Modelo de recibo de Document Intelligence
Este conteúdo aplica-se a: ![]() v2.1 | Última versão:
v2.1 | Última versão: ![]() v4.0 (GA)
v4.0 (GA)
O modelo de recibo Document Intelligence combina poderosas capacidades de Reconhecimento Ótico de Carateres (OCR) com modelos de aprendizagem profunda para analisar e extrair informações importantes dos recibos de vendas. Os recibos podem ser de vários formatos e qualidade, incluindo recibos impressos e manuscritos. A API extrai informações importantes, como nome do comerciante, número de telefone do comerciante, data da transação, impostos e total da transação e retorna dados JSON estruturados. O modelo de recibo v4.0 (GA) também suporta outros campos, incluindo ReceiptType, TaxDetails.NetAmount, TaxDetails.DescriptionTaxDetails.Rate e CountryRegion.
Tipos de recibos suportados na versão mais recente (4.0):
- Refeição
- Materiais
- Hotel
- Combustível &Energia
- Transportes
- Comunicação
- Subscrições
- Entretenimento
- Formação
- Cuidados de saúde
Extração de dados de recibo
A digitalização de recibos engloba a transformação de vários tipos de recibos, incluindo cópias digitalizadas, fotografadas e impressas, em um formato digital para processamento simplificado a jusante. Exemplos incluem gestão de despesas, análise do comportamento do consumidor, automação fiscal, etc. O uso da inteligência documental com a tecnologia OCR (Optical Character Recognition) pode extrair e interpretar dados desses diversos formatos de recebimento. O processamento de Inteligência Documental simplifica o processo de conversão, mas também reduz significativamente o tempo e o esforço necessários, facilitando assim o gerenciamento e a recuperação eficientes de dados.
