Tutorial: Ingerir dados em um pool de dados do SQL Server com trabalhos do Spark
Aplica-se a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Este tutorial demonstra como usar trabalhos do Spark para carregar dados no pool de dados de um Clusters de Big Data do SQL Server 2019.
Neste tutorial, você aprenderá como:
- Criar uma tabela externa no pool de dados.
- Crie um trabalho do Spark para carregar dados do HDFS.
- Consultar os resultados na tabela externa.
Dica
Se preferir, você poderá baixar e executar um script para os comandos neste tutorial. Para obter instruções, confira os Exemplos de pools de dados no GitHub.
Pré-requisitos
- Ferramentas de Big Data
- kubectl
- Azure Data Studio
- Extensão do SQL Server 2019
- Carregar dados de exemplo em seu cluster de Big Data
Criar uma tabela externa no pool de dados
As etapas a seguir criam uma tabela externa no pool de dados chamado web_clickstreams_spark_results. Essa tabela pode ser usada como uma localização para ingerir dados no cluster de Big Data.
No Azure Data Studio, conecte-se à instância mestre do SQL Server do cluster de Big Data. Para obter mais informações, confira Conectar-se à instância mestre do SQL Server.
Clique duas vezes na conexão na janela Servidores para mostrar o painel do servidor da instância mestre do SQL Server. Selecione Nova Consulta.
Crie permissões para o Conector MSSQL-Spark.
USE Sales CREATE LOGIN sample_user WITH PASSWORD ='<password>' CREATE USER sample_user FROM LOGIN sample_user -- To create external tables in data pools GRANT ALTER ANY EXTERNAL DATA SOURCE TO sample_user; -- To create external tables GRANT CREATE TABLE TO sample_user; GRANT ALTER ANY SCHEMA TO sample_user; -- To view database state for Sales GRANT VIEW DATABASE STATE ON DATABASE::Sales TO sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user ALTER ROLE [db_datawriter] ADD MEMBER sample_userCrie uma fonte de dados externos para o pool de dados se ela ainda não existir.
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlDataPool') CREATE EXTERNAL DATA SOURCE SqlDataPool WITH (LOCATION = 'sqldatapool://controller-svc/default');Crie uma tabela externa chamada web_clickstreams_spark_results no pool de dados.
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_tables WHERE name = 'web_clickstreams_spark_results') CREATE EXTERNAL TABLE [web_clickstreams_spark_results] ("wcs_click_date_sk" BIGINT , "wcs_click_time_sk" BIGINT , "wcs_sales_sk" BIGINT , "wcs_item_sk" BIGINT , "wcs_web_page_sk" BIGINT , "wcs_user_sk" BIGINT) WITH ( DATA_SOURCE = SqlDataPool, DISTRIBUTION = ROUND_ROBIN );Crie um logon para os pools de dados e forneça permissões para o usuário.
EXECUTE( ' Use Sales; CREATE LOGIN sample_user WITH PASSWORD = ''<password>;'') AT DATA_SOURCE SqlDataPool; EXECUTE('Use Sales; CREATE USER sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user; ALTER ROLE [db_datawriter] ADD MEMBER sample_user;') AT DATA_SOURCE SqlDataPool;
A criação da tabela externa do pool de dados é uma operação de bloqueio. O controle retorna quando a tabela especificada foi criada em todos os nós do pool de dados do back-end. Se a falha ocorrer durante a operação de criação, uma mensagem de erro será retornada ao chamador.
Iniciar um trabalho de streaming do Spark
A próxima etapa é criar um trabalho de streaming do Spark que carregue dados de cliques da Web do pool de armazenamento (HDFS) na tabela externa que você criou no pool de dados. Esses dados foram adicionados a /clickstream_data em Carregar dados de exemplo no cluster de Big Data.
No Azure Data Studio, conecte-se à instância mestre do cluster de Big Data. Para obter mais informações, confira Conectar-se a um cluster de Big Data.
Crie um notebook e selecione Spark | Scala como o kernel.
Executar o trabalho de ingestão do Spark
- Configurar os parâmetros do conector Spark-SQL
Observação
Se o cluster de Big Data for implantado com a integração do Active Directory, substitua o valor de nome do host abaixo para incluir o FQDN acrescentado ao nome do serviço. Por exemplo hostname=master-p-svc.<domainName>.
