Como o Azure Data Explorer funciona
Nesta unidade, analisamos como o Azure Data Explorer funciona nos bastidores discutindo os principais componentes do sistema. Em seguida, você aprenderá a interagir com o serviço explorando um fluxo de trabalho comum:
- Ingestão de dados
- Linguagem de Consulta Kusto
- Visualização de dados
Esse conhecimento ajuda você a decidir se o Azure Data Explorer é uma boa opção para suas necessidades de dados.
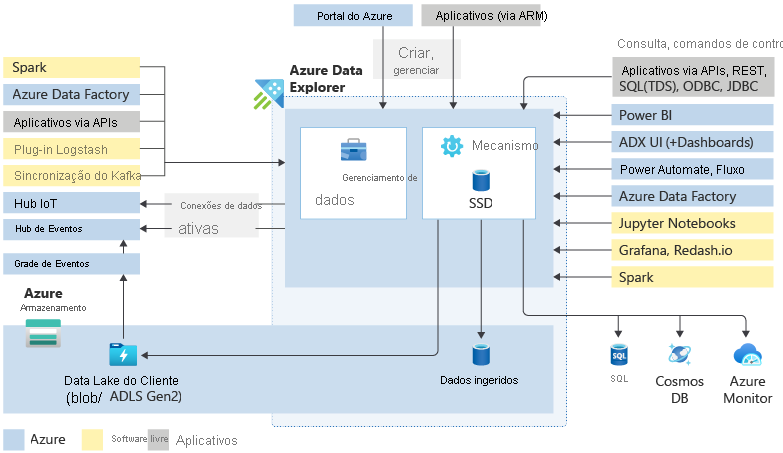
Principais componentes
Um cluster do Azure Data Explorer faz todo o trabalho de ingerir, processar e consultar seus dados. Os clusters são dimensionáveis automaticamente de acordo com suas necessidades. O Azure Data Explorer também armazena os dados no Armazenamento do Microsoft Azure e armazena em cache alguns desses dados nos nós de computação do cluster para obter o desempenho de consulta ideal.
O que um cluster do Azure Data Explorer contém?
Cada cluster do Azure Data Explorer pode conter até dez mil bancos de dados e cada banco de dados pode conter até dez mil tabelas. Os dados em cada tabela são armazenados em fragmentos de dados, também chamados de "extensões". Todos os dados são indexados e particionados automaticamente com base no tempo de ingestão. Diferente de um banco de dados relacional, não há restrições de chave estrangeira primária nem outras restrições, como de exclusividade. Esse design significa que você pode armazenar grandes quantidades de dados variados. E por causa da maneira como ele é armazenado, você obtém acesso rápido para consultá-lo.
A estrutura lógica de um banco de dados é semelhante a muitos outros bancos de dados relacionais. Um banco de dados do Azure Data Explorer pode conter:
- Tabelas: compostas por um conjunto de colunas. Cada coluna tem um de nove tipos de dados diferentes.
- Tabelas externas: tabelas cujo armazenamento subjacente está em outros locais, como o Azure Data Lake.
Conheça o fluxo de trabalho geral
De modo geral, ao interagir com o Azure Data Explorer, você passa pelo seguinte fluxo de trabalho: Primeiro você ingere seus dados para obtê-los no sistema. Em seguida, você analisa seus dados. Em seguida, você visualiza os resultados de sua análise. A qualquer momento, você também pode se envolver com os recursos de gerenciamento de dados. Esse trabalho com o Azure Data Explorer é feito por meio da interação com o cluster. Você pode acessar esses recursos na interface do usuário da Web ou usando SDKs.
Como inserir meus dados no Azure Data Explorer?
A ingestão de dados é o processo usado para carregar registros de dados de uma ou mais fontes em uma tabela no Azure Data Explorer. Manipular ainda mais os dados inclui realizar a correspondência de esquema, organização, indexação, codificação e compactação dos dados. O Gerenciador de Dados, em seguida, confirma a ingestão de dados para o mecanismo, onde está disponível para consulta.
