Domínio de segurança: segurança operacional
O domínio de segurança operacional garante que os ISVs implementam um conjunto forte de técnicas de mitigação de segurança contra uma miríade de ameaças que os atores de ameaças enfrentam. Esta ação foi concebida para proteger o ambiente operativo e os processos de desenvolvimento de software para criar ambientes seguros.
Formação de sensibilização
A formação de sensibilização para a segurança é importante para as organizações, uma vez que ajuda a minimizar os riscos decorrentes de erros humanos, que está envolvido em mais de 90% das falhas de segurança. Ajuda os colaboradores a compreender a importância das medidas e procedimentos de segurança. Quando a formação de sensibilização de segurança é oferecida, reforça a importância de uma cultura com reconhecimento de segurança onde os utilizadores sabem reconhecer e responder a potenciais ameaças. Um programa eficaz de formação de sensibilização de segurança deve incluir conteúdos que abrangem uma vasta gama de tópicos e ameaças que os utilizadores possam enfrentar, como engenharia social, gestão de palavras-passe, privacidade e segurança física.
Controlo N.º 1
Forneça provas de que:
A organização fornece formação de sensibilização de segurança estabelecida aos utilizadores do sistema de informação (incluindo gestores, executivos superiores e empreiteiros):
Como parte da preparação inicial para novos utilizadores.
Quando necessário, as alterações do sistema de informações.
Frequência de formação de sensibilização definida pela organização.
Documenta e monitoriza atividades de deteção de segurança do sistema de informações individuais e retém registos de formação individuais através de uma frequência definida pela organização.
Intenção: formação para novos utilizadores
Este subponto centra-se na criação de um programa de formação de sensibilização de segurança obrigatório concebido para todos os funcionários e novos funcionários que aderirem à organização, independentemente do seu papel. Isto inclui gestores, executivos seniores e empreiteiros. O programa de sensibilização de segurança deve abranger um programa curricular abrangente concebido para transmitir conhecimentos fundamentais sobre os protocolos, políticas e melhores práticas de segurança de informações da organização para garantir que todos os membros da organização estão alinhados com um conjunto unificado de normas de segurança, criando um ambiente de segurança de informação resiliente.
Diretrizes: formação para novos utilizadores
A maioria das organizações utilizará uma combinação de formação de sensibilização de segurança baseada na plataforma e documentação administrativa, como documentação de políticas e registos, para controlar a conclusão da formação para todos os funcionários em toda a organização. As provas fornecidas devem mostrar que os funcionários concluíram a formação, o que deve ser apoiado com políticas/procedimentos de apoio que delineiem o requisito de sensibilização de segurança.
Exemplo de evidência: formação para novos utilizadores
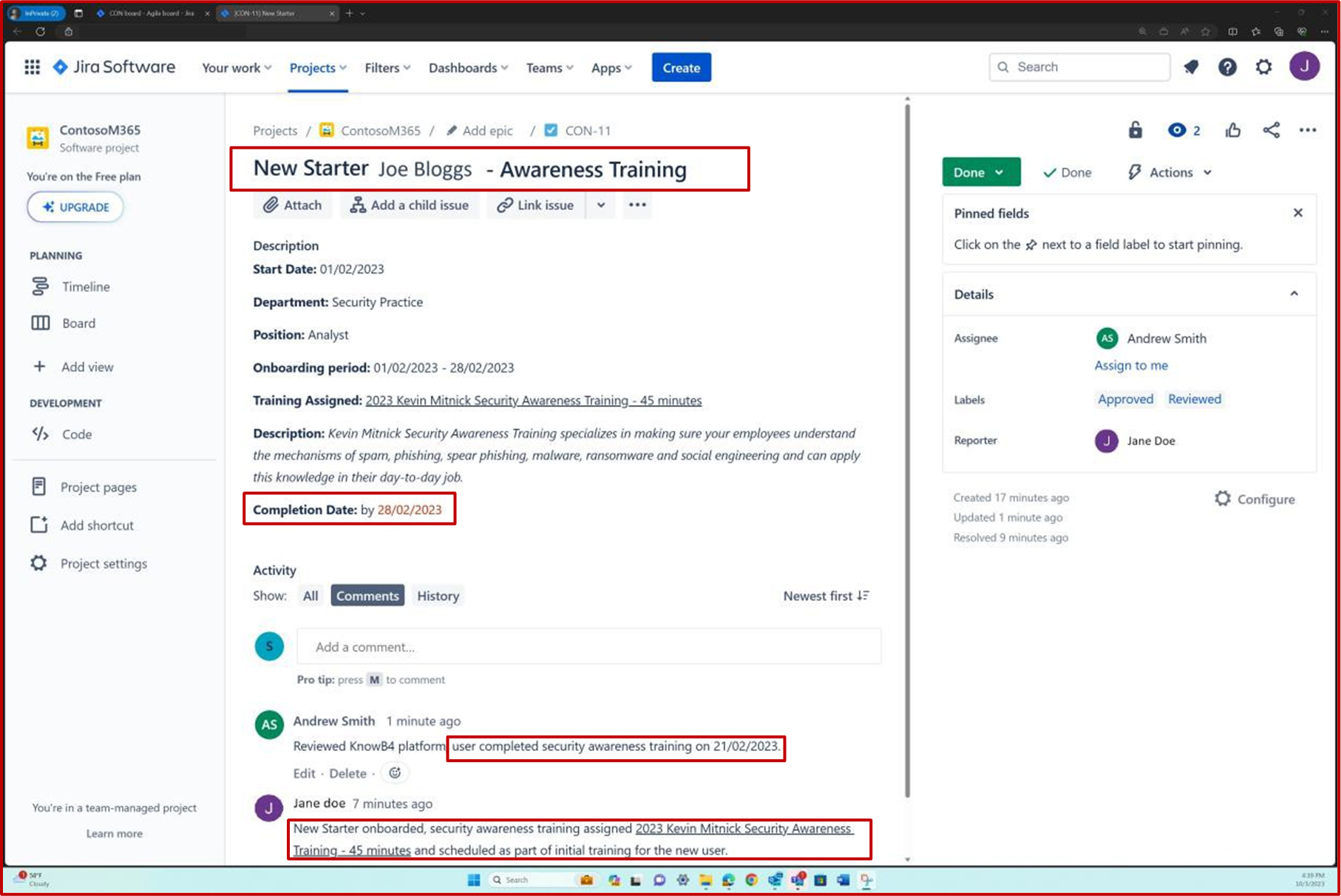
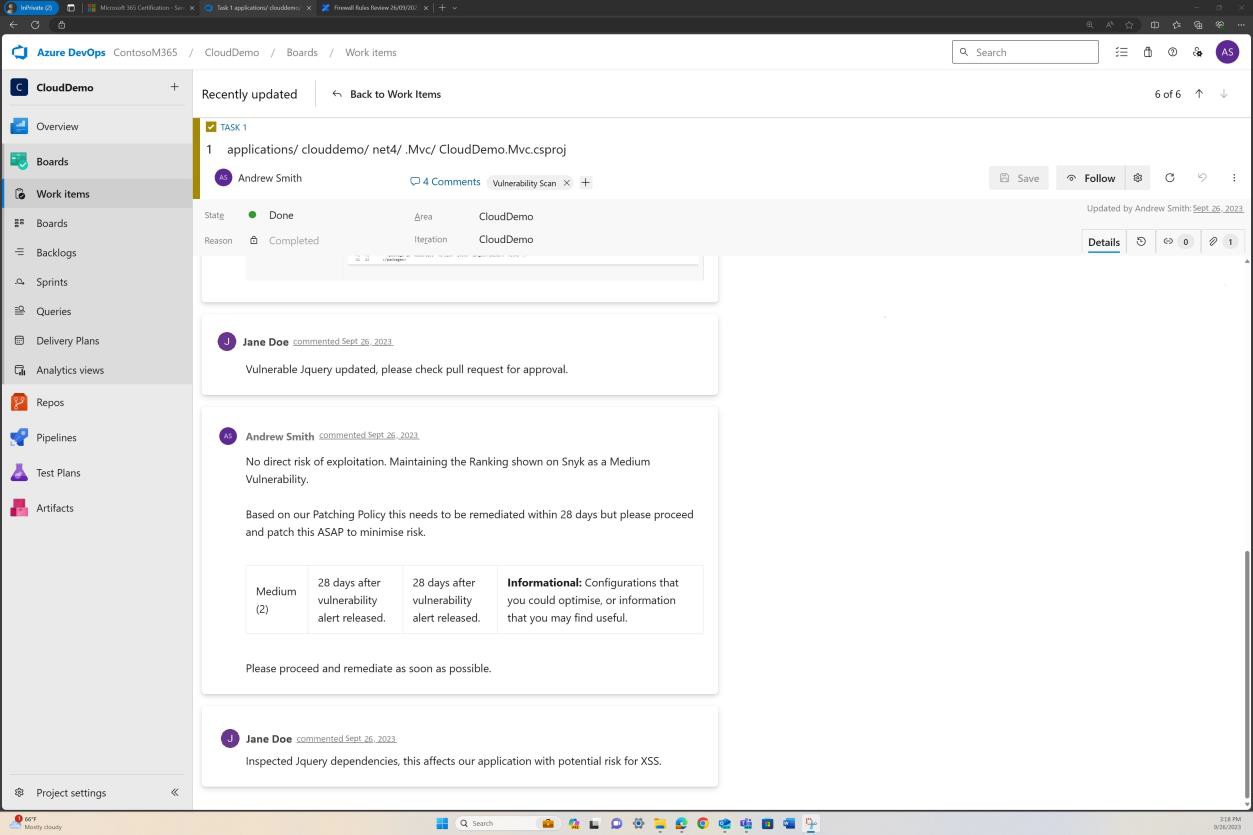
A seguinte captura de ecrã mostra a plataforma Confluence a ser utilizada para controlar a integração de novos funcionários. Foi angariado um bilhete JIRA para o novo funcionário, incluindo a respetiva atribuição, função, departamento, etc. Com o novo processo de arranque, a formação de sensibilização de segurança foi selecionada e atribuída ao colaborador que tem de estar concluída até à data para conclusão de28 de fevereiro de 2023.
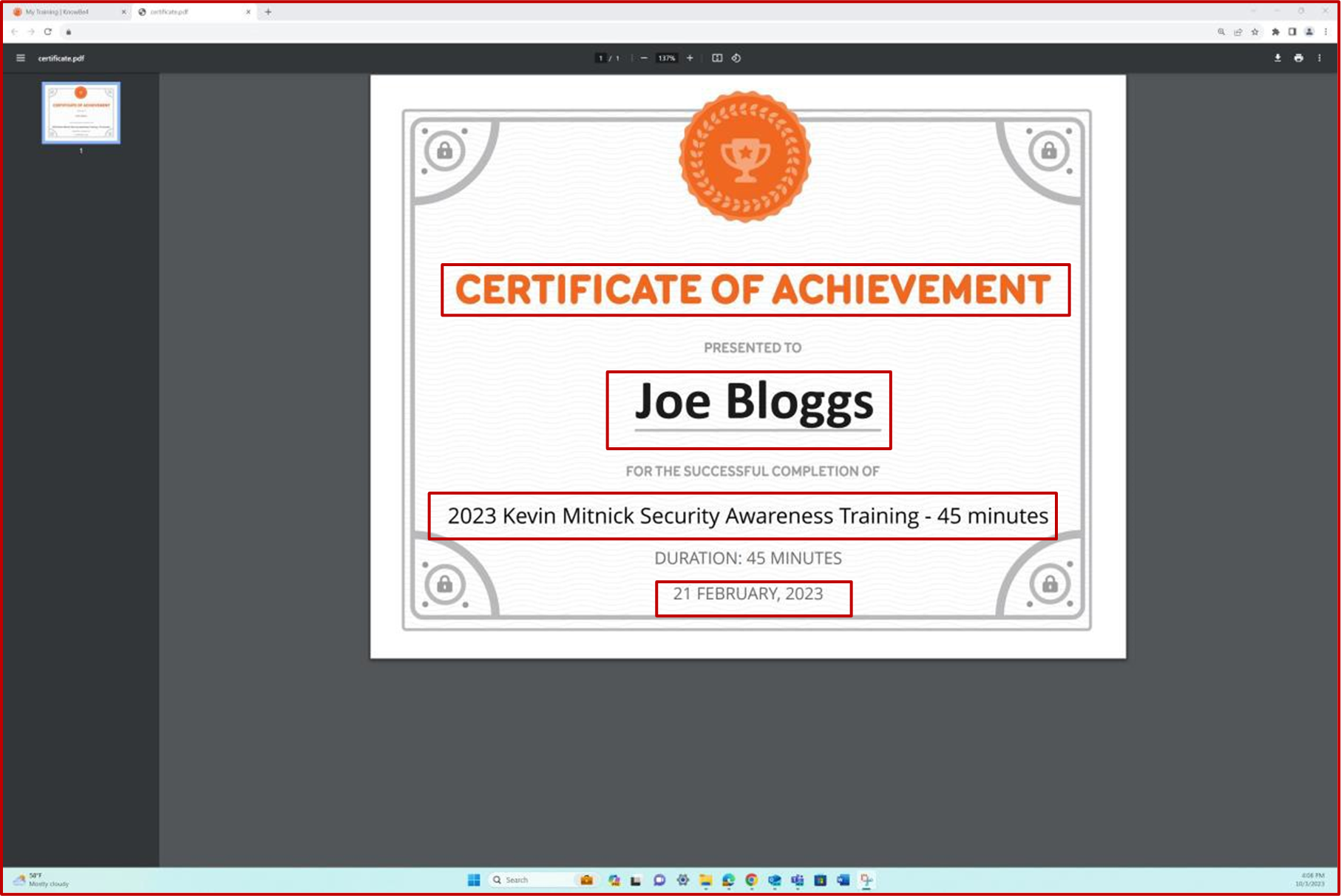
A captura de ecrã mostra o certificado de conclusão gerado pelo Knowb4 após a conclusão bem-sucedida da formação de deteção de segurança por parte do funcionário. A data de conclusão é 21de fevereiro de 2023, que se encontra dentro do período atribuído.
Intenção: alterações ao sistema de informações.
O objetivo deste subponto é garantir que a formação de sensibilização de segurança adaptável seja iniciada sempre que houver alterações significativas nos sistemas de informação da organização. As modificações podem ocorrer devido a atualizações de software, alterações de arquitetura ou novos requisitos regulamentares. A sessão de formação atualizada garante que todos os funcionários são informados sobre as novas alterações e o impacto resultante nas medidas de segurança, permitindo-lhes adaptar as suas ações e decisões em conformidade. Esta abordagem proativa é vital para proteger os recursos digitais da organização contra vulnerabilidades que podem surgir de alterações do sistema.
Diretrizes: alterações do sistema de informações.
A maioria das organizações utilizará uma combinação de formação de sensibilização de segurança baseada na plataforma e documentação administrativa, como documentação de política e registos, para controlar a conclusão da formação para todos os funcionários. As provas fornecidas têm de demonstrar que vários funcionários concluíram a formação com base em diferentes alterações aos sistemas da organização.
Exemplo de evidência: alterações do sistema de informações.
As capturas de ecrã seguintes mostram a atribuição de formação de sensibilização de segurança a vários funcionários e demonstram que ocorrem simulações de phishing.
A plataforma é utilizada para atribuir nova preparação sempre que ocorre uma alteração do sistema ou um teste falhar.
Intenção: frequência de formação de sensibilização.
O objetivo deste subponto é definir uma frequência específica da organização para a formação periódica de sensibilização de segurança. Isto pode ser agendado anualmente, semestralmente ou num intervalo diferente determinado pela organização. Ao definir uma frequência, a organização garante que os utilizadores são atualizados regularmente sobre o panorama evolutivo das ameaças, bem como sobre novas medidas e políticas de proteção. Esta abordagem pode ajudar a manter um elevado nível de deteção de segurança entre todos os utilizadores e a reforçar componentes de formação anteriores.
Diretrizes: frequência de formação de sensibilização.
A maioria das organizações terá documentação administrativa e/ou uma solução técnica para destacar/implementar o requisito e o procedimento para a formação de sensibilização de segurança, bem como definir a frequência da formação. As provas fornecidas devem demonstrar a conclusão de várias formações de sensibilização dentro do período definido e que existe um período definido pela sua organização.
Exemplo de evidência: frequência de formação de sensibilização.
As capturas de ecrã seguintes mostram instantâneos da documentação da política de deteção de segurança e que existe e é mantida. A política requer que todos os funcionários da organização recebam formação de deteção de segurança, conforme descrito na secção de âmbito da política. A formação tem de ser atribuída e concluída anualmente pelo departamento relevante.
De acordo com o documento de política, todos os colaboradores da organização têm de concluir três cursos (uma formação e duas avaliações) anualmente e no prazo de vinte dias após a atribuição. Os cursos têm de ser enviados por e-mail e atribuídos através do KnowBe4.
O exemplo fornecido mostra apenas instantâneos da política. Tenha em atenção que a expectativa é que o documento de política completo seja submetido.

A segunda captura de ecrã é a continuação da política e mostra a secção do documento que determina o requisito anual de formação e demonstra que a frequência definida pela organização da formação de sensibilização está definida para anualmente.

As duas capturas de ecrã seguintes demonstram a conclusão bem-sucedida das avaliações de preparação mencionadas anteriormente. As capturas de ecrã foram tiradas de dois funcionários diferentes.
Intenção: documentação e monitorização.
O objetivo deste subponto é criar, manter e monitorizar registos meticulosos da participação de cada utilizador na formação de sensibilização de segurança. Estes registos devem ser mantidos durante um período definido pela organização. Esta documentação serve como um registo auditável para a conformidade com regulamentos e políticas internas. O componente de monitorização permite que a organização avalie a eficácia do
formação, identificação de áreas para melhorar e compreender os níveis de envolvimento dos utilizadores. Ao manter estes registos durante um período definido, a organização pode controlar a eficácia e a conformidade a longo prazo.
Diretrizes: documentação e monitorização.
As provas que podem ser fornecidas para a formação de sensibilização de segurança dependerão da forma como a formação é implementada ao nível da organização. Isto pode incluir se a formação é realizada através de uma plataforma ou executada internamente com base num processo interno. As provas fornecidas têm de mostrar que os registos históricos de preparação concluídos para todos os utilizadores ao longo de um período existem e como este processo é controlado.
Exemplo de provas: documentação e monitorização.
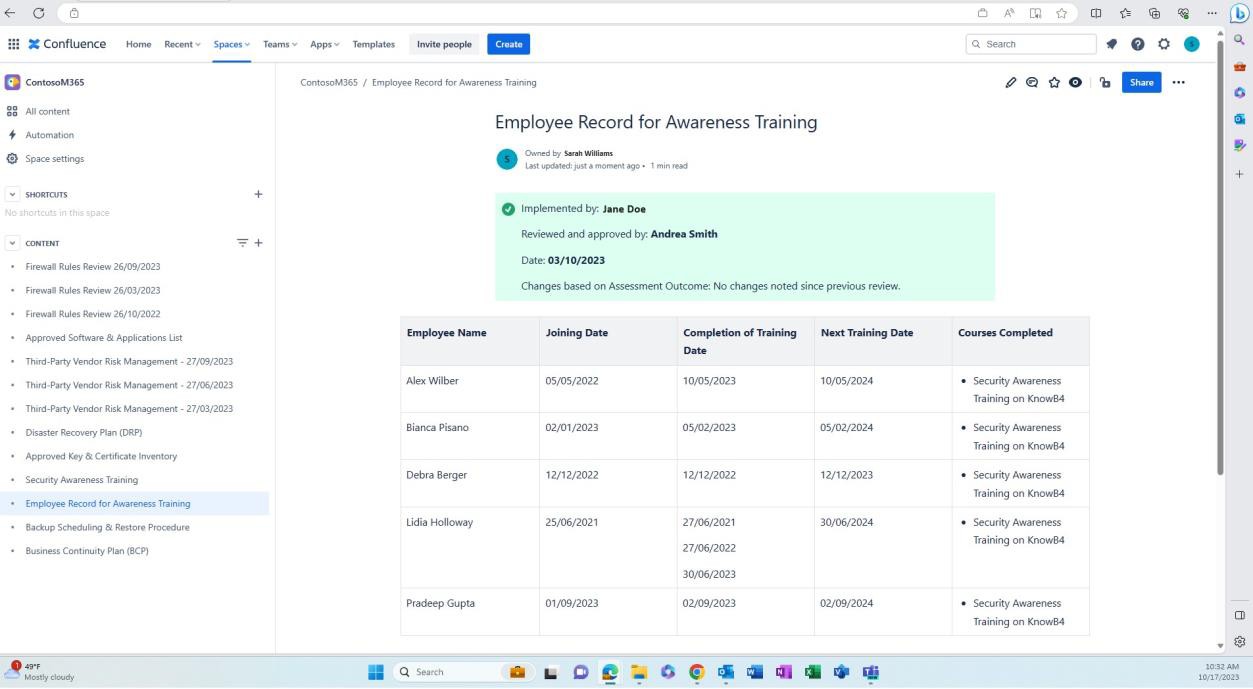
A captura de ecrã seguinte mostra o histórico do registo de formação de cada utilizador, incluindo a data de adesão, a conclusão da formação e quando a próxima formação está agendada. A avaliação deste documento é realizada periodicamente e, pelo menos, uma vez por ano para garantir que os registos de formação de sensibilização de segurança para cada funcionário são mantidos atualizados.
Proteção contra software maligno/antimalware
O software maligno representa um risco significativo para as organizações que podem variar o impacto de segurança causado ao ambiente operacional, consoante as características do software maligno. Os atores de ameaças perceberam que o software maligno pode ser rentabilizado com êxito, o que foi realizado através do crescimento de ataques de software maligno de estilo ransomware. O software maligno também pode ser utilizado para fornecer um ponto de entrada para um ator de ameaças comprometer um ambiente para roubar dados confidenciais, ou seja, Trojans/Rootkits de Acesso Remoto. Por conseguinte, as organizações precisam de implementar mecanismos adequados para proteger contra estas ameaças. As defesas que podem ser utilizadas são a análise baseada em antivírus (AV)/Deteção e Resposta de Pontos Finais (EDR)/Resposta de Deteção e Proteção de Pontos Finais (EDPR)/Análise heurística com Inteligência Artificial (IA). Se tiver implementado uma técnica diferente para mitigar o risco de software maligno, informe o Analista de Certificação sobre quem terá todo o gosto em explorar se isto cumpre ou não a intenção.
Controlo N.º 2
Forneça provas de que a solução antimalware está ativada e ativada em todos os componentes do sistema de exemplo e configurada para cumprir os seguintes critérios:
se a análise no acesso do antivírus estiver ativada e se as assinaturas estiverem atualizadas no prazo de um dia.
para antivírus que bloqueia automaticamente software maligno ou alertas e quarentenas quando é detetado software maligno
OU se EDR/EDPR/NGAV:
que a análise periódica está a ser efetuada.
está a gerar registos de auditoria.
é mantido atualizado continuamente e tem capacidades de auto-aprendizagem.
bloqueia software maligno conhecido e identifica e bloqueia novas variantes de software maligno com base em comportamentos de macros, bem como ter capacidades de concessão completas.
Intenção: análise no acesso
Este subponto foi concebido para verificar se o software antimalware está instalado em todos os componentes de sistema de exemplo e está a realizar a análise no acesso. O controlo também determina que a base de dados de assinatura da solução antimalware está atualizada dentro de um período de tempo de um dia. Uma base de dados de assinatura atualizada é crucial para identificar e mitigar as ameaças de software maligno mais recentes, garantindo assim que os componentes do sistema estão devidamente protegidos.
Diretrizes: análise no acesso**.**
Para demonstrar que uma instância ativa do AV está em execução no ambiente avaliado, forneça uma captura de ecrã para cada dispositivo no conjunto de exemplo acordado com o seu analista que suporte a utilização de antimalware. A captura de ecrã deve mostrar que o antimalware está em execução e que o software antimalware está ativo. Se existir uma consola de gestão centralizada para antimalware, poderão ser fornecidas provas da consola de gestão. Além disso, certifique-se de que fornece uma captura de ecrã que mostra que os dispositivos de exemplo estão ligados e a funcionar.
Exemplo de provas: análise no acesso**.**
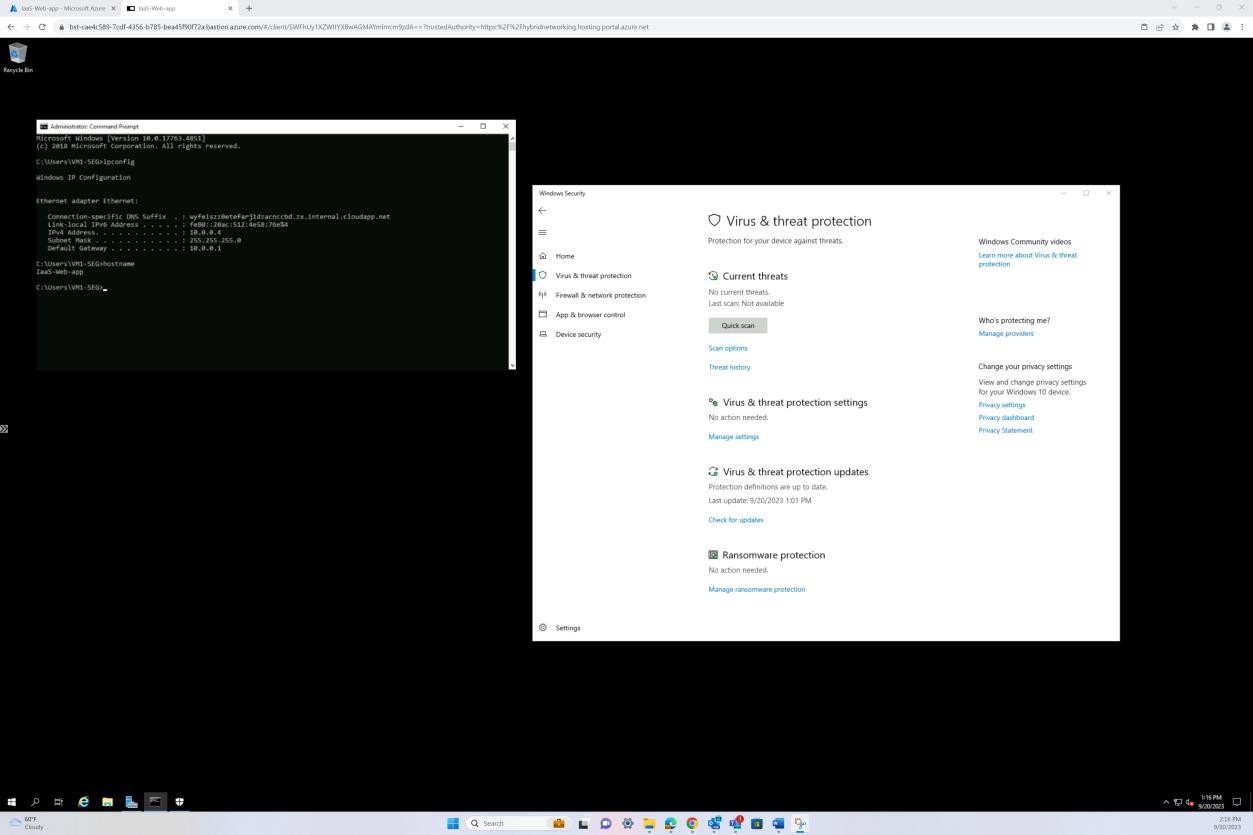
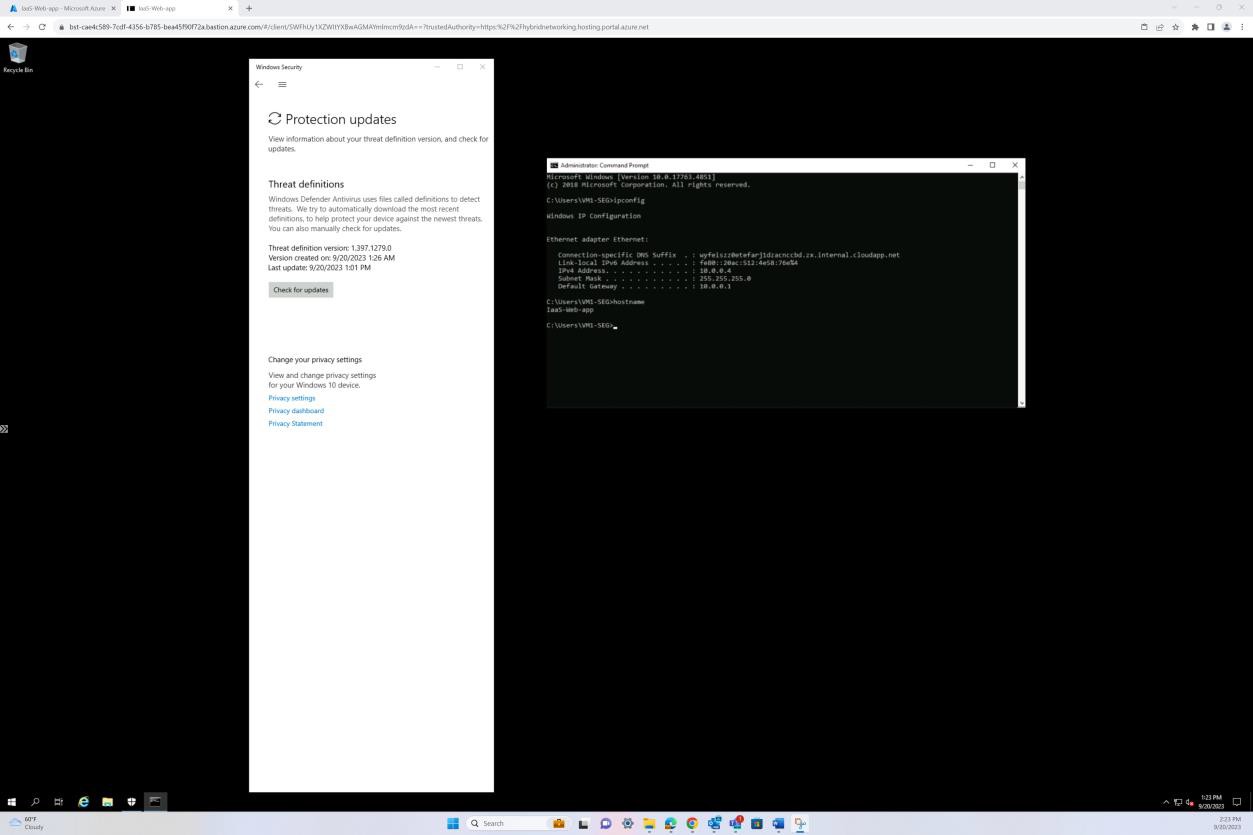
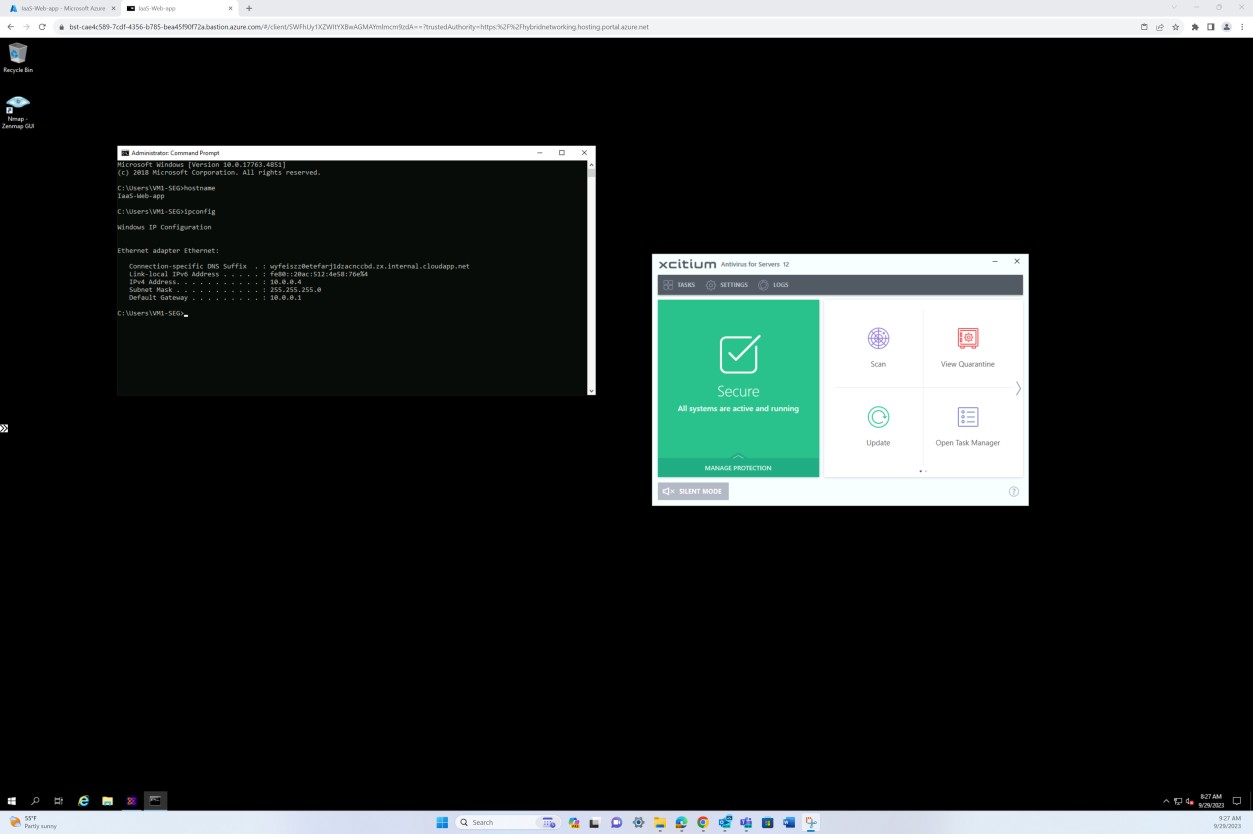
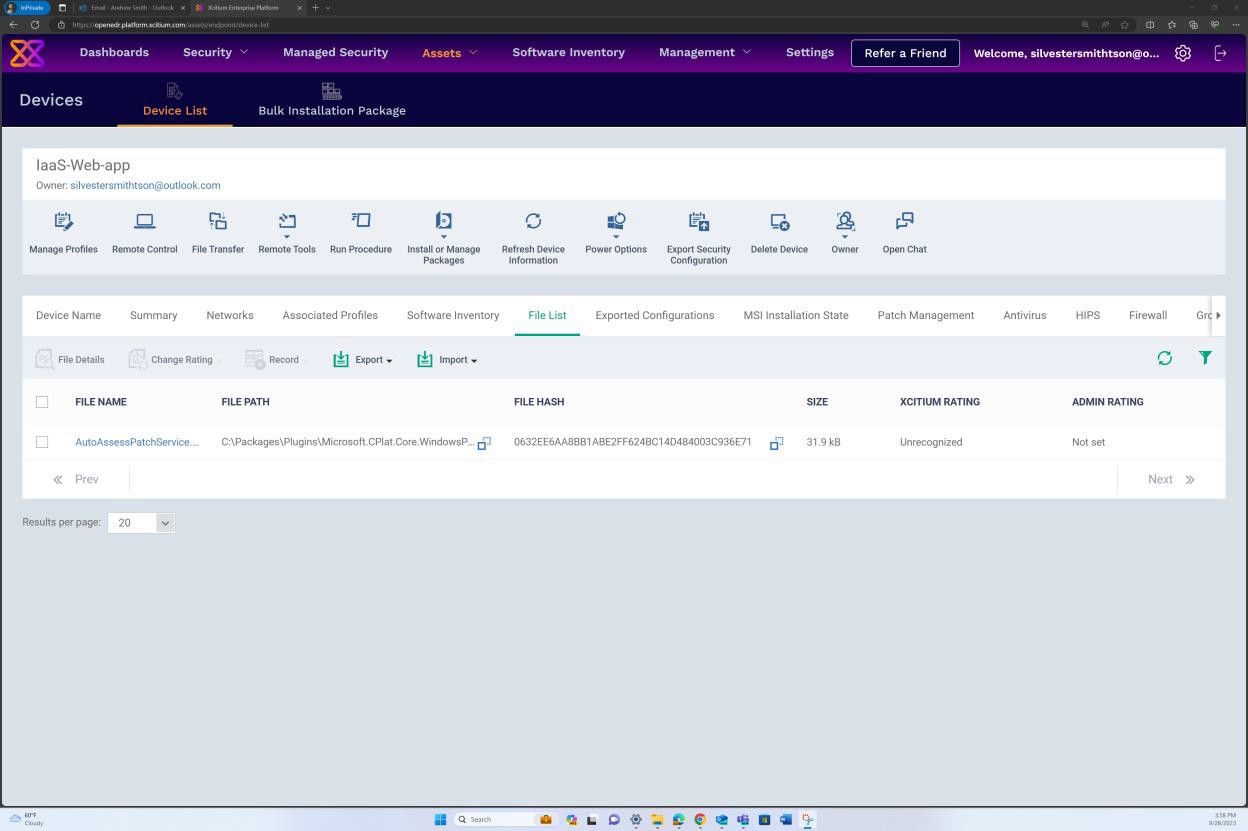
A seguinte captura de ecrã foi obtida a partir de um dispositivo Windows Server, que mostra que o "Microsoft Defender" está ativado para o nome de anfitrião "IaaS-Web-app".
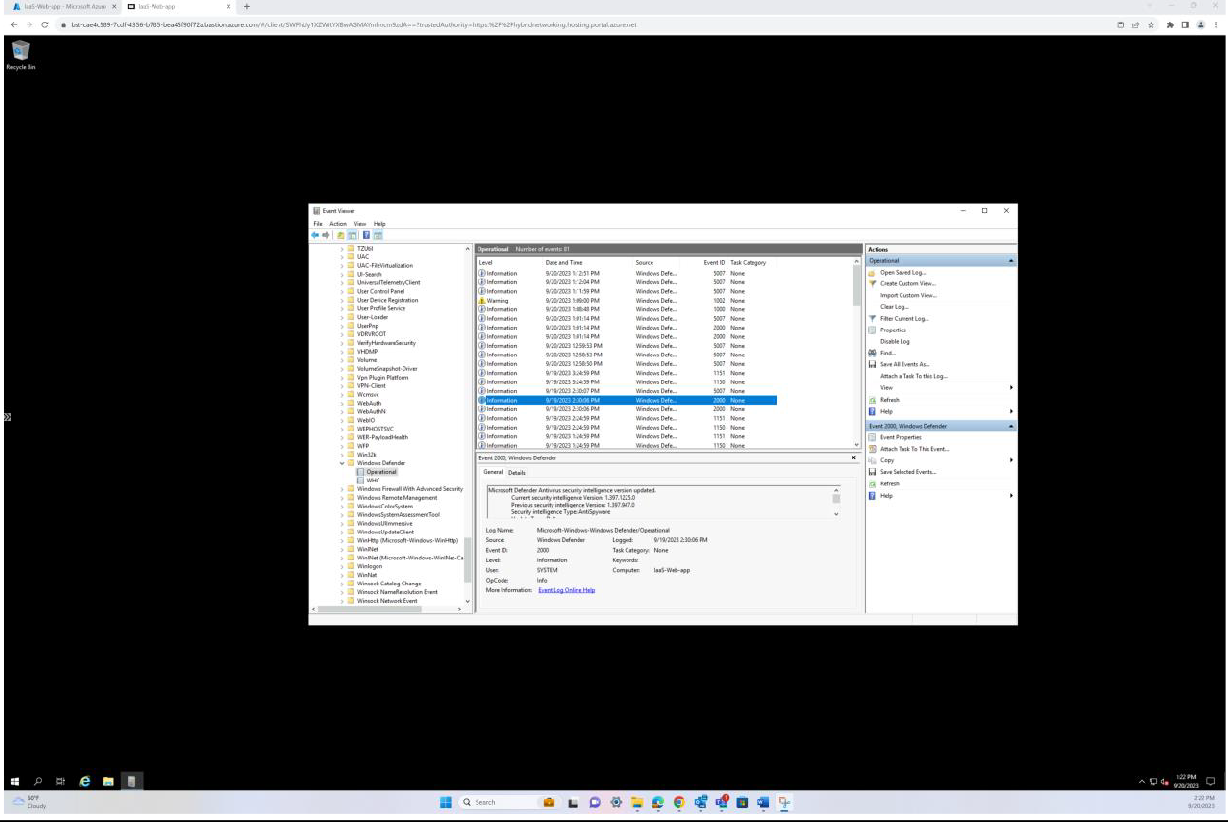
A captura de ecrã seguinte foi obtida a partir de um dispositivo Windows Server, que mostra que a versão de informações de segurança do Microsoft Defender Antimalware atualizou o registo a partir do visualizador de eventos do Windows. Isto demonstra as assinaturas mais recentes para o nome de anfitrião "IaaS-Web-app".
Esta captura de ecrã foi obtida a partir de um dispositivo Windows Server, que mostra as atualizações da Proteção Antimalware do Microsoft Defender. Isto mostra claramente as versões de definição de ameaças, a versão criada em e a última atualização para demonstrar que as definições de software maligno estão atualizadas para o nome de anfitrião "IaaS-Web- app".
Intenção: blocos antimalware.
O objetivo deste subponto é confirmar que o software antimalware está configurado para bloquear automaticamente software maligno após a deteção ou gerar alertas e mover software maligno detetado para uma área de quarentena segura. Isto pode garantir que são tomadas medidas imediatas quando uma ameaça é detetada, reduzindo a janela de vulnerabilidade e mantendo uma postura de segurança forte do sistema.
Diretrizes: blocos antimalware.
Forneça uma captura de ecrã para cada dispositivo no exemplo que suporte a utilização de antimalware. A captura de ecrã deve mostrar que o antimalware está em execução e está configurado para bloquear automaticamente software maligno, alerta ou para quarentena e alerta.
Exemplo de evidência: blocos antimalware.
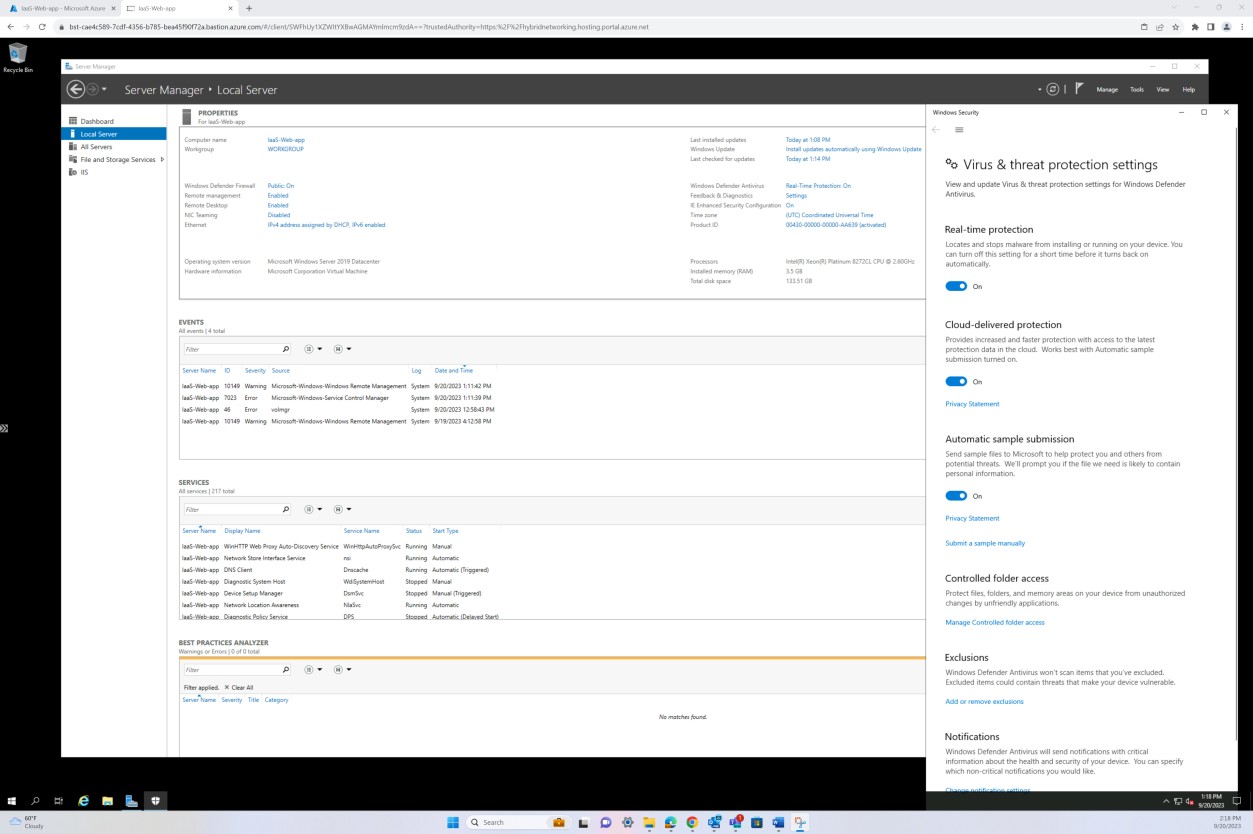
A captura de ecrã seguinte mostra que o anfitrião "IaaS-Web-app" está configurado com proteção em tempo real como ATIVADO para o Microsoft Defender Antimalware. Como diz a definição, esta ação localiza e impede que o software maligno seja instalado ou executado no dispositivo.
Intenção: EDR/NGAV
Este subponto tem como objetivo verificar se a Deteção e Resposta de Pontos Finais (EDR) ou o Antivírus de Próxima Geração (NGAV) estão a realizar ativamente análises periódicas em todos os componentes do sistema de amostra; os registos de auditoria são gerados para controlar atividades e resultados de análise; A solução de análise é continuamente atualizada e possui capacidades de auto-aprendizagem para se adaptar a novos cenários de ameaças.
Diretrizes: EDR/NGAV
Forneça uma captura de ecrã da sua solução EDR/NGAV a demonstrar que todos os agentes dos sistemas de exemplo estão a comunicar e a mostrar que o respetivo estado está ativo.
Exemplo de evidência: EDR/NGAV
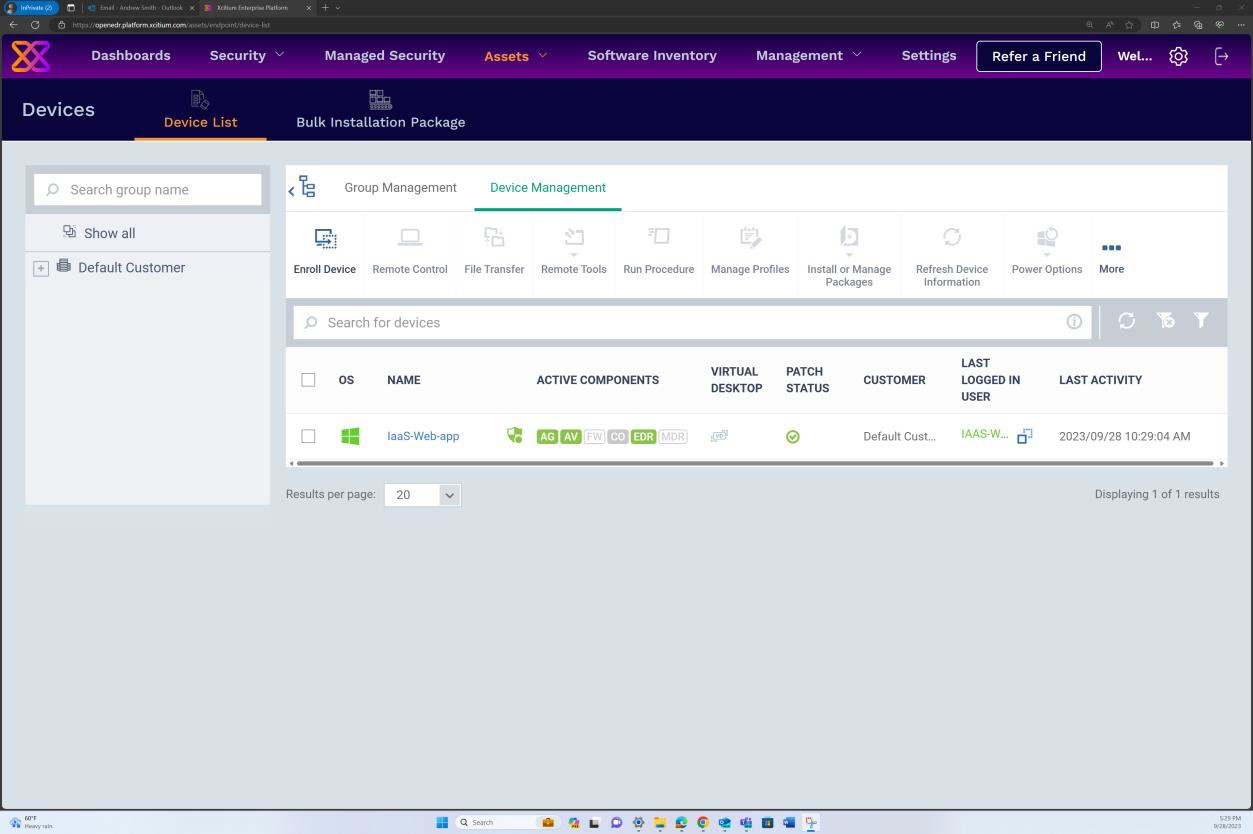
A captura de ecrã seguinte da solução OpenEDR mostra que um agente para o anfitrião "IaaS-Web-app" está ativo e a reportar.
A captura de ecrã seguinte da solução OpenEDR mostra que a análise em tempo real está ativada.
A captura de ecrã seguinte mostra que os alertas são gerados com base em métricas de comportamento que foram obtidas em tempo real a partir do agente instalado ao nível do sistema.
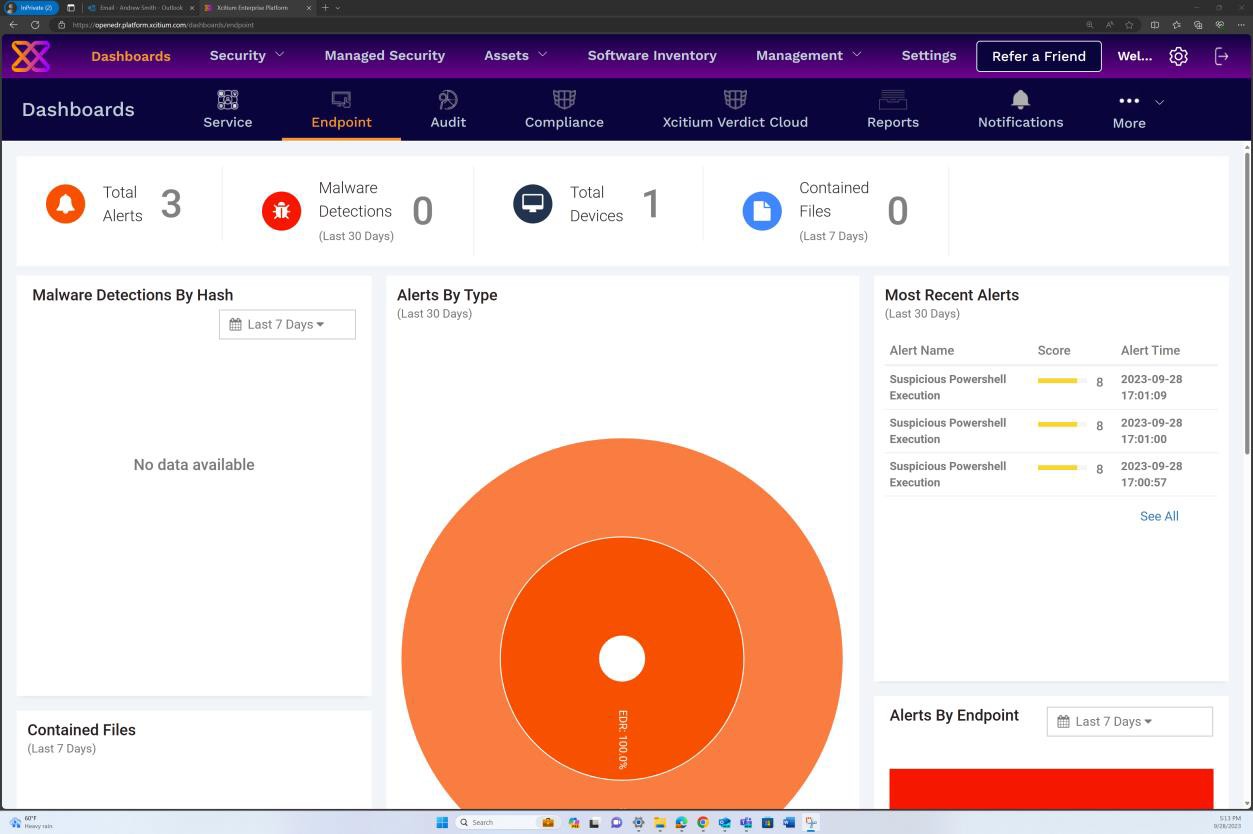
As capturas de ecrã seguintes da solução OpenEDR demonstram a configuração e geração de alertas e registos de auditoria. A segunda imagem mostra que a política está ativada e os eventos estão configurados.
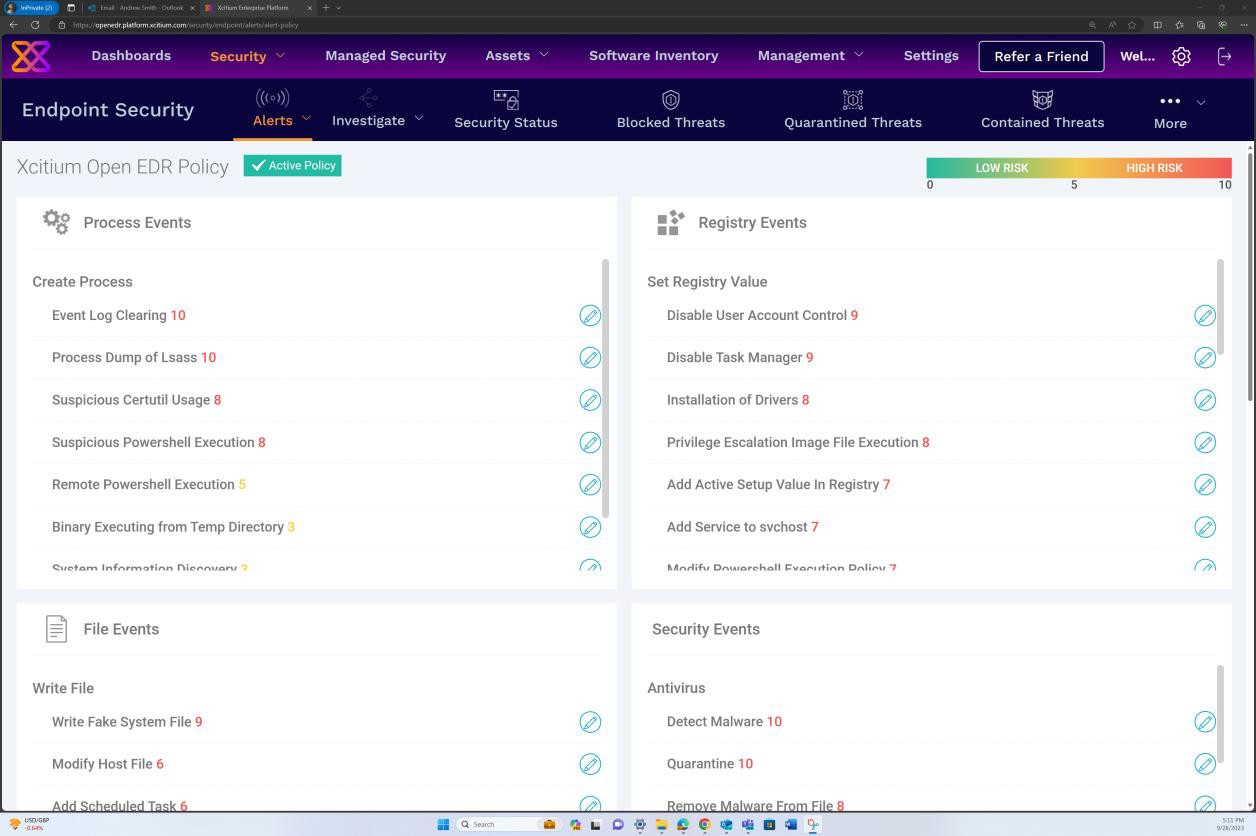
A captura de ecrã seguinte da solução OpenEDR demonstra que a solução é mantida atualizada continuamente.
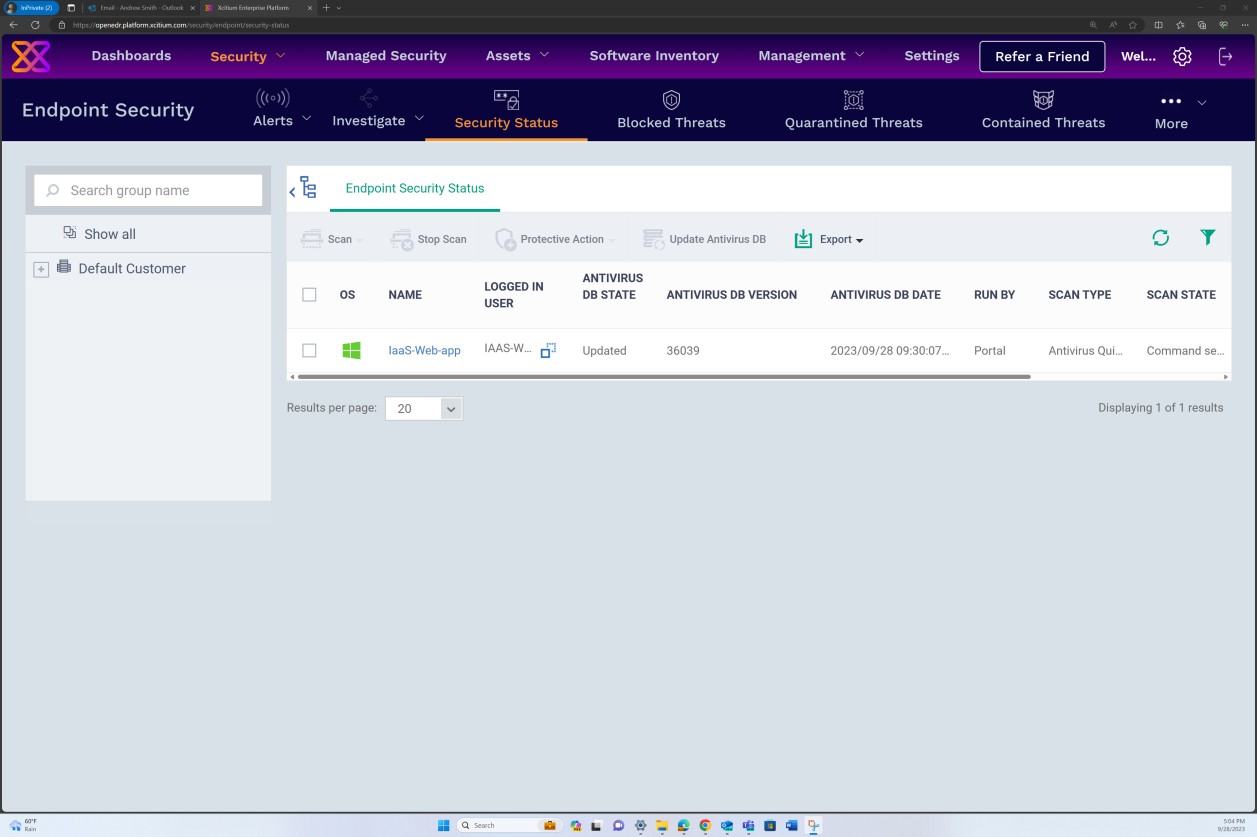
Intenção: EDR/NGAV
O foco deste subponto é garantir que o EDR/NGAV tem a capacidade de bloquear automaticamente software maligno conhecido e identificar e bloquear novas variantes de software maligno com base em comportamentos de macro. Também garante que a solução tem todas as capacidades de aprovação, permitindo que a organização permita software fidedigno enquanto bloqueia tudo o resto, adicionando assim uma camada adicional de segurança.
Diretrizes: EDR/NGAV
Consoante o tipo de solução utilizada, podem ser fornecidas provas que mostram as definições de configuração da solução e que a solução tem capacidades de Machine Learning/heurística, além de estar configurada para bloquear software maligno após a deteção. Se a configuração estiver implementada por predefinição na solução, esta tem de ser validada pela documentação do fornecedor.
Exemplo de evidência: EDR/NGAV
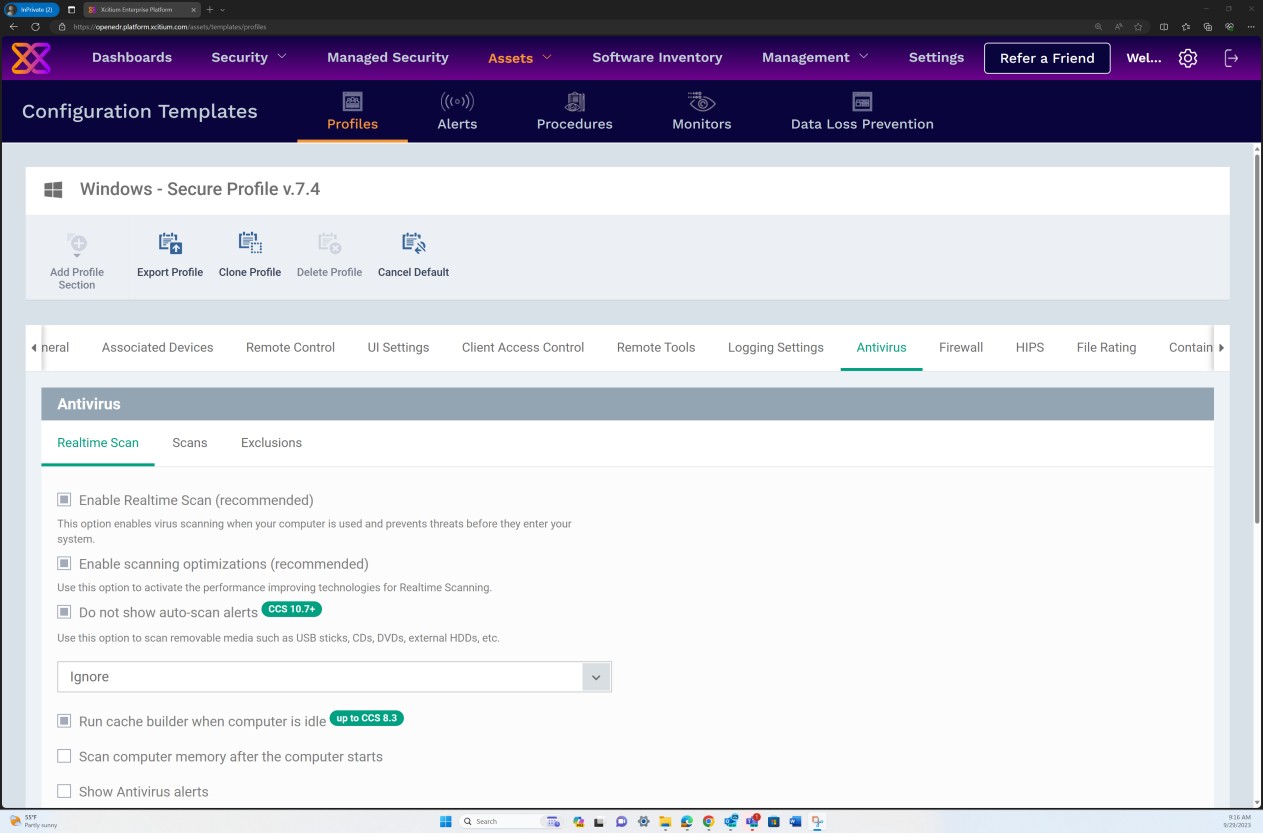
As capturas de ecrã seguintes da solução OpenEDR demonstram que um Perfil Seguro v7.4 está configurado para impor a análise em tempo real, bloquear software maligno e quarentena.
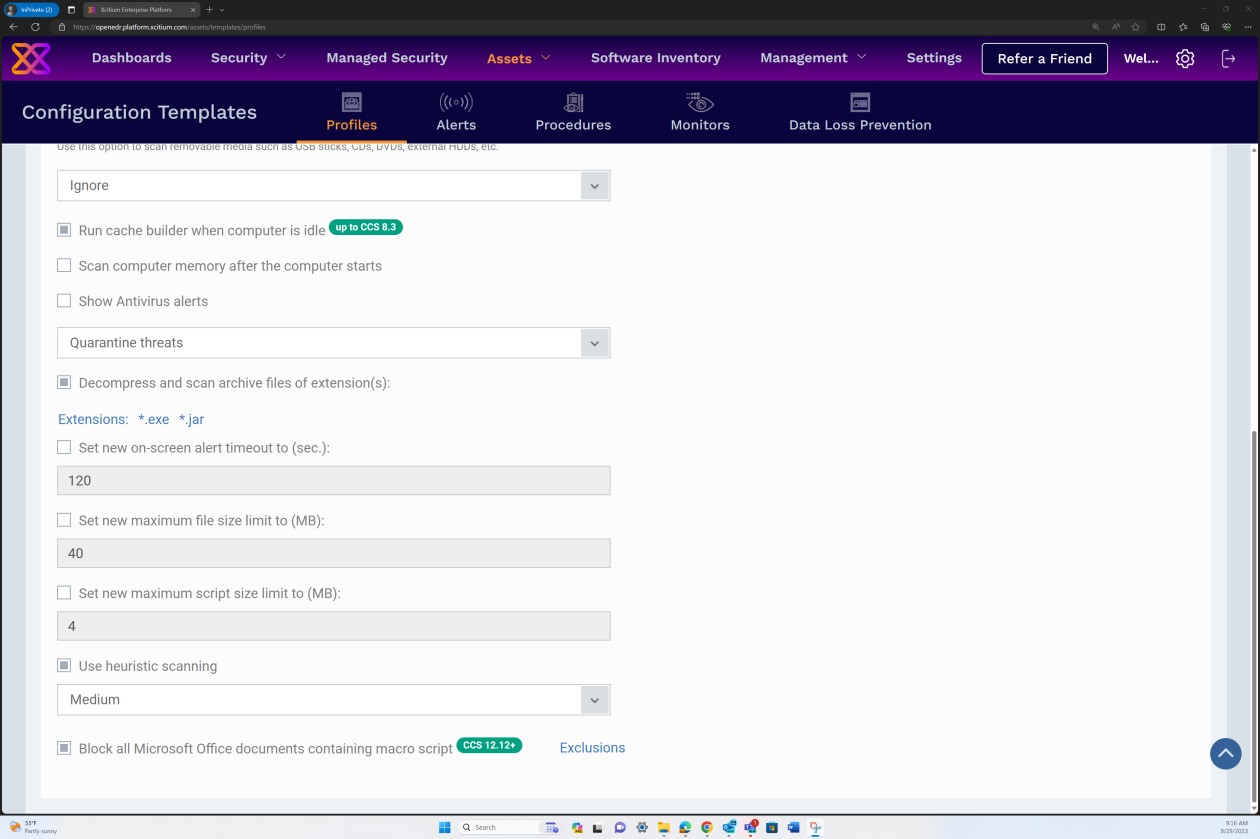
As capturas de ecrã seguintes da configuração do Perfil Seguro v7.4 demonstram que a solução implementa a análise "Em tempo real" com base numa abordagem antimalware mais tradicional, que procura assinaturas de software maligno conhecidas e a análise "Heurística" definida para um nível médio. A solução deteta e remove software maligno ao verificar os ficheiros e o código que se comportam de forma suspeita/inesperada ou maliciosa.
O scanner está configurado para descomprimir arquivos e analisar os ficheiros no interior para detetar potenciais softwares malignos que possam estar a mascarar-se no arquivo. Além disso, o scanner está configurado para bloquear micro scripts nos ficheiros do Microsoft Office.
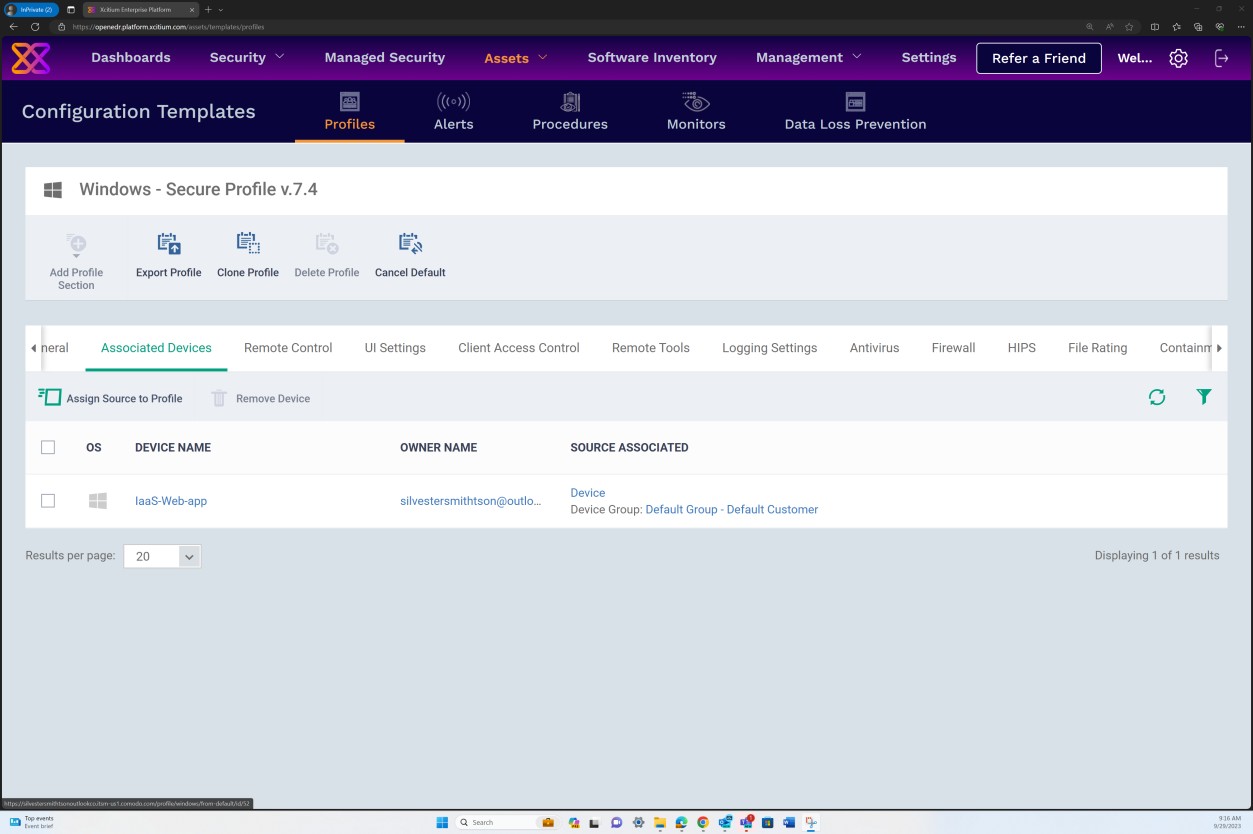
As capturas de ecrã seguintes demonstram que o Perfil Seguro v.7.4 foi atribuído ao nosso anfitrião "IaaS-Web-app" do dispositivo Windows Server.
A captura de ecrã seguinte foi tirada do dispositivo Windows Server "IaaS-Web-app", que demonstrou que o agente OpenEDR está ativado e em execução no anfitrião.
Proteção contra software maligno/controlo de aplicações
O controlo de aplicações é uma prática de segurança que bloqueia ou restringe a execução de aplicações não autorizadas de formas que colocam os dados em risco. Os controlos de aplicações são uma parte importante de um programa de segurança empresarial e podem ajudar a impedir que atores maliciosos explorem vulnerabilidades de aplicações e reduzam o risco de uma falha de segurança. Ao implementar o controlo de aplicações, as empresas e as organizações podem reduzir consideravelmente os riscos e ameaças associados à utilização da aplicação, uma vez que as aplicações são impedidas de serem executadas se colocarem em risco a rede ou os dados confidenciais. Os controlos de aplicações fornecem às equipas de operações e segurança uma abordagem fiável, padronizada e sistemática para mitigar o risco cibernético. Também dão às organizações uma imagem mais completa das aplicações no seu ambiente, o que pode ajudar as organizações de TI e segurança a gerir eficazmente o risco cibernético.
Controlo N.º 3
Forneça provas que demonstrem que:
Tem uma lista aprovada de software/aplicações com justificação comercial:
existe e é mantido atualizado, e
que cada aplicação é submetida a um processo de aprovação e aprovação antes da respetiva implementação.
Essa tecnologia de controlo de aplicações está ativa, ativada e configurada em todos os componentes do sistema de exemplo, conforme documentado.
Intenção: lista de software
Este subponto visa garantir que existe uma lista aprovada de software e aplicações na organização e é continuamente mantido atualizado. Certifique-se de que cada software ou aplicação na lista tem uma justificação comercial documentada para validar a respetiva necessidade. Esta lista serve como uma referência autoritativa para regular a implementação de software e aplicações, ajudando assim na eliminação de software não autorizado ou redundante que pode representar um risco de segurança.
Diretrizes: lista de software
Um documento que contém a lista aprovada de software e aplicações, se mantido como um documento digital (Word, PDF, etc.). Se a lista aprovada de software e aplicações for mantida através de uma plataforma, as capturas de ecrã da lista da plataforma têm de ser fornecidas.
Exemplo de evidência: lista de software
As capturas de ecrã seguintes demonstram que uma lista de aplicações e software aprovados é mantida na plataforma Confluence Cloud.
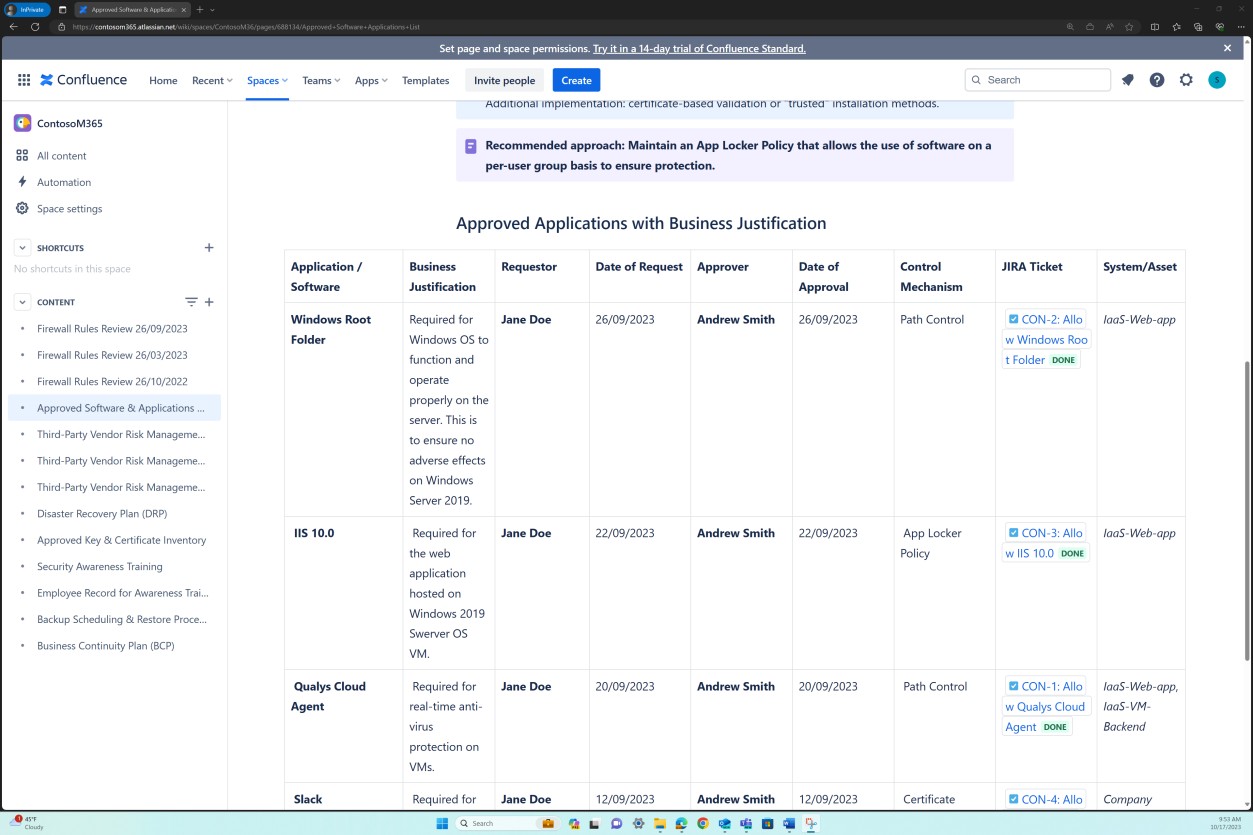
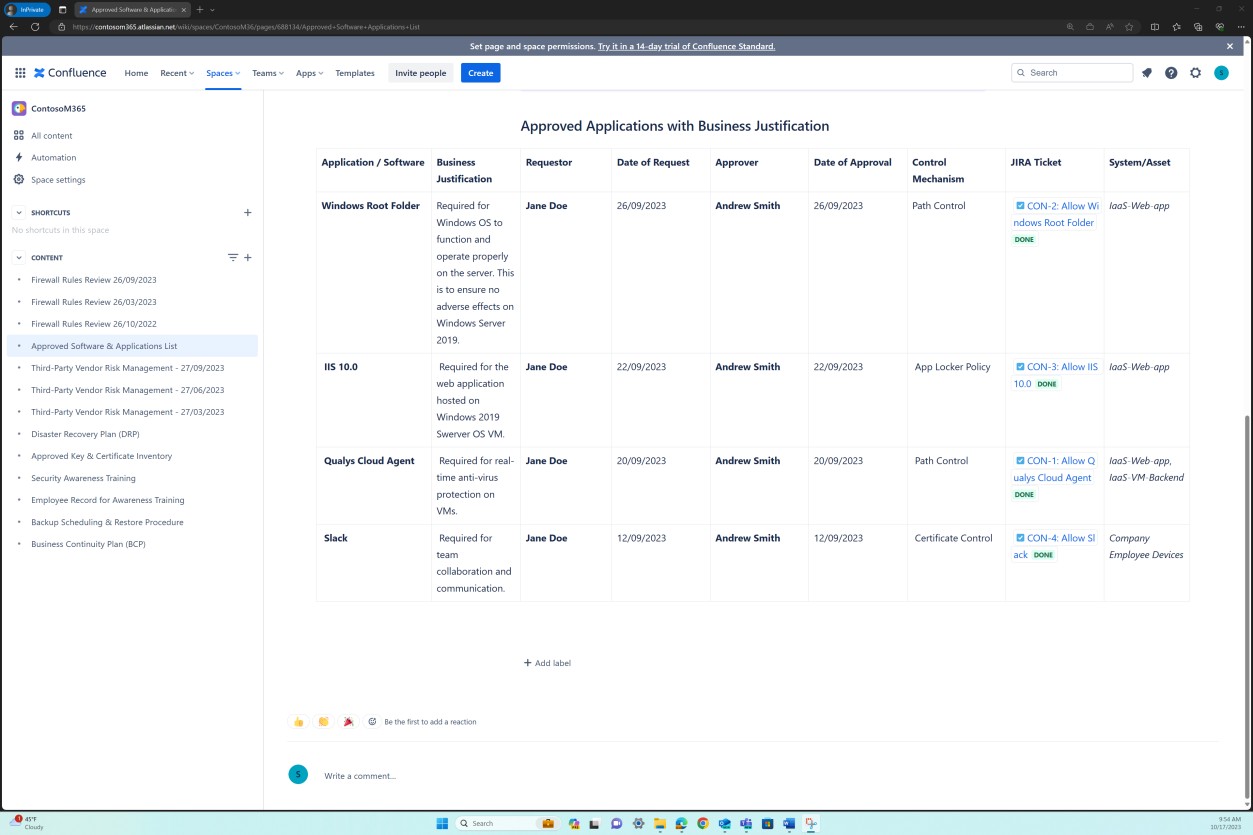
As capturas de ecrã seguintes demonstram que a lista de aplicações e software aprovados, incluindo o requerente, a data do pedido, o aprovador, a data de aprovação, o mecanismo de controlo, o pedido JIRA, o sistema/recurso é mantida.
Intenção: aprovação de software
O objetivo deste subponto é confirmar que cada software/aplicação é submetido a um processo de aprovação formal antes da sua implementação na organização. O processo de aprovação deve incluir uma avaliação técnica e uma aprovação executiva, garantindo que as perspetivas operacionais e estratégicas foram consideradas. Ao instituir este processo rigoroso, a organização garante que apenas o software verificado e necessário é implementado, minimizando assim as vulnerabilidades de segurança e garantindo o alinhamento com os objetivos empresariais.
Diretrizes
Podem ser fornecidas provas que mostram que o processo de aprovação está a ser seguido. Isto pode ser fornecido através de documentos assinados, controlo dentro dos sistemas de controlo de alterações ou utilização de algo como o Azure DevOps/JIRA para controlar os pedidos de alteração e a autorização.
Exemplo de provas
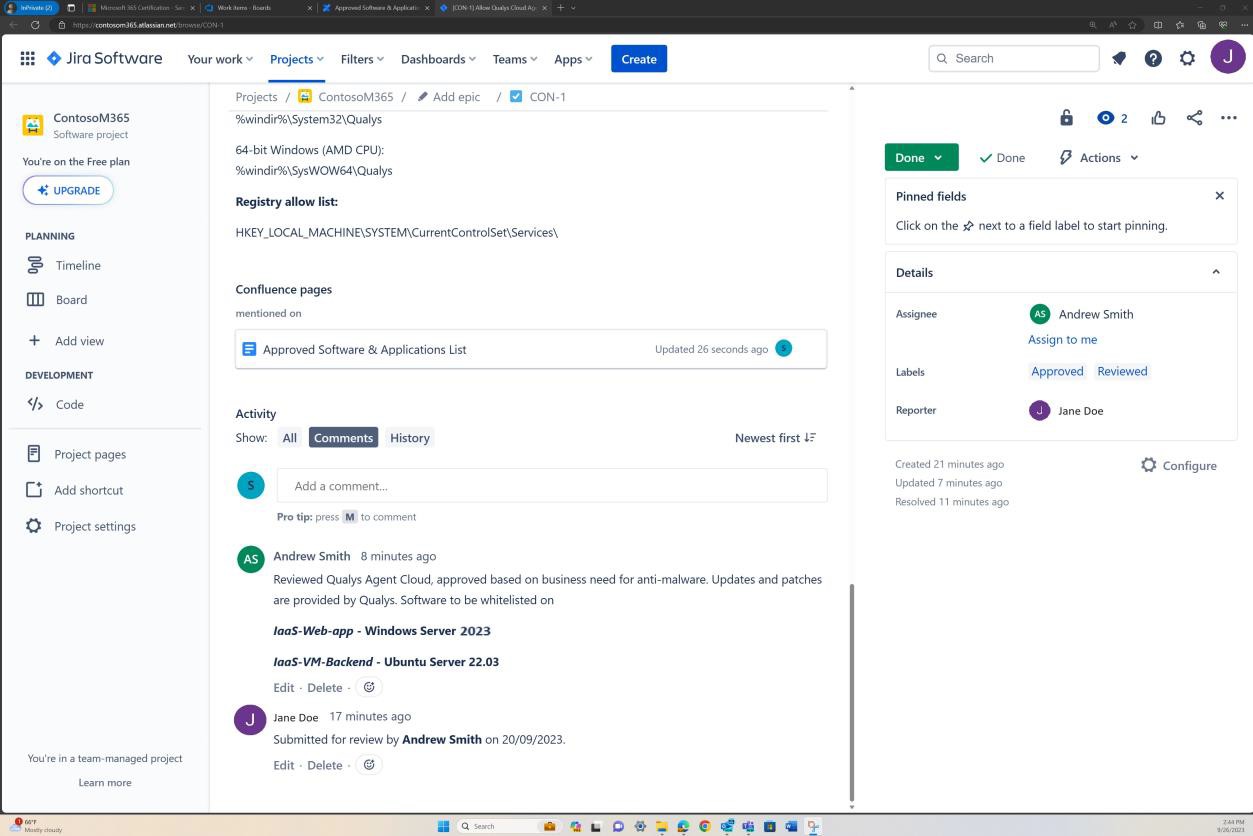
As capturas de ecrã seguintes demonstram um processo de aprovação completo no Software JIRA. Um utilizador "Jane Doe" emitiu um pedido para que "Permitir que o Qualys Cloud Agent" seja instalado nos servidores "IaaS-Web-app" e "IaaS-VM- Backend". 'Andrew Smith' reviu o pedido e aprovou-o com o comentário "aprovado com base na necessidade empresarial de antimalware. Atualizações e patches fornecidos pela Qualys. Software a ser aprovado.
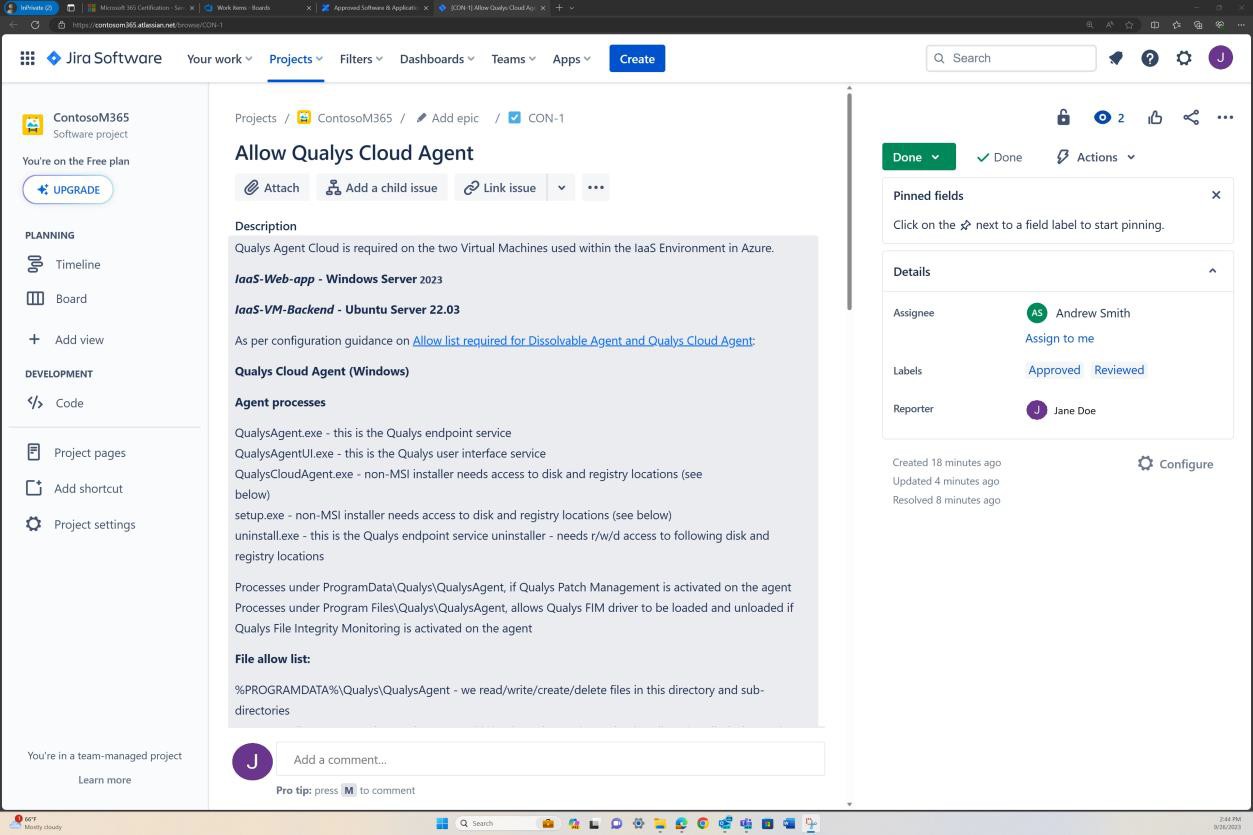
A captura de ecrã seguinte mostra a aprovação a ser concedida através do pedido de suporte gerado na plataforma Confluence antes de permitir que a aplicação seja executada no servidor de produção.
Intenção: tecnologia de controlo de aplicações
Este subponto concentra-se em verificar se a tecnologia de controlo de aplicações está ativa, ativada e configurada corretamente em todos os componentes do sistema de exemplo. Certifique-se de que a tecnologia funciona de acordo com as políticas e procedimentos documentados, que servem de diretrizes para a sua implementação e manutenção. Ao ter uma tecnologia de controlo de aplicações ativada, ativada e bem configurada, a organização pode ajudar a impedir a execução de software não autorizado ou malicioso e melhorar a postura de segurança geral do sistema.
Diretrizes: tecnologia de controlo de aplicações
Forneça documentação que detalha como o controlo de aplicações foi configurado e provas da tecnologia aplicável que mostram como cada aplicação/processo foi configurado.
Exemplo de evidência: tecnologia de controlo de aplicações
As capturas de ecrã seguintes demonstram que as Políticas de Grupo do Windows (GPO) estão configuradas para impor apenas software e aplicações aprovados.
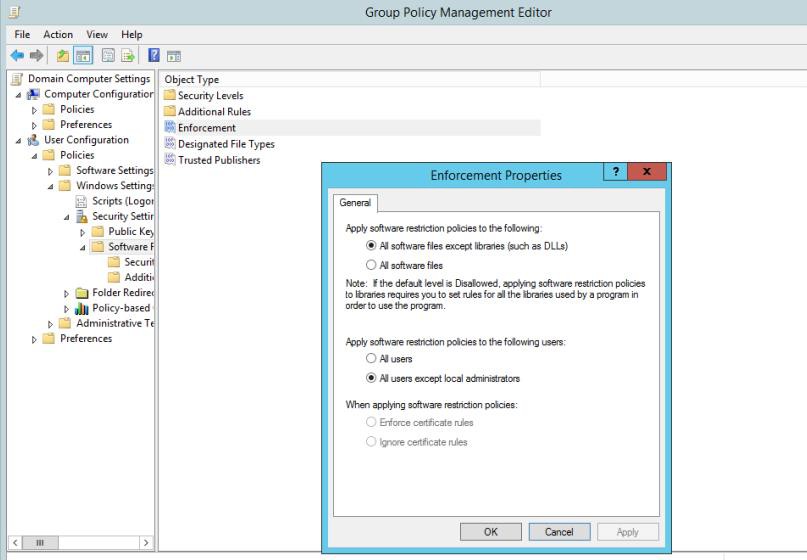
A captura de ecrã seguinte mostra o software/aplicações autorizados a ser executados através do controlo de caminho.
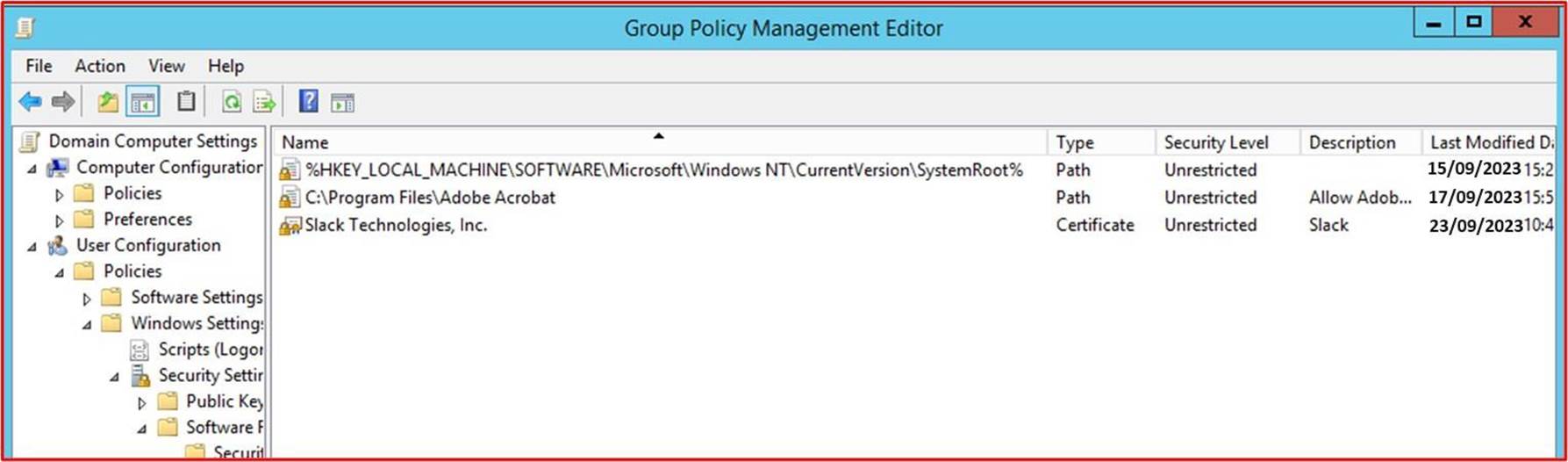
Nota: nestes exemplos, não foram utilizadas capturas de ecrã completas. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã inteiro que mostrem qualquer URL, utilizador com sessão iniciada e a hora e data do sistema.
Gestão de patches/aplicação de patches e classificação de risco
A gestão de patches, muitas vezes referida como aplicação de patches, é um componente crítico de qualquer estratégia de cibersegurança robusta. Envolve o processo sistemático de identificação, teste e aplicação de patches ou atualizações a software, sistemas operativos e aplicações. O principal objetivo da gestão de patches é mitigar vulnerabilidades de segurança, garantindo que os sistemas e o software permanecem resilientes contra potenciais ameaças. Além disso, a gestão de patches engloba a classificação de risco de um elemento vital na atribuição de prioridades a patches. Isto envolve avaliar vulnerabilidades com base na sua gravidade e impacto potencial na postura de segurança de uma organização. Ao atribuir classificações de risco a vulnerabilidades, as organizações podem alocar recursos de forma eficiente, concentrando os seus esforços na resolução rápida de vulnerabilidades críticas e de alto risco, mantendo uma posição proativa contra ameaças emergentes. Uma estratégia eficaz de gestão de patches e classificação de riscos não só melhora a segurança, como também contribui para a estabilidade e desempenho gerais da infraestrutura de TI, ajudando as organizações a manterem-se resilientes no cenário em constante evolução das ameaças de cibersegurança.
Para manter um ambiente operativo seguro, as aplicações/suplementos e os sistemas de suporte têm de ser corrigidos adequadamente. Um período de tempo adequado entre a identificação (ou o lançamento público) e a aplicação de patches tem de ser gerido para reduzir a janela de oportunidade para que uma vulnerabilidade seja explorada por um ator de ameaças. A Certificação do Microsoft 365 não estipula uma "Janela de Aplicação de Patches"; No entanto, os analistas de certificação irão rejeitar intervalos de tempo que não sejam razoáveis ou em conformidade com as melhores práticas da indústria. Este grupo de controlo de segurança também está no âmbito dos ambientes de alojamento PaaS (Plataforma como Serviço), uma vez que as bibliotecas de software de terceiros e a base de código de terceiros do suplemento têm de ser corrigidas com base na classificação de risco.
Controlo N.º 4
Forneça provas de que a política de gestão de patches e a documentação do procedimento definem todas as seguintes opções:
Uma janela de aplicação de patches mínima adequada para vulnerabilidades de risco crítico/alto e médio.
Desativação de sistemas operativos e software não suportados.
Como as novas vulnerabilidades de segurança são identificadas e atribuídas uma classificação de risco.
Intenção: gestão de patches
A gestão de patches é necessária por muitas arquiteturas de conformidade de segurança, ou seja, PCI-DSS, ISO 27001, NIST (SP) 800-53, FedRAMP e SOC 2. A importância de uma boa gestão de patches não pode ser excessivamente stressada
uma vez que pode corrigir problemas de segurança e funcionalidade no software, firmware e mitigar vulnerabilidades, o que ajuda na redução de oportunidades de exploração. A intenção deste controlo é minimizar a janela de oportunidade que um ator de ameaças tem para explorar vulnerabilidades que podem existir no ambiente de âmbito.
Forneça uma política de gestão de patches e documentação de procedimentos que abrange de forma abrangente os seguintes aspetos:
Uma janela de aplicação de patches mínima adequada para vulnerabilidades de risco crítico/alto e médio.
A documentação de política e procedimento de gestão de patches da organização tem de definir claramente uma janela de aplicação de patches mínima adequada para vulnerabilidades categorizadas como riscos críticos/elevados e médios. Esta aprovisionamento estabelece o tempo máximo permitido no qual os patches têm de ser aplicados após a identificação de uma vulnerabilidade, com base no seu nível de risco. Ao indicar explicitamente estes períodos de tempo, a organização uniformizou a sua abordagem à gestão de patches, minimizando o risco associado a vulnerabilidades não corrigidas.
Desativação de sistemas operativos e software não suportados.
A política de gestão de patches inclui disposições para a desativação de sistemas operativos e software não suportados. Os sistemas operativos e software que já não recebem atualizações de segurança representam um risco significativo para a postura de segurança de uma organização. Por conseguinte, este controlo garante que esses sistemas são identificados e removidos ou substituídos em tempo útil, conforme definido na documentação da política.
- Um procedimento documentado que descreve como as novas vulnerabilidades de segurança são identificadas e atribuídas uma classificação de risco.
A aplicação de patches tem de ser baseada no risco, quanto mais arriscada for a vulnerabilidade, mais rápida será a sua remediação. A classificação de risco de vulnerabilidades identificadas é parte integrante deste processo. A intenção deste controlo é garantir que existe um processo documentado de classificação de riscos que está a ser seguido para garantir que todas as vulnerabilidades identificadas são devidamente classificadas com base no risco. Normalmente, as organizações utilizam a classificação do Sistema de Classificação de Vulnerabilidades (CVSS) comum fornecida por fornecedores ou investigadores de segurança. Recomenda-se que, se as organizações dependerem do CVSS, seja incluído um mecanismo de nova classificação no processo para permitir que a organização altere a classificação com base numa avaliação de risco interna. Por vezes, a vulnerabilidade pode não ser aplicável devido à forma como a aplicação foi implementada no ambiente. Por exemplo, pode ser lançada uma vulnerabilidade Java que afeta uma biblioteca específica que não é utilizada pela organização.
Nota: mesmo que esteja a executar num ambiente "PaaS/Sem Servidor" de Plataforma como Serviço, continua a ter a responsabilidade de identificar vulnerabilidades na base de código: ou seja, bibliotecas de terceiros.
Diretrizes: gestão de patches
Indique o documento da política. Têm de ser fornecidas provas administrativas, como documentação de políticas e procedimentos que detalham os processos definidos da organização que abrangem todos os elementos do controlo especificado.
Nota: essa evidência lógica pode ser fornecida como prova de apoio que fornecerá mais informações sobre o Programa de Gestão de Vulnerabilidades (VMP) da sua organização, mas não cumprirá este controlo por si só.
Exemplo de evidência: gestão de patches
A captura de ecrã seguinte mostra um fragmento de uma política de gestão de patches/classificação de risco, bem como os diferentes níveis de categorias de risco. Segue-se a classificação e os intervalos de tempo de remediação. Nota: a expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.


Exemplo de (Opcional) Provas Técnicas Adicionais que suportam o Documento de Política
Provas lógicas, como folhas de cálculo de controlo de vulnerabilidades, relatórios de avaliação técnica de vulnerabilidades ou capturas de ecrã dos pedidos de suporte gerados através de plataformas de gestão online para controlar o estado e o progresso das vulnerabilidades utilizadas para suportar a implementação do processo descrito na documentação da política a fornecer. A captura de ecrã seguinte demonstrou que o Snyk, que é uma ferramenta de Análise de Composição de Software (SCA), é utilizado para analisar a base de código quanto a vulnerabilidades. Segue-se uma notificação por e-mail.
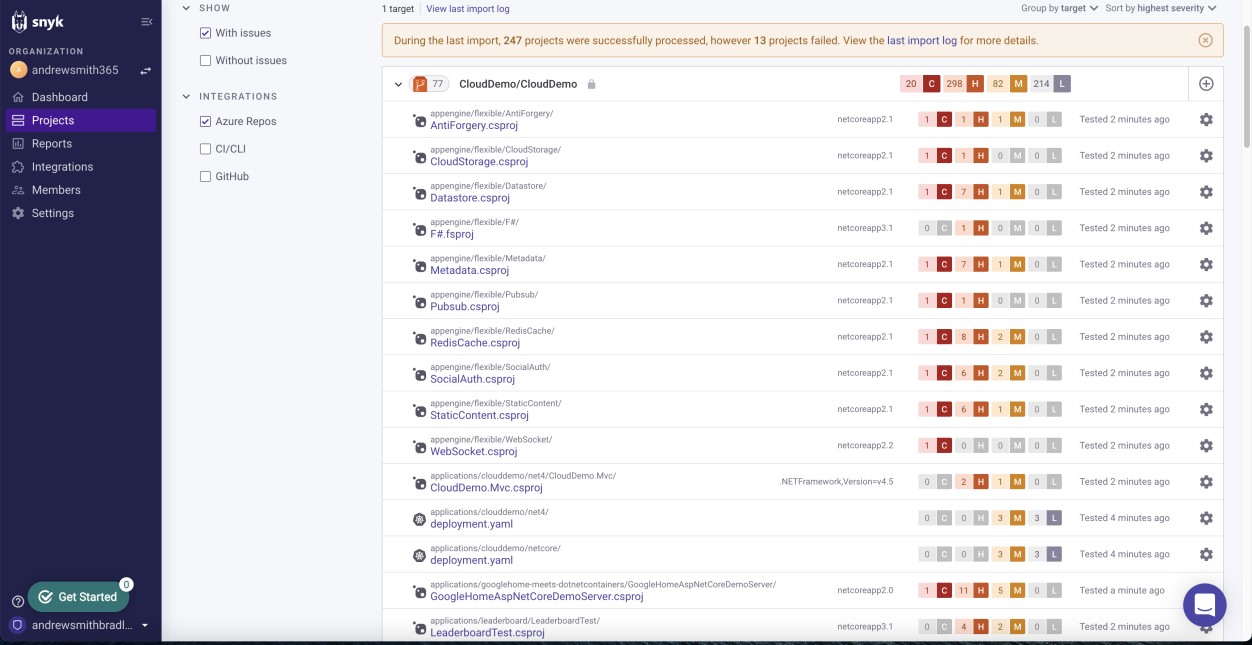
Nota: neste exemplo, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã de provas submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem qualquer URL, utilizador com sessão iniciada e a hora e data do sistema.
As duas capturas de ecrã seguintes mostram um exemplo da notificação por e-mail recebida quando novas vulnerabilidades são sinalizadas pelo Snyk. Podemos ver que o e-mail contém o projeto afetado e o utilizador atribuído para receber os alertas.
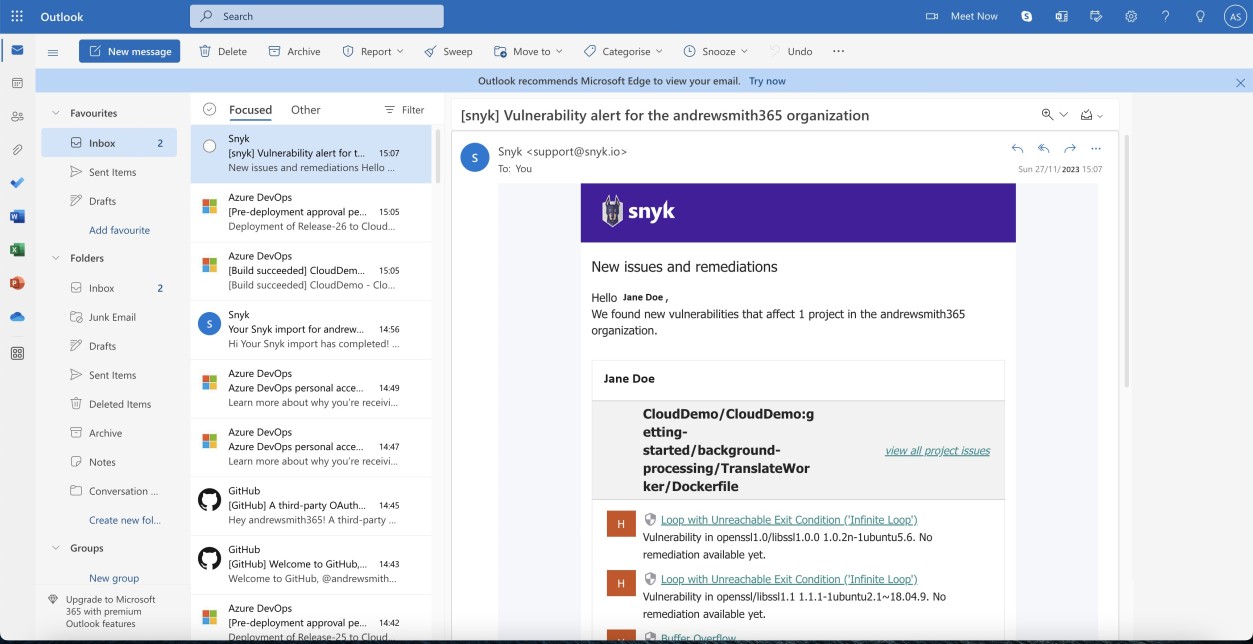
A captura de ecrã seguinte mostra as vulnerabilidades identificadas.
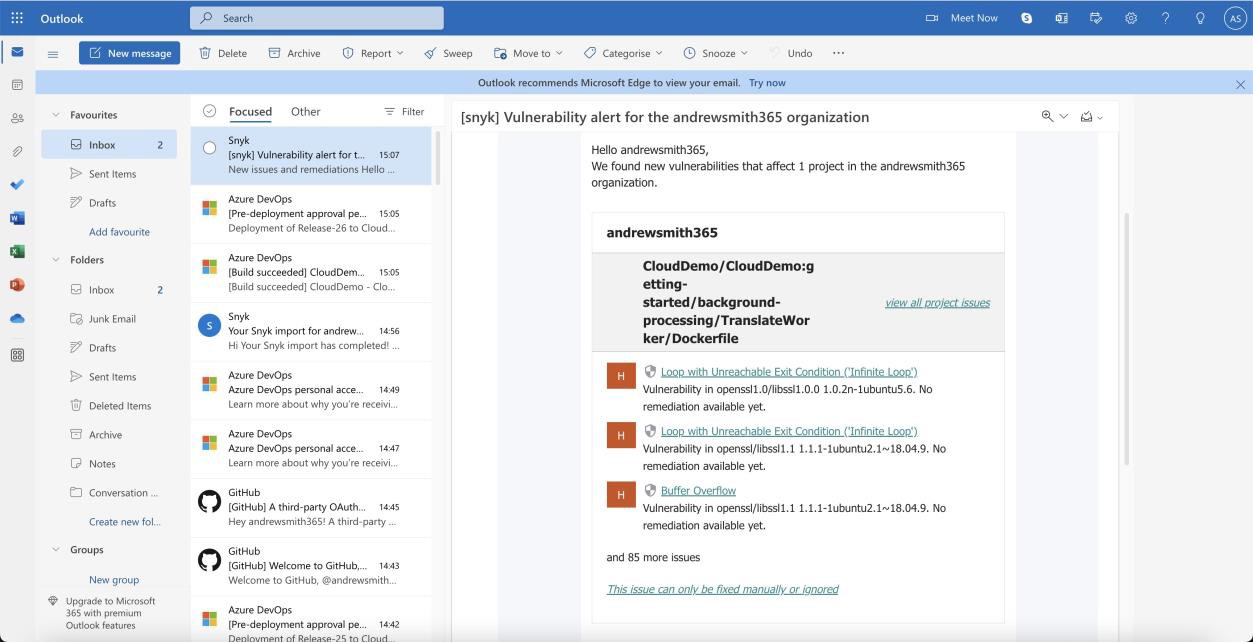
Nota: nos exemplos anteriores, não foram utilizadas capturas de ecrã completas. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas a mostrar o URL, qualquer data e hora do utilizador e do sistema com sessão iniciada.
Exemplo de provas
As capturas de ecrã seguintes mostram as ferramentas de segurança do GitHub configuradas e ativadas para procurar vulnerabilidades na base de código e os alertas são enviados por e-mail.
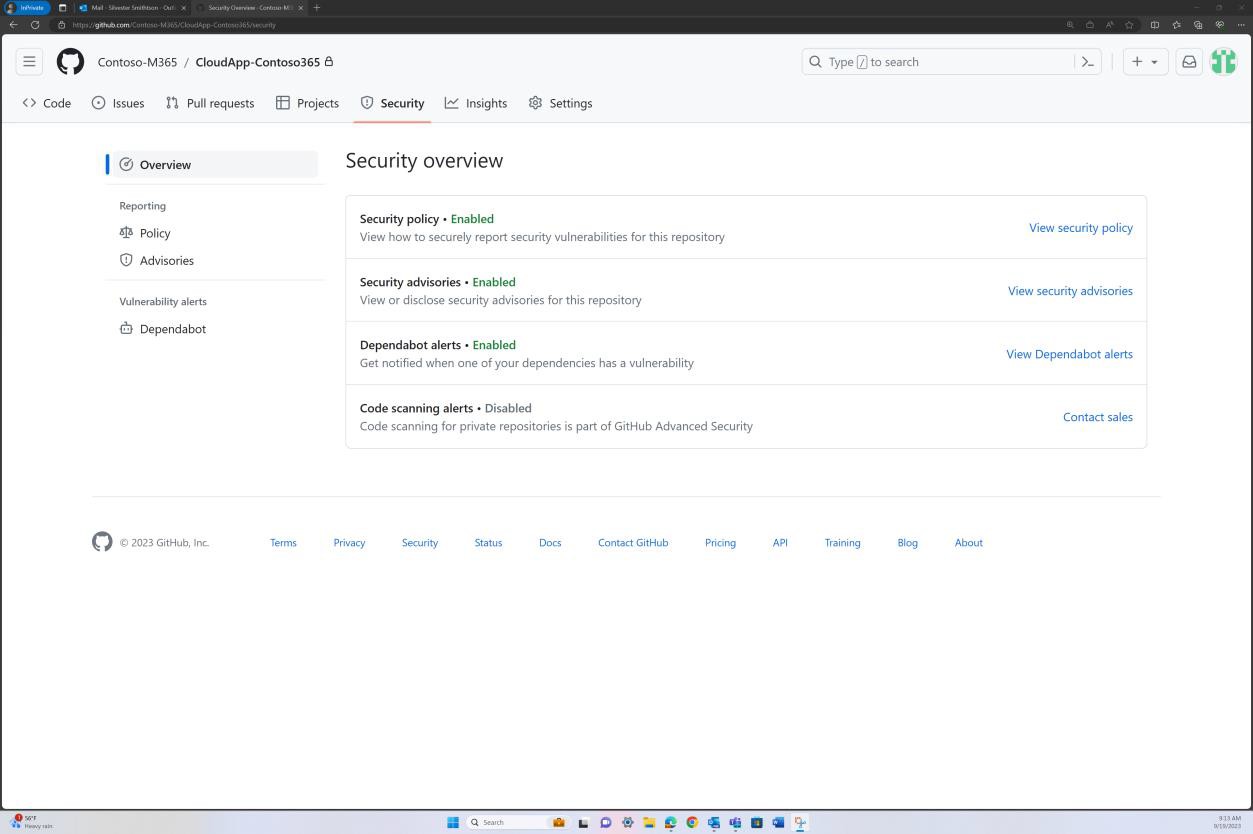
A notificação por e-mail apresentada a seguir é uma confirmação de que os problemas sinalizados serão resolvidos automaticamente através de um pedido Pull.
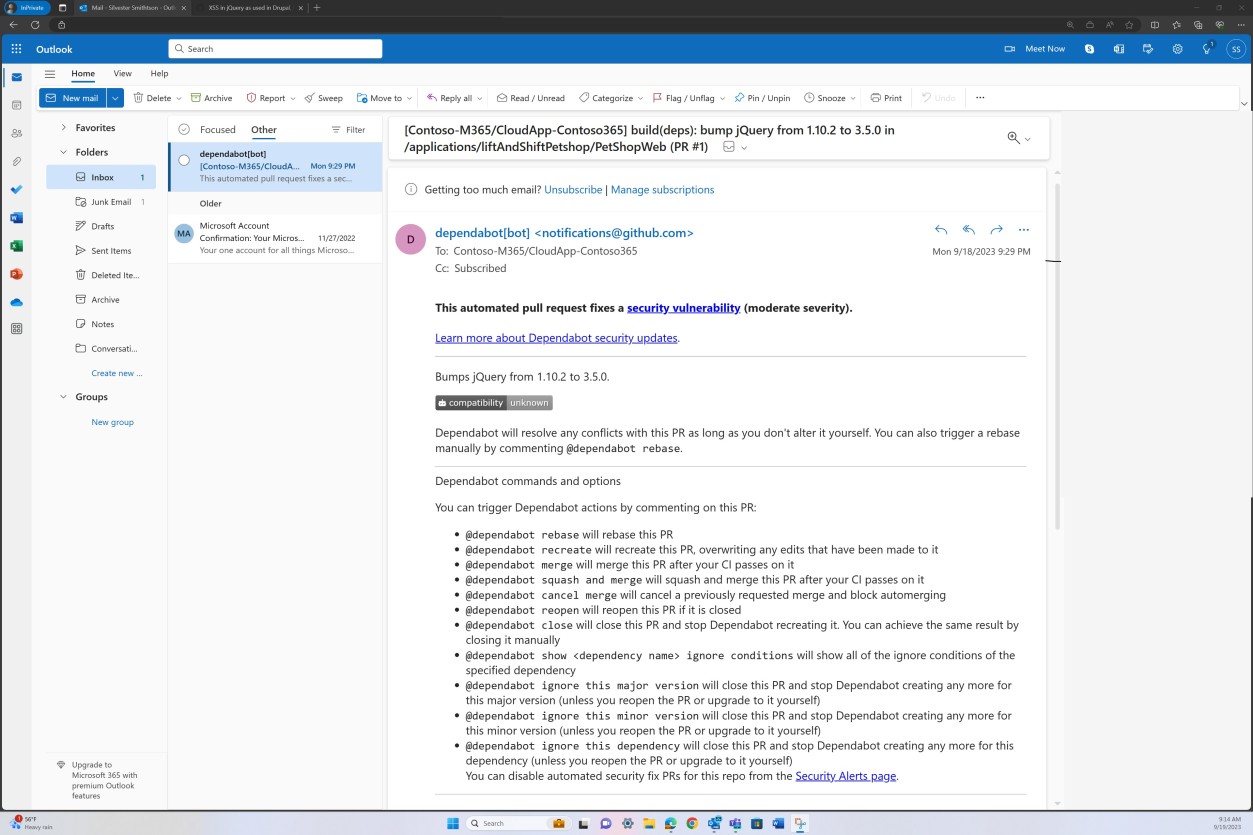
Exemplo de provas
A captura de ecrã seguinte mostra a avaliação técnica interna e a classificação de vulnerabilidades através de uma folha de cálculo.
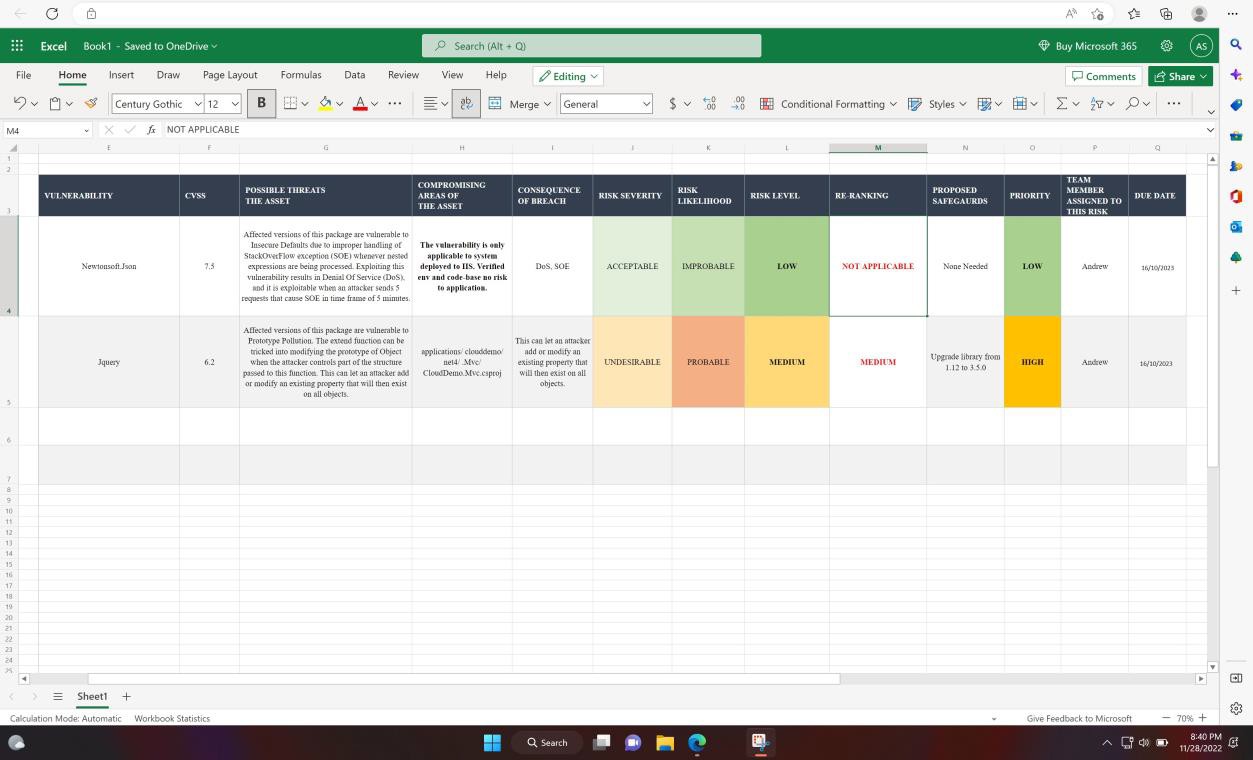
Exemplo de provas
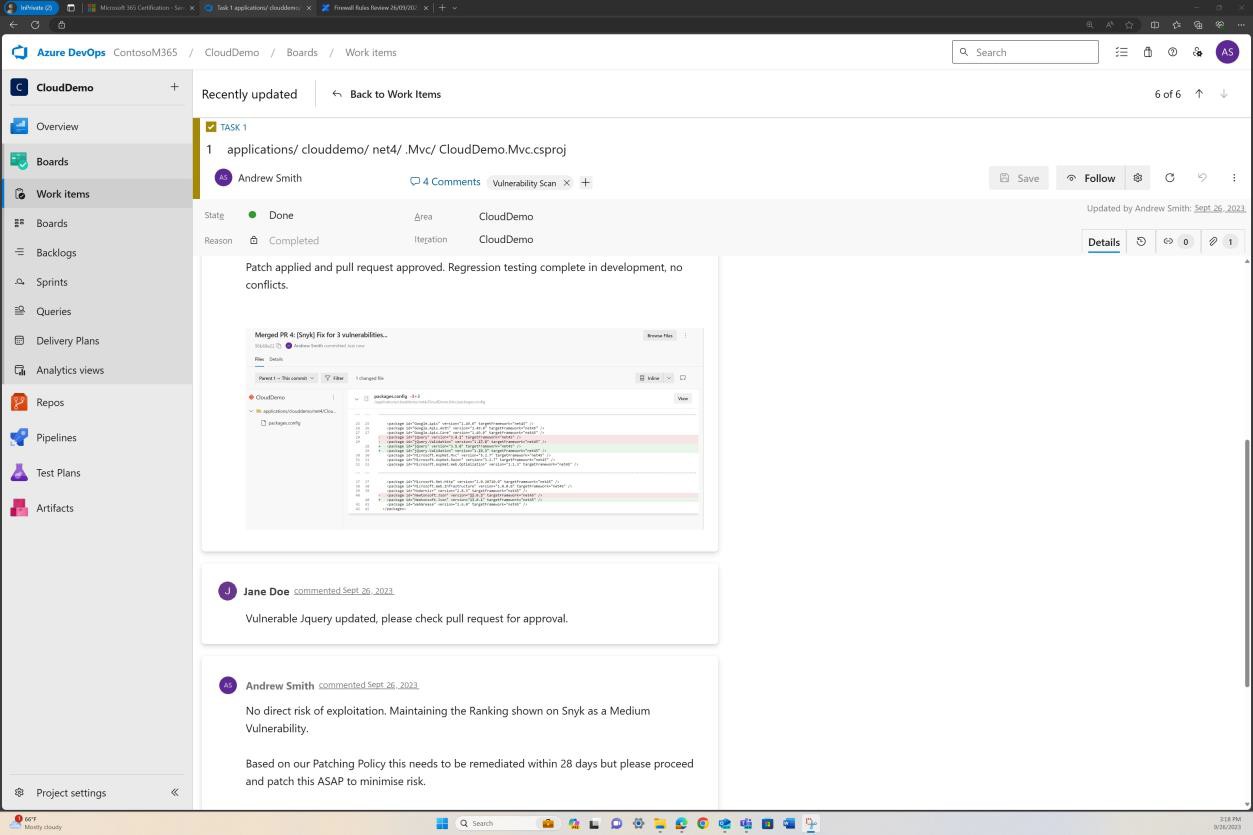
As capturas de ecrã seguintes mostram os pedidos de suporte gerados no DevOps para cada vulnerabilidade detetada.
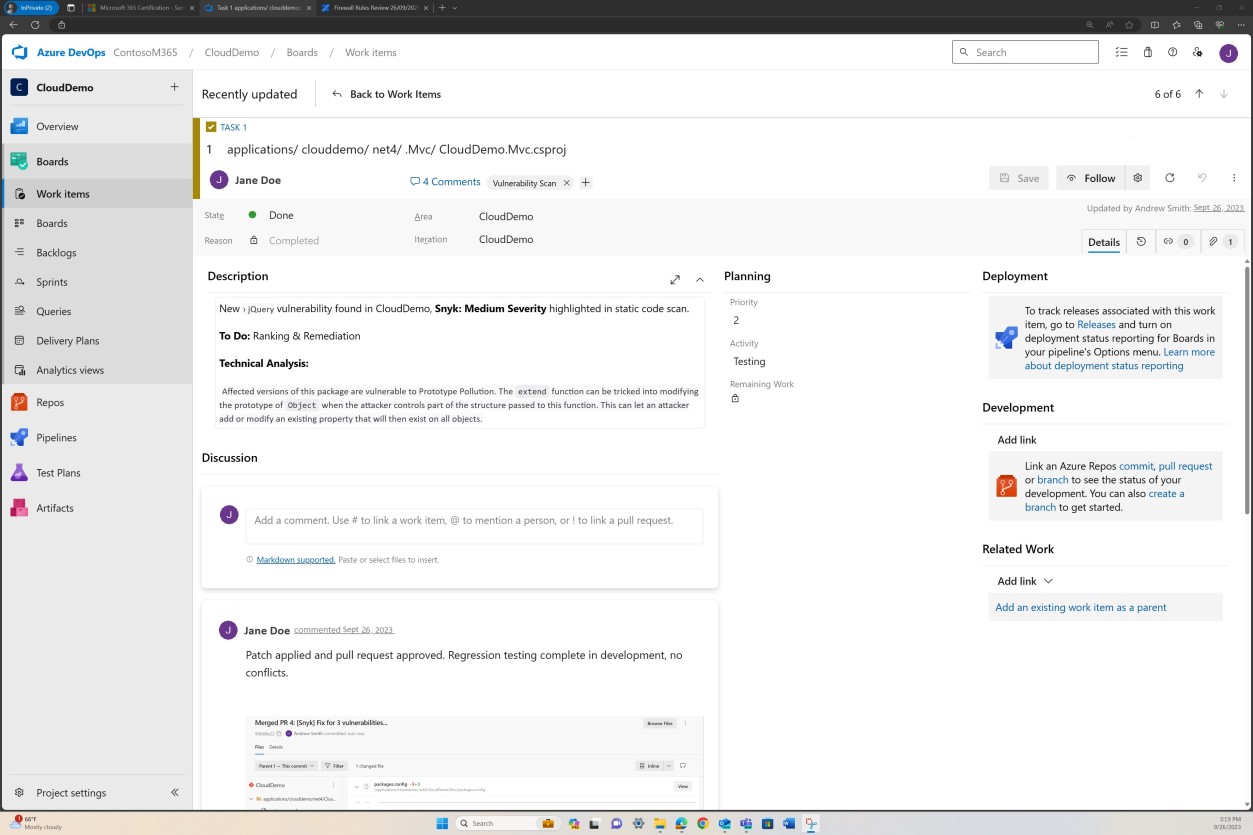
A avaliação, classificação e revisão por um colaborador separado ocorre antes de implementar as alterações.
Controlo N.º 5
Forneça provas de que:
Todos os componentes de sistema de exemplo estão a ser corrigidos.
Forneça provas de que os sistemas operativos não suportados e os componentes de software não estão a ser utilizados.
Intenção: componentes do sistema de exemplo
Este subponto visa garantir que são fornecidas provas verificáveis para confirmar que todos os componentes de sistema de amostra na organização estão a ser corrigidos ativamente. As provas podem incluir, mas não se limita a, registos de gestão de patches, relatórios de auditoria do sistema ou procedimentos documentados que mostram que foram aplicados patches. Quando a tecnologia sem servidor ou a Plataforma como Um Serviço (PaaS) é utilizada, esta ação deve ser expandida para incluir a base de código para confirmar que as versões mais recentes e seguras de bibliotecas e dependências estão a ser utilizadas.
Diretrizes: componentes do sistema de exemplo
Forneça uma captura de ecrã para cada dispositivo no exemplo e componentes de software de suporte que mostram que os patches estão instalados em conformidade com o processo de aplicação de patches documentado. Além disso, forneça capturas de ecrã que demonstrem a aplicação de patches da base de código.
Exemplo de evidência: componentes do sistema de exemplo
A captura de ecrã seguinte demonstra a aplicação de patches de uma máquina virtual do sistema operativo Linux "IaaS- VM-Backend".
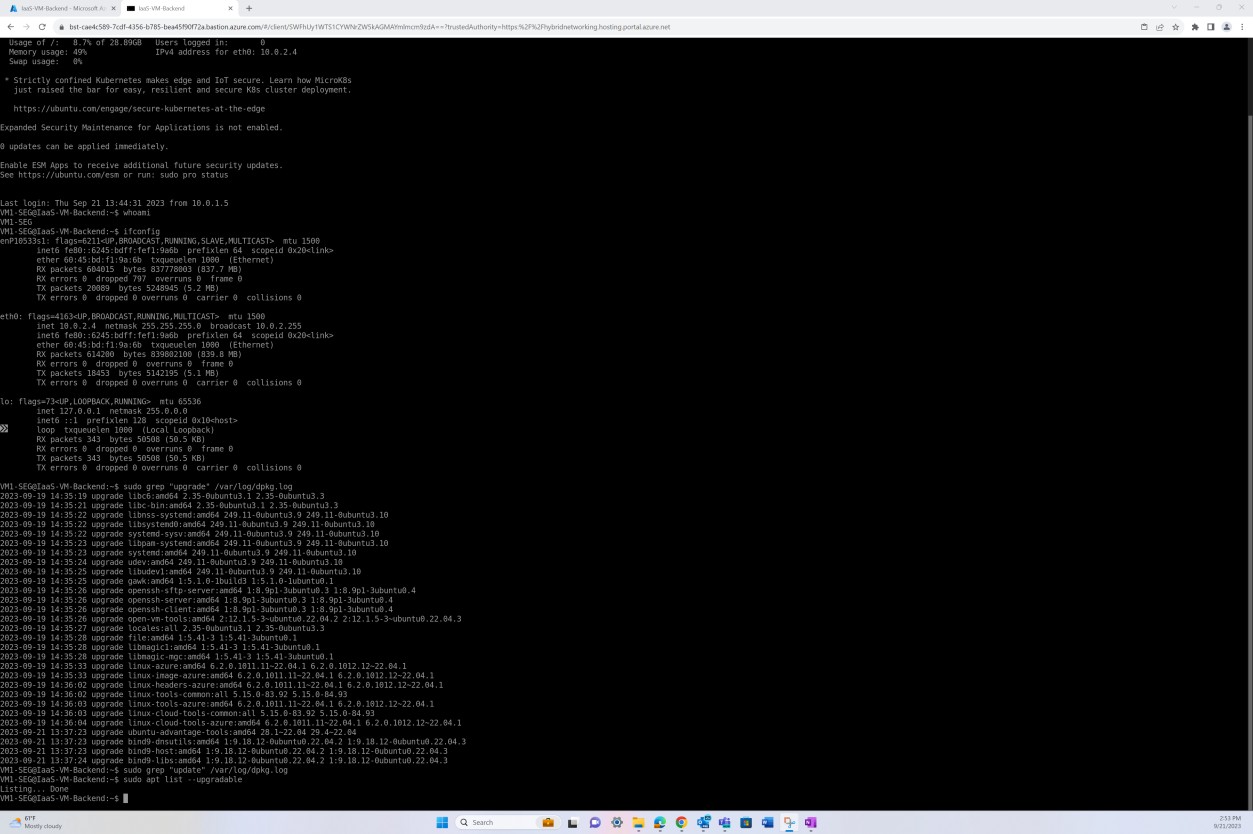
Exemplo de provas
A captura de ecrã seguinte demonstra a aplicação de patches de uma máquina virtual do sistema operativo Windows "IaaS-Web-app".
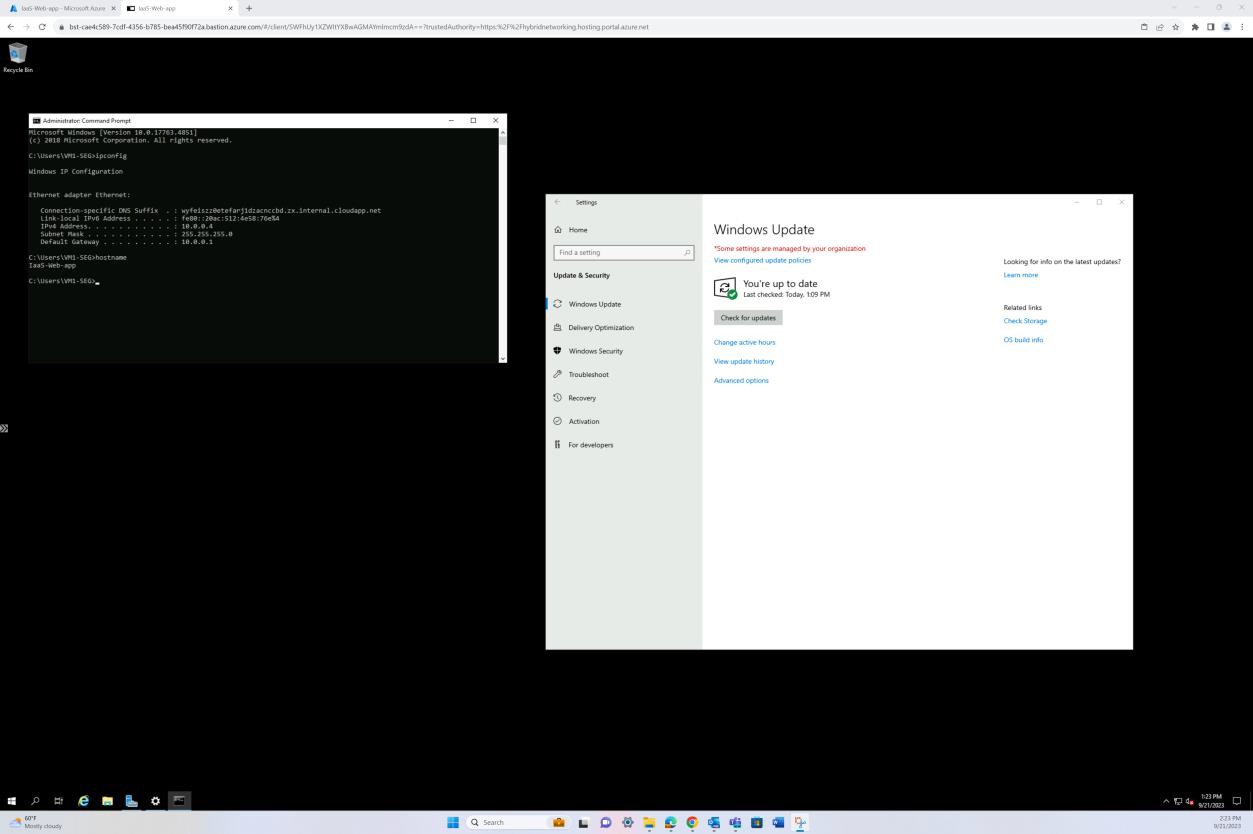
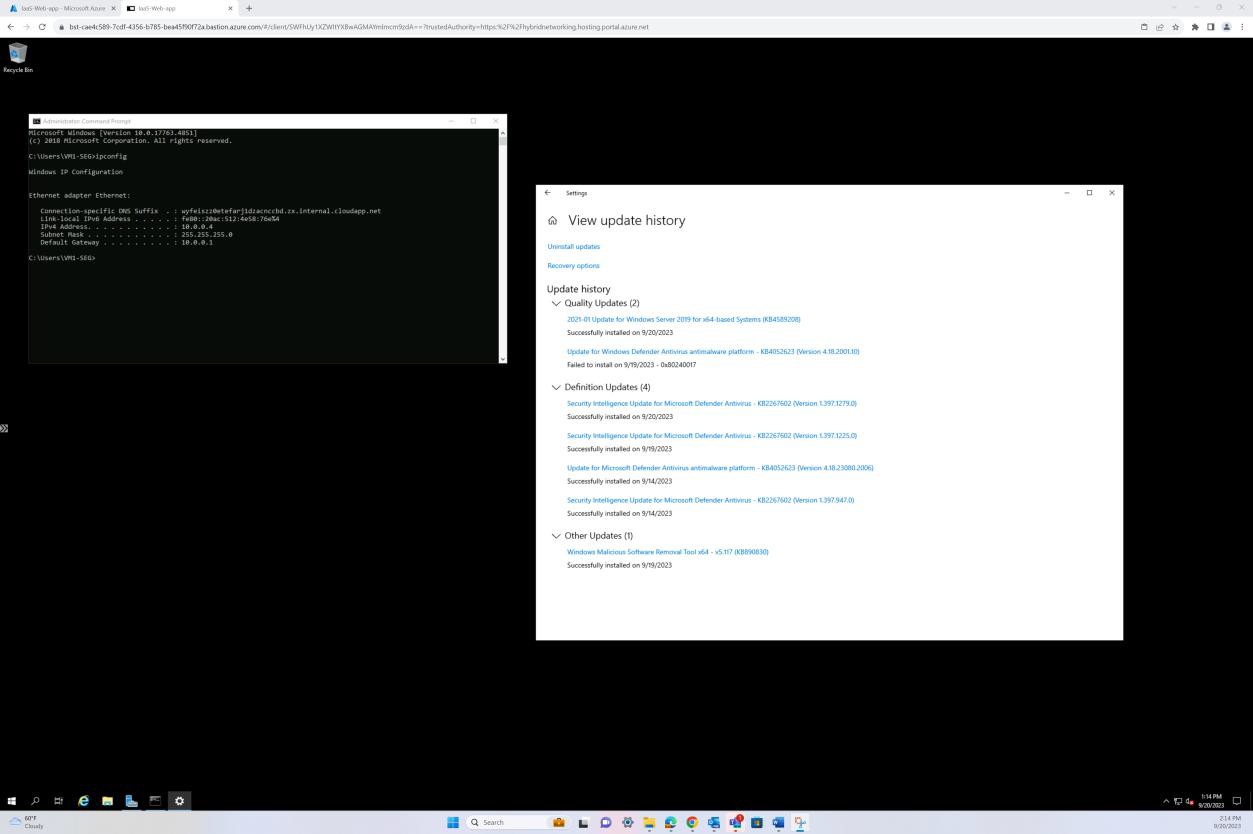
Exemplo de provas
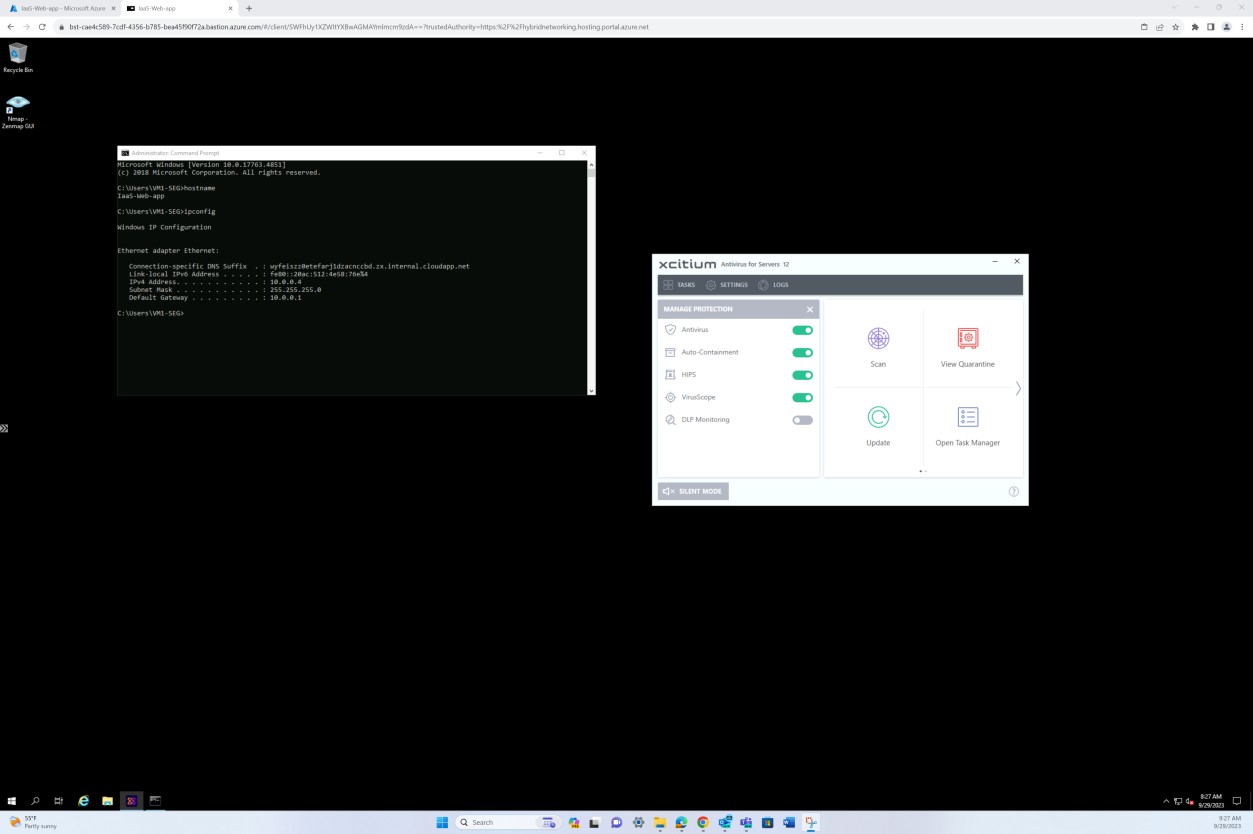
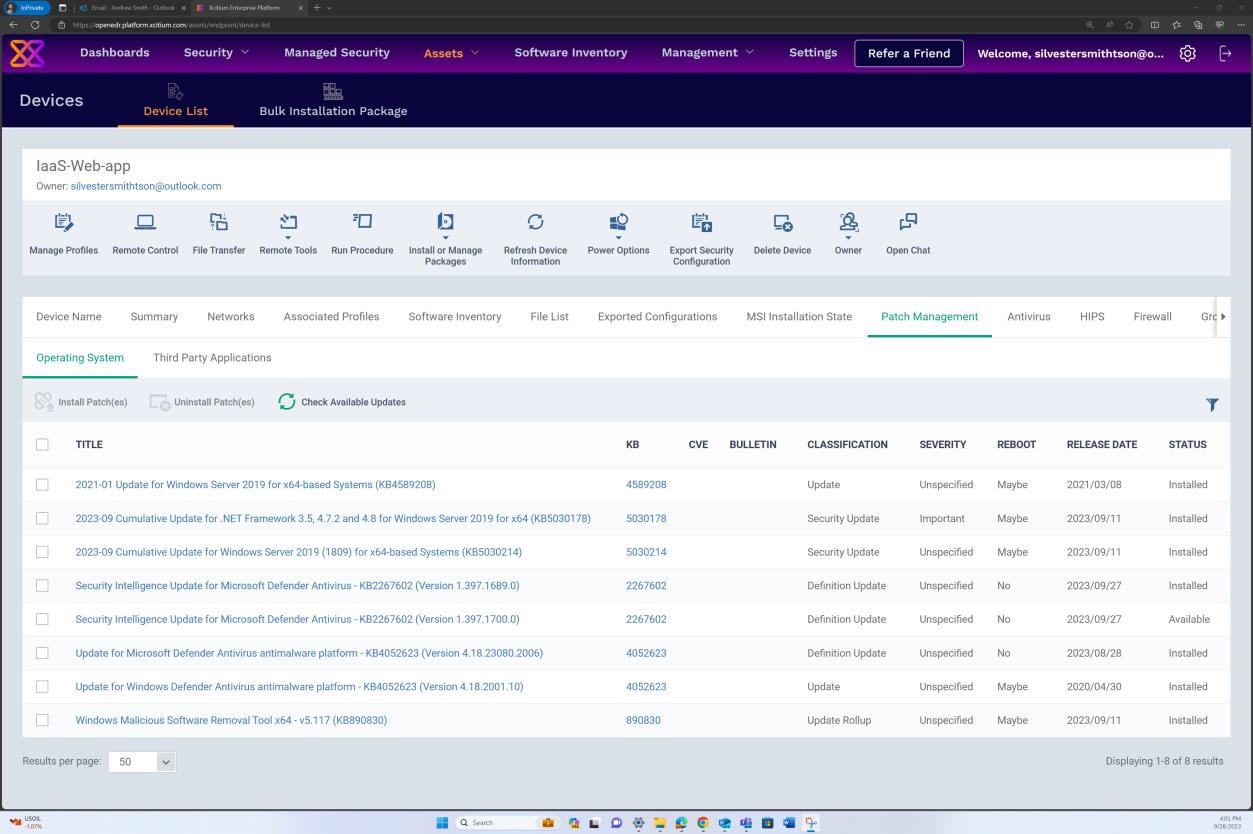
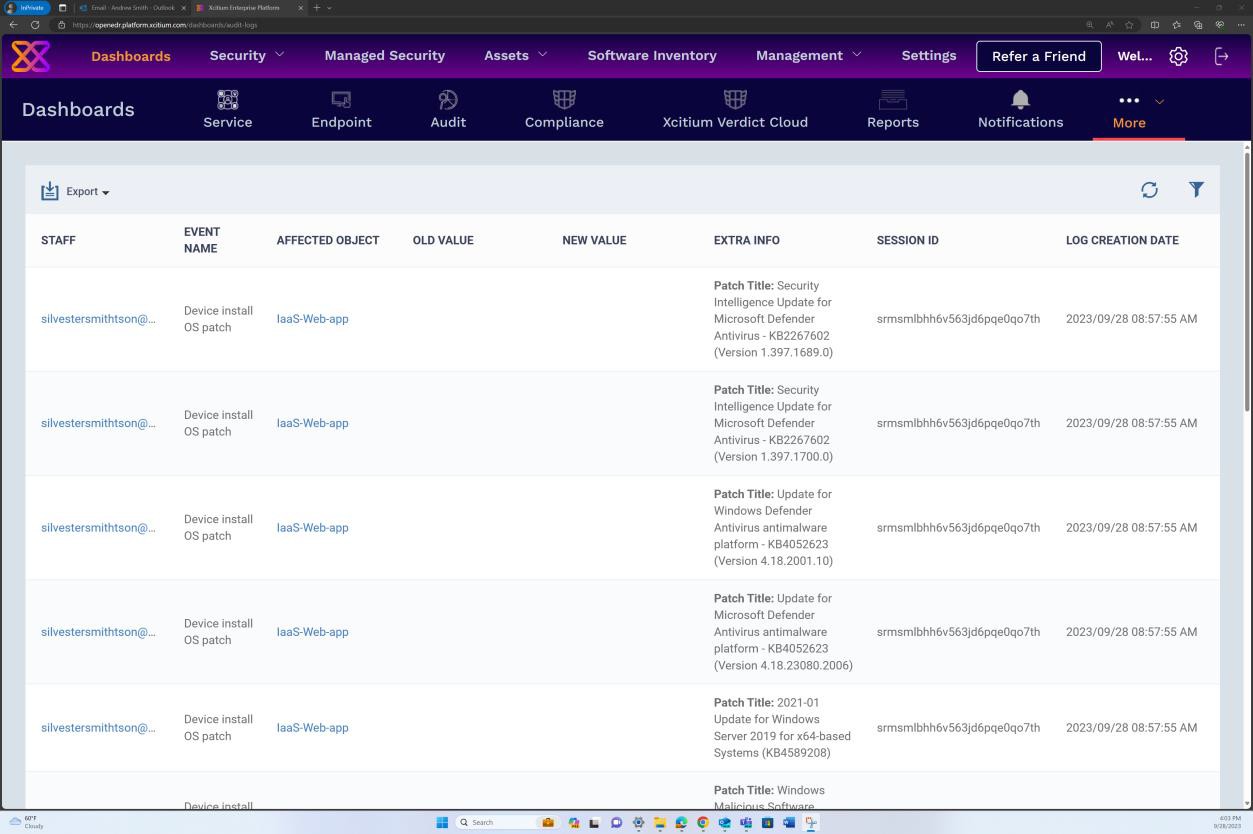
Se estiver a manter a aplicação de patches a partir de outras ferramentas, como o Microsoft Intune, o Defender para a Cloud, etc., podem ser fornecidas capturas de ecrã a partir destas ferramentas. As capturas de ecrã seguintes da solução OpenEDR demonstram que a gestão de patches é realizada através do portal OpenEDR.
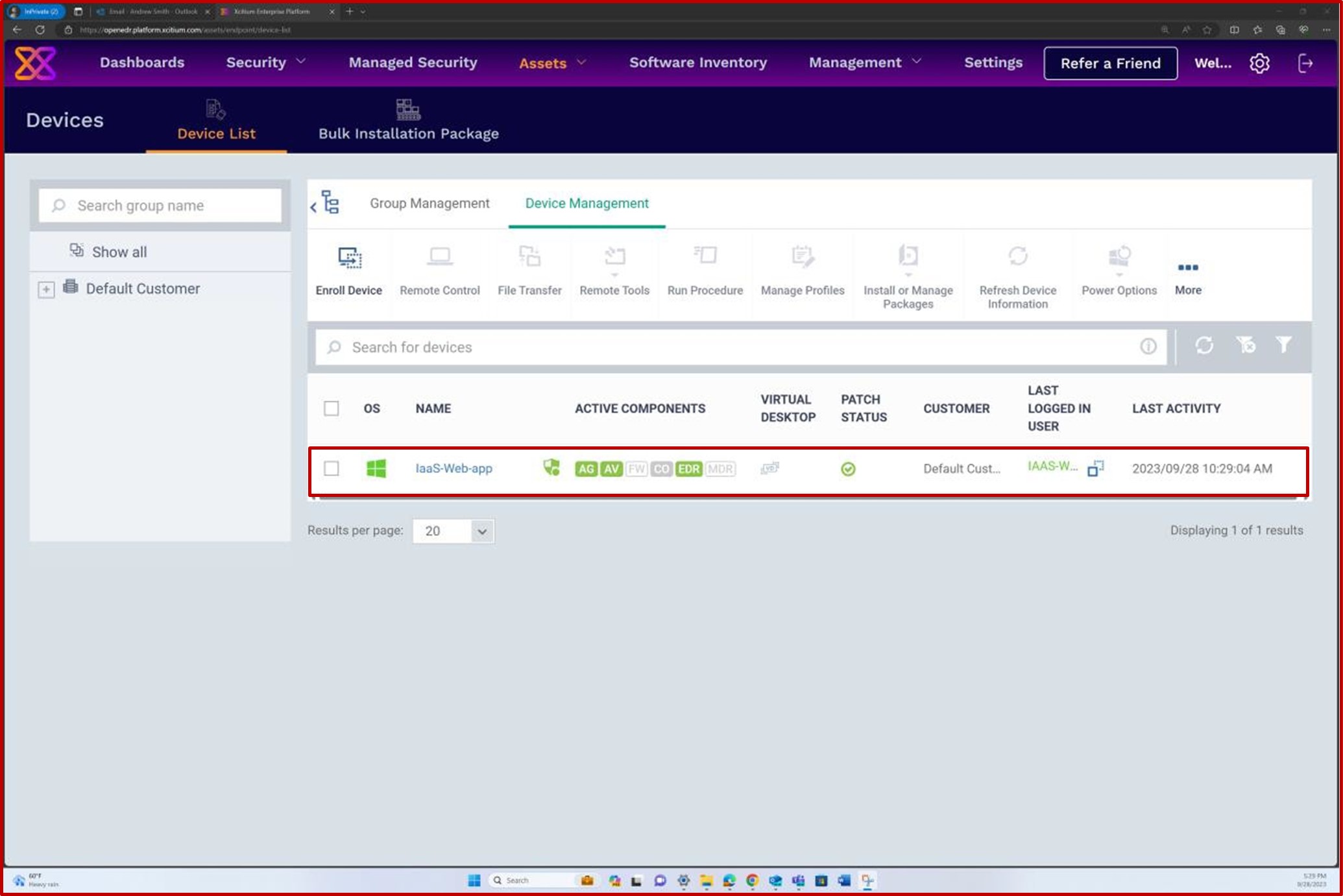
A captura de ecrã seguinte demonstra que a gestão de patches do servidor no âmbito é feita através da plataforma OpenEDR. A classificação e o estado estão visíveis abaixo, o que demonstra que ocorre a aplicação de patches.
A captura de ecrã seguinte mostra que são gerados registos para os patches instalados com êxito no servidor.
Exemplo de provas
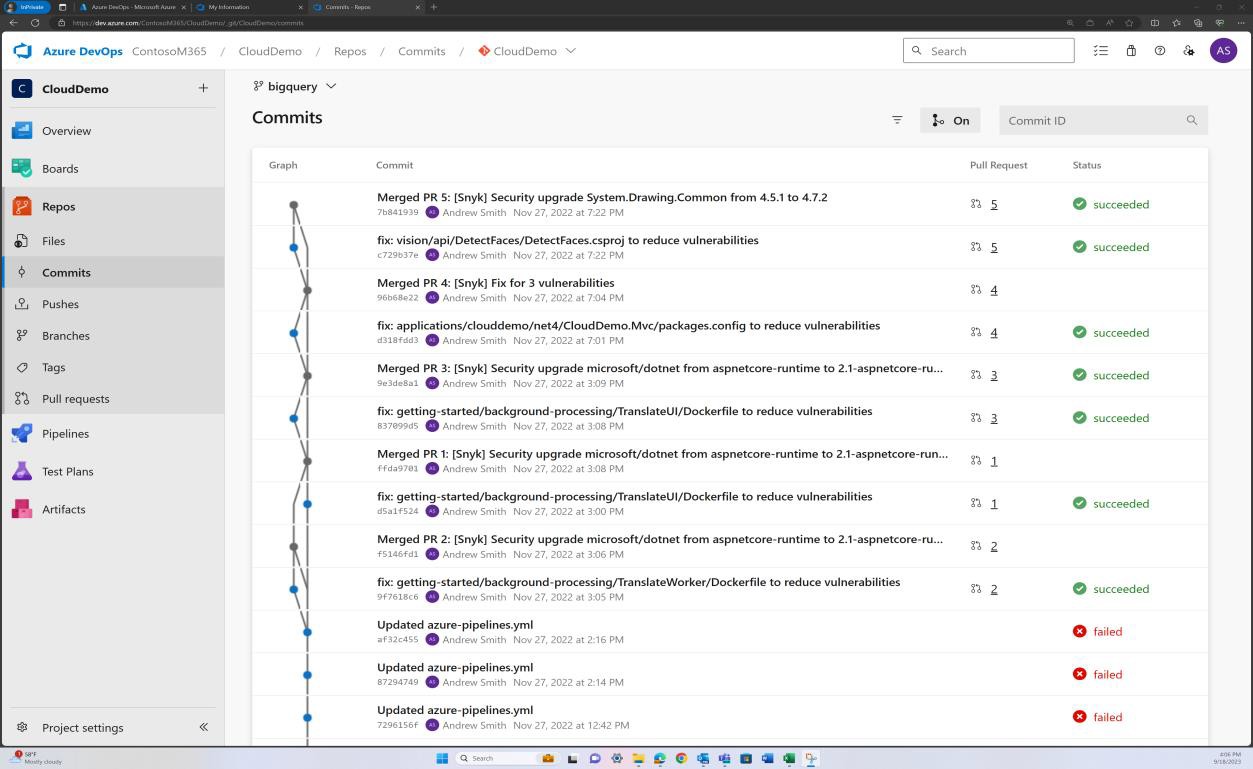
A captura de ecrã seguinte demonstra que as dependências da biblioteca base/de terceiros do código são corrigidas através do Azure DevOps.
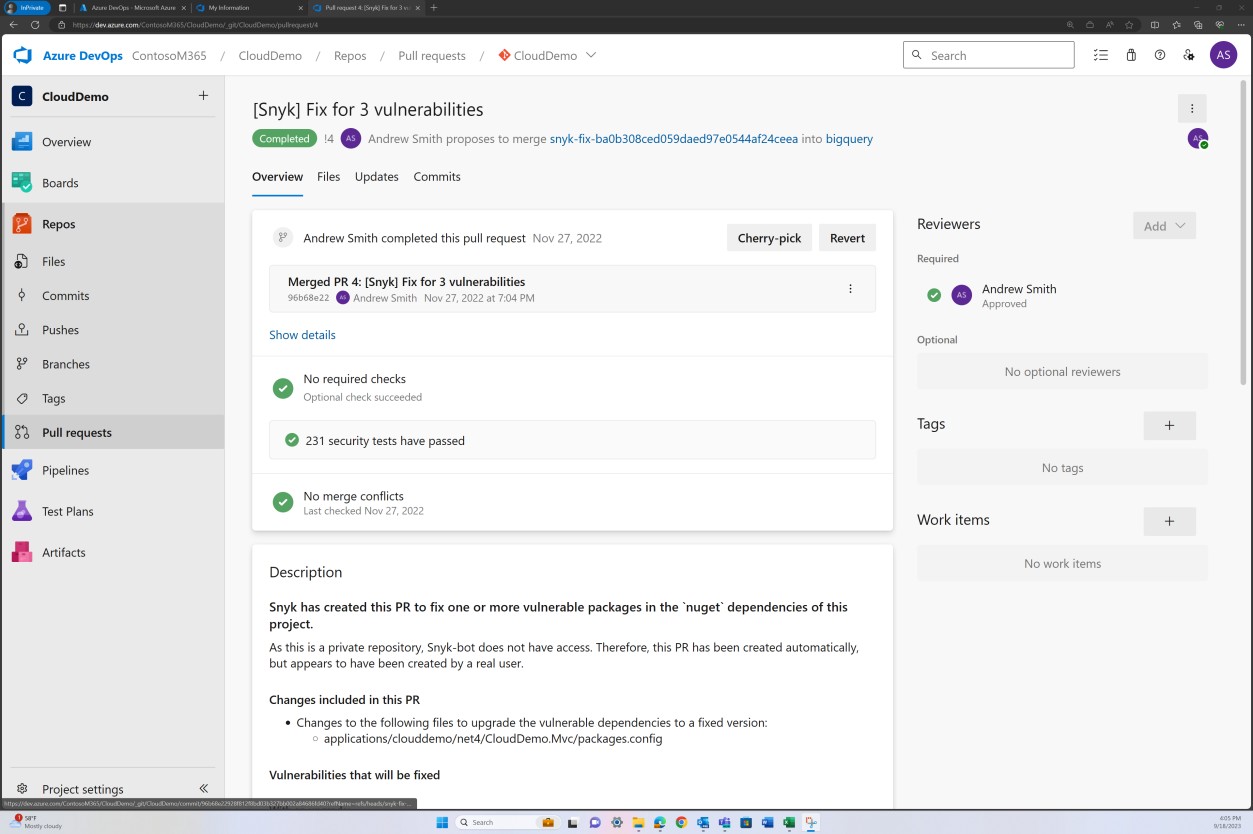
A captura de ecrã seguinte mostra que está a ser consolidada uma correção para as vulnerabilidades detetadas pelo Snyk no ramo para resolver bibliotecas desatualizadas.
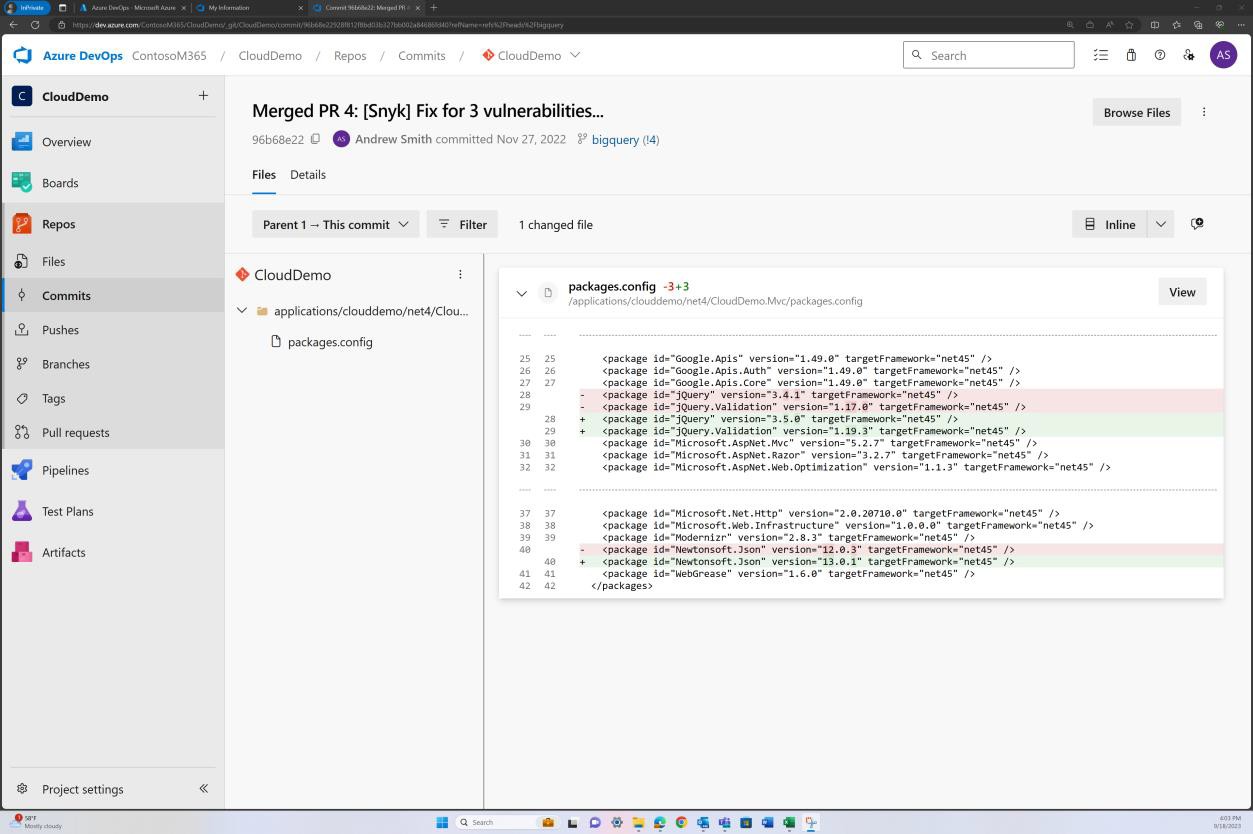
A captura de ecrã seguinte demonstra que as bibliotecas foram atualizadas para versões suportadas.
Exemplo de provas
As capturas de ecrã seguintes demonstram que a aplicação de patches base de código é mantida através do GitHub Dependabot. Os itens fechados demonstram que ocorre a aplicação de patches e que as vulnerabilidades foram resolvidas.
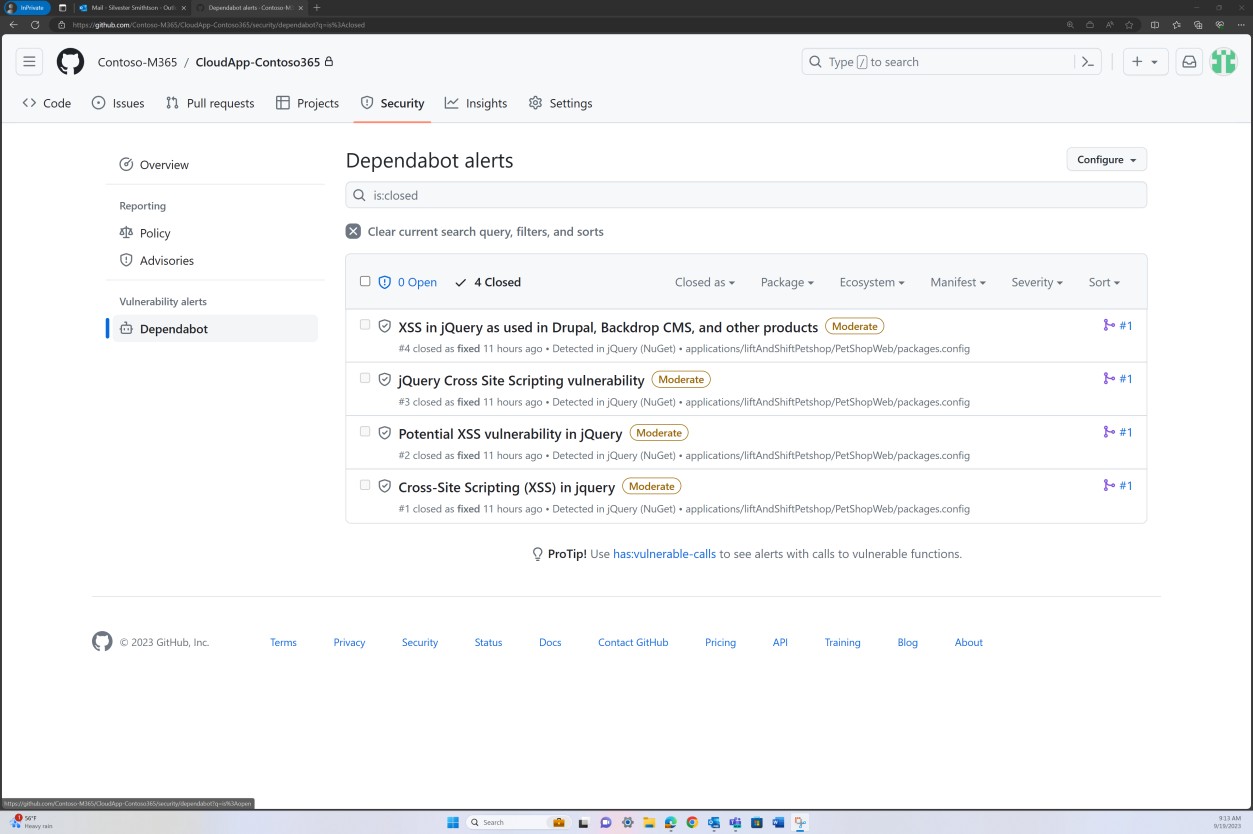
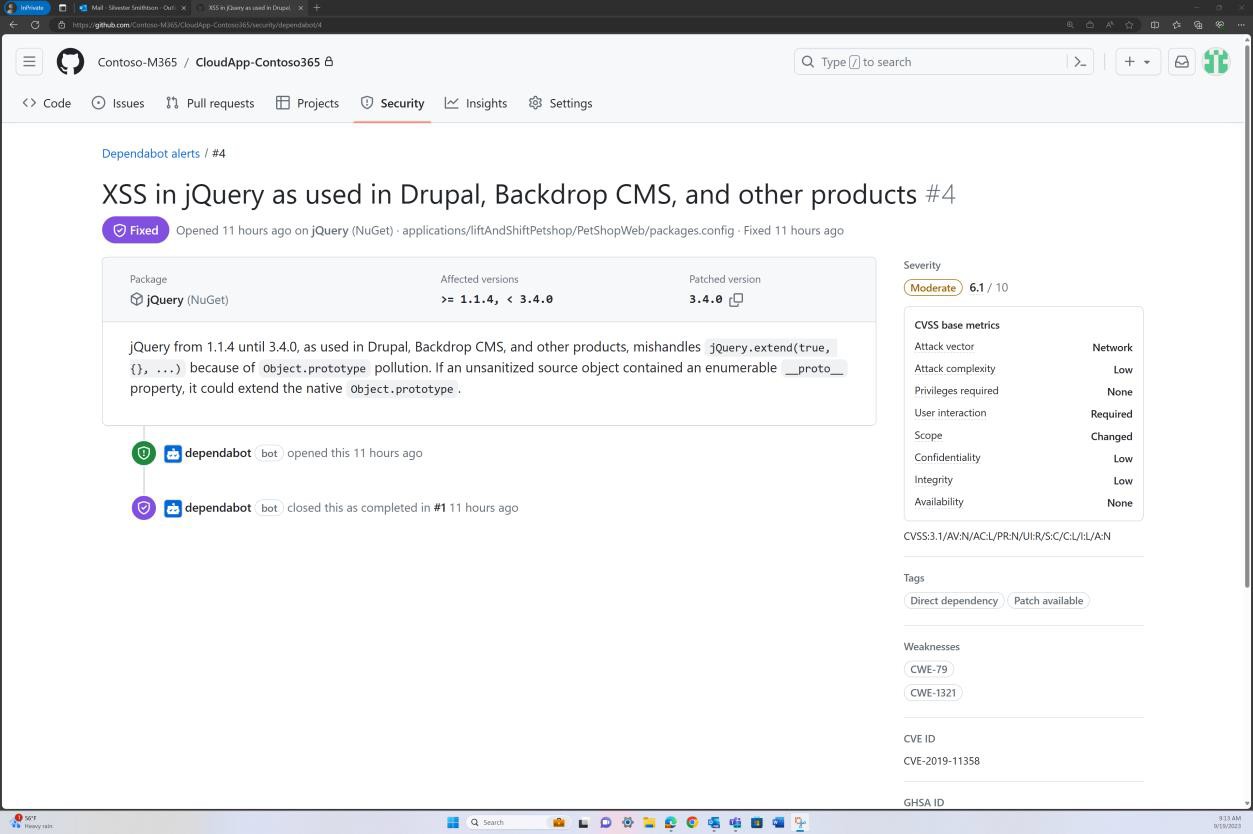
Intenção: SO não suportado
O software que não está a ser mantido pelos fornecedores sofrerá, horas extraordinárias, de vulnerabilidades conhecidas que não são corrigidas. Por conseguinte, a utilização de sistemas operativos e componentes de software não suportados não pode ser utilizada em ambientes de produção. Quando a Infraestrutura como Serviço (IaaS) é implementada, o requisito para este subponto expande-se para incluir a infraestrutura e a base de código para garantir que cada camada da pilha de tecnologia está em conformidade com a política da organização sobre a utilização de software suportado.
Diretrizes: SO não suportado
Forneça uma captura de ecrã para cada dispositivo no conjunto de exemplo escolhido pelo seu analista para recolher provas contra a apresentação da versão do SO em execução (inclua o nome do dispositivo/servidor na captura de ecrã). Além disso, forneça provas de que os componentes de software em execução no ambiente estão a executar versões suportadas do software. Isto pode ser feito ao fornecer a saída de relatórios internos de análise de vulnerabilidades (desde que a análise autenticada esteja incluída) e/ou a saída de ferramentas que verificam bibliotecas de terceiros, como o Snyk, Trivy ou Auditoria NPM. Se a execução da aplicação de patches da biblioteca paaS apenas de terceiros tiver de ser abrangida.
Exemplo de evidência: SO não suportado
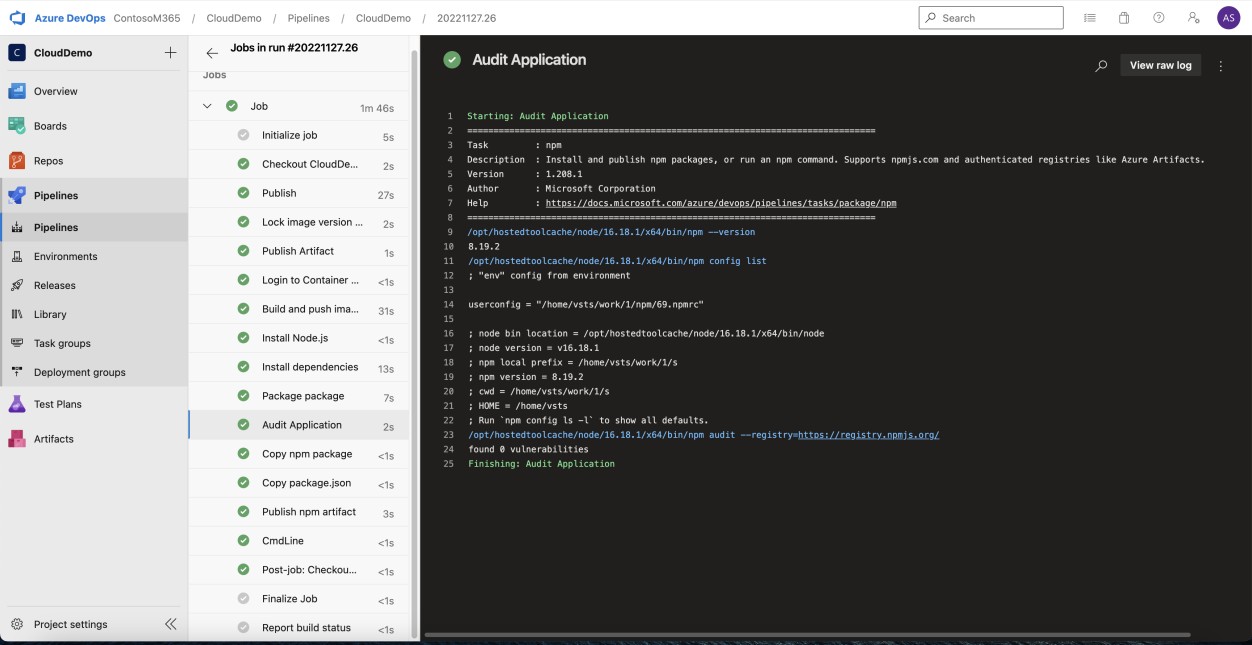
A captura de ecrã seguinte da auditoria NPM do Azure DevOps demonstra que não são utilizadas bibliotecas/dependências não suportadas na aplicação Web.
Nota: no exemplo seguinte, não foi utilizada uma captura de ecrã completa, no entanto, todas as capturas de ecrã de provas submetidas pelo ISV têm de ser capturas de ecrã completas a mostrar o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Exemplo de provas
A captura de ecrã seguinte do GitHub Dependabot demonstra que não são utilizadas bibliotecas/dependências na aplicação Web.
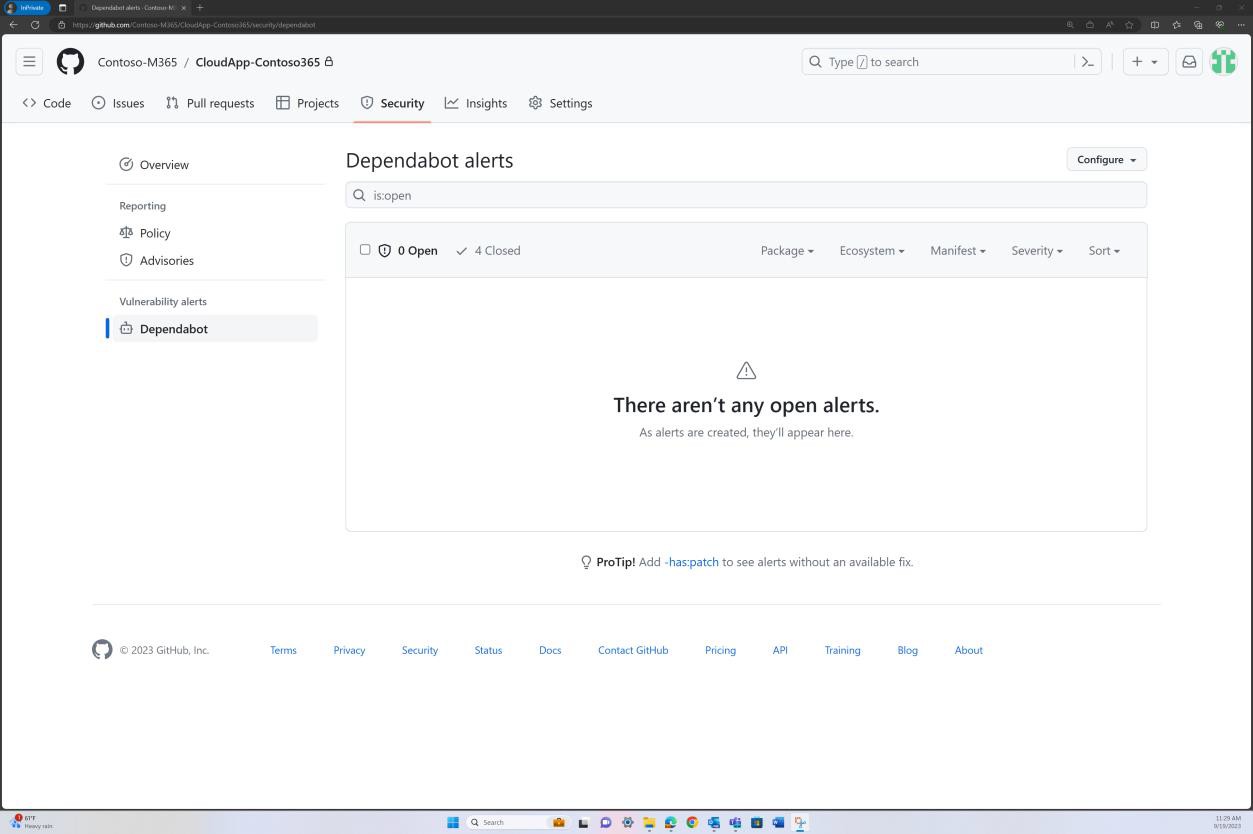
Exemplo de provas
A captura de ecrã seguinte do inventário de software para o sistema operativo Windows através do OpenEDR demonstra que não foram encontradas versões de software e sistema operativo não suportados ou desatualizados.
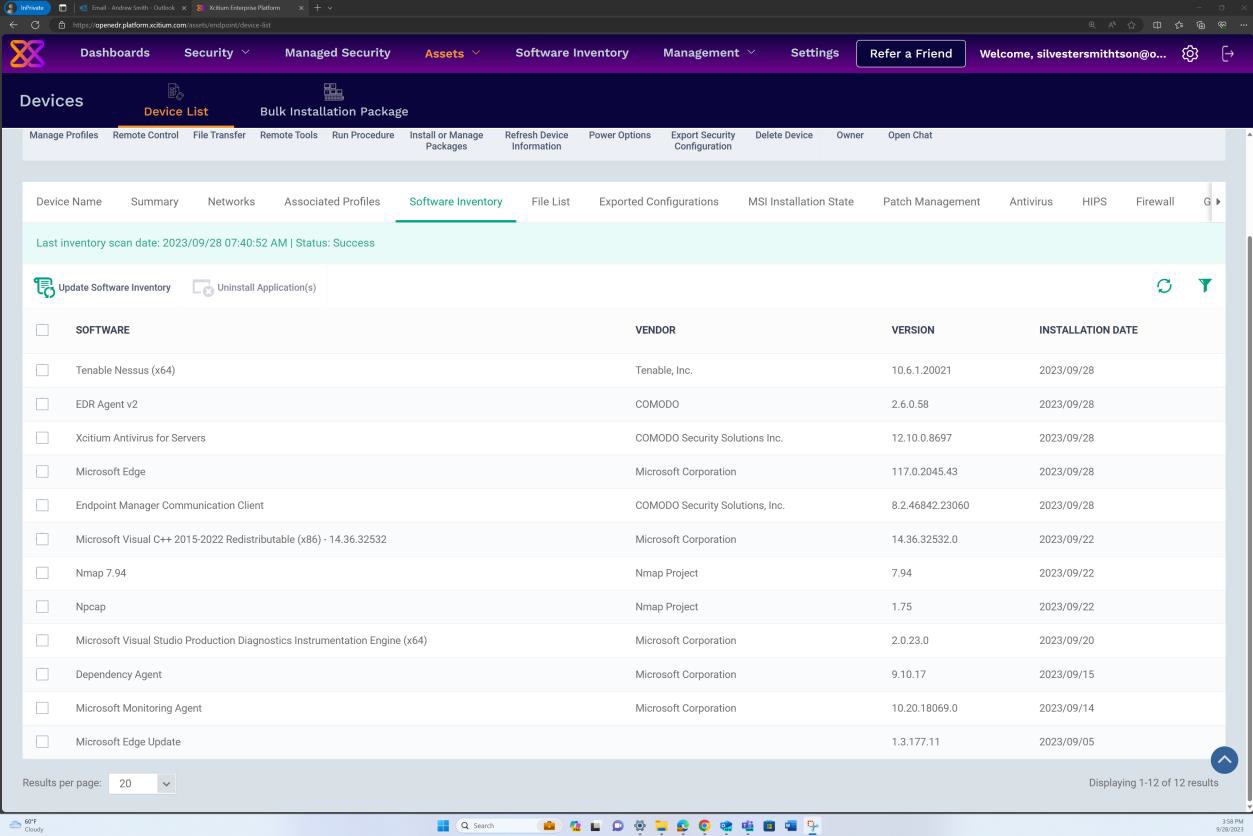
Exemplo de provas
A captura de ecrã seguinte é do OpenEDR no Resumo do SO que mostra o Windows Server 2019 Datacenter (x64) e o histórico de versões completas do SO, incluindo service pack, versão de compilação, etc... validando que não foi encontrado nenhum sistema operativo não suportado.
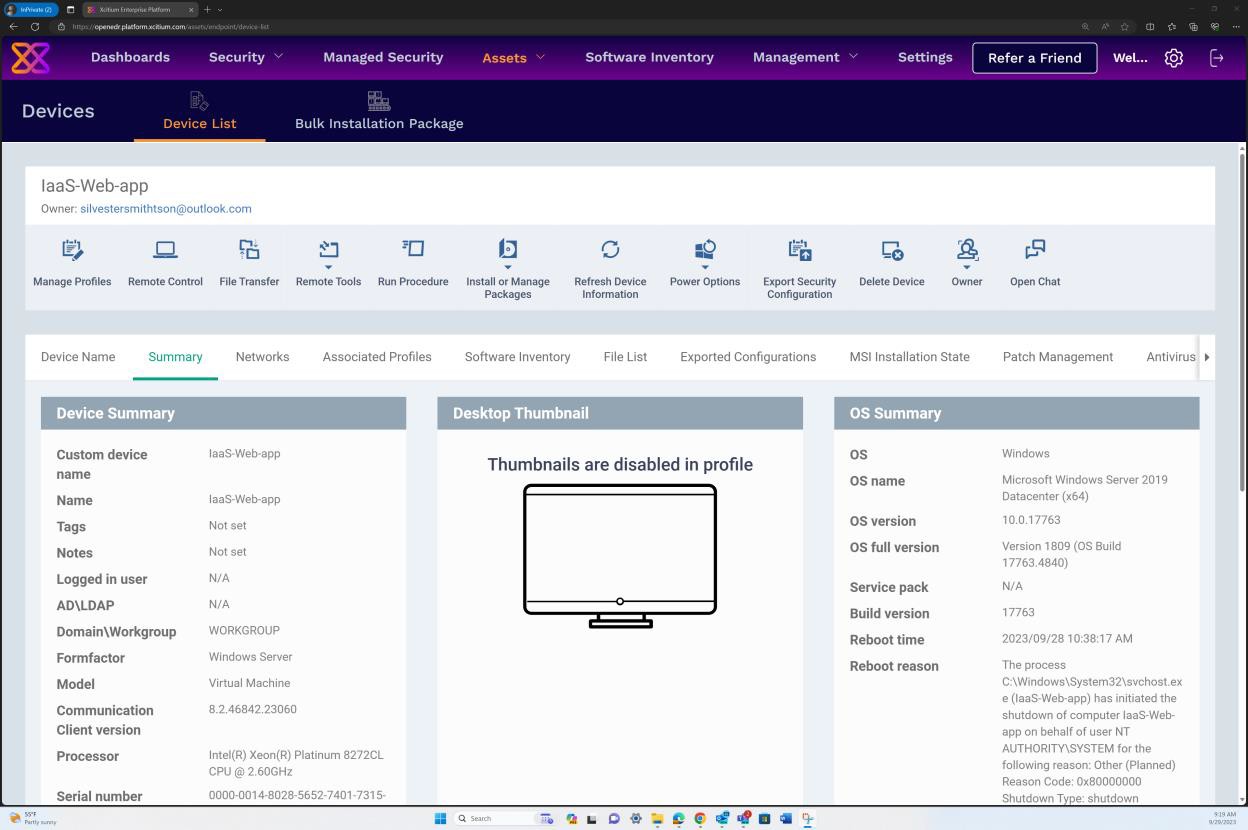
Exemplo de provas
A captura de ecrã seguinte de um servidor do sistema operativo Linux demonstra todos os detalhes da versão, incluindo o ID do Distribuidor, Descrição, Versão e Nome de Código, validando que não foi encontrado nenhum sistema operativo Linux não suportado.
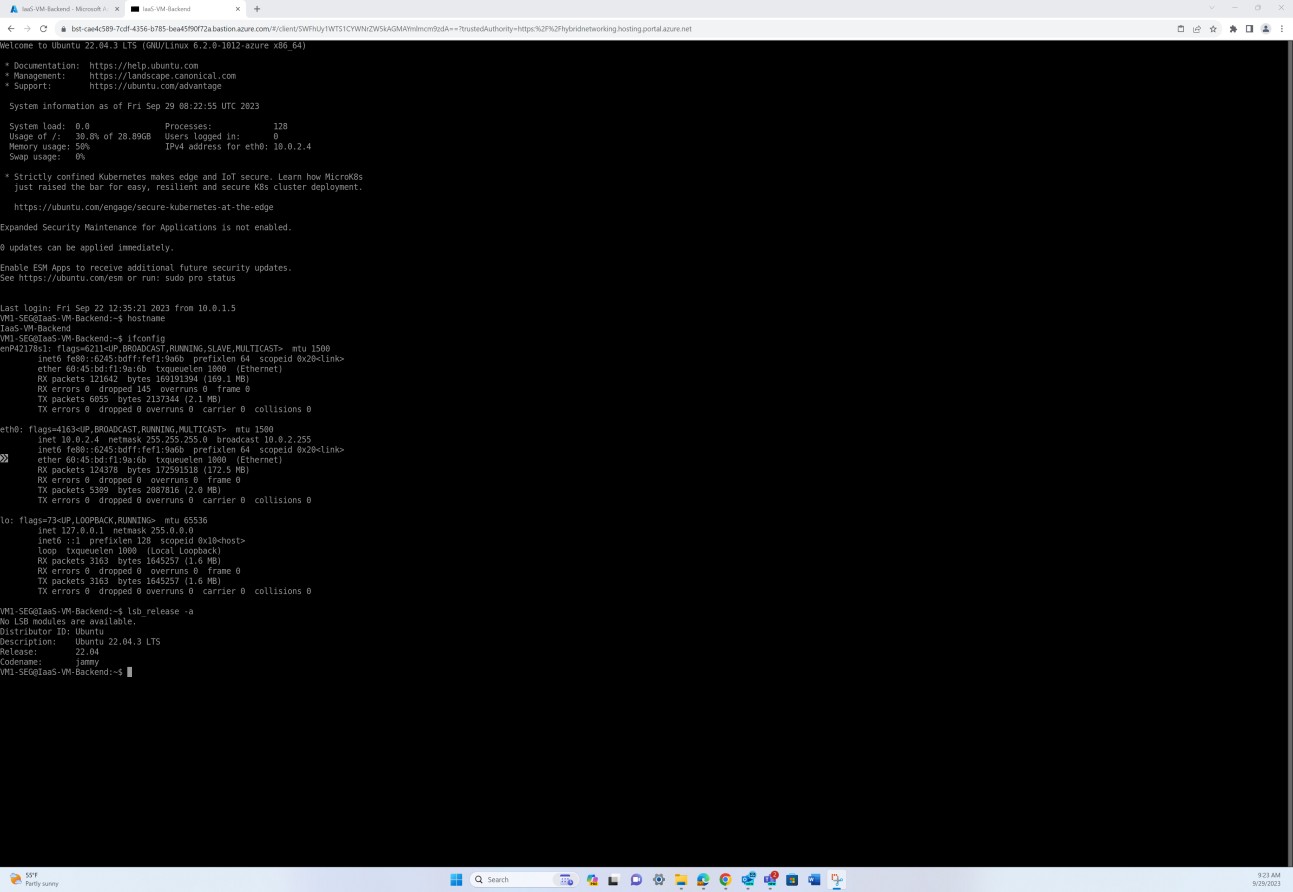
Exemplo de provas:
A captura de ecrã seguinte do relatório de análise de vulnerabilidades do Nessus demonstra que não foi encontrado nenhum sistema operativo (SO) e software não suportados no computador de destino.
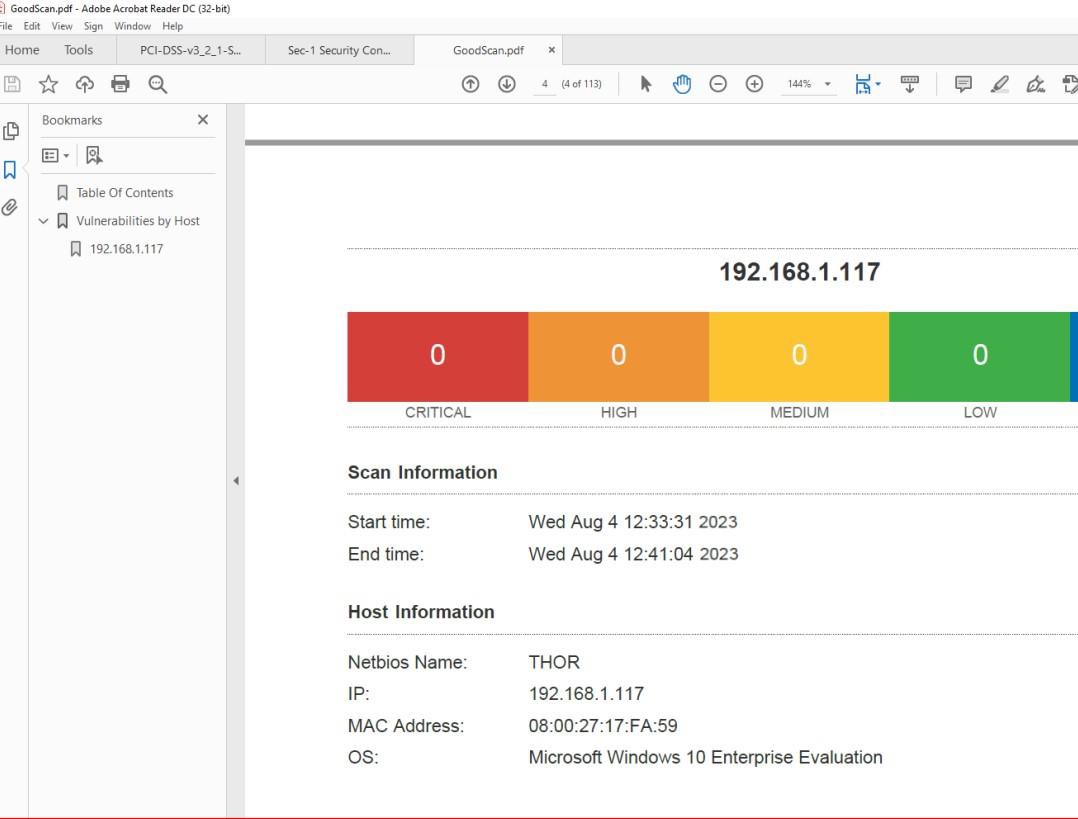
Nota: nos exemplos anteriores, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas a mostrar o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Verificação de vulnerabilidade
A análise de vulnerabilidades procura possíveis fraquezas no sistema informático, redes e aplicações Web de uma organização para identificar buracos que possam potencialmente levar a falhas de segurança e à exposição de dados confidenciais. A análise de vulnerabilidades é frequentemente exigida pelas normas da indústria e regulamentos governamentais, por exemplo, o PCI DSS (Payment Card Industry Data Security Standard).
Um relatório da Métrica de Segurança intitulado "Guia de Métricas de Segurança de 2020 para a Conformidade do PCI DSS" afirma que "em média, demorou 166 dias a partir do momento em que uma organização foi vista a ter vulnerabilidades para um atacante comprometer o sistema. Depois de comprometidos, os atacantes tiveram acesso a dados confidenciais durante uma média de 127 dias, pelo que este controlo visa identificar potenciais fraquezas de segurança no ambiente no âmbito.
Ao introduzir avaliações regulares de vulnerabilidades, as organizações podem detetar fraquezas e inseguranças nos seus ambientes, o que pode fornecer um ponto de entrada para um ator malicioso comprometer o ambiente. A análise de vulnerabilidades pode ajudar a identificar patches em falta ou configurações incorretas no ambiente. Ao realizar regularmente estas análises, uma organização pode fornecer uma remediação adequada para minimizar o risco de um compromisso devido a problemas que são normalmente recolhidos por estas ferramentas de análise de vulnerabilidades.
Controlo N.º 6
Forneça provas que demonstrem que:
A análise trimestral de vulnerabilidades de aplicações Web e infraestrutura é realizada.
A análise tem de ser efetuada relativamente a toda a quantidade de espaço público (IPs/URLs) e aos intervalos de IP internos se o ambiente for IaaS, Híbrido ou No Local.
Nota: tem de incluir o âmbito completo do ambiente.
Intenção: análise de vulnerabilidades
Este controlo visa garantir que a organização realiza a análise de vulnerabilidades trimestralmente, visando a infraestrutura e as aplicações Web. A análise tem de ser abrangente, abrangendo requisitos de espaço público, como IPs públicos e URLs, bem como intervalos de IP internos. O âmbito da análise varia consoante a natureza da infraestrutura da organização:
Se uma organização implementar modelos híbridos, no local ou de Infraestrutura como Serviço (IaaS), a análise tem de abranger IPs/URLs públicos externos e intervalos de IP internos.
Se uma organização implementar a Plataforma como Serviço (PaaS), a análise tem de abranger apenas IPs/URLs públicos externos.
Este controlo também determina que a análise deve incluir o âmbito completo do ambiente, não deixando assim nenhum componente desmarcado. O objetivo é identificar e avaliar vulnerabilidades em todas as partes da pilha tecnológica da organização para garantir uma segurança abrangente.
Diretrizes: análise de vulnerabilidades
Indique os relatórios de análise completos para as análises de vulnerabilidades de cada trimestre que foram realizadas nos últimos 12 meses. Os relatórios devem indicar claramente os objetivos para validar que a quantidade total de espaço público está incluída e, quando aplicável, cada sub-rede interna. Indique TODOS os relatórios de análise para CADA trimestre.
Exemplo de evidência: análise de vulnerabilidades
A captura de ecrã seguinte mostra uma deteção de rede e uma análise de porta realizada através do Nmap na Infraestrutura externa para identificar quaisquer portas abertas não protegidas.
Nota: o Nmap por si só não pode ser utilizado para cumprir este controlo, uma vez que a expectativa é que seja fornecida uma análise completa de vulnerabilidades. A deteção de portas Nmap faz parte do processo de gestão de vulnerabilidades exemplificada abaixo e é complementada por análises OpenVAS e OWASP ZAP relativamente à infraestrutura externa.
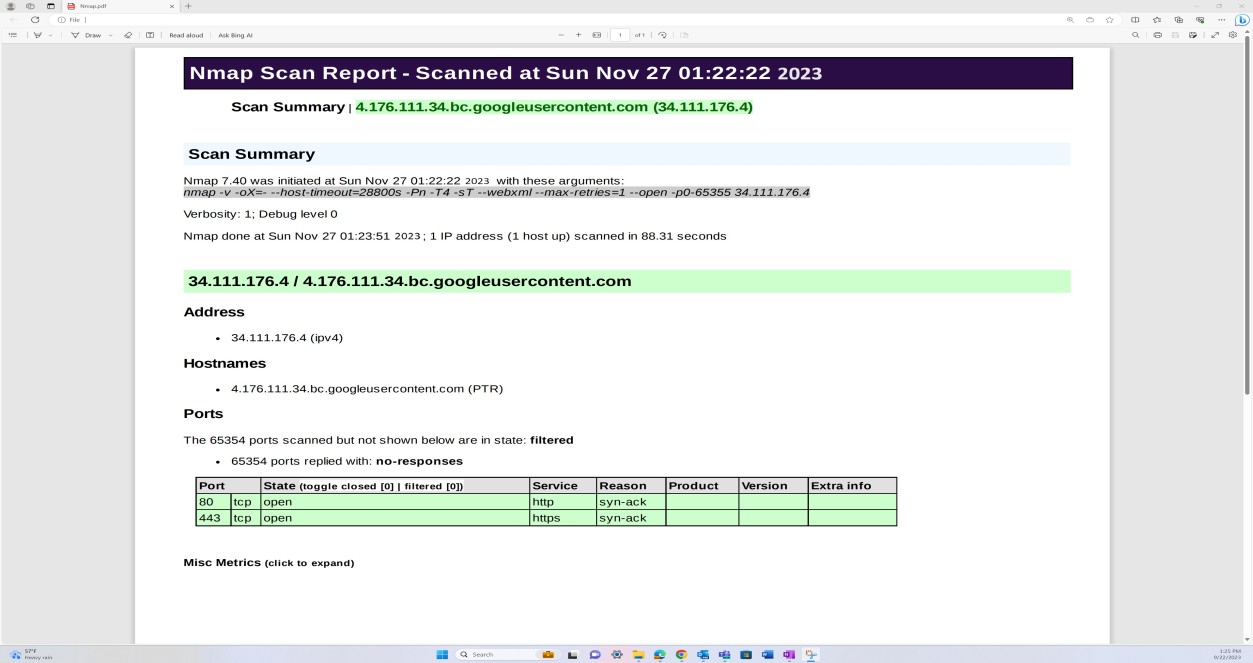
A captura de ecrã mostra a análise de vulnerabilidades através do OpenVAS relativamente à infraestrutura externa para identificar eventuais configurações incorretas e vulnerabilidades pendentes.
A captura de ecrã seguinte mostra o relatório de análise de vulnerabilidades do OWASP ZAP a demonstrar testes de segurança de aplicações dinâmicos.
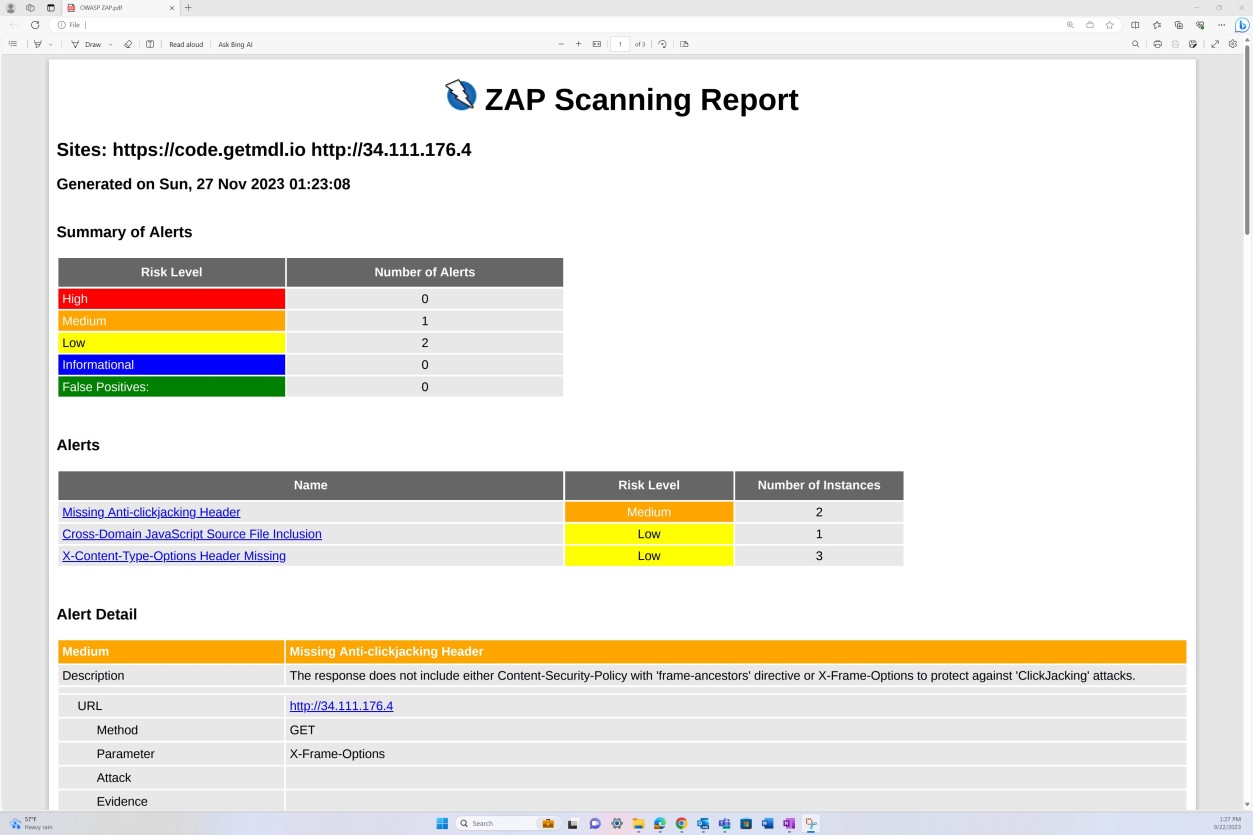
Exemplo de evidência: análise de vulnerabilidades
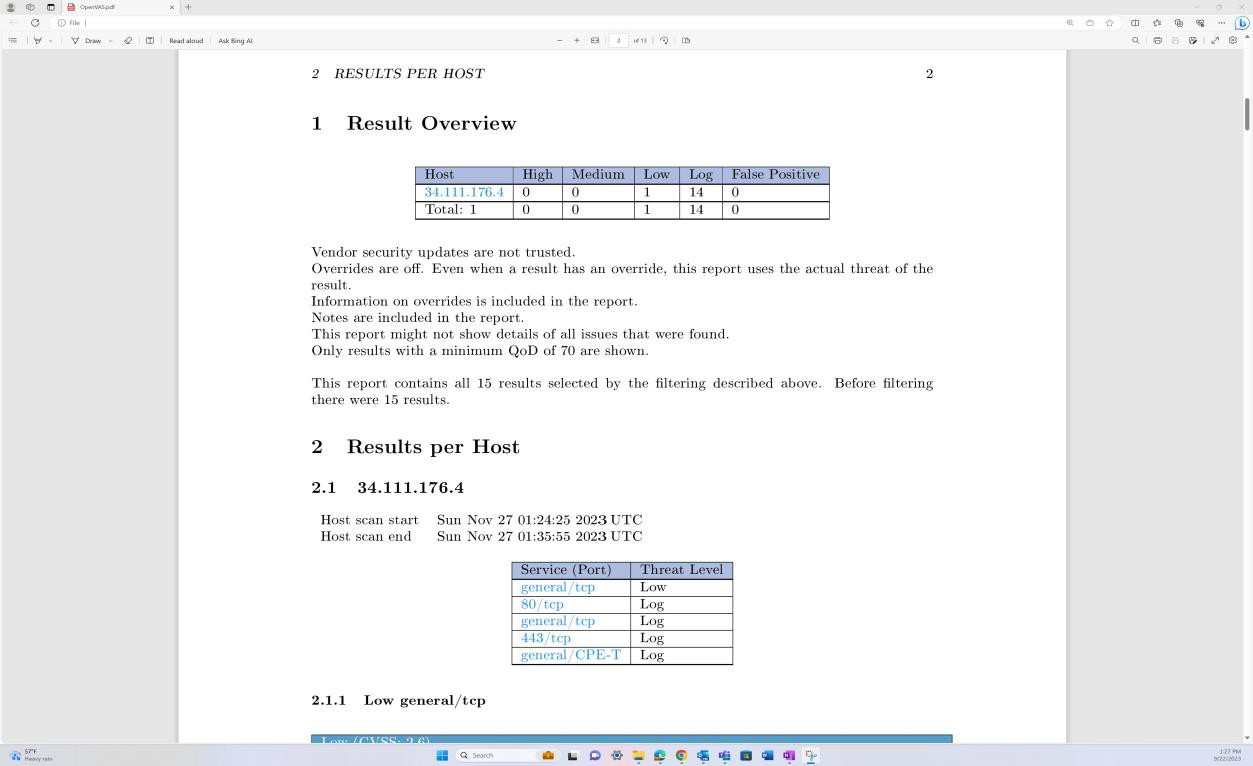
As capturas de ecrã seguintes do relatório de análise de vulnerabilidades do Nessus Essentials tenable demonstram que a análise da infraestrutura interna é efetuada.
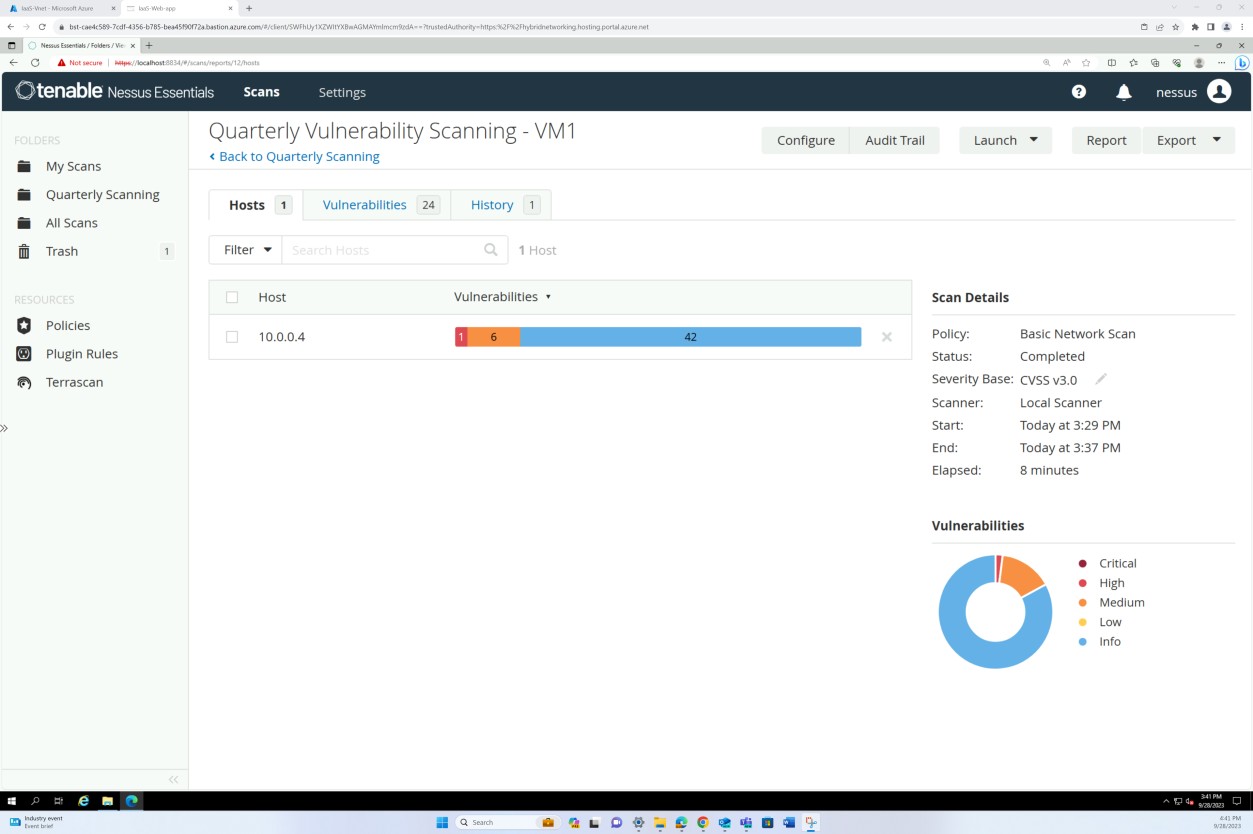
As capturas de ecrã anteriores demonstram a configuração das pastas para análises trimestrais nas VMs do anfitrião.
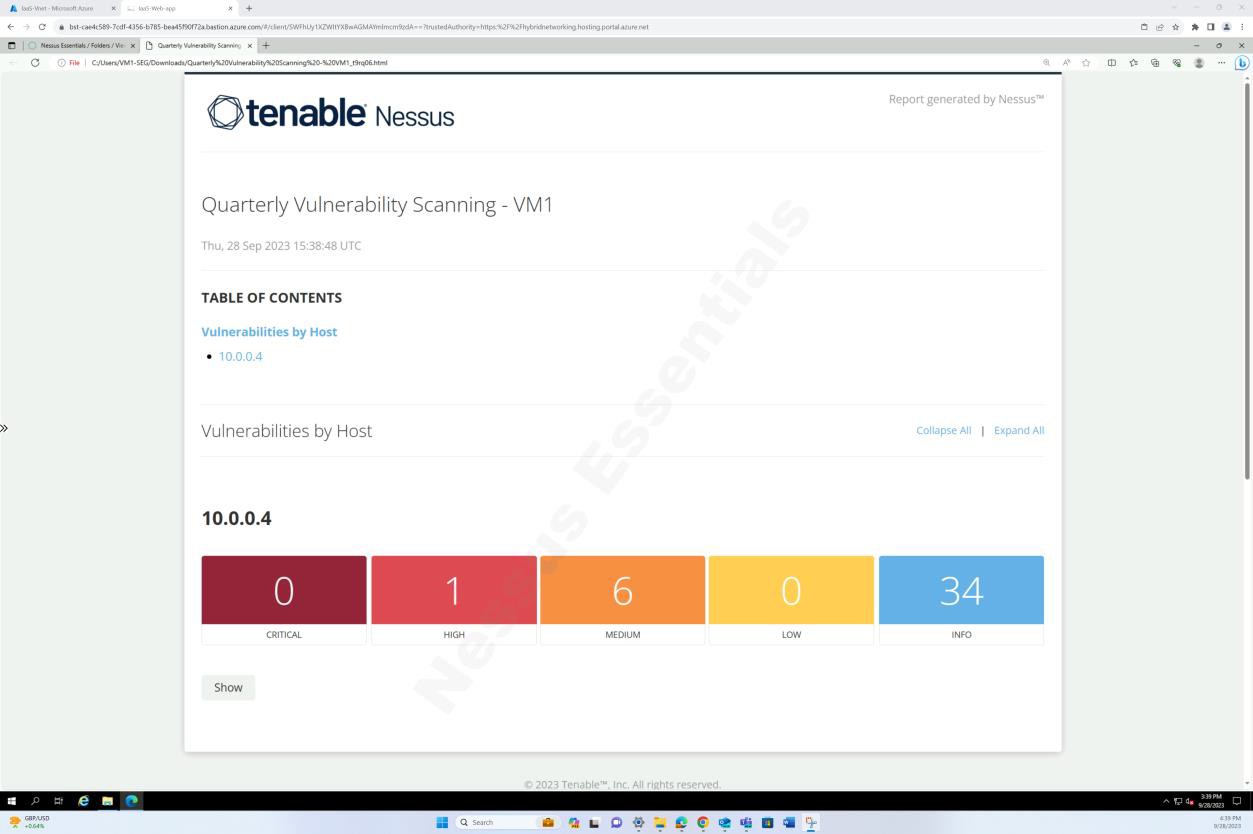
As capturas de ecrã acima e abaixo mostram o resultado do relatório de análise de vulnerabilidades.
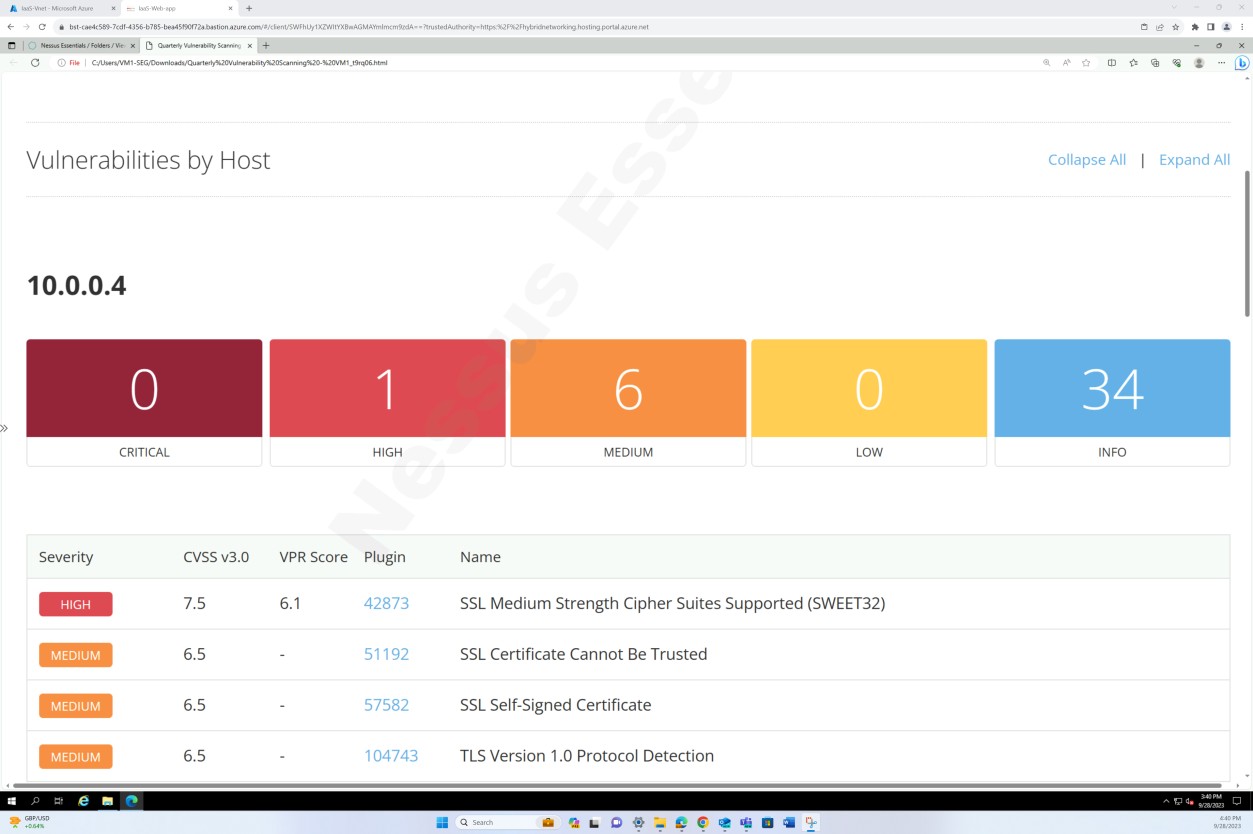
A captura de ecrã seguinte mostra a continuação do relatório que abrange todos os problemas encontrados.
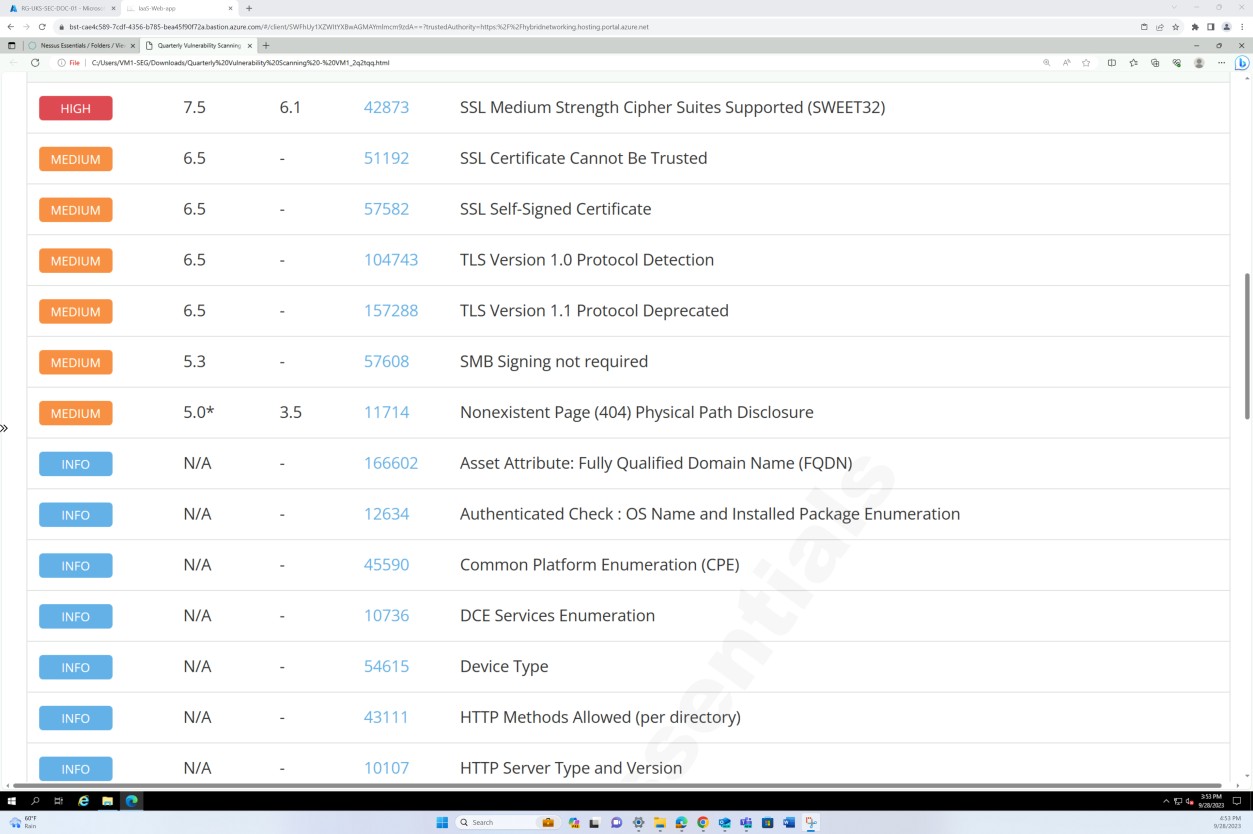
Controlo N.º 7
Forneça provas de reanálise que demonstrem que:
- A remediação de todas as vulnerabilidades identificadas no Controlo 6 é corrigida de acordo com a janela de aplicação de patches mínima definida na sua política.
Intenção: aplicação de patches
A falta de identificação, gestão e remediação rápida de vulnerabilidades e configurações incorretas pode aumentar o risco de um compromisso por parte de uma organização que conduza a potenciais violações de dados. Identificar e remediar corretamente problemas é visto como importante para a postura e o ambiente de segurança gerais de uma organização que está em consonância com as melhores práticas de várias arquiteturas de segurança, por exemplo, ISO 27001 e PCI DSS.
A intenção deste controlo é garantir que a organização fornece provas credíveis de reanálises, demonstrando que todas as vulnerabilidades identificadas num Controlo 6 foram remediadas. A remediação tem de estar alinhada com a janela de aplicação de patches mínima definida na política de gestão de patches da organização.
Diretrizes: aplicação de patches
Forneça relatórios de nova análise que confirmem que quaisquer vulnerabilidades identificadas no controlo 6 foram remediadas de acordo com as janelas de aplicação de patches definidas no controlo 4 .
Exemplo de evidência: aplicação de patches
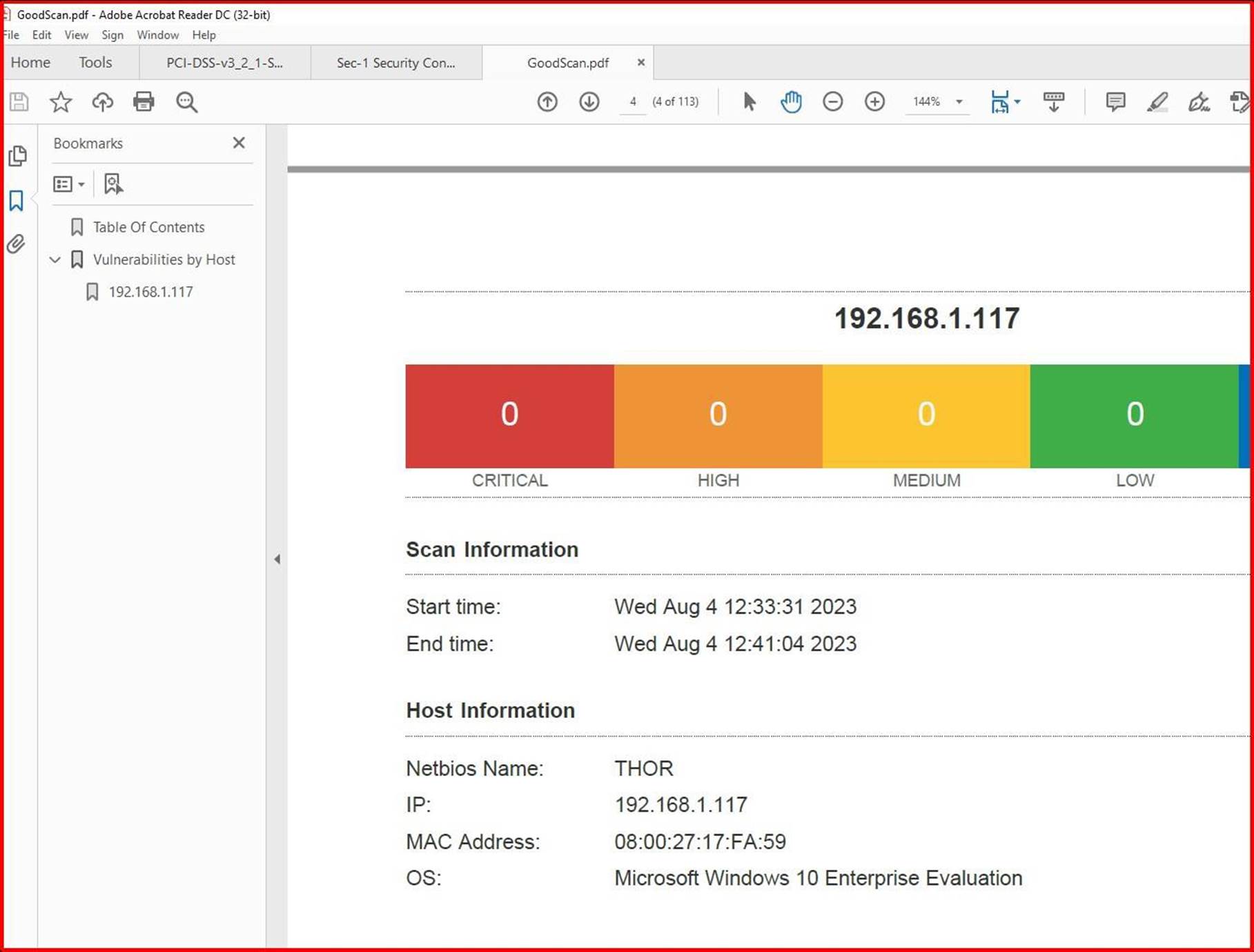
A captura de ecrã seguinte mostra uma análise Nessus do ambiente no âmbito (uma única máquina neste exemplo chamada Thor) a mostrar vulnerabilidades nodia 2de agosto de 2023.
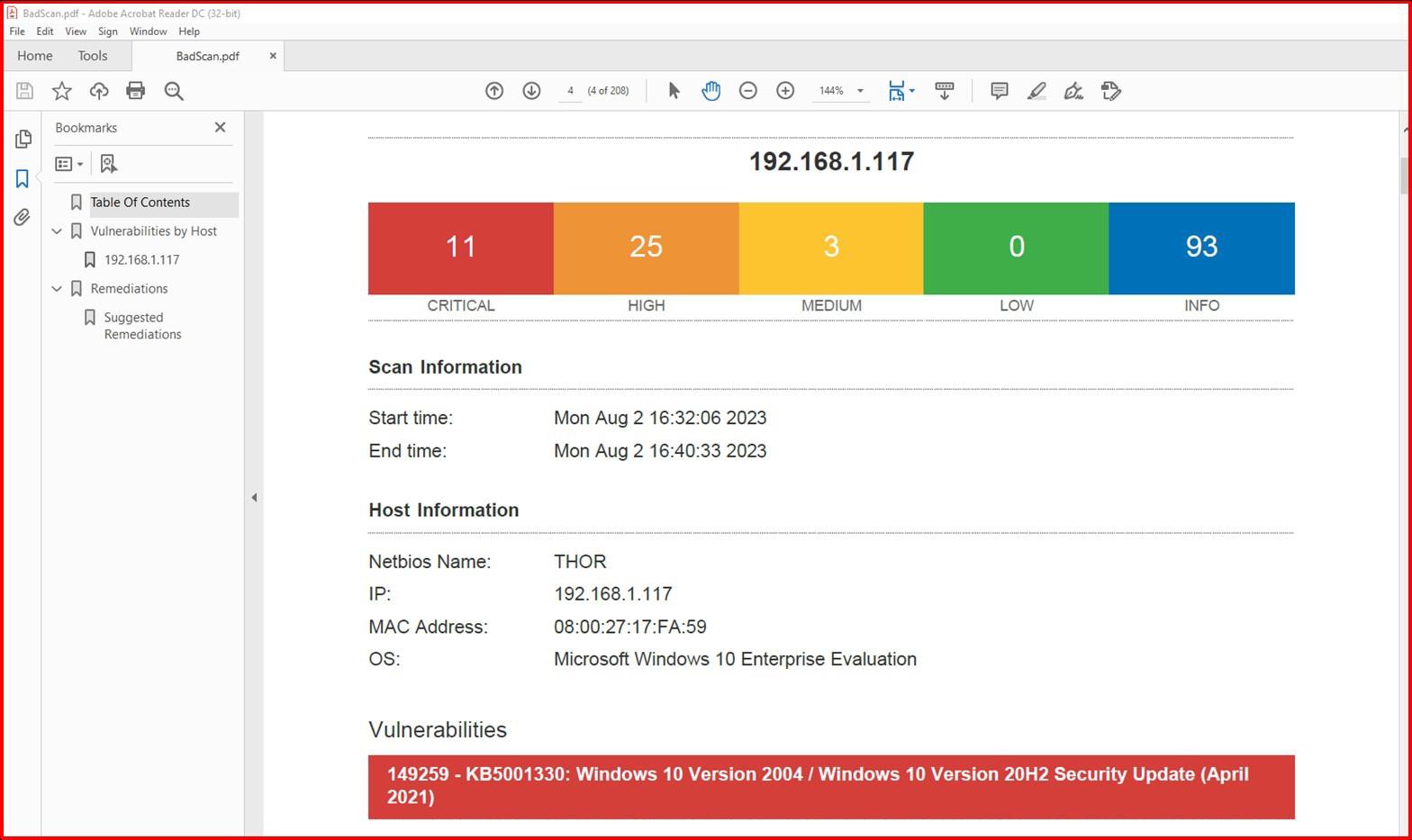
A captura de ecrã seguinte mostra que os problemas foram resolvidos, 2 dias depois, que se encontra na janela de aplicação de patches definida na política de aplicação de patches.
Nota: nos exemplos anteriores, não foi utilizada uma captura de ecrã completa, no entanto, TODOS os ISV submetidos
as capturas de ecrã de provas têm de ser capturas de ecrã completas que mostrem qualquer URL, utilizador com sessão iniciada e a data e hora do sistema.
Controlos de Segurança de Rede (NSC)
Os controlos de segurança de rede são um componente essencial das arquiteturas de cibersegurança, como a ISO 27001, os controlos CIS e o NIST Cybersecurity Framework. Ajudam as organizações a gerir riscos associados a ameaças cibernéticas, a proteger dados confidenciais contra acesso não autorizado, a cumprir os requisitos regulamentares, a detetar e a responder a ameaças cibernéticas em tempo útil e a garantir a continuidade do negócio. A segurança de rede eficaz protege os recursos organizacionais contra uma vasta gama de ameaças dentro ou fora da organização.
Controlo N.º 8
Forneça provas demonstráveis de que:
- Os Controlos de Segurança de Rede (NSC) são instalados no limite do ambiente no âmbito e instalados entre a rede de perímetro e as redes internas.
E se Híbrido, No Local, IaaS também fornecer provas de que:
- Todos os acessos públicos terminam na rede de perímetro.
Intenção: NSC
Este controlo visa confirmar que os Controlos de Segurança de Rede (NSC) estão instalados em localizações-chave na topologia de rede da organização. Especificamente, os NSCs têm de ser colocados no limite do ambiente no âmbito e entre a rede de perímetro e as redes internas. O objetivo deste controlo é confirmar que estes mecanismos de segurança estão corretamente situados para maximizar a sua eficácia na proteção dos recursos digitais da organização.
Diretrizes: NSC
Devem ser fornecidas provas para demonstrar que os Controlos de Segurança de Rede (NSC) estão instalados no limite e configurados entre o perímetro e as redes internas. Isto pode ser conseguido ao fornecer as capturas de ecrã das definições de configuração dos Controlos de Segurança de Rede (NSC) e do âmbito ao qual é aplicada, por exemplo, uma firewall ou tecnologia equivalente, como Grupos de Segurança de Rede do Azure (NSGs), Azure Front Door, etc.
Exemplo de evidência: NSC
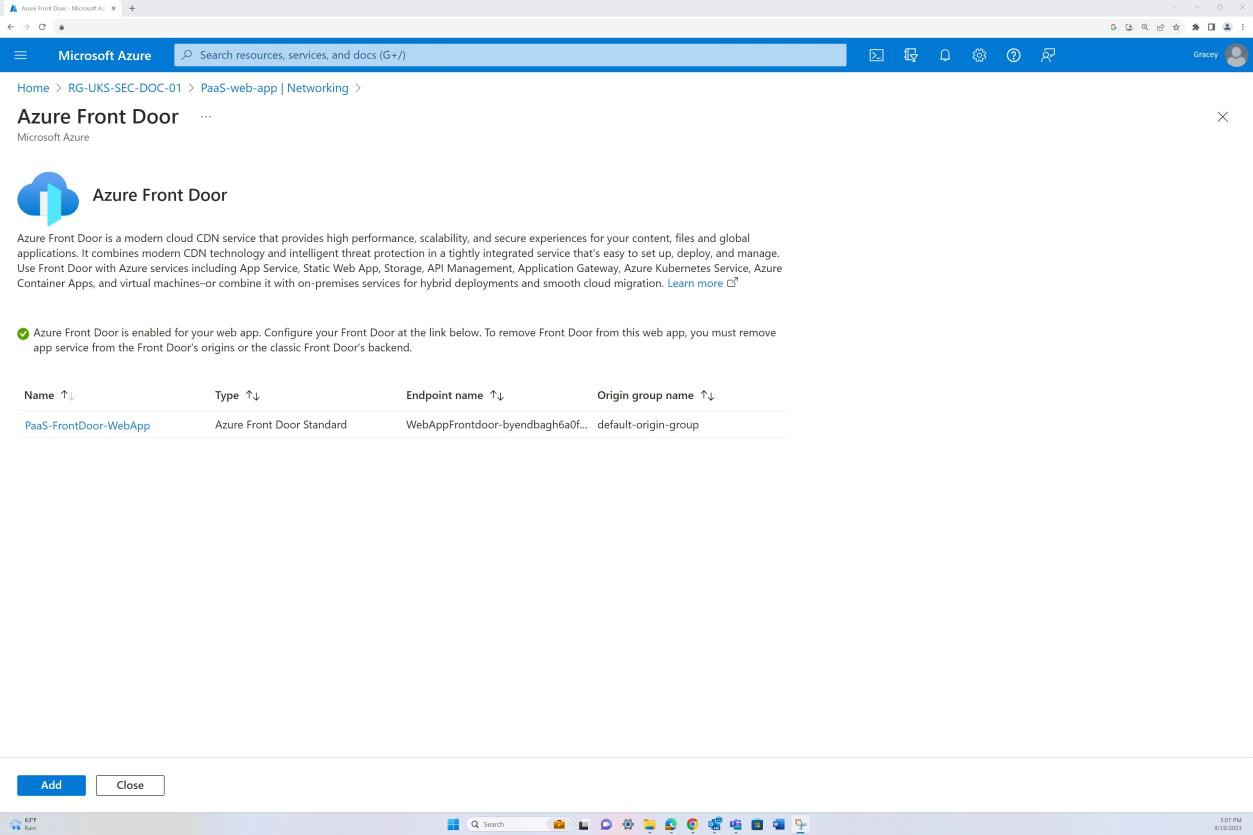
A captura de ecrã seguinte é da aplicação Web "PaaS-web-app"; O painel de rede demonstra que todo o tráfego de entrada está a passar pelo Azure Front Door, enquanto todo o tráfego da aplicação para outros recursos do Azure é encaminhado e filtrado através do NSG do Azure através da integração da VNET.
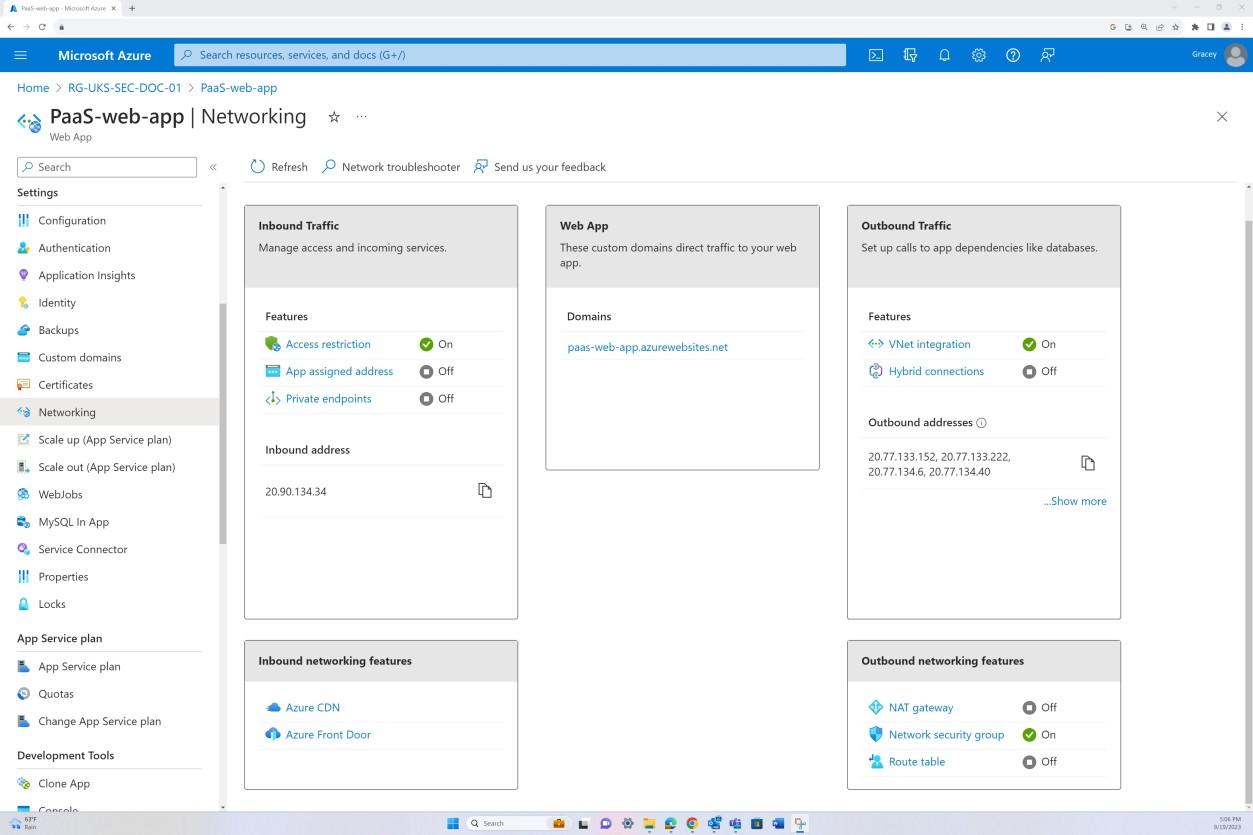
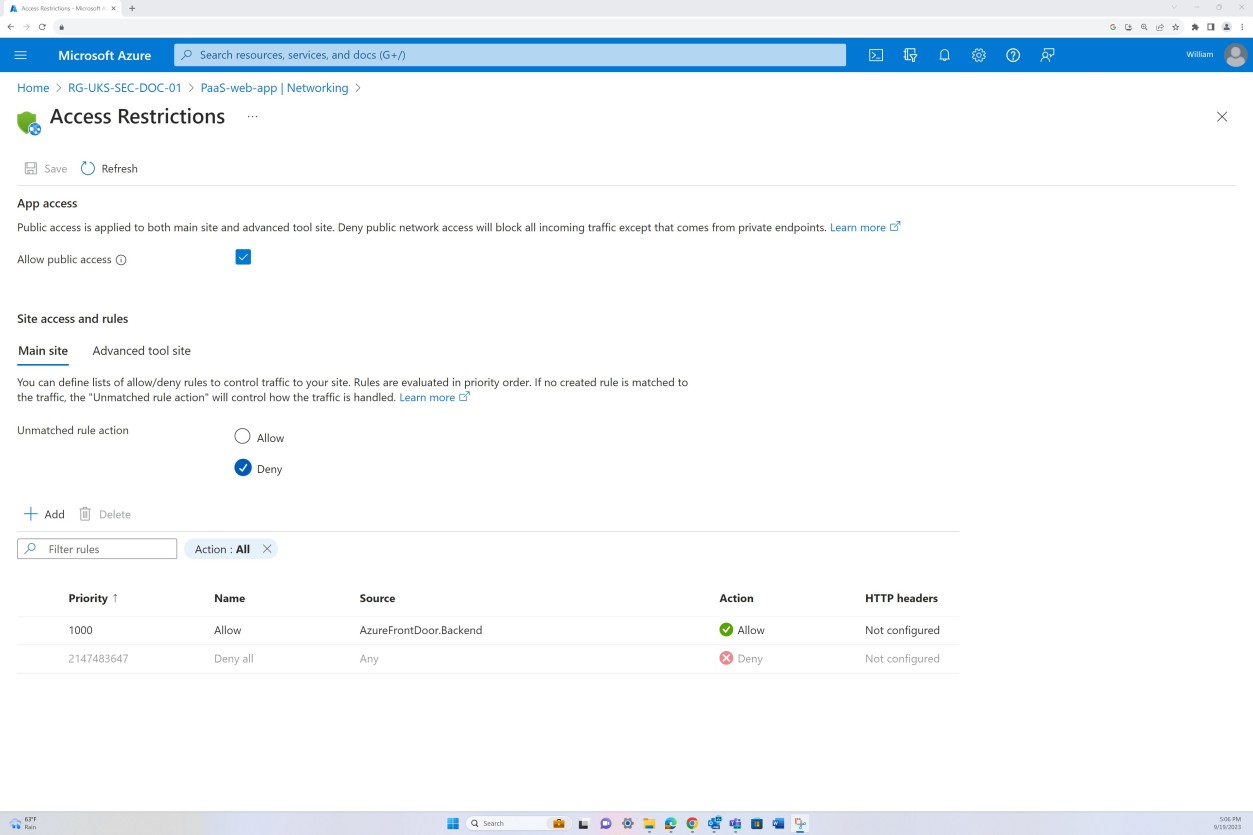
