Escalamento horizontal do Azure Analysis Services
Com a expansão, as consultas do cliente podem ser distribuídas entre várias réplicas de consulta em um pool de consultas, reduzindo os tempos de resposta durante cargas de trabalho de consulta altas. Você também pode separar o processamento do pool de consultas, garantindo que as consultas do cliente não sejam afetadas negativamente pelas operações de processamento. A expansão pode ser configurada no portal do Azure ou usando a API REST do Analysis Services.
O escalamento horizontal está disponível para servidores no escalão de preço Standard. As réplicas de consultas são faturadas com a mesma tarifa do servidor. As réplicas de consultas são criadas na mesma região do servidor. O número de réplicas de consultas que pode configurar é limitado pela região em que se encontra o servidor. Para saber mais, consulte Disponibilidade por região. A expansão não aumenta a quantidade de memória disponível para o servidor. Para aumentar a memória, tem de atualizar o plano.
Porquê expandir a escala?
Em uma implantação de servidor típica, um servidor serve como servidor de processamento e servidor de consulta. Se o número de consultas de cliente em modelos no servidor exceder as Unidades de Processamento de Consultas (QPU) para o plano do servidor, ou se o processamento do modelo ocorrer ao mesmo tempo que cargas de trabalho de consulta elevadas, o desempenho poderá diminuir.
Com a expansão, você pode criar um pool de consultas com até mais sete recursos de réplica de consulta (oito no total, incluindo o servidor primário ). Pode dimensionar o número de réplicas no conjunto de consultas para satisfazer as exigências de QPU em momentos críticos e pode separar um servidor de processamento do conjunto de consultas em qualquer altura.
Independentemente do número de réplicas de consulta que você tem em um pool de consultas, as cargas de trabalho de processamento não são distribuídas entre réplicas de consulta. O servidor primário serve como o servidor de processamento. As réplicas de consulta servem apenas consultas nos bancos de dados modelo sincronizados entre o servidor primário e cada réplica no pool de consultas.
Quando você expande, pode levar até cinco minutos para que novas réplicas de consulta sejam adicionadas incrementalmente ao pool de consultas. Quando todas as novas réplicas de consulta estão em execução, as novas conexões de cliente são balanceadas entre os recursos no pool de consultas. As conexões de cliente existentes não são alteradas do recurso ao qual estão conectadas no momento. Quando você dimensiona, todas as conexões de cliente existentes com um recurso de pool de consultas que está sendo removido do pool de consultas são encerradas. Os clientes podem se reconectar a um recurso de pool de consultas restante.
Como funciona
Quando você configura o dimensionamento pela primeira vez, os bancos de dados modelo no servidor primário são sincronizados automaticamente com novas réplicas em um novo pool de consultas. A sincronização automática ocorre apenas uma vez. Durante a sincronização automática, os arquivos de dados do servidor primário (criptografados em repouso no armazenamento de blobs) são copiados para um segundo local, também criptografados em repouso no armazenamento de blobs. As réplicas no pool de consultas são então hidratadas com dados do segundo conjunto de arquivos.
Embora uma sincronização automática seja executada somente quando você dimensiona um servidor pela primeira vez, você também pode executar uma sincronização manual. A sincronização garante que os dados em réplicas no pool de consultas correspondam aos do servidor primário. Ao processar (atualizar) modelos no servidor primário, uma sincronização deve ser executada após a conclusão das operações de processamento. Essa sincronização copia dados atualizados dos arquivos do servidor primário no armazenamento de blob para o segundo conjunto de arquivos. As réplicas no pool de consultas são então hidratadas com dados atualizados do segundo conjunto de arquivos no armazenamento de blobs.
Quando você executa uma operação de expansão subsequente, por exemplo, aumentando o número de réplicas no pool de consultas de duas para cinco, as novas réplicas são hidratadas com dados do segundo conjunto de arquivos no armazenamento de blobs. Não há sincronização. Se você executar uma sincronização após a expansão, as novas réplicas no pool de consultas serão hidratadas duas vezes - uma hidratação redundante. Ao executar uma operação de expansão subsequente, é importante ter em mente:
Execute uma sincronização antes da operação de expansão para evitar a hidratação redundante das réplicas adicionadas. Não são permitidas operações simultâneas de sincronização e expansão executadas ao mesmo tempo.