Além do assistente nativo de interface do usuário da Web, há várias ferramentas de ingestão disponíveis. Incluindo os pipelines gerenciados, a Grade de Eventos, o Hub IoT e o Azure Data Factory. Você pode usar conectores e plug-ins, como o plug-in do Logstash, o conector do Kafka, o Power Automate e o conector do Apache Spark. Você também pode usar a ingestão programática usando SDKs ou o LightIngest.
Os dados podem ser ingeridos de dois modos: por envio em lote ou streaming. A ingestão por envio em lote é otimizada para alta taxa de transferência de ingestão e resultados de consulta rápidos. A ingestão de streaming permite latência quase em tempo real para pequenos conjuntos de dados por tabela.
Como fazer para analisar meus dados?
O Azure Data Explorer usa o KQL (Linguagem de Consulta Kusto), que é proprietário, para analisar dados. Ele é amplamente usado na Microsoft (Azure Monitor, Log Analytics, Application Insights, Microsoft Sentinel e Microsoft Defender XDR). O KQL é otimizado para exploração de Big Data diversificada e de fluxo rápido. Ele consulta tabelas de referência, exibições, funções e qualquer outra expressão tabular. Incluindo tabelas em bancos de dados diferentes ou até mesmo clusters. As consultas podem ser executadas usando a interface do usuário da Web, diversas ferramentas de consulta ou com um dos SDKs do Azure Data Explorer.
Como a Linguagem de Consulta Kusto funciona?
A Linguagem de Consulta Kusto é expressiva, intuitiva e altamente produtiva. Ela oferece uma transição suave de scripts simples de uma linha para scripts complexos de processamento de dados e dá suporte à consulta de dados estruturados, semiestruturados e não estruturados (pesquisa de texto). Há uma ampla variedade de operadores e funções de linguagem de consulta (agregação, filtragem, funções de séries temporais, funções geoespaciais, junções, uniões e muito mais) na linguagem. O KQL dá suporte a consultas entre clusters e entre bancos de dados e é rico em recursos da perspectiva da análise (JSON, XML etc.). Além disso, a linguagem tem suporte nativo para análise avançada.
Como posso exibir os resultados da consulta?
A interface do usuário da Web do Azure Data Explorer foi projetada com o Big Data em mente, permitindo que você execute consultas e crie painéis. Ele dá suporte a uma exibição de até 500 mil registros e milhares de colunas. É altamente escalonável e rica, com funcionalidades que ajudam você a obter insights rápidos de seus dados. Você também pode usar diferentes exibições visuais de seus dados em painéis do Azure Data Explorer. Além disso, pode exibir os resultados usando conectores nativos para alguns dos principais serviços de visualização disponíveis atualmente, como o Power BI e o Grafana. O Azure Data Explorer também tem suporte do conector do ODBC e do JDBC para ferramentas como Tableau e Qlik.
Como fazer para gerenciar meus dados?
Os administradores desejam executar várias tarefas de manutenção e política em seus clusters do Azure Data Explorer, e os comandos de controle oferecem a eles a capacidade de fazê-lo. Usando comandos de controle, eles podem criar novos clusters ou bancos de dados, estabelecer conexões de dados, executar dimensionamento automático e ajustar configurações de cluster. Eles também podem controlar e modificar entidades, objetos de metadados, gerenciamento de permissões e políticas de segurança. Além disso, eles podem modificar exibições materializadas (exibições filtradas atualizadas continuamente de outras tabelas), funções (funções armazenadas e funções definidas pelo usuário) e a política de atualização (funções que são disparadas após a ingestão).
Os comandos de controle são executados diretamente no mecanismo usando a interface do usuário da Web, o portal do Azure, várias ferramentas de consulta ou um dos SDKs do Azure Data Explorer.