Determinar as necessidades de escala do servidor do Banco de Dados do Azure para MySQL
Quando se trata de dimensionar recursos de computação, considere se o uso existente e previsto está dentro da capacidade. Você pode obter as informações necessárias monitorando métricas básicas de desempenho, como utilização de CPU e RAM. Talvez seja possível usar o log de consultas lentas para identificar e otimizar consultas com desempenho ruim e corrigir o problema de desempenho sem dimensionar o tamanho da computação. Você também deve monitorar o desempenho de E/S para garantir que as leituras e gravações do banco de dados não sejam um gargalo de desempenho. Outra opção para aumentar efetivamente a capacidade disponível no banco de dados principal é provisionar uma réplica de leitura para deslocar a carga da consulta.
Monitorar as métricas de desempenho do banco de dados
O portal do Azure apresenta acesso a um número de métricas que você pode usar para monitorar o desempenho do banco de dados. Por exemplo, você pode visualizar o percentual de CPU usado por um servidor flexível.

À medida que a utilização da CPU se aproxima de 100%, o desempenho do banco de dados degrada severamente. Como resultado, se a utilização da CPU em seu servidor flexível estiver consistentemente acima de 50%, considere aumentar o tamanho da computação.
Você pode exibir suas métricas de desempenho na pasta de trabalho de visão geral do monitoramento. Para acessar a pasta de trabalho de visão geral, execute estas etapas:
No portal do Azure, no painel esquerdo, em Monitoramento para sua instância de servidor flexível do Banco de Dados do Azure para MySQL, selecione Pastas de trabalho.
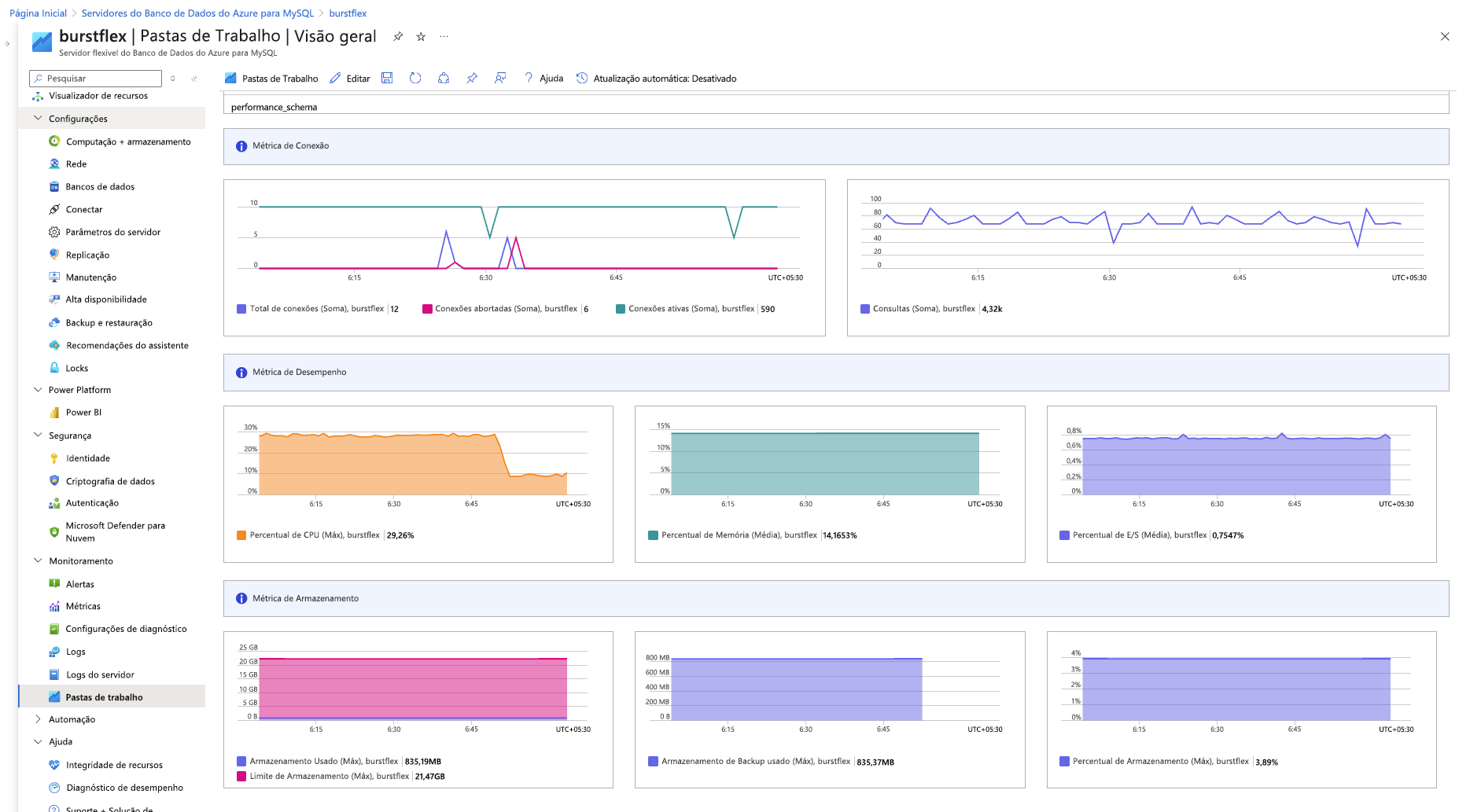
Selecione a pasta de trabalho Visão geral. Você verá gráficos mostrando conexões, uso de CPU e memória, e outras métricas, como mostrado na captura de tela a seguir.


