Mise en place d’une machine virtuelle dédiée à l’analyse de données – 2nde partie
La première partie de ce billet nous a permis d'introduire la machine virtuelle « Data Science VM » mise à disposition par Microsoft sur le magasin en ligne Azure Marketplace.
Dans cette seconde partie du billet, nous nous intéressons à une première illustration de mise en œuvre des fonctionnalités ainsi offertes au travers de cette VM prête à l'usage.
J'en profite pour remercier très sincèrement Morgan Funtowicz, en stage au sein de l'équipe, qui vous propose cette exploration.
Mise en œuvre des fonctionnalités offertes
Nous allons maintenant voir au travers d'un exemple simple les fonctionnalités offertes par les divers outils de la machine.
Pour se faire, s'il existe de nombreux jeux de données publics sur le Machine Learning Repository, nous utiliserons dans la suite de ce billet l'un des jeux de données les plus populaires et déjà utilisé dans de précédents billets, en l'occurrence le jeu de données iris téléchargeable ici.
Il s'agit d'un historique recensant les dimensions ou variables (longueur des sépales, largeur des sépales, longueur des pétales, et largeur des pétales) de 150 iris et l'espèce associée à chaque iris (prédiction) :

Dans un premier temps, nous utiliserons ce jeu de données afin de mettre en application les fonctionnalités de Power BI dans le but de visualiser nos données simplement. Puis, dans un second temps, nous utiliserons Jupyter et le langage Python afin d'étendre les possibilités de Power BI, et mettre en place un algorithme de classification supervisée.
Prise en main du jeu de données via Power BI
Afin de nous familiariser avec le jeu de données iris, nous allons commencer par utiliser le logiciel Power BI inclut dans notre machine. Ce logiciel permet de générer des rapports graphiques provenant de différentes sources, sans aucune ligne de code.
Figure 2 : Ecran d'accueil de Power BI
Nous allons donc commencer par importer notre jeu de données, lequel se trouve être un fichier au format texte. Pour ce faire, il suffit de cliquer sur le bouton Get Data, de choisir Text et d'indiquer l'emplacement du fichier de données que nous avons téléchargé. (Le lien de téléchargement est disponible dans la précédente section).
Une fois le fichier chargé, Power BI nous affiche une prévisualisation des données contenues. Cette étape permet de repérer d'éventuels problèmes lors de l'importation du schéma du fichier dans le logiciel.
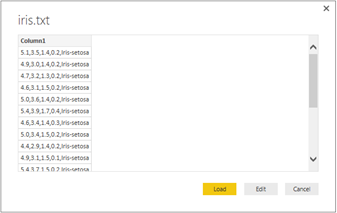
Comme vous l'avez surement remarqué, le schéma que Power BI nous propose d'importer n'est pas adapté à notre contexte. Pour un fichier texte, Power BI considère en effet chaque ligne comme une unique colonne texte. Afin d'éditer nos colonnes, nous allons éditer l'importation via le bouton Edit.
L'éditeur de requête permet de modifier à notre guise la manière dont les éléments sont importés dans Power BI. Ainsi nous pouvons indiquer par exemple, de séparer la colonne Column1 suivant un délimiteur « , » (Comma). Pour ce faire, un simple clic droit sur le nom de la colonne => Split column => By delimiter puis valider.
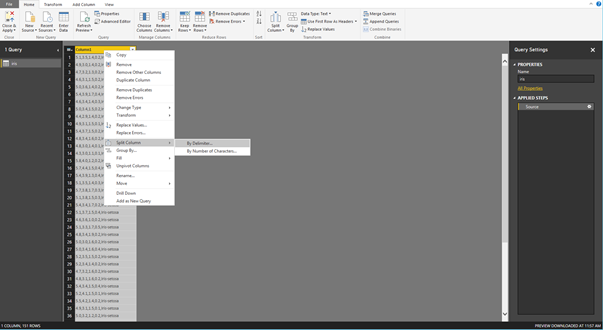
Cette manipulation permet d'obtenir une source de données bien plus facilement interrogeable. Enfin, pour encore plus de confort lors de l'utilisation de la source de donnée, nous allons renommer nos colonnes afin de les faire correspondre à des éléments intelligibles pour quiconque souhaiterait réutiliser notre jeu de données. Pour cela, un simple clic droit sur le nom d'une colonne, puis Rename suffit.
Voici dans l'ordre, les noms des colonnes (Sans oublier d'appliquer en haut à gauche, une fois terminé) :
- sepal_length.
- sepal_width.
- petal_length.
- petal_width.
- iris_class.
Il convient de noter que, par défaut, Power BI cherche à agréger les données (somme, moyenne, etc.). De façon à supprimer ce comportement, en sélectionnant chaque colonne, nous allons modifier la valeur Default Summarization à droite dans le bandeau Modeling.
Suite à quoi, nous obtenons un jeu de données semblable à celui-ci-dessous :
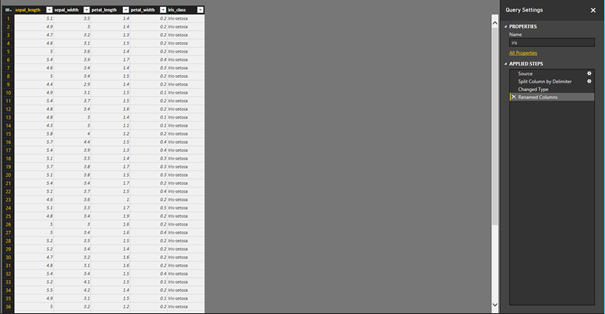
Figure 3 : Fichier après transformation
Cette étape permet de s'assurer de la qualité des données. Ce processus d'inspection qualitative des données peut être long et couteux. Cependant, il demeure essentiel, car de lui dépend la pertinence de nos analyses futures. Parmi les transformations courantes, on trouve le traitement des valeurs manquantes, le filtrage des individus (lignes) aberrantes ou encore la normalisation des données.
Peut-être que certain(e)s d'entre vous ont fait l'analogie entre cette étape et le processus plus couramment appelé ETL (Extract Transform Load) permettant d'extraire de l'information d'une source, opérer des transformations sur celle-ci (jointure, filtrage, etc.) et enfin injecter cette nouvelle donnée transformée dans un stockage de sortie.
Maintenant que nos données sont bien matérialisées dans Power BI, nous allons pouvoir commencer à les représenter graphiquement.
Nous allons donc afficher la moyenne et la variance de chacune des variables en groupant ces dernières par classe. La moyenne nous permettra de nous donner une idée de la tendance pour chaque variable par classe, tandis que la variance mesurera la dispersion des valeurs au sein d'une même classe.
La première étape consiste à choisir le type de graphique adapté à l'information que l'on souhaite communiquer. Une représentation adaptée aura un impact beaucoup plus grand et rapide sur la personne qui l'observe, tandis qu'une représentation non adaptée, rendra l'interprétation fastidieuse, complexe et potentiellement erronée.
Nous allons donc devoir afficher en abscisse les différentes classes, et en ordonnée une valeur agrégée (moyenne et variance).
Afin de définir le type de graphique à utiliser, jetons un œil à nos données :
- Sur l'axe des X : Les différentes classes d'iris (variable qualitative, catégorielle)
- Sur l'axe des Y : La moyenne et/ou la variance d'une variable.
Etant donné la nature de nos valeurs sur l'axe des X (ensemble fini de valeurs), nous devons forcément utiliser un histogramme. Nous aurions pu utiliser une représentation sous forme de courbe si les valeurs sur l'axe des X étaient continues (ensemble infini de valeurs).
Afin de créer un histogramme dans Power BI, cliquez sur New Visual dans le bandeau supérieur.

