Distributed Deep Learning on AZTK and HDInsight Spark Clusters
This post is authored by Chenhui Hu, Data Scientist at Microsoft.
Deep learning has achieved great success in many areas recently. It has attained state-of-the-art performance in applications ranging from image classification and speech recognition to time series forecasting. The key success factors of deep learning are – big volumes of data, flexible models and ever-growing computing power.
With the increase in the number of parameters and training data, it is observed that the performance of deep learning can be improved dramatically. However, when models and training data get big, they may not fit in the memory of a single CPU or GPU machine, and thus model training could become slow. One of the approaches to handle this challenge is to use large-scale clusters of machines to distribute the training of deep neural networks (DNNs). This technique enables a seamless integration of scalable data processing with deep learning. Other approach like using multiple GPUs on a single machine works well with modest data but could be inefficient for big data.
Although the term "distributed deep learning" may sound scary if you're hearing it for the first time, through this blog post, I show how you can quickly write scripts to train DNNs in a distributed manner on AZTK Spark Cluster and Azure HDInsight Spark Cluster. I do so by walking you through two examples – one for image classification and another for time series forecasting. The source code is available on GitHub.
Distributed Deep Learning Concept
Distributed deep learning aims at training a single DNN model across multiple machines. Essentially, it is solving a stochastic optimization problem in a distributed fashion. To help understand this concept, I will introduce the basic ideas and few popular algorithms of distributed deep learning.
Model Parallelism vs. Data Parallelism
There are two main types of distributed deep learning frameworks, namely model parallelism and data parallelism. Model parallelism distributes the computations of a single model across multiple machines. As a simple example, it is possible to split the computations of the output of a perceptron (single neuron) by having each input node compute the product of the input and the associated weight. In contrast, data parallelism tries to parallelize the gradient descent over multiple machines by splitting training data into several partitions or data shards. Since this blog uses the data parallelism framework, I will briefly describe the typical steps in this framework. As illustrated in Figure 1, the training data is split into mini-batches over workers, with each mini-batch of size . When the training starts, every worker gets a copy of the model parameters (e.g., the weight matrices and bias vectors in a multilayer perceptron) from the parameter server and computes the accumulated gradient based on its own data. Then, the local gradient information is sent back to the parameter server, which will average all the accumulated gradients and applies this combined gradient to update the model parameters. After this, the workers will download the new model parameters and the above process will be repeated.

Figure 1: Typical architecture of data parallelism for deep learning [1].
Representative Algorithms
In this blog, we exploit distributed optimization algorithms based on data parallelism. Many such algorithms have been proposed to speed up the training of DNNs, e.g., DOWNPOUR [2] and ADAG [1]. DOWNPOUR is an asynchronous optimization algorithm which allows the parameter server to update the model parameters whenever it receives the information from a worker. Although it is one of the most commonly used algorithms, it has large communication overhead and is not very stable with large number of workers. As an improved algorithm, ADAG is a DOWNPOUR variant which is significantly better in terms of the statistical performance and less sensitive to hyperparameters.
Environment Setup
To illustrate the above concept, we will use the Distributed Keras Python package referred to as dist-keras in the examples. This package implements several distributed optimization algorithms including ADAG, Dynamic SGD, etc. We need to install this package as well as Keras and TensorFlow on the AZTK Spark cluster and Azure HDInsight Spark cluster. Note that you can also install relevant packages on Azure Databricks and perform distributed deep learning like this example.
Install Packages on AZTK Spark Cluster
As a python CLI application, Azure Distributed Data Engineering Toolkit (AZTK) is a tool for provisioning on-demand Spark on Docker clusters in Azure. You can find the steps of setting up AZTK in its Github repository. Before we create a new cluster, as shown in Figure 2, we can specify additional packages that we want to install in jupyter.sh file, which is under custom-scripts folder of the AZTK source code. Note that we need to install the packages on all the nodes. Hence, we should set runOn option to be all-nodes in cluster.yaml file under .aztk folder and modify the if statement in jupyter.sh. Another option to install packages on AZTK is to use a custom docker image with the packages preinstalled.

a) jupyter.sh file with additional packages specified.

b) Modified cluster.yaml file for installing package on all nodes.
Figure 2: Configurations for package installation on AZTK Spark cluster.
Install Packages on HDInsight Spark Cluster
HDInsight Spark cluster is the Apache Hadoop in the cloud implemented by Microsoft. You can easily create a Spark cluster in HDInsight and run Jupyter notebooks on it by following this tutorial. Script action can be used to install external Python packages for Jupyter notebooks in HDInsight Spark cluster. In particular, we just need to run the bash script shown in Figure 3 according to this guidance.

Figure 3: Bash script for installing packages on HDInsight Spark cluster.
Examples
Image Classification
Image classification is one of the first successful areas dominated by deep learning. In this example script, I train a convolutional network for handwritten digits classification using distributed deep learning on an AZTK Spark cluster. It uses the MNIST dataset and is adapted from the example provided by Distributed Keras package. In the beginning, we specify the Spark master for AZTK as follows

Figure 4: Specification of AZTK Spark cluster.
We can scale up or down the number of processes and the number of executors based on the need. Each executor and process correspond to a worker and a core of the worker, respectively. Then, we load the training data and testing data from the MNIST dataset as Spark DataFrames and perform a series of transformations to convert the data into the format that Distributed Keras requires. After the data is prepared, we can define the DNN model using Keras and perform the distributed training on Spark with any algorithm provided by dist-keras, such as

Figure 5: Use ADAG algorithm to train a convolutional network.
Time Series Forecasting
Time series forecasting is a ubiquitous problem in many domains, including energy, retail, finance, healthcare, and many others. In this example, I demonstrate energy demand forecasting using Distributed Keras on both an AZTK and an HDInsight Spark cluster. It trains a long short-term memory (LSTM) model and a gated recurrent unit (GRU) model. Both are recurrent neural networks (RNNs) that have been revealed to be powerful in time series forecasting. Specifically, LSTM model is able to learn long term dependencies in sequential data and GRU model is close to LSTM model but with a simpler structure. The data used here is downloaded from the NYISO website which includes the hourly energy consumption and local weather of cities in New York State. I've selected the New York City data from February 2016 to April 2017 (see Figure 6) and the associated weather data for developing the example. In total, the data has 11596 rows and 3 informative columns indicating the time, hourly energy consumption, and temperature. For a quick overview, please check the HDInsight Jupyter notebook and the AZTK Python script.

Figure 6: Hourly energy consumption of New York City.
When you use AZTK, the setup of the cluster is the same as what I introduced in the last example. If you have an HDInsight Spark cluster, you need to specify 'yarn-client' as your master and stop the default Spark context before creating a new one. The tricky parts are how to normalize the data and how to create features for time series forecasting using PySpark. MinMaxTransformer in Distributed Keras is exploited to normalize the range of each data column. Unlike MinMaxScaler in scikit learn, we need to specify the range of values before and after transformation in Figure 7. But this allows us to use MinMaxTransformer for the inverse transformation as well.

Figure 7: Normalize the range of a data column.
Since the transformers defined in Distributed Keras package operate on Spark DataFrame, I use window function in PySpark to create the input features and output targets:

Figure 8: Create input features and output targets.
Then, I assemble all the features into a vector and reshape the vectors into the format that Keras requires. Similarly, I do the assembling and reshaping for the target variables. After the data is prepared, two networks will be trained: one is LSTM and the other is GRU. For instance, I define and train a basic LSTM model as follows
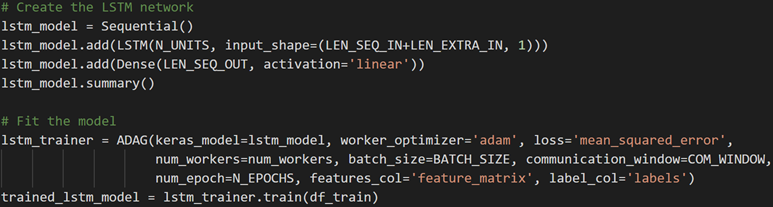
Figure 9: Create and fit an LSTM model.
The input sequence length and output sequence length are 24 and 1, respectively. Basically, the model maps the energy consumption in the last 24 hours to the consumption in the next hour. I use the last 120-hour (5-day) data as testing data and all the previous data as training data. After the model is trained, we can apply it to predict the energy consumption and convert the predictions to the original range of the energy consumptions. Mean-absolute-percentage-errors (MAPEs) are computed for GRU and LSTM models on the testing data.
Table 1: Training time and MAPE vs. the number of executors (i.e., workers)
| Model | Number of executors | Training time (second) | Testing MAPE (%) |
| LSTM | 1 | 381.8 | 3.80 |
| LSTM | 2 | 223.0 | 4.64 |
| LSTM | 4 | 151.9 | 5.25 |
| GRU | 1 | 341.3 | 3.38 |
| GRU | 2 | 188.9 | 3.37 |
| GRU | 4 | 127.2 | 4.80 |
Table 1 summarizes the training time and average MAPE with 5 repeated runs of each model. In the tests, each worker or executor is a standard_d4_v2 virtual machine with 2 Intel Xeon E5-2690 CPU cores and 7 GB memory. The number of processes in each executor is 2; the LSTM or GRU has 128 units; the batch size, the communication window, and the number of epochs in the training are 32, 5, and 4, respectively. The training time reduces significantly with more executors, indicating that the model is effectively trained across multiple machines. Moreover, the average MAPE is 4.64% and 3.37% with 2 executors. This shows that RNNs trained by Distributed Keras perform well on time series forecasting. In this example, we use training data that fits in the memory of a single machine to illustrate the concept of distributed deep learning. The benefit to the training speed could be more remarkable if the data volume is beyond the memory size. Besides, we observe the testing MAPE is different with different number of executors. This variation may be an artifact of distributed deep learning and could be related to the data set. You probably want to try the example out with your own data. You can also play with other algorithms simply by calling it from Distributed Keras. E.g., you can choose DOWNPOUR algorithm by replacing ADAG in Figure 9 with DOWNPOUR. In addition, you are encouraged to deploy AZTK Spark clusters with GPU using a single-line command and further speed up the model training!
Conclusion
In this blog, I introduced the concept of distributed deep learning and shared examples of training different DNNs on Spark clusters offered by Azure. With PySpark and Distributed Keras, big data processing and deep learning can be integrated smoothly for solving image classification and time series forecasting problems. I hope this blog will be a starting point for people who need to train large DNNs with big data on Azure and enable more enterprise applications.
Chenhui
Acknowledgements
Special thanks to Ilan Reiter, Dmitry Pechyoni and Angus Taylor for reviewing this blog and providing helpful feedbacks.
References