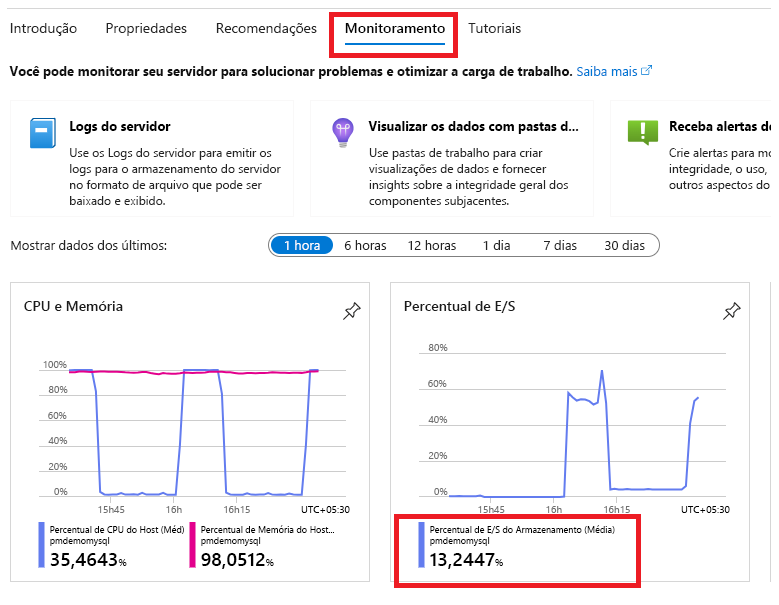
Além de analisar essas métricas, você pode exibir o diagnóstico do servidor para obter informações sobre o desempenho no painel Logs do servidor flexível.

Além dessas métricas e logs, você também pode monitorar o Log de consultas lentas para capturar detalhes sobre consultas de execução longa. Essas informações podem revelar consultas lentas existentes para otimização e você pode configurar alertas para detectar imediatamente futuras regressões de desempenho de consulta para mitigação.
Para habilitar o recurso de log de consulta lenta, na página associada ao servidor flexível, selecione Logs do servidore, em seguida, marque as caixas de seleção "Habilitar" e "Logs de consulta lenta".

Após habilitar o registro de consultas lentas, você poderá exibir insights sobre o desempenho das consultas usando a análise de logs ou workbooks. Para acessar os insights de desempenho de consulta, siga as mesmas etapas acima, mas selecione Insights de Desempenho de Consulta em vez de Visão Geral.
Você verá várias visualizações, incluindo as cinco consultas mais longas ou um resumo de consultas lentas, conforme mostrado na captura de tela a seguir.