As regras de negação nas "Restrições de acesso" impedem qualquer entrada, exceto a partir do Front Door (FD), o tráfego é encaminhado através de FD antes de chegar à aplicação.
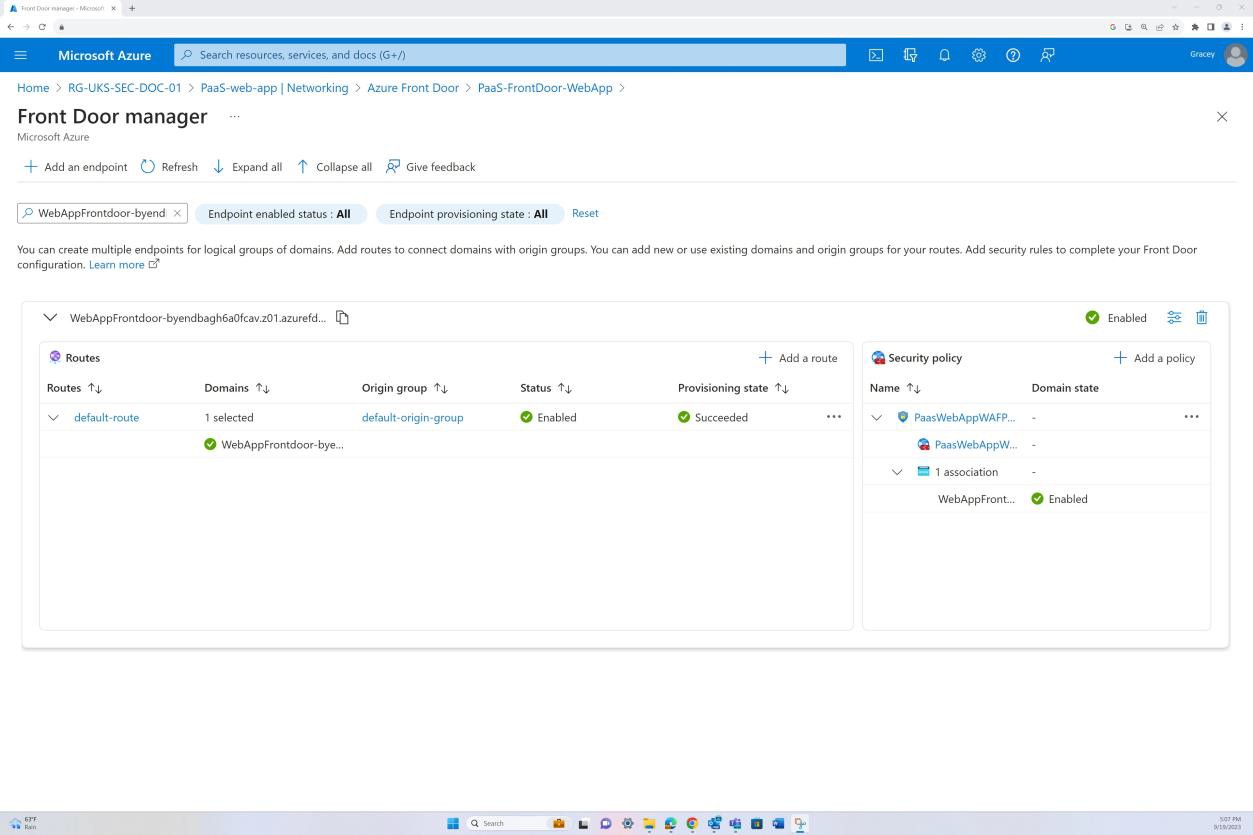
Exemplo de evidência: NSC
A captura de ecrã seguinte mostra a rota predefinida do Azure Front Door e que o tráfego é encaminhado através do Front Door antes de chegar à aplicação. A política waf também foi aplicada.
Exemplo de evidência: NSC
A primeira captura de ecrã mostra um Grupo de Segurança de Rede do Azure aplicado ao nível da VNET para filtrar o tráfego de entrada e saída. A segunda captura de ecrã demonstra que o SQL Server não é encaminhável através da Internet e está integrado através da VNET e através de uma ligação privada.
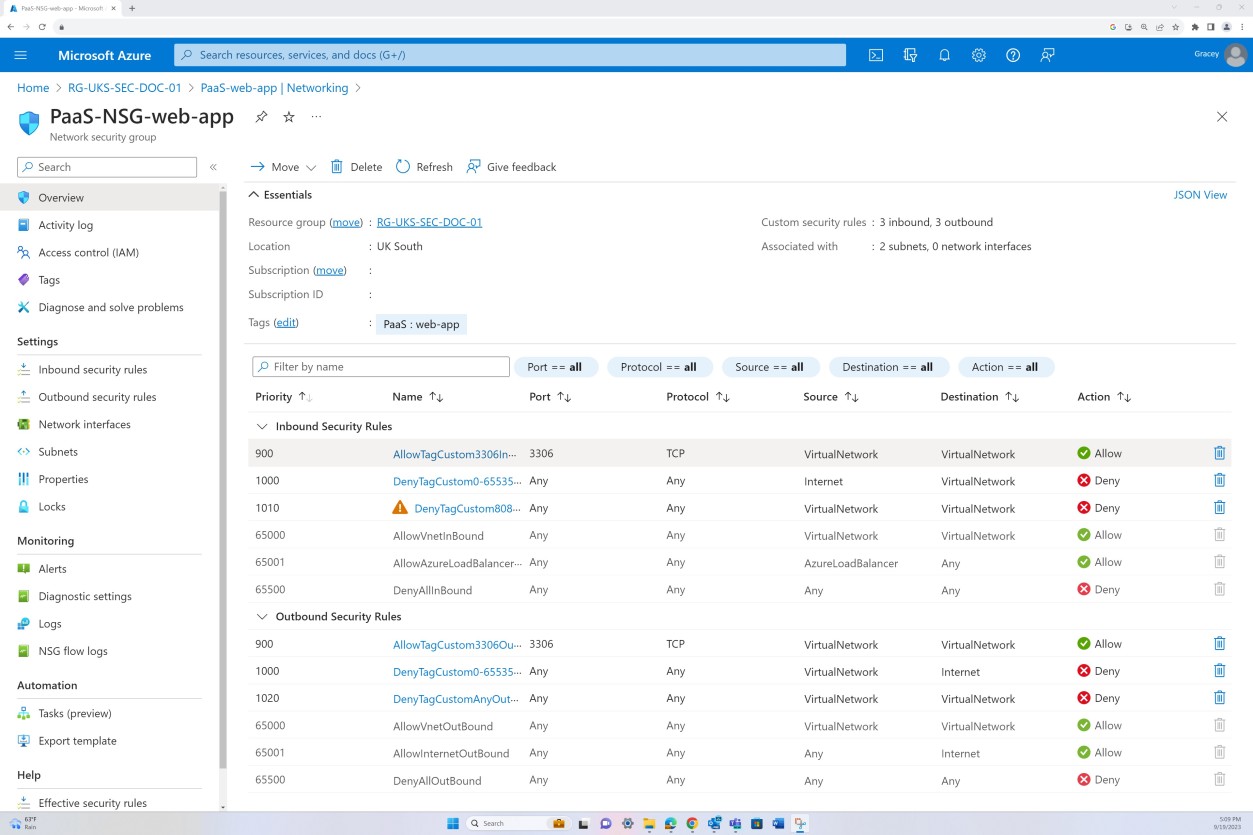
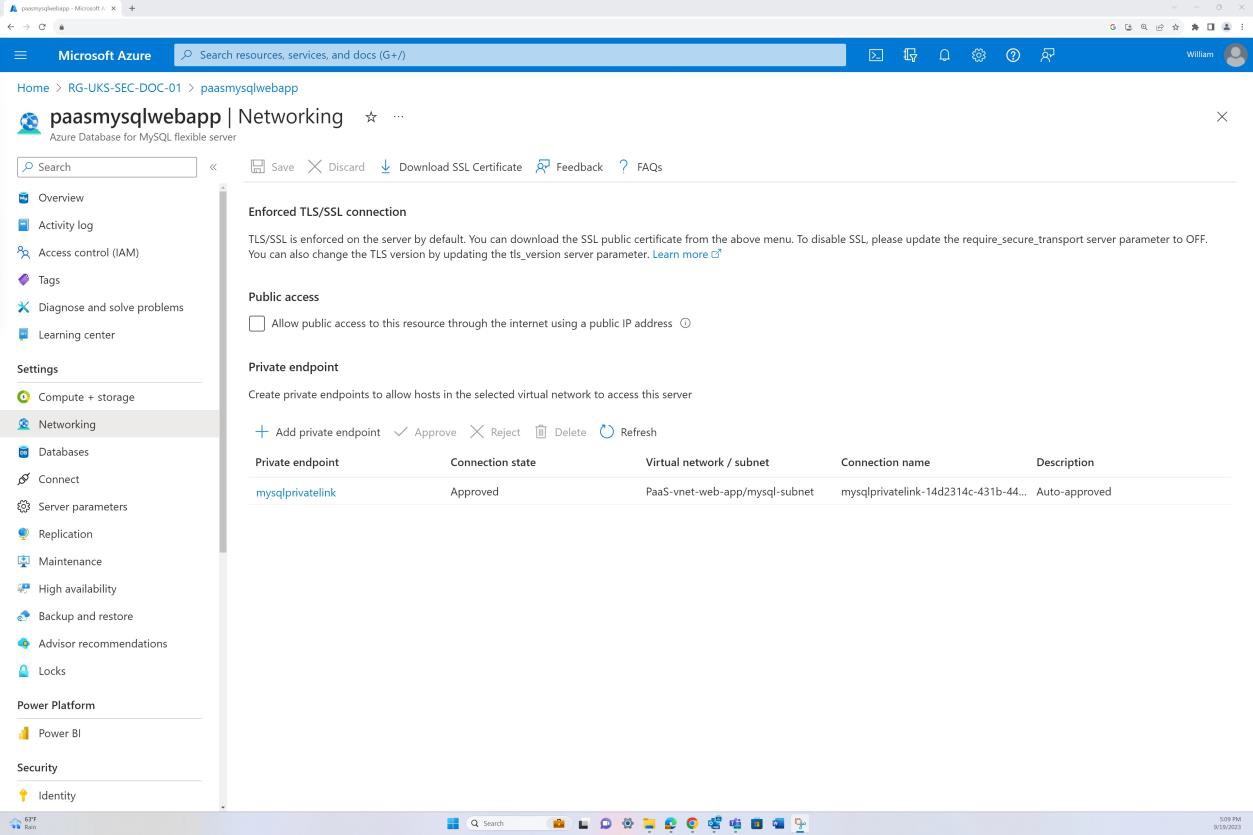
Isto garante que o tráfego interno e a comunicação são filtrados pelo NSG antes de chegar ao SQL Server.
Intent**:** híbrido, no local, IaaS
Este subponto é essencial para organizações que operam modelos híbridos, no local ou de Infraestrutura como serviço (IaaS). Procura garantir que todos os acessos públicos terminem na rede de perímetro, o que é crucial para controlar os pontos de entrada na rede interna e reduzir a exposição potencial a ameaças externas. As provas de conformidade podem incluir configurações de firewall, listas de controlo de acesso à rede ou outra documentação semelhante que possa fundamentar a afirmação de que o acesso público não se estende para além da rede de perímetro.
Exemplo de evidência: híbrido, no local, IaaS
A captura de ecrã demonstra que o SQL Server não é encaminhável através da Internet e está integrado através da VNET e através de uma ligação privada. Isto garante que apenas é permitido tráfego interno.
Exemplo de evidência: híbrido, no local, IaaS
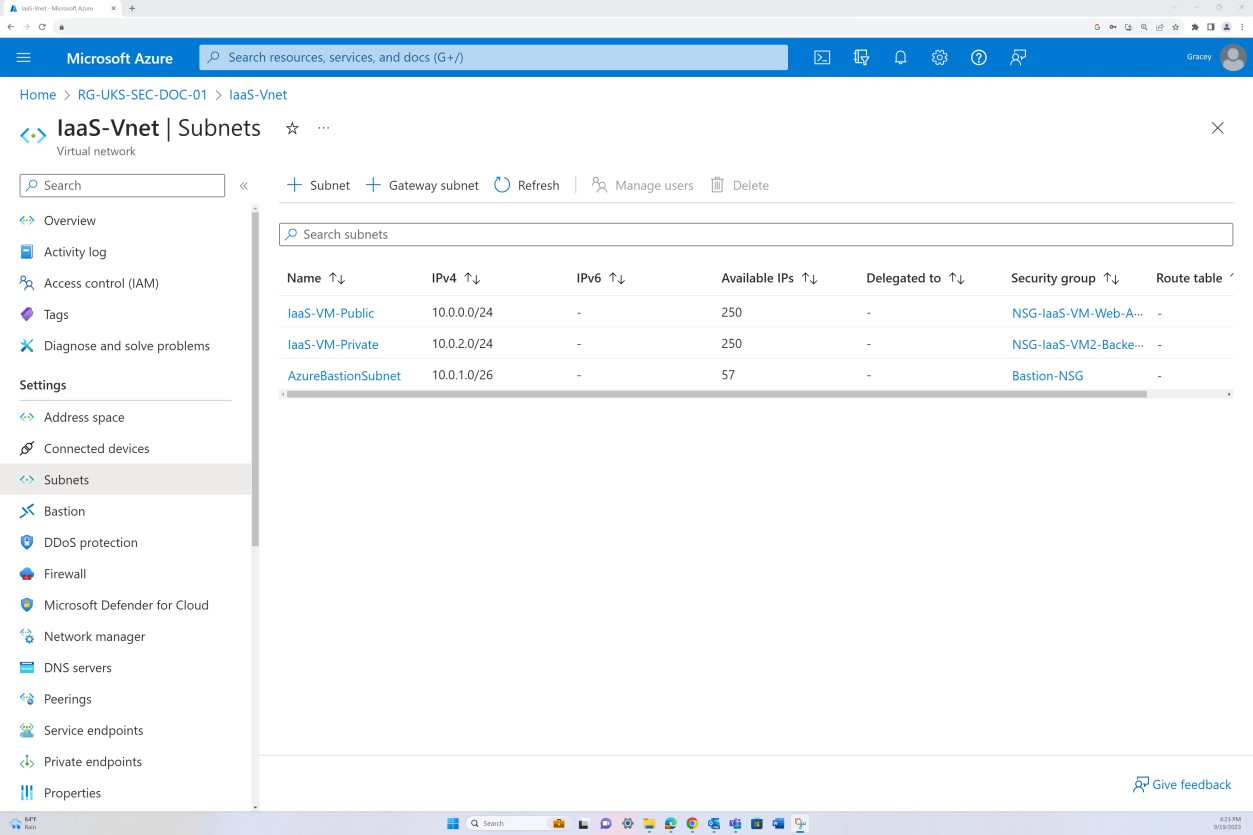
As capturas de ecrã seguintes demonstram que a segmentação de rede está em vigor na rede virtual no âmbito. A VNET, conforme mostrado a seguir, está dividida em três sub-redes, cada uma com um NSG aplicado.
A sub-rede pública funciona como a rede de perímetro. Todo o tráfego público é encaminhado através desta sub-rede e filtrado através do NSG com regras específicas e só é permitido tráfego explicitamente definido. O back-end consiste na sub-rede privada sem acesso público. Todo o acesso à VM só é permitido através do Anfitrião do Bastion, que tem o seu próprio NSG aplicado ao nível da sub-rede.
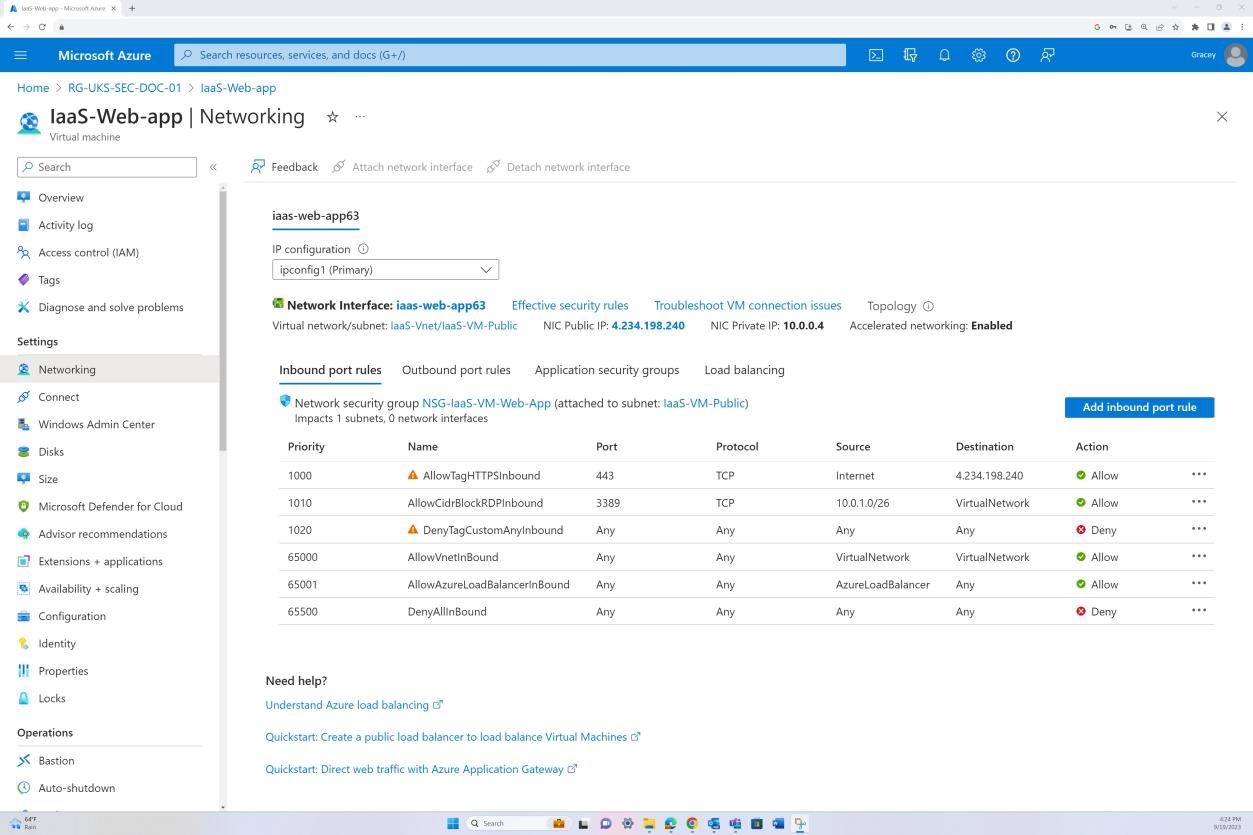
A captura de ecrã seguinte mostra que o tráfego é permitido da Internet para um endereço IP específico apenas na porta 443. Além disso, o RDP só é permitido a partir do intervalo de IP do Bastion para a rede virtual.
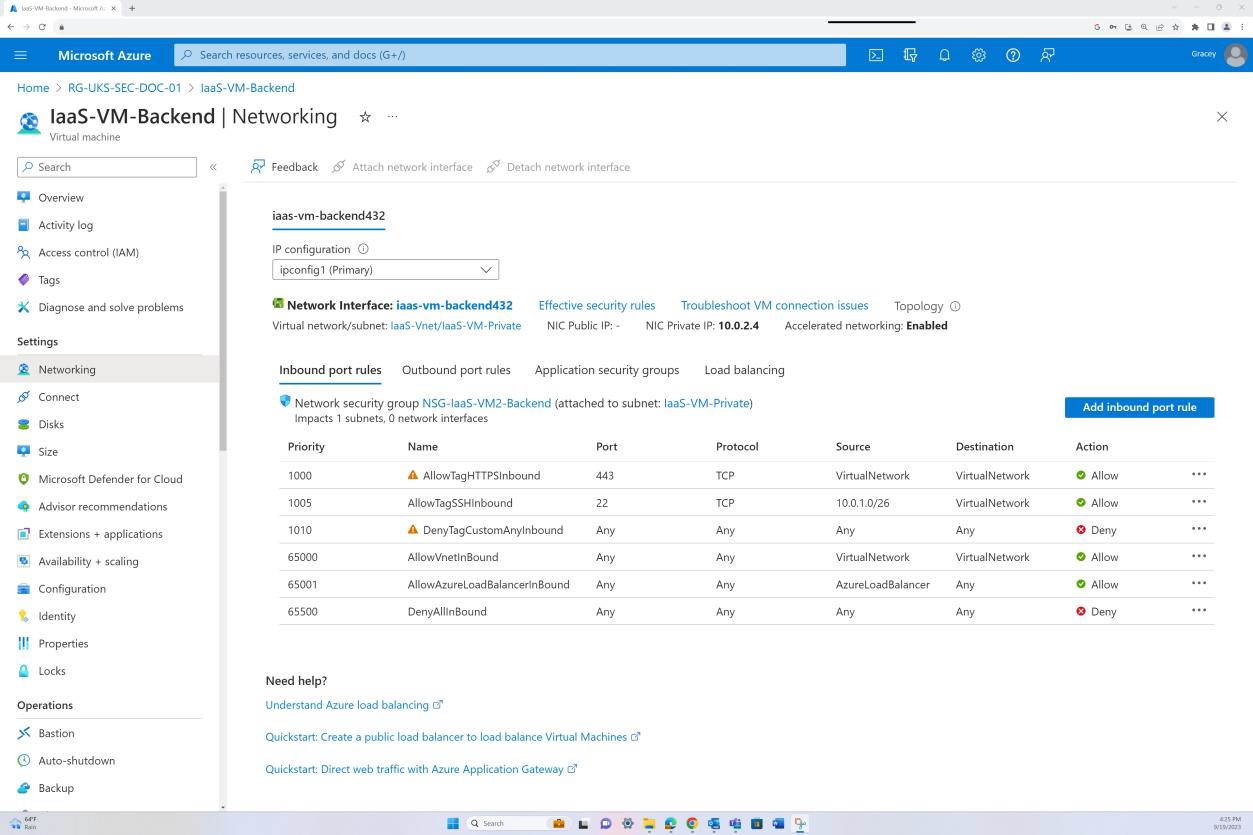
A captura de ecrã seguinte demonstra que o back-end não é encaminhável através da Internet (isto deve-se ao facto de não existir nenhum IP público para a NIC) e que o tráfego só tem permissão para ter origem na Rede Virtual e no Bastion.
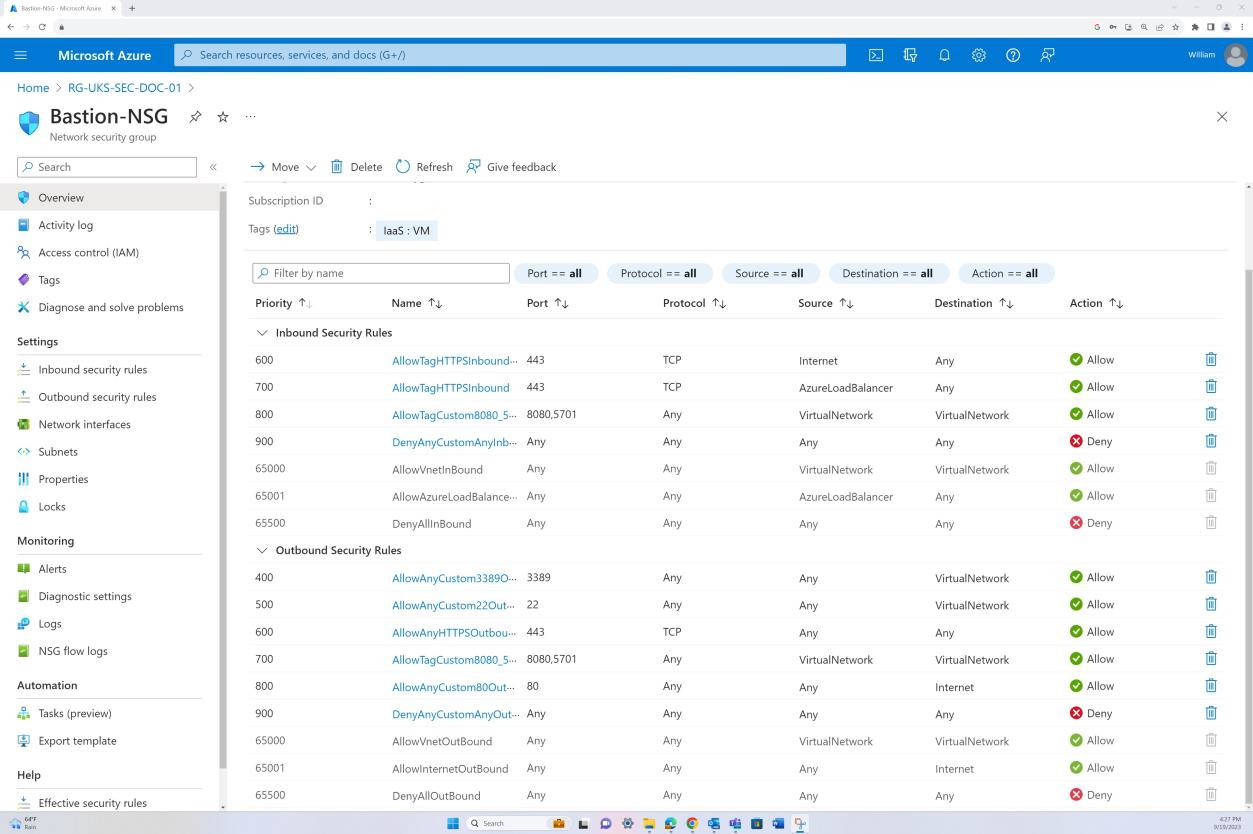
A captura de ecrã demonstra que o anfitrião do Azure Bastion é utilizado para aceder apenas às máquinas virtuais para fins de manutenção.
Controlo N.º 9
Todos os Controlos de Segurança de Rede (NSC) estão configurados para remover o tráfego não explicitamente definido na base de regras.
As revisões de regras dos Controlos de Segurança de Rede (NSC) são realizadas pelo menos a cada 6 meses.
Intenção: NSC
Este subponto garante que todos os Controlos de Segurança de Rede (NSC) numa organização estão configurados para remover qualquer tráfego de rede que não esteja explicitamente definido na respetiva base de regras. O objetivo é impor o princípio do menor privilégio na camada de rede ao permitir apenas tráfego autorizado enquanto bloqueia todo o tráfego não especificado ou potencialmente malicioso.
Diretrizes: NSC
As provas fornecidas podem ser configurações de regras que mostram as regras de entrada e onde estas regras são terminadas; ao encaminhar endereços IP públicos para os recursos ou ao fornecer o NAT (Tradução de Endereços de Rede) do tráfego de entrada.
Exemplo de evidência: NSC
A captura de ecrã mostra a configuração do NSG, incluindo o conjunto de regras predefinidas e uma regra Negar:Todos personalizada para repor todas as regras predefinidas do NSG e garantir que todo o tráfego é proibido. Nas regras personalizadas adicionais, a regra Negar:Todos define explicitamente o tráfego permitido.
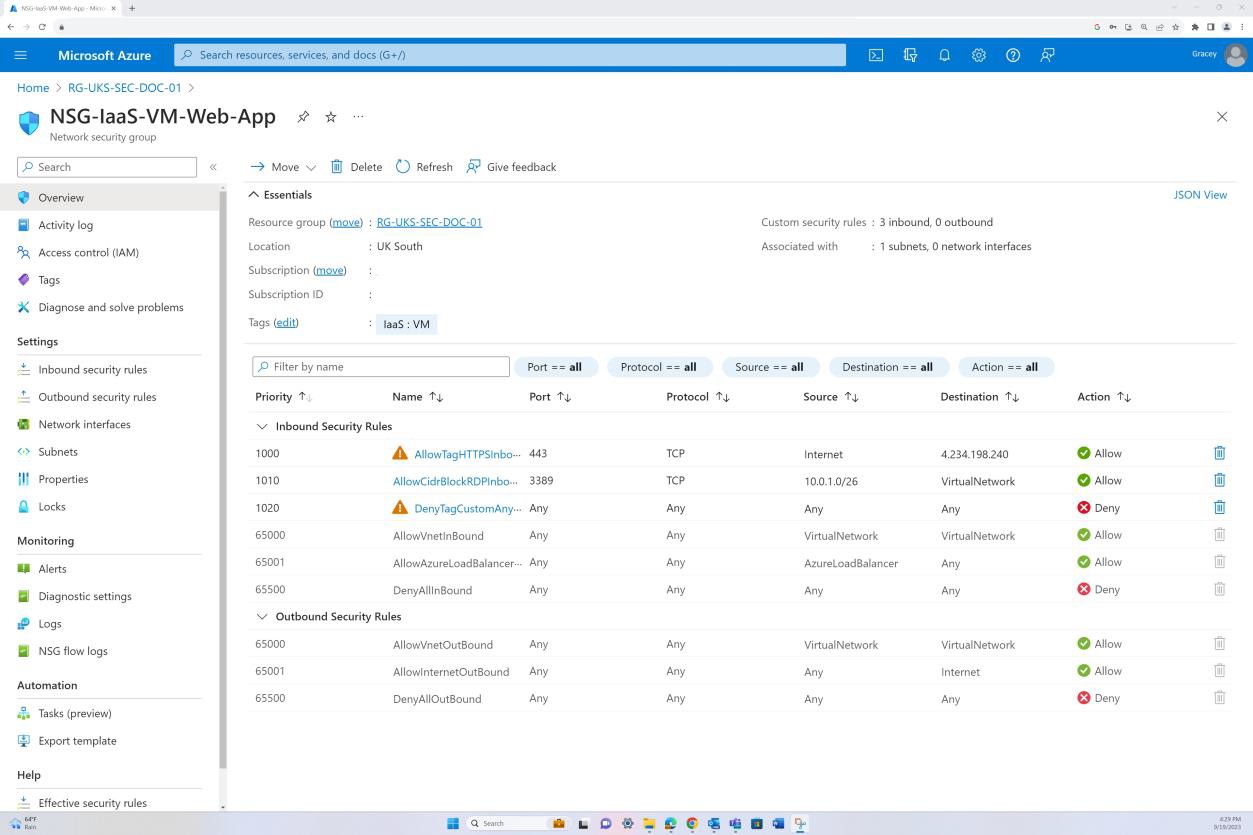
Exemplo de evidência: NSC
As capturas de ecrã seguintes mostram que o Azure Front Door está implementado e todo o tráfego é encaminhado através do Front Door. É aplicada uma Política de WAF no "Modo de Prevenção", que filtra o tráfego de entrada para potenciais payloads maliciosos e bloqueia-o.
Intenção: NSC
Sem revisões regulares, os Controlos de Segurança de Rede (NSC) podem tornar-se desatualizados e ineficazes, deixando uma organização vulnerável a ciberataques. Isto pode resultar em violações de dados, roubo de informações confidenciais e outros incidentes de cibersegurança. As revisões normais do NSC são essenciais para gerir riscos, proteger dados confidenciais, cumprir os requisitos regulamentares, detetar e responder a ameaças cibernéticas em tempo útil e garantir a continuidade do negócio. Este subponto requer que os Controlos de Segurança de Rede (NSC) sejam submetidos a revisões de base de regras pelo menos a cada seis meses. As revisões regulares são cruciais para manter a eficácia e a relevância das configurações do NSC, especialmente em ambientes de rede em mudança dinâmica.
Diretrizes: NSC
Quaisquer provas fornecidas têm de ser capazes de demonstrar que as reuniões de revisão de regras têm ocorrido. Isto pode ser feito ao partilhar as atas de reunião da revisão do NSC e quaisquer provas adicionais de controlo de alterações que mostrem quaisquer ações tomadas a partir da revisão. Certifique-se de que as datas estão presentes como o analista de certificação que revê a sua submissão teria de ver um mínimo de duas destas reuniões rever documentos (ou seja, a cada seis meses).
Exemplo de evidência: NSC
Estas capturas de ecrã demonstram que existem revisões de firewall de seis meses e que os detalhes são mantidos na plataforma Confluence Cloud.
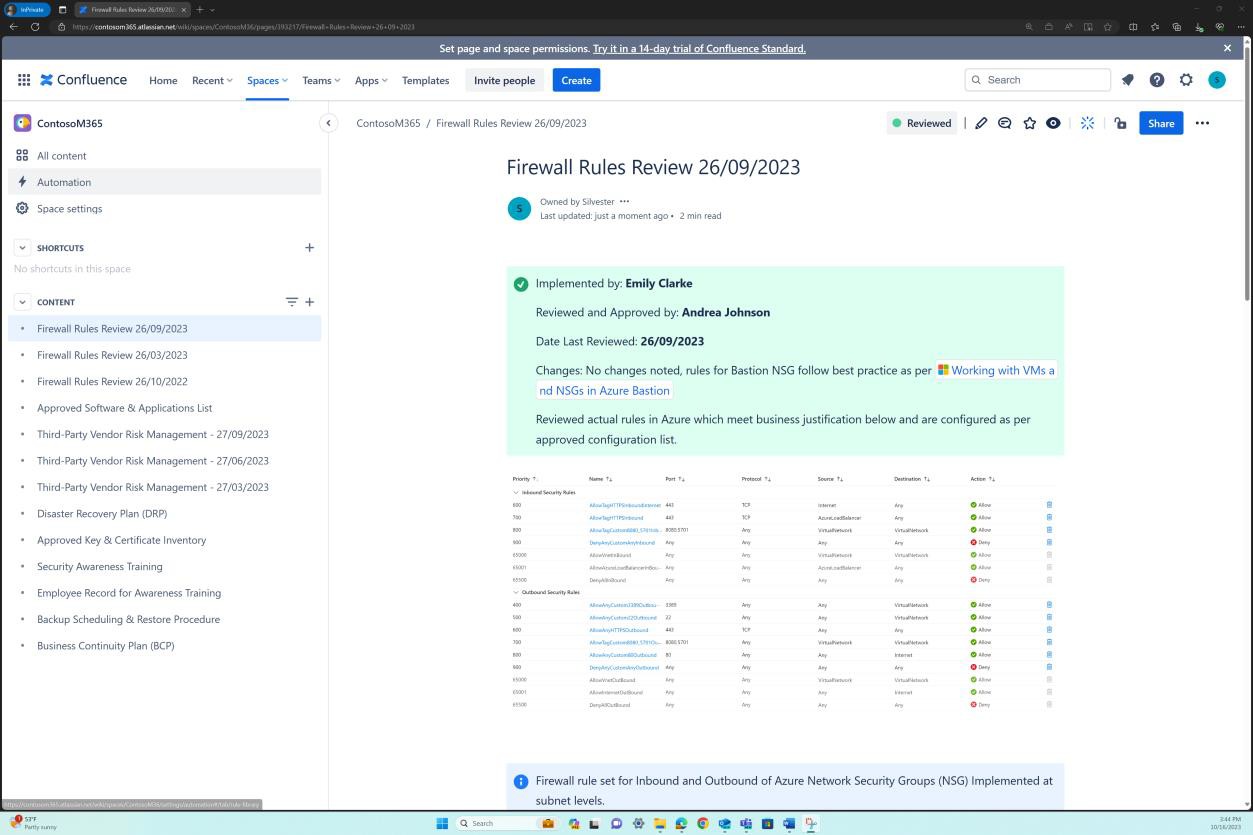
A captura de ecrã seguinte demonstra que cada revisão de regras tem uma página criada no Confluence. A revisão da regra contém uma lista de conjuntos de regras aprovada que descreve o tráfego permitido, o número da porta, o protocolo, etc. juntamente com a justificação comercial.
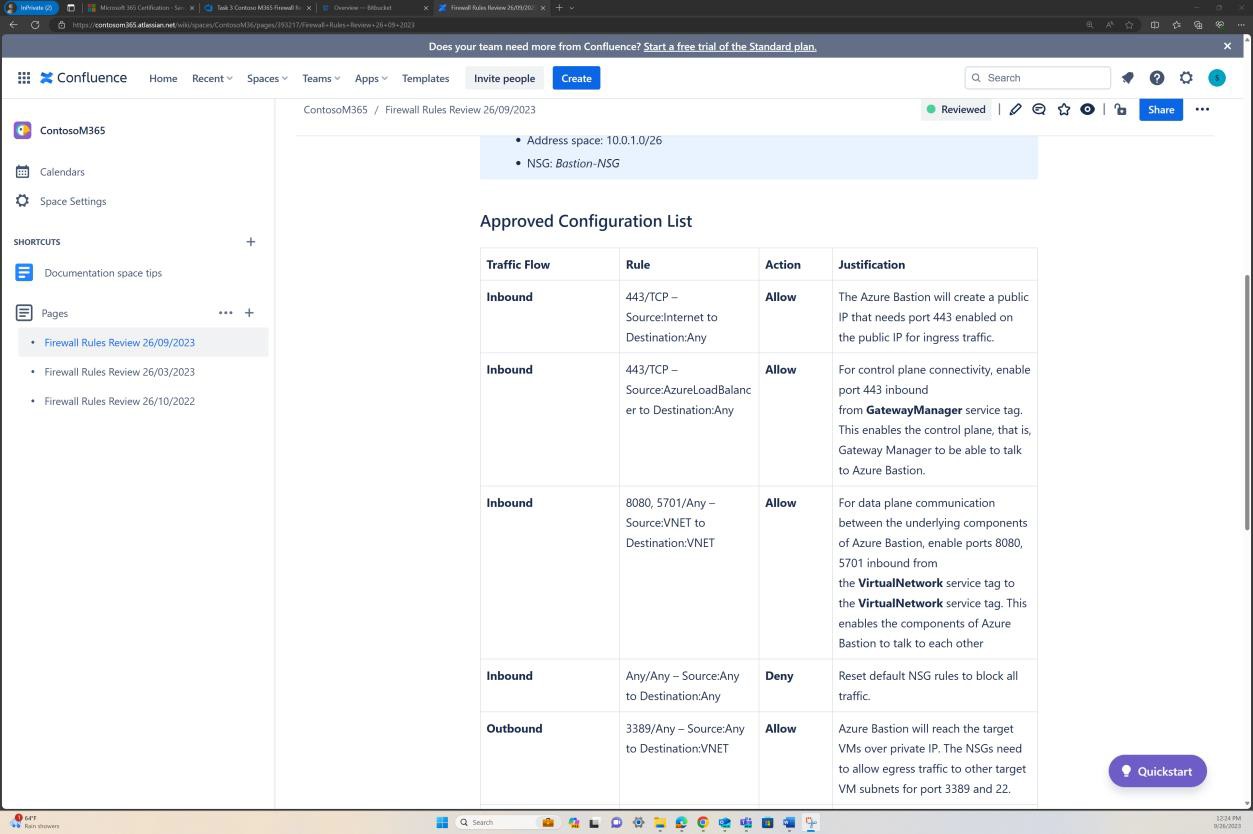
Exemplo de evidência: NSC
A captura de ecrã seguinte demonstra um exemplo alternativo de revisão de regras de seis meses a ser mantida no DevOps.
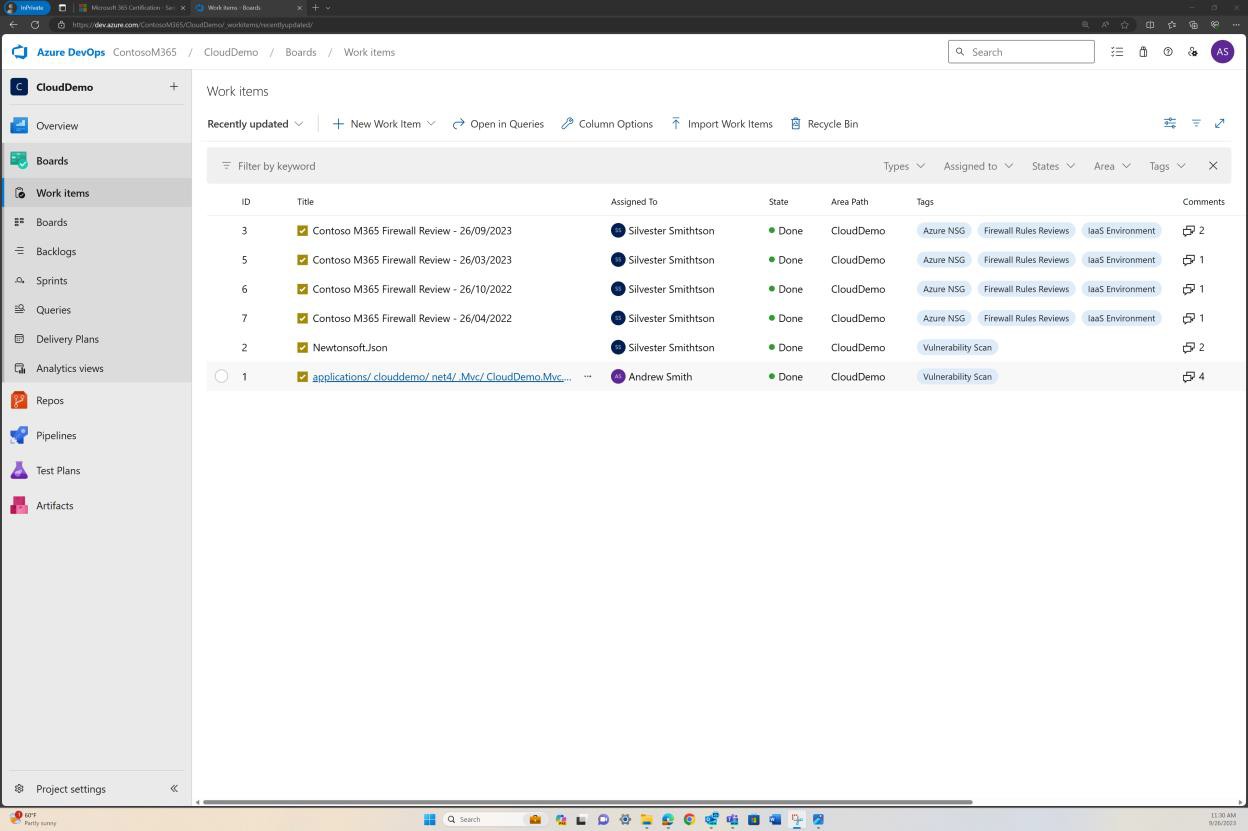
Exemplo de evidência: NSC
Esta captura de ecrã demonstra um exemplo de uma revisão de regras a ser executada e gravada como um pedido de suporte no DevOps.
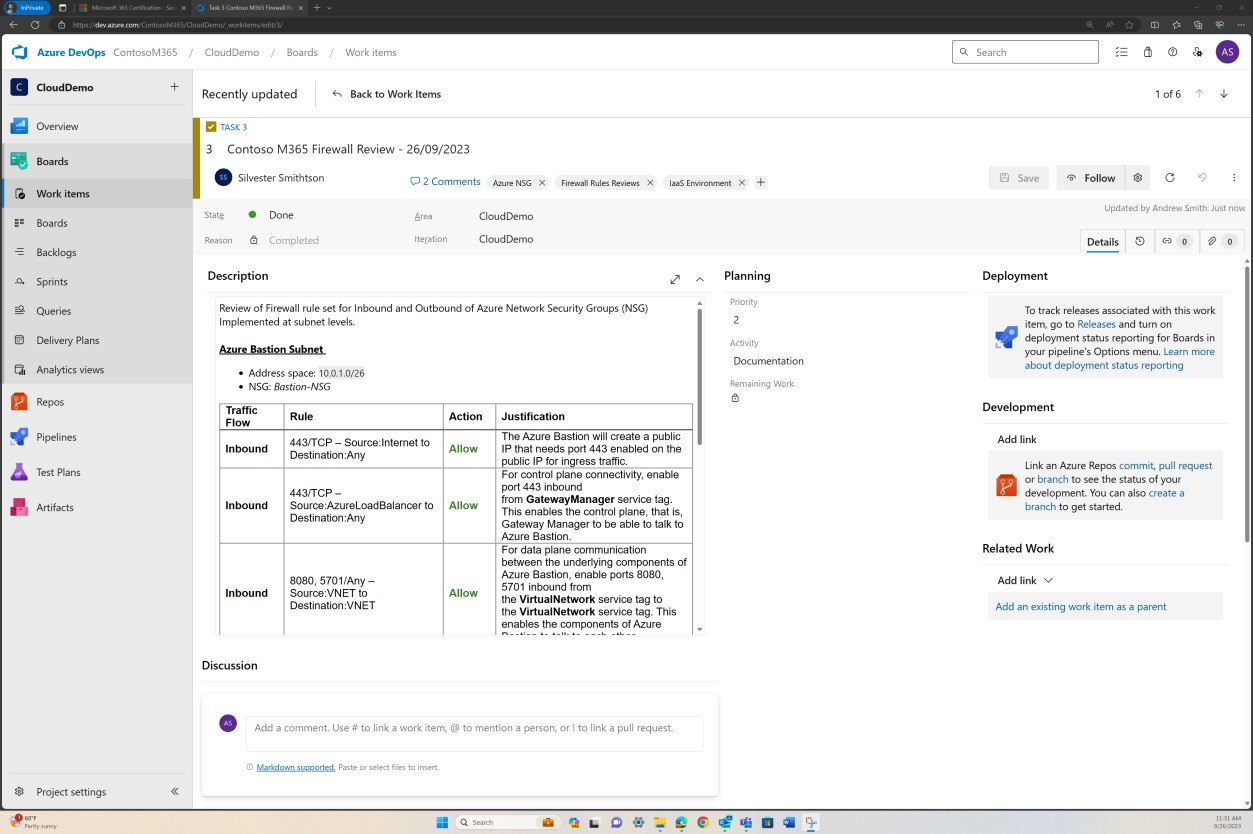
A captura de ecrã anterior mostra a lista de regras documentadas estabelecida juntamente com a justificação comercial, enquanto a imagem seguinte demonstra um instantâneo das regras dentro do pedido de suporte do sistema real.
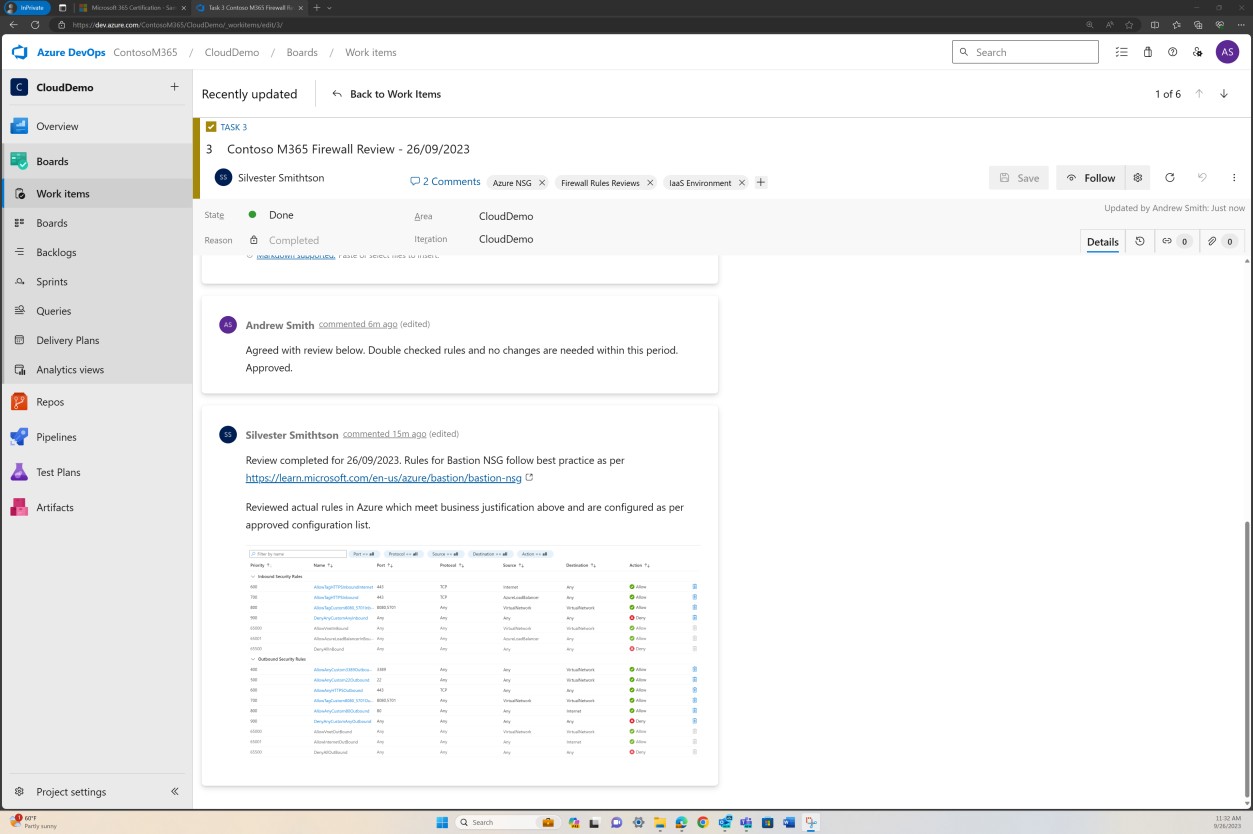
Alterar controlo
Um processo de controlo de alterações estabelecido e compreendido é essencial para garantir que todas as alterações passam por um processo estruturado que é repetível. Ao garantir que todas as alterações passam por um processo estruturado, as organizações podem garantir que as alterações são geridas de forma eficaz, revistas pelo elemento da rede e testadas adequadamente antes de serem assinadas. Isto não só ajuda a minimizar o risco de indisponibilidade do sistema, como também ajuda a minimizar o risco de potenciais incidentes de segurança através da introdução de alterações inadequadas.
Controlo N.º 10
Forneça provas que demonstrem que:
Quaisquer alterações introduzidas nos ambientes de produção são implementadas através de pedidos de alteração documentados que contêm:
impacto da alteração.
detalhes dos procedimentos de back-out.
testes a serem realizados.
revisão e aprovação por pessoal autorizado.
Intenção: alterar o controlo
O objetivo deste controlo é garantir que todas as alterações pedidas foram cuidadosamente consideradas e documentadas. Isto inclui avaliar o impacto da alteração na segurança do sistema/ambiente, documentar quaisquer procedimentos de back-out para ajudar na recuperação se algo correr mal e detalhar os testes necessários para validar o sucesso da alteração.
Devem ser implementados processos que proíbam a realização de alterações sem autorização adequada e a sua autorização. A alteração tem de ser autorizada antes de ser implementada e a alteração tem de ser assinada depois de concluída. Isto garante que os pedidos de alteração foram devidamente revistos e que alguém na autoridade assinou a alteração.
Diretrizes: alterar o controlo
As provas podem ser fornecidas através da partilha de capturas de ecrã de uma amostra de pedidos de alteração que demonstram que os detalhes do impacto da alteração, procedimentos de back-out, testes são mantidos no pedido de alteração.
Exemplo de evidência: alterar o controlo
A captura de ecrã seguinte mostra uma nova Vulnerabilidade de Scripting entre Sites (XSS) a ser atribuída e um documento para pedido de alteração. Os bilhetes abaixo demonstram as informações que foram definidas ou adicionadas ao bilhete na sua viagem para serem resolvidos.
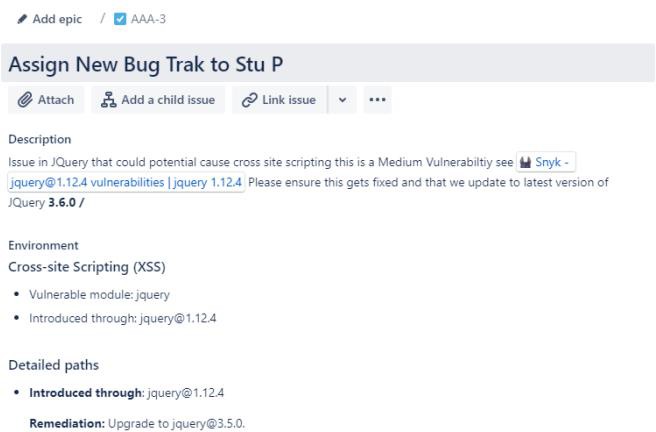
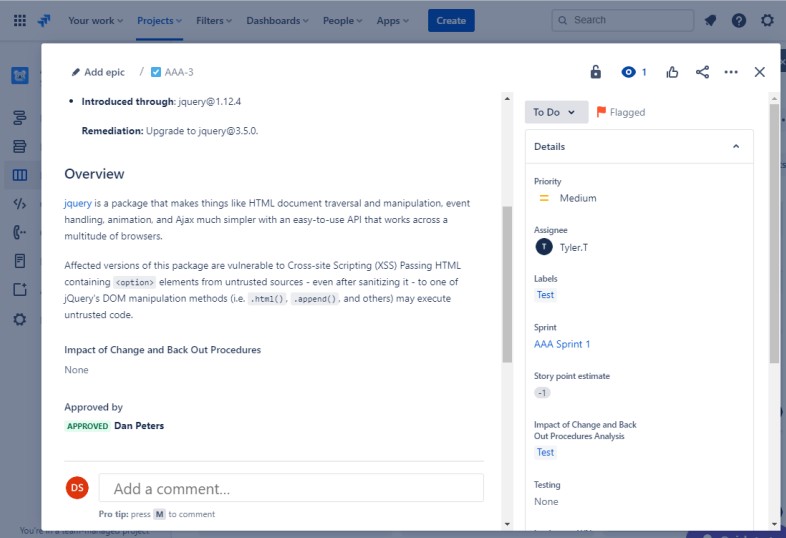
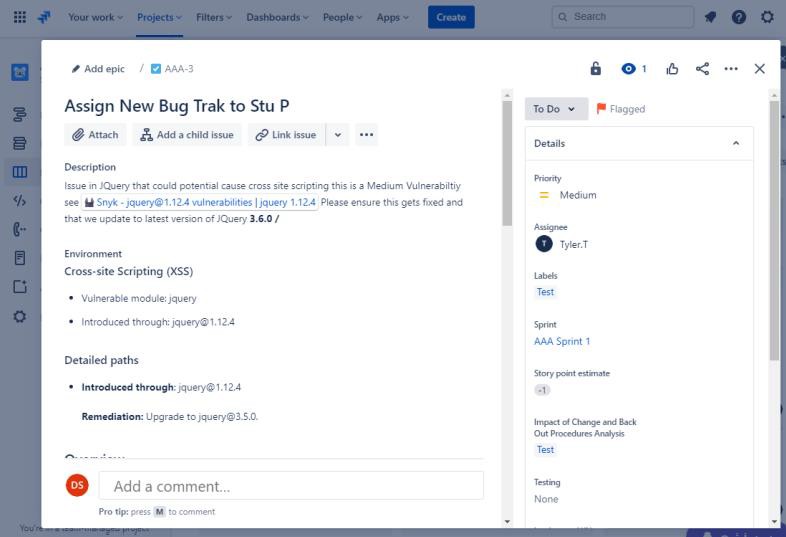
Os dois bilhetes seguintes mostram o impacto da alteração no sistema e os procedimentos de recuo que podem ser necessários em caso de problema. O impacto das alterações e dos procedimentos de recuo passou por um processo de aprovação e foi aprovado para testes.
Na captura de ecrã seguinte, o teste das alterações foi aprovado e, à direita, verá que as alterações foram agora aprovadas e testadas.
Ao longo do processo, tenha em atenção que a pessoa que está a fazer o trabalho, a pessoa que o reporta e a pessoa que aprova o trabalho a fazer são pessoas diferentes.
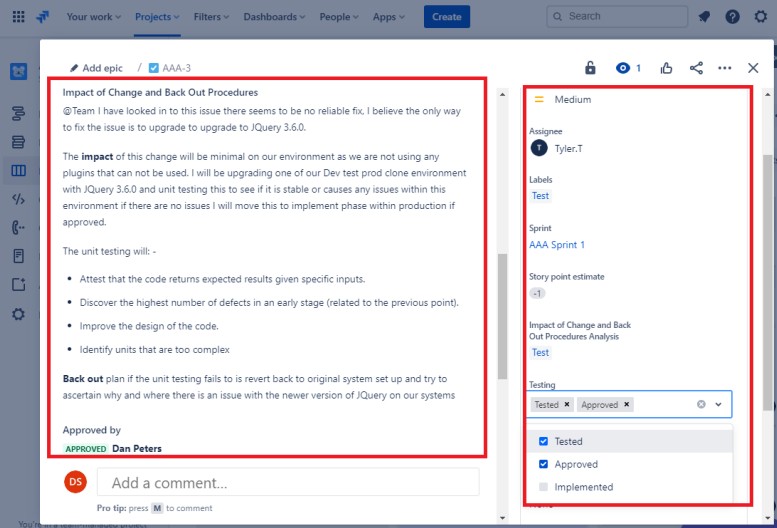
O pedido seguinte mostra que as alterações foram agora aprovadas para implementação no ambiente de produção. A caixa do lado direito mostra que o teste funcionou e foi bem-sucedido e que as alterações foram agora implementadas no Ambiente Prod.
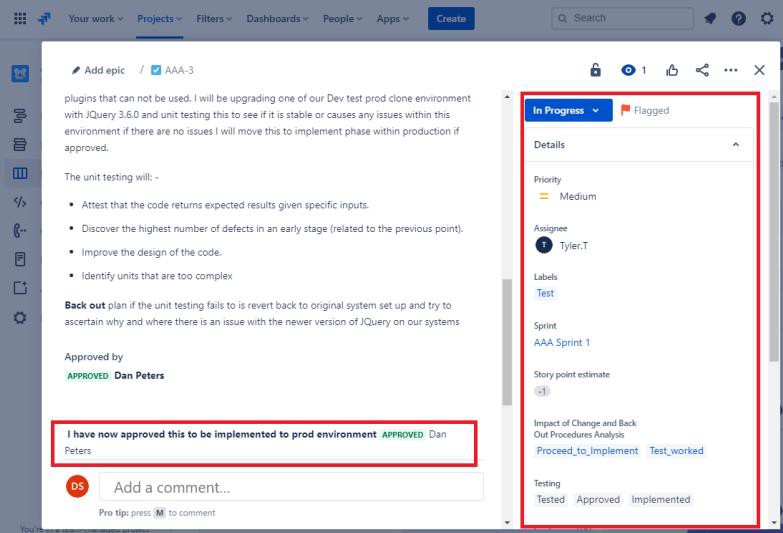
Exemplo de provas
As capturas de ecrã seguintes mostram um pedido Jira de exemplo que mostra que a alteração tem de ser autorizada antes de ser implementada e aprovada por outra pessoa que não seja o programador/requerente. As alterações são aprovadas por alguém com autoridade. O lado direito da captura de ecrã mostra que a alteração foi assinada pelo DP depois de concluída.
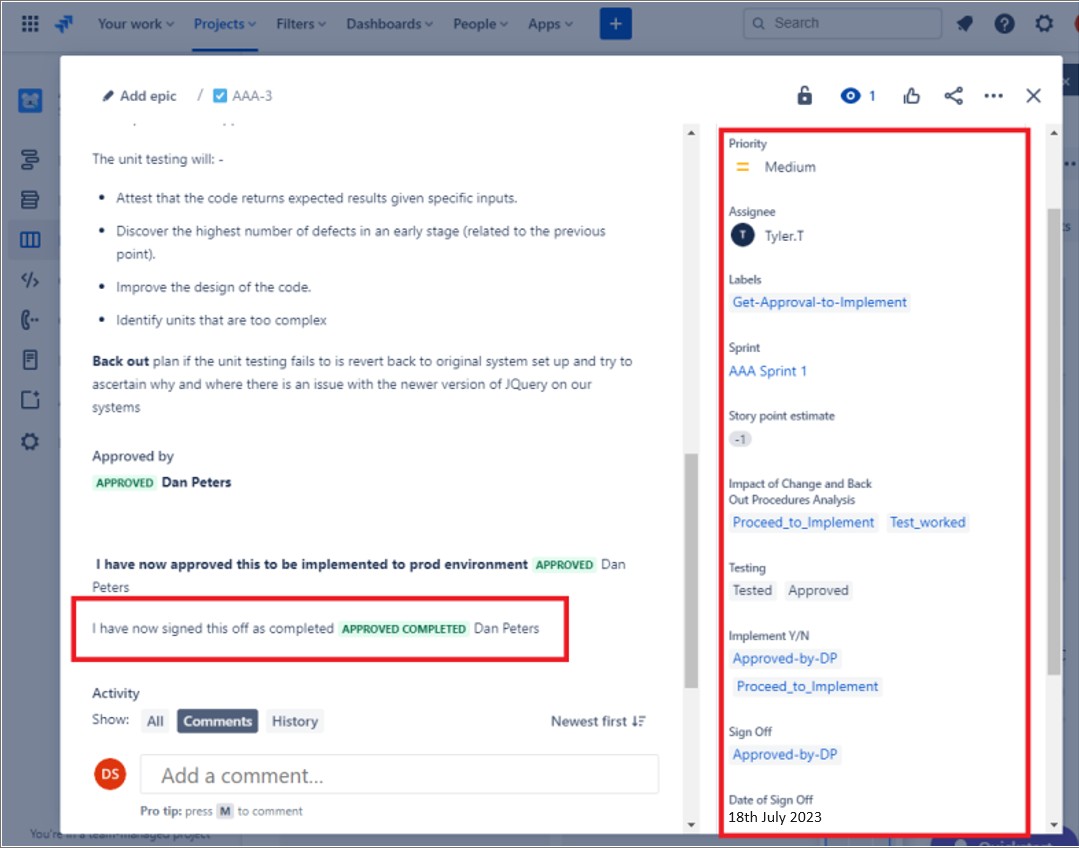
No pedido de suporte que se segue, a alteração foi terminada depois de concluída e mostra a tarefa concluída e fechada.
Nota: nestes exemplos, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem qualquer URL, utilizador com sessão iniciada e a hora e data do sistema.
Controlo N.º 11
Forneça provas de que:
Existem ambientes separados para que:
Os ambientes de desenvolvimento e teste/teste impõem a separação de deveres do ambiente de produção.
A separação de deveres é imposta através de controlos de acesso.
Os dados de produção confidenciais não estão a ser utilizados nos ambientes de desenvolvimento ou teste/teste.
Intenção: ambientes separados
Os ambientes de desenvolvimento/teste da maioria das organizações não estão configurados com o mesmo vigor que os ambientes de produção e, portanto, são menos seguros. Além disso, os testes não devem ser realizados no ambiente de produção, uma vez que isto pode introduzir problemas de segurança ou pode ser prejudicial para a entrega de serviços para os clientes. Ao manter ambientes separados que impõem uma separação de deveres, as organizações podem garantir que as alterações estão a ser aplicadas aos ambientes corretos, reduzindo assim o risco de erros ao implementar alterações nos ambientes de produção quando se destinava ao ambiente de desenvolvimento/teste.
Os controlos de acesso devem ser configurados de modo a que o pessoal responsável pelo desenvolvimento e teste não tenha acesso desnecessário ao ambiente de produção e vice-versa. Isto minimiza o potencial de alterações não autorizadas ou exposição de dados.
A utilização de dados de produção em ambientes de desenvolvimento/teste pode aumentar o risco de um compromisso e expor a organização a violações de dados ou acesso não autorizado. A intenção requer que todos os dados utilizados para desenvolvimento ou teste sejam sanitizados, anonimizados ou gerados especificamente para esse fim.
Diretrizes: ambientes separados
Podem ser fornecidas capturas de ecrã que demonstram diferentes ambientes que estão a ser utilizados para ambientes de desenvolvimento/teste e ambientes de produção. Normalmente, teria pessoas/equipas diferentes com acesso a cada ambiente ou, se tal não fosse possível, os ambientes utilizariam diferentes serviços de autorização para garantir que os utilizadores não podem iniciar sessão no ambiente errado por engano para aplicar alterações.
Exemplo de evidência: ambientes separados
As capturas de ecrã seguintes demonstram que os ambientes para desenvolvimento/teste estão separados da produção, o que é conseguido através de Grupos de Recursos no Azure, que é uma forma de agrupar recursos lógicos num contentor. Outras formas de alcançar a separação podem ser diferentes Subscrições do Azure, Redes e Sub-redes, etc.
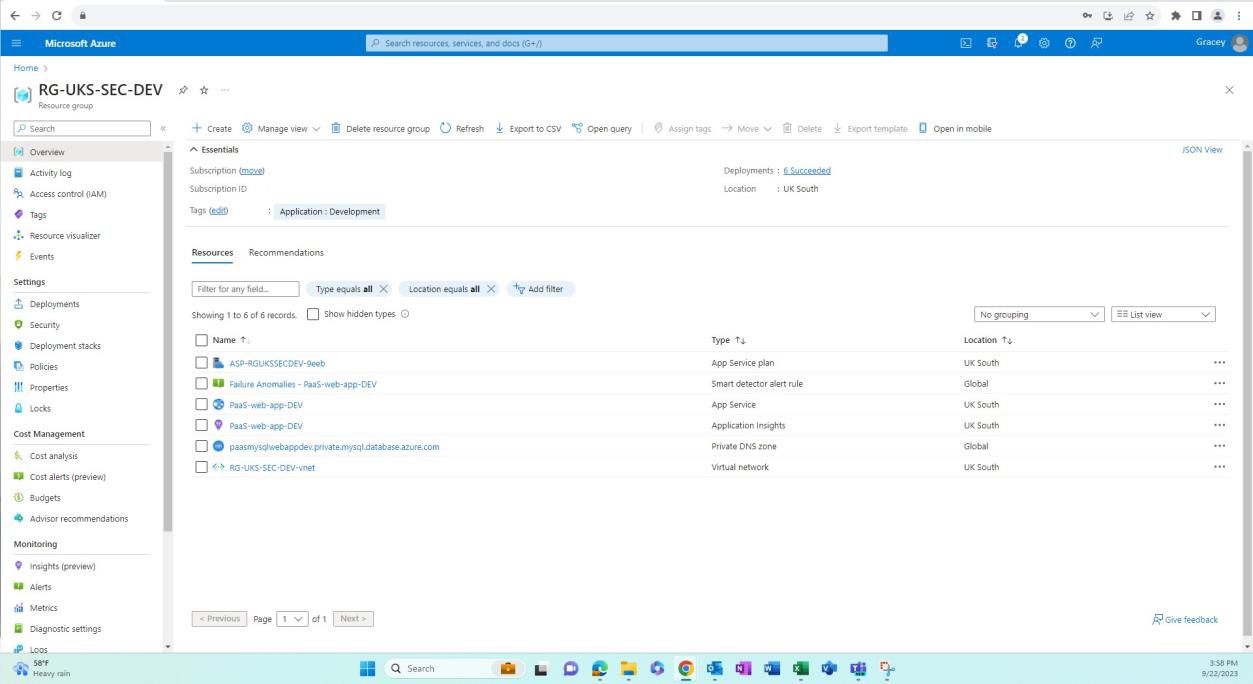
A captura de ecrã seguinte mostra o ambiente de desenvolvimento e os recursos neste grupo de recursos.
A captura de ecrã seguinte mostra o ambiente de produção e os recursos neste grupo de recursos.
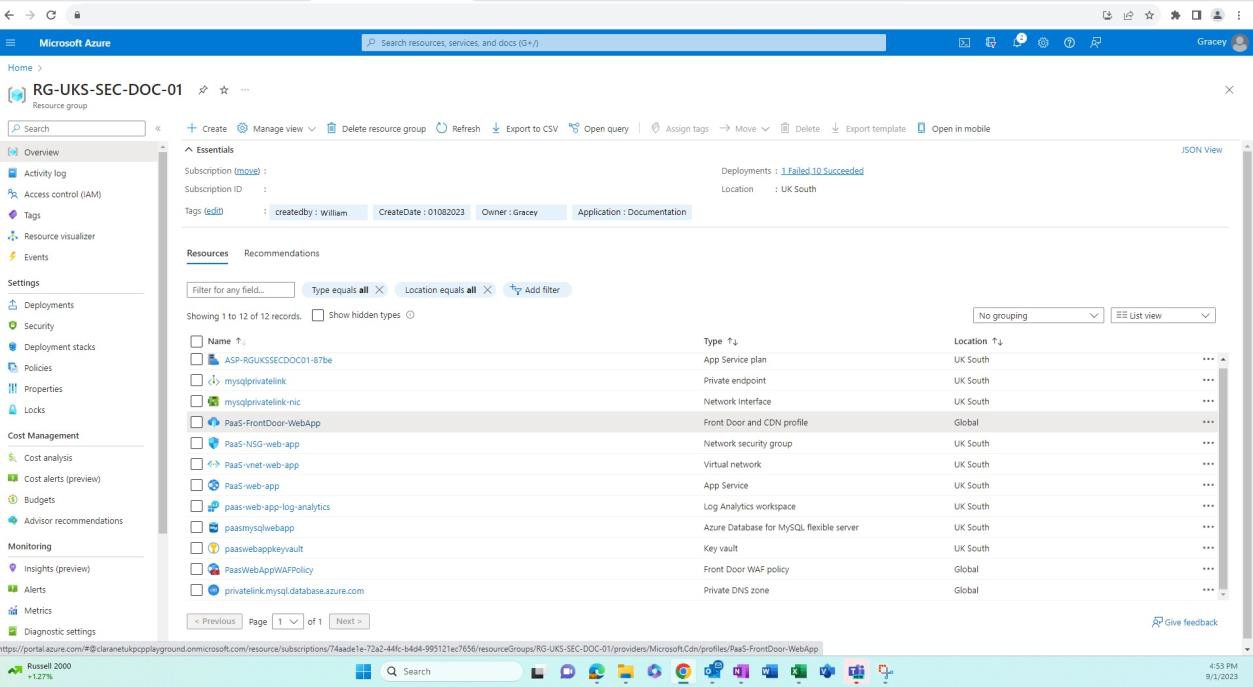
Exemplo de provas:
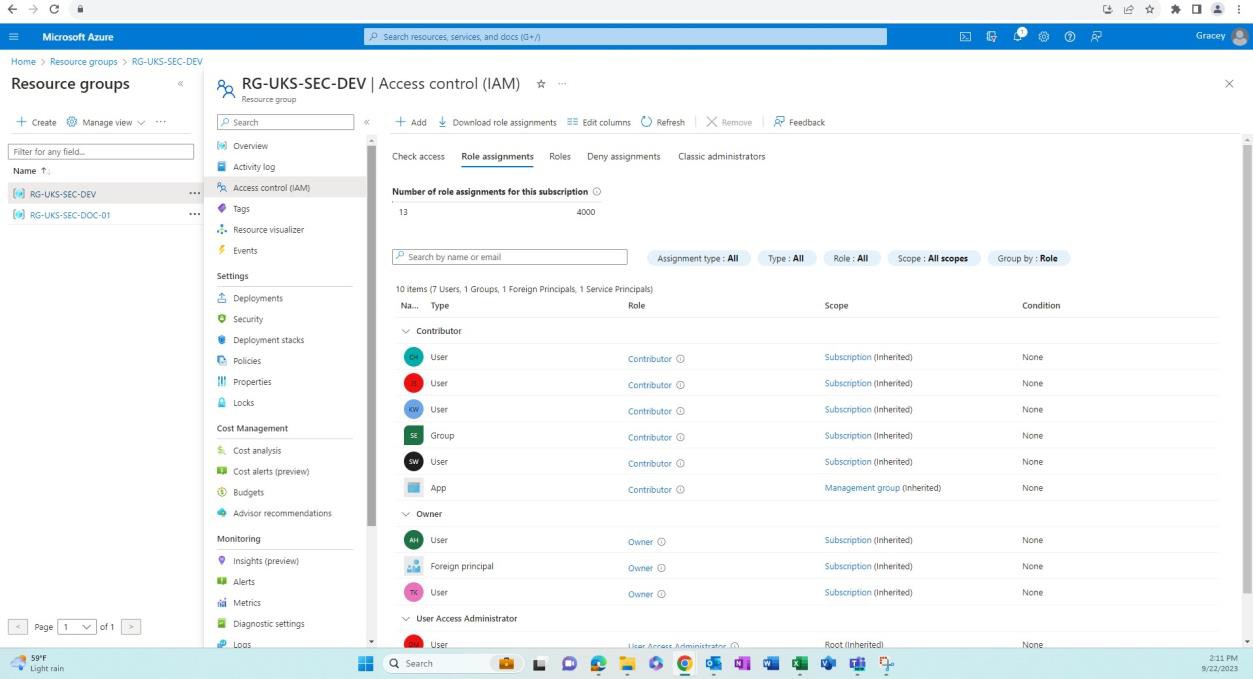
As capturas de ecrã seguintes demonstram que os ambientes para desenvolvimento/teste são separados do ambiente de produção. A separação adequada de ambientes é obtida através de diferentes utilizadores/grupos com permissões diferentes associadas a cada ambiente.
A captura de ecrã seguinte mostra o ambiente de desenvolvimento e os utilizadores com acesso a este grupo de recursos.
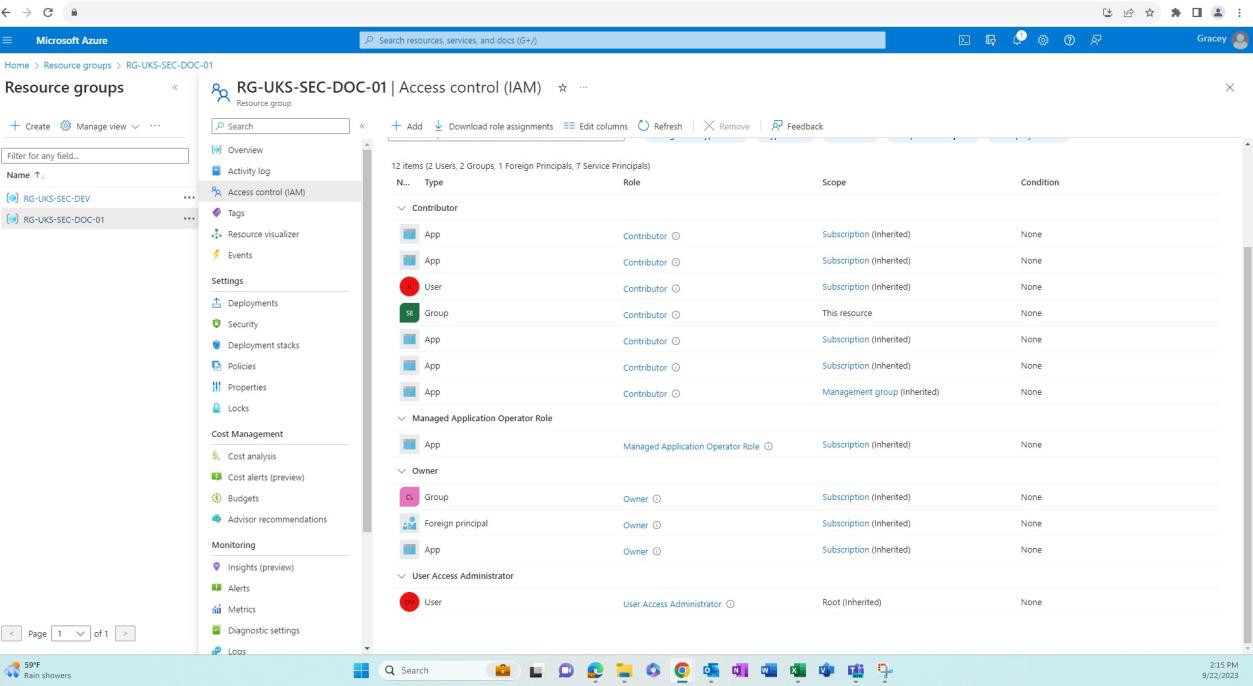
A captura de ecrã seguinte mostra o ambiente de produção e os utilizadores (diferentes do ambiente de desenvolvimento) que têm acesso a este grupo de recursos.
Diretrizes:
As provas podem ser fornecidas através da partilha de capturas de ecrã da saída da mesma consulta SQL numa base de dados de produção (redigir informações confidenciais) e da base de dados de desenvolvimento/teste. O resultado dos mesmos comandos deve produzir conjuntos de dados diferentes. Quando os ficheiros estão a ser armazenados, a visualização do conteúdo das pastas em ambos os ambientes também deve demonstrar diferentes conjuntos de dados.
Exemplo de provas
A captura de ecrã mostra os 3 registos principais (para submissão de provas, forneça os 20 primeiros) da base de dados de produção.
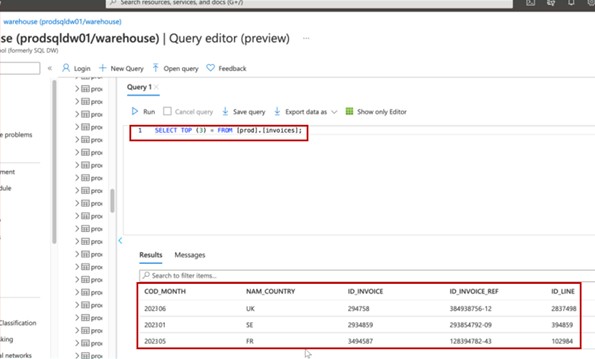
A captura de ecrã seguinte mostra a mesma consulta da Base de Dados de Desenvolvimento, que mostra registos diferentes.
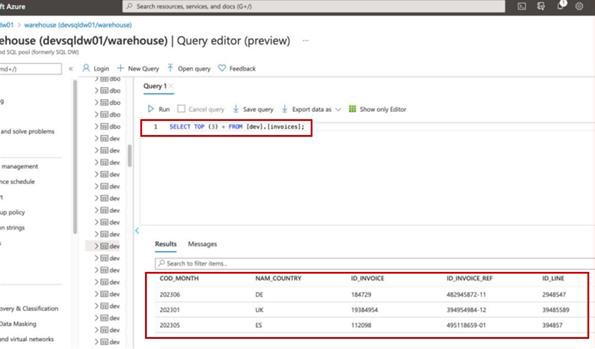
Nota: neste exemplo, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Desenvolvimento/implementação de software seguro
As organizações envolvidas em atividades de desenvolvimento de software são frequentemente confrontadas com prioridades concorrentes entre as pressões de segurança e TTM (Time to Market), no entanto, a implementação de atividades relacionadas com a segurança ao longo do ciclo de vida de desenvolvimento de software (SDLC) não só pode poupar dinheiro, como também poupar tempo. Quando a segurança é deixada como uma reflexão posterior, os problemas são geralmente identificados apenas durante a fase de teste do (DSLC), o que, muitas vezes, pode ser mais demorado e dispendioso de corrigir. A intenção desta secção de segurança é garantir que são seguidas práticas seguras de desenvolvimento de software para reduzir o risco de falhas de codificação introduzidas no software desenvolvido. Além disso, esta secção procura incluir alguns controlos para ajudar na implementação segura de software.
Controlo N.º 12
Forneça provas que demonstrem que a documentação existe e é mantido que:
suporta o desenvolvimento de software seguro e inclui normas da indústria e/ou melhores práticas para codificação segura, como OWASP Top 10 ou SANS Top 25 CWE.
os programadores são submetidos anualmente a uma codificação segura relevante e a uma formação segura de desenvolvimento de software.
Intenção: desenvolvimento seguro
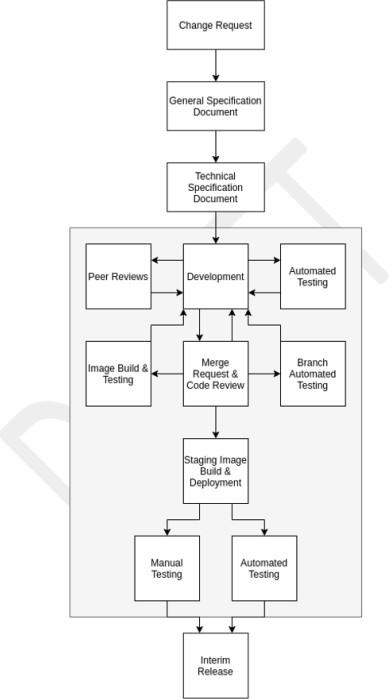
As organizações precisam de fazer tudo o que estiver ao seu alcance para garantir que o software é desenvolvido de forma segura e livre de vulnerabilidades. Num melhor esforço para o conseguir, deve ser estabelecido um ciclo de vida de desenvolvimento de software seguro robusto (SDLC) e melhores práticas de codificação segura para promover técnicas de codificação seguras e desenvolvimento seguro em todo o processo de desenvolvimento de software. A intenção é reduzir o número e a gravidade das vulnerabilidades no software.
Existem melhores práticas e técnicas de codificação para todas as linguagens de programação para garantir que o código é desenvolvido de forma segura. Existem cursos de formação externos concebidos para ensinar aos programadores os diferentes tipos de classes de vulnerabilidades de software e as técnicas de codificação que podem ser utilizadas para parar a introdução destas vulnerabilidades no software. A intenção deste controlo é também ensinar estas técnicas a todos os programadores e garantir que estas técnicas não sejam esquecidas ou que as técnicas mais recentes sejam aprendidas ao realizar esta ação anualmente.
Diretrizes: desenvolvimento seguro
Forneça a documentação documentada do SDLC e/ou suporte que demonstra que está a ser utilizado um ciclo de vida de desenvolvimento seguro e que são fornecidas orientações para todos os programadores promoverem melhores práticas de codificação seguras. Veja o OWASP no SDLC e o OWASP Software Assurance MaturityModel (SAMM).
Exemplo de evidência: desenvolvimento seguro
Abaixo, é apresentado um exemplo do documento de política de Desenvolvimento de Software Seguro. Segue-se um extrato do Procedimento de Desenvolvimento de Software Seguro da Contoso, que demonstra práticas de programação e codificação seguras.

