Exercício – Monitorar e solucionar problemas de desempenho
Neste exercício, você aprenderá a monitorar e a solucionar um problema de desempenho no SQL do Azure usando ferramentas e funcionalidades novas e conhecidas.
Configuração: Usar scripts para implantar o Banco de Dados SQL do Azure
A sessão do terminal à direita, Azure Cloud Shell, permite que você interaja com o Azure usando um navegador. Para este exercício, você executará um script para criar o ambiente: uma instância do Banco de Dados SQL do Azure com o banco de dados AdventureWorks. (O banco de dados de exemplo AdventureWorksLT menor e mais simples é usado, mas vamos chamá-lo de AdventureWorks para evitar confusão). No script, será solicitado que você insira uma senha e o endereço IP local para permitir que o dispositivo se conecte ao banco de dados.
Esse script leva de 3 a 5 minutos para ser concluído. Não deixe de anotar a senha, a ID exclusiva e a região. Elas não serão mostradas novamente.
Comece obtendo o endereço IP local. Verifique se você está desconectado de qualquer serviço de VPN e abra um terminal do PowerShell local no dispositivo. Execute o comando a seguir e anote o endereço IP resultante:
(Invoke-WebRequest -Uri "https://ipinfo.io/ip").ContentNo Azure Cloud Shell à direita, insira o código a seguir e, quando solicitado, forneça uma senha complexa e seu endereço IP público local recuperado na etapa anterior. Pressione Enter para executar a última linha do script.
$adminSqlLogin = "cloudadmin" $password = Read-Host "Your username is 'cloudadmin'. Please enter a password for your Azure SQL Database server that meets the password requirements" # Prompt for local ip address $ipAddress = Read-Host "Disconnect your VPN, open PowerShell on your machine and run '(Invoke-WebRequest -Uri "https://ipinfo.io/ip").Content'. Please enter the value (include periods) next to 'Address':" # Get resource group and location and random string $resourceGroup = Get-AzResourceGroup | Where ResourceGroupName -like "<rgn>Sandbox resource group name</rgn>" $resourceGroupName = "<rgn>Sandbox resource group name</rgn>" $uniqueID = Get-Random -Minimum 100000 -Maximum 1000000 $storageAccountName = "mslearnsa"+$uniqueID $location = $resourceGroup.Location $serverName = "aw-server$($uniqueID)"Execute o script a seguir no Azure Cloud Shell. Salve a saída; você precisará dessas informações em todo o módulo. Pressione Enter depois de colar o código, para que a última linha de código imprima a saída de que você precisa.
Write-Host "Please note your unique ID for future exercises in this module:" Write-Host $uniqueID Write-Host "Your resource group name is:" Write-Host $resourceGroupName Write-Host "Your resources were deployed in the following region:" Write-Host $location Write-Host "Your server name is:" Write-Host $serverNameDica
Salve a saída e anote a senha, a ID exclusiva e o servidor. Você precisará dessas informações ao longo do módulo.
Execute o script a seguir para implantar uma instância do Banco de Dados SQL do Azure e um servidor lógico com o exemplo de
AdventureWorks. Esse script adiciona seu endereço IP como uma regra de firewall, habilita a Segurança de Dados Avançada e cria uma conta de armazenamento para uso nos exercícios restantes deste módulo. O script pode levar vários minutos para ser concluído e pausar várias vezes. Aguarde um prompt de comando.# The logical server name has to be unique in the system $serverName = "aw-server$($uniqueID)" # The sample database name $databaseName = "AdventureWorks" # The storage account name has to be unique in the system $storageAccountName = $("sql$($uniqueID)") # Create a new server with a system wide unique server name $server = New-AzSqlServer -ResourceGroupName $resourceGroupName ` -ServerName $serverName ` -Location $location ` -SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $adminSqlLogin, $(ConvertTo-SecureString -String $password -AsPlainText -Force)) # Create a server firewall rule that allows access from the specified IP range and all Azure services $serverFirewallRule = New-AzSqlServerFirewallRule ` -ResourceGroupName $resourceGroupName ` -ServerName $serverName ` -FirewallRuleName "AllowedIPs" ` -StartIpAddress $ipAddress -EndIpAddress $ipAddress $allowAzureIpsRule = New-AzSqlServerFirewallRule ` -ResourceGroupName $resourceGroupName ` -ServerName $serverName ` -AllowAllAzureIPs # Create a database $database = New-AzSqlDatabase -ResourceGroupName $resourceGroupName ` -ServerName $serverName ` -DatabaseName $databaseName ` -SampleName "AdventureWorksLT" ` -Edition "GeneralPurpose" -Vcore 2 -ComputeGeneration "Gen5" # Enable Advanced Data Security $advancedDataSecurity = Enable-AzSqlServerAdvancedDataSecurity ` -ResourceGroupName $resourceGroupName ` -ServerName $serverName # Create a Storage Account $storageAccount = New-AzStorageAccount -ResourceGroupName $resourceGroupName ` -AccountName $storageAccountName ` -Location $location ` -Type "Standard_LRS"No dispositivo local, abra o SSMS (SQL Server Management Studio) para criar uma conexão com o servidor lógico.
