Utilizar a API de dados do setor como um motor de extração, transformação e carregamento (ETL) (pré-visualização)
Importante
As APIs na versão /beta no Microsoft Graph estão sujeitas a alterações. Não há suporte para o uso dessas APIs em aplicativos de produção. Para determinar se uma API está disponível na v1.0, use o seletor Versão.
A API de dados do setor é uma plataforma ETL (Extract-Transform-Load) focada no setor da educação que combina dados de múltiplas origens num único arquivo de dados do Azure Data Lake, normaliza os dados e exporta-os em fluxos de saída. A API fornece recursos que pode utilizar para obter estatísticas após o processamento dos dados e ajudar na monitorização e resolução de problemas.
A API de dados do setor é definida no subnamespace microsoft.graph.industryDataOData .
API e educação de dados do setor
A API de dados do setor alimenta a plataforma Microsoft School Data Sync (SDS) para ajudar a automatizar o processo de importação de dados e sincronização de organizações, associações de utilizadores e utilizadores e grupos com o Microsoft Entra ID e o Microsoft 365 a partir de sistemas de informação de estudantes (SIS) e sistemas de gestão de estudantes (SMS). Depois de normalizar os dados, a API utiliza os dados através de vários fluxos de aprovisionamento de saída para gerir utilizadores, grupos de classes, unidades administrativas e grupos de segurança.
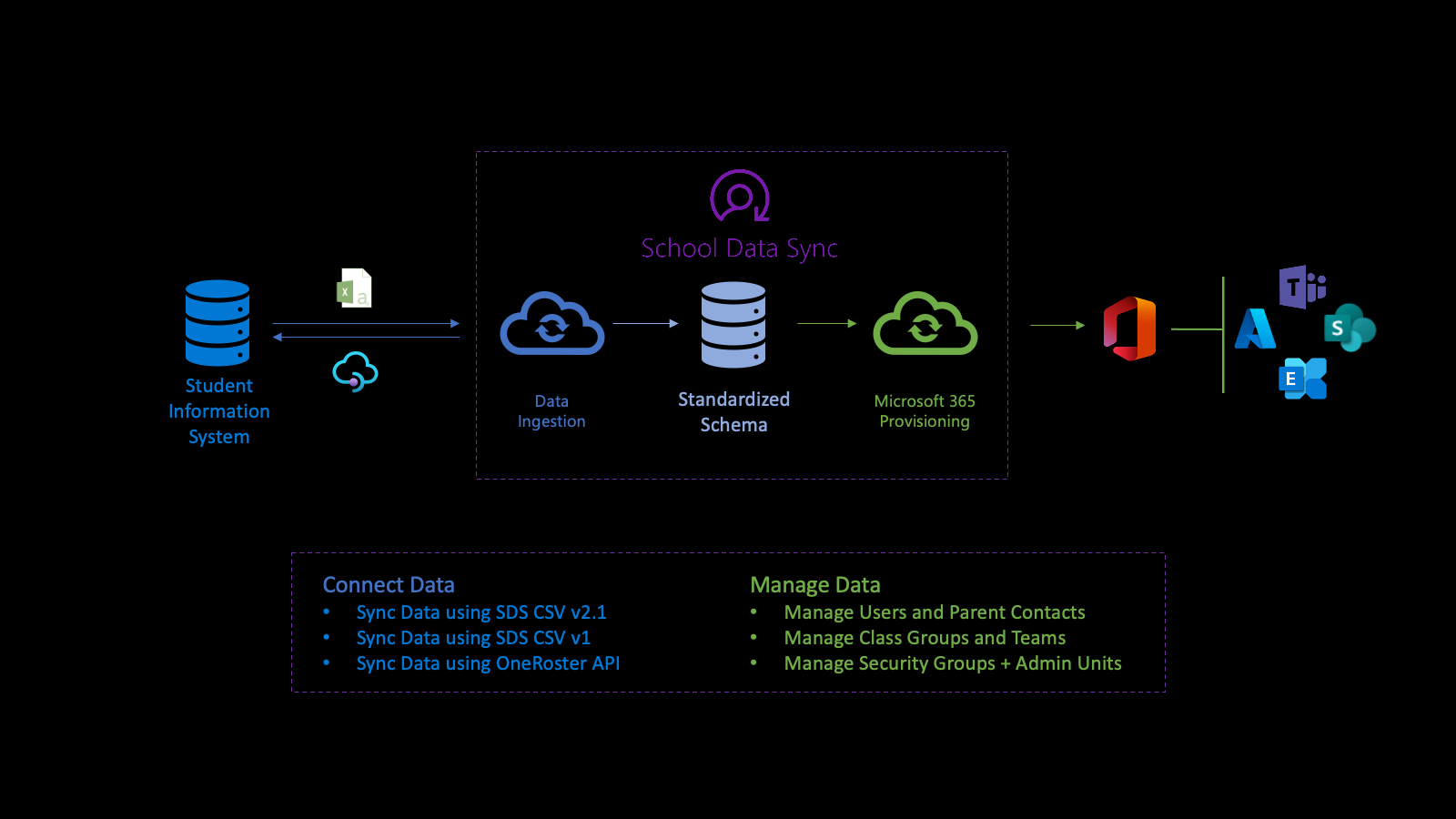
Em primeiro lugar, ligue-se aos dados da sua instituição. Para definir um fluxo de entrada, crie uma sourceSystemDefinition, dataConnector e yearTimePeriodDefinition. Por predefinição, o fluxo de entrada é ativado duas vezes (2x) diariamente (denominado execução).