Nota: nos exemplos anteriores, não foram utilizadas capturas de ecrã completas. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem qualquer URL, utilizador com sessão iniciada e a hora e data do sistema.
Diretrizes: formação de desenvolvimento segura
Forneça provas através de certificados se a formação for realizada por uma empresa de formação externa ou ao fornecer capturas de ecrã dos diários de formação ou de outros artefactos que demonstram que os programadores participaram na formação. Se esta formação for realizada através de recursos internos, forneça também provas do material de preparação.
Exemplo de evidência: formação de desenvolvimento seguro
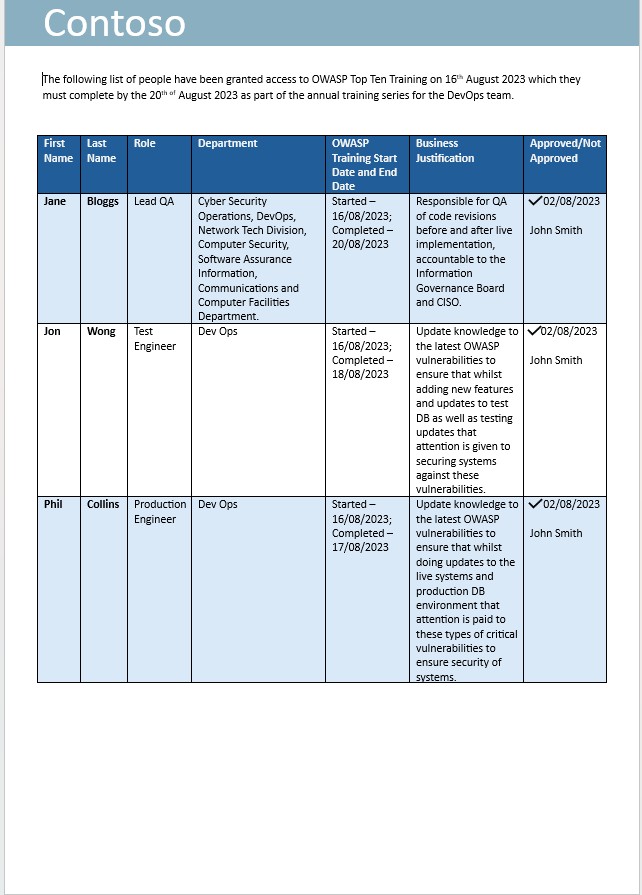
A captura de ecrã seguinte é um e-mail a pedir à equipa do DevOps para se inscrever na Formação Anual das Dez Principais Formações do OWASP.