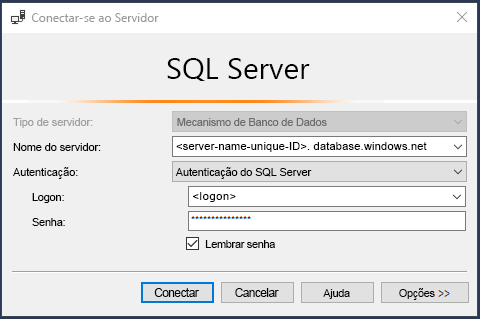
Na caixa de diálogo de logon da conexão com o servidor, forneça as seguintes informações:
Campo Valor Tipo de servidor Mecanismo de Banco de Dados (padrão). Nome do servidor O $serverName retornado no Cloud Shell, mais o restante do URI. Por exemplo: aw-server <unique ID>.database.windows.net.Autenticação Autenticação do SQL Server (padrão). Logon cloudadmin O adminSqlLogin atribuído na etapa 1 deste exercício. Senha A senha que você forneceu na etapa 1 deste exercício. Lembrar senha checked Selecione Conectar.
Observação
Dependendo da sua configuração local (por exemplo, VPN), o endereço IP do cliente pode ser diferente do endereço IP que o portal do Azure usou durante a implantação. Se for, você receberá a seguinte mensagem: "O endereço IP do cliente não tem acesso ao servidor. Entre em uma conta do Azure e crie uma regra de firewall para permitir o acesso". Se receber essa mensagem, entre com a conta usada para a área restrita e adicione uma regra de firewall para o endereço IP do cliente. Você pode concluir todas essas etapas usando o assistente no SSMS.
Preparar o exercício carregando e editando os scripts
Você pode encontrar todos os scripts deste exercício na pasta 04-Performance\monitor_and_scale no repositório GitHub clonado ou no arquivo zip que você baixou. Vamos preparar o exercício carregando e editando os scripts.
No SSMS, no Pesquisador de Objetos, expanda a pasta Bancos de Dados e selecione o banco de dados AdventureWorks.
Selecione Arquivo>Abrir>Arquivo e abra o script dmexecrequests.sql. A janela do editor de consultas deverá ser semelhante ao seguinte texto:
SELECT er.session_id, er.status, er.command, er.wait_type, er.last_wait_type, er.wait_resource, er.wait_time FROM sys.dm_exec_requests er INNER JOIN sys.dm_exec_sessions es ON er.session_id = es.session_id AND es.is_user_process = 1;Use o mesmo método no SSMS para carregar o script dmdbresourcestats.sql. Uma nova janela do editor de consultas deverá ser semelhante ao seguinte texto:
SELECT * FROM sys.dm_db_resource_stats;Essa DMV (exibição de gerenciamento dinâmico) rastreará o uso geral de recursos de sua carga de trabalho no Banco de Dados SQL do Azure. Por exemplo, ela rastreia a CPU, a E/S e a memória.
Abra e edite o script sqlworkload.cmd (que usará o programa ostress.exe).
- Substitua a
unique_idsalva do script de implantação pelo nome do servidor. - Substitua a senha de que você usou para entrar no servidor do Banco de Dados SQL do Azure pelo
-P parameter. - Salve as alterações no script.
- Substitua a
Executar a carga de trabalho
Nesta tarefa, você executará uma carga de trabalho em uma consulta T-SQL para observar seu desempenho simulando usuários simultâneos.
Use o SSMS para abrir o arquivo de script topcustomersales.sql e observar a consulta. Você não executará a consulta do SSMS. A janela do editor de consultas deverá ser semelhante ao seguinte texto:
DECLARE @x int DECLARE @y float SET @x = 0; WHILE (@x < 10000) BEGIN SELECT @y = sum(cast((soh.SubTotal*soh.TaxAmt*soh.TotalDue) as float)) FROM SalesLT.Customer c INNER JOIN SalesLT.SalesOrderHeader soh ON c.CustomerID = soh.CustomerID INNER JOIN SalesLT.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID INNER JOIN SalesLT.Product p ON p.ProductID = sod.ProductID GROUP BY c.CompanyName ORDER BY c.CompanyName; SET @x = @x + 1; END GOEste banco de dados é pequeno. A consulta para recuperar uma lista de clientes e as informações de vendas associadas, ordenadas segundo os clientes com mais vendas, não deverá gerar um conjunto de resultados grande. Você pode ajustar essa consulta reduzindo o número de colunas no conjunto de resultados, mas elas são necessárias para fins de demonstração neste exercício.
Em um prompt de comando do PowerShell, digite o seguinte comando para mover para o diretório correto para este exercício. Substitua
<base directory>pela sua ID de usuário e o caminho para este módulo:cd <base directory>\04-Performance\monitor_and_scaleExecute a carga de trabalho com o seguinte comando:
.\sqlworkload.cmdEsse script usará 10 usuários simultâneos executando a consulta de carga de trabalho duas vezes. Observe que o script em si executa apenas um lote, mas executa um loop 10.000 vezes. Ele também atribuiu o resultado a uma variável, eliminando assim quase todo o tráfego do conjunto de resultados para o cliente. Isso não é necessário, mas ajuda a mostrar uma execução carga de trabalho de CPU "pura" totalmente no servidor.
