Como o Azure Data Factory funciona
Aqui, você aprende sobre os componentes e os sistemas interconectados do Azure Data Factory e como eles funcionam. Esse conhecimento ajudará a determinar a melhor maneira de usar o Azure Data Factory para atender aos requisitos da sua organização.
O Azure Data Factory é uma coleção de sistemas interconectados que se combinam para fornecer uma plataforma de análise de dados de ponta a ponta. Nesta unidade, você aprende sobre as seguintes funções do Azure Data Factory:
- Conectar e coletar
- Transformar e enriquecer
- CI/CD (integração e entrega contínuas) e publicação
- Monitoramento
Você também aprende sobre esses componentes principais do Azure Data Factory:
- Pipelines
- Atividades
- Conjunto de dados
- Serviços vinculados
- Fluxos de dados
- Runtimes de integração
Funções do Azure Data Factory
O Azure Data Factory é composto por várias funções que são combinadas para fornecer aos engenheiros de dados uma plataforma de análise de dados completa.
Conectar e coletar
A primeira parte do processo é coletar os dados necessários das fontes de dados apropriadas. Essas fontes podem estar localizadas em locais diferentes, incluindo fontes locais e na nuvem. Os dados podem ser:
- Estruturados
- Não estruturados
- Semiestruturados
Além disso, esses dados distintos podem chegar em diferentes velocidades e intervalos. Com o Azure Data Factory, você pode usar a atividade Copy para mover dados de várias fontes para um armazenamento de dados centralizado na nuvem. Depois de copiar os dados, use outros sistemas para transformá-los e analisá-los.
A atividade Copy executa as seguintes etapas de alto nível:
Ler dados do armazenamento de dados de origem.
Execute as seguintes tarefas nos dados:
- Serialização/desserialização
- Compactação/descompactação
- Mapeamento de coluna
Observação
Pode haver tarefas adicionais.
Grave dados no armazenamento de dados de destino (conhecido como coletor).
Esse processo é resumido no seguinte gráfico:

Transformar e enriquecer
Depois de copiar os dados com êxito para um local central baseado em nuvem, você pode processar e transformar os dados conforme necessário usando fluxos de dados de mapeamento do Azure Data Factory. Os fluxos de dados permitem que você crie grafos de transformação de dados que são executados no Spark. No entanto, você não precisa entender os clusters do Spark nem a programação do Spark.
Dica
Embora não seja necessário, talvez você prefira codificar as suas transformações manualmente. Se for o caso, o Azure Data Factory dará suporte a atividades externas para executar as suas transformações.
CI/CD e publicar
O suporte para CI/CD permite que você desenvolva e entregue os seus processos de ETL (extração, transformação e carga) incrementalmente antes de publicar. O Azure Data Factory fornece CI/CD dos seus pipelines de dados usando:
- Azure DevOps
- GitHub
Observação
Integração contínua significa testar automaticamente cada alteração feita na sua base de código o mais cedo possível. A entrega contínua segue esse teste e envia por push alterações para um sistema de preparo ou de produção.