A captura de ecrã seguinte mostra que a formação foi pedida com justificação comercial e aprovação. Em seguida, segue-se capturas de ecrã tiradas da formação e um registo de conclusão que mostra que a pessoa terminou a formação anual.
Nota: neste exemplo, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Controlo N.º 13
Forneça provas de que os repositórios de código estão protegidos para que:
todas as alterações de código são submetidas a um processo de revisão e aprovação por um segundo revisor antes de serem intercaladas com o ramo principal.
os controlos de acesso adequados estão implementados.
todo o acesso é imposto através da autenticação multifator (MFA).
todas as versões efetuadas nos ambientes de produção são revistas e aprovadas antes da respetiva implementação.
Intenção: revisão de código
A intenção deste subponto é efetuar uma revisão de código por outro programador para ajudar a identificar quaisquer erros de codificação que possam introduzir uma vulnerabilidade no software. A autorização deve ser estabelecida para garantir que as revisões de código são realizadas, os testes são realizados, etc. antes da implementação. O passo de autorização valida que foram seguidos os processos corretos que sustentam o SDLC definido no controlo 12.
O objetivo é garantir que todas as alterações de código sejam submetidas a um rigoroso processo de revisão e aprovação por um segundo revisor antes de serem intercaladas no ramo principal. Este processo de aprovação dupla serve como uma medida de controlo de qualidade, com o objetivo de detetar quaisquer erros de codificação, vulnerabilidades de segurança ou outros problemas que possam comprometer a integridade da aplicação.
Diretrizes: revisão de código
Forneça provas de que o código é submetido a uma revisão ponto a ponto e tem de ser autorizado antes de poder ser aplicado ao ambiente de produção. Estes elementos de prova podem ser através de uma exportação de bilhetes de alteração, demonstrando que foram realizadas revisões de código e as alterações autorizadas, ou podem ser através de software de revisão de código, como o Crucible.
Exemplo de evidência: revisão de código
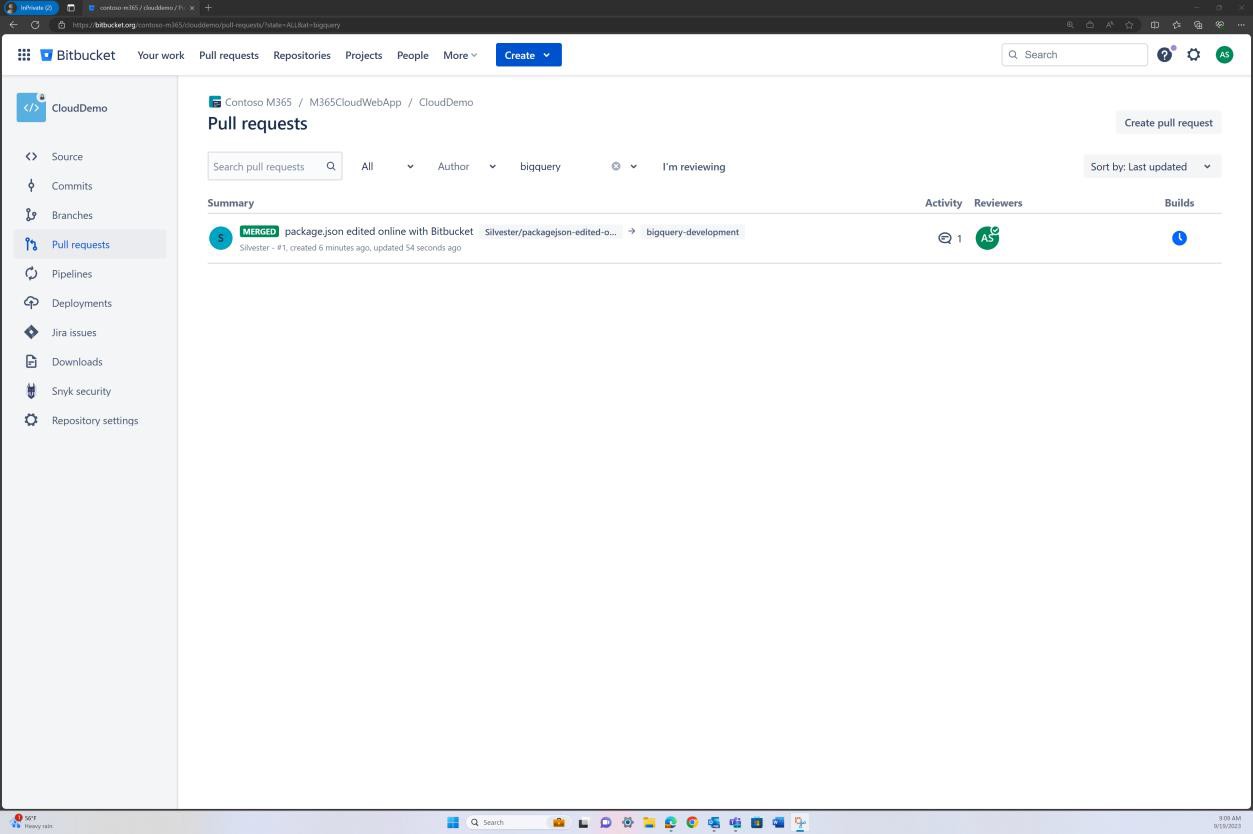
Segue-se um pedido de suporte que mostra que as alterações de código são submetidas a um processo de revisão e autorização por outra pessoa que não seja o programador original. Mostra que foi pedida uma revisão de código pelo detentor e que será atribuída a outra pessoa para a revisão do código.
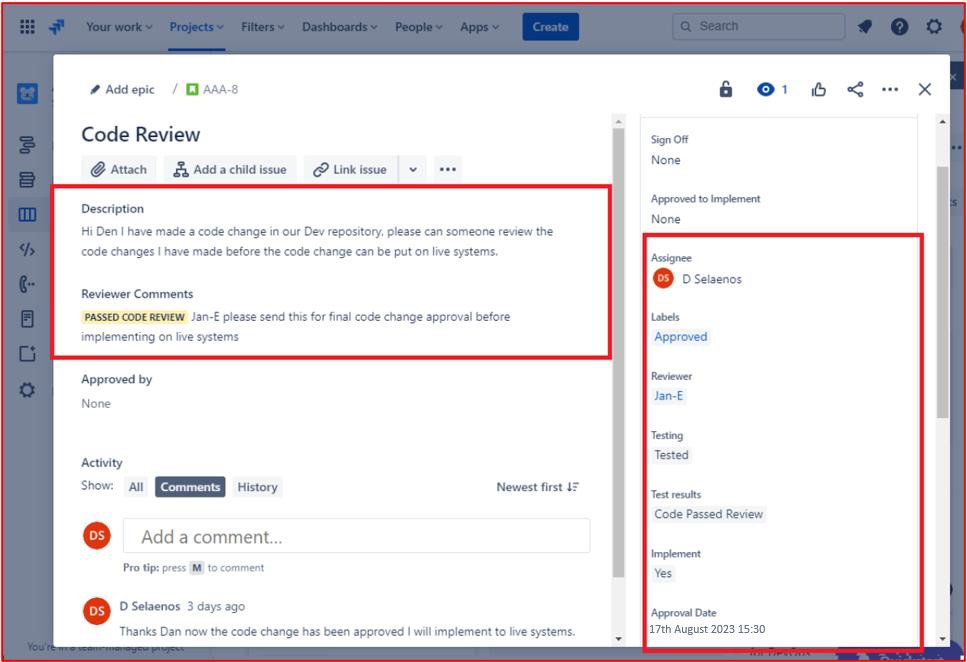
A imagem seguinte mostra que a revisão de código foi atribuída a alguém que não seja o programador original, conforme mostrado pela secção realçada no lado direito da imagem. No lado esquerdo, o código foi revisto e foi-lhe atribuído o estado "REVISÃO DO CÓDIGO PASSADO" pelo revisor de código. O pedido de suporte tem agora de ser aprovado por um gestor para que as alterações possam ser colocadas em sistemas de produção em direto.
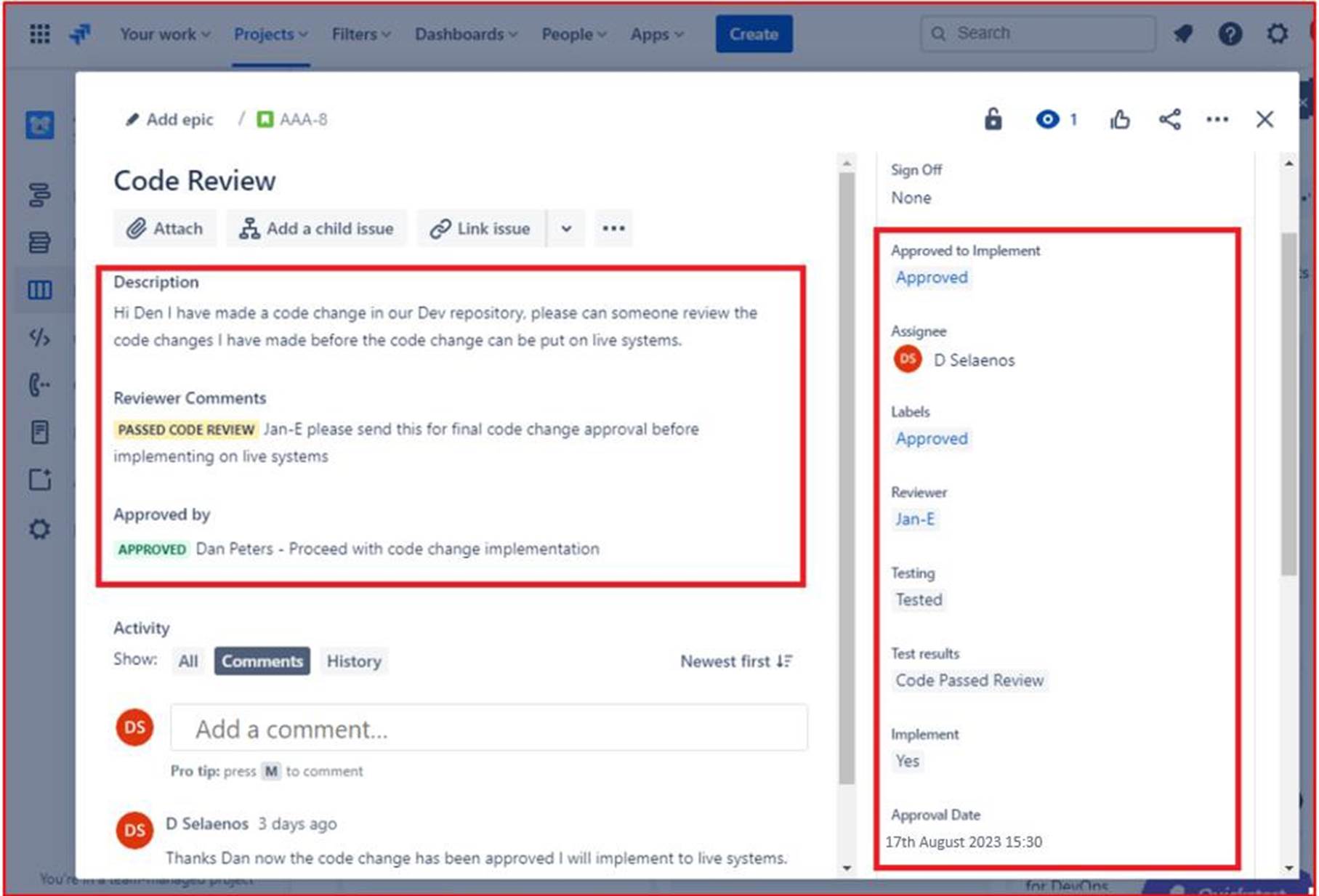
A imagem seguinte mostra que o código revisto foi aprovado para ser implementado nos sistemas de produção em direto. Depois de as alterações ao código terem sido efetuadas, a tarefa final é terminada. Tenha em atenção que ao longo do processo existem três pessoas envolvidas, o programador original do código, o revisor de código e um gestor para dar aprovação e aprovação. Para cumprir os critérios para este controlo, seria uma expectativa que os seus pedidos de suporte seguissem este processo.
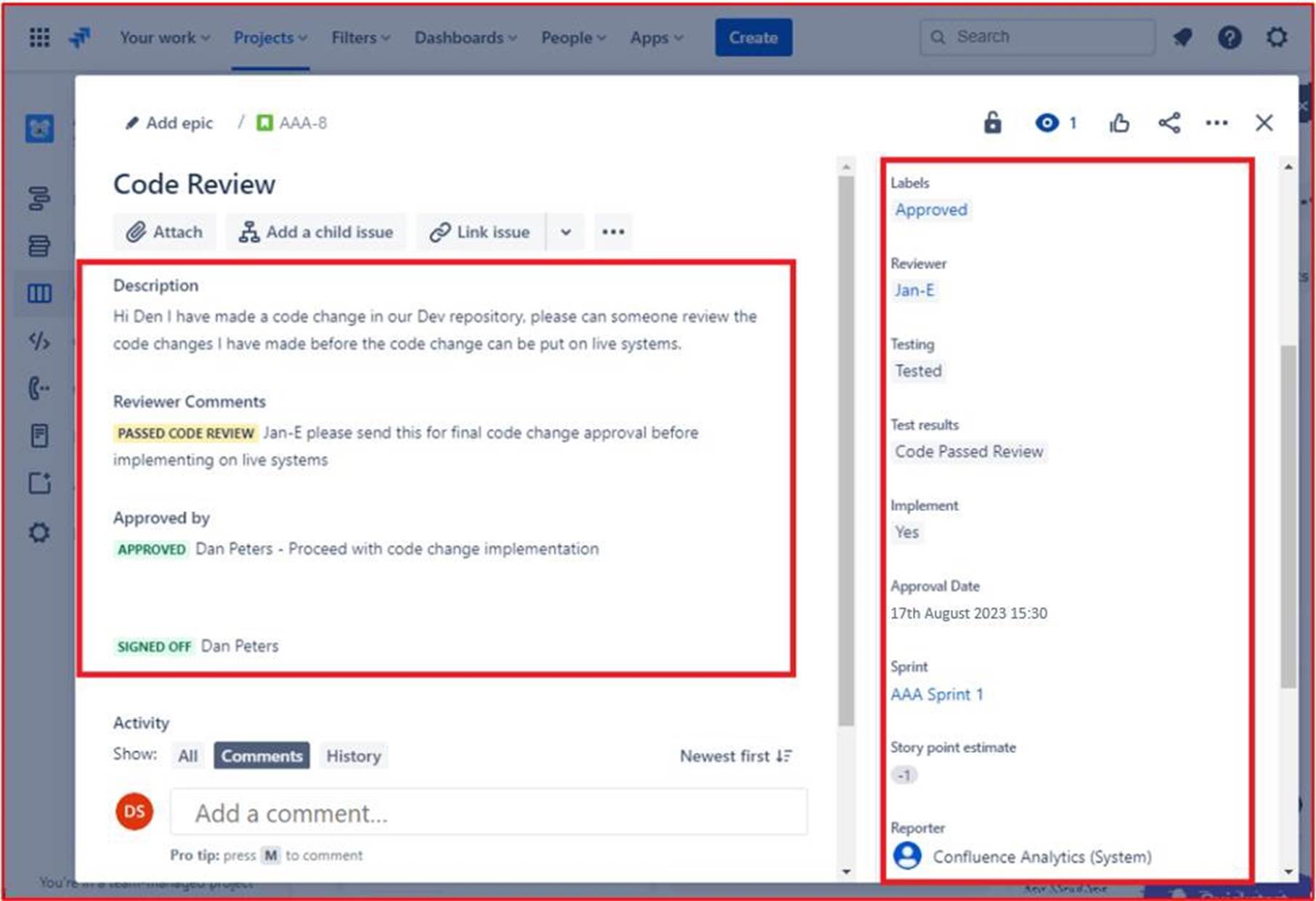
Nota: neste exemplo, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Exemplo de evidência: revisão de código
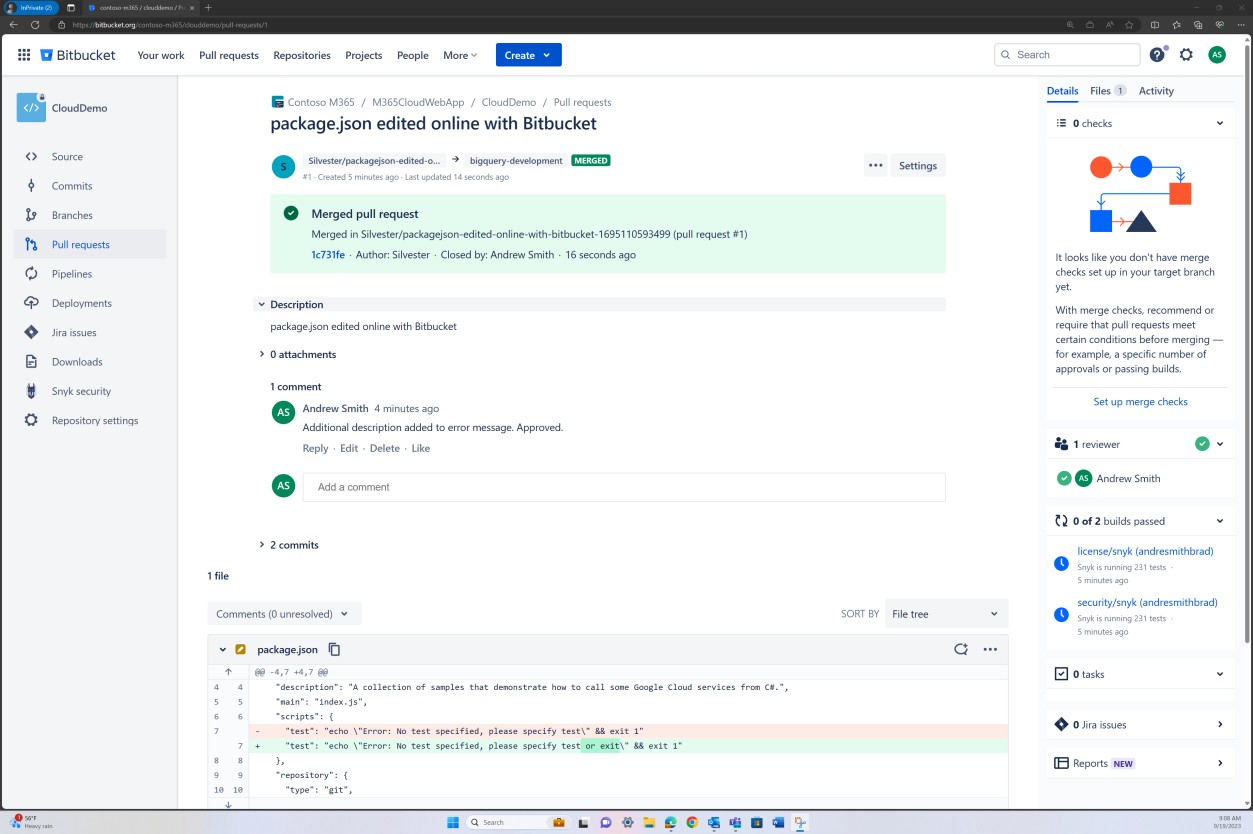
Além da parte administrativa do processo apresentado acima, com repositórios de código modernos e plataformas, podem ser implementados controlos adicionais, como a revisão de imposição de políticas de ramo, para garantir que as intercalações não podem ocorrer até que essa revisão seja concluída. O exemplo seguinte mostra que está a ser conseguido no DevOps.
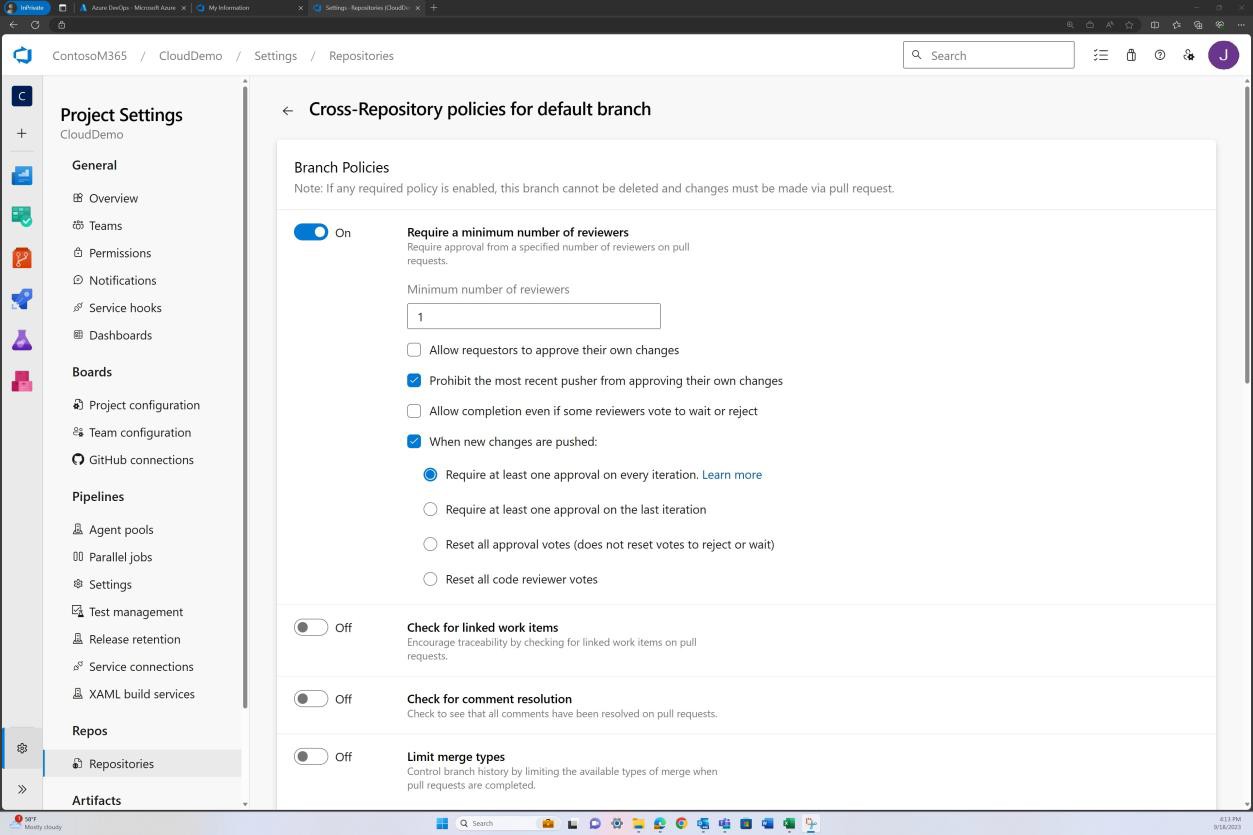
A captura de ecrã seguinte mostra que os revisores predefinidos são atribuídos e que a revisão é automaticamente necessária.
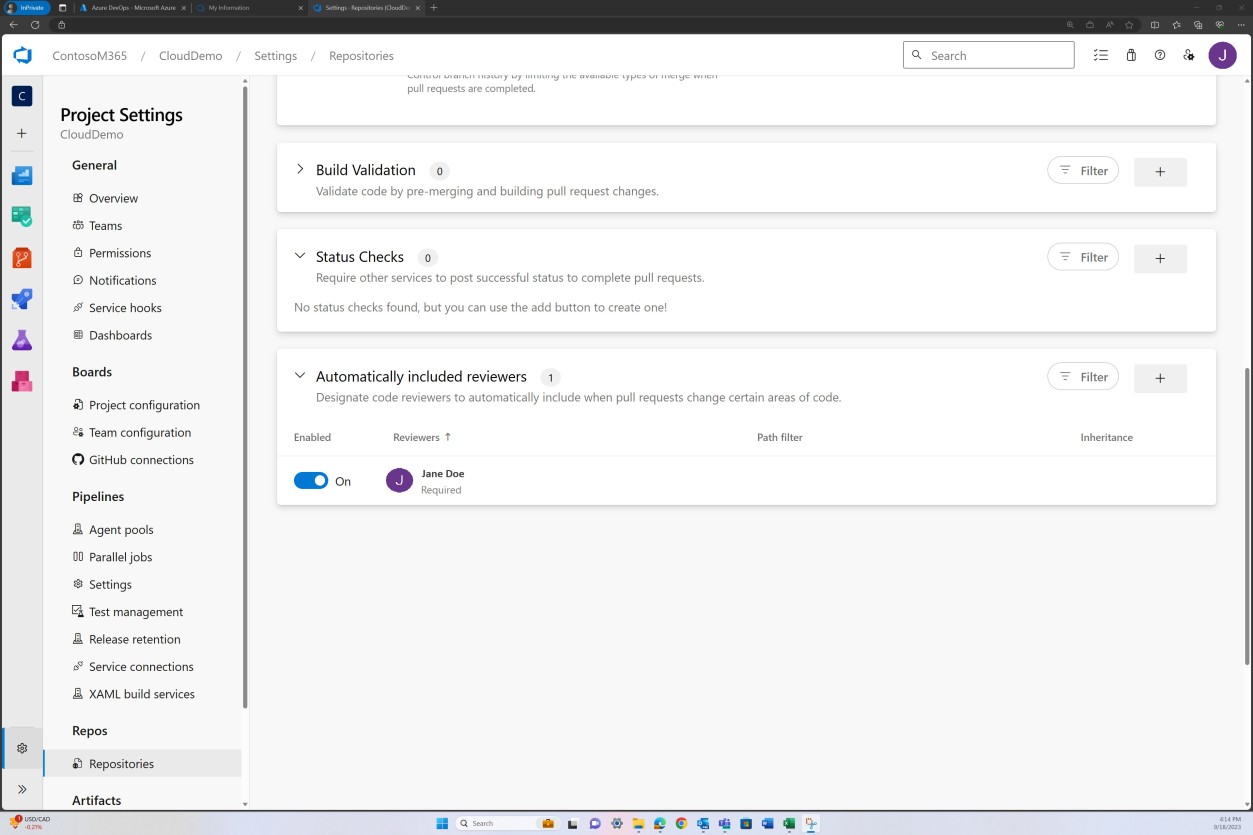
Exemplo de evidência: revisão de código
A revisão da imposição da política de ramificação também pode ser efetuada no Bitbucket.
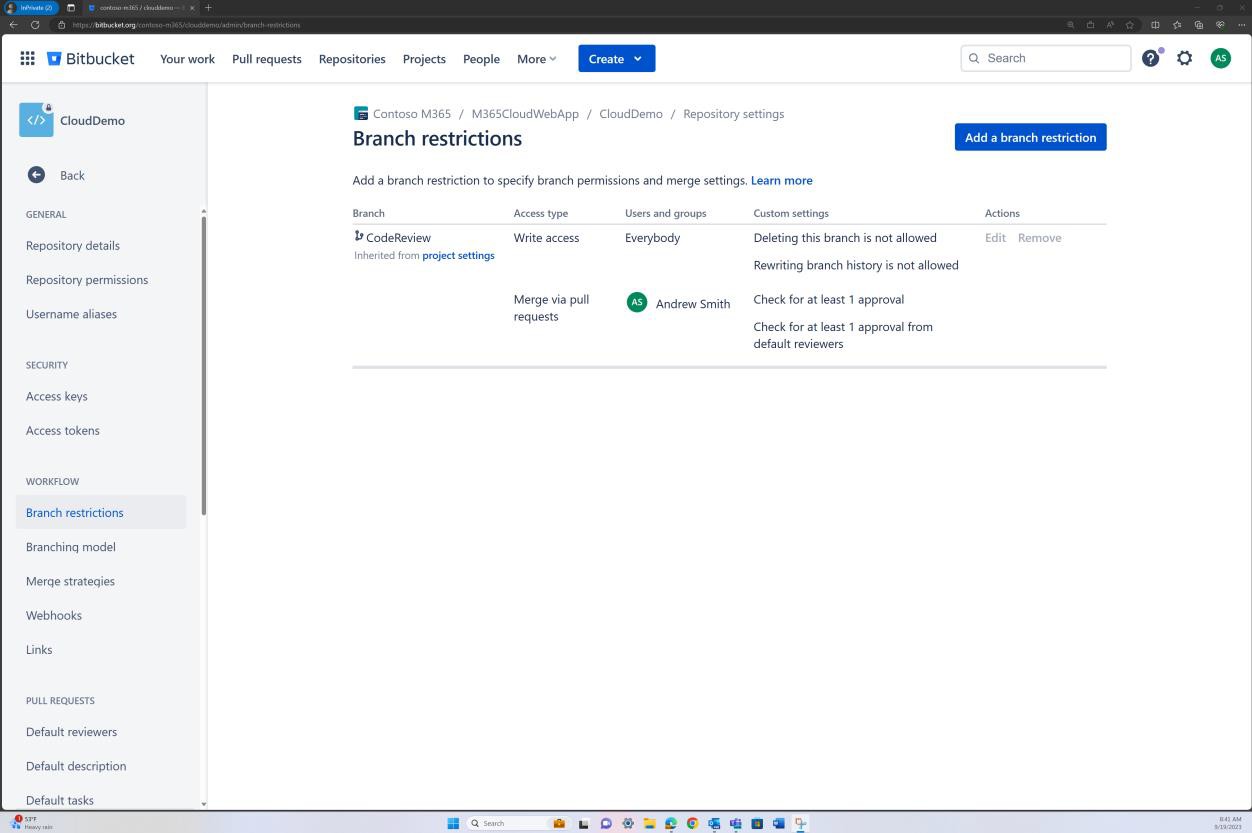
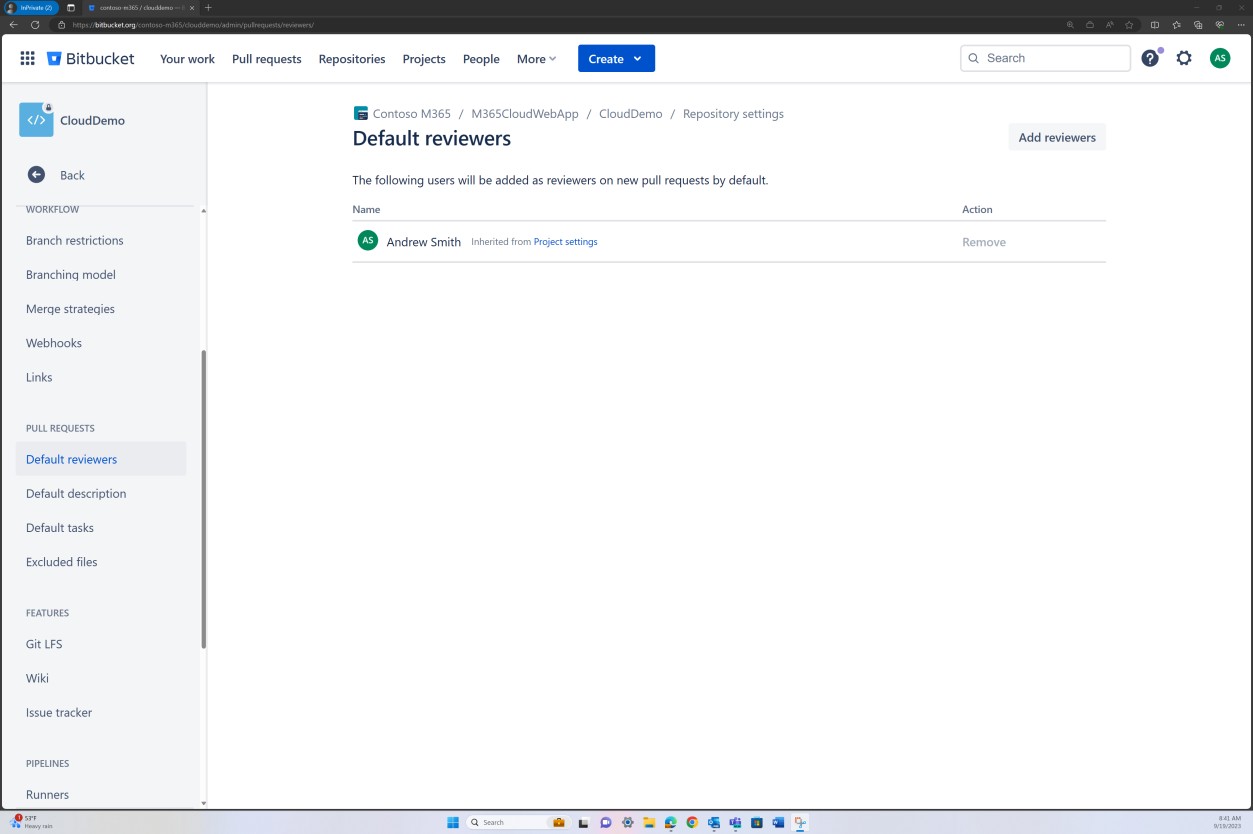
Na captura de ecrã seguinte, é definido um revisor predefinido. Isto garante que todas as intercalações exigirão uma revisão do indivíduo atribuído antes de a alteração ser propagada para o ramo principal.
As duas capturas de ecrã subsequentes demonstram um exemplo das definições de configuração que estão a ser aplicadas. Além de um pedido Pull concluído, que foi iniciado pelo utilizador Silvester e precisou da aprovação do revisor predefinido Andrew antes de ser intercalado com o ramo principal.
Tenha em atenção que, quando forem fornecidas provas, a expectativa será que o processo ponto a ponto seja demonstrado. Nota: as capturas de ecrã devem ser fornecidas com as definições de configuração se uma política de ramo estiver em vigor (ou outro método/controlo programático) e permissões/registos de aprovação a serem concedidos.
Intenção: acesso restrito
A partir do controlo anterior, os controlos de acesso devem ser implementados para limitar o acesso apenas a utilizadores individuais que estejam a trabalhar em projetos específicos. Ao limitar o acesso, pode limitar o risco de efetuar alterações não autorizadas e, assim, introduzir alterações de código inseguras. Deve ser tomada uma abordagem com menos privilégios para proteger o repositório de código.
Diretrizes: acesso restrito
Forneça provas através de capturas de ecrã do repositório de código que restringem o acesso a indivíduos necessários, incluindo privilégios diferentes.
Exemplo de provas: acesso restrito
As capturas de ecrã seguintes mostram os controlos de acesso que foram implementados no Azure DevOps. A "Equipa do CloudDemo" mostra que tem dois membros e cada membro tem permissões diferentes.
Nota: as capturas de ecrã seguintes mostram um exemplo do tipo de provas e formato que seria esperado para cumprir este controlo. Isto não é de forma alguma extenso e os casos do mundo real podem diferir sobre a forma como os controlos de acesso são implementados.
Se as permissões forem definidas ao nível do grupo, as provas de cada grupo e dos utilizadores desse grupo têm de ser fornecidas, conforme mostrado no segundo exemplo do Bitbucket.
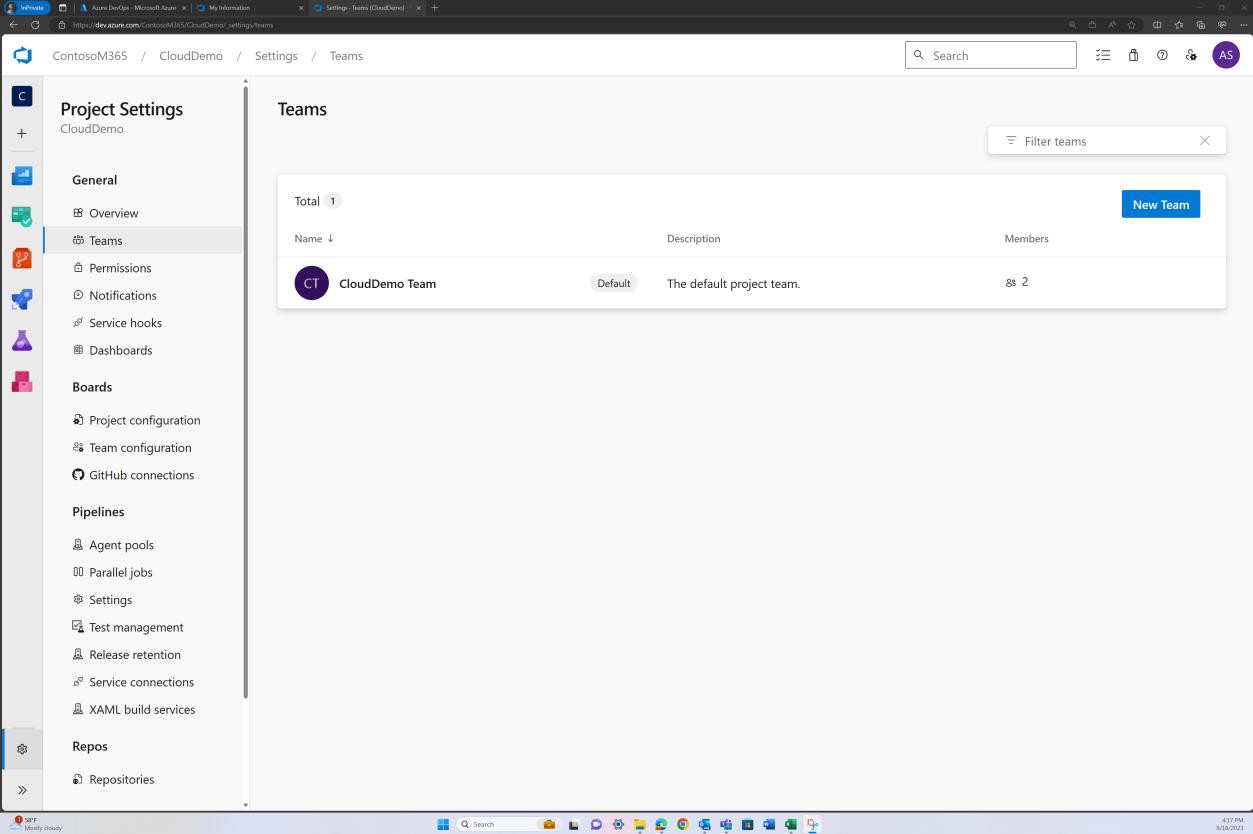
Captura de ecrã a seguir a mostrar os membros da "Equipa cloudDemo".
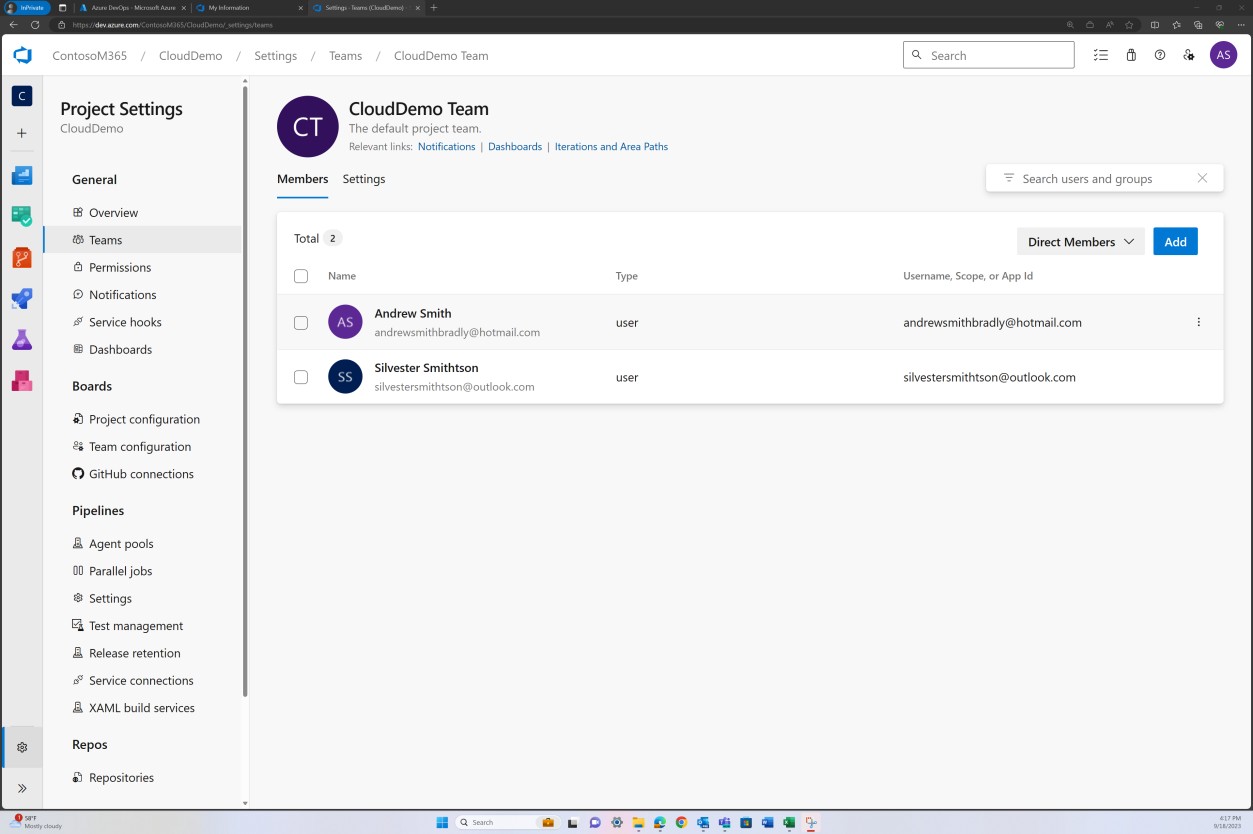
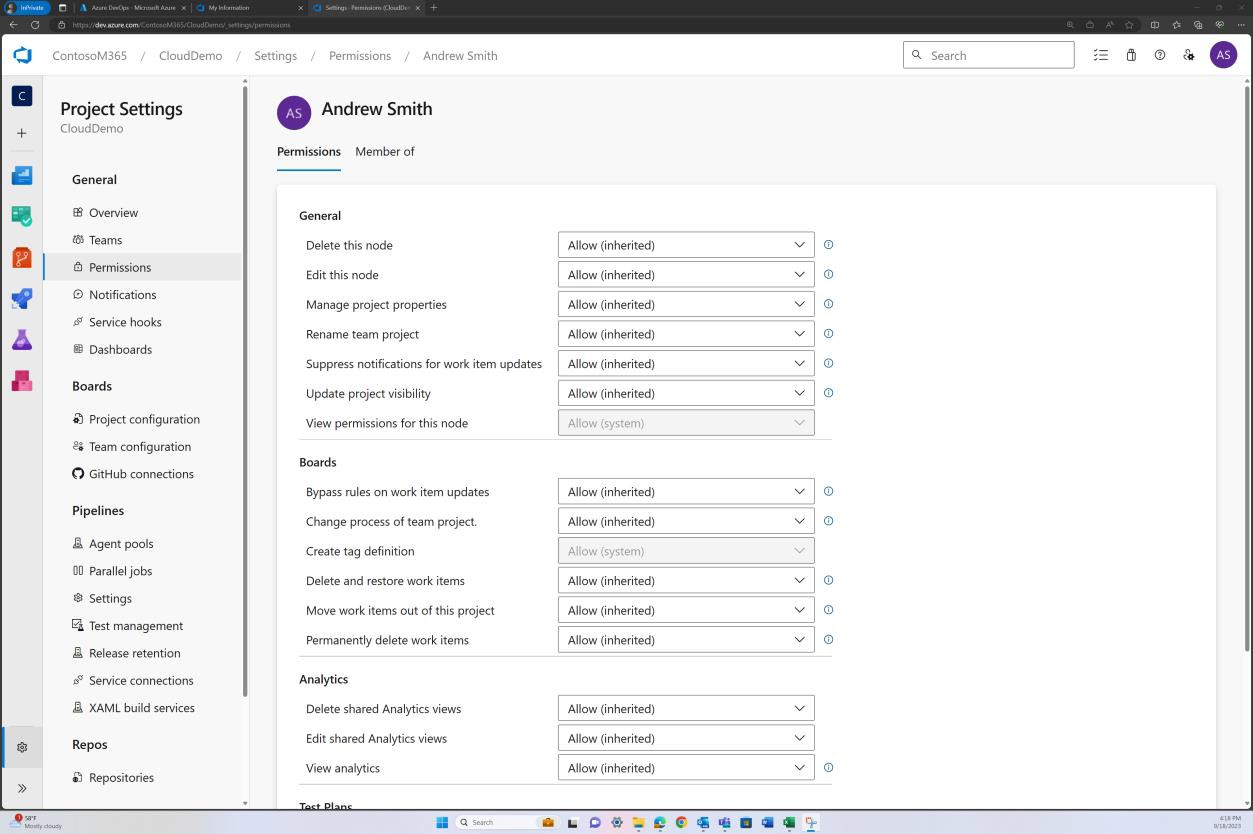
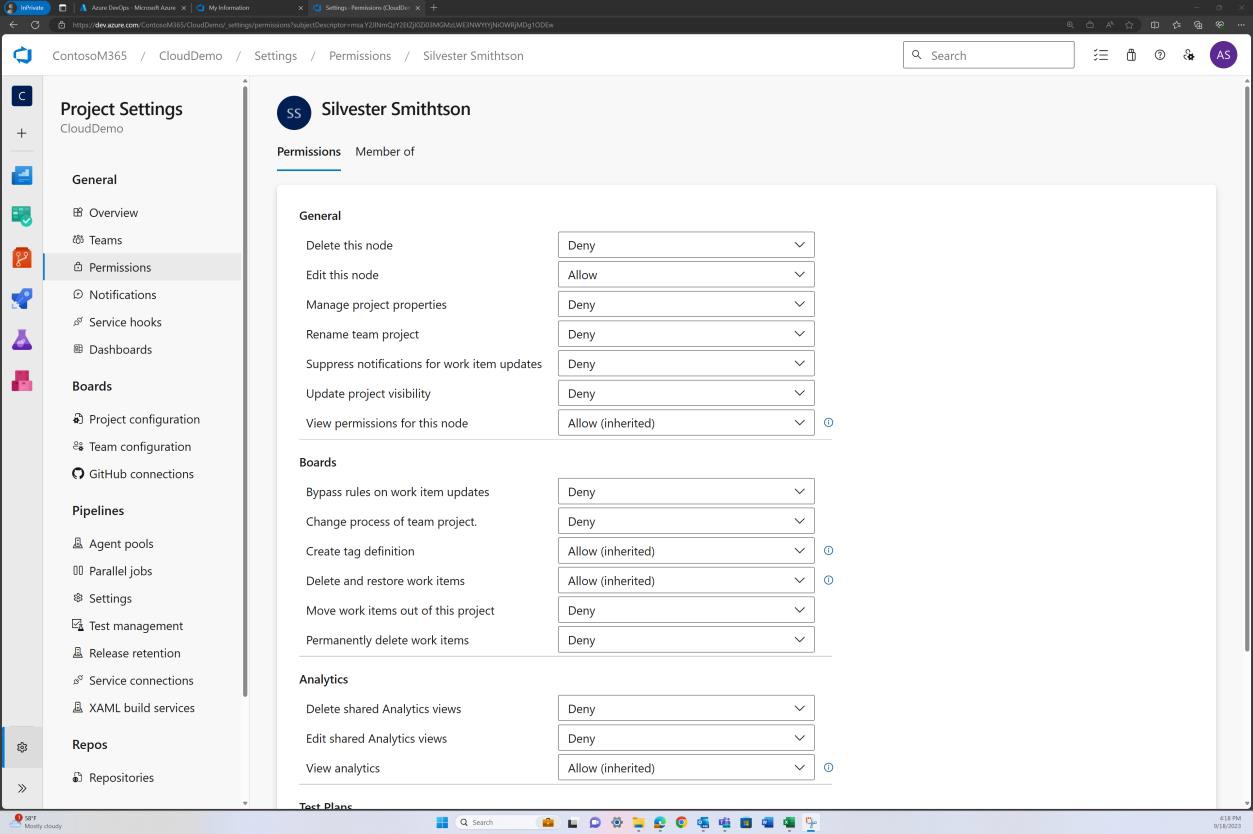
A imagem anterior mostra que Andrew Smith tem privilégios significativamente mais elevados como proprietário do projeto do que Silvester abaixo.
Exemplo de provas
Na captura de ecrã seguinte, os controlos de acesso implementados no Bitbucket são obtidos através de permissões definidas ao nível do grupo. Para o nível de acesso do repositório, existe um grupo "Administrador" com um utilizador e um grupo "Programador" com outro utilizador.
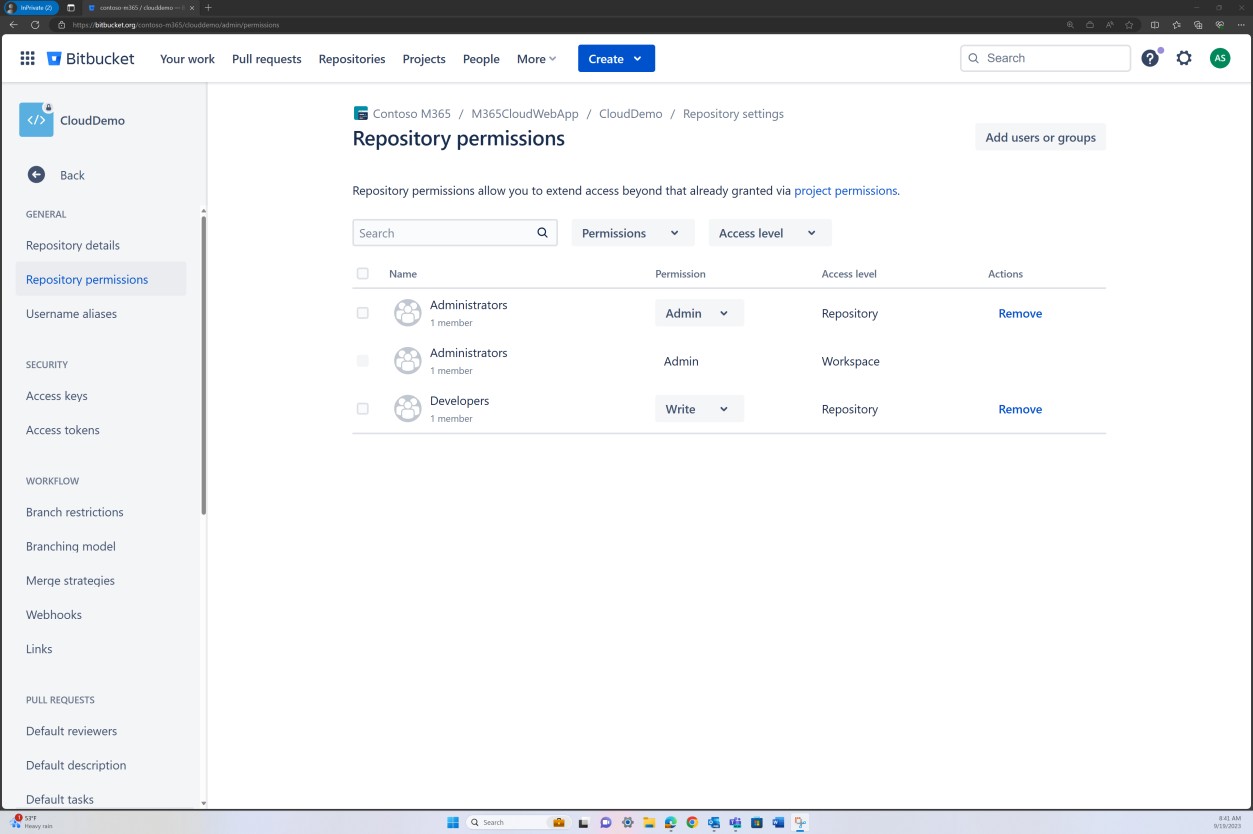
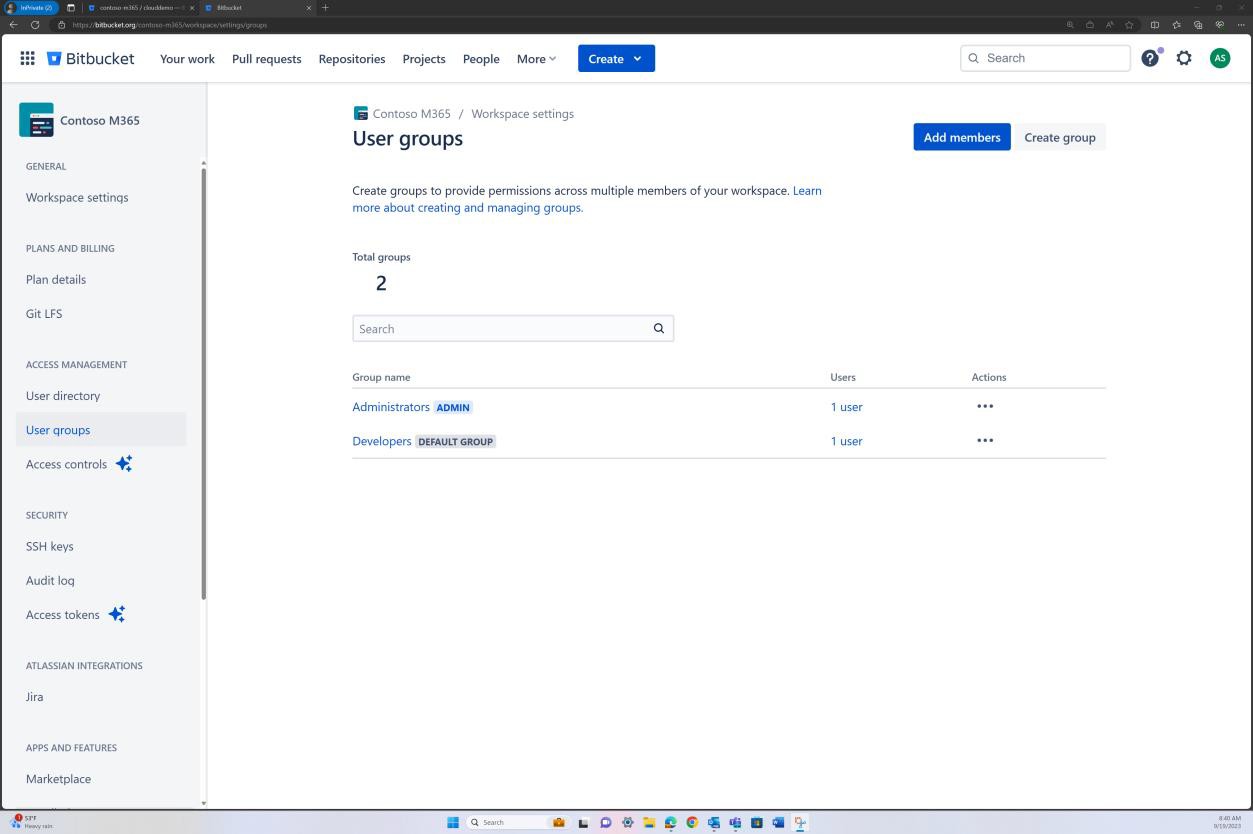
As capturas de ecrã seguintes mostram que cada um dos utilizadores pertence a um grupo diferente e que, inerentemente, tem um nível diferente de permissões. Andrew Smith é o Administrador e Silvester faz parte do grupo Programador, que lhe concede apenas privilégios de programador.
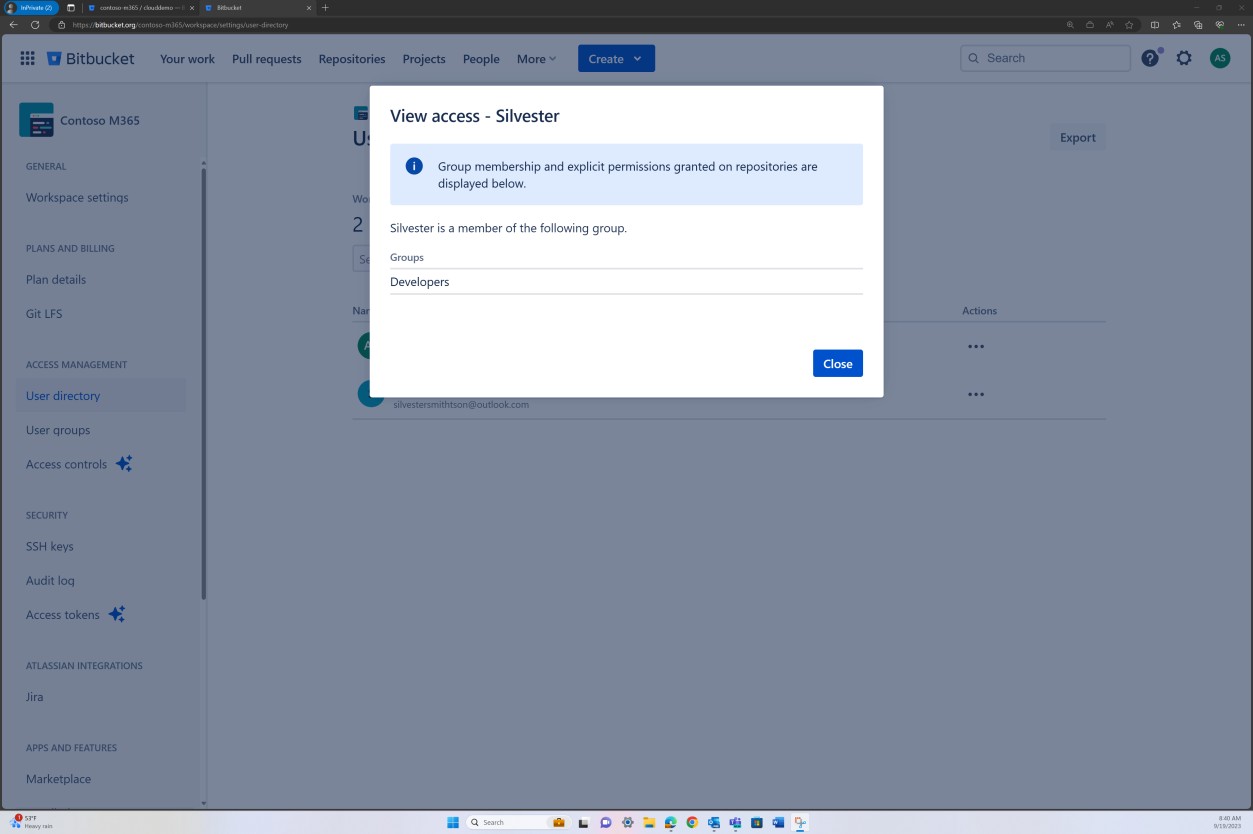
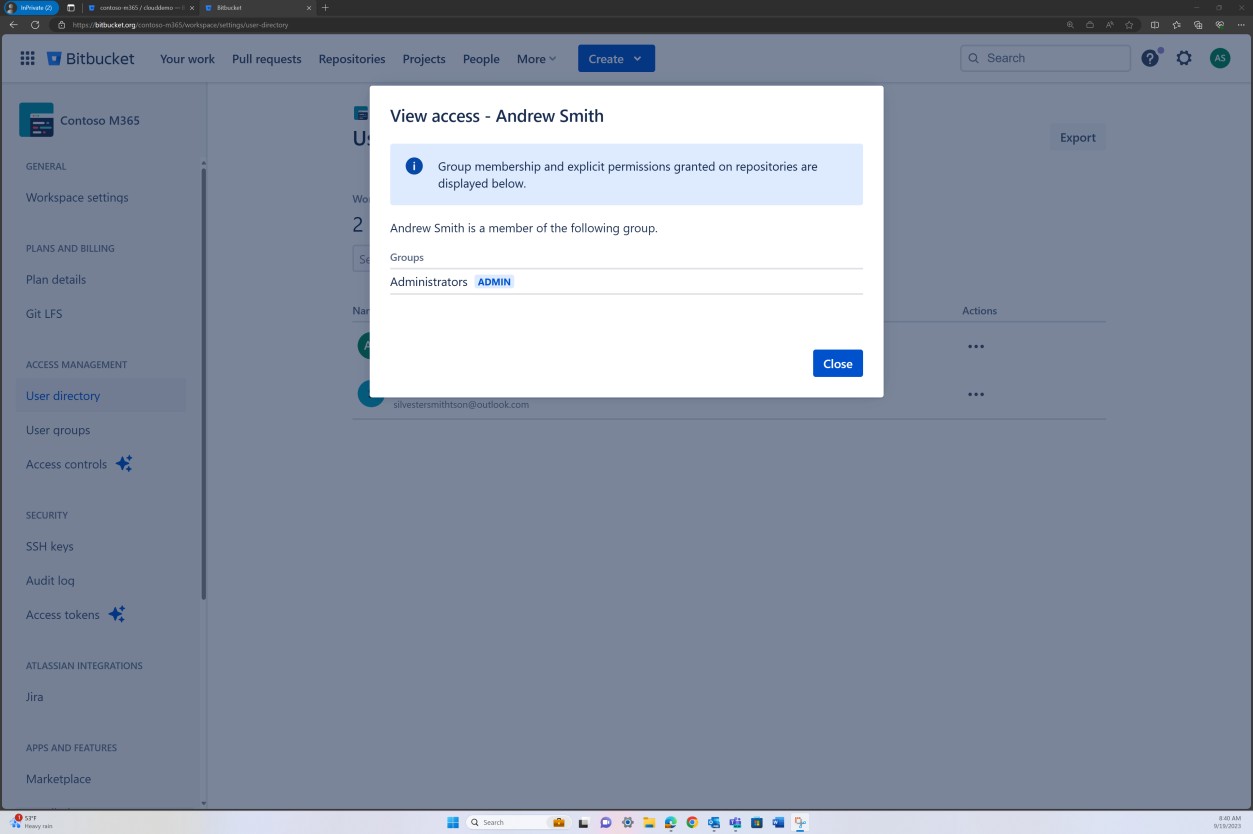
Intenção: MFA
Se um ator de ameaças conseguir aceder e modificar a base de código de um software, pode introduzir vulnerabilidades, backdoors ou código malicioso na base de código e, portanto, na aplicação. Já houve vários casos deste problema, com provavelmente o mais divulgado a ser o ataque solarWinds de 2020, onde os atacantes injetaram código malicioso num ficheiro que foi mais tarde incluído nas atualizações de software SolarWinds's Orion. Mais de 18.000 clientes solarWinds instalaram as atualizações maliciosas, com o software maligno a propagar-se sem ser detetado.
A intenção deste subponto é verificar se todo o acesso aos repositórios de código é imposto através da autenticação multifator (MFA).
Diretrizes: MFA
Forneça provas através de capturas de ecrã do repositório de código que todos os utilizadores têm a MFA ativada.
Exemplo de evidência: MFA
Se os repositórios de código forem armazenados e mantidos no Azure DevOps, dependendo de como a MFA foi configurada ao nível do inquilino, podem ser fornecidas provas a partir do AAD, por exemplo, "MFA por utilizador". A captura de ecrã seguinte mostra que a MFA é imposta a todos os utilizadores no AAD, o que também se aplicará ao Azure DevOps.
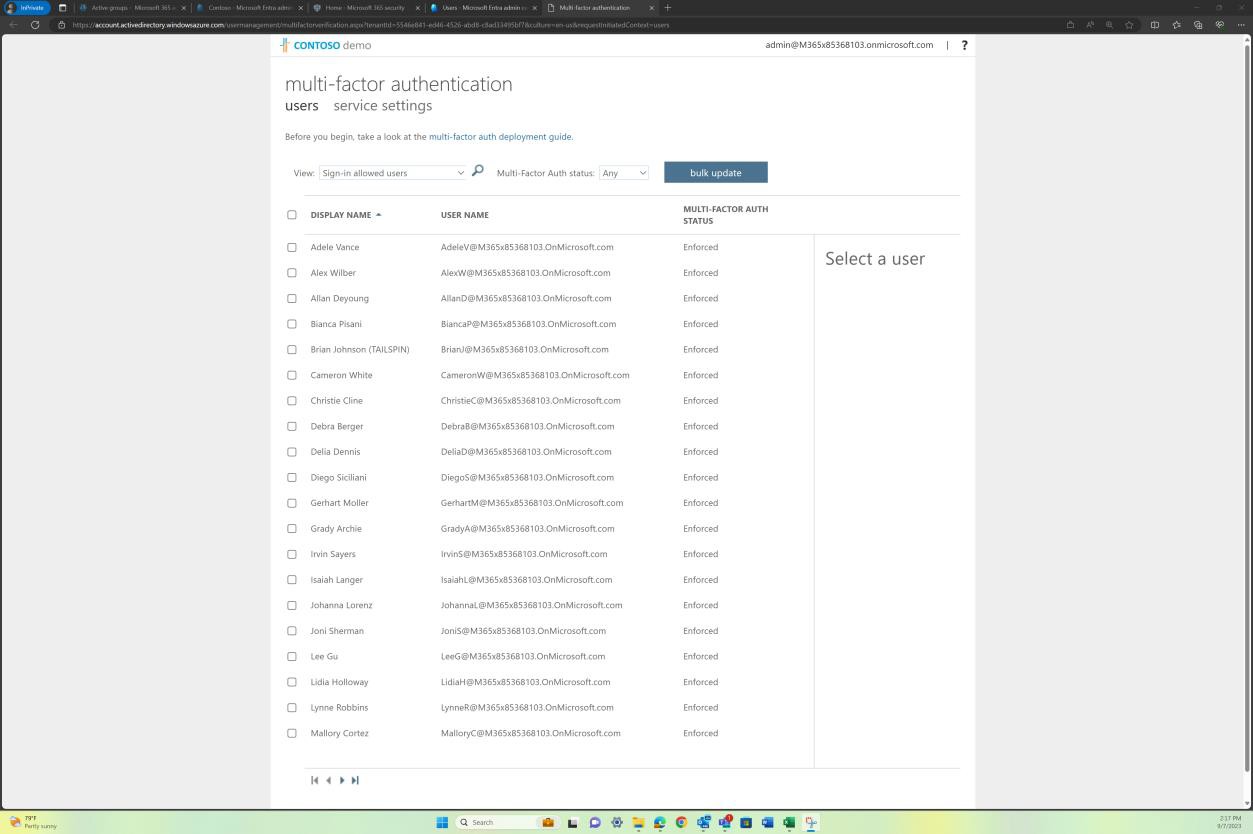
Exemplo de evidência: MFA
Se a organização utilizar uma plataforma como o GitHub, pode demonstrar que a 2FA está ativada ao partilhar as provas da conta "Organização", conforme mostrado nas capturas de ecrã seguintes.
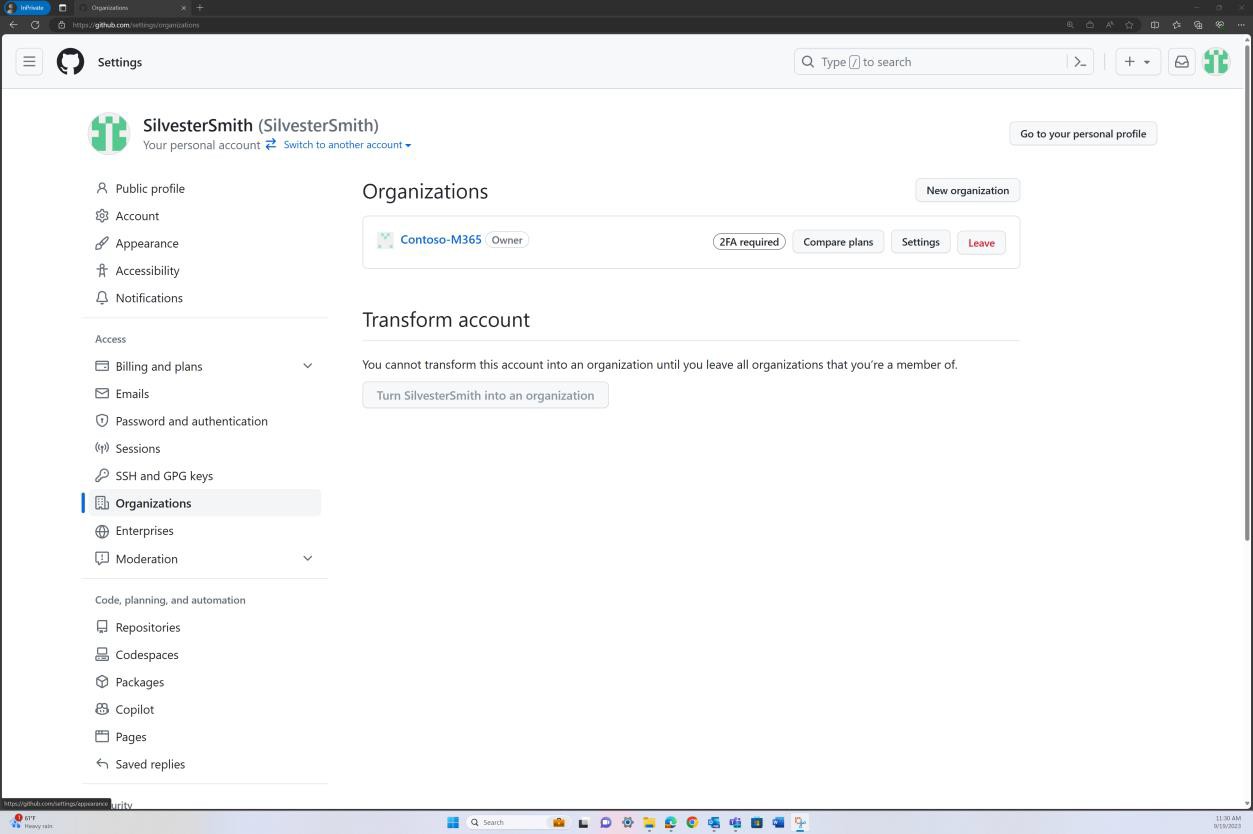
Para ver se a 2FA é imposta a todos os membros da sua organização no GitHub, pode navegar para o separador definições da organização, tal como na captura de ecrã seguinte.
Ao navegar para o separador "Pessoas" no GitHub, pode ser estabelecido que "2FA" está ativado para todos os utilizadores na organização, conforme mostrado na captura de ecrã seguinte.
Intenção: críticas
A intenção deste controlo é efetuar uma revisão da versão num ambiente de desenvolvimento por outro programador para ajudar a identificar quaisquer erros de codificação, bem como configurações incorretas que possam introduzir uma vulnerabilidade. A autorização deve ser estabelecida para garantir que as revisões de versão são realizadas, os testes são realizados, etc. antes da implementação na produção. A autorização. O passo pode validar que foram seguidos os processos corretos que sustentam os princípios do SDLC.
Diretrizes
Forneça provas de que todas as versões do ambiente de teste/desenvolvimento para o ambiente de produção estão a ser revistas por uma pessoa/programador diferente do iniciador. Se tal for conseguido através de um pipeline de Integração Contínua/Implementação Contínua, as provas fornecidas têm de mostrar (tal como acontece com as revisões de código) que as revisões são impostas.
Exemplo de provas
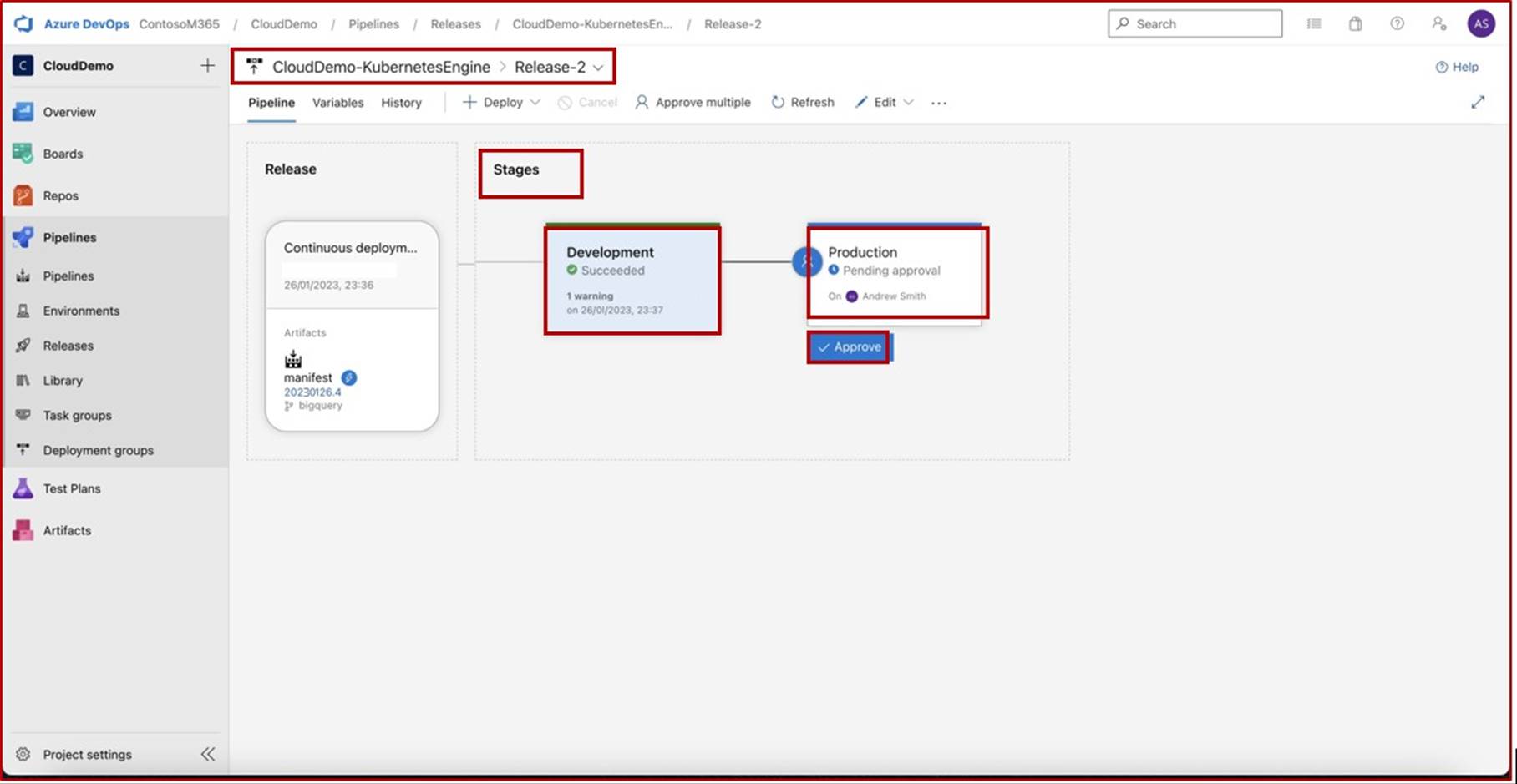
Na captura de ecrã seguinte, podemos ver que um pipeline CI/CD está a ser utilizado no Azure DevOps, o pipeline contém duas fases: Desenvolvimento e Produção. Uma versão foi acionada e implementada com êxito no ambiente de Desenvolvimento, mas ainda não foi propagada para a segunda fase (Produção) e está pendente da aprovação de Andrew Smith.
A expectativa é que, uma vez implementados no desenvolvimento, os testes de segurança ocorram pela equipa relevante e apenas quando o indivíduo atribuído com a autoridade certa para rever a implementação tiver realizado uma revisão secundária, e estiver satisfeito com o cumprimento de todas as condições, irá então conceder aprovação que permitirá que a versão seja efetuada em produção.
O alerta de e-mail que normalmente seria recebido pelo revisor atribuído informando que foi acionada uma condição de pré-implementação e que uma revisão e aprovação estão pendentes.
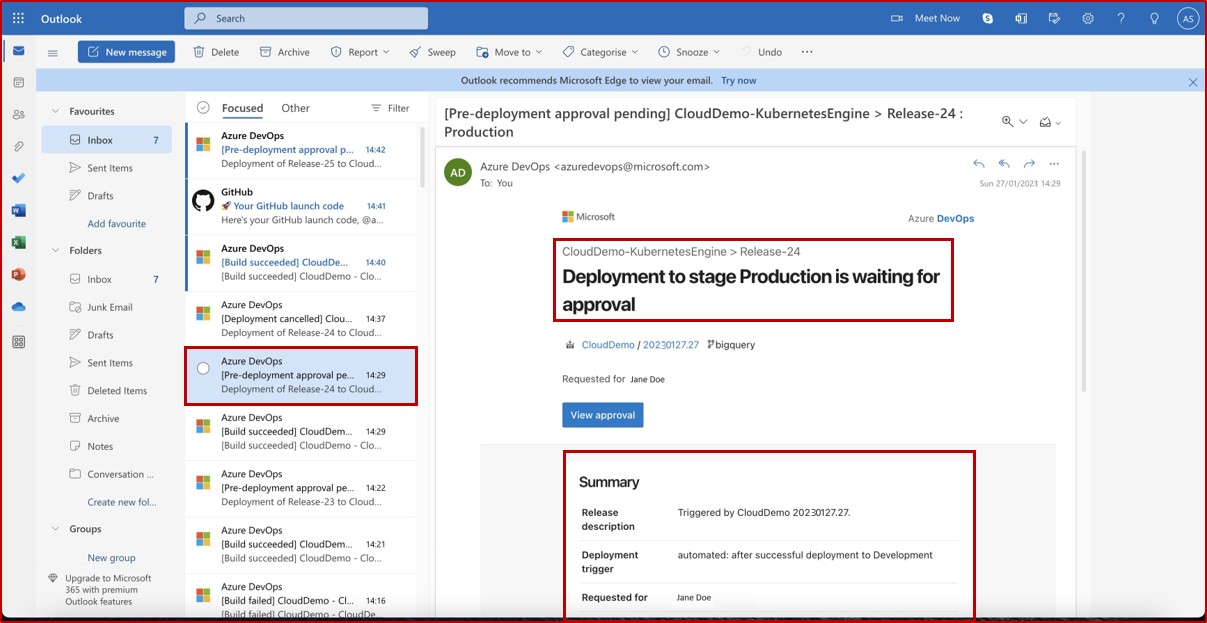
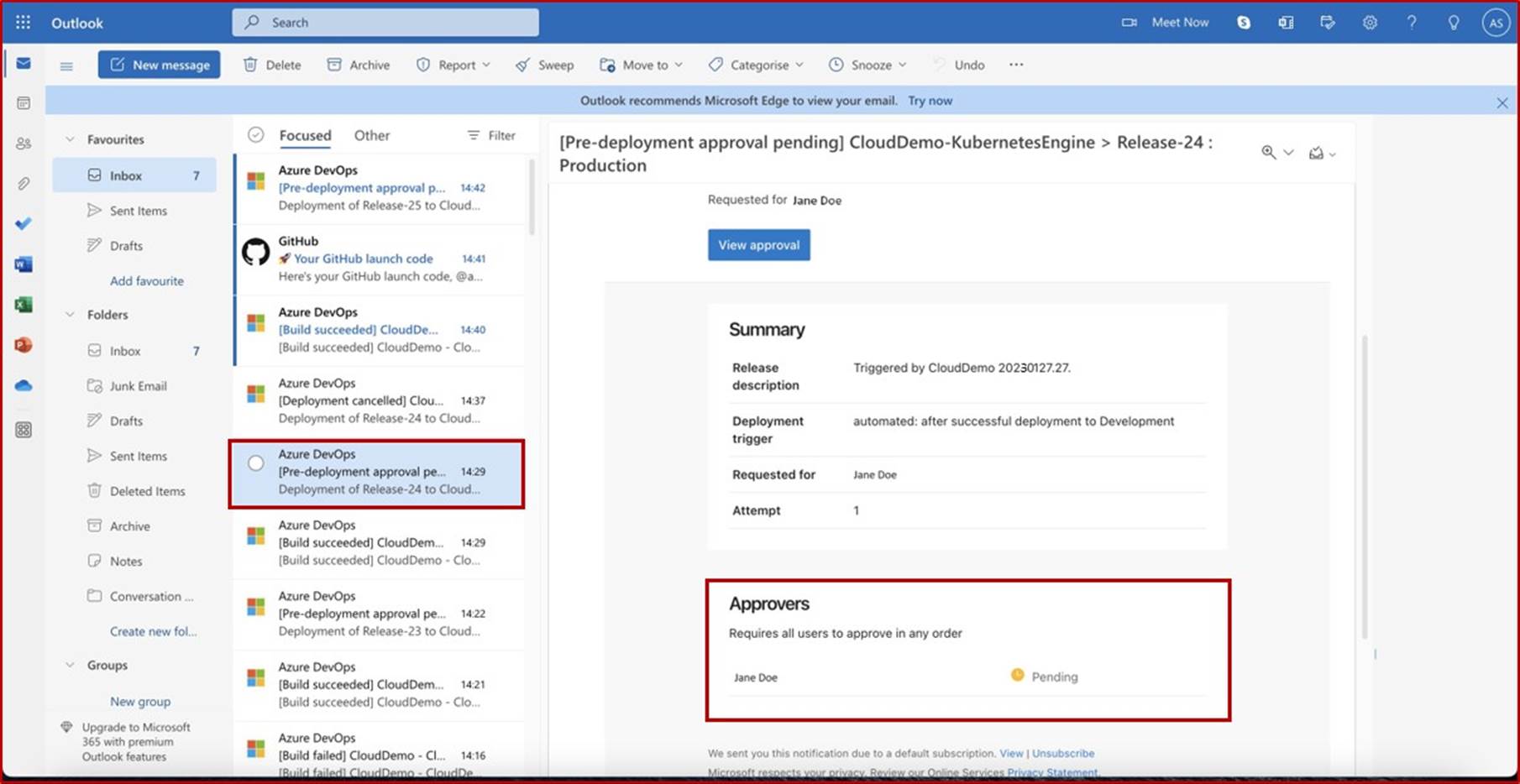
Com a notificação por e-mail, o revisor pode navegar para o pipeline de versão no DevOps e conceder aprovação. Podemos ver a seguir que são adicionados comentários que justificam a aprovação.
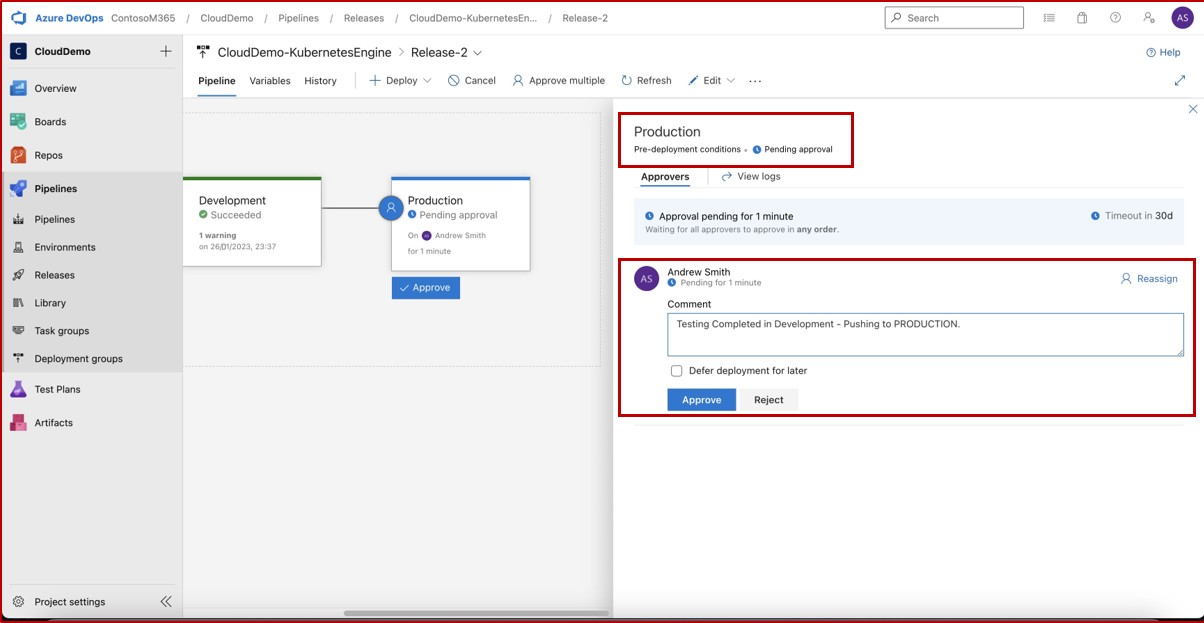
Na segunda captura de ecrã, é mostrado que a aprovação foi concedida e que a versão para produção foi bem-sucedida.
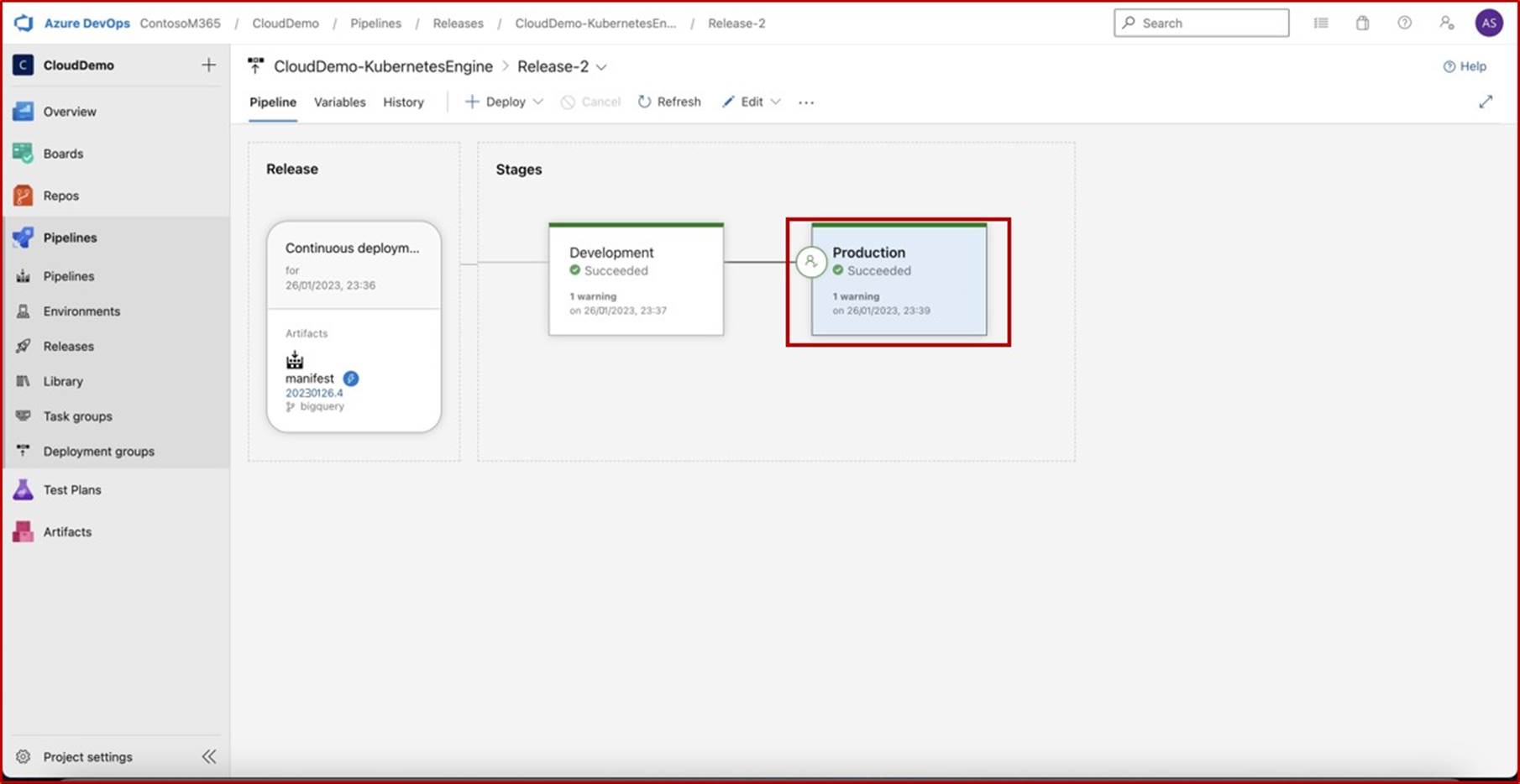
As duas capturas de ecrã seguintes mostram uma amostra das provas esperadas.
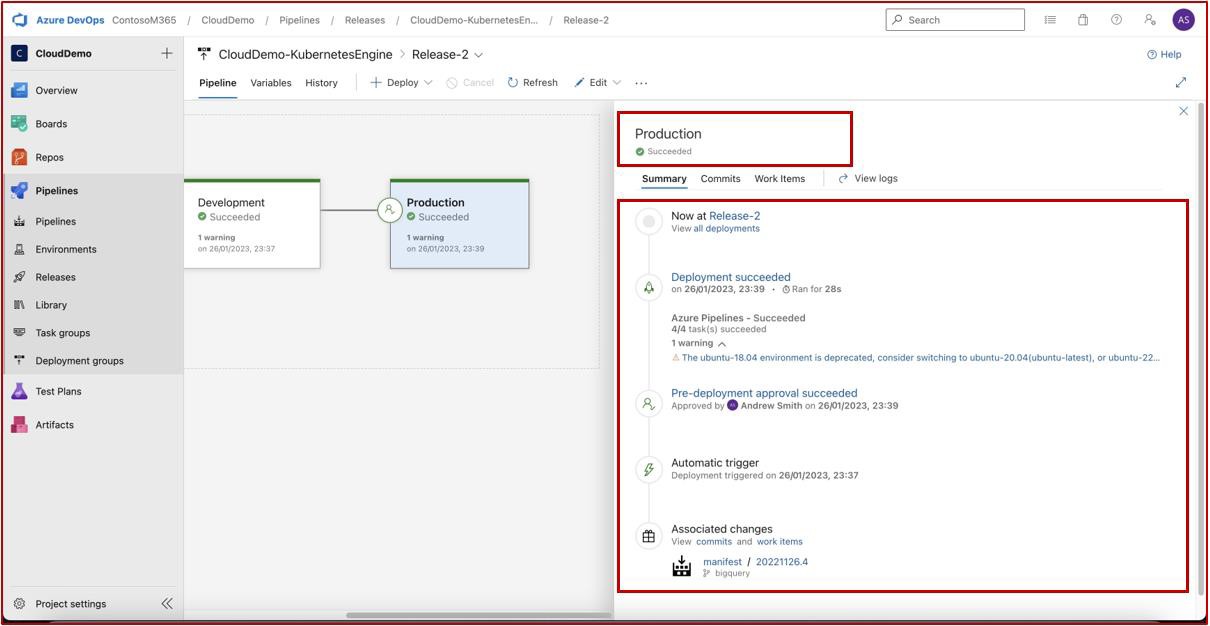
As evidências mostram versões históricas e que as condições de pré-implementação são impostas e é necessária uma revisão e aprovação antes de a implementação poder ser efetuada no ambiente de Produção.
Captura de ecrã seguinte a mostrar o histórico de lançamentos, incluindo a versão recente que podemos ver ter sido implementada com êxito tanto no desenvolvimento como na produção.
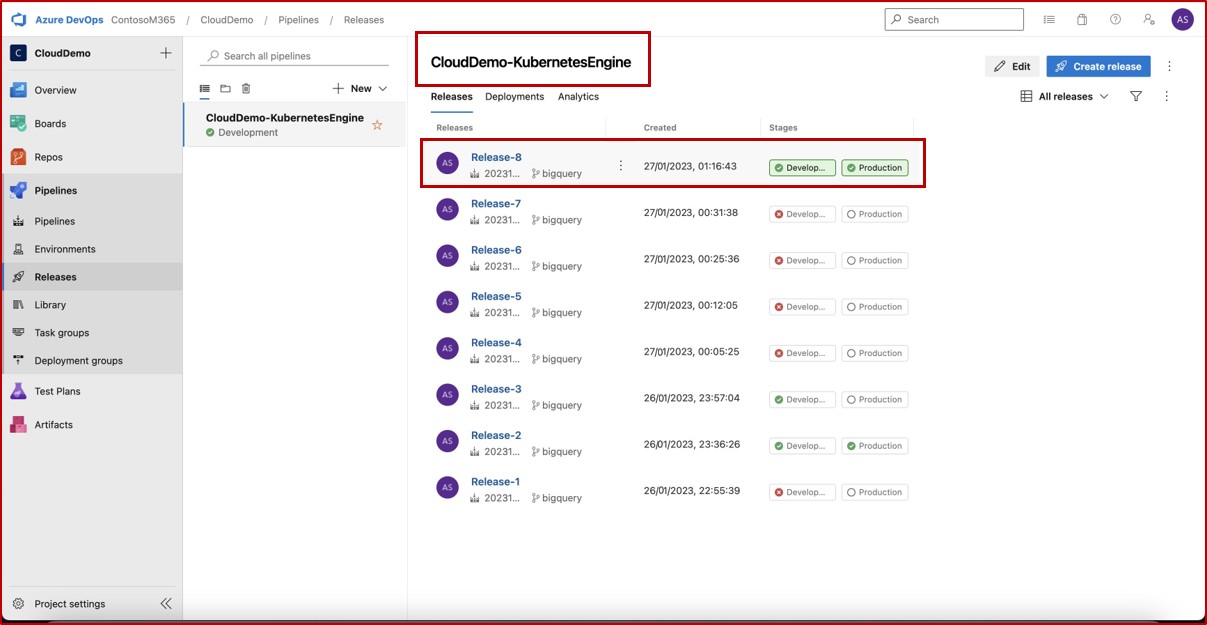
Nota: nos exemplos anteriores, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Account management
As práticas de gestão de contas seguras são importantes, uma vez que as contas de utilizador constituem a base para permitir o acesso a sistemas de informação, ambientes de sistema e dados. As contas de utilizador têm de ser devidamente protegidas, uma vez que um compromisso das credenciais do utilizador pode fornecer não só um ponto de apoio no ambiente e acesso a dados confidenciais, mas também pode fornecer controlo administrativo sobre todo o ambiente ou sistemas chave se as credenciais do utilizador tiverem privilégios administrativos.
Controlo N.º 14
Forneça provas de que:
As credenciais predefinidas são desativadas, removidas ou alteradas nos componentes do sistema de exemplo.
Está em curso um processo para proteger (proteger) contas de serviço e que este processo foi seguido.
Intenção: credenciais predefinidas
Embora isto esteja a tornar-se menos popular, ainda existem instâncias em que os atores de ameaças podem tirar partido das credenciais de utilizador predefinidas e bem documentadas para comprometer os componentes do sistema de produção. Um exemplo popular disto é com Dell iDRAC (Integrated Dell Remote Access Controller). Este sistema pode ser utilizado para gerir remotamente um Dell Server, que pode ser aproveitado por um ator de ameaças para obter controlo sobre o sistema operativo do Servidor. A credencial predefinida de root::calvin está documentada e, muitas vezes, pode ser aproveitada por atores de ameaças para obter acesso aos sistemas utilizados pelas organizações. A intenção deste controlo é garantir que as credenciais predefinidas são desativadas ou removidas para melhorar a segurança.
Diretrizes: credenciais predefinidas
Existem várias formas através das quais as provas podem ser recolhidas para apoiar este controlo. Capturas de ecrã de utilizadores configurados em todos os componentes do sistema podem ajudar, ou seja, capturas de ecrã das contas predefinidas do Windows através da linha de comandos (CMD) e para Linux /etc/shadow e /etc/passwd ficheiros ajudarão a demonstrar se as contas foram desativadas.
Exemplo de evidência: credenciais predefinidas
A captura de ecrã seguinte mostra o ficheiro /etc/shadow para demonstrar que as contas predefinidas têm uma palavra-passe bloqueada e que as novas contas criadas/ativas têm uma palavra-passe utilizável.
Tenha em atenção que o ficheiro /etc/shadow seria necessário para demonstrar que as contas estão verdadeiramente desativadas ao observar que o hash de palavra-passe começa com um caráter inválido, como '!' que indica que a palavra-passe é inutilizável. Nas capturas de ecrã seguintes, "L" significa bloquear a palavra-passe da conta nomeada. Esta opção desativa uma palavra-passe alterando-a para um valor que não corresponde a nenhum valor encriptado possível (adiciona um! no início da palavra-passe). O "P" significa que é uma palavra-passe utilizável.
A segunda captura de ecrã demonstra que, no servidor Windows, todas as contas predefinidas foram desativadas. Ao utilizar o comando "net user" num terminal (CMD), pode listar os detalhes de cada uma das contas existentes, observando que todas estas contas não estão ativas.
Ao utilizar o comando net user no CMD, pode apresentar todas as contas e observar que todas as contas predefinidas não estão ativas.
Intenção: credenciais predefinidas
Muitas vezes, as contas de serviço serão alvo de atores de ameaças, uma vez que são muitas vezes configuradas com privilégios elevados. Estas contas podem não seguir as políticas padrão de palavra-passe porque a expiração das palavras-passe da conta de serviço muitas vezes interrompe a funcionalidade. Por conseguinte, podem ser configuradas com palavras-passe fracas ou palavras-passe reutilizadas na organização. Outro problema potencial, particularmente num ambiente windows, pode ser o facto de o sistema operativo colocar em cache o hash de palavra-passe. Isto pode ser um grande problema se:
a conta de serviço está configurada num serviço de diretório, uma vez que esta conta pode ser utilizada para aceder a vários sistemas com o nível de privilégios configurado ou
a conta de serviço é local, a probabilidade é que a mesma conta/palavra-passe seja utilizada em vários sistemas dentro do ambiente.
Os problemas anteriores podem levar a que um ator de ameaças obtenha acesso a mais sistemas dentro do ambiente e pode levar a uma elevação adicional de privilégios e/ou movimento lateral. Por conseguinte, a intenção é garantir que as contas de serviço são devidamente protegidas e protegidas para ajudar a protegê-las de serem assumidas por um ator de ameaças ou ao limitar o risco caso uma destas contas de serviço seja comprometida. O controlo requer que seja implementado um processo formal para a proteção destas contas, que pode incluir a restrição de permissões, a utilização de palavras-passe complexas e a rotação regular de credenciais.
Diretrizes
Existem muitos guias na Internet para ajudar a proteger as contas de serviço. As provas podem estar na forma de capturas de ecrã que demonstram como a organização implementou uma proteção segura da conta. Alguns exemplos (a expectativa é que sejam utilizadas múltiplas técnicas) incluem:
Restringir as contas a um conjunto de computadores no Active Directory,
Definir a conta para que o início de sessão interativo não seja permitido,
Definir uma palavra-passe extremamente complexa,
Para o Active Directory, ative o sinalizador "A conta é confidencial e não pode ser delegada".
Exemplo de provas
Existem várias formas de proteger uma conta de serviço que será dependente de cada ambiente individual. Seguem-se alguns dos mecanismos que podem ser utilizados:
A captura de ecrã seguinte mostra a opção "A conta é confidencial e ligar-se a ser delegada" está selecionada na conta de serviço "_Prod Conta de Serviço do SQL".
Esta segunda captura de ecrã mostra que a conta de serviço "_Prod Conta de Serviço SQL" está bloqueada no SQL Server e só pode iniciar sessão nesse servidor.
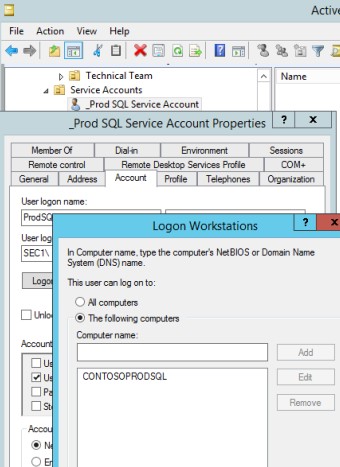
Esta captura de ecrã seguinte mostra que a conta de serviço "_Prod Conta de Serviço SQL" só tem permissão para iniciar sessão como um serviço.
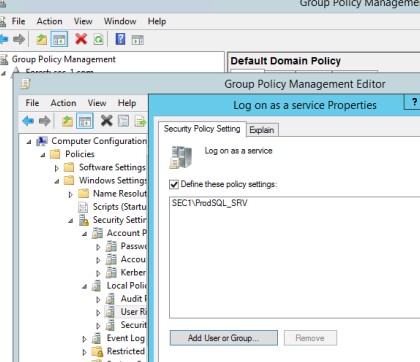
Nota: nos exemplos anteriores, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Controlo N.º 15
Forneça provas de que:
As contas de utilizador exclusivas são emitidas para todos os utilizadores.
Os princípios de menor privilégio do utilizador estão a ser seguidos no ambiente.
Está implementada uma política de palavra-passe/frase de acesso segura ou outras mitigações adequadas.
Um processo está em vigor e é seguido, pelo menos, a cada três meses para desativar ou eliminar contas não utilizadas no prazo de 3 meses.
Intenção: contas de serviço seguras
A intenção deste controlo é a responsabilidade. Ao emitir utilizadores com as suas próprias contas de utilizador exclusivas, os utilizadores serão responsáveis pelas suas ações, uma vez que a atividade do utilizador pode ser controlada por um utilizador individual.
Diretrizes: contas de serviço seguras
A prova seria através de capturas de ecrã que mostram contas de utilizador configuradas nos componentes do sistema no âmbito, que podem incluir servidores, repositórios de código, plataformas de gestão da cloud, Active Directory, Firewalls, etc.
Exemplo de evidência: contas de serviço seguras
A captura de ecrã seguinte mostra as contas de utilizador configuradas para o ambiente do Azure no âmbito e que todas as contas são exclusivas.
Intenção: privilégios
Os utilizadores só devem receber os privilégios necessários para cumprir a função de trabalho. Isto é para limitar o risco de um utilizador aceder intencional ou involuntariamente aos dados que não deve ou realizar uma
ato malicioso. Ao seguir este princípio, também reduz a potencial superfície de ataque (ou seja, contas com privilégios) que podem ser alvo de um ator de ameaças maliciosos.
Diretrizes: privilégios
A maioria das organizações utilizará grupos para atribuir privilégios com base em equipas dentro da organização. As provas podem ser capturas de ecrã que mostram os vários grupos com privilégios e apenas as contas de utilizador das equipas que necessitam destes privilégios. Normalmente, seria criada uma cópia de segurança com políticas/processos de suporte que definem cada grupo definido com os privilégios necessários e justificação comercial e uma hierarquia de membros da equipa para validar que a associação ao grupo está configurada corretamente.
Por exemplo: no Azure, o grupo Proprietários deve ser muito limitado, pelo que deve ser documentado e deve ter um número limitado de pessoas atribuídas a esse grupo. Outro exemplo pode ser um número limitado de funcionários com a capacidade de fazer alterações de código, um grupo pode ser configurado com este privilégio com os membros da equipa considerados como estando a precisar desta permissão configurada. Isto deve ser documentado para que o analista de certificação possa fazer referência cruzada ao documento com os grupos configurados, etc.
Exemplo de evidência: privilégios
As capturas de ecrã seguintes demonstram o princípio do menor privilégio num ambiente do Azure.
A captura de ecrã seguinte realça a utilização de vários grupos no Azure Active Directory (AAD)/Microsoft Entra. Observe que existem três grupos de segurança, Programadores, Engenheiros Potenciais, Operações de Segurança.
Ao navegar para o grupo "Programadores", ao nível do grupo, as únicas funções atribuídas são "Programador de Aplicações" e "Leitores de diretórios".
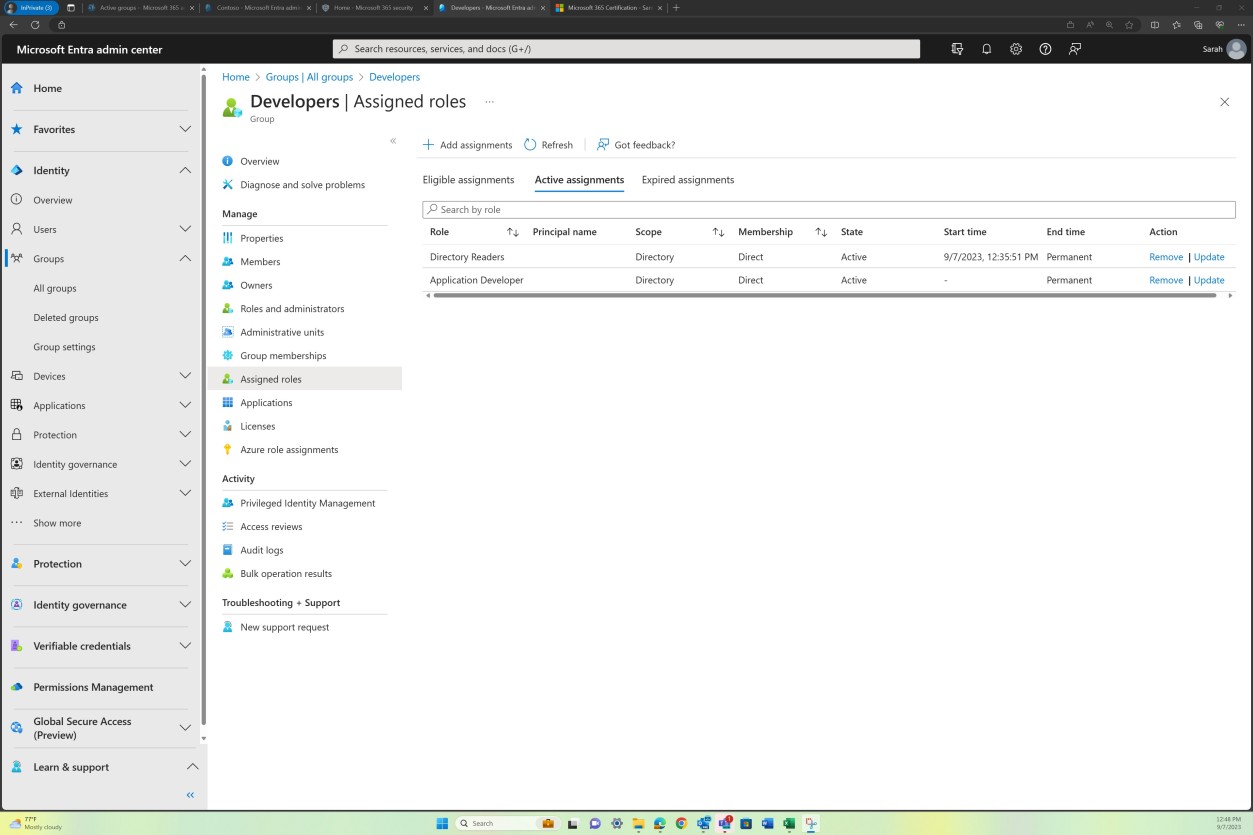
A captura de ecrã seguinte mostra os membros do grupo "Programadores".
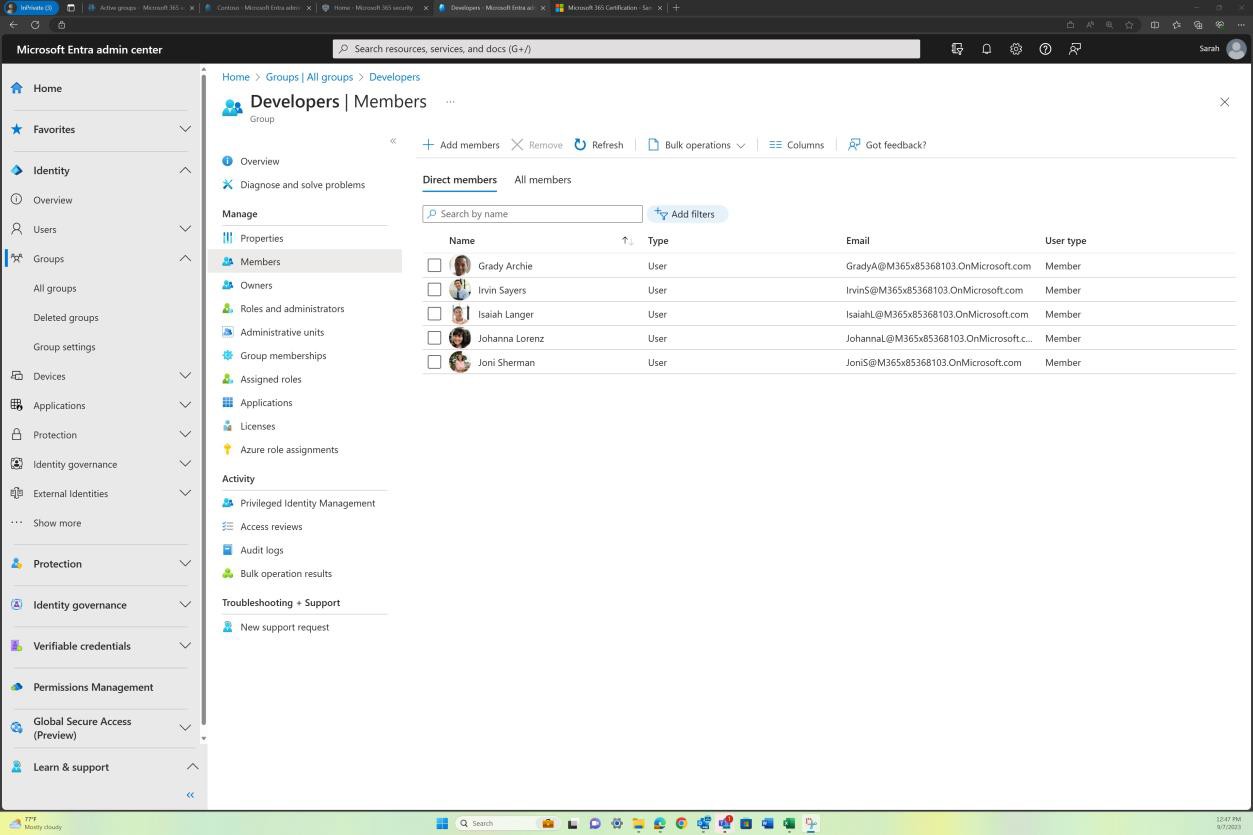
Por fim, a captura de ecrã seguinte mostra o Proprietário do grupo.
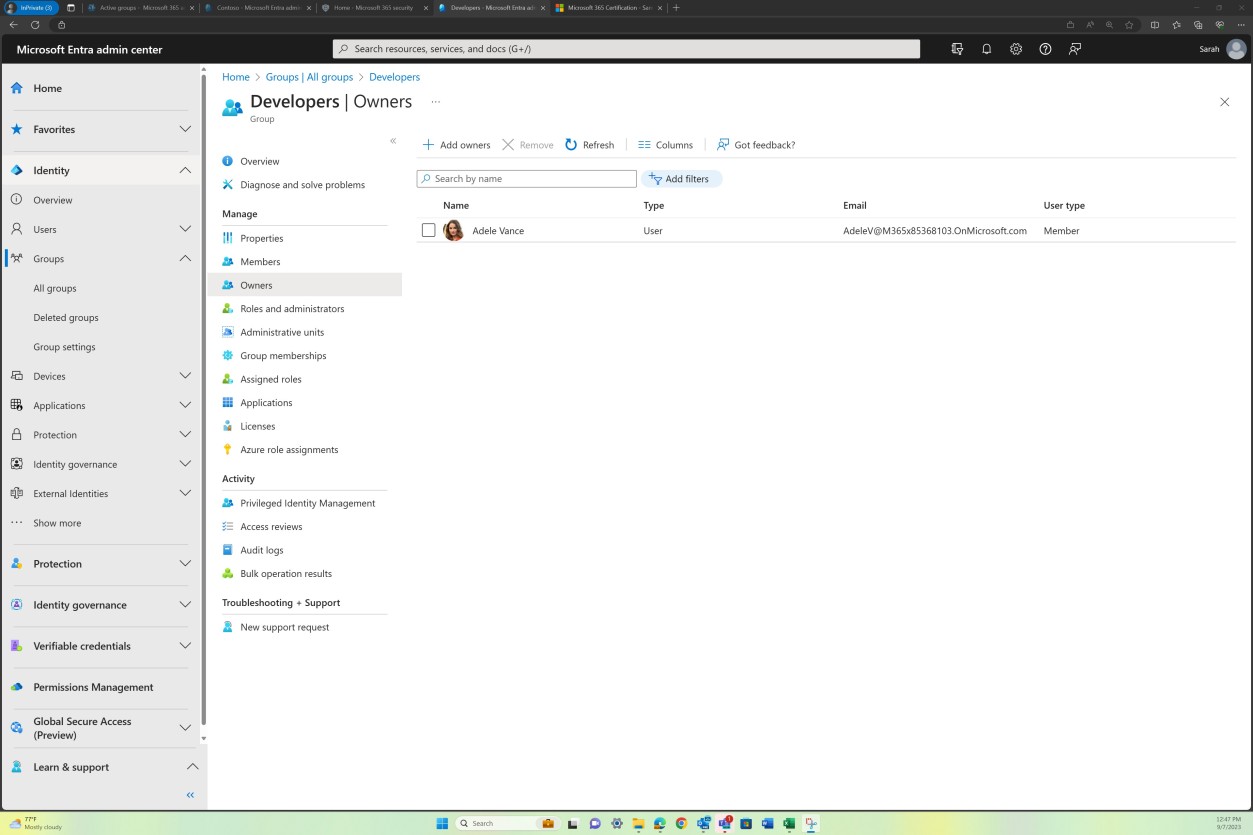
Em contraste com o grupo "Programadores", as "Operações de Segurança" têm diferentes funções atribuídas, ou seja, "Operador de Segurança", que está em conformidade com o requisito da tarefa.
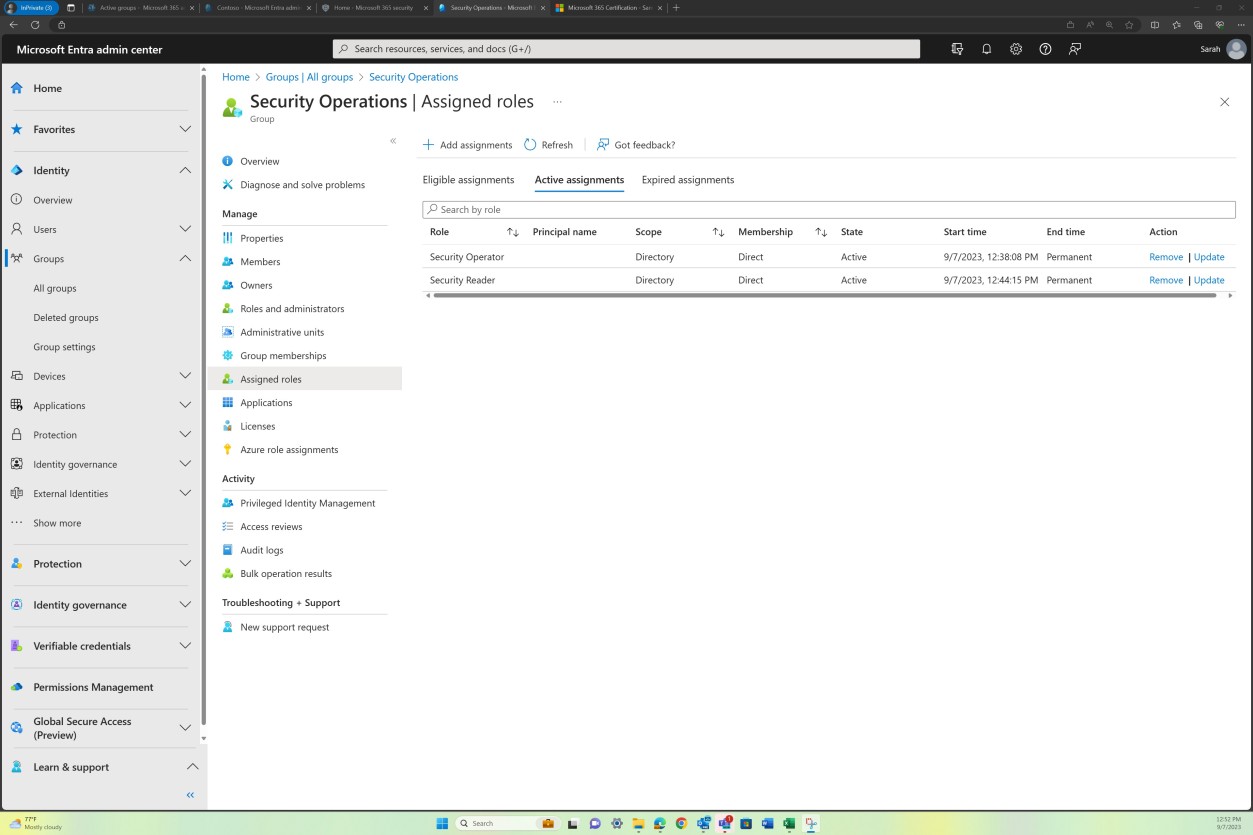
A captura de ecrã seguinte mostra que existem diferentes membros que fazem parte do grupo "Operações de Segurança".
Por fim, o grupo tem um Proprietário diferente.
Os administradores globais são uma função altamente privilegiada e as organizações têm de decidir o nível de risco que pretendem aceitar ao fornecer este tipo de acesso. No exemplo fornecido, existem apenas dois utilizadores que têm esta função. Isto é para garantir que a superfície de ataque e o impacto são diminuídos.
Intenção: política de palavras-passe
As credenciais de utilizador são frequentemente alvo de ataques por parte de atores de ameaças que tentam obter acesso ao ambiente de uma organização. A intenção de uma política de palavras-passe forte é tentar forçar os utilizadores a escolher palavras-passe fortes para mitigar as hipóteses de os atores de ameaças serem capazes de os forçar de forma bruta. A intenção de adicionar a "ou outras mitigações adequadas" é reconhecer que as organizações podem implementar outras medidas de segurança para ajudar a proteger as credenciais do utilizador com base em desenvolvimentos do setor, como a Publicação Especial NIST 800-63B.
Diretrizes: política de palavras-passe