Dica
Se não estiver vendo o comportamento de uso da CPU com essa carga de trabalho em seu ambiente, ajuste o
-n parameterpara o número de usuários e o-r parameterpara as iterações.A saída no prompt de comando deverá ser semelhante à seguinte saída:
[datetime] [ostress PID] Max threads setting: 10000 [datetime] [ostress PID] Arguments: [datetime] [ostress PID] -S[server].database.windows.net [datetime] [ostress PID] -isqlquery.sql [datetime] [ostress PID] -U[user] [datetime] [ostress PID] -dAdventureWorks [datetime] [ostress PID] -P******** [datetime] [ostress PID] -n10 [datetime] [ostress PID] -r2 [datetime] [ostress PID] -q [datetime] [ostress PID] Using language id (LCID): 1024 [English_United States.1252] for character formatting with NLS: 0x0006020F and Defined: 0x0006020F [datetime] [ostress PID] Default driver: SQL Server Native Client 11.0 [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_1.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_2.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_3.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_4.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_5.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_6.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_7.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_8.out] [datetime] [ostress PID] Attempting DOD5015 removal of [directory]\sqlquery_9.out] [datetime] [ostress PID] Starting query execution... [datetime] [ostress PID] BETA: Custom CLR Expression support enabled. [datetime] [ostress PID] Creating 10 thread(s) to process queries [datetime] [ostress PID] Worker threads created, beginning execution...
Observar o desempenho da carga de trabalho
Vamos usar as consultas de DMV carregadas anteriormente para observar o desempenho.
Execute a consulta no SSMS que você carregou para monitorar
dm_exec_requests(dmexecrequests.sql) e observar as solicitações ativas. Execute a consulta cinco ou seis vezes e observe alguns dos resultados:SELECT er.session_id, er.status, er.command, er.wait_type, er.last_wait_type, er.wait_resource, er.wait_time FROM sys.dm_exec_requests er INNER JOIN sys.dm_exec_sessions es ON er.session_id = es.session_id AND es.is_user_process = 1;Você deve ver que muitas das solicitações têm um status de
RUNNABLE, elast_wait_typeéSOS_SCHEDULER_YIELD. Um indicador de muitas solicitaçõesRUNNABLEe muitas esperasSOS_SCHEDULER_YIELDé uma possível falta de recursos de CPU para consultas ativas.Observação
Você pode ver uma ou mais solicitações ativas com um comando
SELECTe umwait_typedeXE_LIVE_TARGET_TVF. Essas são consultas executadas por serviços gerenciados pela Microsoft. Elas ajudam com recursos como insights de desempenho usando eventos estendidos. A Microsoft não publica os detalhes dessas sessões.Deixe essa janela do editor de consultas aberta. Você o executará novamente no próximo exercício.
Execute a consulta no SSMS que você carregou para monitorar sys.dm_db_resource_stats (dmdbresourcestats.sql). Execute a consulta para ver os resultados dessa DMV três ou quatro vezes.
SELECT * FROM sys.dm_db_resource_stats;Essa DMV registra um instantâneo do uso de recursos do banco de dados a cada 15 segundos (mantidos por 1 hora). Você deverá ver a coluna avg_cpu_percent perto de 100% em vários instantâneos. Esse é um sintoma de que uma carga de trabalho está pressionando os limites de recursos da CPU para o banco de dados.
Em um ambiente local do SQL Server, normalmente você usaria uma ferramenta específica do sistema operacional para rastrear o uso geral de recursos, como de uma CPU. Por exemplo, você pode usar o Monitor de Desempenho do Windows para essa finalidade. Se você executou este exemplo em um SQL Server local ou no SQL Server em uma máquina virtual com duas CPUs, verá quase 100% de utilização da CPU no servidor.
Observação
Você pode executar outra DMV,
sys.resource_stats, no contexto do banco de dadosmasterdo servidor do Banco de Dados SQL do Azure para ver o uso de recursos de todos os bancos de dados do Banco de Dados SQL do Azure associados ao servidor. Essa exibição é menos granular e mostra o uso de recursos a cada cinco minutos (mantidas por 14 dias).Deixe essa janela do editor de consultas aberta. Você o executará novamente no próximo exercício.
Deixe a carga de trabalho ser concluída e anote sua duração geral. Quando a carga de trabalho for concluída, você verá resultados como a seguinte saída e um retorno para o prompt de comando:
[datetime] [ostress PID] Total IO waits: 0, Total IO wait time: 0 (ms) [datetime] [ostress PID] OSTRESS exiting normally, elapsed time: 00:01:22.637A duração pode variar, mas normalmente leva pelo menos de 1 a 3 minutos. Aguarde a conclusão da execução. Quando a carga de trabalho for concluída, você será levado de volta ao prompt de comando.
Usar o Repositório de Consultas para análise adicional
O Repositório de Consultas é uma capacidade no SQL Server para rastrear o desempenho da execução de consultas. Dados de desempenho são armazenados no banco de dados do usuário. O Repositório de Consultas não fica habilitado por padrão para bancos de dados criados no SQL Server, mas fica ativado por padrão para o Banco de Dados SQL do Azure (e a Instância Gerenciada de SQL do Azure).
O Repositório de Consultas conta com uma série de exibições de catálogo do sistema para exibir dados de desempenho. O SSMS fornece relatórios usando essas exibições.
Usando o Pesquisador de Objetos no SSMS, abra a pasta Repositório de Consultas para localizar o relatório de Principais Consultas de Consumo de Recursos.
