Ações de OCR
O Power Automate permite a usuários ler, extrair e gerenciar dados em arquivos por meio do OCR (reconhecimento óptico de caracteres).
Para criar um mecanismo de OCR e extrair texto de imagens e documentos, use a ação Extrair texto com OCR. O exemplo a seguir extrai o texto de toda a imagem especificada.
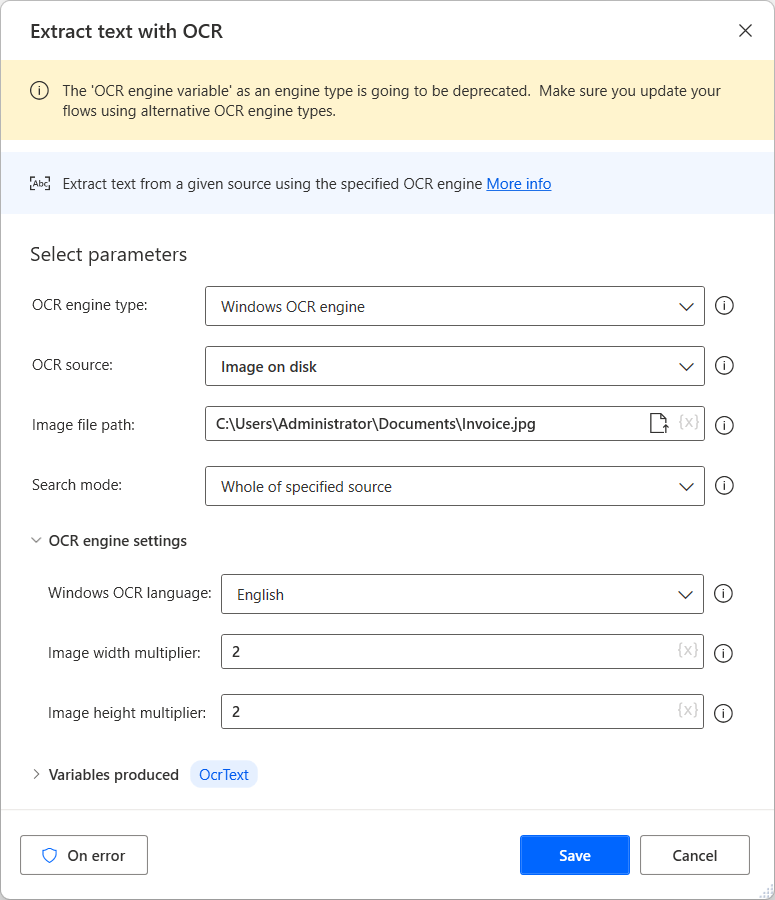
Todas as ações de OCR podem criar uma nova variável de mecanismo de OCR ou usar uma existente. Você pode usar variáveis existentes do mecanismo de OCR em qualquer ação que ofereça recursos de OCR.
O Power Automate oferece suporte aos mecanismos de OCR e Tesseract do Windows. Para configurar o mecanismo de OCR selecionado, navegue até Configurações do mecanismo de OCR da ação apropriada. As opções disponíveis incluem o idioma, a altura da imagem e os multiplicadores de largura.
Observação
- Todos os mecanismos de OCR disponíveis são pré-instalados no Power Automate e funcionam localmente sem conexão à nuvem. No entanto, pode ser necessário baixar pacotes de idiomas ou arquivos de dados para extrair textos em idiomas específicos.
- Os multiplicadores aumentam o tamanho da imagem para tornar a pesquisa e a extração de texto mais eficazes. A definição de valores maiores que 3 pode levar a resultados errôneos.
Use do mecanismo de OCR do Windows
O mecanismo de OCR padrão no Power Automate é o mecanismo de OCR do Windows. Para extrair textos usando o mecanismo de OCR do Windows, você deve instalar o pacote de idiomas apropriado para o idioma a ser extraído.
Se o pacote de idiomas apropriado não estiver instalado, o Power Automate gerará um erro solicitando que você o instale. Para encontrar mais informações sobre como baixar e instalar pacotes de idiomas, vá para Pacotes de idiomas para o Windows.
Depois de instalar o pacote de idiomas apropriado, estenda as Configurações do mecanismo de OCR da ação de OCR e selecione o idioma desejado. O mecanismo de OCR do Windows dá suporte a 25 idiomas, incluindo: chinês (simplificado e tradicional), tcheco, dinamarquês, holandês, inglês, finlandês, francês, alemão, grego, húngaro, italiano, japonês, coreano, norueguês, polonês, português, romeno, russo, sérvio (cirílico e latim), eslovaco, espanhol, sueco e turco.