Ajustar parâmetros de desempenho do servidor
Você pode configurar parâmetros do servidor MySQL para otimizar o desempenho com base no monitoramento. Por exemplo, você pode aumentar o valor de innodb_buffer_pool_size para manter mais dados de tabela na memória e salvar em leituras de disco. Você pode aumentar o innodb_log_file_size para reduzir a atividade de liberação do ponto de verificação do pool de buffers, ao custo de recuperação de falha mais lenta.
Se você descobrir que as conexões de aplicativo estão na fila e a carga do servidor for aceitável, você poderá aumentar o número máximo de conexões para permitir mais paralelismo.
Para modificar parâmetros de servidor, acesse o portal do Azure para seu servidor flexível MySQL e navegue até a seção Parâmetros do servidor. Insira o nome do parâmetro na barra de pesquisa ou navegue pelos parâmetros de servidor Principal ou Todos com suporte.
Explorar e habilitar o recurso IOPS com Dimensionamento Automático
O Banco de Dados do Azure para MySQL tem duas maneiras de alocar a capacidade de E/S do disco: IOPS pré-provisionada versus “dimensionada automaticamente” (operações de E/S por segundo).
IOPS pré-provisionado pode ser preferível quando a carga do banco de dados é previsível e não aumenta. O servidor obtém um número base de IOPS provisionado e você pode alocar IOPS adicional (até o tamanho máximo da computação), conforme necessário, acessando Computação + armazenamento:

Se houver um pico, o desempenho do servidor pode degradar temporariamente se as operações de I/O excederem o valor alocado. No entanto, a capacidade e os custos são previsíveis.
O recurso IOPS de Dimensionamento Automático é criado para o tráfego de banco de dados imprevisível, espetado ou crescente. Com esse recurso habilitado, o IOPS é dimensionado dinamicamente, portanto, o ajuste manual não é necessário para otimizar o custo ou o desempenho à medida que o fluxo de trabalho flutua. Como resultado, o uso do recurso IOPS de Dimensionamento Automático lida com picos de carga de trabalho não preteridos de forma transparente e você paga apenas pelas operações consumidas, não pela capacidade não utilizada.
Para um servidor flexível MySQL existente, você pode habilitar o recurso IOPS de Dimensionamento Automático no portal do Azure selecionando Computação + armazenamento:

Observação
Você também pode habilitar o recurso IOPS de Dimensionamento Automático durante a criação do servidor.
Monitorar IOPS
O monitoramento de IOPS permite determinar quão próximo sua instância está do máximo de IOPS, se você estiver usando IOPS pré-provisionados, ou do máximo do tamanho de computação, se estiver usando o recurso de Dimensionamento Automático de IOPS.
Para monitorar o desempenho do IOPS, navegue até a folha Métricas na seçãoMonitoramento ou até a folha Visão geral do, se desejar exibir o desempenho do IOPS juntamente com outras métricas comuns.
Na WingTip Toys, como você prevê um grande aumento no tráfego em momentos imprevisíveis à medida que a campanha de marketing é distribuída, você quer evitar o risco de não conseguir acomodar pedidos de entrada. Você também deseja evitar pagar pela capacidade máxima se você realmente não precisar dela. Você seleciona usar o recurso IOPS de Dimensionamento Automático em vez de IOPS pré-provisionado, o que requer a adição de mais IOPS manualmente conforme necessário. Essa abordagem equilibra a eficácia do custo com a escalabilidade sob demanda.
Provisionar uma réplica de leitura
Você provisiona réplicas de leitura para descarregar consultas somente leitura em um banco de dados separado, reduzindo a carga no banco de dados do aplicativo principal.
Para provisionar uma réplica de leitura, no portal do Azure, na página associada ao servidor flexível, selecione Replicaçãoe selecione Adicionar réplica.

Depois de criar a réplica de leitura, você pode definir o nome do servidor de réplica e suas configurações de computação e armazenamento. Você não pode alterar algumas configurações, como autenticação, que são herdadas do servidor primário.

Na Wingtip Toys, a equipe de ciência de dados e as ferramentas de relatório agora podem consultar o servidor de réplica de leitura, reduzindo a carga no banco de dados do aplicativo principal e removendo a necessidade de limitar a análise ou limitar as consultas fora do horário comercial.