O que é AutoML?
O ML automatizado é um recurso do Azure Databricks que permite automatizar o treinamento e a avaliação de um modelo de aprendizado de máquina usando diferentes combinações de valores de algoritmo e hiperparâmetro. Ao usar o ML automatizado, você pode reduzir o esforço envolvido em um processo iterativo de treinamento de modelo e criar um modelo ideal para seus dados com mais rapidez.
Como o AutoML funciona?
O ML automatizado funciona gerando várias execuções de experimento, cada uma treinando um modelo usando um algoritmo e uma combinação de hiperparâmetro diferentes. Em cada execução, um modelo é treinado e avaliado com base nos dados e na métrica preditiva especificada. O Azure Databricks controla as execuções e os modelos que produzem usando o MLflow, permitindo que você identifique o modelo de melhor desempenho e implante-o em produção.
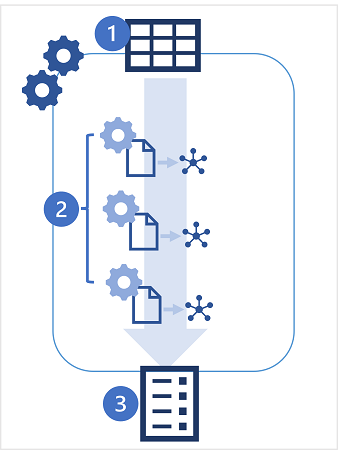
- Você inicia um experimento de ML automatizado, especificando uma tabela no workspace do Azure Databricks como a fonte de dados para treinamento e a métrica de desempenho específica para a qual você deseja otimizar.
- O experimento de ML automatizado gera várias execuções do MLflow, cada uma produzindo um notebook com código para pré-processar os dados antes de treinar e validar um modelo. Os modelos treinados são salvos como artefatos nas execuções ou arquivos do MLflow no repositório DBFS.
- As execuções do experimento são listadas em ordem de desempenho, com os modelos de melhor desempenho mostrados primeiro. Você pode explorar os notebooks que foram gerados para cada execução, escolher o modelo que deseja usar e, em seguida, registrá-lo e implantá-lo.
Dica
Para obter detalhes sobre as transformações de pré-processamento específicas e os algoritmos de treinamento usados pelo ML automatizado, confiraComo o Azure Databricks AutoML funciona na documentação do Azure Databricks.
Preparar dados para o ML automatizado
O AutoML precisa de uma fonte de dados de treinamento que inclua valores de recurso e rótulo. Para fornecer esses dados, crie uma tabela no metastore do Hive no workspace do Azure Databricks.
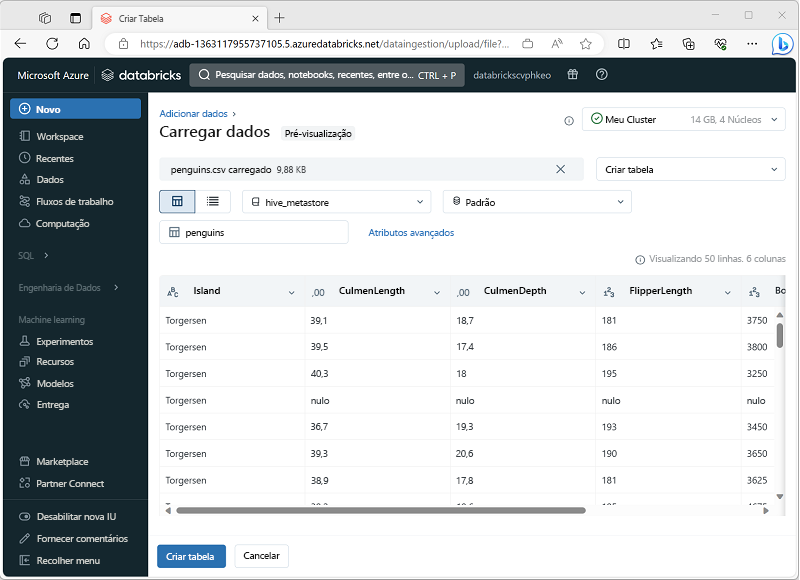
Uma maneira simples de criar uma tabela de dados de treinamento para o ML automatizado é carregar um arquivo de dados no portal do Azure Databricks, conforme mostrado aqui.
O ML automatizado gera código para lidar com tarefas comuns de pré-processamento de dados; como codificar variáveis categóricas, dimensionar variáveis numéricas, lidar com valores nulos e lidar com conjuntos de dados desequilibrados.