Criar uma arquitetura de dados geograficamente distribuídos
A parte final do design arquitetônico do nosso aplicativo a ser considerada é a camada de armazenamento de dados. Queremos verificar se os dados são legíveis e graváveis com funcionalidade completa após uma falha em toda a região.
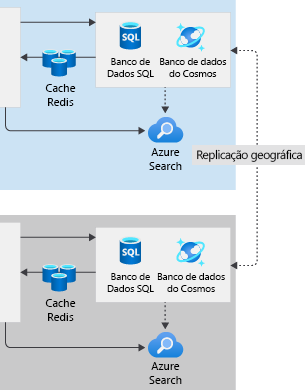
No portal de acompanhamento de envio, optamos por usar o Azure Front Door para enviar todas as solicitações para os Serviços de Aplicativos na região Leste dos EUA. Se a região Leste dos EUA falha, o Front Door detecta a falha e envia solicitações para componentes duplicados dos Serviços de Aplicativos na região Oeste dos EUA. Em nossa arquitetura original e de região única, armazenamos os dados relacionais no Banco de Dados SQL do Azure e em dados semiestruturados no Cosmos DB. Agora desejamos entender como podemos garantir que os dois bancos de dados continuem disponíveis se a região Leste dos EUA falhar.
Aqui, aprendemos a replicar dados entre regiões e a verificar se o failover pode ocorrer rapidamente, se necessário.
Banco de Dados SQL do Azure
Para criar uma implementação de várias regiões do Banco de Dados SQL do Azure para armazenar dados relacionais, podemos usar:
- Replicação geográfica ativa
- Grupos de failover automático
Replicação geográfica ativa
O Banco de Dados SQL do Azure pode replicar automaticamente um banco de dados e todas as suas alterações de um banco de dados para outro com o recurso de replicação geográfica ativa. Somente os hosts de servidor lógico primário hospedam uma cópia gravável do banco de dados. Podemos criar até quatro outros servidores lógicos que hospedam cópias somente leitura do banco de dados.
Para o portal de acompanhamento de envio, crie um banco de dados secundário na região Oeste dos EUA e configure uma replicação geográfica da região Leste dos EUA. Quando uma falha regional ocorre, o Front Door redireciona solicitações de usuário a Serviços de Aplicativos na região Oeste dos EUA. Os Serviços de Aplicativos e o Azure Functions podem acessar os dados relacionais porque uma cópia já foi replicada para a região Oeste dos EUA.
Essa alteração é automática, mas lembre-se de que o banco de dados secundário na região Oeste dos EUA é somente leitura. Se um usuário tentar modificar dados, por exemplo, criando um envio, poderão surgir erros. Podemos iniciar manualmente um failover na região Oeste dos EUA assim que observarmos o problema no portal do Azure. Se desejarmos automatizar esse processo, nossos desenvolvedores poderão escrever código que chama o método failover na API REST do Banco de Dados SQL do Azure.
Observação
As instâncias gerenciadas do Banco de Dados SQL do Azure não dão suporte à replicação geográfica ativa. As instâncias gerenciadas são projetadas para simplificar a migração de dados de um SQL Server local enquanto mantém a segurança. Se você usa uma instância gerenciada, considere usar grupos de failover opcionalmente.
Grupos de failover automático
Um grupo de failover automático é um grupo de bancos de dados em que os dados são replicados automaticamente de um servidor primário para um ou mais servidores secundários. Esse design é como a replicação geográfica ativa e usa o mesmo método de replicação de dados. No entanto, podemos automatizar a resposta a uma falha definindo uma política.
Para o portal de envio, criamos um banco de dados secundário na região Oeste dos EUA. Adicionamos uma política que faz failover da réplica primária do banco de dados para a região Oeste dos EUA se ocorre uma falha catastrófica na região Leste dos EUA. Se isso acontecer, a réplica da região Oeste dos EUA automaticamente se tornará o banco de dados primário gravável e a funcionalidade completa será mantida.
Considere usar um grupo de failover automático se desejar automatizar o failover do banco de dados gravável sem escrever código personalizado para dispará-lo. Além disso, use grupos de failover automático se seu banco de dados é executado em uma instância gerenciada do Banco de Dados SQL do Azure.
Importante
A replicação subjacente aos grupos de replicação geográfica e de failover automático é assíncrona. Uma confirmação é enviada para o cliente quando uma alteração é aplicada à réplica primária. Neste ponto, a transação é considerada concluída e a replicação ocorre. Se ocorrer uma falha, as últimas alterações feitas no banco de dados primário poderão não ter sido replicadas para o secundário. Tenha em mente que, após um desastre, as alterações mais recentes no banco de dados poderão ser perdidas.
Azure Cosmos DB
Nossa configuração é menos complexa com o Azure Cosmos DB porque ela foi projetada como um sistema de banco de dados de nuvem multirregional. O Cosmos DB são vários modelos de banco de dados, capaz de armazenar dados relacionais e semiestruturados e outras formas de dados. Mesmo se executamos o Cosmos DB em uma única região, os dados são replicados para várias instâncias entre domínios de falha diferentes para obter a melhor disponibilidade.
Quando criamos várias regiões de conta do Cosmos DB, podemos escolher entre os seguintes modos:
As contas de várias regiões com várias regiões de gravação.
Nesse modo, todas as cópias do banco de dados são sempre graváveis. Se uma região falhar, nenhum failover será necessário.
Contas de várias regiões com uma única região de gravação.
Nesse modo, apenas a região primária contém bancos de dados graváveis. Os dados replicados para as regiões secundárias são somente leitura. As atualizações são desabilitadas por padrão quando a região primária falha. No entanto, podemos selecionar habilitar failover automático para que o Cosmos DB faça failover automaticamente por meio da copa gravável primária do banco de dados para outra região.
Importante
No Cosmos DB, a replicação de dados é síncrona. Quando uma alteração é aplicada, a transação não é considerada concluída até que seja replicada para um quorum de réplicas. Em seguida, uma confirmação é enviada para o cliente. Quando ocorre uma falha, nenhuma alteração recente é perdida porque a replicação já ocorreu.