Quando a execução é iniciada, liga-se ao sourceSystemDefinition e ao dataConnector do fluxo de entrada e executa a validação básica. A validação básica garante que a ligação está correta, quando a API do OneRoster é a origem ou os nomes de ficheiro e cabeçalhos estão corretos quando um CSV é a origem.
Em seguida, o sistema transforma os dados para importação em preparação para validação avançada. Como parte da transformação de dados, os dados são associados com base no yearTimePeriodDefinition configurado.
O sistema armazena a cópia mais recente do Microsoft Entra ID do inquilino no Azure Data Lake. A cópia do Microsoft Entra ajuda com a correspondência de utilizadores entre o objeto sourceSystemDefinition e o objeto de utilizador do Microsoft Entra. Nesta fase, a ligação de correspondência é escrita apenas no Azure Data Lake.
Em seguida, o fluxo de entrada efetua uma validação avançada para determinar o estado de funcionamento dos dados. A validação centra-se na identificação de erros e avisos para garantir que os bons dados entram e os dados inválidos ficam de fora. Os erros indicam que um registo não passou na validação e foi removido do processamento adicional. Os avisos indicam que o valor num campo opcional de um registo não passou. O valor é removido do registo, mas o registo está incluído para processamento adicional.
Os erros e avisos ajudam-no a compreender melhor o estado de funcionamento dos dados.
Para os dados que passaram na validação, o processo utiliza o yearTimePeriodDefinition configurado para determinar a associação do armazenamento longitudinal, da seguinte forma:
- À medida que os dados são armazenados na representação interna no Azure Data Lake do inquilino, identifica quando foram vistos pela primeira vez pelos dados do setor.
- Para dados ligados a uma organização de utilizador, associação de funções e associação de grupo, também identifica os dados como ativos na sessão com base no yearTimePeriodDefinition.
- Em execuções futuras, para o mesmo fluxo de entrada, sourceSystemDefinition e yearTimePeriodDefinition, os dados da indústria identificam se o registo ainda é visto.
- Com base na presença ou ausência de registo, o registo é mantido ativo ou marcado como já não ativo na sessão para o yearTimePeriodDefinition configurado. Este processo determina a natureza histórica e longitudinal dos dados entre dias, meses e anos.
No final de cada execução, industryDataRunStatistics está disponível para determinar o estado de funcionamento dos dados.
São produzidos erros e avisos relacionados com industryDataRunStatistics para ajudar a fornecer uma compreensão inicial do estado de funcionamento dos dados. Quando investiga o estado de funcionamento dos dados, os dados do setor permitem transferir um ficheiro de registo que contém informações com base nos erros e avisos encontrados para iniciar o processo de investigação de dados para corrigir os dados no sistema de origem.
Depois de investigar e resolver quaisquer erros ou avisos de dados, quando estiver confortável com o estado atual do estado de funcionamento dos dados, pode ativar os cenários com os dados. Quando ativa um cenário para utilizar estes dados, o cenário cria um fluxo de aprovisionamento de saída.
A gestão de dados através de fluxos de aprovisionamento de saída simplifica a gestão de utilizadores e classes. Apenas os utilizadores ativos e correspondentes são incluídos nos dados utilizados para escrever a ligação para o objeto de utilizador do Microsoft Entra. Esta ligação facilita a integração entre o SIS/SMS e as respetivas secções para grupos e salas de aula do Microsoft Teams.
Para obter mais informações, veja as secções School Data Sync, pré-requisitos do SDS e conceitos principais do SDS da descrição geral do School Data Sync.
Registo, permissões e autorização
Pode integrar APIs de dados do setor em aplicações de terceiros. Para obter detalhes sobre como fazê-lo, consulte os seguintes artigos:
- Noções básicas de autenticação e autorização.
- Registar uma aplicação na plataforma de identidades da Microsoft.
- Obter acesso em nome de um utilizador.
- Referência de permissões do Microsoft Graph.
- Resolver erros de autorização do Microsoft Graph.