As provas para demonstrar uma política de palavras-passe fortes podem estar na forma de uma captura de ecrã de um Objeto de Política de Grupo de organizações ou das definições de Política de Segurança Local "Políticas de Conta → Política de Palavra-passe" e "Políticas de Conta → Política de Bloqueio de Conta". As provas dependem das tecnologias que estão a ser utilizadas, ou seja, para Linux, pode ser o ficheiro de configuração /etc/pam.d/common-password, para o Bitbucket, a secção "Políticas de Autenticação" no Portal de Administração [Gerir a política de palavras-passe | Suporte atlassiano, etc.
Exemplo de evidência: política de palavras-passe
As provas seguintes mostram a política de palavras-passe configurada na "Política de Segurança Local" do componente de sistema no âmbito "CONTOSO-SRV1".
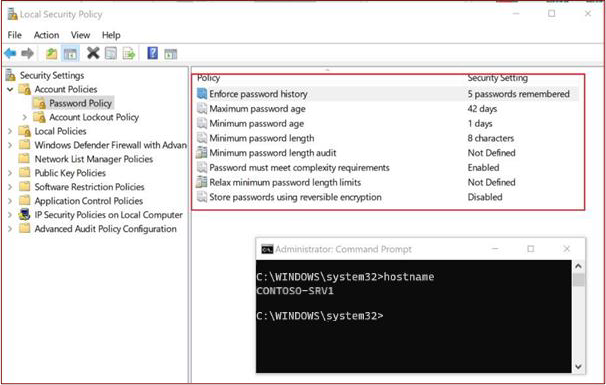
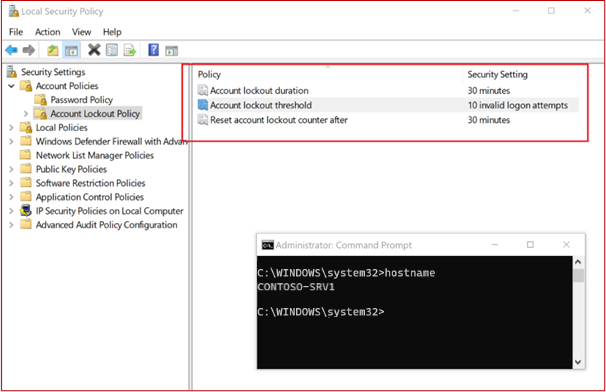
A captura de ecrã seguinte mostra as definições de Bloqueio de Conta para uma Firewall do WatchGuard.
Segue-se um exemplo de um comprimento mínimo de frase de acesso para a Firewall do WatchGuard.
Nota: nos exemplos anteriores, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas a mostrar o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Intenção: contas inativas
Por vezes, as contas inativas podem ficar comprometidas porque são alvo de ataques de força bruta que podem não ser sinalizados, uma vez que o utilizador não está a tentar iniciar sessão nas contas ou através de uma falha de segurança da base de dados de palavras-passe em que a palavra-passe de um utilizador foi reutilizada e está disponível numa captura de nome de utilizador/palavra-passe na Internet. As contas não utilizadas devem ser desativadas/removidas para reduzir a superfície de ataque que um ator de ameaças tem de realizar atividades de comprometimento de conta. Estas contas podem dever-se ao facto de um processo de abandono não estar a ser realizado corretamente, de um membro do pessoal que se depare com doença de longa duração ou de um membro do pessoal em licença de maternidade/paternidade. Ao implementar um processo trimestral para identificar estas contas, as organizações podem minimizar a superfície de ataque.
Este controlo determina que um processo tem de estar em vigor e seguido, pelo menos, de três em três meses para desativar ou eliminar contas que não tenham sido utilizadas nos últimos três meses com o objetivo de reduzir o risco, garantindo revisões regulares da conta e desativação atempadamente das contas não utilizadas.
Diretrizes: contas inativas
As provas devem ser duplas:
Primeiro, uma captura de ecrã ou exportação de ficheiros a mostrar o "último início de sessão" de todas as contas de utilizador no ambiente no âmbito. Podem ser contas locais, bem como contas num serviço de diretório centralizado, como o AAD (Azure Active Directory). Isto irá demonstrar que não existem contas com mais de 3 meses ativadas.
Em segundo lugar, os elementos de prova do processo de revisão trimestral, que podem ser provas documentais da tarefa a ser concluída no ADO (Azure DevOps) ou em bilhetes JIRA, ou através de registos em papel que devem ser assinados.
Exemplo de evidência: contas inativas
A captura de ecrã seguinte demonstra que foi utilizada uma plataforma na cloud para realizar revisões de acesso. Isto foi conseguido com a funcionalidade Governação de Identidades no Azure.
A captura de ecrã seguinte demonstra o histórico de revisões, o período de revisão e o estado.
O dashboard e as métricas formam a revisão e fornecem detalhes adicionais, como o âmbito que é todos os utilizadores da organização e o resultado da revisão, bem como a frequência trimestral.
Ao avaliar os resultados da revisão, a imagem indica que foi fornecida uma ação recomendada, que se baseia em condições pré-configuradas. Além disso, requer que um indivíduo atribuído aplique manualmente as decisões da revisão.
Pode observar no seguinte que, para cada colaborador, existe uma recomendação e uma justificação fornecidas. Conforme mencionado, a decisão de aceitar a recomendação ou ignorá-la antes de aplicar a revisão é exigida por um indivíduo atribuído. Se a decisão final for contra a recomendação, então a expectativa será que sejam fornecidas provas para explicar o porquê.
Controlo N.º 16
Confirme que a autenticação multifator (MFA) está configurada para todas as ligações de acesso remoto e todas as interfaces administrativas não consola, incluindo o acesso a quaisquer repositórios de código e interfaces de gestão da cloud.
Significado destes termos
Acesso Remoto – refere-se às tecnologias utilizadas para aceder ao ambiente de suporte. Por exemplo, VPN IPSec de Acesso Remoto, VPN SSL ou Jumpbox/Anfitrião Bastian.
Interfaces Administrativas não consola – refere-se às ligações administrativas de rede aos componentes do sistema. Isto pode ser através do Ambiente de Trabalho Remoto, SSH ou de uma interface Web.
Repositórios de Código – a base de código da aplicação tem de ser protegida contra modificações maliciosas que possam introduzir software maligno na aplicação. A MFA tem de ser configurada nos repositórios de código.
Interfaces de Gestão da Cloud – onde alguns ou todos os ambientes estão alojados no Fornecedor de Serviços Cloud (CSP). A interface administrativa para a gestão da cloud está incluída aqui.
Intenção: MFA
A intenção deste controlo é fornecer mitigações contra ataques de força bruta em contas privilegiadas com acesso seguro ao ambiente através da implementação da autenticação multifator (MFA). Mesmo que uma palavra-passe seja comprometida, o mecanismo de MFA deve continuar a ser protegido, garantindo que todas as ações administrativas e de acesso são realizadas apenas por docentes autorizados e fidedignos.
Para melhorar a segurança, é importante adicionar uma camada adicional de segurança para ligações de acesso remoto e interfaces administrativas não consola com mFA. As ligações de acesso remoto são particularmente vulneráveis a entradas não autorizadas e as interfaces administrativas controlam funções de privilégio elevado, tornando ambas as áreas críticas que requerem medidas de segurança elevadas. Além disso, os repositórios de código contêm trabalhos confidenciais de desenvolvimento e as interfaces de gestão da cloud fornecem um amplo acesso aos recursos da cloud de uma organização, tornando-os pontos críticos adicionais que devem ser protegidos com MFA.
Diretrizes: MFA
As provas têm de mostrar que a MFA está ativada em todas as tecnologias que se enquadram nas categorias anteriores. Isto pode ser através de uma captura de ecrã que mostra que a MFA está ativada ao nível do sistema. Ao nível do sistema, precisamos de provas de que está ativada para todos os utilizadores e não apenas um exemplo de uma conta com a MFA ativada. Quando a tecnologia é recuada para uma solução de MFA, precisamos de provas que demonstrem que está ativada e em utilização. O que significa isto é; em que a tecnologia está configurada para a Autenticação Radius, que aponta para um fornecedor de MFA, também tem de evidenciar que o Servidor Radius para o qual está a apontar é uma solução de MFA e que as contas estão configuradas para utilizá-lo.
Exemplo de evidência: MFA
As capturas de ecrã seguintes demonstram como uma política Condicional de MFA pode ser implementada no AAD/Entra para impor o requisito de autenticação de dois fatores em toda a organização. Podemos ver no seguinte que a política está "ativada".
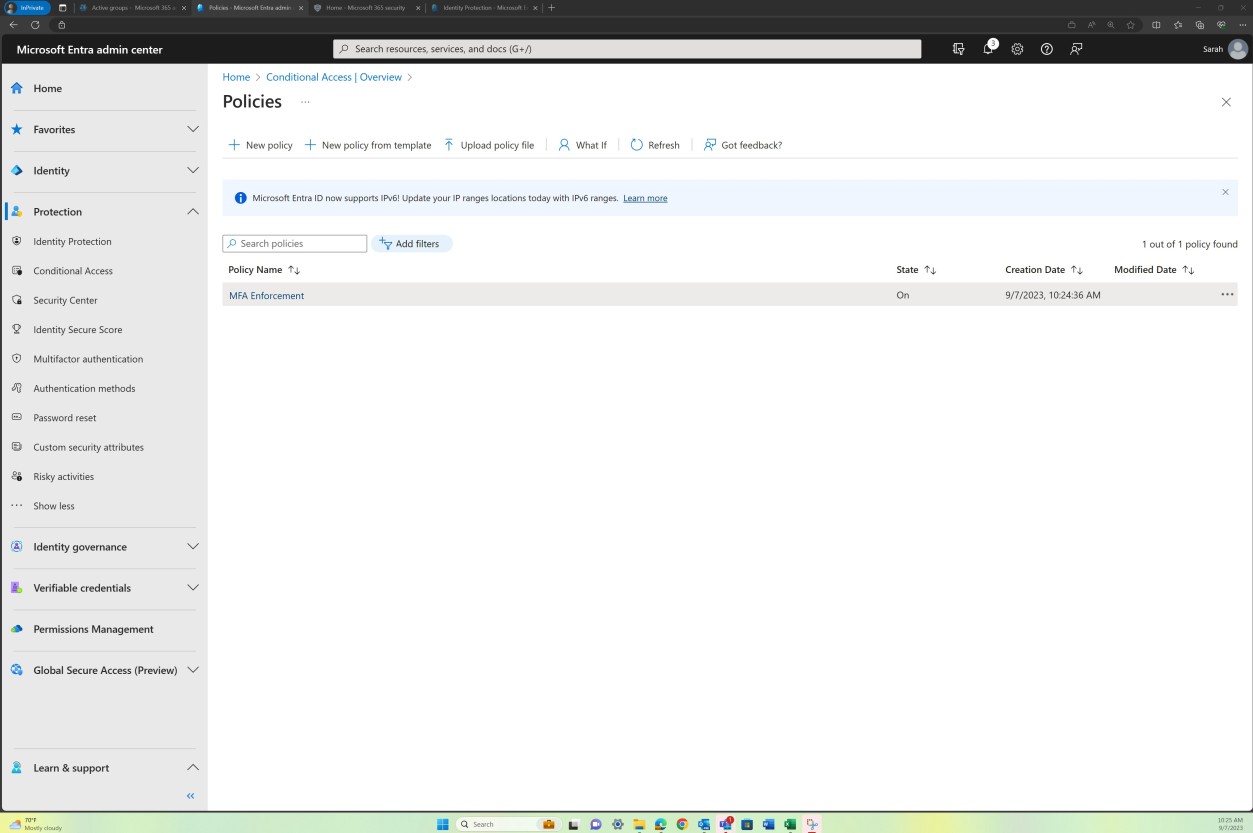
A captura de ecrã seguinte mostra que a política de MFA deve ser aplicada a todos os utilizadores na organização e que esta ação está ativada.
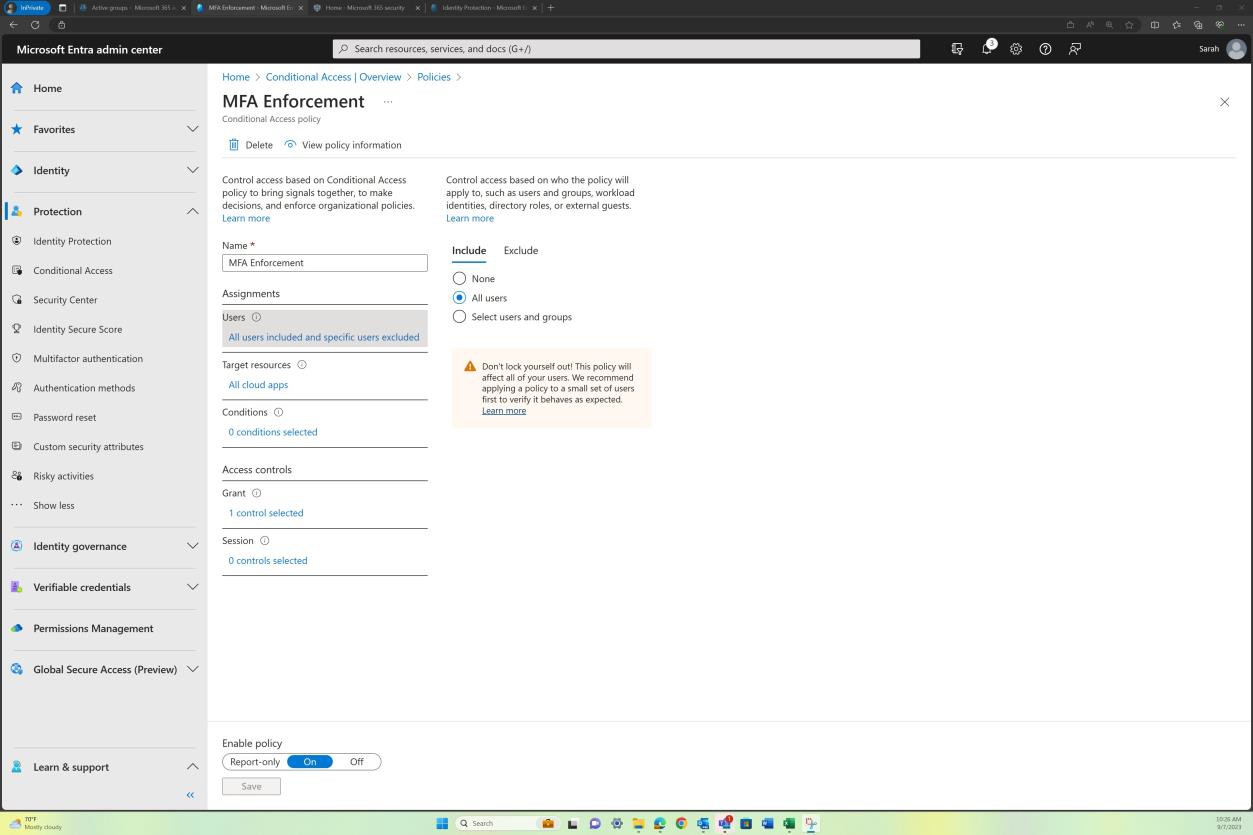
A captura de ecrã seguinte demonstra que o acesso é concedido após cumprir a condição de MFA. No lado direito da captura de ecrã, podemos ver que o acesso só será concedido a um utilizador assim que a MFA for implementada.
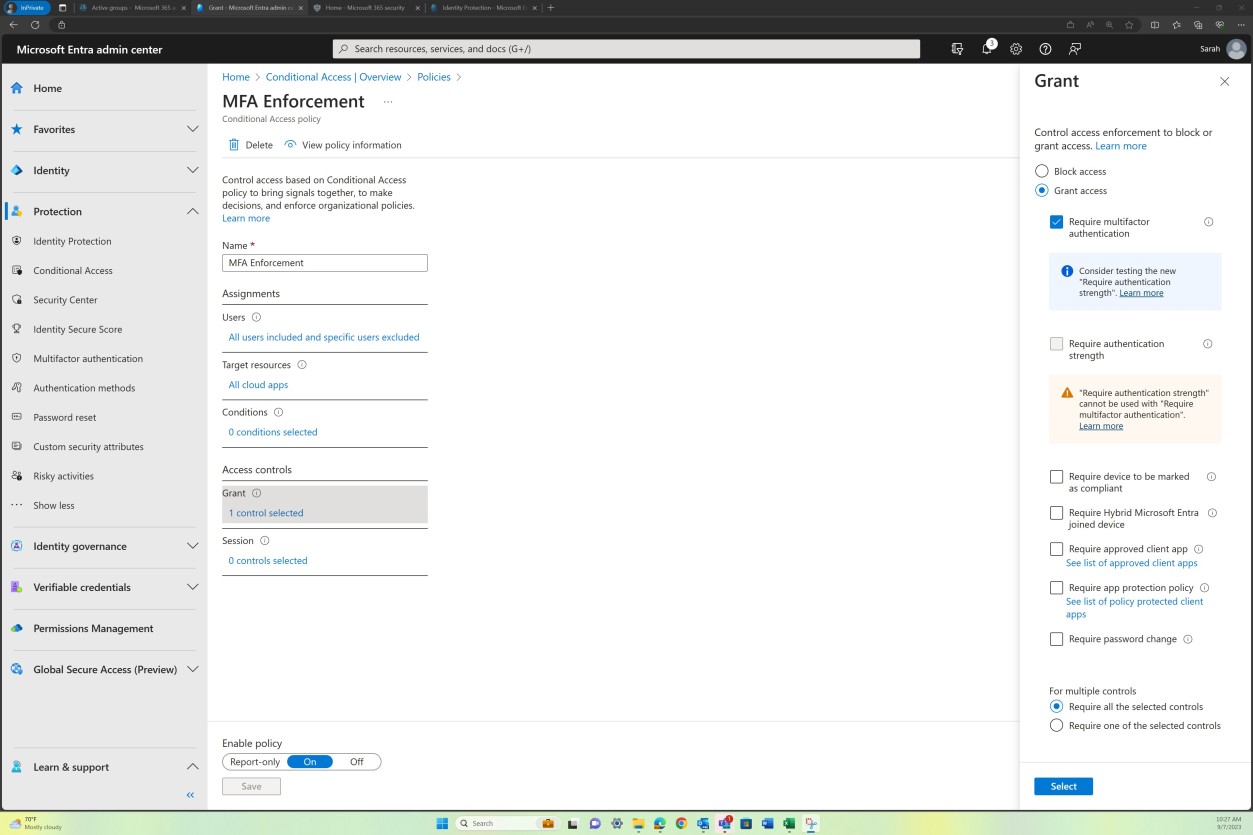
Exemplo de evidência: MFA
Podem ser implementados controlos adicionais, como um requisito de registo da MFA, que garante que, após o registo, os utilizadores terão de configurar a MFA antes de ser concedido acesso à nova conta. Pode observar abaixo a configuração de uma política de registo da MFA que é aplicada a todos os utilizadores.
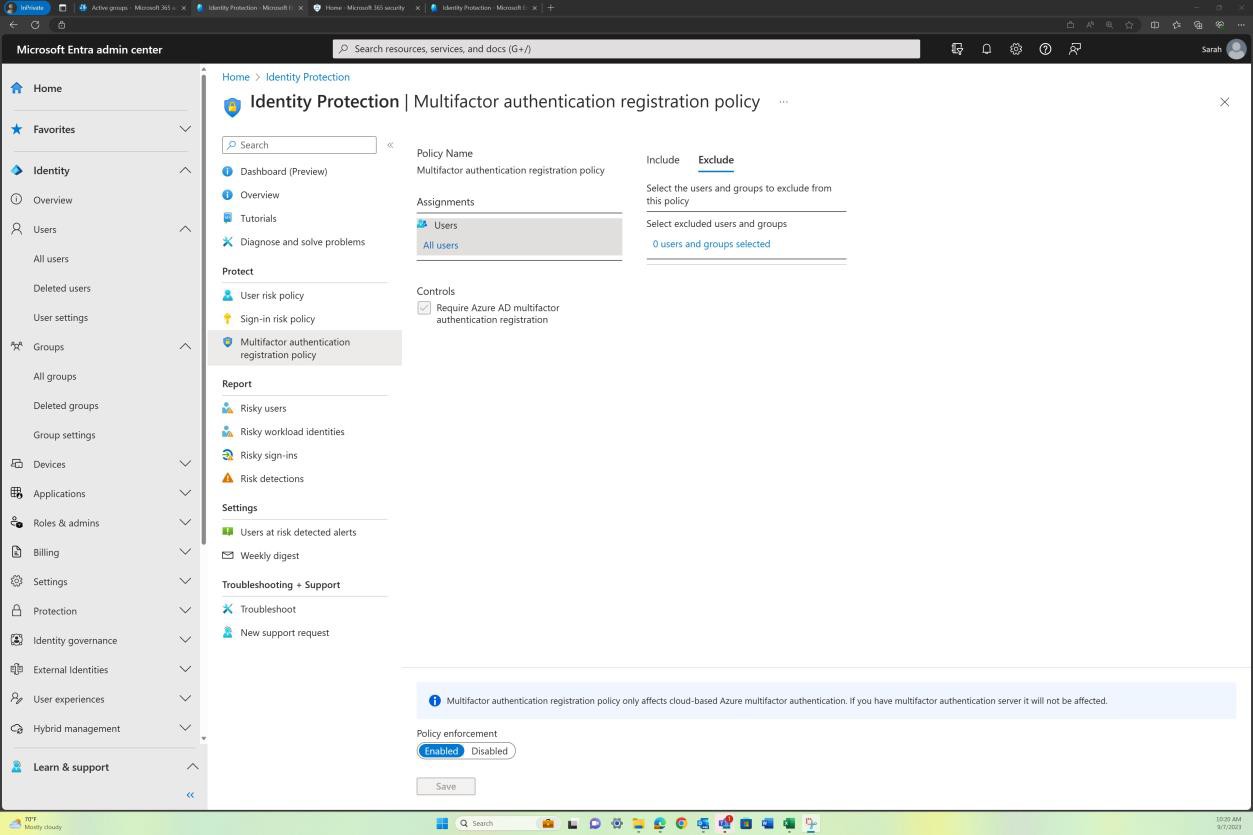
Na continuação da captura de ecrã anteriormente que mostra a política a ser aplicada sem exclusões, a captura de ecrã seguinte demonstra que todos os utilizadores estão incluídos na política.
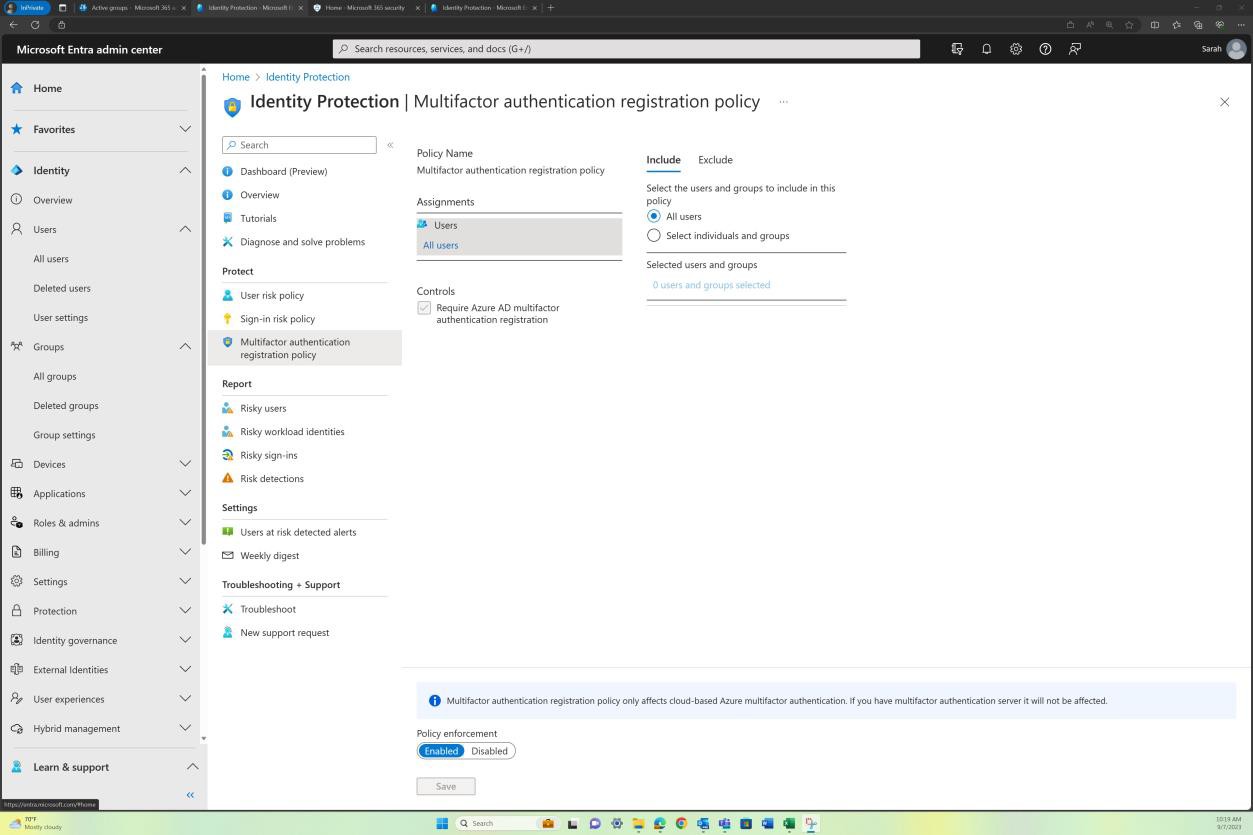
Exemplo de evidência: MFA
A captura de ecrã seguinte mostra que a página "MFA por utilizador" está a demonstrar que a MFA é imposta a todos os utilizadores.
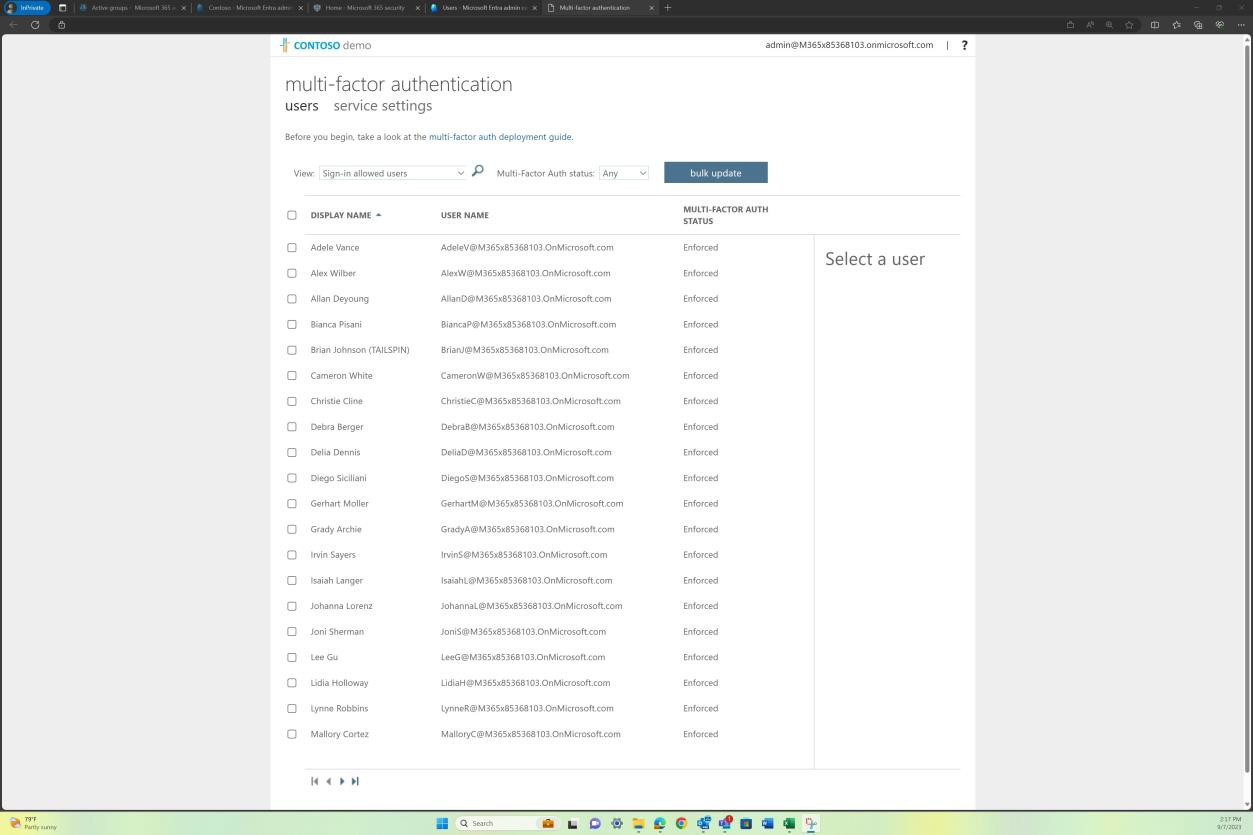
Exemplo de evidência: MFA
As capturas de ecrã seguintes mostram os realms de autenticação configurados no Pulse Secure, que é utilizado para o acesso remoto ao ambiente. A autenticação é suportada pelo Serviço SaaS Duo para Suporte da MFA.
Esta captura de ecrã demonstra que está ativado um servidor de autenticação adicional que está a apontar para "Duo-LDAP" para o realm de autenticação "Duo - Rota Predefinida".
Esta captura de ecrã final mostra a configuração do servidor de autenticação Duo-LDAP, que demonstra que está a apontar para o serviço Duo SaaS para MFA.
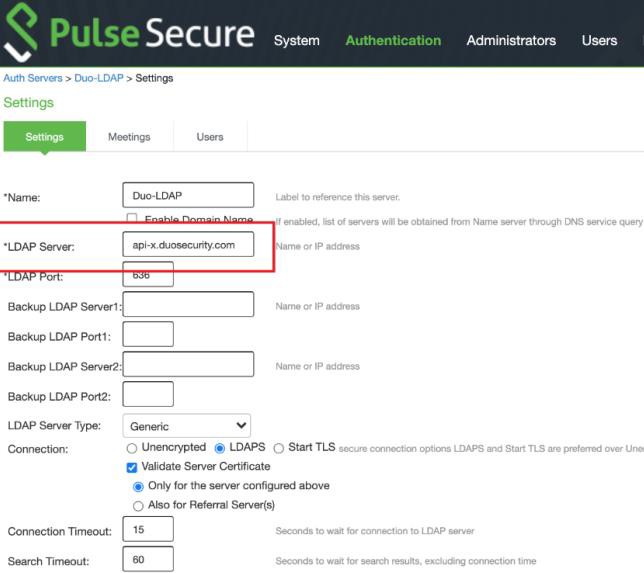
Nota: nos exemplos anteriores, não foi utilizada uma captura de ecrã completa. No entanto, todas as capturas de ecrã submetidas pelo ISV têm de ser capturas de ecrã completas que mostrem o URL, qualquer data e hora do sistema e utilizador com sessão iniciada.
Registo, revisão e alertas de eventos de segurança
O registo de eventos de segurança é parte integrante do programa de segurança de uma organização. O registo adequado de eventos de segurança associados a alertas ajustados e processos de revisão ajuda as organizações a identificar falhas ou tentativas de violação que podem ser utilizadas pela organização para melhorar estratégias de segurança defensivas e de segurança. Além disso, o registo adequado será fundamental para uma capacidade de resposta a incidentes de organizações que pode alimentar outras atividades, tais como ser capaz de identificar com precisão o que e quem os dados foram comprometidos, o período de comprometimento, fornecer relatórios de análise detalhados a agências governamentais, etc.
Rever os registos de segurança é uma função importante para ajudar as organizações a identificar eventos de segurança que podem indicar uma falha de segurança ou atividades de reconhecimento que podem ser uma indicação de algo que está para vir. Isto pode ser feito diariamente através de um processo manual ou através de uma solução SIEM (Gestão de Informações de Segurança e Eventos) que ajuda na análise de registos de auditoria, à procura de correlações e anomalias que podem ser sinalizadas para uma inspeção manual.
Os eventos de segurança críticos têm de ser imediatamente investigados para minimizar o impacto nos dados e no ambiente operacional. Os alertas ajudam a destacar imediatamente potenciais falhas de segurança para os funcionários para garantir uma resposta atempadamente para que a organização possa conter o evento de segurança o mais rapidamente possível. Ao garantir que os alertas estão a funcionar de forma eficaz, as organizações podem minimizar o impacto de uma falha de segurança, reduzindo assim a possibilidade de uma grave violação que possa prejudicar a marca das organizações e impor perdas financeiras através de multas e danos reputacionais.
Controlo N.º 17
Forneça provas de que o registo de eventos de segurança está configurado no ambiente no âmbito para registar eventos quando aplicável, tais como:
Acesso de utilizador/s aos componentes do sistema e à aplicação.
Todas as ações executadas por um utilizador com privilégios elevados.
Tentativas de acesso lógico inválidas.
Criação/modificação de conta privilegiada.
Adulteração do registo de eventos.
Desativar as ferramentas de segurança; por exemplo, registo de eventos.
Registo antimalware; por exemplo, atualizações, deteção de software maligno, falhas de análise.
Intenção: registo de eventos
Para identificar falhas de segurança tentadas e reais, é importante que estejam a ser recolhidos registos de eventos de segurança adequados por todos os sistemas que constituem o ambiente. A intenção deste controlo é garantir que os tipos corretos de eventos de segurança estão a ser capturados, que podem, em seguida, alimentar os processos de revisão e alerta para ajudar a identificar e responder a estes eventos.
Este subponto requer que um ISV tenha configurado o registo de eventos de segurança para capturar todas as instâncias de acesso do utilizador a aplicações e componentes do sistema. Isto é fundamental para monitorizar quem está a aceder aos componentes do sistema e às aplicações na organização e é essencial para fins de segurança e auditoria.
Este subponto requer que todas as ações realizadas por utilizadores com privilégios de alto nível sejam registadas. Os utilizadores com privilégios elevados podem fazer alterações significativas que podem afetar a postura de segurança da organização. Por conseguinte, é fundamental manter um registo das suas ações.
Este subponto requer o registo de quaisquer tentativas inválidas para obter acesso lógico a aplicações ou componentes do sistema. Este registo é uma forma principal de detetar tentativas de acesso não autorizado e potenciais ameaças de segurança.
Este subponto requer o registo de qualquer criação ou modificação de contas com acesso privilegiado. Este tipo de registo é crucial para controlar as alterações às contas que têm um elevado nível de acesso ao sistema e podem ser alvo de atacantes.
Este subponto requer o registo de quaisquer tentativas de adulteração dos registos de eventos. A adulteração de registos pode ser uma forma de ocultar atividades não autorizadas e, por conseguinte, é fundamental que essas ações sejam registadas e executadas.
Este subponto requer o registo de quaisquer ações que desativem as ferramentas de segurança, incluindo o próprio registo de eventos. Desativar as ferramentas de segurança pode ser um sinalizador vermelho que indica um ataque ou uma ameaça interna.
Este subponto requer o registo de atividades relacionadas com ferramentas antimalware, incluindo atualizações, deteção de software maligno e falhas de análise. O bom funcionamento e a atualização das ferramentas antimalware são essenciais para a segurança e os registos de uma organização relacionados com estas atividades ajudam na monitorização.
Diretrizes: registo de eventos
As provas através de capturas de ecrã ou definições de configuração devem ser fornecidas em todos os dispositivos de amostra e quaisquer componentes de sistema relevantes para demonstrar como o registo é configurado para garantir que estes tipos de eventos de segurança são capturados.
Exemplo de provas
As capturas de ecrã seguintes mostram as configurações de registos e métricas geradas por diferentes recursos no Azure, que são depois ingeridos na área de trabalho centralizada do Log Analytic.
Na primeira captura de ecrã, podemos ver que a localização de armazenamento de registos é "PaaS-web-app-log-analytics".
No Azure, as definições de diagnóstico podem ser ativadas nos recursos do Azure para acesso a registos de auditoria, segurança e diagnóstico, conforme demonstrado abaixo. Os registos de atividades, que estão disponíveis automaticamente, incluem origem do evento, data, utilizador, carimbo de data/hora, endereços de origem, endereços de destino e outros elementos úteis.
Nota: os exemplos seguintes mostram um tipo de prova que pode ser fornecido para cumprir este controlo. Isto depende da forma como a sua organização configurou o registo de eventos de segurança no ambiente no âmbito. Outros exemplos podem incluir o Azure Sentinel, o Datadog, etc.
Ao utilizar a opção "Definições de Diagnóstico" para a aplicação Web alojada nos Serviços de Aplicações do Azure, pode configurar os registos gerados e para onde são enviados para armazenamento e análise.
Na captura de ecrã seguinte, "Aceder a Registos de Auditoria" e "Registos de Auditoria ipSecurity" estão configurados para serem gerados e capturados na área de trabalho do Log Analytic.
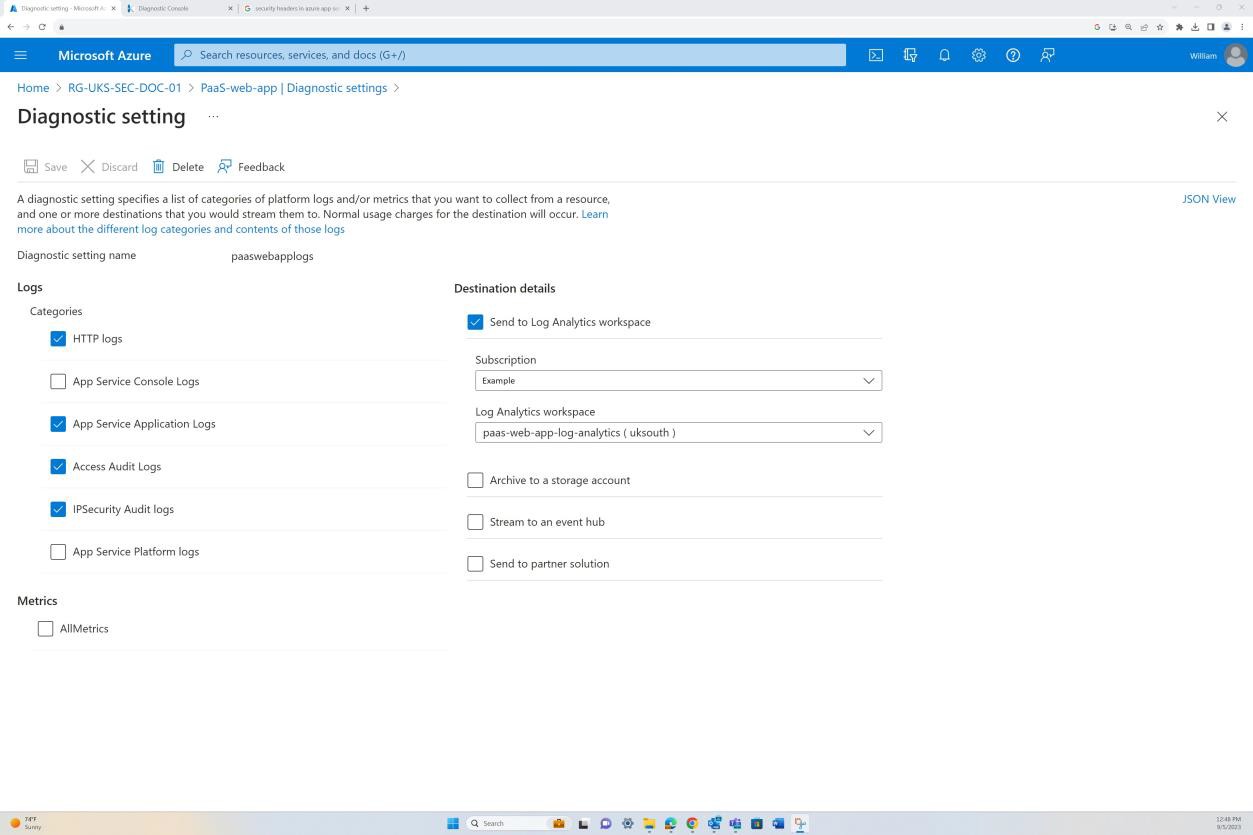
Outro exemplo é o Azure Front Door, que está configurado para enviar registos gerados para a mesma área de trabalho centralizada do Log Analytic.
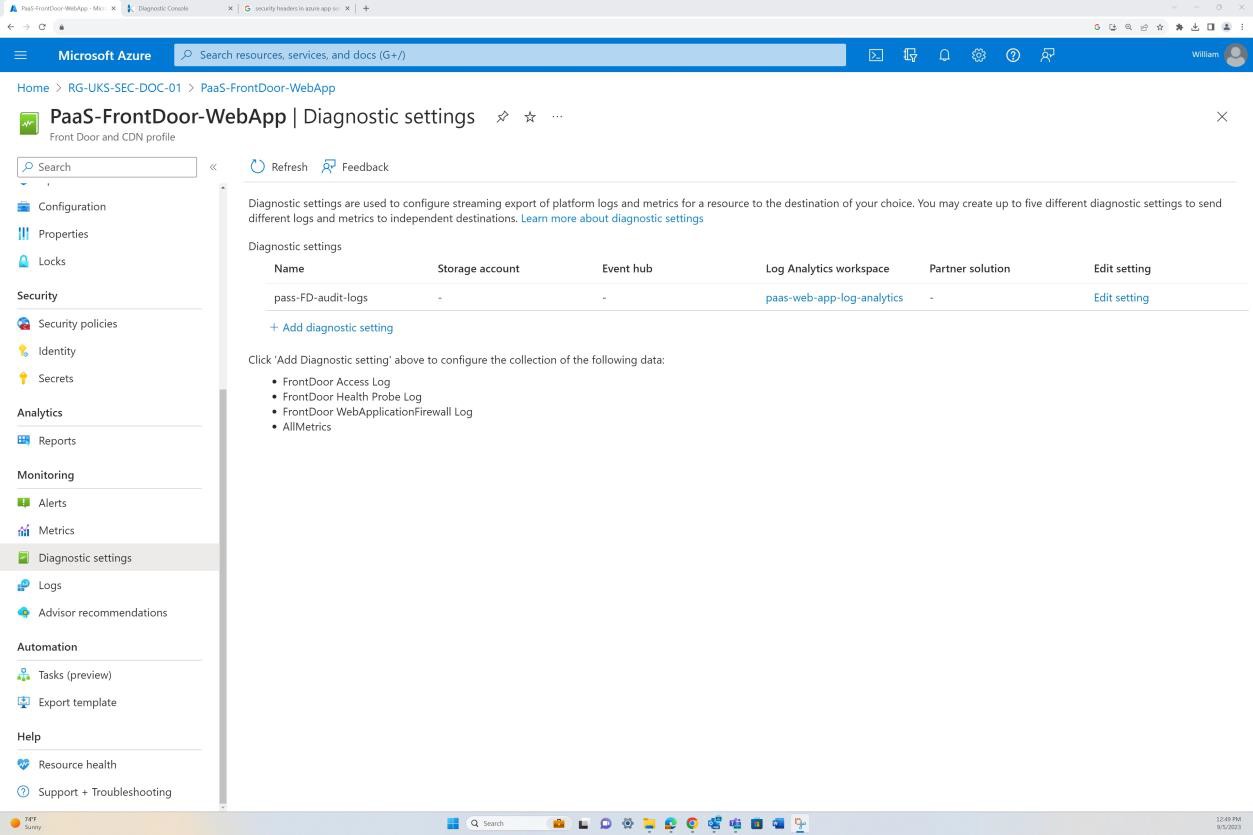
Tal como antes de utilizar a opção "Definições de Diagnóstico", configure que registos são gerados e para onde são enviados para armazenamento e análise. A captura de ecrã seguinte demonstra que foram configurados "Registos de acesso" e "registos WAF".
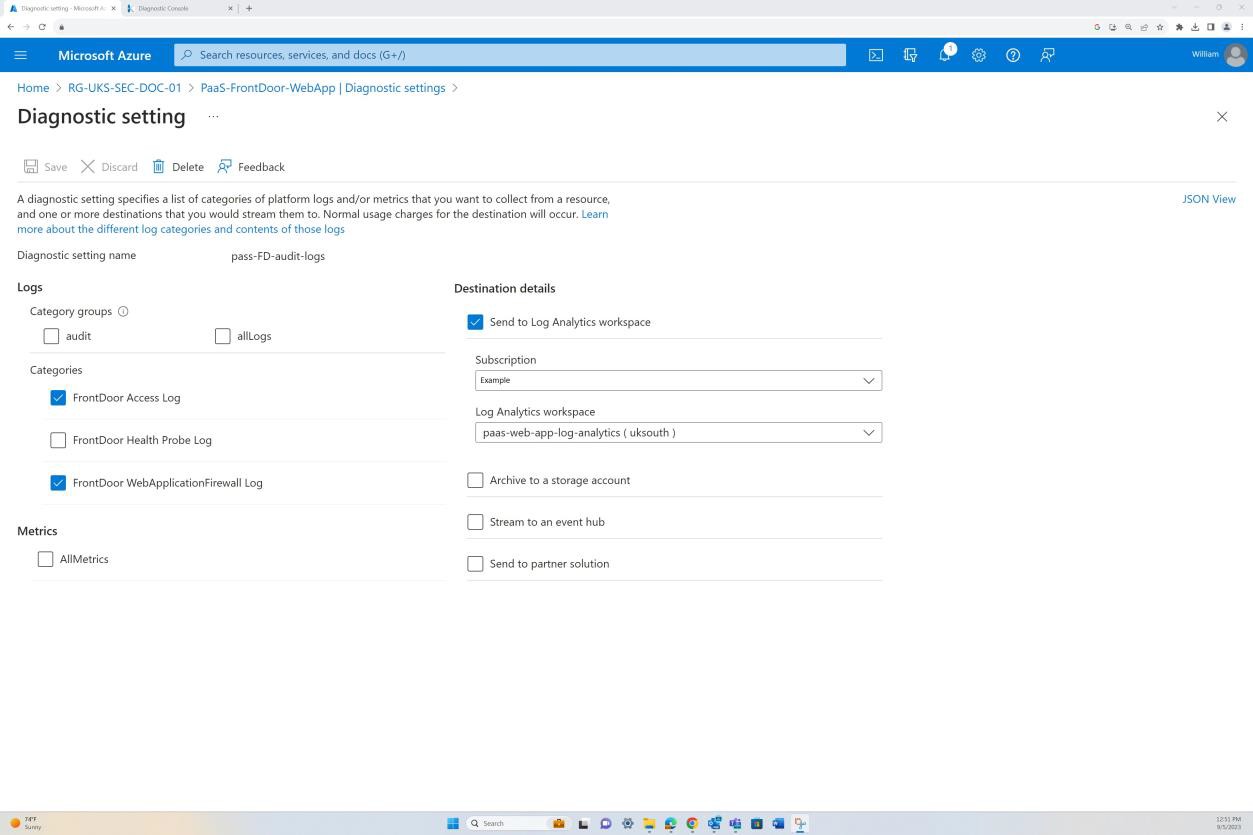
Da mesma forma, para o SQL Server do Azure, as "Definições de Diagnóstico" podem configurar que registos são gerados e para onde são enviados para armazenamento e análise.
A captura de ecrã seguinte demonstra que os registos de "auditoria" do SQL Server são gerados e enviados para a área de trabalho do Log Analytics.
Exemplo de provas
A captura de ecrã seguinte do AAD/Entra demonstra que estão a ser gerados registos de auditoria para administradores e funções com privilégios. As informações incluem estado, atividade, serviço, destino e iniciador.
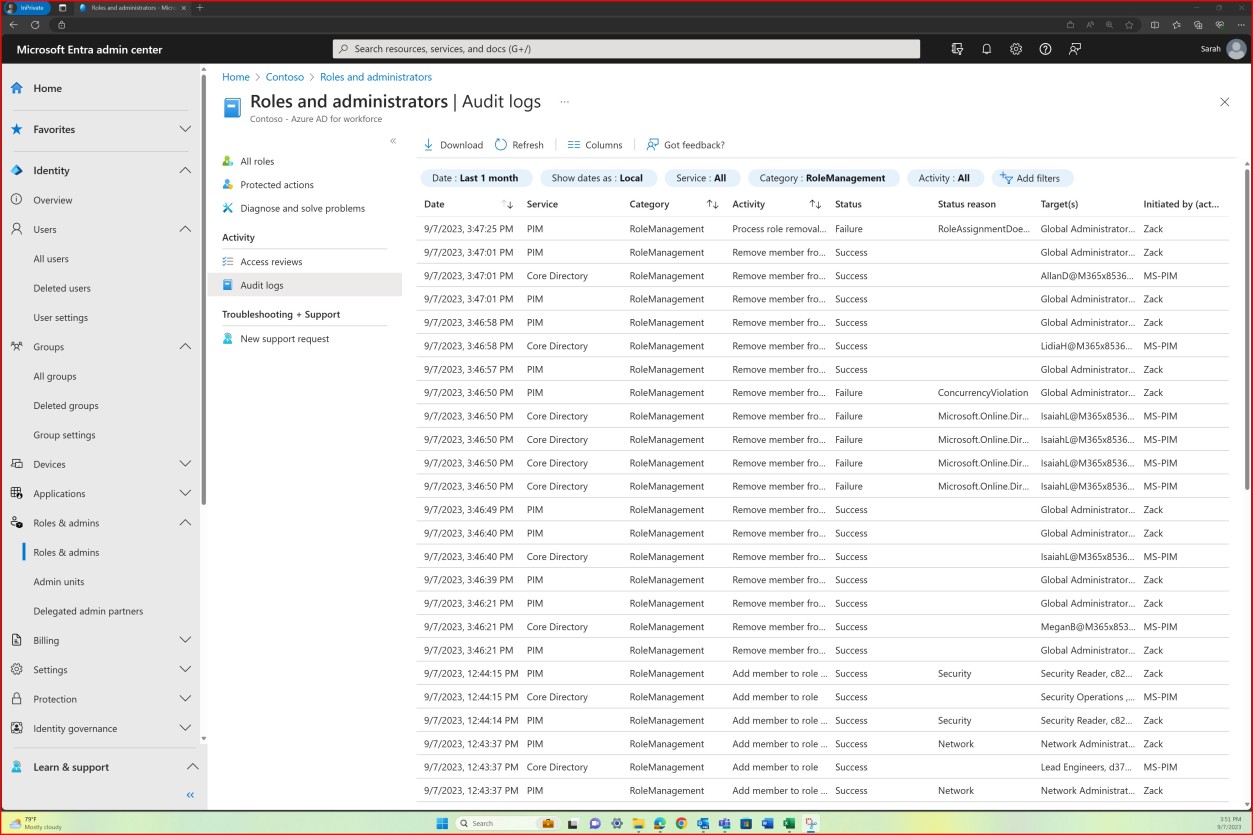
A captura de ecrã seguinte mostra os registos de início de sessão. As informações de registo incluem o endereço IP, o Estado, a Localização e a Data.
Exemplo de provas
O exemplo seguinte centra-se nos registos gerados para instâncias de computação, como Máquinas Virtuais (VMs). Foi implementada uma regra de recolha de dados e os registos de eventos do Windows, incluindo os registos de Auditoria de Segurança, são capturados.
A captura de ecrã seguinte mostra outro exemplo de definições de configuração de um dispositivo de amostra denominado "Galaxy-Compliance". As definições demonstram as várias definições de auditoria ativadas na "Política de Segurança Local".
Esta captura de ecrã seguinte mostra um evento em que um utilizador limpou o registo de eventos do dispositivo de amostra "Galaxy-Compliance".
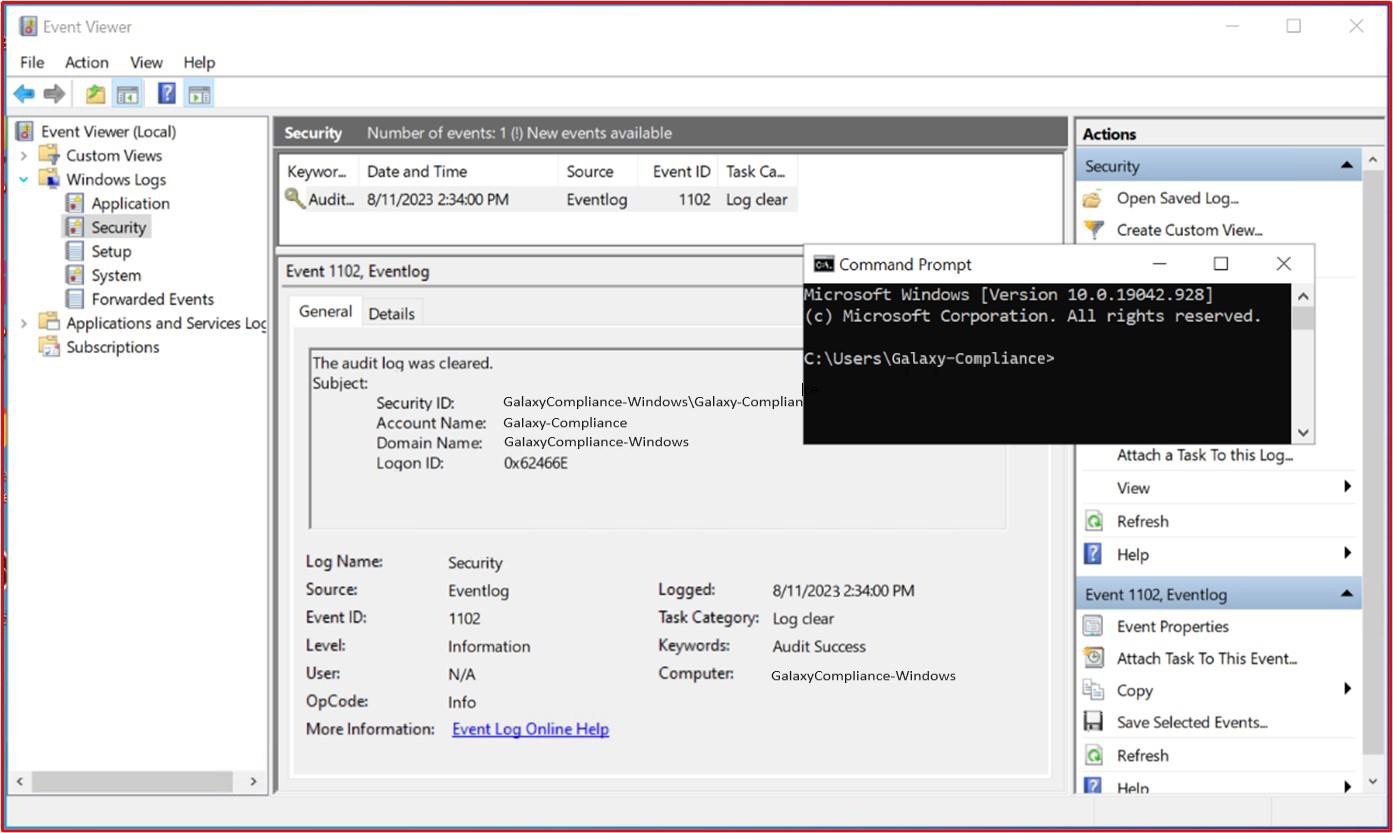
Tenha em atenção que os exemplos anteriores não são capturas de ecrã inteiro. Terá de submeter capturas de ecrã inteiro com qualquer URL, utilizador com sessão iniciada e carimbo de data e hora para revisão de provas. Se for um utilizador do Linux, isto pode ser feito através da linha de comandos.
Controlo N.º 18
Forneça provas de que estão imediatamente disponíveis, no mínimo, 30 dias de dados de registo de eventos de segurança, com 90 dias de registos de eventos de segurança retidos.
Intenção: registo de eventos
Por vezes, existe uma lacuna no tempo entre um evento de compromisso ou segurança e uma organização que o identifica. A intenção deste controlo é garantir que a organização tem acesso a dados históricos de eventos para ajudar na resposta ao incidente e em qualquer trabalho de investigação forense que possa ser necessário. Garantir que a organização retém um mínimo de 30 dias de dados de registo de eventos de segurança que estão imediatamente disponíveis para análise para facilitar uma investigação rápida e resposta a incidentes de segurança. Além disso, é retido um total de 90 dias de registos de eventos de segurança para permitir uma análise aprofundada.
Diretrizes: registo de eventos
Normalmente, as provas serão apresentadas através da apresentação das definições de configuração da solução de registo centralizada, que mostra durante quanto tempo os dados são mantidos. Os dados de registo de eventos de segurança no valor de 30 dias têm de estar imediatamente disponíveis na solução. No entanto, quando os dados são arquivados, é necessário demonstrar que estão disponíveis 90 dias. Tal pode dever-se à apresentação de pastas de arquivo com datas de dados exportados.
Exemplo de evidência: registo de eventos
Seguindo o exemplo anterior no Controlo 17 em que uma área de trabalho centralizada do Log Analytic está a ser utilizada para armazenar todos os registos gerados pelos recursos da cloud, pode observar abaixo que os registos estão a ser armazenados em tabelas individuais para cada categoria de registo. Além disso, a retenção interativa para todas as tabelas é de 90 dias.
A captura de ecrã seguinte fornece provas adicionais que demonstram as definições de configuração para o período de retenção da área de trabalho do Log Analytic.
Exemplo de provas
As capturas de ecrã seguintes demonstram que estão disponíveis registos no valor de 30 dias no AlienVault.
Nota: uma vez que se trata de um documento destinado ao público, o número de série da firewall foi redigido. No entanto, os ISVs terão de submeter estas informações sem redações, a menos que contenham Informações Pessoais (PII) que têm de ser divulgadas ao analista.
Esta captura de ecrã seguinte mostra que os registos estão disponíveis ao mostrar um extrato de registo que remonta há cinco meses.
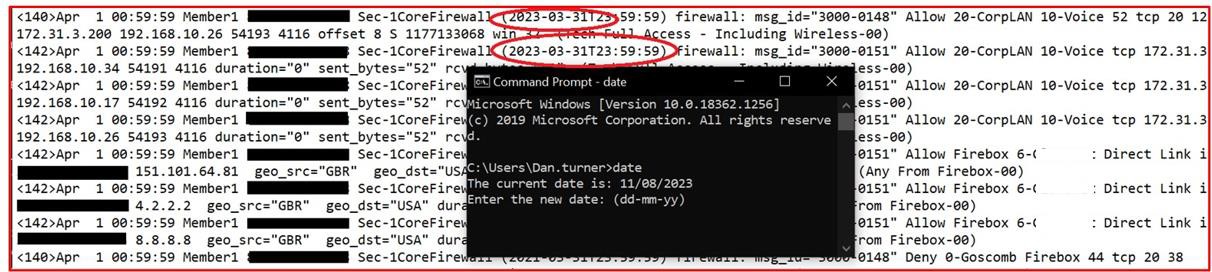
Nota: uma vez que se trata de um documento destinado ao público, os Endereços IP Públicos foram redigidos. No entanto, os ISVs terão de submeter estas informações sem qualquer redacção, a menos que contenham Informações Pessoais (PII) que têm de discutir primeiro com o seu analista.
Nota: os exemplos anteriores não são capturas de ecrã inteiro. Terá de submeter capturas de ecrã inteiro com qualquer URL, utilizador com sessão iniciada e carimbo de data e hora para revisão de provas. Se for um utilizador do Linux, isto pode ser feito através da linha de comandos.
Exemplo de provas
A captura de ecrã seguinte mostra que os eventos de registo são mantidos durante 30 dias disponíveis em direto e 90 dias no armazenamento a frio no Azure.
Nota: a expectativa será que, para além de quaisquer definições de configuração que demonstrem a retenção configurada, é fornecida uma amostra dos registos do período de 90 dias para validar que os registos são retidos durante 90 dias.
Nota: estes exemplos não são capturas de ecrã inteiro. Terá de submeter capturas de ecrã inteiro com qualquer URL, utilizador com sessão iniciada e carimbo de data e hora para revisão de provas. Se for um utilizador do Linux, isto pode ser feito através da linha de comandos.
Controlo N.º 19
Forneça provas que demonstrem que:
Os registos estão a ser revistos periodicamente e quaisquer potenciais eventos/anomalias de segurança identificados durante o processo de revisão são investigados e resolvidos.
Intenção: registo de eventos
O objetivo deste controlo é garantir que estão a ser realizadas revisões periódicas dos registos. Isto é importante para identificar quaisquer anomalias que possam não ser detetas pelos scripts/consultas de alerta que estão configurados para fornecer alertas de eventos de segurança. Além disso, todas as anomalias identificadas durante as revisões de registo são investigadas e é executada a remediação ou ação adequadas. Normalmente, isto envolverá um processo de triagem para identificar se as anomalias requerem ação e, em seguida, poderá ter de invocar o processo de resposta a incidentes.
Diretrizes: registo de eventos
As provas seriam fornecidas por capturas de ecrã, demonstrando que as revisões de registos estão a ser realizadas. Isto pode ser através de formulários que são concluídos todos os dias ou através de um pedido de suporte JIRA ou DevOps com
comentários relevantes que estão a ser publicados para mostrar que esta ação é realizada. Se forem sinalizadas anomalias, isto pode ser documentado neste mesmo pedido para demonstrar que as anomalias identificadas como parte da revisão de registos são seguidas e, em seguida, detalham as atividades que foram realizadas posteriormente. Isto pode levar à criação de um pedido de suporte JIRA específico para controlar todas as atividades que estão a ser realizadas ou apenas pode ser documentado no pedido de revisão de registos. Se for necessária uma ação de resposta a incidentes, esta ação deve ser documentada como parte do processo de resposta a incidentes e devem ser fornecidas provas para o demonstrar.
Exemplo de evidência: registo de eventos
Esta primeira captura de ecrã identifica onde um utilizador foi adicionado ao grupo "Admins de Domínio".

