Visão geral do dimensionamento automático de cluster no Serviço Kubernetes do Azure (AKS)
Para acompanhar as demandas de aplicativos no Serviço Kubernetes do Azure (AKS), talvez seja necessário ajustar o número de nós que executam suas cargas de trabalho. O componente autoscaler do cluster procura pods no cluster que não podem ser agendados devido a restrições de recursos. Quando o autoscaler do cluster deteta pods não agendados, ele aumenta o número de nós no pool de nós para atender à demanda do aplicativo. Ele também verifica regularmente os nós que não têm pods agendados e reduz o número de nós conforme necessário.
Este artigo ajuda você a entender como o autoscaler de cluster funciona no AKS. Ele também fornece orientação, práticas recomendadas e considerações ao configurar o autoscaler de cluster para suas cargas de trabalho AKS. Se você quiser habilitar, desabilitar ou atualizar o autoscaler de cluster para suas cargas de trabalho AKS, consulte Usar o autoscaler de cluster no AKS.
Sobre o autoscaler de cluster
Os clusters geralmente precisam de uma maneira de dimensionar automaticamente para se ajustar às demandas de aplicativos em constante mudança, como entre dias úteis e noites ou fins de semana. Os clusters AKS podem ser dimensionados das seguintes maneiras:
- O autoscaler de cluster verifica periodicamente se há pods que não podem ser agendados em nós devido a restrições de recursos. Em seguida, o cluster aumenta automaticamente o número de nós. O dimensionamento manual é desativado quando utiliza o dimensionamento automático de clusters. Para obter mais informações, consulte Como funciona o aumento de escala?.
- O Horizontal Pod Autoscaler usa o Metrics Server em um cluster Kubernetes para monitorar a demanda de recursos de pods. Se um aplicativo precisar de mais recursos, o número de pods é automaticamente aumentado para atender à demanda.
- O Vertical Pod Autoscaler define automaticamente solicitações de recursos e limites em contêineres por carga de trabalho com base no uso anterior para garantir que os pods sejam agendados em nós que tenham os recursos de CPU e memória necessários.
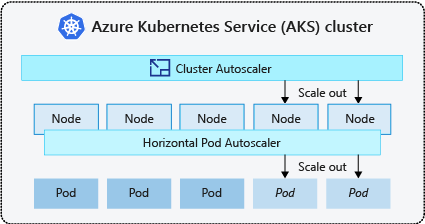
É uma prática comum habilitar o autoscaler de cluster para nós e o Vertical Pod Autoscaler ou o Horizontal Pod Autoscaler para pods. Quando você habilita o dimensionador automático de cluster, ele aplica as regras de dimensionamento especificadas quando o tamanho do pool de nós é menor do que a contagem mínima de nós, até a contagem máxima de nós. O autoscaler de cluster aguarda para entrar em vigor até que um novo nó seja necessário no pool de nós ou até que um nó possa ser excluído com segurança do pool de nós atual. Para obter mais informações, consulte Como funciona a redução de escala?
Práticas recomendadas e considerações
- Ao implementar zonas de disponibilidade com o autoscaler de cluster, recomendamos o uso de um único pool de nós para cada zona. Você pode definir o
--balance-similar-node-groupsparâmetro paraTruemanter uma distribuição equilibrada de nós entre zonas para suas cargas de trabalho durante operações de expansão. Quando essa abordagem não é implementada, as operações de redução de escala podem interromper o equilíbrio de nós entre zonas. - Para clusters com mais de 400 nós, recomendamos usar o Azure CNI ou o Azure CNI Overlay.
- Para executar efetivamente cargas de trabalho simultaneamente em pools de nós Spot e Fixo, considere o uso de expansores de prioridade. Essa abordagem permite que você programe pods com base na prioridade do pool de nós.
- Tenha cuidado ao atribuir solicitações de CPU/memória em pods. O autoscaler do cluster aumenta a escala com base em pods pendentes em vez da pressão da CPU/memória nos nós.
- Para clusters que hospedam simultaneamente cargas de trabalho de longa duração, como aplicativos Web, e cargas de trabalho curtas/intermitidas, recomendamos separá-las em pools de nós distintos com expansores de Regras de Afinidade/ou usar o PodDisruptionBudget para ajudar a evitar a drenagem desnecessária de nós ou reduzir as operações. Especificar a anotação cluster-autoscaler.kubernetes.io/safe-to-evict: "false" na especificação do Pod também impedirá que os pods sejam removidos. Use essa anotação com cuidado, pois ela pode fazer com que o Autoscaler de cluster encontre problemas ao drenar um nó com um Pod em execução que inclua essa anotação.