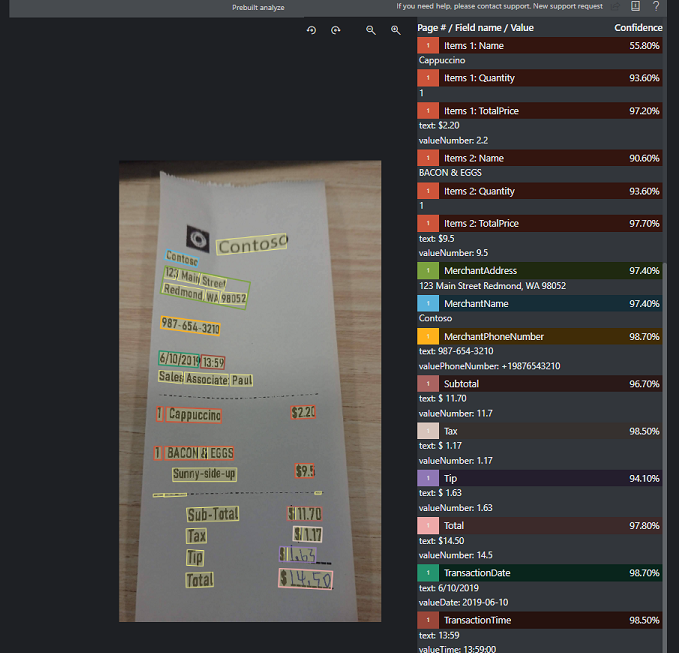
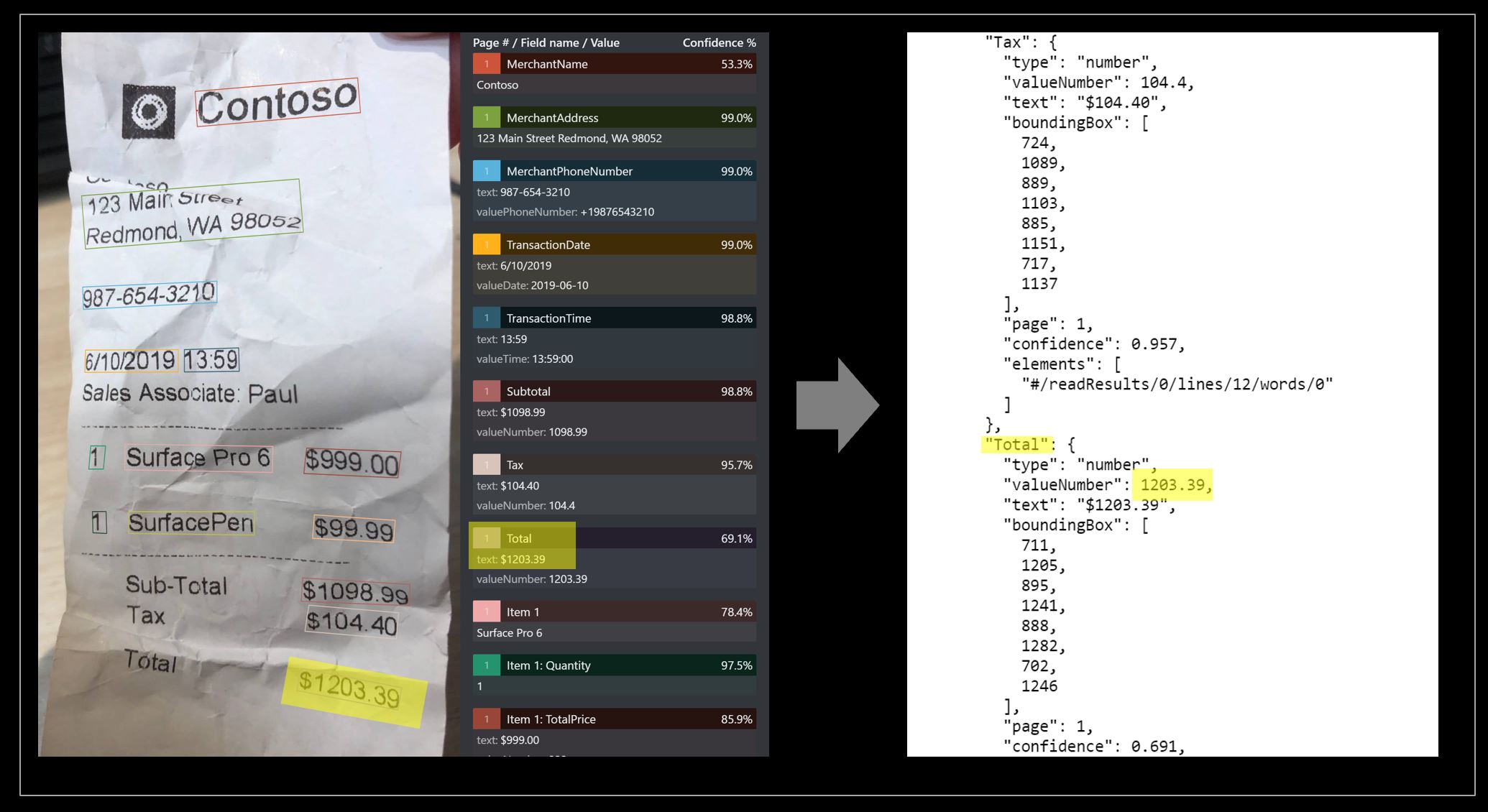
Exemplo de recibo processado com o Document Intelligence Studio:

Recibo de amostra processado com a ferramenta Document Intelligence Sample Labeling:
Opções de desenvolvimento
O Document Intelligence v4.0: 2024-11-30 (GA) suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de recibo | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
recibo pré-embutido |
O Document Intelligence v3.1 suporta as seguintes ferramentas, aplicativos e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de recibo | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
recibo pré-embutido |
O Document Intelligence v3.0 suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de recibo | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
recibo pré-embutido |
O Document Intelligence v2.1 suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos |
|---|---|
| Modelo de recibo | • Ferramenta de etiquetagem de Inteligência Documental• API REST • SDK de biblioteca cliente• Contêiner Docker de Inteligência Documental |
Requisitos de entrada
Formatos de ficheiro suportados:
Modelo PDF Imagem: JPEG/JPG,PNG,BMP,TIFF, ,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLida ✔ ✔ ✔ Esquema ✔ ✔ ✔ Documento Geral ✔ ✔ Pré-criado ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ Para obter melhores resultados, forneça uma foto nítida ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de nível gratuito, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para analisar documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 pixels x 50 pixels e 10.000 pixels x 10.000 pixels.