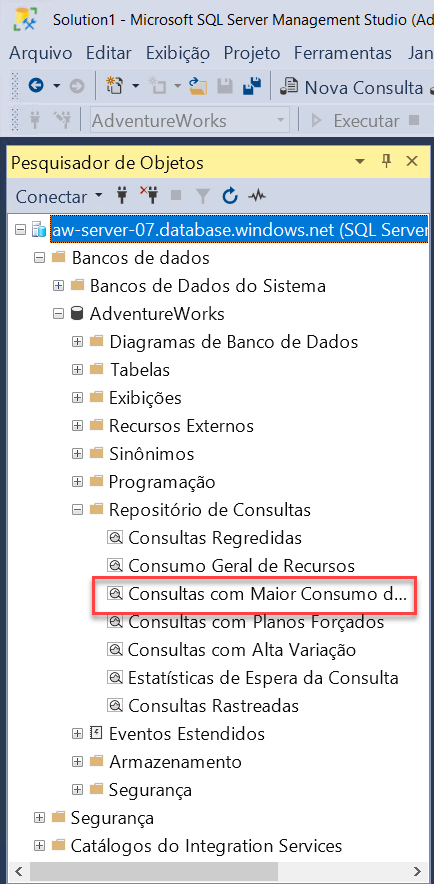
Selecione o relatório para descobrir quais consultas consumiram mais recursos em média, bem como os detalhes de execução dessas consultas. Com base na carga de trabalho executada até esse ponto, o relatório deverá ser semelhante à seguinte imagem:
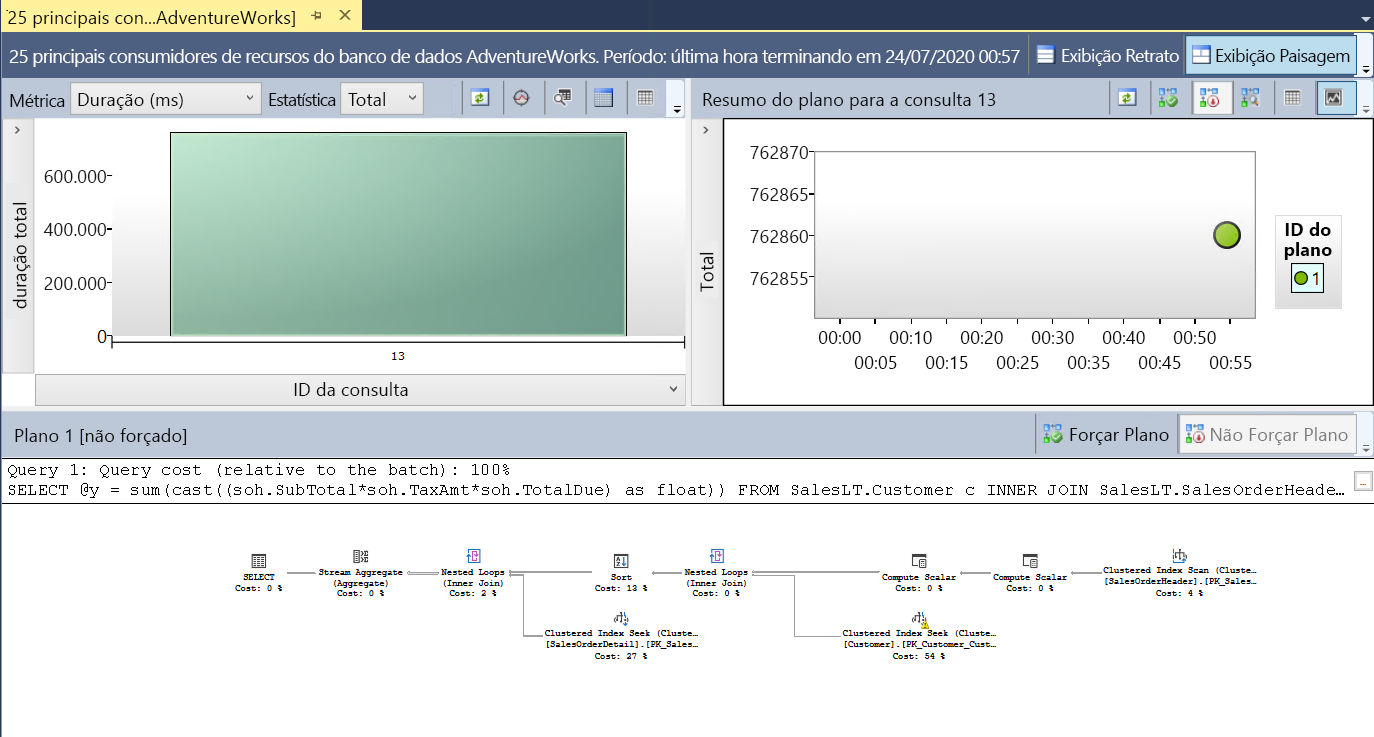
A consulta mostrada é a consulta SQL da carga de trabalho de vendas do cliente. Esse relatório tem três componentes: consultas com duração total alta (você pode alterar a métrica), as estatísticas do runtime e do plano de consulta associados e o plano de consulta associado em um mapa visual.
Selecione o gráfico de barras da consulta (o
query_idpode ser diferente para seu sistema). Os resultados deverão ser semelhantes a esta imagem: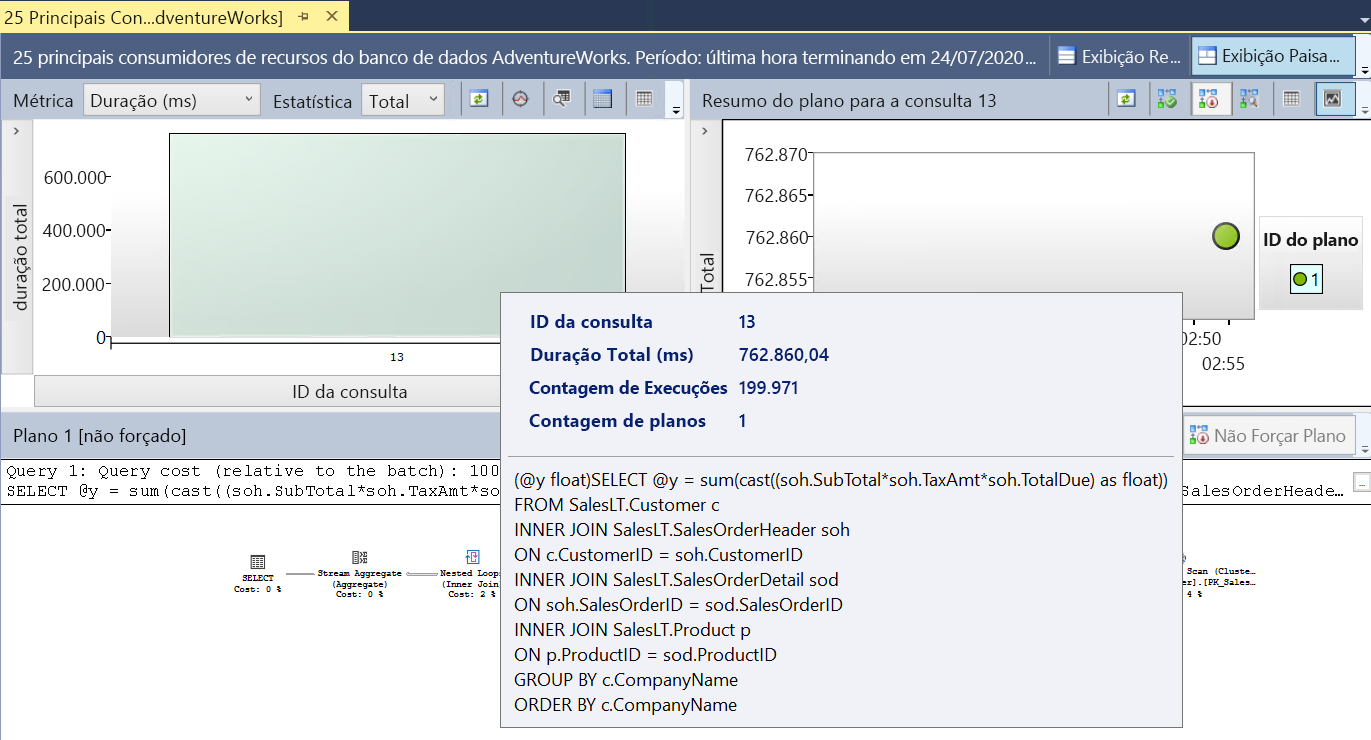
Você pode ver a duração total da consulta e do texto da consulta.
À direita desse gráfico de barras, há um gráfico com as estatísticas do plano de consulta associado à consulta. Passe o mouse sobre o ponto associado ao plano. Os resultados deverão ser semelhantes a esta imagem:
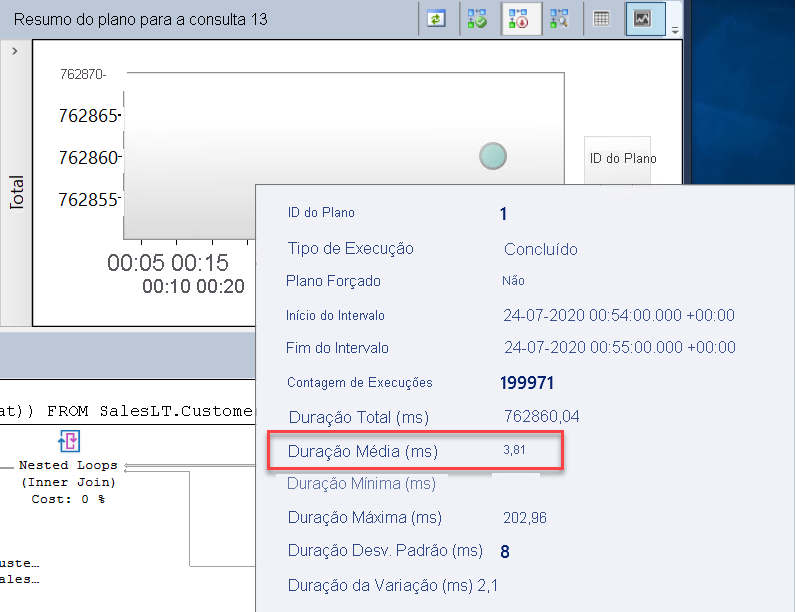
Observe a duração média da consulta. Os períodos podem variar, mas compare essa duração média com o tempo de espera médio da consulta. Posteriormente, introduziremos uma melhoria de desempenho e você fará essa comparação novamente para ver a diferença.
O componente final é o plano de consulta visual. O plano dessa consulta é semelhante à seguinte imagem:
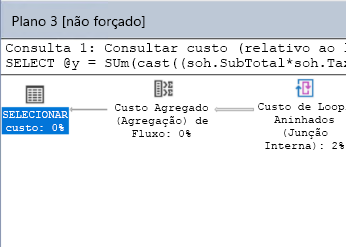
Essa tabela do banco de dados tem poucas linhas que não precisam de um plano; isto pode ser ineficiente. O ajuste da consulta não melhorará o desempenho de maneira que possa ser mensurável. Você poderá ver um aviso no plano relacionado à falta de estatísticas de uma das colunas da busca do índice clusterizado. Isso não afeta o desempenho geral.