Puis remplissez les champs comme indiqué ci-dessous :
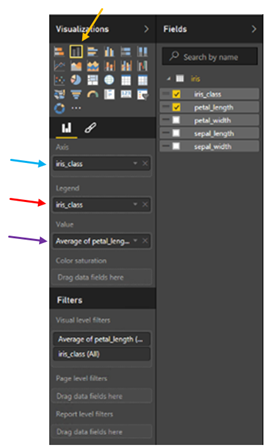
- Création d'une nouvelle zone graphique
- Définition du type de graphique : Dans notre cas, un histogramme
- Axis : Défini les valeurs prises sur l'axe des X et selon lesquelles grouper les données
- Legend : Facultatif, défini une valeur à afficher au survol d'une classe sur le graphique
- Value : La valeur qui définira la « hauteur » d'une classe sur le graphique (ici Average)
Répétez cette opération pour les 2 valeurs (Average & Variance) pour chacune des 4 variables ; ce qui nous amènes à quelque chose de semblable à cette représentation :

Figure 5 : Exemple de présentation de la moyenne (en haut) et variance (en bas) de chaque variable
Ces différents graphiques nous permettent de mettre en évidence certains points :
- Les iris setosa ont tendance à avoir une longueur/largeur de sépale et pétale plus faible que les deux autres classes.
- La variance de chacune des variables est très faible, indiquant une dispersion faible
- Les iris versicolor et virginica sont relativement semblables.
Les interprétations qu'il est possible de sortir de ces différents points :
- Les individus de chaque classe sont tous centrés vers la moyenne (peu de dispersion).
- Les individus de la classe iris virginica sont globalement supérieurs en termes de longueur/largeur que les deux autres classes.
- Les individus de la classe iris versicolor sont globalement supérieurs en termes de longueur/largeur que la classe iris setosa.
Cette première prise en main vous donne un aperçu, simple et rapide, des capacités de présentation de l'information au travers de Power BI. Bien sûr, le champ des possibilités est bien plus étendu que cette simple présentation, mais nécessiteraient plusieurs billets spécifiques pour réussir à obtenir une couverture complète du sujet.
Pour autant, une troisième et dernière partie vous accompagne dans une analyse avancée via Jupyter.