Se os seus PDFs forem bloqueados por uma palavra-passe, terá de remover o bloqueio antes da submetê-los.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1024 x 768 pixels. Esta dimensão corresponde a cerca
8de texto pontual a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GB com um máximo de 10.000 páginas. Para 2024-11-30 (GA), o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
- Formatos de ficheiro suportados: JPEG, PNG, PDF e TIFF.
- Permissão de página suportada para PDF e TIFF: o Document Intelligence pode processar até 2.000 páginas para assinantes de nível padrão ou apenas as duas primeiras páginas para assinantes de nível gratuito.
- Tamanho do ficheiro suportado: menos de 50 MB; pixels mínimos: 50 x 50 px; máximo de pixels 10.000 x 10.000 px.
Extração de dados do modelo de recibo
Veja como o Document Intelligence extrai dados, incluindo hora e data das transações, informações do comerciante e totais de valores dos recibos. Você precisa dos seguintes recursos:
Uma assinatura do Azure — você pode criar uma gratuitamente.
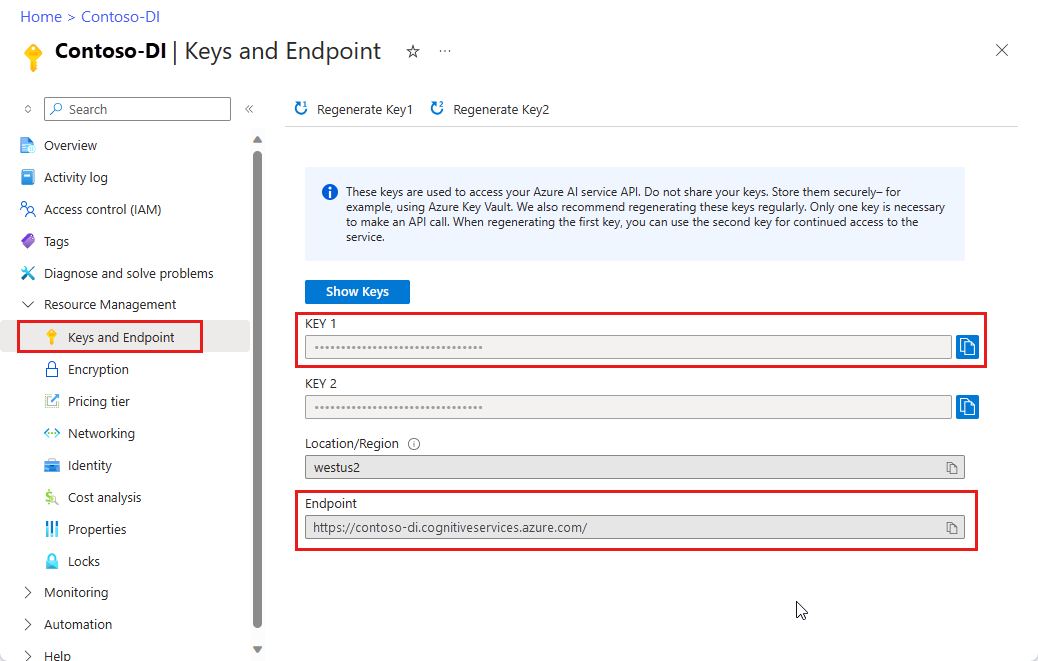
Uma instância de Document Intelligence no portal do Azure. Você pode usar o nível de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter sua chave e o ponto de extremidade.
Nota
O Document Intelligence Studio está disponível com APIs v3.1 e v3.0 e versões posteriores.
Na home page do Document Intelligence Studio, selecione Recibos.
Você pode analisar o recibo de amostra ou fazer upload de seus próprios arquivos.
Selecione o botão Executar análise e, se necessário, configure as opções Analisar:

Ferramenta de etiquetagem de exemplo de inteligência de documentos
Navegue até a Ferramenta de Exemplo de Inteligência de Documentos.
Na página inicial da ferramenta de exemplo, selecione o bloco Usar modelo pré-criado para obter dados .
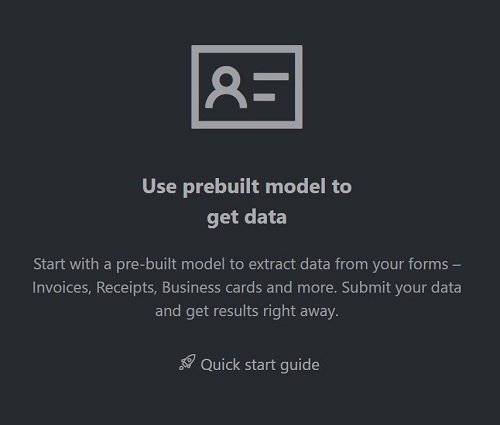
Selecione o Tipo de formulário a ser analisado no menu suspenso.
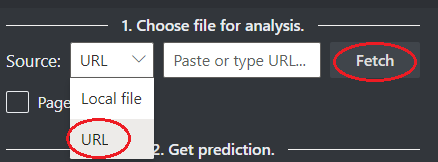
Escolha um URL para o arquivo que você gostaria de analisar a partir das opções abaixo:
Exemplo de documento de fatura.
Exemplo de documento de identificação.
Imagem de recibo de amostra.
Exemplo de imagem de cartão de visita.
No campo Origem, selecione URL no menu suspenso, cole o URL selecionado e selecione o botão Buscar.
No campo Ponto de extremidade do serviço de Inteligência Documental, cole o ponto de extremidade obtido com sua assinatura do Document Intelligence.
No campo chave, cole a chave obtida do recurso Document Intelligence.

Selecione Executar análise. A ferramenta Document Intelligence Sample Labeling chama a API Analyze Prebuilt e analisa o documento.
Exibir os resultados - veja os pares chave-valor extraídos, itens de linha, texto realçado extraído e tabelas detetadas.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nota
A ferramenta Exemplo de etiquetagem não suporta o formato de ficheiro BMP. Esta é uma limitação da ferramenta e não do Serviço de Inteligência Documental.
Idiomas e localidades suportados
Para obter uma lista completa dos idiomas suportados, consulte a nossa página de suporte a idiomas de modelos pré-construídos.
Extração de campo
Para campos de extração de documentos suportados, consulte a página do esquema do modelo de recibo em nosso repositório de exemplo do GitHub
| Nome | Tipo | Description | Saída padronizada |
|---|---|---|---|
| Tipo de recibo | String | Tipo de recibo de venda | Discriminado |
| MerchantName | String | Nome do comerciante que emite o recibo | |
| Número de telefone do comerciante | phoneNumber | Número de telefone listado do comerciante | +1 xxx xxx xxxx |
| MerchantAddress | String | Endereço listado do comerciante | |
| TransactionDate | Date | Data de emissão do recibo | AAAA-MM-DD |
| TransactionTime | Hora | Hora de emissão do recibo | HH-MM-SS (24 horas) |
| Total | Número (USD) | Total total de recebimento da transação | Flutuação de duas casas decimais |
| Subtotal | Número (USD) | Subtotal do recebimento, muitas vezes antes da aplicação dos impostos | Flutuação de duas casas decimais |
| Imposto | Número (USD) | Total de impostos no recebimento (geralmente imposto sobre vendas ou equivalente). Renomeado para "TotalTax" na versão 2022-06-30. | Flutuação de duas casas decimais |
| Gorjeta | Número (USD) | Dica incluída pelo comprador | Flutuação de duas casas decimais |
| Items | Matriz de objetos | Itens de linha extraídos, com nome, quantidade, preço unitário e preço total extraído | |
| Nome | Cadeia (de carateres) | Descrição do artigo. Renomeado para "Descrição" na versão 2022-06-30. | |
| Quantidade | Número | Quantidade de cada item | Flutuação de duas casas decimais |
| Preço | Número | Preço individual de cada unidade de item | Flutuação de duas casas decimais |
| PreçoTotal | Número | Preço total do item de linha | Flutuação de duas casas decimais |
Guia de migração e API REST v3.1
- Siga nosso guia de migração do Document Intelligence v3.1 para saber como usar a versão v3.1 em seus aplicativos e fluxos de trabalho.
Próximos passos
Tente processar seus próprios formulários e documentos com o Document Intelligence Studio.
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.
Tente processar seus próprios formulários e documentos com a ferramenta Document Intelligence Sample Labeling.
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.