Usar o mecanismo de OCR do Tesseract
Observação
Para usar o mecanismo de OCR Tesseract, certifique-se de que a CPU do computador seja compatível com o conjunto de instruções AVX2.
Além do mecanismo de OCR do Windows, o Power Automate dá suporte ao mecanismo Tesseract. Esse mecanismo pode extrair texto em cinco idiomas sem configuração adicional: inglês, alemão, espanhol, francês e italiano.
Para extrair texto em um idioma fora da lista mencionada, habilite a opção Usar outros idiomas nas Configurações do mecanismo de OCR da ação de OCR. Quando esta opção estiver habilitada, a ação exibirá mais dois parâmetros: Abreviação do idioma e Caminho de dados do idioma.
O campo Abreviação do idioma indica para o mecanismo qual idioma procurar durante o OCR. O campo Caminho de dados do idioma contém os arquivos de dados do idioma (.traineddata) usado para treinar o mecanismo de OCR. Você pode encontrar os arquivos de dados de idioma para todos os idiomas disponíveis neste repositório do GitHub.
Você também pode usar o mecanismo Tesseract para extrair texto de documentos multilíngues. Para encontrar mais informações sobre como extrair texto de documentos multilíngues, vá para Executar o OCR em documentos multilíngues.
Se existe texto na tela (OCR)
Marca o início de um bloco condicional de ações, dependendo de um determinado texto aparecer ou não na tela, usando o OCR.
Parâmetros de entrada
| Argumento | Opcional | Aceita | Valor padrão | Description |
|---|---|---|---|---|
| Se for texto | N/D | Existe, Não existe | Existe | Especifica se deve verificar a existência do texto na origem fornecida para ser analisada |
| Tipo de mecanismo de OCR | Não | Mecanismo de OCR do Windows, mecanismo Tesseract, variável de mecanismo de OCR | Variável de mecanismo de OCR | O tipo de mecanismo de OCR a ser usado. Selecione um mecanismo de OCR pré-configurado ou configure um novo. |
| Variável de mecanismo de OCR | Não | OCREngineObject | O mecanismo a ser usado para a operação de OCR | |
| Text to find | Não | Valor do texto | O texto a ser pesquisado na origem especificada | |
| Is regular expression | N/D | Valor booliano | False | Especifica se deve ser usada uma expressão regular para localizar o texto especificado |
| Search for text on | N/D | Tela inteira, Janela em primeiro plano | Tela inteira | Especifica se deve ser pesquisado o texto especificado em toda a tela visível ou apenas na janela de primeiro plano |
| Search mode | N/A | Toda a fonte especificada, Somente a sub-região específica, Sub-região relativa à imagem | Toda a origem especificada | Especifica se deve verificar toda a tela (ou janela) ou uma sub-região reduzida dela |
| Imagens | Não | Lista de Imagens | As imagens que especificam a sub-região (em relação ao canto superior esquerdo da imagem) a ser verificada para o texto fornecido | |
| X1 | Sim | Valor numérico | A coordenada X inicial da sub-região a ser verificada para o texto fornecido | |
| Tolerance | Sim | Valor numérico | 10 | Especifica o quanto as imagens pesquisadas podem ser diferentes da imagem escolhida originalmente |
| Y1 | Sim | Valor numérico | A coordenada Y inicial da sub-região a ser verificada para o texto fornecido | |
| X1 | Sim | Valor numérico | A coordenada X inicial da sub-região relativa à imagem especificada a ser verificada para o texto fornecido | |
| X2 | Sim | Valor numérico | A coordenada X final da sub-região a ser verificada para o texto fornecido | |
| Y1 | Sim | Valor numérico | A coordenada Y inicial da sub-região relativa à imagem especificada a ser verificada para o texto fornecido | |
| Y2 | Sim | Valor numérico | A coordenada Y final da sub-região a ser verificada para o texto fornecido | |
| X2 | Sim | Valor numérico | A coordenada X final da sub-região relativa à imagem especificada a ser verificada para o texto fornecido | |
| Y2 | Sim | Valor numérico | A coordenada Y final da sub-região relativa à imagem especificada a ser verificada para o texto fornecido | |
| Idioma do OCR do Windows | N/A | Chinês (simplificado), chinês (tradicional), tcheco, dinamarquês, holandês, inglês, finlandês, francês, alemão, grego, húngaro, italiano, japonês, coreano, norueguês, polonês, português, romeno, russo, sérvio (cirílico), sérvio (latino), eslovaco, espanhol, sueco, turco | Inglês | O idioma do texto detectado pelo mecanismo de OCR do Windows |
| Usar outro idioma | N/A | Valor booliano | Falso | Especifica se um idioma que não foi fornecido no campo "Idioma do Tesseract" deve ser usado |
| Idioma do Tesseract | N/A | Inglês, alemão, espanhol, francês, italiano | Inglês | O idioma do texto que o mecanismo Tesseract detecta |
| Abreviação do idioma | Não | Valor do texto | A abreviação Tesseract do idioma a ser usado. Por exemplo, se os dados forem "eng.traineddata", defina este parâmetro como "eng" | |
| Caminho de dados do idioma | Não | Valor do texto | O caminho da pasta que contém os dados do Tesseract do idioma especificado | |
| Multiplicador de largura da imagem | Não | Valor numérico | 1 | O multiplicador de largura da imagem |
| Multiplicador de altura da imagem | Não | Valor numérico | 1 | O multiplicador de altura da imagem |
| Algoritmo de correspondência de imagens | N/A | Básico, Avançado | Básica | Qual algoritmo de imagem usar ao pesquisar por imagem |
Observação
- O mecanismo de expressão regular do Power Automate é o .NET. Para encontrar mais informações sobre expressões regulares, vá para Linguagem de Expressões Regulares – Referência Rápida.
- A opção Variável do mecanismo de OCR será preterida.
Variáveis produzidas
| Argumento | Type | Description |
|---|---|---|
| LocationOfTextFoundX | Valor numérico | A coordenada X do ponto em que o texto aparece na tela. Se a pesquisa for realizada na janela em primeiro plano, a coordenada retornada é relativa ao canto superior esquerdo da janela |
| LocationOfTextFoundY | Valor numérico | A coordenada X do ponto em que o texto aparece na tela. Se a pesquisa for realizada na janela em primeiro plano, a coordenada retornada é relativa ao canto superior esquerdo da janela |
Exceções
| Exceção | Description |
|---|---|
| Não é possível verificar se existe texto no modo não interativo | Indica que não é possível verificar o texto na tela quando no modo não interativo |
| Invalid subregion coordinates | Indica que as coordenadas especificadas da sub-região são inválidas |
| Failed to analyze text with OCR | Indica que ocorreu um erro ao tentar analisar o texto usando OCR |
| Falha ao criar o mecanismo de OCR | Indica que ocorreu um erro ao tentar criar o mecanismo de OCR |
| A pasta de caminho de dados não existe | Indica que a pasta especificada para os dados do idioma não existe |
| O pacote de idiomas do Windows selecionado não está instalado no computador | O pacote de idiomas do Windows selecionado não está instalado no computador |
| Mecanismo de OCR não ativo | Indica que o mecanismo de OCR não está ativo |
Aguardar o texto na tela (OCR)
Aguardar até que um texto específico apareça/desapareça da tela, da janela de primeiro plano ou relativo a uma imagem na tela ou na janela de primeiro plano usando OCR.
Parâmetros de entrada
| Argumento | Opcional | Aceita | Valor padrão | Description |
|---|---|---|---|---|
| Wait for text to | N/D | Aparecer, Desaparecer | Aparecer | Especifica se deve aguardar o texto aparecer ou desaparecer |
| Tipo de mecanismo de OCR | Não | Mecanismo de OCR do Windows, mecanismo Tesseract, variável de mecanismo de OCR | Variável de mecanismo de OCR | O tipo de mecanismo de OCR a ser usado. Selecione um mecanismo de OCR pré-configurado ou configure um novo. |
| Variável de mecanismo de OCR | Não | OCREngineObject | O mecanismo a ser usado para a operação de OCR | |
| Text to find | Não | Valor do texto | O texto a ser pesquisado na origem especificada | |
| Is regular expression | N/D | Valor booliano | False | Especifica se deve ser usada uma expressão regular para localizar o texto especificado |
| Search for text on | N/D | Tela inteira, Janela em primeiro plano | Tela inteira | Especifica se deve ser pesquisado o texto especificado em toda a tela visível ou apenas na janela de primeiro plano |
| Search mode | N/A | Toda a fonte especificada, Somente a sub-região específica, Sub-região relativa à imagem | Toda a origem especificada | Especifica se deve verificar toda a tela (ou janela) ou uma sub-região reduzida dela |
| Imagens | Não | Lista de Imagens | As imagens que especificam a sub-região (em relação ao canto superior esquerdo da imagem) a ser verificada para o texto fornecido | |
| X1 | Sim | Valor numérico | A coordenada X inicial da sub-região a ser verificada para o texto fornecido | |
| Tolerance | Sim | Valor numérico | 10 | Especifica o quanto as imagens pesquisadas podem ser diferentes da imagem escolhida originalmente |
| Y1 | Sim | Valor numérico | A coordenada Y inicial da sub-região a ser verificada para o texto fornecido | |
| X1 | Sim | Valor numérico | A coordenada X inicial da sub-região relativa à imagem especificada a ser verificada para o texto fornecido | |
| X2 | Sim | Valor numérico | A coordenada X final da sub-região a ser verificada para o texto fornecido | |
| Y1 | Sim | Valor numérico | A coordenada Y inicial da sub-região relativa à imagem especificada a ser verificada para o texto fornecido | |
| Y2 | Sim | Valor numérico | A coordenada Y final da sub-região a ser verificada para o texto fornecido | |
| X2 | Sim | Valor numérico | A coordenada X final da sub-região relativa à imagem especificada a ser verificada para o texto fornecido | |
| Y2 | Sim | Valor numérico | A coordenada Y final da sub-região relativa à imagem especificada a ser verificada para o texto fornecido | |
| Idioma do OCR do Windows | N/A | Chinês (simplificado), chinês (tradicional), tcheco, dinamarquês, holandês, inglês, finlandês, francês, alemão, grego, húngaro, italiano, japonês, coreano, norueguês, polonês, português, romeno, russo, sérvio (cirílico), sérvio (latino), eslovaco, espanhol, sueco, turco | Inglês | O idioma do texto detectado pelo mecanismo de OCR do Windows |
| Usar outro idioma | N/A | Valor booliano | Falso | Especifica se um idioma que não foi fornecido no campo "Idioma do Tesseract" deve ser usado |
| Idioma do Tesseract | N/A | Inglês, alemão, espanhol, francês, italiano | Inglês | O idioma do texto que o mecanismo Tesseract detecta |
| Abreviação do idioma | Não | Valor do texto | A abreviação Tesseract do idioma a ser usado. Por exemplo, se os dados forem "eng.traineddata", defina este parâmetro como "eng" | |
| Caminho de dados do idioma | Não | Valor do texto | O caminho da pasta que contém os dados do Tesseract do idioma especificado | |
| Multiplicador de largura da imagem | Não | Valor numérico | 1 | O multiplicador de largura da imagem |
| Multiplicador de altura da imagem | Não | Valor numérico | 1 | O multiplicador de altura da imagem |
| Algoritmo de correspondência de imagens | N/A | Básico, Avançado | Básico | Qual algoritmo de imagem usar ao pesquisar por imagem |
| Falha com erro de tempo limite | N/A | Valor booliano | False | Especificar se você deseja que a ação aguarde indefinidamente ou haja falha após um período definido |
Observação
- O mecanismo de expressão regular do Power Automate é o .NET. Para encontrar mais informações sobre expressões regulares, vá para Linguagem de Expressões Regulares – Referência Rápida.
- A opção Variável do mecanismo de OCR será preterida.
Variáveis produzidas
| Argumento | Type | Description |
|---|---|---|
| LocationOfTextFoundX | Valor numérico | A coordenada X do ponto em que o texto aparece na tela. Se a pesquisa for realizada na janela em primeiro plano, a coordenada retornada é relativa ao canto superior esquerdo da janela |
| LocationOfTextFoundY | Valor numérico | A coordenada X do ponto em que o texto aparece na tela. Se a pesquisa for realizada na janela em primeiro plano, a coordenada retornada é relativa ao canto superior esquerdo da janela |
Exceções
| Exceção | Description |
|---|---|
| Não é possível verificar se existe texto no modo não interativo | Indica que não é possível verificar o texto na tela quando no modo não interativo |
| Invalid subregion coordinates | Indica que as coordenadas especificadas da sub-região são inválidas |
| Failed to analyze text with OCR | Indica que ocorreu um erro ao tentar analisar o texto usando OCR |
| Falha ao criar o mecanismo de OCR | Indica que ocorreu um erro ao tentar criar o mecanismo de OCR |
| A pasta de caminho de dados não existe | Indica que a pasta especificada para os dados do idioma não existe |
| O pacote de idiomas do Windows selecionado não está instalado no computador | O pacote de idiomas do Windows selecionado não está instalado no computador |
| Mecanismo de OCR não ativo | Indica que o mecanismo de OCR não está ativo |
| Erro de tempo limite | Indica que a ação falhou após um determinado período |
Extrair texto com OCR
Extrair texto de uma determinada origem usando o mecanismo de OCR fornecido.
