Configurar o Kubernetes em vários computadores para implantações de cluster de Big Data do SQL Server
Aplica-se a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Este artigo fornece um exemplo de como usar kubeadm para configurar o Kubernetes em vários computadores para implantações do Clusters de Big Data do SQL Server. Neste exemplo, vários computadores com Ubuntu 16.04 ou 18.04 LTS (físicos ou virtuais) são o destino. Se você estiver implantando em uma plataforma diferente do Linux, deverá alterar alguns dos comandos para corresponder ao seu sistema.
Dica
Para scripts de exemplo que configuram o Kubernetes, confira Criar um cluster do Kubernetes usando o Kubeadm no Ubuntu 20.04 LTS.
Para ver um script de amostra que automatiza uma implantação de kubeadm de nó único em uma VM e implanta uma configuração padrão de cluster de Big Data sobre ela, confira Implantar um cluster kubeadm de nó único.
Pré-requisitos
- Mínimo de três computadores físicos ou máquinas virtuais com Linux
- Configuração recomendada por computador:
- 8 CPUs
- 64 GB de memória
- 100 GB de armazenamento
Importante
Antes de iniciar a implantação do cluster de Big Data, verifique se os relógios estão sincronizados em todos os nós do Kubernetes que serão destinos da implantação. Como o cluster de Big Data tem propriedades de integridade internas para vários serviços que são sensíveis ao tempo, distorções de relógio podem causar status incorretos.
Preparar os computadores
Em cada computador, há vários pré-requisitos necessários. Em um terminal de Bash, execute os seguintes comandos em cada computador:
Adicione o computador atual ao arquivo
/etc/hosts:echo $(hostname -i) $(hostname) | sudo tee -a /etc/hostsDesabilite a troca em todos os dispositivos.
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -aImporte as chaves e registre o repositório para o Kubernetes.
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.listConfigure os pré-requisitos do Docker e do Kubernetes no computador.
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bashDefina
net.bridge.bridge-nf-call-iptables=1. No Ubuntu 18.04, os comandos a seguir habilitam obr_netfilterprimeiro.. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
Configurar o Kubernetes mestre
Depois de executar os comandos anteriores em cada computador, escolha um dos computadores para ser o Kubernetes mestre. Em seguida, execute os seguintes comandos nesse computador.
Primeiro, crie um arquivo rbac.yaml no diretório atual com o comando a seguir.
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOFInicialize o Kubernetes mestre nesse computador. O script de exemplo abaixo especifica a versão
1.15.0do Kubernetes. A versão usada depende do cluster do Kubernetes.KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSIONVocê deve ver a saída que o Kubernetes mestre foi inicializado com êxito.
Observe o comando
kubeadm joinque você precisa usar nos outros servidores para unir o cluster do Kubernetes. Copie isso para uso posterior.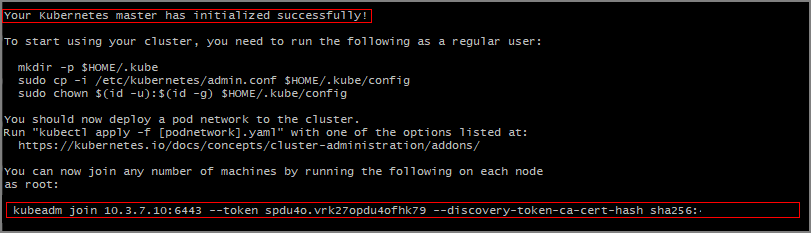
Configure um arquivo de configuração do Kubernetes em seu diretório base.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/configConfigure o cluster e o painel do Kubernetes.
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
Configurar os agentes do Kubernetes
Os outros computadores atuarão como agentes do Kubernetes no cluster.
Em cada um dos outros computadores, execute o comando kubeadm join que você copiou na seção anterior.

Exibir o status do cluster
Para verificar a conexão com o cluster, use o comando kubectl get para retornar uma lista dos nós de cluster.
kubectl get nodes
Próximas etapas
As etapas neste artigo configuraram um cluster do Kubernetes em vários computadores Ubuntu. A próxima etapa é implantar o cluster de Big Data do SQL Server 2019. Para obter instruções, confira o seguinte artigo: