Como o Azure HDInsight funciona
Aqui, você verá como o Azure HDInsight funciona. Você conhecerá os seguintes componentes e como eles se ajustam para fornecer controle e gerenciamento de dados:
- Apache Hadoop
- Armazenamento do HDInsight
- Processamento do HDInsight
O que é o Apache Hadoop?
O Apache Hadoop é um sistema de processamento de dados distribuído na nuvem no núcleo do HDInsight. Ele tem três componentes, descritos pela tabela a seguir:
| Componente do Apache Hadoop | Descrição |
|---|---|
| HDFS | O HDFS (Sistema de Arquivos Distribuído do Apache Hadoop) fornece armazenamento para o sistema Hadoop. |
| YARN | O componente YARN (Yet Another Resource Negotiator) do Apache Hadoop fornece processamento para o sistema. |
| MapReduce | O MapReduce é um modelo de programação que permite processar e analisar dados. |
Como os componentes interagem?
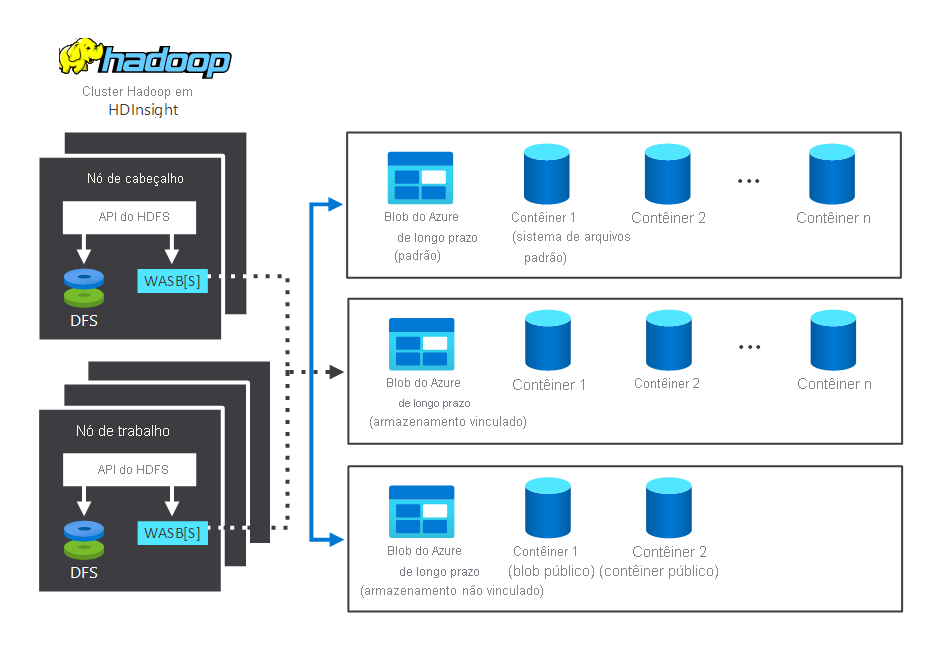
O diagrama a seguir ilustra os componentes de armazenamento e processamento que interagem em um cluster típico do HDInsight Hadoop. Ele ilustra os seguintes componentes:
- O nó principal e os nós de trabalho, que realizam o processamento.
- Vários centros de armazenamento do WASB (Windows Azure Storage Blob), dentro dos nós. O HDFS interage com esses contêineres.
- Vários contêineres de armazenamento padrão, vinculados e desvinculados. Eles estão disponíveis para os dois nós.
Agora vamos examinar como o armazenamento e o processamento funcionam.
Como o armazenamento funciona?
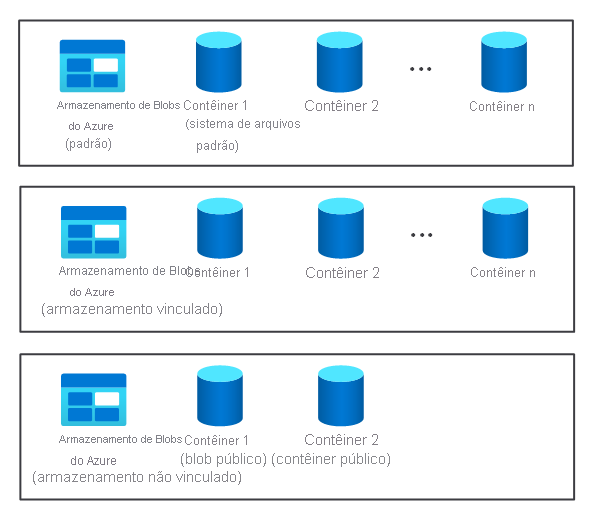
O componente de armazenamento de um cluster não é criado automaticamente quando você provisiona um cluster HDInsight. Em vez disso, ele é fornecido por um sistema em conformidade com HDFS, como o Armazenamento do Azure ou o Azure Data Lake.
Há benefícios em separar o componente de armazenamento de um cluster do componente de processamento. Por exemplo, você pode excluir com segurança todos os clusters HDInsight usados somente para computação sem se preocupar com a perda de dados. Ao adicionar um cluster do HDInsight, você deverá definir um sistema de arquivos padrão.
Importante
Para o armazenamento do Azure, você deve especificar um contêiner de blob como o sistema de arquivos padrão.
Fornecer um sistema de arquivos padrão garante que o HDInsight possa resolver referências de arquivos relativos durante a pesquisa de arquivos.
Dica
Quando você quiser aumentar o armazenamento disponível, poderá vincular e desvincular sistemas de arquivos adicionais conforme necessário.
Como o processamento funciona?
Ao processar dados, o componente de computação de um cluster Hadoop no HDInsight será dividido em duas áreas lógicas. A tabela a seguir descreve estas duas áreas:
| Componente | Descrição |
|---|---|
| Nó de cabeçalho | O nó principal aceita e gerencia solicitações de cliente e passa as solicitações para os nós de trabalho. |
| Nó de trabalho | Os nós de trabalho processam dados. |
Observação
O nó principal às vezes é chamado de nó mestre.
A maioria dos clusters contém dois nós principais, incluindo:
- Um nó principal ativo, que gerencia conexões de cliente.
- Um nó principal passivo, que fornece resiliência caso o nó ativo fique offline.
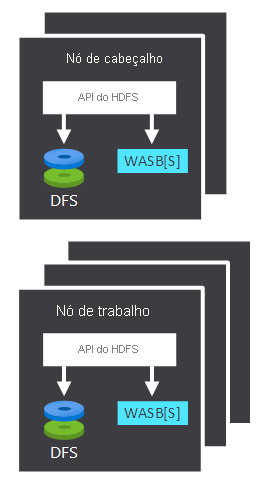
Os nós principal e de trabalho podem se conectar diretamente a um HDFS anexado localmente ou acessar dados armazenados no Blob do Azure ou no Azure Data Lake. Quais dados são gerenciados depende de dois fatores:
- Como o modelo de programação MapReduce definiu a forma de trabalhar com os dados
- Como o nó principal aloca o trabalho
O que o YARN faz?
O YARN executa o gerenciamento de recursos em um cluster HDInsight. Quando você está processando dados, este serviço gerencia recursos e agendamento de trabalho.
O YARN fica entre o HDFS e o sistema de computação do cluster HDInsight. Ele funciona com o nó principal para ajudar a distribuir um trabalho entre os nós de trabalho do cluster. Isso ajuda a garantir que os trabalhos de processamento de dados ocorram em paralelo.