Após o relatório Consultas que consomem mais recursos no SSMS, há um relatório chamado Estatísticas de espera da consulta. Você sabe com base em diagnósticos anteriores que um grande número de solicitações estava constantemente com status RUNNABLE, juntamente com quase 100% da CPU. O Repositório de Consultas fornece relatórios para examinar possíveis gargalos de desempenho decorrentes de esperas por recursos. Selecione esse relatório e passe o mouse sobre o gráfico de barras. Os resultados deverão ser semelhantes a esta imagem:
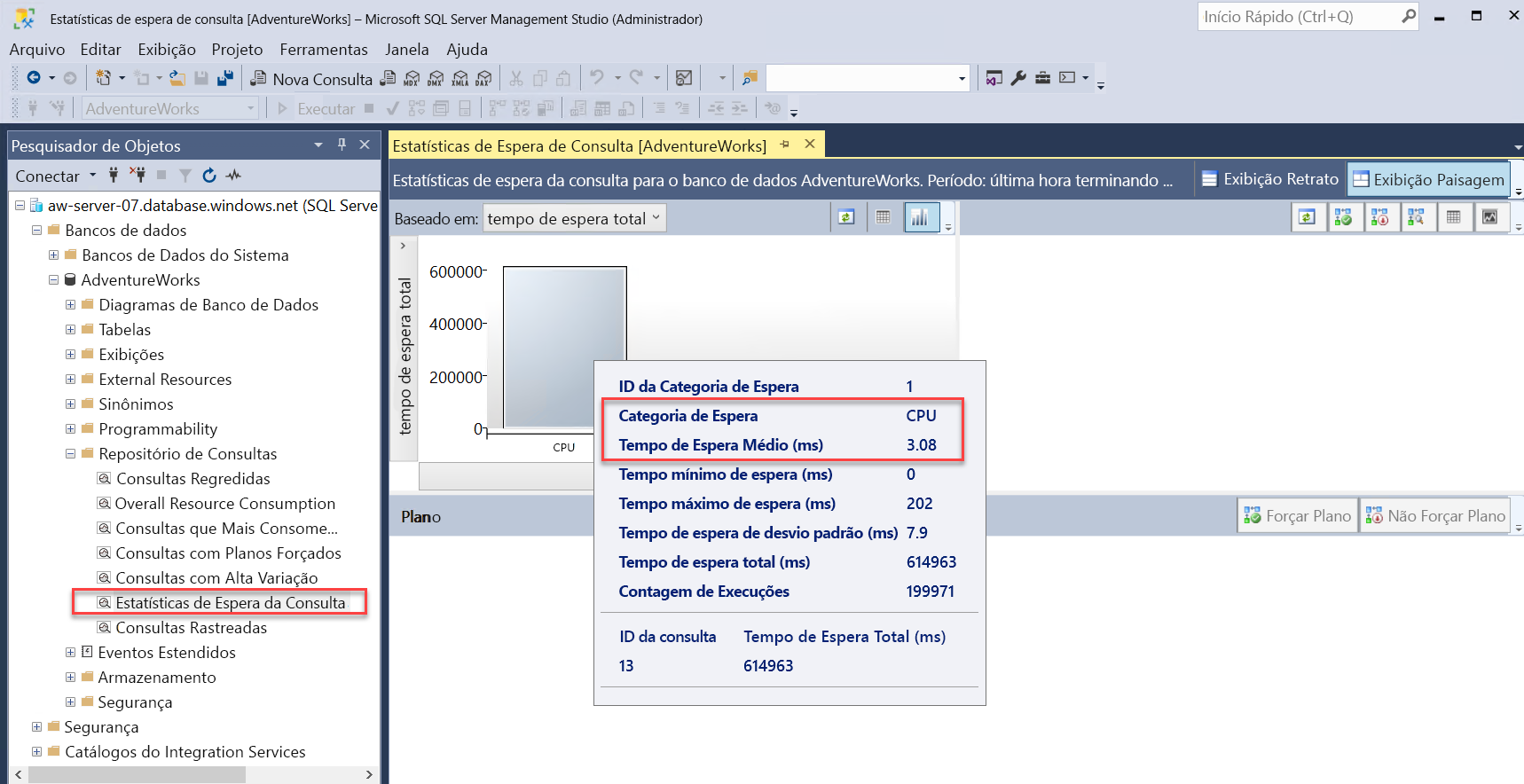
Você pode ver que a principal categoria de espera é a CPU (é equivalente ao
wait_typeSOS_SCHEDULER_YIELD, que pode ser visto emsys.dm_os_wait_stats), bem como o tempo de espera médio.Selecione o gráfico de barras da CPU no relatório. A principal consulta aguardando a CPU é a consulta da carga de trabalho que você está usando.

Observe que o tempo de espera médio pela CPU nessa consulta é um alto percentual da duração média geral da consulta.
Considerando as evidências, sem nenhum ajuste de consulta, nossa carga de trabalho requer mais capacidade de CPU do que implantamos para nossa instância do Banco de Dados SQL do Azure.
Feche os dois Repositórios de Consultas. Você usará os mesmos relatórios no próximo exercício.



Observar o desempenho com o Azure Monitor
Vamos usar outro método para exibir o uso de recursos de nossa carga de trabalho. O Azure Monitor fornece métricas de desempenho que você pode exibir de várias maneiras, incluindo o portal do Azure.