Ao automatizar as operações de processamento e expansão, é importante primeiro processar dados no servidor primário, depois executar uma sincronização e, em seguida, executar a operação de expansão. Esta sequência garante um impacto mínimo na QPU e nos recursos de memória.
Durante as operações de expansão, todos os servidores no pool de consultas, incluindo o servidor primário, ficam temporariamente offline.
A sincronização é permitida mesmo quando não há réplicas no pool de consultas. Se você estiver dimensionando de zero para uma ou mais réplicas com novos dados de uma operação de processamento no servidor primário, execute a sincronização primeiro sem réplicas no pool de consultas e, em seguida, dimensione. A sincronização antes da expansão evita a hidratação redundante das réplicas recém-adicionadas.
Quando você exclui um banco de dados modelo do servidor primário, ele não é excluído automaticamente das réplicas no pool de consultas. Tem de executar uma operação de sincronização com o comando Sync-AzAnalysisServicesInstance do PowerShell que remove os ficheiros dessa base de dados da localização de armazenamento de blobs partilhados da réplica e, em seguida, elimina a base de dados modelo nas réplicas do conjunto de consultas. Para determinar se existe um banco de dados modelo em réplicas no pool de consultas, mas não no servidor primário, verifique se a configuração Separar o servidor de processamento do pool de consultas é Sim. Em seguida, use o SQL Server Management Studio (SSMS) para se conectar ao servidor primário usando o
:rwqualificador para ver se o banco de dados existe. Em seguida, conecte-se a réplicas no pool de consultas conectando-se sem o:rwqualificador para ver se o mesmo banco de dados também existe. Se o banco de dados existir em réplicas no pool de consultas, mas não no servidor primário, execute uma operação de sincronização.Quando você renomeia um banco de dados no servidor primário, há outra etapa necessária para garantir que o banco de dados esteja sincronizado corretamente com quaisquer réplicas. Depois de renomear, execute uma sincronização usando o comando Sync-AzAnalysisServicesInstance especificando o
-Databaseparâmetro com o nome do banco de dados antigo. Essa sincronização remove o banco de dados e os arquivos com o nome antigo de todas as réplicas. Em seguida, execute outra sincronização especificando o-Databaseparâmetro com o novo nome do banco de dados. A segunda sincronização copia o banco de dados recém-nomeado para o segundo conjunto de arquivos e hidrata todas as réplicas. Essas sincronizações não podem ser executadas usando o comando Synchronize model no portal.
Modo de sincronização
Por padrão, as réplicas de consulta são reidratadas na íntegra, não incrementalmente. A reidratação acontece por etapas. Eles são separados e anexados dois de cada vez (supondo que haja pelo menos três réplicas) para garantir que pelo menos uma réplica seja mantida on-line para consultas a qualquer momento. Em alguns casos, os clientes podem precisar se reconectar a uma das réplicas on-line enquanto esse processo está ocorrendo. Usando a configuração ReplicaSyncMode, agora você pode especificar que a sincronização da réplica de consulta ocorre em paralelo. A sincronização paralela oferece os seguintes benefícios:
- Redução significativa no tempo de sincronização.
- É mais provável que os dados entre réplicas sejam consistentes durante o processo de sincronização.
- Uma vez que as bases de dados são mantidas online em todas as réplicas durante o processo de sincronização, os clientes não têm de restabelecer a ligação.
- O cache na memória é atualizado incrementalmente apenas com os dados alterados, o que pode ser mais rápido do que a reidratação completa do modelo.
Definindo ReplicaSyncMode
Use o SSMS para definir ReplicaSyncMode em Propriedades Avançadas. Os valores possíveis são:
1(padrão): reidratação completa do banco de dados de réplica em estágios (incremental).2: Sincronização otimizada em paralelo.