- Em um pool de nós habilitado para autoscaler, reduza os nós removendo cargas de trabalho, em vez de reduzir manualmente a contagem de nós. Isso pode ser problemático se o pool de nós já estiver na capacidade máxima ou se houver cargas de trabalho ativas em execução nos nós, potencialmente causando um comportamento inesperado pelo autoscaler do cluster.
- Os nós não são dimensionados se os pods tiverem um valor PriorityClass inferior a -10. A prioridade -10 é reservada para pods de superprovisionamento. Para obter mais informações, consulte Usando o autoscaler de cluster com prioridade e preempção de pod.
- Não combine outros mecanismos de dimensionamento automático de nós, como escaladores automáticos do Conjunto de Escala de Máquina Virtual, com o autoscaler de cluster.
- O autoscaler de cluster pode não conseguir reduzir a escala se os pods não puderem se mover, como nas seguintes situações:
- Um pod criado diretamente não apoiado por um objeto controlador, como um Deployment ou ReplicaSet.
- Um orçamento de interrupção de pods (PDB) que é muito restritivo e não permite que o número de pods fique abaixo de um determinado limite.
- Um pod usa seletores de nó ou antiafinidade que não podem ser honrados se agendados em um nó diferente. Para obter mais informações, consulte Que tipos de pods podem impedir que o autoscaler do cluster remova um nó?.
Importante
Não faça alterações em nós individuais dentro dos pools de nós dimensionados automaticamente. Todos os nós no mesmo grupo de nós devem ter capacidade uniforme, rótulos, manchas e pods do sistema em execução neles.
- O autoscaler de cluster não é responsável por impor uma "contagem máxima de nós" em um pool de nós de cluster, independentemente das considerações de agendamento de pod. Se qualquer ator que não seja de escalonamento automático de cluster definir a contagem do pool de nós para um número além do máximo configurado do autoscaler de cluster, o autoscaler de cluster não removerá automaticamente os nós. Os comportamentos de redução do dimensionamento automático do cluster permanecem com escopo para remover apenas nós que não têm pods agendados. O único objetivo da configuração de contagem máxima de nós do autoscaler do cluster é impor um limite superior para operações de scale-up. Não tem qualquer efeito sobre as considerações de redução de escala.
Perfil do autoscaler do cluster
O perfil do autoscaler do cluster é um conjunto de parâmetros que controlam o comportamento do autoscaler do cluster. Você pode configurar o perfil do autoscaler do cluster ao criar um cluster ou atualizar um cluster existente.
Otimizando o perfil do autoscaler do cluster
Você deve ajustar as configurações do perfil do autoscaler do cluster de acordo com seus cenários de carga de trabalho específicos e, ao mesmo tempo, considerar as compensações entre desempenho e custo. Esta seção fornece exemplos que demonstram essas compensações.
É importante observar que as configurações do perfil do autoscaler do cluster são em todo o cluster e aplicadas a todos os pools de nós habilitados para dimensionamento automático. Quaisquer ações de dimensionamento que ocorram em um pool de nós podem afetar o comportamento de dimensionamento automático de outros pools de nós, o que pode levar a resultados inesperados. Certifique-se de aplicar configurações de perfil consistentes e sincronizadas em todos os pools de nós relevantes para garantir que você obtenha os resultados desejados.
Exemplo 1: Otimizando para desempenho
Para clusters que lidam com cargas de trabalho substanciais e intermitentes com foco principal no desempenho, recomendamos aumentar e scan-interval diminuir o scale-down-utilization-threshold. Essas configurações ajudam a agrupar várias operações de dimensionamento em uma única chamada, otimizando o tempo de dimensionamento e a utilização de cotas de leitura/gravação de computação. Ele também ajuda a mitigar o risco de reduzir rapidamente as operações em nós subutilizados, aumentando a eficiência do agendamento do pod. Também aumentar ok-total-unready-counte max-total-unready-percentage.