Após o Azure Data Factory refinar os dados brutos, será possível carregar os dados em qualquer mecanismo de análise que os usuários de negócios possam acessar por meio das ferramentas de business intelligence, incluindo:
- Azure Synapse Analytics
- Banco de Dados SQL do Azure
- Azure Cosmos DB
Monitor
Depois de criar e implantar com êxito o pipeline de integração de dados, é importante que você possa monitorar as suas atividades e pipelines agendados. O monitoramento permite acompanhar as taxas de êxito e falha. O Azure Data Factory dá suporte ao monitoramento de pipeline usando um dos seguintes métodos:
- Azure Monitor
- API
- PowerShell
- Logs do Azure Monitor
- Painéis de integridade no portal do Azure
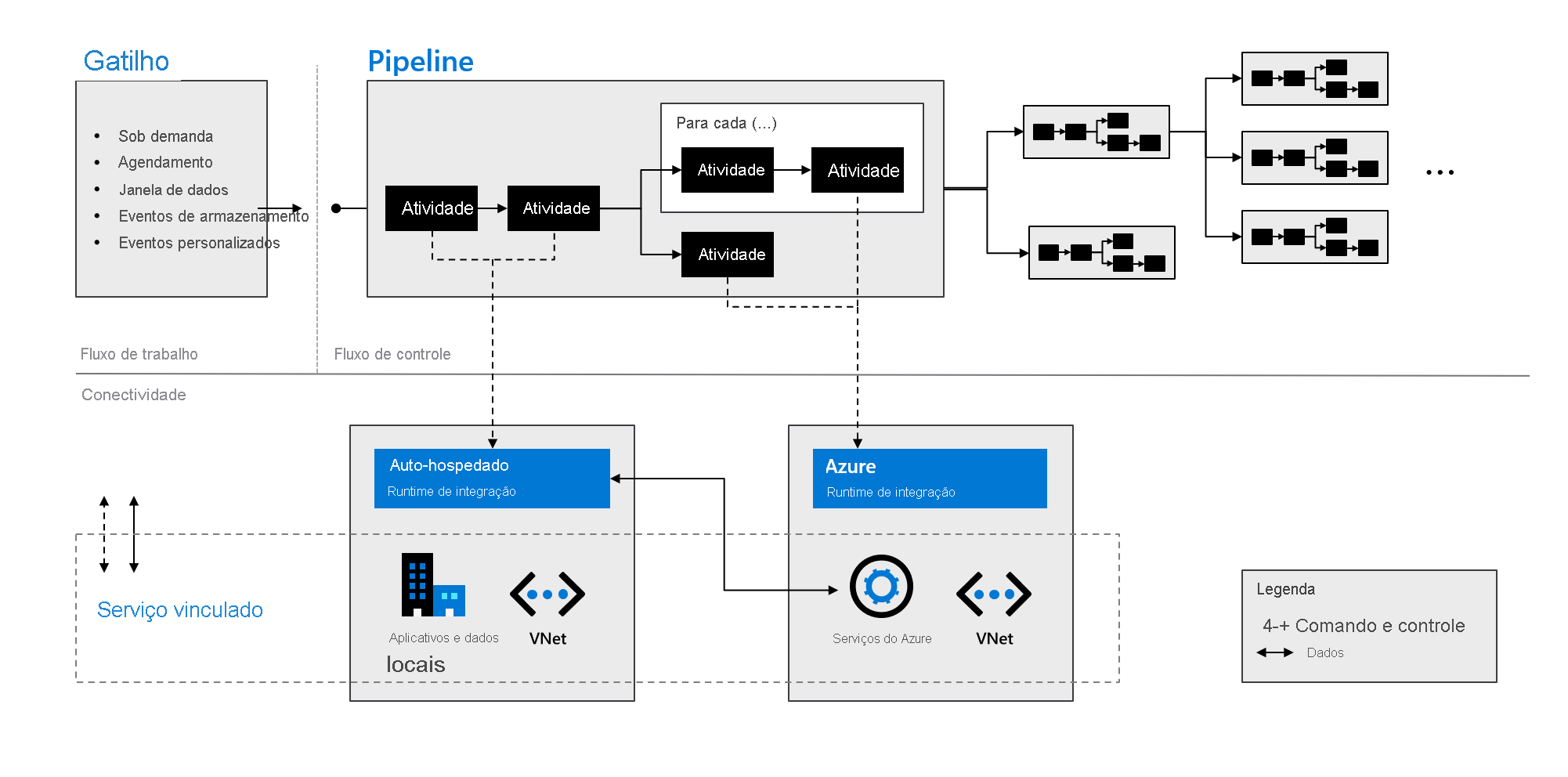
Componentes do Azure Data Factory
O Azure Data Factory é composto pelos componentes descritos na seguinte tabela:
| Componente | Descrição |
|---|---|
| Pipelines | Um grupo lógico de atividades que executam uma unidade de trabalho específica. Essas atividades juntas executam uma tarefa. A vantagem de usar um pipeline é que você pode gerenciar mais facilmente as atividades como um conjunto em vez de como itens individuais. |
| Atividades | Uma etapa de processamento em um pipeline. O Azure Data Factory dá suporte a três tipos de atividades: atividade de movimentação de dados, de transformação de dados e de controle. |
| Conjunto de dados | Representa estruturas de dados nos seus armazenamentos de dados. Conjuntos de dados apontam (ou fazem referência) aos dados que você deseja usar nas suas atividades como entradas ou saídas. |
| Serviços vinculados | Define as informações de conexão necessárias para que o Azure Data Factory se conecte a recursos externos, como uma fonte de dados. O Azure Data Factory usa serviços vinculados para duas finalidades: para representar um armazenamento de dados ou um recurso de computação. |
| Fluxos de dados | Permite que os engenheiros de dados desenvolvam a lógica de transformação de dados sem a necessidade de escrever código. Os fluxos de dados são executados como atividades em pipelines do Azure Data Factory que usam clusters do Apache Spark expandidos. |
| Runtimes de integração | O Azure Data Factory usa a infraestrutura de computação para fornecer as funcionalidades de integração de dados a seguir em diferentes ambientes de rede: fluxo de dados, movimentação de dados, expedição de atividade e execução de pacote SSIS (SQL Server Integration Services). No Azure Data Factory, um runtime de integração faz a ponte entre a atividade e os serviços vinculados. |
Conforme indicado no gráfico a seguir, esses componentes funcionam em conjunto para fornecer uma plataforma de ponta a ponta para engenheiros de dados. Usando o Data Factory, você pode:
- Definir gatilhos sob demanda e agendar o processamento de dados com base nas suas necessidades.
- Associar um pipeline a um gatilho ou iniciá-lo manualmente como e quando necessário.
- Conectar-se a serviços vinculados (como dados e aplicativos locais) ou a serviços do Azure por meio de runtimes de integração.
- Monitorar todas as execuções de pipeline nativamente na experiência de usuário do Azure Data Factory ou usando o Azure Monitor.