Abra o portal do Azure e, em seguida, localize sua instância do banco de dados SQL AdventureWorks. No painel Visão geral do banco de dados, selecione a guia Monitoramento. A exibição padrão no painel Monitoramento é Utilização de Computação:
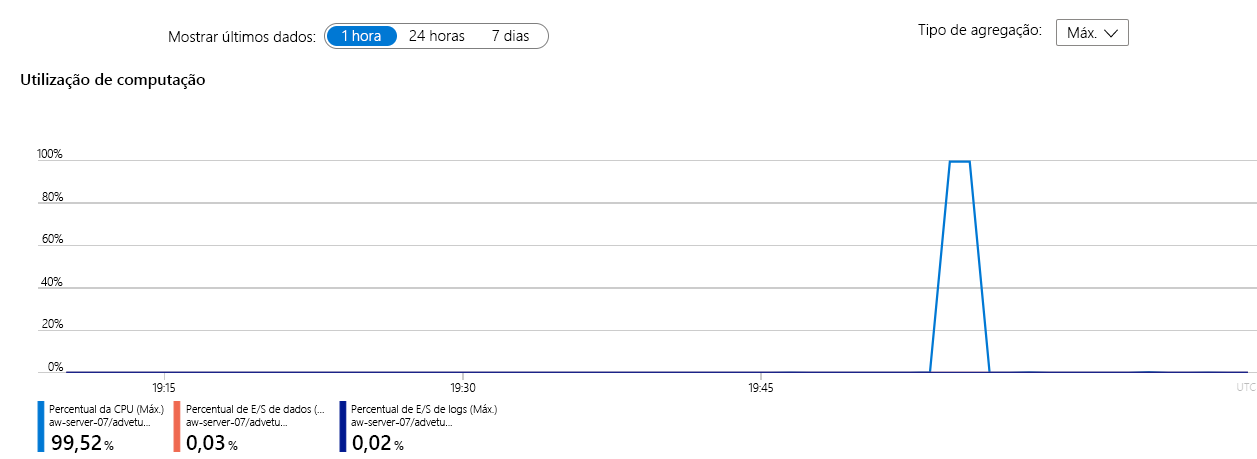
Neste exemplo, o percentual da CPU está quase em 100% em um intervalo de tempo recente. Esse gráfico mostra o uso de recursos (CPU e E/S são os padrões) na última hora e é atualizado continuamente. Selecione o gráfico para personalizá-lo e examinar o uso de outros recursos.
No menu do banco de dados SQL, selecione Adicionar métrica. Outra maneira de exibir as métricas de Utilização de Computação e outras métricas que são coletadas automaticamente pelo Azure Monitor para o Banco de Dados SQL do Azure é usar o Metrics Explorer.
Observação
Utilização de Computação é uma exibição predefinida do Metrics Explorer. Se você selecionar a lista suspensa Métrica na janela Adicionar métricas, verá os seguinte resultados:
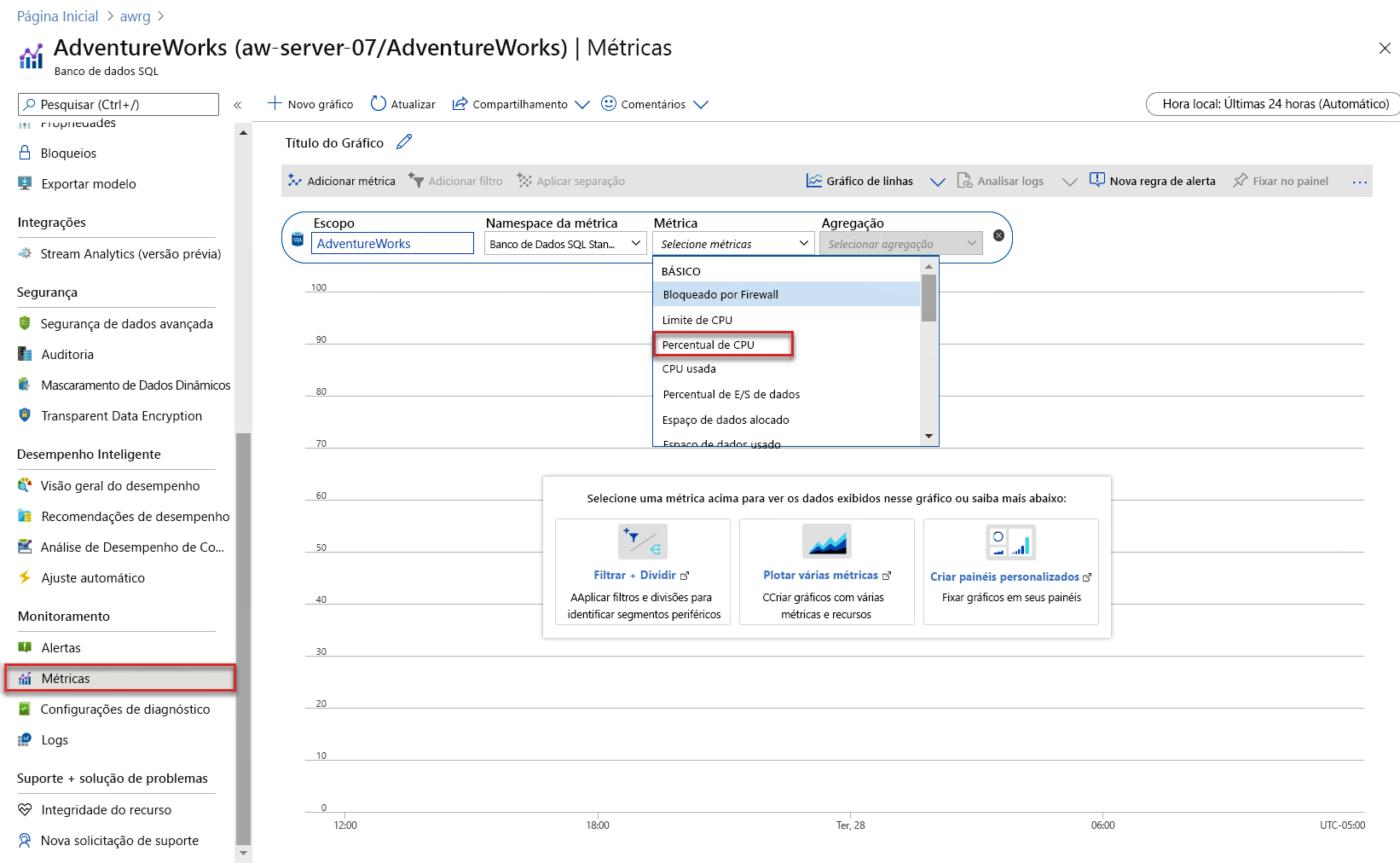
Como mostrado na captura de tela, várias métricas podem ser usadas para exibição no Metrics Explorer. A exibição padrão do Metrics Explorer é referente a um período de 24 horas, com granularidade de cinco minutos. A exibição Utilização de Computação é da última hora, com uma granularidade de um minuto (que você pode alterar). Para ver a mesma exibição, selecione Percentual de CPU e altere a captura para uma hora. A granularidade será alterada para um minuto e deverá ser parecida com a seguinte imagem:

O padrão é um gráfico de linhas, mas a exibição do Explorer permite alterar o tipo de gráfico. O Metrics Explorer tem muitas opções, incluindo a capacidade de mostrar várias métricas no mesmo gráfico.

Logs do Azure Monitor
Neste exercício, você não configurou um log do Azure Monitor, mas vale a pena ver qual seria a aparência de um log em um cenário de uso de recursos de CPU. Os logs do Azure Monitor podem fornecer um registro histórico muito mais longo do que as Métricas do Azure.
Se tivesse configurado os logs do Azure Monitor com um workspace do Log Analytics, você poderia usar a seguinte consulta Kusto para ver os mesmos resultados de utilização da CPU para o banco de dados:
AzureMetrics
| where MetricName == 'cpu_percent'
| where Resource == "ADVENTUREWORKS"
| project TimeGenerated, Average
| render columnchart
Os resultados seriam semelhantes a esta imagem:
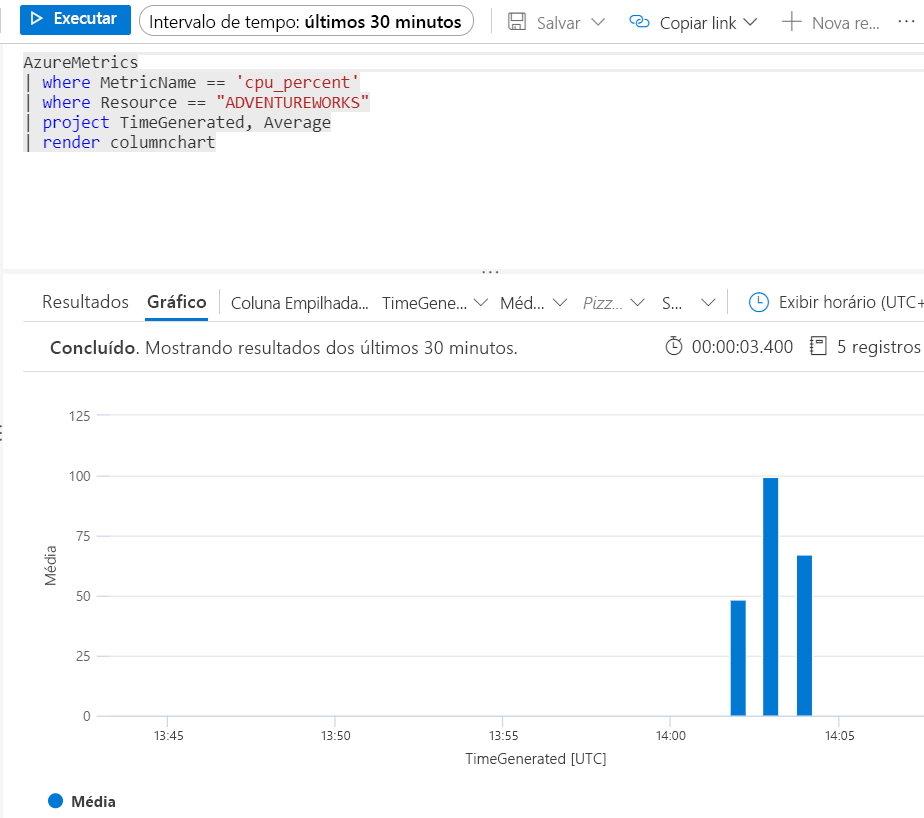
Os logs do Azure Monitor têm um atraso quando você configura pela primeira vez o diagnóstico de log de um banco de dados, de modo que esses resultados podem levar algum tempo para ser exibidos.
Neste exercício, você aprendeu a observar um cenário de desempenho de SQL Server comum e a aprofundar-se nos detalhes para decidir quanto a uma possível solução para aprimorar o desempenho. Na próxima unidade, você aprenderá os métodos usados para acelerar e ajustar o desempenho.