Esta captura de ecrã seguinte identifica onde várias tentativas de início de sessão falhadas são seguidas por um início de sessão bem-sucedido que pode realçar um ataque de força bruta bem-sucedido.

Esta captura de ecrã final identifica onde ocorreu uma alteração da política de palavra-passe ao definir a política, para que as palavras-passe da conta não expirem.

Esta captura de ecrã seguinte mostra que um pedido de suporte é gerado automaticamente na ferramenta ServiceNow do SOC, acionando a regra anterior acima.
Nota: estes exemplos não são capturas de ecrã inteiro. Terá de submeter capturas de ecrã inteiro com qualquer URL, utilizador com sessão iniciada e carimbo de data e hora para revisão de provas. Se for um utilizador do Linux, isto pode ser feito através da linha de comandos.
Controlo N.º 20
Forneça provas que demonstrem que:
As regras de alerta são configuradas para que os alertas sejam acionados para investigação para os seguintes eventos de segurança, quando aplicável:
Criação/modificações de conta privilegiada.
Atividades ou operações privilegiadas/de alto risco.
Eventos de software maligno.
Adulteração do registo de eventos.
Eventos IDPS/WAF (se configurados).
Intenção: alertas
Estes são alguns tipos de eventos de segurança que podem realçar um evento de segurança que pode apontar para uma falha de ambiente e/ou violação de dados.
Este subponto é para garantir que as regras de alerta são especificamente configuradas para acionar investigações após a criação ou modificação de contas com privilégios. No caso de criação ou modificações de contas com privilégios, os registos devem ser gerados e os alertas devem ser acionados sempre que for criada uma nova conta com privilégios ou as permissões de conta com privilégios existentes forem alteradas. Isto ajuda a controlar atividades não autorizadas ou suspeitas.
Este subponto tem como objetivo ter regras de alerta definidas para notificar o pessoal adequado quando são realizadas atividades ou operações com privilégios ou de alto risco. Para atividades ou operações privilegiadas ou de alto risco, os alertas têm de ser configurados para notificar o pessoal adequado quando essas atividades são iniciadas. Isto pode incluir alterações às regras da firewall, transferências de dados ou acesso a ficheiros confidenciais.
A intenção deste subponto é ordenar a configuração de regras de alerta que são acionadas por eventos relacionados com software maligno. Os eventos de software maligno não só devem ser registados, como também devem acionar um alerta imediato para investigação. Estes alertas devem ser concebidos para incluir detalhes como a origem, a natureza do software maligno e os componentes do sistema afetados para agilizar o tempo de resposta.
Este subponto foi concebido para garantir que qualquer adulteração dos registos de eventos aciona um alerta imediato para investigação. Relativamente à adulteração do registo de eventos, o sistema deve ser configurado para acionar alertas quando forem detetados acessos não autorizados a registos ou modificações de registos. Isto garante a integridade dos registos de eventos, que são cruciais para análise forense e auditorias de conformidade.
Este subponto pretende garantir que, se os Sistemas de Deteção e Prevenção de Intrusões (IDPS) ou Firewalls de Aplicações Web (WAF) estiverem configurados, serão definidos para acionar alertas para investigação. Se os Sistemas de Deteção e Prevenção de Intrusões (IDPS) ou Firewalls de Aplicações Web (WAF) estiverem configurados, também devem ser definidos para acionar alertas para atividades suspeitas, tais como falhas de início de sessão repetidas, tentativas de injeção de SQL ou padrões que sugiram um ataque denial-of-service.
Diretrizes: alertas
As provas devem ser fornecidas através de capturas de ecrã da configuração de alerta e provas dos alertas que estão a ser recebidos. As capturas de ecrã de configuração devem mostrar a lógica que está a acionar os alertas e como os alertas são enviados. Os alertas podem ser enviados através de SMS, E-mail, canais do Teams, canais Slack, etc....
Exemplo de evidência: alertas
A captura de ecrã seguinte mostra um exemplo de alertas a serem configurados no Azure. Podemos observar na primeira captura de ecrã que um alerta foi acionado quando a VM foi parada e desalocada. Tenha em atenção que isto ilustra um exemplo de alertas que estão a ser configurados no Azure e a expectativa será que sejam fornecidas provas para demonstrar que os alertas são gerados para todos os eventos especificados na descrição do controlo.
A captura de ecrã seguinte mostra os alertas configurados para quaisquer ações administrativas executadas ao nível do Serviço de Aplicações do Azure, bem como ao nível do Grupo de Recursos do Azure.
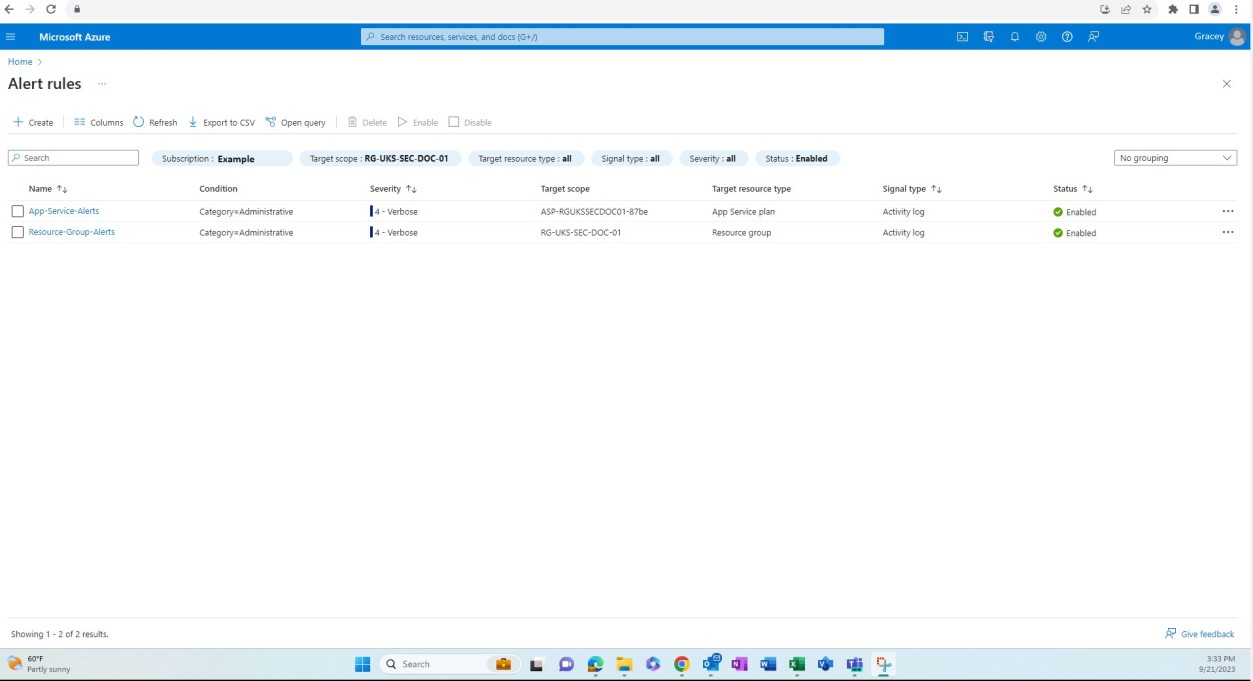
Exemplo de provas
A Contoso utiliza um Centro de Operações de Segurança (SOC) de terceiros fornecido pela Segurança da Contoso. O exemplo mostra que os alertas no AlienVault, utilizados pelo SOC, estão configurados para enviar um alerta para um membro da Equipa SOC, Sally Gold na Segurança Contoso.
Esta captura de ecrã seguinte mostra um alerta a ser recebido pela Sally.
Nota: estes exemplos não são capturas de ecrã inteiro. Terá de submeter capturas de ecrã inteiro com qualquer URL, utilizador com sessão iniciada e carimbo de data e hora para revisão de provas. Se for um utilizador do Linux, isto pode ser feito através da linha de comandos.
Gestão de riscos de segurança de informações
A Gestão de Riscos de Segurança de Informações é uma atividade importante que todas as organizações devem realizar, pelo menos, anualmente. As organizações têm de compreender os seus riscos para mitigar eficazmente as ameaças. Sem uma gestão de riscos eficaz, as organizações podem implementar recursos de segurança em áreas que consideram importantes, quando outras ameaças podem ser mais prováveis. A gestão de riscos eficaz ajudará as organizações a concentrarem-se nos riscos que representam a maior ameaça para a empresa. Isto deve ser realizado anualmente, uma vez que o panorama da segurança está em constante mudança e, por conseguinte, as ameaças e os riscos podem mudar as horas extraordinárias. Por exemplo, durante o recente bloqueio da COVID-19, houve um grande aumento de ataques de phishing com a mudança para o trabalho remoto.
Controlo N.º 21
Forneça provas de que um processo/política de gestão de riscos de segurança de informações formal ratificado está documentado e estabelecido.
Intenção: gestão de riscos
Um processo robusto de gestão de riscos de segurança de informações é importante para ajudar as organizações a gerir os riscos de forma eficaz. Isto ajudará as organizações a planear mitigações eficazes contra ameaças ao ambiente. O objetivo deste controlo é confirmar que a organização tem uma política ou processo formalmente ratificado de gestão de riscos de segurança de informações que está documentado de forma abrangente. A política deve destacar a forma como a organização identifica, avalia e gere os riscos de segurança de informações. Deve incluir funções e responsabilidades, metodologias de avaliação de riscos, critérios de aceitação de riscos e procedimentos de mitigação de riscos.
Nota: a avaliação de riscos deve focar-se nos riscos de segurança de informações e não apenas nos riscos gerais para a empresa.
Diretrizes: gestão de riscos
O processo de gestão da avaliação de riscos formalmente documentado deve ser fornecido.
Exemplo de evidência: gestão de riscos
A seguinte prova é uma captura de ecrã de parte do processo de avaliação de riscos da Contoso.
Nota: a expectativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
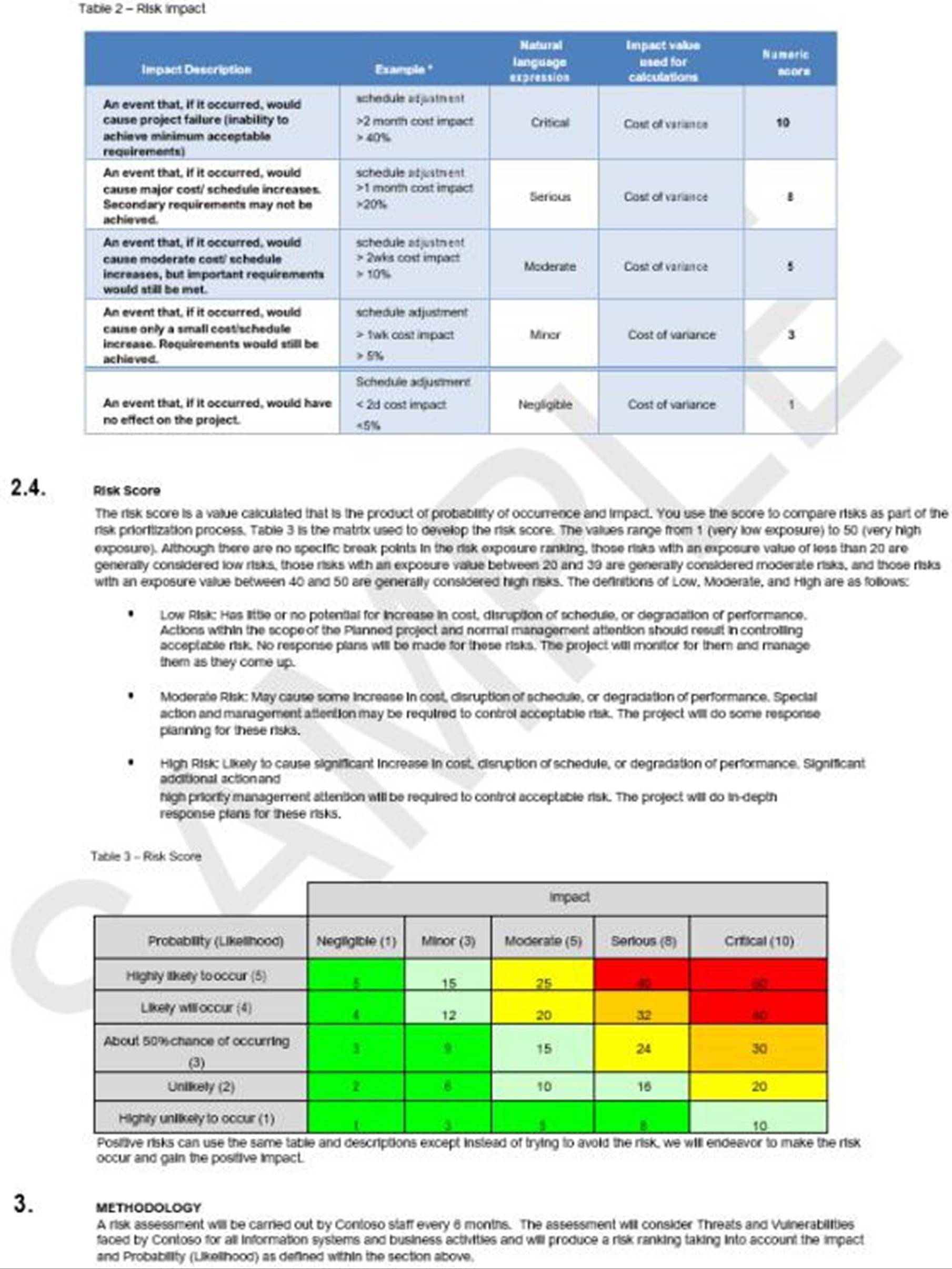
Nota: a expectativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
Controlo N.º 22
Forneça provas que demonstrem que:
- Uma avaliação formal dos riscos de segurança da informação a nível da empresa é realizada, pelo menos, anualmente.
OU Para análise de riscos direcionados:
Uma análise de risco direcionada é documentada e executada:
No mínimo, a cada 12 meses para cada instância em que não existe um controlo tradicional ou uma melhor prática da indústria.
Quando uma limitação de design/tecnologia cria um risco de introdução de uma vulnerabilidade no ambiente/coloca utilizadores e dados em risco.
Por suspeita ou confirmação de compromisso.
Intenção: avaliação anual
As ameaças de segurança estão constantemente a mudar com base nas alterações ao ambiente, nas alterações aos serviços oferecidos, nas influências externas, na evolução do panorama das ameaças de segurança, etc. As organizações precisam de passar pelo processo de avaliação de riscos, pelo menos, anualmente. Recomenda-se que este processo também seja realizado após alterações significativas, uma vez que as ameaças podem mudar.
O objetivo deste controlo é verificar se a organização realiza uma avaliação formal dos riscos de segurança de informações a nível da empresa, pelo menos uma vez por ano e/ou uma análise de risco direcionada durante alterações do sistema ou após incidentes, deteção de vulnerabilidades, alterações de infraestrutura, etc. Esta avaliação deve abranger todos os recursos, processos e dados organizacionais, com o objetivo de identificar e avaliar potenciais vulnerabilidades e ameaças.
Para a análise de risco direcionada, este controlo realça a necessidade de efetuar uma análise de risco em cenários específicos, que se foca num âmbito mais restrito, como um recurso, uma ameaça, um sistema ou um controlo. O objetivo é garantir que as organizações avaliam e identificam continuamente os riscos introduzidos por desvios das melhores práticas de segurança ou limitações de design do sistema. Ao realizar análises de risco direcionadas, pelo menos anualmente, em que faltam controlos, quando as restrições tecnológicas criam vulnerabilidades e, em resposta a incidentes de segurança suspeitos ou confirmados, a organização pode identificar fraquezas e exposições. Isto permite decisões informadas baseadas no risco sobre a prioridade dos esforços de remediação e a implementação de controlos de compensação para minimizar a probabilidade e o impacto da exploração. O objectivo é fornecer diligências, orientações e provas contínuas de que as lacunas conhecidas estão a ser resolvidas de forma consciente do risco, em vez de serem ignoradas indefinidamente. A realização destas avaliações de risco direcionadas demonstra o compromisso organizacional de melhorar proativamente a postura de segurança ao longo do tempo.
Diretrizes: avaliação anual
As provas podem ser por meio de controlo de versões ou provas datadas. Devem ser fornecidas provas que mostram a saída da avaliação de riscos de segurança de informações e NÃO as datas do próprio processo de avaliação de riscos de segurança de informações.
Exemplo de evidência: avaliação anual
A captura de ecrã seguinte mostra uma reunião de avaliação de riscos agendada a cada seis meses.
Estas duas capturas de ecrã seguintes mostram um exemplo de atas de reunião de duas avaliações de risco. A expectativa é que seja fornecido um relatório/atas de reunião ou um relatório da avaliação de risco.