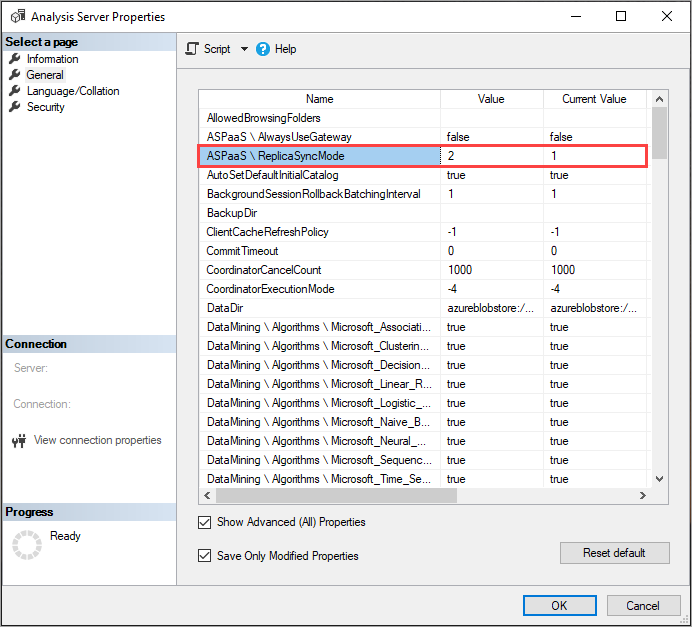
Ao definir ReplicaSyncMode=2, dependendo de quanto do cache precisa ser atualizado, mais memória pode ser consumida pelas réplicas de consulta. Para manter o banco de dados on-line e disponível para consultas, dependendo de quanto dos dados foram alterados, a operação pode exigir até o dobro da memória na réplica, pois os segmentos antigo e novo são mantidos na memória simultaneamente. Os nós de réplica têm a mesma alocação de memória que o nó primário e, normalmente, há memória extra no nó primário para operações de atualização, portanto, pode ser improvável que as réplicas fiquem sem memória. Além disso, o cenário comum é que o banco de dados é atualizado incrementalmente no nó primário e, portanto, o requisito para o dobro da memória deve ser incomum. Se a operação de sincronização encontrar um erro de falta de memória, ela tentará novamente usando a técnica padrão (anexar/desanexar dois de cada vez).
Processamento separado do pool de consultas
Para obter o máximo desempenho para operações de processamento e consulta, você pode optar por separar o servidor de processamento do pool de consultas. Quando separadas, novas conexões de cliente são atribuídas a réplicas de consulta somente no pool de consultas. Se as operações de processamento levarem apenas um curto período de tempo, você poderá optar por separar o servidor de processamento do pool de consultas somente pelo tempo necessário para executar as operações de processamento e sincronização e, em seguida, incluí-lo novamente no pool de consultas. Separar o servidor de processamento do pool de consultas ou adicioná-lo novamente ao pool de consultas pode levar até cinco minutos para que a operação seja concluída.
Monitorar o uso de QPU
Para determinar se a expansão do servidor é necessária, monitore as métricas do servidor no portal do Azure. Se a sua QPU atingir regularmente o máximo, isso significa que o número de consultas em relação aos seus modelos está excedendo o limite de QPU para o seu plano. A métrica de comprimento da fila de tarefas do pool de consultas também aumenta quando o número de consultas na fila do pool de threads de consulta excede a QPU disponível.
Outra boa métrica para observar é o QPU médio por ServerResourceType. Essa métrica compara a QPU média do servidor primário com o pool de consultas.
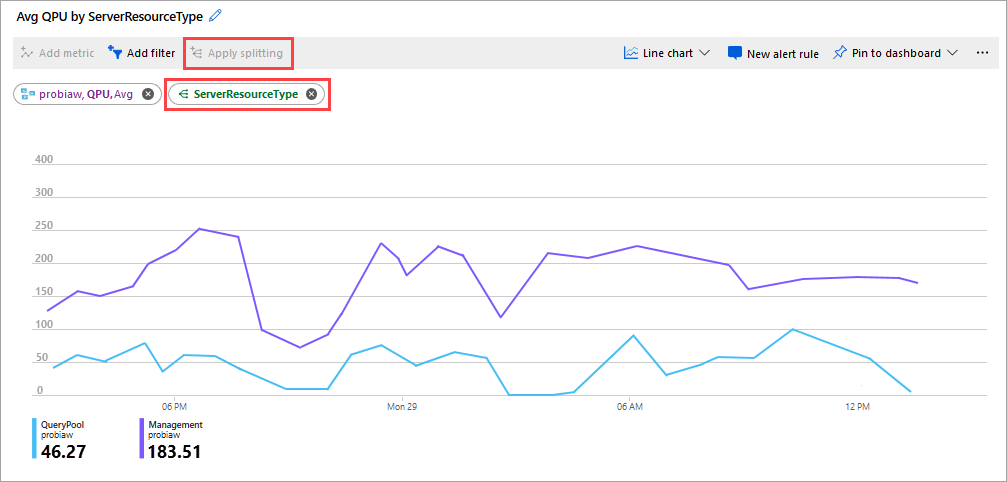
Para configurar a QPU por ServerResourceType
- Em um gráfico de linhas de métricas, clique em Adicionar métrica.