Casos de uso comuns
| Caso de uso | Recurso REST | Confira também |
|---|---|---|
| Criar uma atividade para importar um conjunto de dados delimitado | inboundFileFlow | métodos inboundFileFlow |
| Definir uma origem de dados de entrada | sourceSystemDefinition | sourceSystemDefinition methods (Métodos sourceSystemDefinition) |
| Criar um conector para publicar dados num Azure Data Lake (se CSV) | azureDataLakeConnector | métodos azureDataLakeConnector |
Domínio de dados
A propriedade dataDomain define o tipo de dados que é importado e determina o formato do modelo de dados comum no qual serão armazenados. Atualmente, o único dataDomain suportado é educationRostering.
Definições de referência
Uma referenceDefinition representa um valor enumerado. Cada domínio da indústria suportado recebe uma coleção distinta de definições. os recursos referenceDefinition são utilizados extensivamente em todo o sistema, tanto para a configuração como para a transformação, em que os valores potenciais são específicos de uma determinada indústria. Cada referenceDefinition utiliza um identificador composto de {referenceType}-{code} para proporcionar uma experiência consistente entre os inquilinos do cliente.
Valores de referência
Os tipos baseados em referenceValue fornecem uma experiência de programador simplificada para referência de enlaceSutilizadores de definição . Cada tipo referenceValue está vinculado a um único tipo de referência, permitindo que os programadores forneçam apenas a parte de código da definição de referência como uma cadeia simples e eliminando potenciais confusões quanto ao tipo de referênciaDefinição que uma determinada propriedade é esperada.
Exemplo
A propriedade userMatchingSettings.sourceIdentifier utiliza um tipo identifierTypeReferenceValue que se vincula ao RefIdentifierTypereferenceType.
"sourceIdentifier": {
"code": "username"
},
Uma referenceDefinition também pode ser vinculada diretamente com a propriedade value .
"sourceIdentifier": {
"value@odata.bind": "external/industryData/referenceDefinitions/RefIdentifierType-username"
},
Grupos de função
A transformação dos dados é frequentemente moldada pela função de cada utilizador individual numa organização. Estas funções são definidas como definições de referência. Dado o número de potenciais funções, vincular cada função individual resultaria numa experiência de utilizador entediante.
Os grupos de funções são uma coleção de RefRole códigos.
{
"@odata.type": "#microsoft.graph.industryDataRoleGroup",
"id": "37a9781b-db61-4a3c-a3c1-8cba92c9998e",
"displayName": "Staff",
"roles": [
{ "code": "adjunct" },
{ "code": "administrator" },
{ "code": "advisor" },
{ "code": "affiliate" },
{ "code": "aide" },
{ "code": "alumni" },
{ "code": "assistant" }
]
}
Conectores de dados do setor
Um industryDataConnector funciona como uma ponte entre uma sourceSystemDefinition e um Fluxo de Entrada. É responsável por adquirir dados de uma origem externa e fornecer os dados aos fluxos de dados de entrada.
Carregar e validar dados CSV
Para obter informações sobre os dados CSV, veja:
Seguem-se os requisitos para o ficheiro CSV:
- Os nomes de ficheiro e os cabeçalhos de coluna são sensíveis às maiúsculas e minúsculas.
- Os ficheiros CSV têm de estar no formato UTF-8.
- Os dados recebidos não podem ter quebras de linha.
Para rever e transferir o conjunto de exemplos de ficheiros CSV SDS V2.1, veja o repositório do GitHub do SDS.
Importante
O industryDataConnector não aceita alterações delta, pelo que cada sessão de carregamento tem de conter o conjunto de dados completo. Fornecer apenas dados parciais ou delta resulta na transição de quaisquer registos em falta para um estado inativo.
Pedir uma sessão de carregamento
O azureDataLakeConnector utiliza ficheiros CSV carregados para um contentor seguro. Este contentor reside no contexto de um único ficheiroUploadSession e é automaticamente destruído após a validação de dados ou a sessão de carregamento de ficheiros expirar.
A sessão de carregamento de ficheiros atual é obtida a partir de um azureDataLakeConnector através de getUploadSession que devolve o URL de SAS para carregar os ficheiros CSV.
Validar ficheiros carregados
Os ficheiros de dados carregados têm de ser validados antes de um fluxo de entrada poder processar os dados. O processo de validação finaliza o ficheiro atualUploadSession e verifica se todos os ficheiros necessários estão presentes e formatados corretamente. A validação é iniciada ao chamar industryDataConnector: validar a ação do recurso azureDataLakeConnector .
A ação validar cria um ficheiro de execução prolongadaValidateOperation. O URI do ficheiroValidateOperation é fornecido no Location cabeçalho da resposta. Pode utilizar este URI para controlar o estado da operação de execução prolongada e quaisquer erros ou avisos criados durante a validação.
Próximas etapas
Utilize as APIs de dados da indústria do Microsoft Graph como um motor de extração, transformação e carregamento (ETL). Para saber mais:
- Explore os recursos e os métodos mais úteis para seu cenário.
- Experimente a API no Explorador do Graph.