Nota: esta captura de ecrã mostra um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
Nota: esta captura de ecrã mostra um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
Controlo N.º 23
Confirme que a avaliação do risco de segurança de informações inclui:
Componente do sistema ou recurso afetado.
Ameaças e vulnerabilidades ou equivalência.
Impacto e matrizes de probabilidade ou equivalentes.
A criação de um plano de tratamento de risco/registo de risco.
Intenção: avaliação de riscos
A intenção é que a avaliação de riscos inclua componentes e recursos do sistema, uma vez que ajuda a identificar os recursos de TI mais críticos e o respetivo valor. Ao identificar e analisar potenciais ameaças à empresa, a organização pode concentrar-se primeiro nos riscos que têm o maior impacto potencial e a maior probabilidade. Ao compreender o impacto potencial na infraestrutura de TI e nos custos associados pode ajudar a gestão a tomar decisões informadas sobre orçamento, políticas, procedimentos e muito mais. Uma lista de componentes ou recursos do sistema que podem ser incluídos na avaliação de riscos de segurança são:
Servidores
Bancos de dados
Aplicativos
Redes
Dispositivos de armazenamento de dados
Pessoas
Para gerir eficazmente os riscos de segurança de informações, as organizações devem realizar avaliações de risco contra ameaças ao ambiente e dados e contra possíveis vulnerabilidades que possam estar presentes. Isto ajudará as organizações a identificar a miríade de ameaças e vulnerabilidades que podem representar um risco significativo. As avaliações de risco devem documentar as classificações de impacto e probabilidade, que podem ser utilizadas para identificar o valor de risco. Isto pode ser utilizado para priorizar o tratamento de risco e ajudar a reduzir o valor de risco geral. As avaliações de riscos têm de ser devidamente controladas para fornecer um registo de um dos quatro tratamentos de risco que estão a ser aplicados. Estes tratamentos de risco são:
Evitar/Terminar: a empresa pode determinar que o custo de lidar com o risco é superior à receita gerada pelo serviço. Por conseguinte, a empresa pode optar por deixar de executar o serviço.
Transferência/Partilha: a empresa pode optar por transferir o risco para terceiros ao mover o processamento para terceiros.
Aceitar/Tolerar/Reter: a empresa pode decidir que o risco é aceitável. Isto depende muito do apetite de risco das empresas e pode variar consoante a organização.
Tratar/Mitigar/Modificar: a empresa decide implementar controlos de mitigação para reduzir o risco a um nível aceitável.
Diretrizes: avaliação de riscos
Os elementos de prova devem ser fornecidos não só pelo processo de avaliação de riscos de segurança de informações já fornecido, mas também pela saída da avaliação de riscos (através de um plano de tratamento de risco/registo de riscos) para demonstrar que o processo de avaliação de riscos está a ser realizado corretamente. O registo de riscos deve incluir riscos, vulnerabilidades, impacto e classificações de probabilidade.
Exemplo de evidência: avaliação de riscos
A captura de ecrã seguinte mostra o registo de riscos que demonstra ameaças e vulnerabilidades incluídas. Também demonstra que o impacto e as probabilidades estão incluídos.
Nota: a documentação completa da avaliação de riscos deve ser fornecida em vez de uma captura de ecrã. A captura de ecrã seguinte demonstra um plano de tratamento de risco.
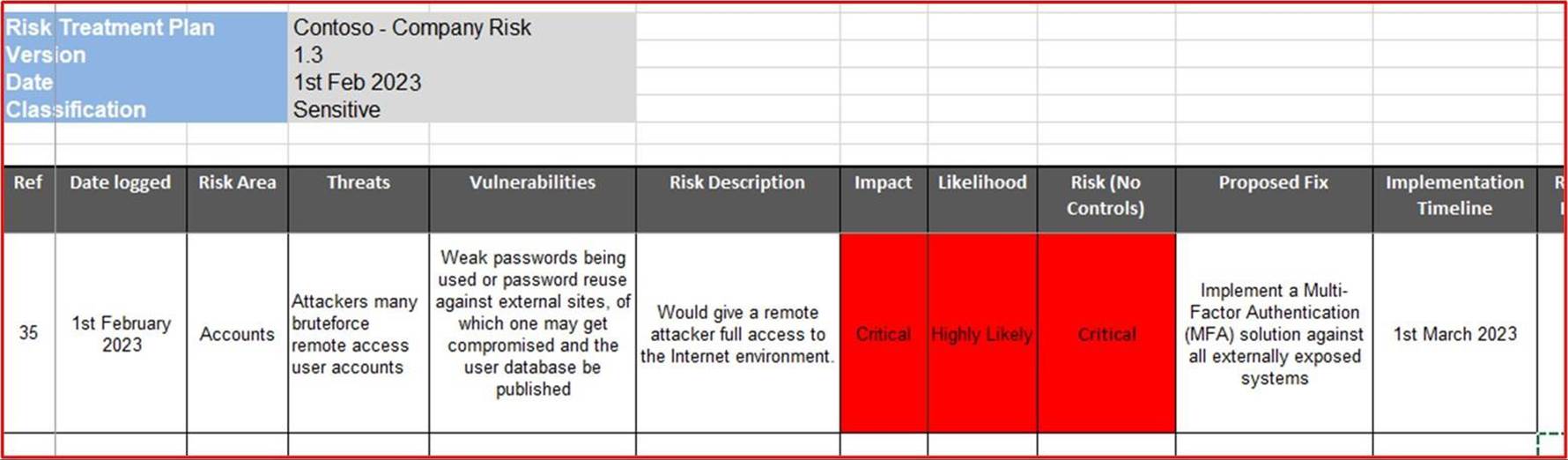
Controlo N.º 24
Forneça provas de que:
O utilizador (ISV) tem processos de gestão de riscos implementados que avaliam e gerem riscos associados a fornecedores e parceiros empresariais.
O utilizador (ISV) pode identificar e avaliar alterações e riscos que podem afetar o seu sistema de controlos internos.
Intenção: fornecedores e parceiros
A gestão de riscos do fornecedor é a prática de avaliar as posturas de risco de parceiros empresariais, fornecedores ou fornecedores de terceiros antes de uma relação comercial ser estabelecida e ao longo da duração da relação. Ao gerir os riscos dos fornecedores, as organizações podem evitar perturbações na continuidade do negócio, evitar impactos financeiros, proteger a sua reputação, cumprir os regulamentos e identificar e minimizar os riscos associados à colaboração com um fornecedor. Para gerir eficazmente os riscos do fornecedor, é importante ter processos em vigor que incluam avaliações de diligência, obrigações contratuais relacionadas com a segurança e monitorização contínua da conformidade do fornecedor.
Diretrizes: fornecedores e parceiros
Podem ser fornecidas provas para demonstrar o processo de avaliação de riscos do fornecedor, como a documentação estabelecida de aprovisionamento e verificação, listas de verificação e questionários para inclusão de novos fornecedores e contratantes, avaliações realizadas, verificações de conformidade, etc.
Exemplo de evidência: fornecedores e parceiros
A captura de ecrã seguinte demonstra que o processo de inclusão e verificação do fornecedor é mantido no Confluence como uma tarefa JIRA. Para cada novo fornecedor, ocorre uma avaliação de risco inicial para rever a postura de conformidade. Durante o processo de aprovisionamento, é preenchido um questionário de avaliação de riscos e o risco geral é determinado com base no nível de acesso a sistemas e dados fornecidos ao fornecedor.
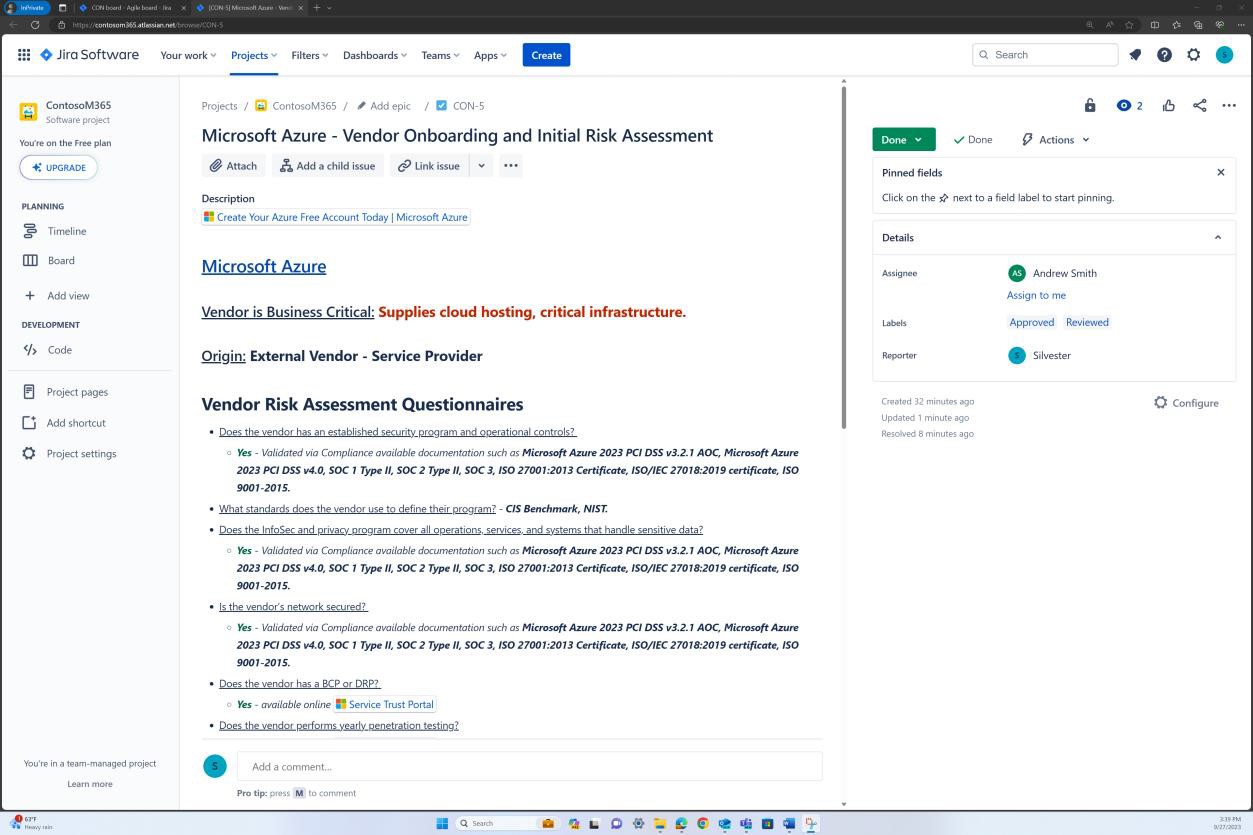
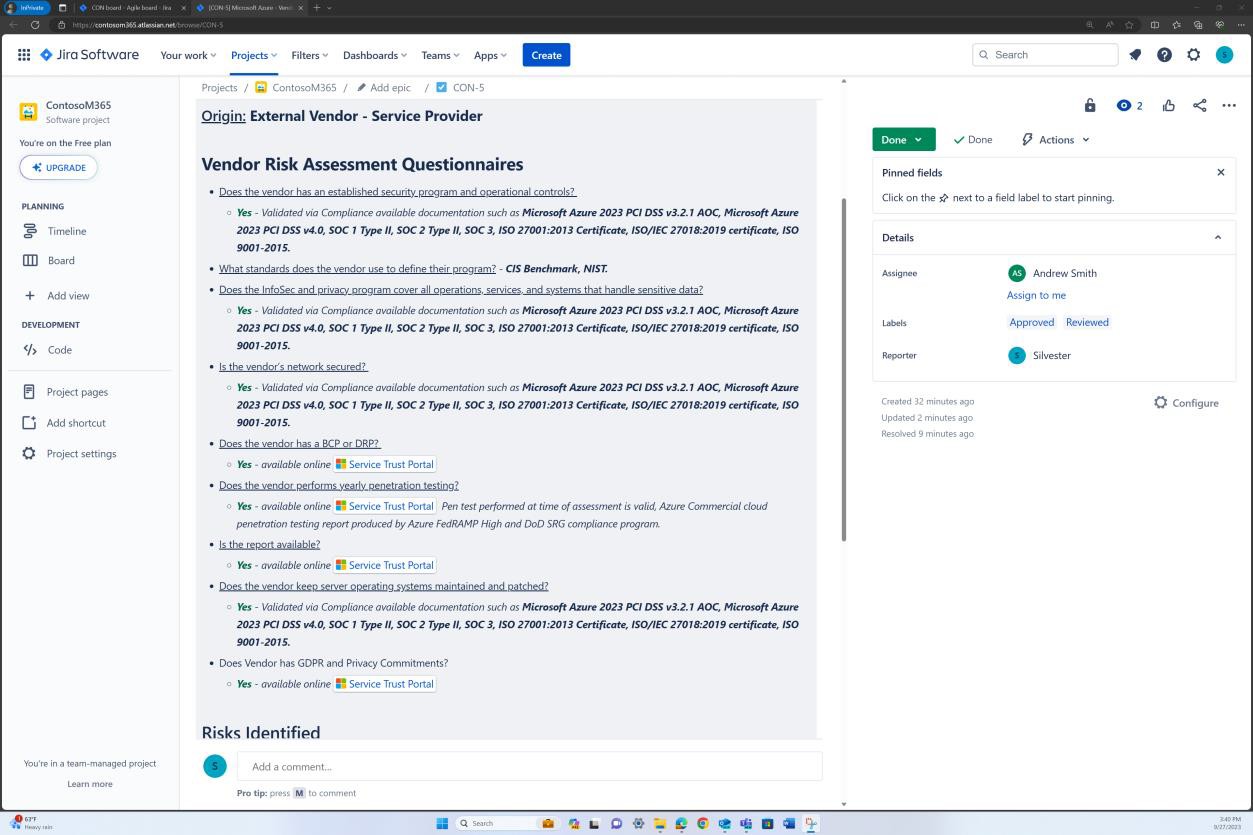
A captura de ecrã seguinte demonstra o resultado da avaliação e o risco geral que foi identificado com base na revisão inicial.
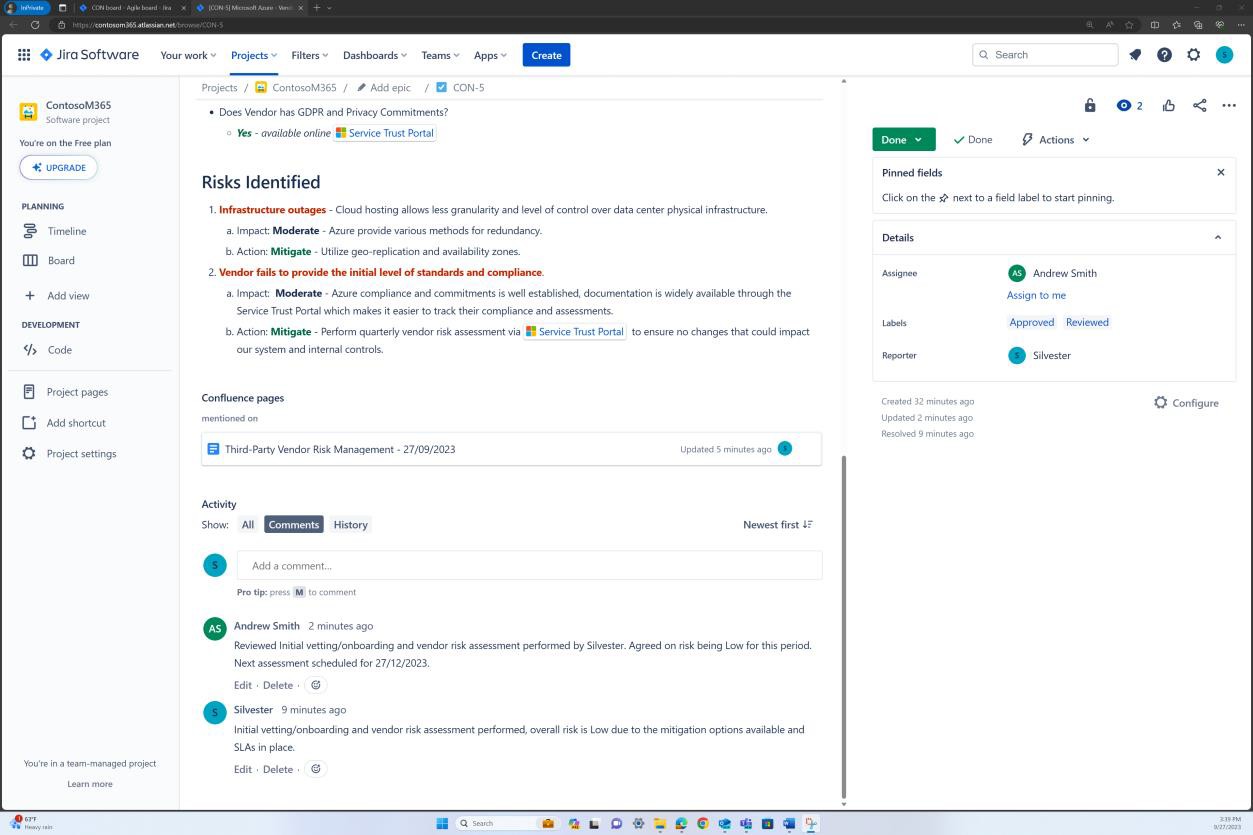
Intenção: controlos internos
O foco deste subponto é reconhecer e avaliar alterações e riscos que podem afetar os sistemas de controlo interno de uma organização para garantir que os controlos internos permanecem eficazes ao longo do tempo. À medida que as operações empresariais mudam, os seus controlos internos podem já não ser eficazes. Os riscos evoluem ao longo do tempo e podem surgir novos riscos que não foram previamente considerados. Ao identificar e avaliar estes riscos, pode garantir que os seus controlos internos foram concebidos para os resolver. Isto ajuda a prevenir fraudes e erros, manter a continuidade do negócio e garantir a conformidade regulamentar.
Diretrizes: controlos internos
Podem ser fornecidas provas, tais como rever atas de reunião e relatórios que podem demonstrar que o processo de avaliação de riscos do fornecedor é atualizado num período definido para garantir que as potenciais alterações do fornecedor são contabilizadas e avaliadas.
Exemplo de evidência: controlos internos
As capturas de ecrã seguintes demonstram que é realizada uma revisão de três meses da lista de fornecedores e contratantes aprovados para garantir que as normas de conformidade e o nível de conformidade são consistentes com a avaliação inicial durante a integração.
A primeira captura de ecrã mostra as diretrizes estabelecidas para efetuar a avaliação e o questionário de risco.
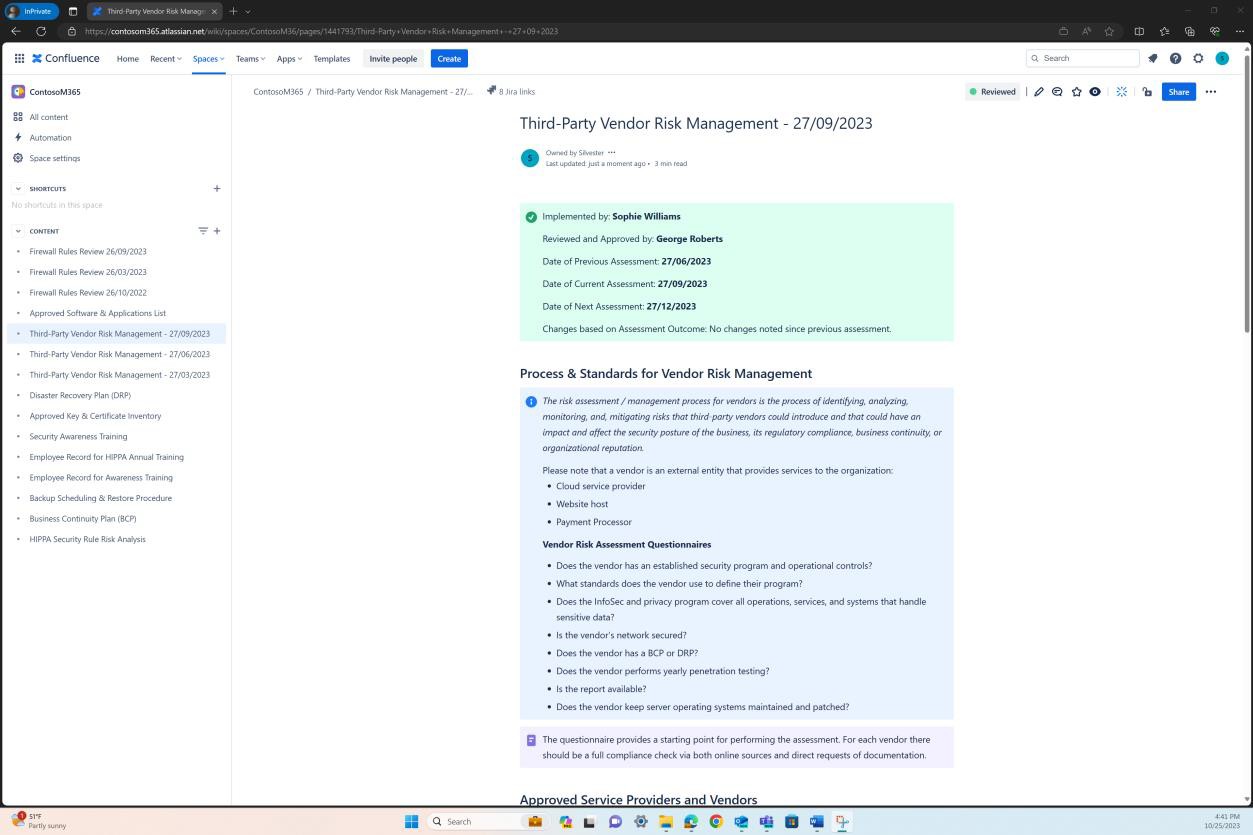
As capturas de ecrã seguintes mostram a lista aprovada pelo fornecedor e o respetivo nível de conformidade, a avaliação realizada, o avaliador, o aprovador, etc. Tenha em atenção que este é apenas um exemplo de uma avaliação de risco do fornecedor rudimentar concebida para fornecer um cenário de linha de base para compreender o requisito de controlo e mostrar o formato das provas esperadas. Como ISV, deve fornecer a sua própria avaliação de risco de fornecedor estabelecida, conforme aplicável à sua organização.
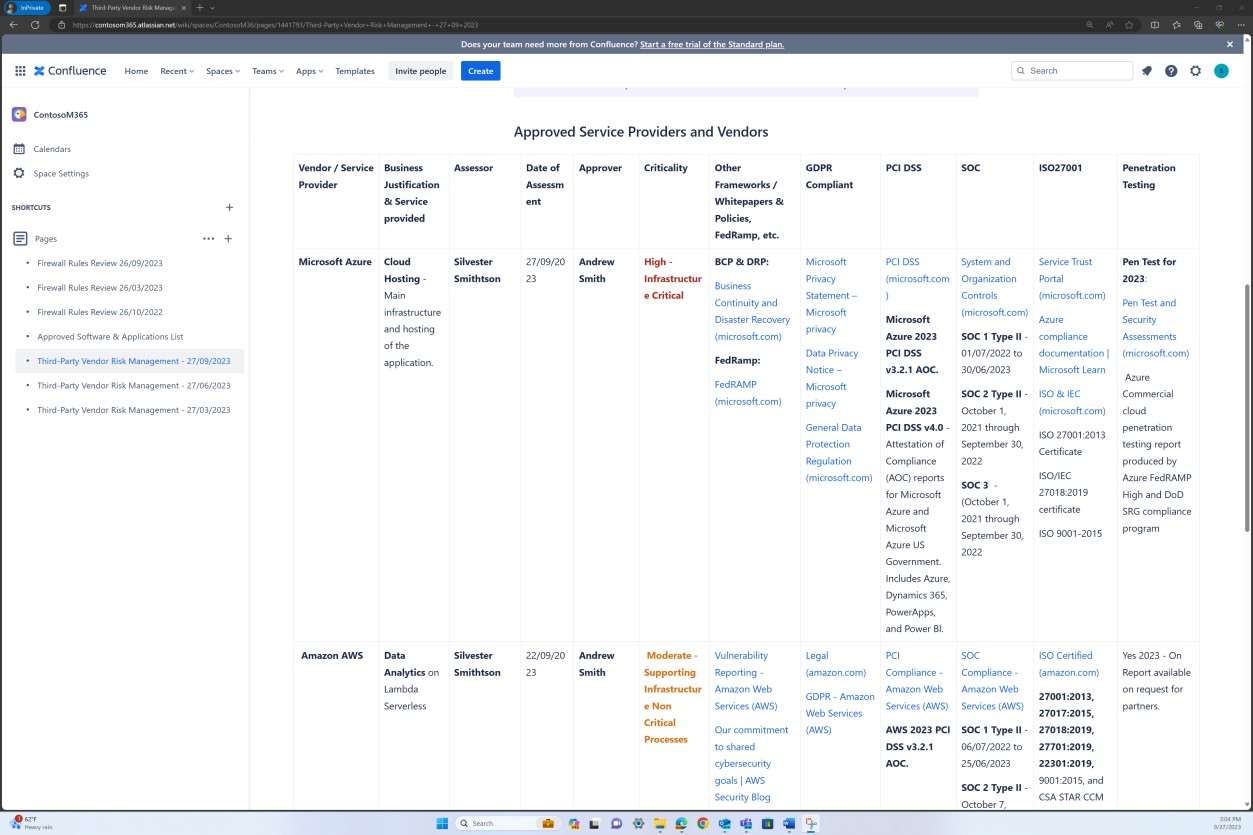
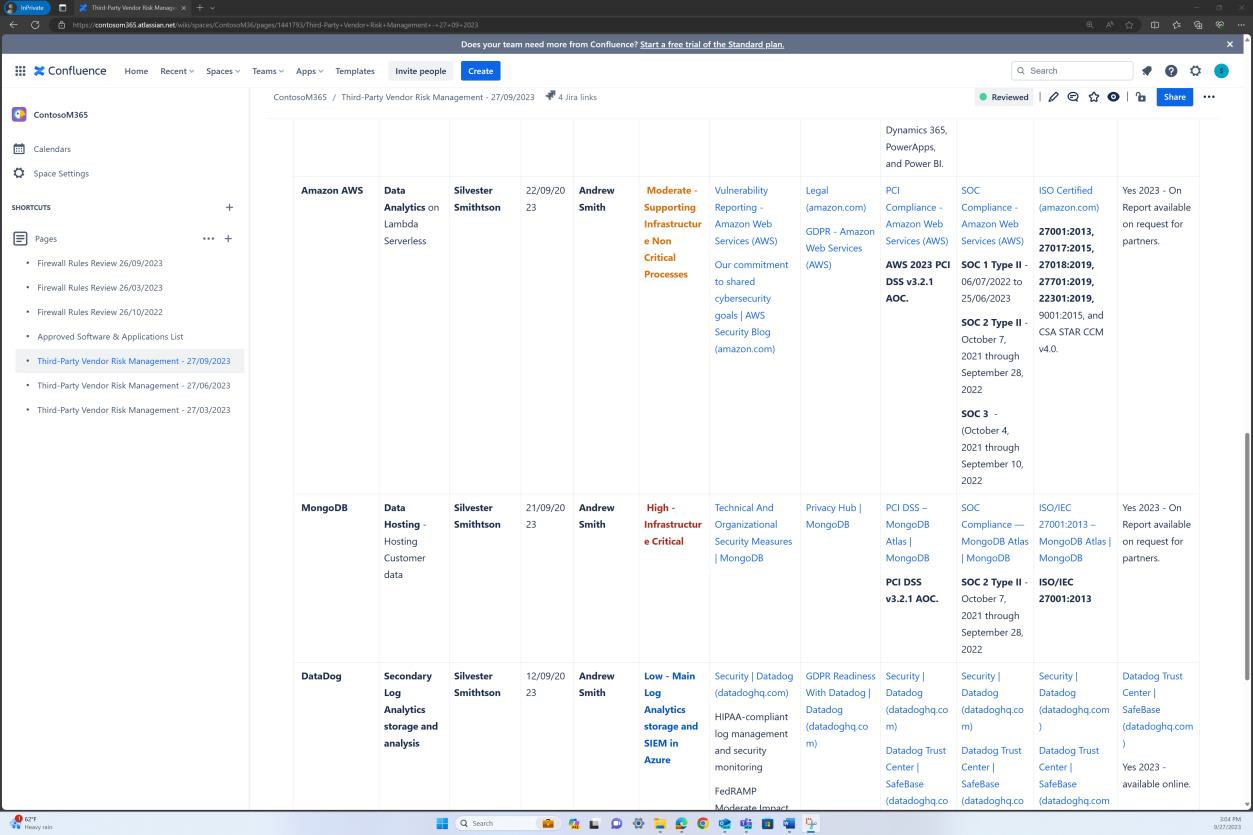
Resposta a incidentes de segurança
A resposta a incidentes de segurança é importante para todas as organizações, uma vez que pode reduzir o tempo despendido por uma organização que contém um incidente de segurança e limitar o nível de exposição da organização à transferência de dados não autorizada. Ao desenvolver um plano de resposta a incidentes de segurança abrangente e detalhado, esta exposição pode ser reduzida desde o momento da identificação até ao momento da contenção.
Um relatório da IBM intitulado "Custo de uma violação de dados Relatório 2020" destaca que, em média, o tempo necessário para conter uma violação foi de 73 dias. Além disso, o mesmo relatório identifica a maior poupança de custos da organização que sofreu uma falha de segurança, foi a preparação da resposta a incidentes, fornecendo uma média de
$2.000.000 de poupança de custos. As organizações devem seguir as melhores práticas de conformidade de segurança através de arquiteturas padrão da indústria, como ISO 27001, NIST, SOC 2, PCI DSS, etc...
Controlo N.º 25
Indique o plano/procedimento de resposta a incidentes de segurança ratificado (IRP) que descreve como a sua organização responde a incidentes, mostra como é mantida e inclui:
detalhes da equipa de resposta a incidentes, incluindo informações de contacto,
um plano de comunicação interna durante o incidente e comunicação externa a partes relevantes, tais como intervenientes importantes, marcas de pagamento e adquirentes, entidades reguladoras (por exemplo, 72 horas para o RGPD), autoridades de supervisão, diretores, clientes,
passos para atividades como classificação de incidentes, contenção, mitigação, recuperação e regresso às operações comerciais normais, consoante o tipo de incidente.
Intenção: Plano de Resposta Incedente (IRP)
A intenção deste controlo é garantir que existe um plano de resposta a incidentes (IRP) formalmente documentado, que inclui uma equipa de resposta a incidentes designada com funções, responsabilidades e informações de contacto claramente documentadas. O IRP deve fornecer uma abordagem estruturada para gerir incidentes de segurança da deteção para a resolução, incluindo classificar a natureza do incidente, conter o impacto imediato, mitigar os riscos, recuperar do incidente e restaurar operações comerciais normais. Cada passo deve ser bem definido, com protocolos claros, para garantir que as ações tomadas estão alinhadas com as estratégias de gestão de riscos e as obrigações de conformidade da organização.
A especificação detalhada da equipa de resposta a incidentes no IRP garante que cada membro da equipa compreende a sua função na gestão do incidente, permitindo uma resposta coordenada e eficiente. Ao ter um IRP implementado, uma organização pode gerir uma resposta a incidentes de segurança de forma mais eficiente, o que pode, em última análise, limitar a exposição à perda de dados da organização e reduzir os custos do compromisso.
As organizações podem ter obrigações de notificação por violação com base no país/países em que operam (por exemplo, o RGPD do Regulamento Geral sobre a Proteção de Dados) ou com base na funcionalidade oferecida (por exemplo, PCI DSS se os dados de pagamento forem processados). A falha da notificação em tempo útil pode implicar ramificações graves; Por conseguinte, para garantir o cumprimento das obrigações de notificação, os planos de resposta a incidentes devem incluir um processo de comunicação, incluindo comunicação com todos os intervenientes, processos de comunicação multimédia e quem pode e não pode falar com os meios de comunicação social.
Diretrizes: controlos internos
Indique a versão completa do plano/procedimento de resposta a incidentes. O plano de resposta a incidentes deve incluir uma secção que abrange o processo de processamento de incidentes, desde a identificação à resolução e um processo de comunicações documentado.
Exemplo de evidência: controlos internos
A captura de ecrã seguinte mostra o início do plano de resposta a incidentes da Contoso.
Nota: como parte da submissão de provas, tem de fornecer todo o plano de resposta a incidentes.

Exemplo de evidência: controlos internos
A captura de ecrã seguinte mostra uma extração do plano de resposta a incidentes que mostra o processo de comunicação.
Controlo N.º 26
Forneça provas que demonstrem que:
Todos os membros da equipa de resposta a incidentes receberam formação anual que lhes permite responder a incidentes.
Intenção: preparação
Quanto mais tempo demorar uma organização a conter um compromisso, maior será o risco de transferência de dados por transferência de dados, o que pode resultar num maior volume de dados exfiltrados e quanto maior for o custo global do compromisso. É importante que as equipas de resposta a incidentes da organização estejam equipadas para responder a incidentes de segurança atempadamente. Ao realizar formação regular e realizar exercícios de tabletop, a equipa está preparada para lidar com incidentes de segurança de forma rápida e eficiente. Esta preparação deve abranger vários aspetos, como a identificação de potenciais ameaças, ações de resposta inicial, procedimentos de escalamento e estratégias de mitigação a longo prazo.
A recomendação é realizar a preparação de resposta a incidentes internos para a equipa de resposta a incidentes E para realizar exercícios regulares de tabletop, que devem ligar ao risco de segurança de informações
avaliação para identificar os incidentes de segurança que são mais prováveis de ocorrer. O exercício de tabletop deve simular cenários do mundo real para testar e aprimorar as capacidades da equipa para reagir sob pressão. Ao fazê-lo, a organização pode garantir que os seus funcionários sabem como lidar corretamente com uma falha de segurança ou ciberataque. E a equipa saberá que passos tomar para conter e investigar rapidamente os incidentes de segurança mais prováveis.
Diretrizes: formação
Devem ser fornecidas provas que demonstrem que a formação foi realizada através da partilha dos conteúdos de formação e dos registos que mostram quem participou (que deve incluir toda a equipa de resposta a incidentes). Em alternativa, ou também registos que mostram que foi realizado um exercício de tabletop. Tudo isto deve ter sido concluído num período de 12 meses a partir do momento em que os elementos de prova são apresentados.
Exemplo de evidência: preparação
A Contoso realizou um exercício de tabletop de resposta a incidentes com uma empresa de segurança externa. Segue-se uma amostra do relatório gerado como parte da consultoria.

Nota: o relatório completo teria de ser partilhado. Este exercício também pode ser realizado internamente, uma vez que não existe qualquer requisito do Microsoft 365 para que tal seja realizado por uma empresa de terceiros.
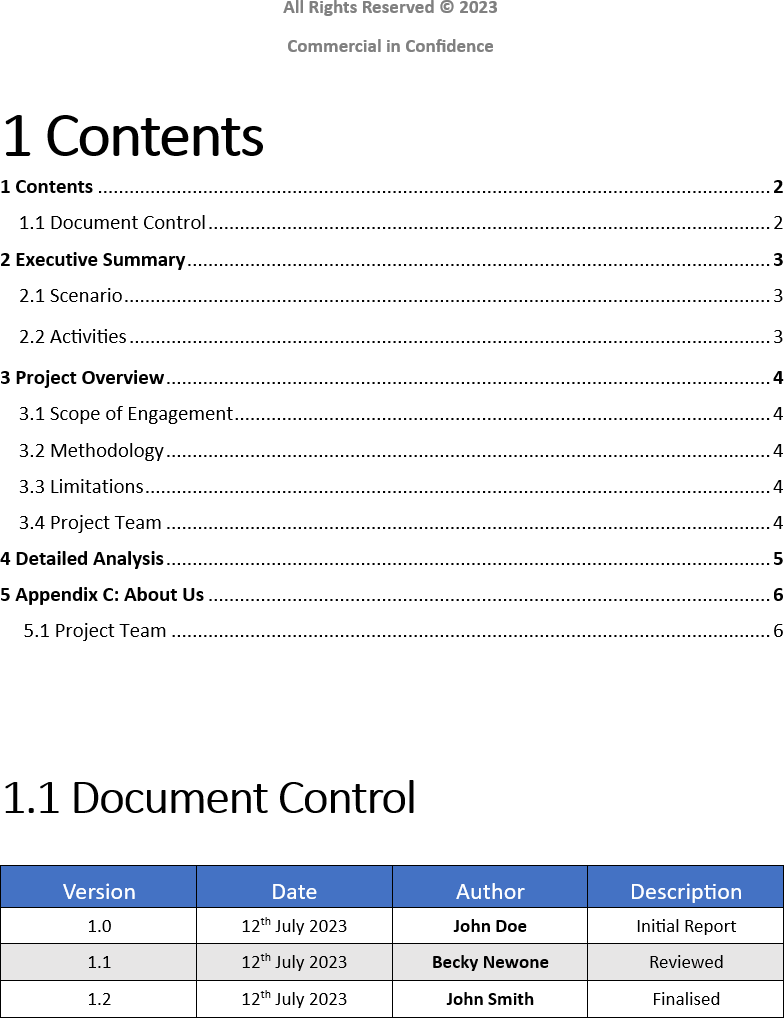
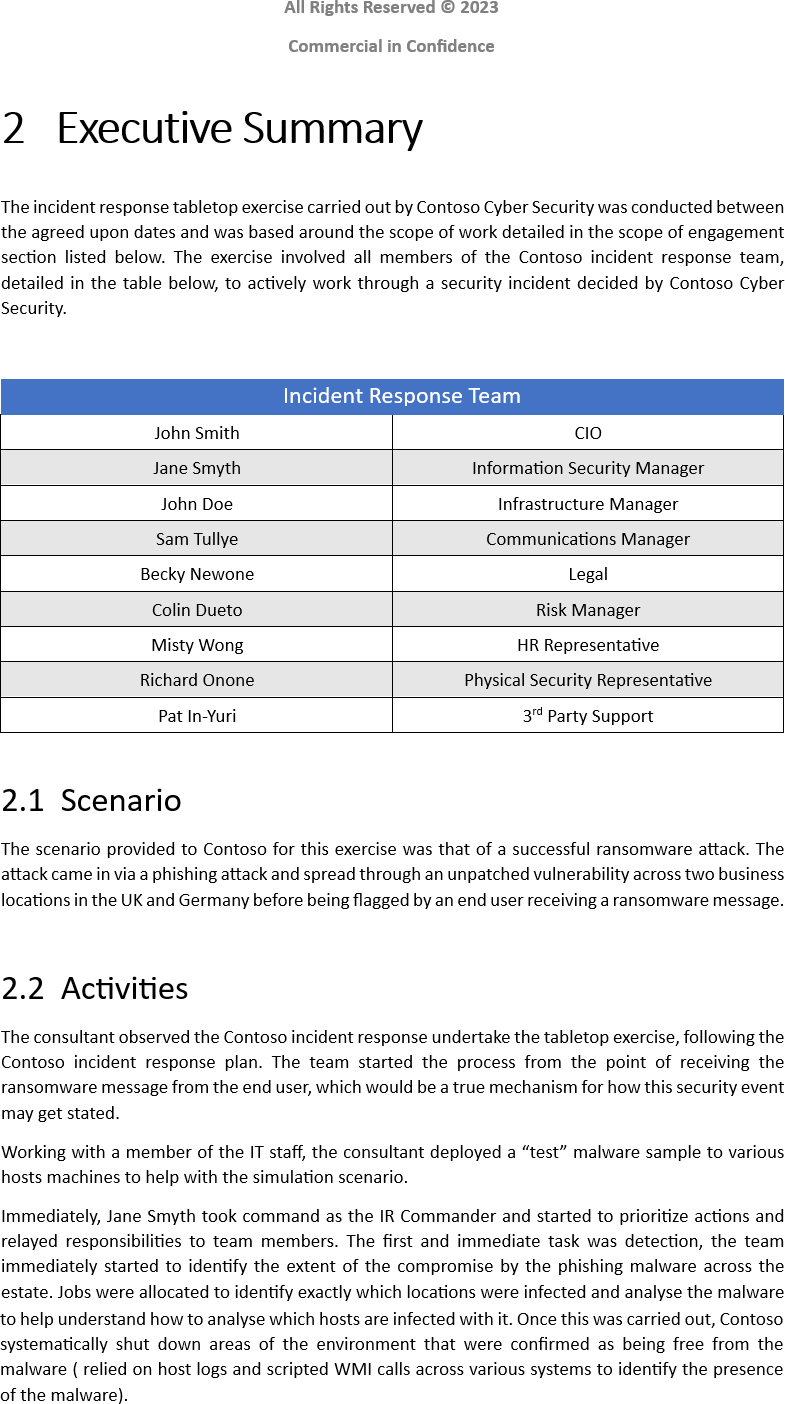
Nota: o relatório completo teria de ser partilhado. Este exercício também pode ser realizado internamente, uma vez que não existe nenhum requisito do Microsoft 365 para que tal seja realizado por uma empresa de terceiros.
Controlo N.º 27
Forneça provas de que:
A estratégia de resposta a incidentes e a documentação de suporte são revistas e atualizadas com base em:
lições aprendidas a partir de um exercício de tabletop
lições aprendidas ao responder a um incidente
alterações organizacionais
Intenção: revisões de planos
Ao longo do tempo, o plano de resposta a incidentes deve evoluir com base em alterações organizacionais ou com base nas lições aprendidas ao aprovar o plano. As alterações ao ambiente operativo podem exigir alterações ao plano de resposta a incidentes, uma vez que as ameaças podem mudar ou os requisitos regulamentares podem mudar. Além disso, à medida que são realizados exercícios de tabletop e respostas reais a incidentes de segurança, isto pode muitas vezes identificar áreas do plano que podem ser melhoradas. Isto tem de ser incorporado no plano e a intenção deste controlo é garantir que este processo está incluído. O objetivo deste controlo é ordenar a revisão e atualização da estratégia de resposta a incidentes da organização e a documentação de suporte com base em três acionadores distintos:
Após os exercícios simulados para testar a eficácia da sua estratégia de resposta a incidentes, quaisquer lacunas ou áreas identificadas para melhoria devem ser imediatamente incorporadas no plano de resposta a incidentes existente.
Um incidente real fornece informações inestimáveis sobre os pontos fortes e fracos da estratégia de resposta atual. Se ocorrer um incidente, deve ser realizada uma revisão pós-incidente para capturar estas lições, que devem ser utilizadas para atualizar a estratégia e os procedimentos de resposta.
Quaisquer alterações significativas na organização, como fusões, aquisições ou alterações no pessoal-chave, devem desencadear uma revisão da estratégia de resposta a incidentes. Estas alterações organizacionais podem introduzir novos riscos ou mudar os existentes e o plano de resposta a incidentes deve ser atualizado em conformidade para permanecer eficaz.
Diretrizes: revisões de planos
Isto será frequentemente evidenciado ao rever os resultados de incidentes de segurança ou exercícios de tabletop em que as lições aprendidas foram identificadas e resultaram numa atualização do plano de resposta a incidentes. O plano deve manter um registo de alterações, que também deve referenciar as alterações que foram implementadas com base nas lições aprendidas ou nas alterações organizacionais.
Exemplo de provas: revisões de planos
As capturas de ecrã seguintes são do plano de resposta a incidentes fornecido, que inclui uma secção sobre a atualização com base nas lições aprendidas e/ou nas alterações da organização.



Nota: estes exemplos não são capturas de ecrã inteiro. Terá de submeter capturas de ecrã inteiro com qualquer URL, utilizador com sessão iniciada e carimbo de data e hora para revisão de provas. Se for um utilizador do Linux, isto pode ser feito através da linha de comandos.
Plano de continuidade de negócio e plano de recuperação após desastre
O planeamento da continuidade de negócio e o planeamento da recuperação após desastre são dois componentes críticos da estratégia de gestão de riscos de uma organização. O planeamento da continuidade de negócio é o processo de criação de um plano para garantir que as funções empresariais essenciais podem continuar a funcionar durante e após um desastre, enquanto o planeamento da recuperação após desastre é o processo de criação de um plano para recuperar de um desastre e restaurar operações comerciais normais o mais rapidamente possível. Ambos os planos se complementam— ambos têm de resistir a desafios operacionais provocados por desastres ou interrupções inesperadas. Estes planos são importantes porque ajudam a garantir que uma organização pode continuar a operar durante um desastre, proteger a sua reputação, cumprir os requisitos legais, manter a confiança dos clientes, gerir os riscos de forma eficaz e manter os colaboradores seguros.
Controlo N.º 28
Forneça provas que demonstrem que:
A documentação existe e é mantida, que descreve o plano de continuidade do negócio e inclui:
detalhes do pessoal relevante, incluindo as respetivas funções e responsabilidades
funções empresariais com requisitos e objetivos de contingência associados
procedimentos de cópia de segurança de sistemas e dados, configuração e agendamento/retenção
prioridade de recuperação e destinos de período de tempo
um plano de contingência que detalha ações, passos e procedimentos a seguir para devolver sistemas de informação críticos, funções empresariais e serviços a funcionar em caso de interrupção inesperada e não agendada
um processo estabelecido que abrange o eventual restauro completo do sistema e regressa ao estado original
Intenção: plano de continuidade de negócio
A intenção subjacente a este controlo é garantir que uma lista claramente definida de pessoal com funções e responsabilidades atribuídas esteja incluída no plano de continuidade de negócio. Estas funções são cruciais para uma ativação e execução eficazes do plano durante um incidente.
Diretrizes: plano de continuidade de negócio
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de evidência: plano de continuidade de negócio
As capturas de ecrã seguintes mostram uma extração de um plano de continuidade de negócio e que este existe e é mantido.
Nota: esta(s) captura(s) de ecrã mostra instantâneos de um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
As capturas de ecrã seguintes mostram uma extração da política em que a secção "Key staff" está descrita, incluindo a equipa relevante, os detalhes de contacto e os passos a seguir.
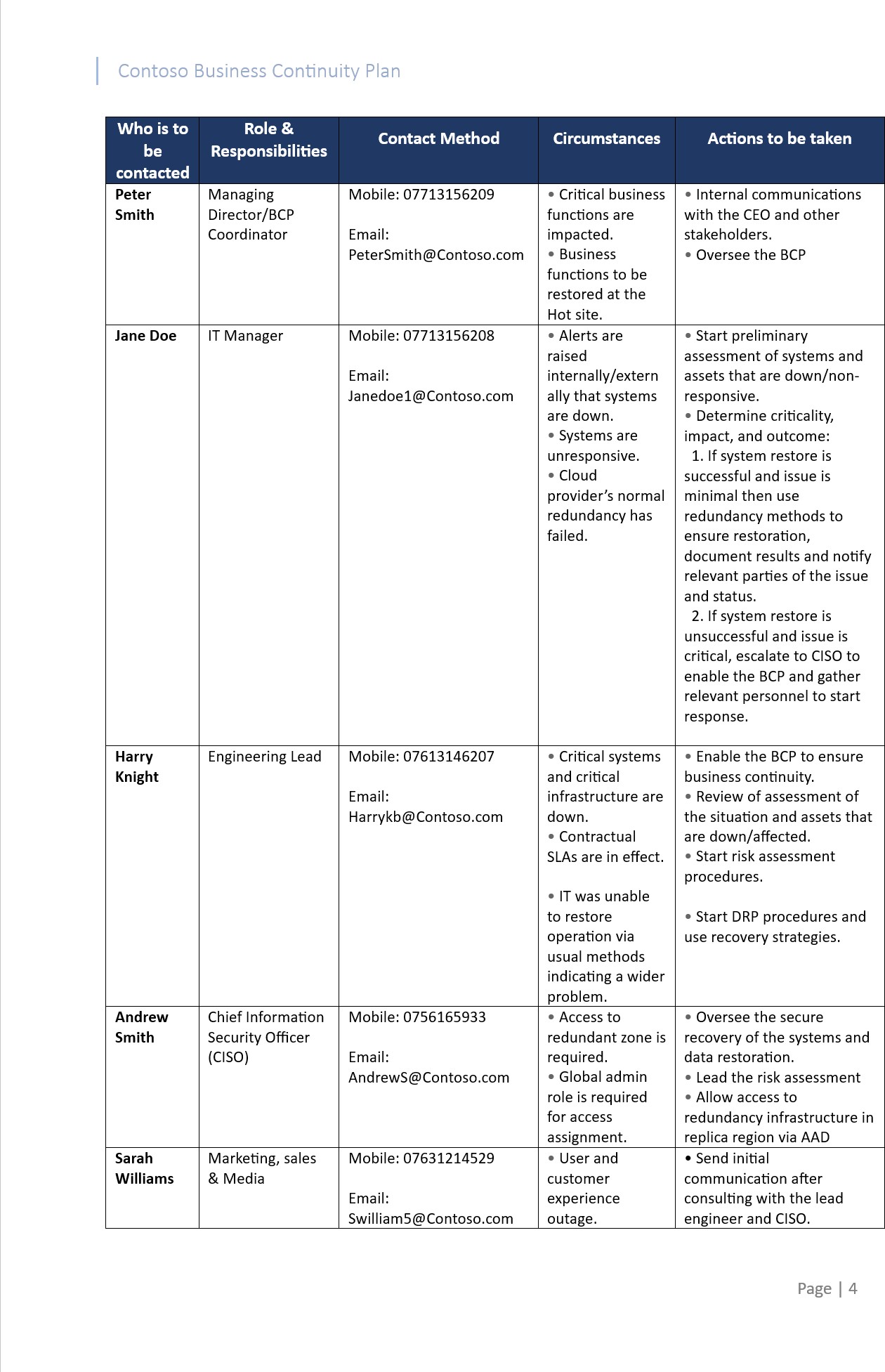
Intenção: atribuição de prioridades
O objetivo deste controlo é documentar e atribuir prioridades a funções empresariais de acordo com a sua importância. Isto deve ser acompanhado por um resumo dos requisitos de contingência correspondentes necessários para manter ou restaurar rapidamente cada função durante uma interrupção não planeada.
Diretrizes: atribuição de prioridades
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de evidência: atribuição de prioridades
As capturas de ecrã seguintes mostram uma extração de um plano de continuidade de negócio e um destaque das funções empresariais e do seu nível de importância, bem como se existirem planos de contingência.
Nota: esta(s) captura(s) de ecrã mostra um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.

Intenção: cópias de segurança
O objetivo deste subponto é manter os procedimentos documentados para criar cópias de segurança de sistemas e dados essenciais. A documentação também deve especificar as definições de configuração, bem como as políticas de agendamento e retenção de cópias de segurança, para garantir que os dados são atuais e recuperáveis.
Diretrizes: cópias de segurança
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de provas: cópias de segurança
As capturas de ecrã seguintes mostram a extração do plano de recuperação após desastre da Contoso e a existência de uma configuração de cópia de segurança documentada para cada sistema. Tenha em atenção que, na captura de ecrã seguinte, a agenda de cópias de segurança também está descrita. Tenha em atenção que, para este exemplo, a configuração da cópia de segurança está descrita como parte do plano de recuperação após desastre, uma vez que os planos de continuidade de negócio e recuperação após desastre funcionam em conjunto.
Nota: esta(s) captura(s) de ecrã mostra um instantâneo de um documento de política/procedimento. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
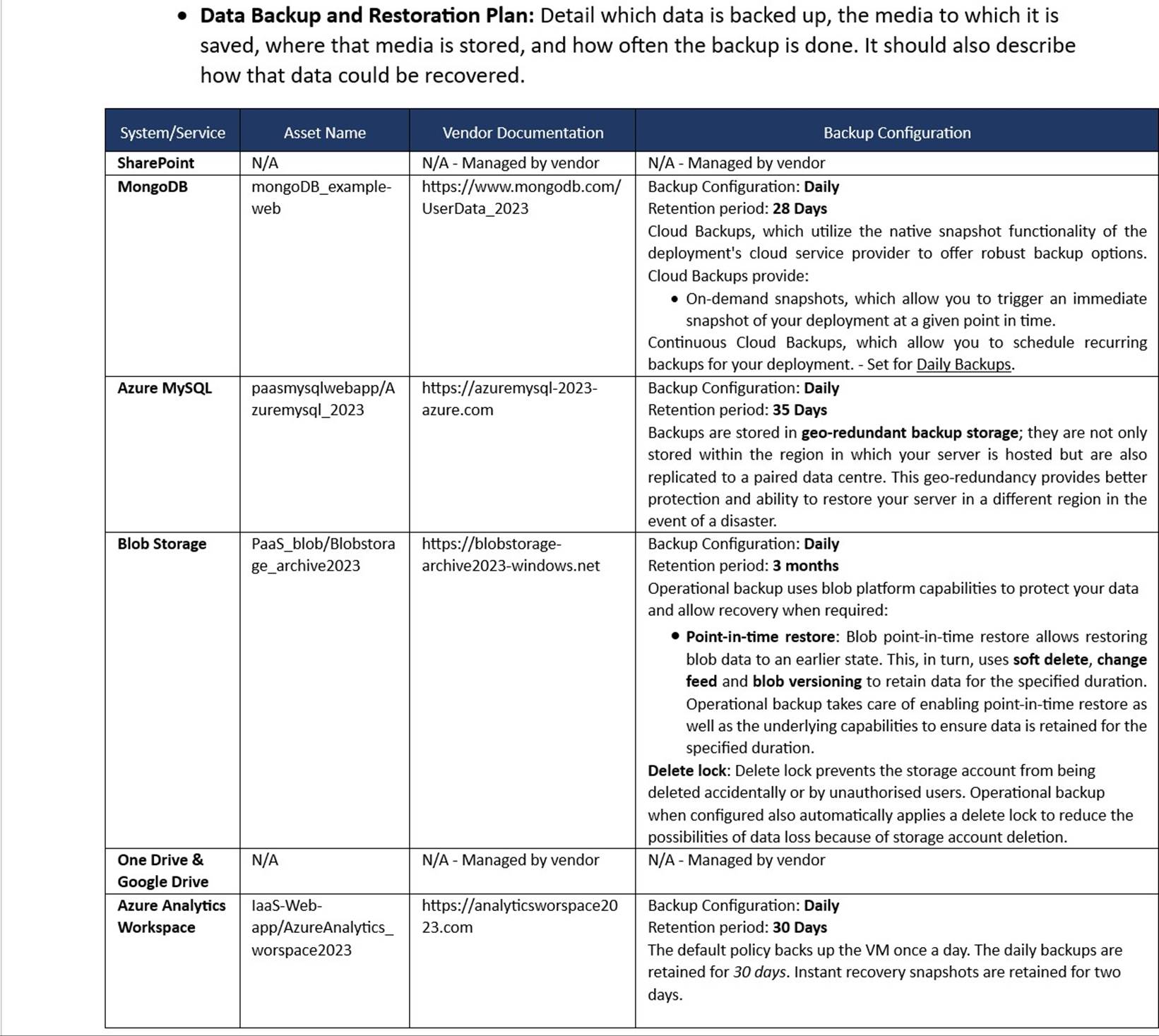
Intenção: linhas cronológicas
Este controlo visa estabelecer linhas cronológicas prioritárias para ações de recuperação. Estes objetivos de tempo de recuperação (RTOs) devem ser alinhados com a análise de impacto comercial e devem ser claramente definidos para que o pessoal compreenda quais os sistemas e funções que têm de ser restaurados primeiro.
Diretrizes: linhas cronológicas
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de evidência: linhas cronológicas
A seguinte captura de ecrã a mostrar a continuação das funções empresariais e a classificação de criticidade, bem como o Objetivo de Tempo de Recuperação (RTO) estabelecido.
Nota: esta(s) captura(s) de ecrã mostra um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.


Intenção: recuperação
Este controlo pretende fornecer um procedimento passo a passo que deve ser seguido para devolver sistemas de informação críticos, funções empresariais e serviços ao estado operacional. Isto deve ser suficientemente detalhado para orientar a tomada de decisões em situações de alta pressão, em que as acções rápidas e eficazes são essenciais.
Diretrizes: recuperação
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de evidência: recuperação
As capturas de ecrã seguintes mostram a extração do nosso plano de recuperação após desastre e que existe um plano de recuperação documentado para cada sistema e função empresarial. Tenha em atenção que, neste exemplo, o procedimento de recuperação do sistema faz parte do plano de recuperação após desastre, uma vez que os planos de continuidade de negócio e recuperação após desastre funcionam em conjunto para alcançar a recuperação/restauro completos.
Nota: esta(s) captura(s) de ecrã mostra um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
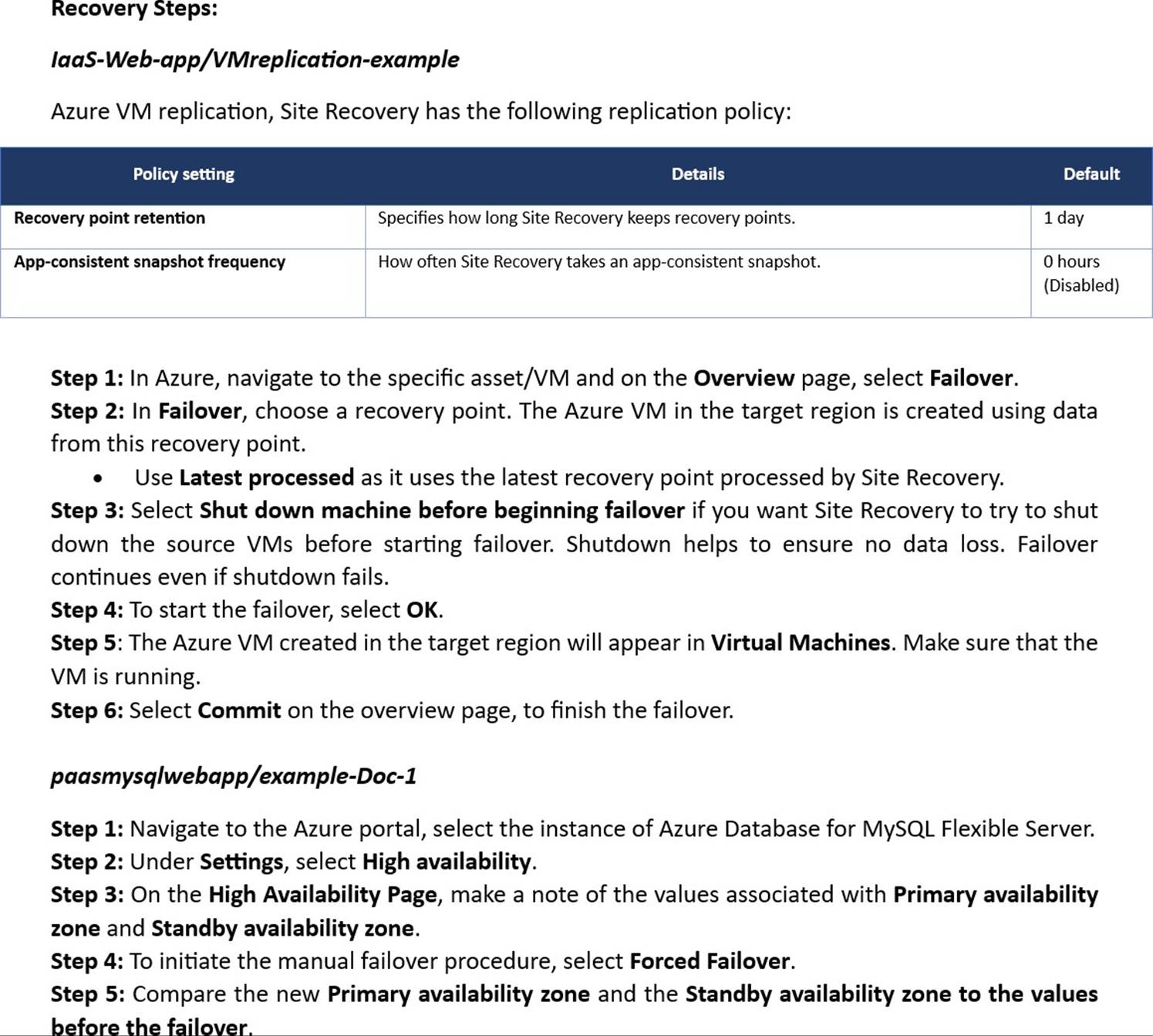
Intenção: validação
Este ponto de controlo visa garantir que o plano de continuidade do negócio inclui um processo estruturado para orientar a organização no restauro dos sistemas para o seu estado original assim que a crise for gerida. Isto inclui passos de validação para garantir que os sistemas estão totalmente operacionais e que mantiveram a sua integridade.
Diretrizes: validação
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de prova: validação
A captura de ecrã seguinte mostra o processo de recuperação descrito na política do plano de continuidade de negócio e os passos/ação a realizar.
Nota: esta(s) captura(s) de ecrã mostra um instantâneo de um documento de política/procedimento. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.

Controlo N.º 29
Forneça provas que demonstrem que:
A documentação existe e é mantida, que descreve o plano de recuperação após desastre e inclui no mínimo:
detalhes do pessoal relevante, incluindo as respetivas funções e responsabilidades
funções empresariais com requisitos e objetivos de contingência associados
procedimentos de cópia de segurança de sistemas e dados, configuração e agendamento/retenção
prioridade de recuperação e destinos de período de tempo
um plano de contingência que detalha ações, passos e procedimentos a seguir para devolver sistemas de informação críticos, funções empresariais e serviços a funcionar em caso de interrupção inesperada e não agendada
um processo estabelecido que abrange o eventual restauro completo do sistema e regressa ao estado original
Intenção: DRP
O objetivo deste controlo é ter funções e responsabilidades bem documentadas para cada membro da equipa de recuperação após desastre. Também deve ser delineado um processo de escalamento para garantir que os problemas são rapidamente elevados e resolvidos por pessoal adequado durante um cenário de desastre.
Diretrizes: DRP
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de evidência: DRP
As capturas de ecrã seguintes mostram a extração de um plano de recuperação após desastre e que este existe e é mantido.
Nota: esta(s) captura(s) de ecrã mostra um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
A captura de ecrã seguinte mostra uma extração da política em que o "Plano de Contingência" está descrito, incluindo a equipa relevante, os detalhes de contacto e os passos de escalamento.
Intenção: inventário
A intenção subjacente a este controlo é manter uma lista de inventário atualizada de todos os sistemas de informação cruciais para suportar operações empresariais. Esta lista é fundamental para compreender que sistemas têm de ser priorizados durante um esforço de recuperação após desastre.
Diretrizes: inventário
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de evidência: inventário
As capturas de ecrã seguintes mostram a extração de um DRP e que existe um inventário de sistemas críticos e o respetivo nível de criticidade, bem como as funções do sistema.
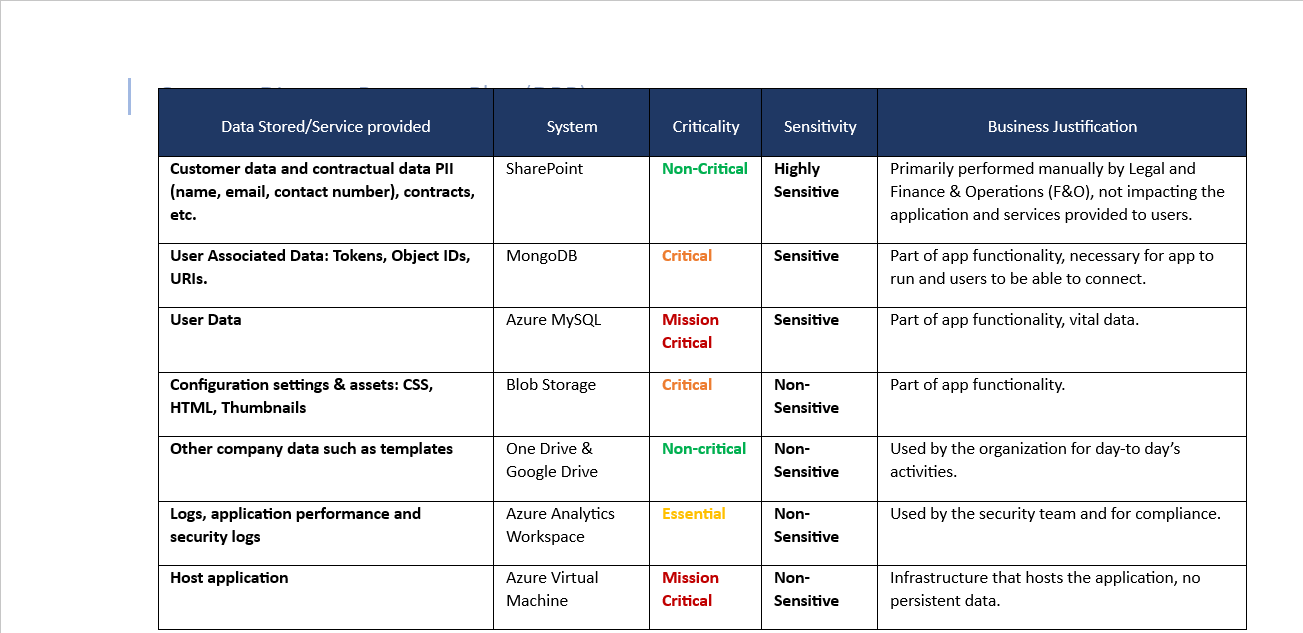
Nota: esta(s) captura(s) de ecrã mostra um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
A captura de ecrã seguinte mostra a definição de classificação e de criticidade do serviço.
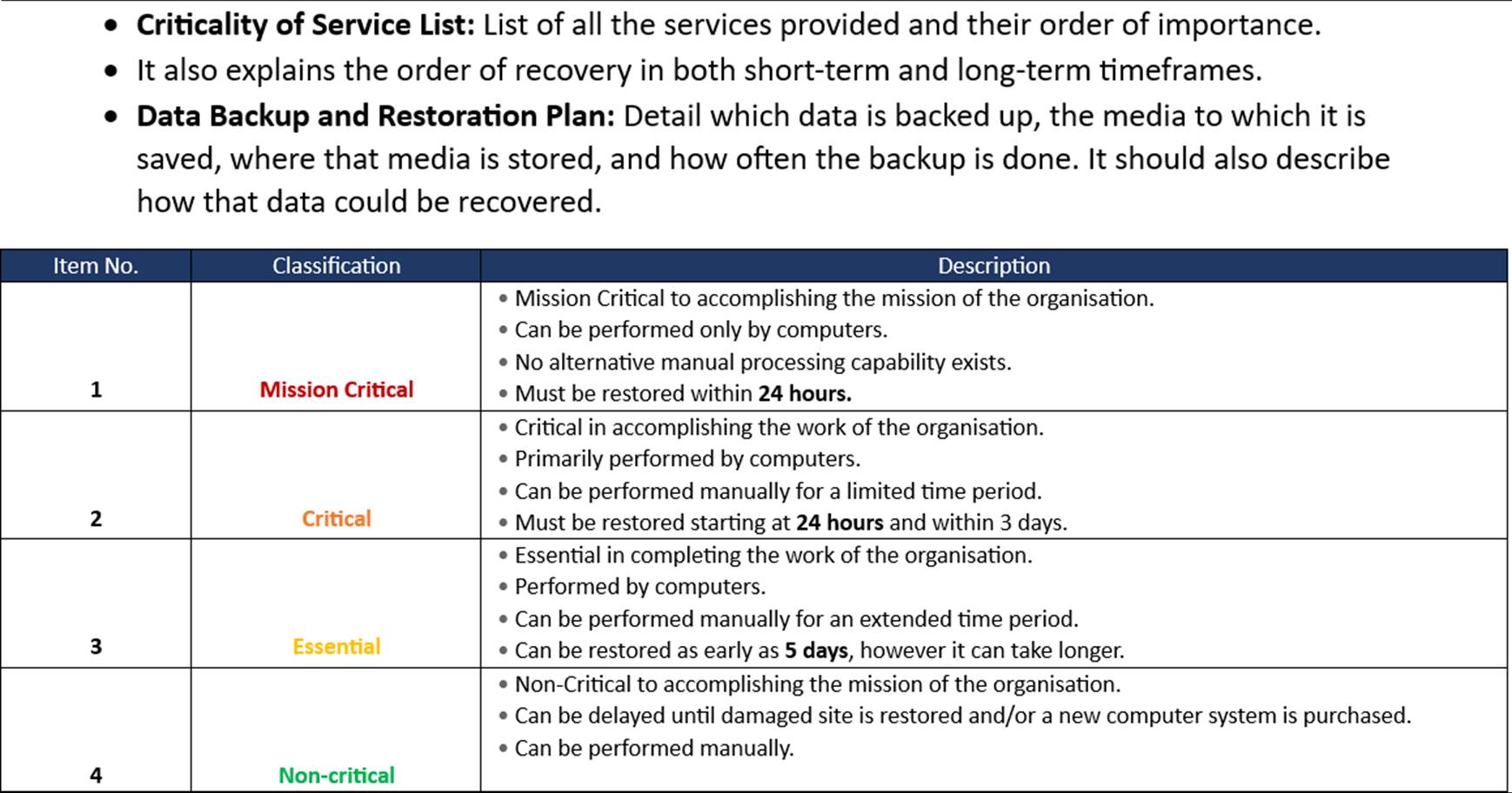
Nota: esta(s) captura(s) de ecrã mostra um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
Intenção: cópias de segurança
Este controlo requer que estejam implementados procedimentos bem definidos para cópias de segurança de sistemas e dados. Estes procedimentos devem destacar a frequência, a configuração e as localizações das cópias de segurança para garantir que todos os dados críticos podem ser restaurados em caso de falha ou desastre.
Diretrizes: cópias de segurança
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de provas: cópias de segurança
As capturas de ecrã seguintes mostram a extração de um plano de recuperação após desastre e que existe uma configuração de cópia de segurança documentada para cada sistema. Observe abaixo que a agenda de cópias de segurança também está descrita.
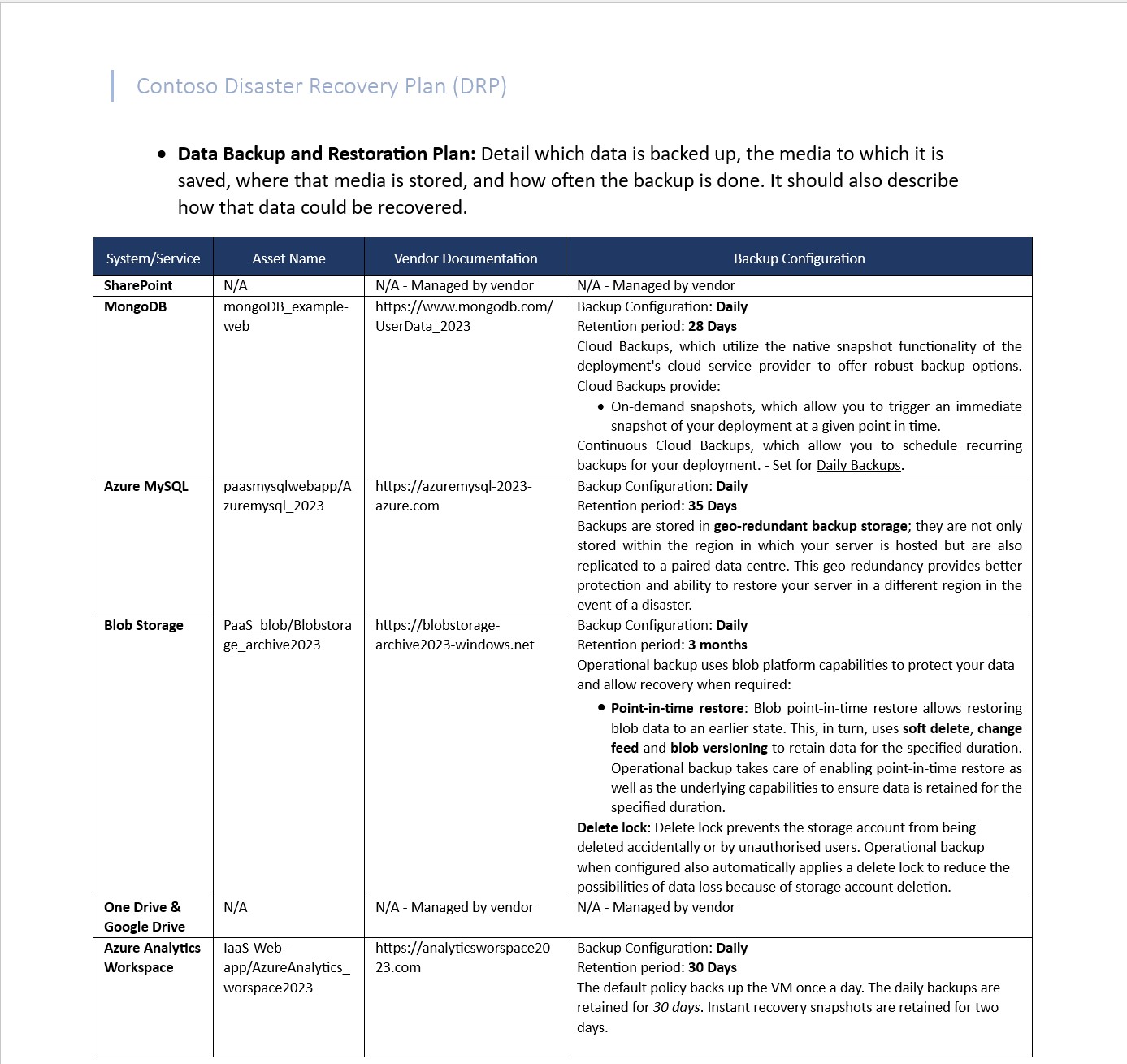
Nota: esta(s) captura(s) de ecrã mostra um instantâneo de um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
Intenção: recuperação
Este controlo exige um plano de recuperação abrangente que delineia procedimentos passo a passo para restaurar sistemas e dados vitais. Isto serve como um mapa de objetivos para a equipa de recuperação após desastre e garante que todas as ações de recuperação são premeditadas e eficazes no restauro de operações empresariais.
Diretrizes: recuperação
Indique a versão completa do plano/procedimento de recuperação após desastre que deve incluir secções que abrangem o destaque processado na descrição do controlo. Forneça o documento PDF/WORD real se estiver numa versão digital, em alternativa, se o processo for mantido através de uma plataforma online, forneça uma exportação ou capturas de ecrã dos processos.
Exemplo de evidência: recuperação
As capturas de ecrã seguintes mostram a extração de um plano de recuperação após desastre e que existem passos e instruções de recuperação do sistema e de substituição do equipamento e estão documentados, bem como o procedimento de recuperação que inclui timeframes de recuperação, ações a serem tomadas para restaurar a infraestrutura de cloud, etc.

Nota: esta(s) captura(s) de ecrã mostra um instantâneo de um documento de política/processo. A expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.
Controlo N.º 30
Forneça provas que demonstrem que:
O plano de continuidade de negócio e o plano de recuperação após desastre estão a ser revistos pelo menos a cada 12 meses para garantir que permanece válido e eficaz durante situações adversas e é atualizado com base em:
Revisão anual do plano.
Todo o pessoal relevante recebe formação sobre as suas funções e responsabilidades atribuídas nos planos de contingência.
Os planos são testados através de exercícios de continuidade de negócio ou recuperação após desastre.
Os resultados dos testes são documentados, incluindo lições aprendidas com exercícios ou alterações organizacionais.
Intenção: revisão anual
O objetivo deste controlo é garantir que os planos de continuidade de negócio e recuperação após desastre sejam revistos anualmente. A revisão deve confirmar que os planos ainda são eficazes, precisos e alinhados com os objetivos empresariais atuais e as arquiteturas tecnológicas.
Intenção: formação anual
Este controlo determina que todas as pessoas com funções designadas nos planos de continuidade de negócio e recuperação após desastre recebem anualmente formação adequada. O objetivo é garantir que estão cientes das suas responsabilidades e capazes de executá-las eficazmente em caso de desastre ou interrupção empresarial.
Intenção: exercícios
A intenção aqui é validar a eficácia dos planos de continuidade de negócio e recuperação após desastre através de exercícios do mundo real. Estes exercícios devem ser concebidos para simular várias condições adversas para testar o quão bem a organização pode manter ou restaurar operações empresariais.
Intenção: análise
O ponto de controlo final visa uma documentação completa de todos os resultados dos testes, incluindo uma análise do que funcionou bem e o que não funcionou. As lições aprendidas devem ser integradas novamente nos planos e quaisquer deficiências devem ser imediatamente abordadas para melhorar a resiliência da organização.
Diretrizes: revisões
Devem ser fornecidas provas como relatórios, notas de reunião e saídas dos exercícios anuais de continuidade empresarial e de planos de recuperação após desastre para revisão.
Exemplo de evidência: revisões
As capturas de ecrã seguintes mostram um resultado de relatório de um exercício (exercício) de continuidade de negócio e plano de recuperação após desastre no qual foi estabelecido um cenário para permitir que a equipa decrete o plano de continuidade de negócio e recuperação após desastre e orientações sobre a situação até ao restauro bem-sucedido das funções empresariais e do funcionamento do sistema.
Nota: estas capturas de ecrã mostram um(s) instantâneo(s) de um documento de política/processo, a expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.





Nota: estas capturas de ecrã mostram um(s) instantâneo(s) de um documento de política/processo, a expetativa é que os ISVs partilhem a documentação de política/procedimento de suporte real e não apenas forneçam uma captura de ecrã.