Para clusters com pods daemonset recomendamos a configuração ignore-daemonsets-utilization como true, que efetivamente ignora a utilização de nós por pods daemonset e minimiza operações desnecessárias de redução de escala. Veja o perfil para cargas de trabalho intermitentes
Exemplo 2: Otimização para custo
Se você quiser um perfil de custo otimizado, recomendamos definir as seguintes configurações de parâmetro:
- Reduzir
scale-down-unneeded-time, que é a quantidade de tempo que um nó deve ser desnecessário antes de ser elegível para redução de escala. - Reduzir
scale-down-delay-after-add, que é a quantidade de tempo de espera após a adição de um nó antes de considerá-lo para redução de escala. - Aumentar
scale-down-utilization-threshold, que é o limite de utilização para remover nós. - Aumentar
max-empty-bulk-delete, que é o número máximo de nós que podem ser excluídos em uma única chamada. - Defina
skip-nodes-with-local-storagecomo false. - Aumento
ok-total-unready-countemax-total-unready-percentage.
Problemas comuns e recomendações de mitigação
Visualize falhas de dimensionamento e eventos de escalonamento não acionados via CLI ou Portal.
Não acionar operações de aumento de escala
| Causas comuns | Recomendações de mitigação |
|---|---|
| Conflitos de afinidade de nó PersistentVolume, que podem surgir ao usar o autoscaler de cluster com várias zonas de disponibilidade ou quando a zona de um pod ou volume persistente difere da zona do nó. | Use um pool de nós por zona de disponibilidade e ative o --balance-similar-node-groups. Você também pode definir o volumeBindingMode campo como WaitForFirstConsumer na especificação do pod para evitar que o volume seja vinculado a um nó até que um pod usando o volume seja criado. |
| Manchas e tolerações/conflitos de afinidade de nós | Avalie as manchas atribuídas aos seus nós e reveja as tolerâncias definidas nos seus pods. Se necessário, faça ajustes nas manchas e tolerâncias para garantir que seus pods possam ser programados de forma eficiente em seus nós. |
Aumente a escala das falhas de operação
| Causas comuns | Recomendações de mitigação |
|---|---|
| Exaustão do endereço IP na sub-rede | Adicione outra sub-rede na mesma rede virtual e adicione outro pool de nós à nova sub-rede. |
| Esgotamento das quotas de base | A quota de base aprovada foi esgotada. Solicite um aumento de cota. O autoscaler de cluster entra em um estado de backoff exponencial dentro do grupo de nós específico quando ocorre várias tentativas de expansão com falha. |
| Tamanho máximo do pool de nós | Aumente os nós máximos no pool de nós ou crie um novo pool de nós. |
| Pedidos/chamadas que excedam o limite da tarifa | Veja 429 erros de solicitações demais. |
Reduza as falhas de operação
| Causas comuns | Recomendações de mitigação |
|---|---|
| Pod impedindo a drenagem do nó/Incapaz de remover o pod | • Veja que tipos de pods podem evitar a redução de escala. • Para pods que usam armazenamento local, como hostPath e emptyDir, defina o sinalizador skip-nodes-with-local-storage de perfil do autoscaler do cluster como false. • Na especificação do pod, defina a cluster-autoscaler.kubernetes.io/safe-to-evict anotação como true. • Verifique o seu APO, pois pode ser restritivo. |
| Tamanho mínimo do pool de nós | Reduza o tamanho mínimo do pool de nós. |
| Pedidos/chamadas que excedam o limite da tarifa | Veja 429 erros de solicitações demais. |
| Operações de gravação bloqueadas | Não faça nenhuma alteração no grupo de recursos AKS totalmente gerenciado (consulte as políticas de suporte do AKS). Remova ou redefina quaisquer bloqueios de recursos aplicados anteriormente ao grupo de recursos. |
Outros problemas
| Causas comuns | Recomendações de mitigação |
|---|---|
| PriorityConfigMapNotMatchedGroup | Certifique-se de adicionar todos os grupos de nós que exigem dimensionamento automático ao arquivo de configuração do expansor. |
Pool de nós em backoff
O pool de nós em backoff foi introduzido na versão 0.6.2 e faz com que o autoscaler de cluster recue do dimensionamento de um pool de nós após uma falha.
Dependendo de quanto tempo as operações de dimensionamento têm sofrido falhas, pode levar até 30 minutos antes de fazer outra tentativa. Você pode redefinir o estado de backoff do pool de nós desativando e reativando o dimensionamento automático.

Azure Kubernetes Service