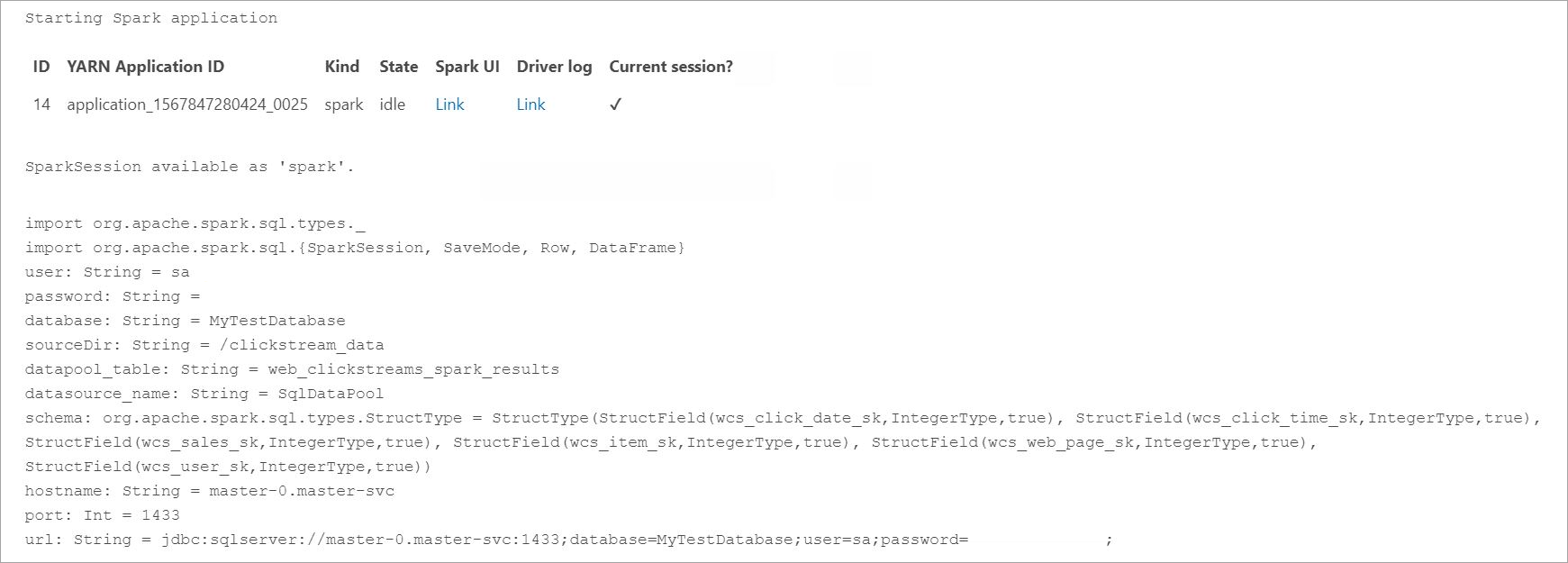
import org.apache.spark.sql.types._ import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} // Change per your installation val user= "username" val password= "<password>" val database = "MyTestDatabase" val sourceDir = "/clickstream_data" val datapool_table = "web_clickstreams_spark_results" val datasource_name = "SqlDataPool" val schema = StructType(Seq( StructField("wcs_click_date_sk",LongType,true), StructField("wcs_click_time_sk",LongType,true), StructField("wcs_sales_sk",LongType,true), StructField("wcs_item_sk",LongType,true), StructField("wcs_web_page_sk",LongType,true), StructField("wcs_user_sk",LongType,true) )) val hostname = "master-p-svc" val port = 1433 val url = s"jdbc:sqlserver://${hostname}:${port};database=${database};user=${user};password=${password};"- Definir e executar o trabalho do Spark
- Cada trabalho tem duas partes: readStream e writeStream. Abaixo, criamos um quadro de dados usando o esquema definido acima e, em seguida, fizemos uma gravação na tabela externa no pool de dados.
import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} val df = spark.readStream.format("csv").schema(schema).option("header", true).load(sourceDir) val query = df.writeStream.outputMode("append").foreachBatch{ (batchDF: DataFrame, batchId: Long) => batchDF.write .format("com.microsoft.sqlserver.jdbc.spark") .mode("append") .option("url", url) .option("dbtable", datapool_table) .option("user", user) .option("password", password) .option("dataPoolDataSource",datasource_name).save() }.start() query.awaitTermination(40000) query.stop()
Consultar os dados
As etapas a seguir mostram que o trabalho de streaming do Spark carregou os dados do HDFS no pool de dados.
Antes de consultar os dados ingeridos, examine o Status de Execução do Spark, incluindo ID do Aplicativo do YARN, Interface do Usuário do Spark e Logs do Driver. Essas informações serão exibidas no notebook quando você iniciar o aplicativo Spark pela primeira vez.
Retorne à janela de consulta da instância mestre do SQL Server que você abriu no início deste tutorial.
Execute a consulta a seguir para inspecionar os dados ingeridos.
USE Sales GO SELECT count(*) FROM [web_clickstreams_spark_results]; SELECT TOP 10 * FROM [web_clickstreams_spark_results];Os dados também podem ser consultados no Spark. Por exemplo, o código abaixo imprime o número de registros na tabela:
def df_read(dbtable: String, url: String, dataPoolDataSource: String=""): DataFrame = { spark.read .format("com.microsoft.sqlserver.jdbc.spark") .option("url", url) .option("dbtable", dbtable) .option("user", user) .option("password", password) .option("dataPoolDataSource", dataPoolDataSource) .load() } val new_df = df_read(datapool_table, url, dataPoolDataSource=datasource_name) println("Number of rows is " + new_df.count)
Limpar
Use o comando a seguir para remover os objetos de banco de dados criados neste tutorial.
DROP EXTERNAL TABLE [dbo].[web_clickstreams_spark_results];
Próximas etapas
Saiba mais sobre como executar um notebook de exemplo no Azure Data Studio: