Registrar e servir modelos com o MLflow
O registro do modelo permite que o MLflow e o Azure Databricks acompanhem os modelos; o que é importante por dois motivos:
- Registrar um modelo permite que você forneça o modelo para inferência em tempo real, em streaming ou em lote. O registro facilita o processo de uso de um modelo treinado, já que os cientistas de dados não precisarão desenvolver o código do aplicativo; o processo de serviço cria esse wrapper e expõe uma API REST ou método para pontuação em lote automaticamente.
- O registro de um modelo permite que você crie versões desse modelo ao longo do tempo; oferecendo a oportunidade de acompanhar as alterações de modelo e até mesmo executar comparações entre diferentes versões históricas de modelos.
Registro de um modelo
Ao executar um experimento para treinar um modelo, você pode registrar o próprio modelo como parte da execução do experimento, conforme mostrado aqui:
with mlflow.start_run():
# code to train model goes here
# log the model itself (and the environment it needs to be used)
unique_model_name = "my_model-" + str(time.time())
mlflow.spark.log_model(spark_model = model,
artifact_path=unique_model_name,
conda_env=mlflow.spark.get_default_conda_env())
Quando você examina a execução do experimento, incluindo as métricas registradas que indicam o quão bem o modelo prevê, o modelo é incluído nos artefatos de execução. Em seguida, você pode selecionar a opção para registrar o modelo usando a interface do usuário no visualizador de experimentos.
Como alternativa, se você quiser registrar o modelo sem examinar as métricas na execução, poderá incluir o parâmetro registered_model_name no método log_model; nesse caso, o modelo é registrado automaticamente durante a execução do experimento.
with mlflow.start_run():
# code to train model goes here
# log the model itself (and the environment it needs to be used)
unique_model_name = "my_model-" + str(time.time())
mlflow.spark.log_model(spark_model=model,
artifact_path=unique_model_name
conda_env=mlflow.spark.get_default_conda_env(),
registered_model_name="my_model")
Você pode registrar várias versões de um modelo, permitindo a comparação do desempenho das versões do modelo durante um período antes de mover todos os aplicativos cliente para a versão com melhor desempenho.
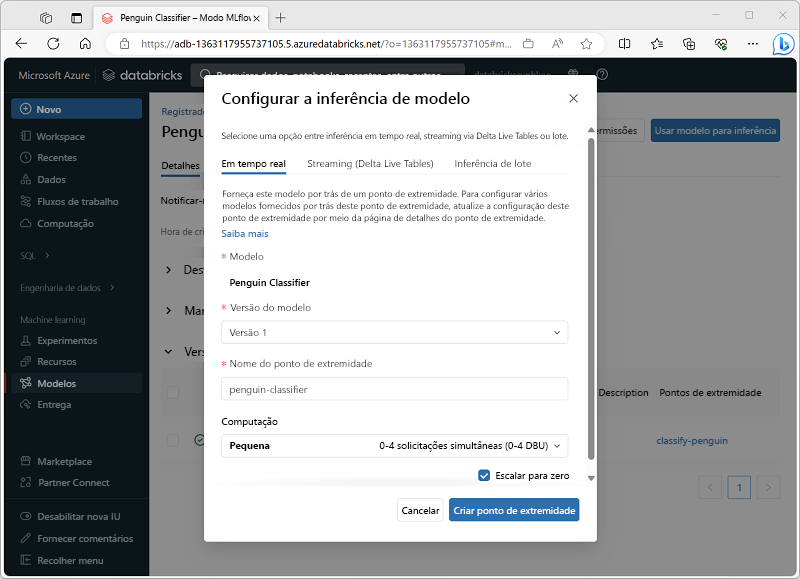
Como usar um modelo para inferência
O processo de usar um modelo para prever rótulos de novos dados de recurso é conhecido como inferência. Você pode usar o MLflow no Azure Databricks para disponibilizar modelos para inferência das seguintes maneiras:
- Hospede o modelo como um serviço em tempo real com um ponto de extremidade HTTP para o qual os aplicativos cliente podem fazer solicitações REST.
- Use o modelo para executar a inferência perpétua de streaming de rótulos com base em uma tabela delta de recursos, gravando os resultados em uma tabela de saída.
- Use o modelo para inferência em lote com base em uma tabela delta, gravando os resultados de cada operação em lote em uma pasta específica.
Você pode implantar um modelo para inferência da sua página na seção Modelos do portal do Azure Databricks, conforme mostrado aqui: