Normalização e padronização
A colocação em escala de recursos é uma técnica que altera o intervalo de valores que um recurso tem. Isso ajuda os modelos a aprender de forma mais rápida e robusta.
Normalização versus padronização
A normalização significa escalar valores para que todos se ajustem em um determinado intervalo, normalmente de 0 a 1. Por exemplo, se você tem uma lista de idades de pessoas entre 0, 50 e 100 anos, você pode normalizá-la dividindo as idades por 100, para que seus valores sejam 0, 0,5 e 1.
A padronização é semelhante, mas, em vez disso, subtraímos a média dos valores e dividimos pelo desvio padrão. Não se preocupe se você não estiver familiarizado com o desvio padrão. Isso significa que, após a padronização, nosso valor médio é zero, e cerca de 95% dos valores ficam entre -2 e 2.
Há outras maneiras de dimensionar dados, mas elas contêm nuances que estão além do que precisamos saber no momento. Vamos explorar por que aplicamos a normalização ou a padronização.
Por que precisamos escalar?
Há muitos motivos para normalizar ou padronizar os dados antes do treinamento. Você pode entendê-las de forma mais fácil com um exemplo. Digamos que desejamos treinar um modelo para prever se um cachorro será bem-sucedido no trabalho na neve. Nossos dados são mostrados no gráfico abaixo como pontos, e a linha de tendência que estamos tentando encontrar é mostrada como uma linha sólida:
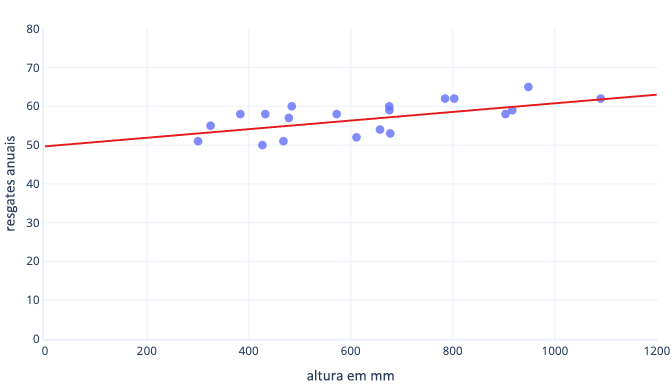
A colocação em escala propicia um melhor ponto de partida ao aprendizado
A linha ideal no gráfico acima tem dois parâmetros: a interceptação, que é 50, a linha em que x = 0; e a inclinação, que é 0,01; cada 1000-milímetros aumentam o número de resgates em 10. Vamos supor que começamos o treinamento com estimativas iniciais de 0 para ambos os parâmetros.
Se nossas iterações de treinamento estiverem alterando parâmetros por cerca de 0,01 por iteração em média, serão necessárias pelo menos 5000 iterações até que a interceptação seja encontrada: 50/0,01 = 5000 iterações. A padronização pode trazer essa interceptação ideal para mais próximo de zero, o que significa que podemos encontrá-la muito mais rapidamente. Por exemplo, se subtrairmos a média entre o nosso rótulo — as comparações anuais — e o nosso recurso — altura — a interceptação é -0,5, e não 50, que podemos encontrar cerca de 100 vezes mais rápido.
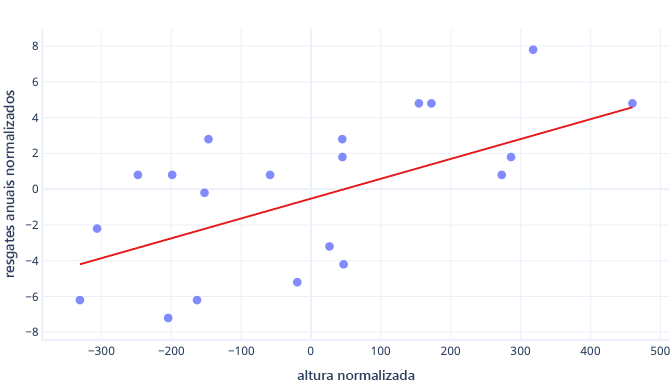
Há outros motivos pelos quais modelos complexos podem ser muito lentos para treinar quando a estimativa inicial está distante da marca, mas a solução permanece a mesma: deslocar recursos para algo mais próximo da estimativa inicial.
A padronização permite que os parâmetros treinem na mesma velocidade
Em nossos dados já deslocados, temos um deslocamento ideal de -0,5 e uma inclinação ideal de 0,01. Embora o deslocamento ajude a acelerar o processo, ainda é muito mais lento treinar o deslocamento do que treinar a inclinação. Isso pode retardar o processo e tornar o treinamento instável.
Por exemplo, nossos palpites iniciais para deslocamento e inclinação são ambos zero. Se formos alterar os nossos parâmetros em cerca de 0,1 em cada iteração, encontraremos o deslocamento rapidamente, mas será muito difícil encontrar a inclinação correta, pois os aumentos na inclinação serão muito grandes (0 + 0,1 > 0,01) e poderão ultrapassar o valor ideal. Podemos diminuir os ajustes, mas com isso reduzimos o tempo necessário para encontrar a interceptação.
O que acontecerá se dimensionarmos nosso recurso de altura?
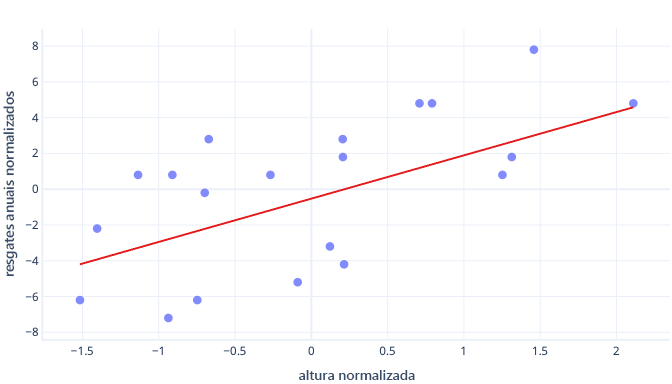
A inclinação da linha verdadeira é 0.5. Preste atenção no eixo x. Nossa interceptação ideal de -0,5 e a inclinação de 0,5 estão na mesma escala! Agora ficou fácil escolher um tamanho de etapa razoável, que é a velocidade com que o descendente de gradiente atualiza os parâmetros.
A colocação em escala ajuda com vários recursos
Quando trabalhamos com múltiplos recursos, tê-los em uma escala diferente pode causar problemas de ajuste, da mesma forma que vimos com os exemplos de intercepção e inclinação. Por exemplo, se estivermos treinando um modelo que aceita a altura em mm e o peso em toneladas, muitos tipos de modelos terão dificuldades em apreciar a importância do recurso de peso, simplesmente porque ele é pequeno demais em comparação ao recurso de altura.
Eu sempre preciso dimensionar?
Nem sempre é preciso escalar. Alguns tipos de modelos, incluindo os modelos anteriores com linhas retas, podem ser ajustados sem um procedimento iterativo como gradiente descendente, de modo que eles não se importam com os recursos de tamanho errado. Outros modelos precisam ser dimensionados para treinar bem, mas suas bibliotecas geralmente executam automaticamente a colocação em escala de recursos.
Em termos gerais, as únicas desvantagens reais da normalização ou da padronização são a dificuldade na interpretação de nossos modelos e o fato de precisarmos escrever um pouco mais de código. Por esse motivo, a colocação em escala de recursos é uma parte padrão da criação de modelos de aprendizado de máquina.