enter. Repita essa etapa para cada célula de código.
Observação
Aguarde até que a marca de verificação de conclusão apareça antes de executar a próxima célula.
Execute a célula a seguir para habilitar o acesso ao contêiner de blob NYC GreenTaxi.

No KustoURI, cole o URI de consulta que você copiou anteriormente em vez do texto do espaço reservado.
Altere o nome do banco de dados do espaço reservado para nycGreenTaxi.
Altere o nome da tabela de espaço reservado para GreenTaxiData.

Execute a célula.
Execute a próxima célula para gravar dados no banco de dados. Pode levar alguns minutos para que essa etapa seja concluída.




Seu banco de dados agora tem dados carregados em uma tabela chamada GreenTaxiData.
5- Executar o notebook
Execute as duas células restantes sequencialmente para consultar dados de sua tabela. Os resultados mostram as 20 maiores e mais baixas tarifas de táxi e distâncias registradas por ano.

6. Limpar os recursos
Limpe os itens criados navegando até o workspace no qual foram criados.
No workspace, passe o mouse sobre o notebook que você deseja excluir, selecione o menu Mais [...] >Excluir.
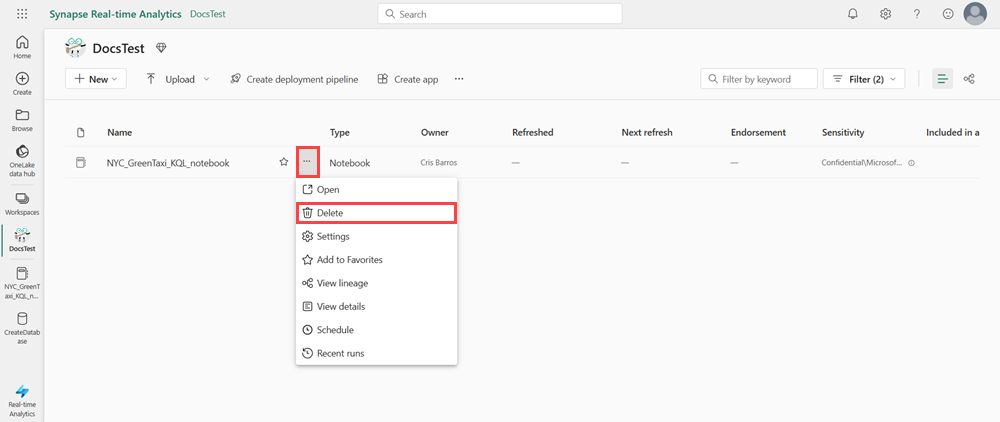
Selecione Excluir. Não é possível recuperar o notebook depois de excluí-lo.
