O que é o Azure HDInsight?
Vamos examinar os recursos e usos do HDInsight. Esta visão geral ajudará você a avaliar se o HDInsight atende aos requisitos da sua organização.
O que é big data?
O termo Big Data descreve os vastos volumes de dados estruturados e não estruturados que as organizações coletam. Esses dados podem ser extremamente úteis para as organizações. Especificamente, se uma organização puder analisar os dados para obter informações, será mais fácil tomar decisões. O resultado é que essas decisões podem ajudar uma organização a ser mais bem-sucedida. Por exemplo, a análise de Big Data pode permitir que uma organização comercial reconheça os hábitos do cliente, o que pode levar a um aumento de vendas.
Definição do Azure HDInsight
O Azure HDInsight é um serviço de análise de software livre baseado em nuvem totalmente gerenciado para empresas. O HDInsight permite que você controle e gerencie seu Big Data. HDInsight:
É uma distribuição de nuvem dos componentes do Hadoop.
Torna mais fácil, rápido e mais econômico processar grandes volumes de dados.
Dá suporte ao uso de estruturas de software livre aberto, como:
- O Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Observação
Com essas estruturas, você pode habilitar uma grande variedade de cenários, como extração, transformação e carregamento (ETL), data warehouse, aprendizado de máquina e IoT.
O HDInsight fornece vários benefícios para as organizações que estão trabalhando com Big Data. Ele:
Código aberto: permite criar clusters otimizados para várias estruturas de software livre.
Confiável: fornece um SLA de ponta a ponta para todas as cargas de trabalho de produção.
Escalonável: permite que você dimensione cargas de trabalho para responder às alterações de demanda.
Dica
Ao criar clusters sob demanda, você poderá reduzir os custos. Pague apenas pelo que usar.
Seguro: permite que você proteja seus ativos de dados corporativos por meio da integração com:
- Rede Virtual do Azure
- Tecnologias de criptografia do Azure
- Microsoft Entra ID
Conformidade: atende aos padrões de conformidade mais populares do setor e do governo.
Monitorado: integra-se com os logs do Azure Monitor para fornecer uma única interface. Monitora todos os clusters usando a interface única.
Como o HDInsight pode ajudar você a trabalhar com Big Data
Você pode usar o HDInsight em muitos cenários utilizando processamento de Big Data. Seus dados podem ser:
- Dados históricos: já coletados e armazenados.
- Dados em tempo real: transmitidos diretamente da origem.
As seguintes categorias resumem os cenários de processamento para os dados:
- Processamento em lotes
- Data warehousing
- IoT
- Ciência de dados
- Híbrido
Vamos examinar as categorias com mais detalhes.
Processamento em lotes
As organizações usam trabalhos de processamento em lote para preparar Big Data para análise posterior. Normalmente, o processo envolve três estágios:
- Leitura de arquivos de dados de origem a partir de fontes de dados heterogêneas.
- Processamento dos dados.
- Gravação dos dados em um armazenamento escalonável.
Observação
Este processo é chamado de ETL.
Você pode usar os dados transformados para ciência de dados ou data warehousing.
Dica
Um requisito significativo de ETL é a expansão da computação. Isso permite o processamento de grandes volumes de dados.
Data warehousing
Uma data warehouse fornece à organização um lugar para armazenar o Big Data enquanto aguarda a análise. O armazenamento de dados permite:
- Armazene seus dados.
- Prepare os dados para análise.
- Forneça os dados preparados em um formato estruturado. Consulte os dados usando ferramentas analíticas.
O diagrama a seguir ilustra como o Apache Hadoop no HDInsight coleta e armazena dados de várias fontes. O Apache Spark e o Apache Hive preparam e analisam os dados. Por fim, os dados são modelados para uso com as ferramentas de BI (business intelligence). O Power BI é usado para visualização de dados.
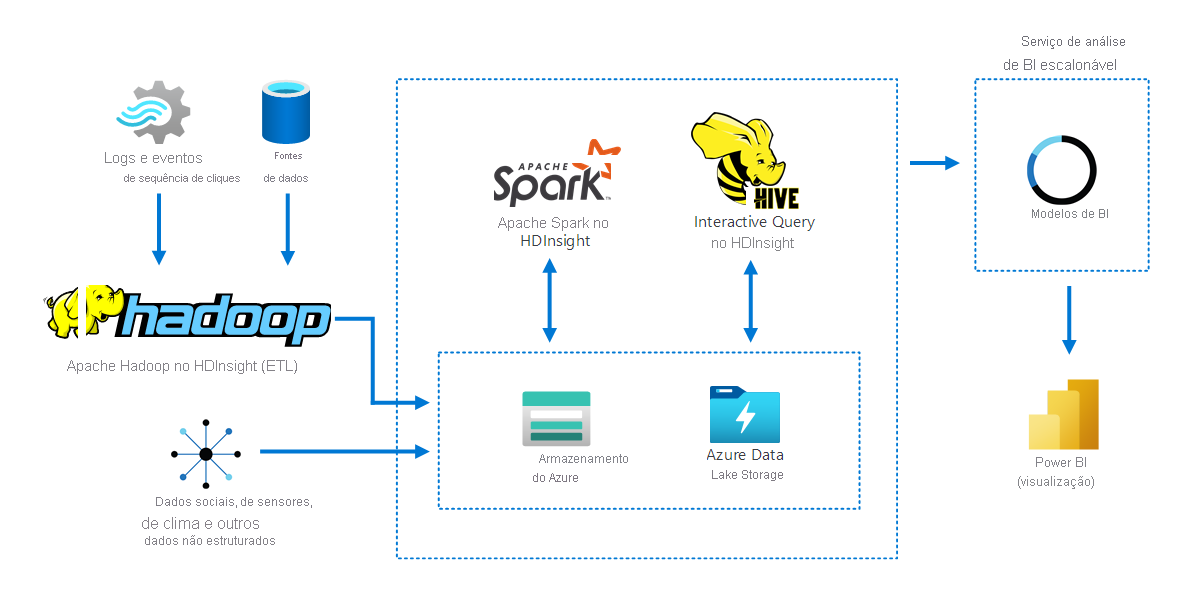
Nesse cenário, os componentes incluem:
- O Apache Spark é uma estrutura de processamento paralelo. Ele dá suporte ao processamento na memória, que ajuda a melhorar o desempenho de aplicativos de análise de Big Data.
- O Apache Hive no HDInsight é um sistema de data warehouse para Apache Hadoop. O Hive permite fazer resumo, consulta e análise de dados. É possível usar esses componentes para realizar consultas em escalas de petabyte sobre dados estruturados e não estruturados em qualquer formato.
Dica
As consultas do Hive são escritas em HiveQL, uma linguagem de consulta semelhante ao SQL.
Internet das coisas
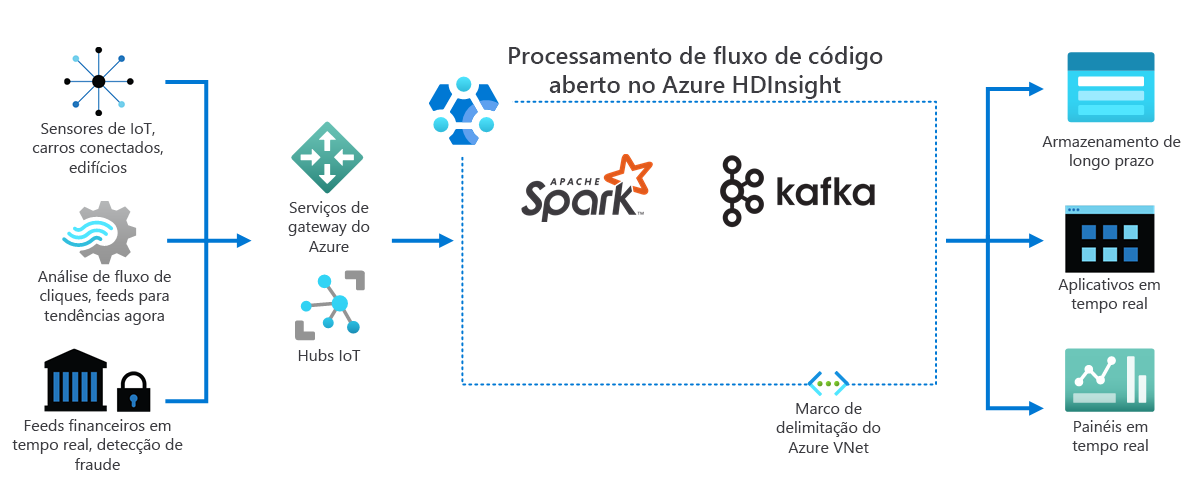
Como mostra o diagrama a seguir, o HDInsight processa os dados de streaming recebidos em tempo real de diferentes dispositivos e sensores. Neste exemplo, várias estruturas de software de código aberto fornecem processamento de fluxo, incluindo Apache Spark e Apache Kafka.
Os serviços de gateway do Azure e os hubs IoT direcionam dados de várias fontes para essas estruturas. As estruturas processam os dados e passam para:
- Armazenamento de longo prazo.
- Aplicativos em tempo real.
- Painéis em tempo real.
Ciência de dados
Você pode usar o HDInsight para concluir tarefas comuns de ciência de dados, como:
- Ingestão de dados.
- Engenharia de recursos.
- Modelagem.
- Avaliação de modelos.
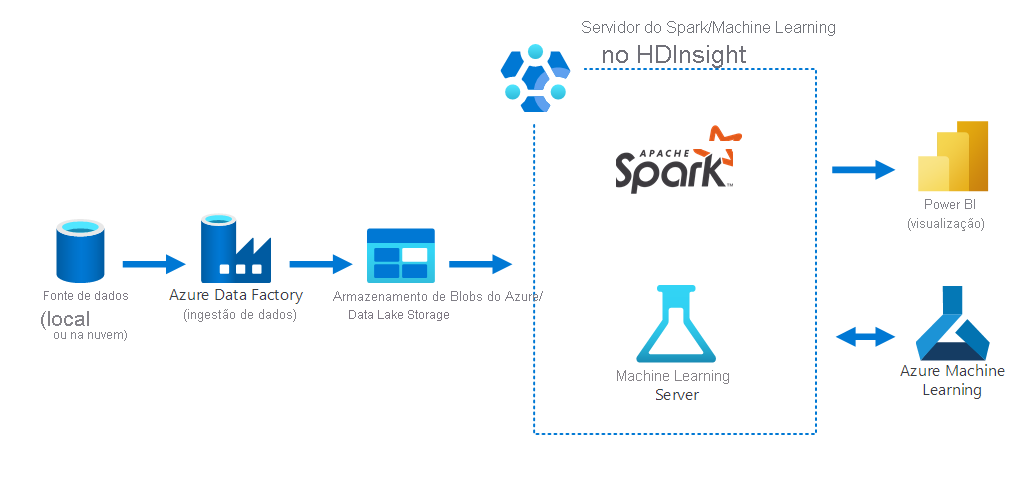
O seguinte diagrama ilustra um cenário de ciência de dados, no qual:
- Os dados são coletados de uma fonte de dados local usando o Azure Data Factory.
- Os dados ingeridos são guardados no armazenamento do Azure (Armazenamento de Blobs do Azure ou Data Lake Store).
- O Azure Spark no HDInsight processa e prepara os dados para o Azure Machine Learning. Os dados também são visualizados usando Power BI.
Híbrido
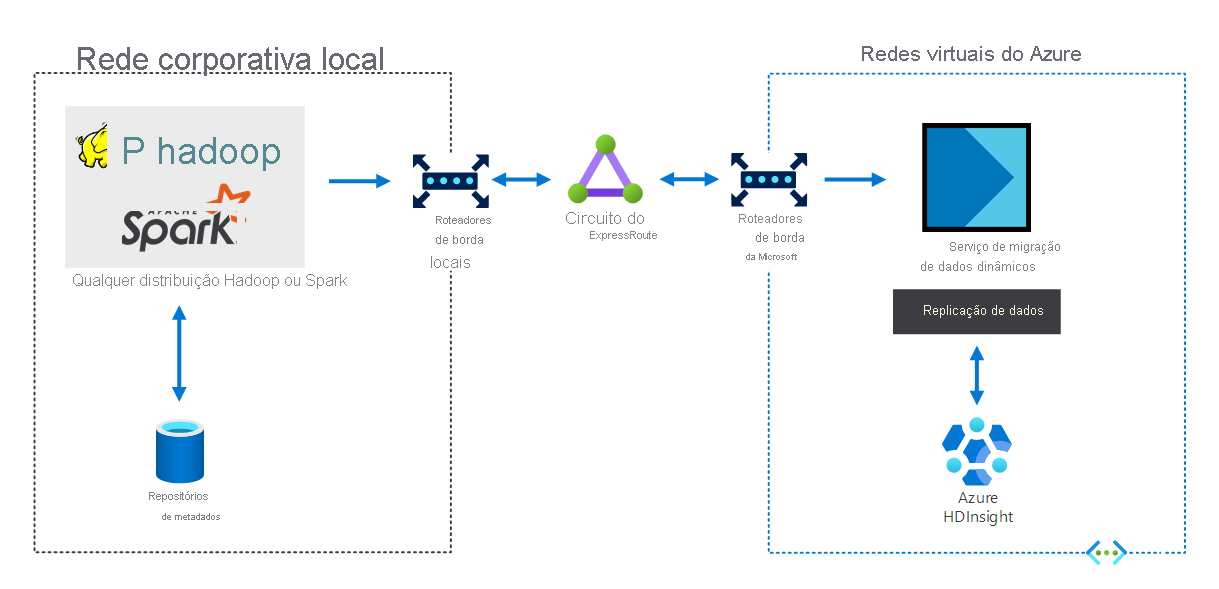
As organizações que têm uma infraestrutura de Big Data local podem usar o HDInsight para estender para o Azure. Isso fornece os benefícios dos recursos de análise avançada da nuvem do Azure. O seguinte diagrama ilustra o cenário híbrido, no qual:
- A infraestrutura de Big Data local consiste em repositórios de metadados e uma distribuição do Hadoop ou Spark em VMs locais.
- Um circuito do Azure ExpressRoute conecta o ambiente de rede corporativa local a redes virtuais do Azure.
- Um migrador de dados ao vivo para o Azure replica os dados recebidos do local para o HDInsight.