Parâmetros de entrada
| Argumento | Opcional | Aceita | Valor padrão | Description |
|---|---|---|---|---|
| Mecanismo de OCR | Não | Mecanismo de OCR do Windows, mecanismo Tesseract, variável de mecanismo de OCR | Variável de mecanismo de OCR | O tipo de mecanismo de OCR a ser usado. Selecione um mecanismo de OCR pré-configurado ou configure um novo |
| Variável de mecanismo de OCR | Não | OCREngineObject | O mecanismo a ser usado para a operação de OCR | |
| OCR source | N/D | Tela, Janela em primeiro plano, Imagem no disco | Tela | A origem da imagem na qual executar a operação de OCR |
| Image file path | Não | Arquivo | O caminho da imagem na qual executar a operação de OCR | |
| Search mode | N/D | Toda a fonte especificada, Somente a sub-região específica, Sub-região relativa à imagem | Toda a origem especificada | O modo selecionado para a operação de OCR |
| Imagem | Não | Lista de Imagens | A imagem a ser usada para restringir a verificação a uma sub-região em relação à imagem especificada | |
| Tolerância | Sim | Valor numérico | 10 | Especifica o quanto a imagem pode ser diferente da imagem escolhida originalmente |
| X1 | Sim | Valor numérico | A coordenada X inicial da sub-região para restringir a verificação | |
| X2 | Sim | Valor numérico | A coordenada X final da sub-região para restringir a verificação | |
| Y1 | Sim | Valor numérico | A coordenada Y inicial da sub-região para restringir a verificação | |
| Y2 | Sim | Valor numérico | A coordenada Y final da sub-região para restringir a verificação | |
| Idioma do OCR do Windows | N/A | Chinês (simplificado), chinês (tradicional), tcheco, dinamarquês, holandês, inglês, finlandês, francês, alemão, grego, húngaro, italiano, japonês, coreano, norueguês, polonês, português, romeno, russo, sérvio (cirílico), sérvio (latino), eslovaco, espanhol, sueco, turco | Inglês | O idioma do texto detectado pelo mecanismo de OCR do Windows |
| Usar outro idioma | N/A | Valor booliano | Falso | Especifica se um idioma que não foi fornecido no campo "Idioma do Tesseract" deve ser usado |
| Idioma do Tesseract | N/A | Inglês, alemão, espanhol, francês, italiano | Inglês | O idioma do texto que o mecanismo Tesseract detecta |
| Abreviação do idioma | Não | Valor do texto | A abreviação Tesseract do idioma a ser usado. Por exemplo, se os dados forem "eng.traineddata", defina este parâmetro como "eng" | |
| Caminho de dados do idioma | Não | Valor do texto | O caminho da pasta que contém os dados do Tesseract do idioma especificado | |
| Multiplicador de largura da imagem | Não | Valor numérico | 1 | O multiplicador de largura da imagem |
| Multiplicador de altura da imagem | Não | Valor numérico | 1 | O multiplicador de altura da imagem |
| Aguarde a imagem aparecer | N/A | Valor booliano | Verdadeiro | Especifica se é preciso aguardar ou não para que a imagem apareça na tela ou na janela de primeiro plano |
| Tempo limite | Não | Valor numérico | 5 | Especifica o tempo de espera para a operação ser concluída antes de considerar que a ação falhou |
| Algoritmo de correspondência de imagens | N/A | Básico, Avançado | Básica | Qual algoritmo de imagem usar ao pesquisar por imagem |
Observação
A opção Variável do mecanismo de OCR será preterida.
Variáveis produzidas
| Argumento | Type | Description |
|---|---|---|
| OcrText | Valor do texto | O resultado após a extração de texto |
Exceções
| Exceção | Descrição |
|---|---|
| Failed to extract text with OCR | Indica que ocorreu um erro ao tentar extrair o texto com OCR da origem fornecida |
| Arquivo de imagem não encontrado | Indica que o arquivo não existe no caminho fornecido |
| Imagem de marco não encontrada | Indica que a imagem de marco não existe |
| Não é possível obter texto da tela no modo não interativo | Indica que não é possível obter o texto da tela quando no modo não interativo |
| Falha ao criar o mecanismo de OCR | Indica que ocorreu um erro ao tentar criar o mecanismo de OCR |
| A pasta de caminho de dados não existe | Indica que a pasta especificada para os dados do idioma não existe |
| O pacote de idiomas do Windows selecionado não está instalado no computador | O pacote de idiomas do Windows selecionado não está instalado no computador |
| Mecanismo de OCR não ativo | Indica que o mecanismo de OCR não está ativo |