- Em RESOURCE, selecione seu servidor, em METRIC NAMESPACE, selecione Analysis Services standard metrics, em METRIC, selecione QPU e, em AGGREGATION, selecione Avg.
- Clique em Aplicar divisão.
- Em VALUES, selecione ServerResourceType.
Registo de diagnóstico detalhado
Use os Logs do Azure Monitor para diagnósticos mais detalhados dos recursos do servidor expandido. Com logs, você pode usar consultas do Log Analytics para dividir QPU e memória por servidor e réplica. Para obter mais informações, consulte Analisar logs no espaço de trabalho do Log Analytics. Para consultas de exemplo, consulte Consultas Kusto de exemplo.
Configurar o escalamento horizontal
No portal do Azure
No portal, clique em Expansão. Use o controle deslizante para selecionar o número de servidores de réplica de consulta. O número de réplicas escolhido é adicional ao servidor existente.
Em Separar o servidor de processamento do pool de consultas, selecione sim para excluir o servidor de processamento dos servidores de consulta. As conexões de cliente que usam a cadeia de conexão padrão (sem
:rw) são redirecionadas para réplicas no pool de consultas.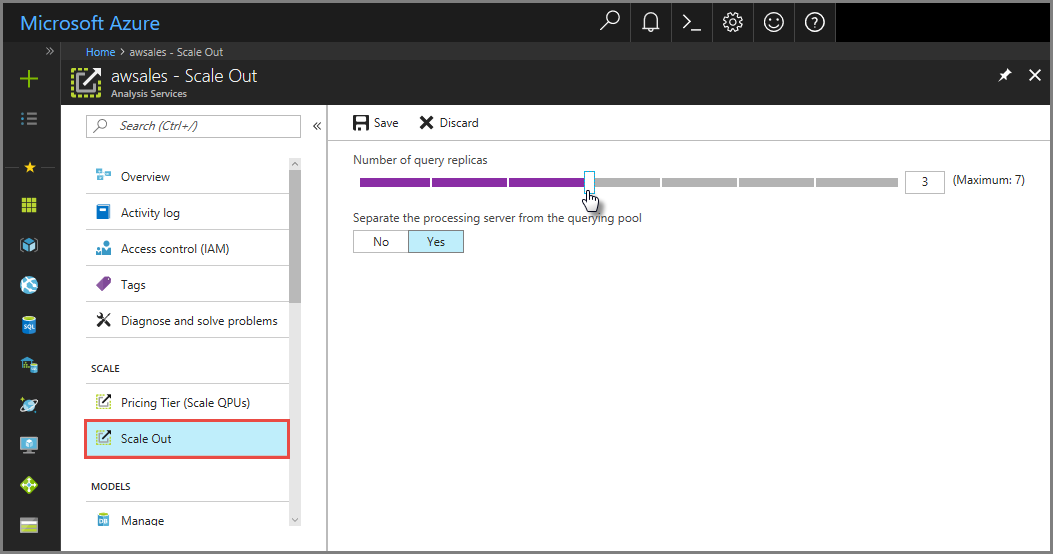
Clique em Salvar para provisionar seus novos servidores de réplica de consulta.
Quando você configura a expansão para um servidor pela primeira vez, os modelos no servidor primário são sincronizados automaticamente com réplicas no pool de consultas. A sincronização automática ocorre apenas uma vez, quando você configura o dimensionamento para uma ou mais réplicas pela primeira vez. Alterações subsequentes no número de réplicas no mesmo servidor não acionam outra sincronização automática. A sincronização automática não ocorrerá novamente, mesmo se você definir o servidor como zero réplicas e, em seguida, expandir novamente para qualquer número de réplicas.
Sincronizar
As operações de sincronização devem ser executadas manualmente ou usando a API REST.
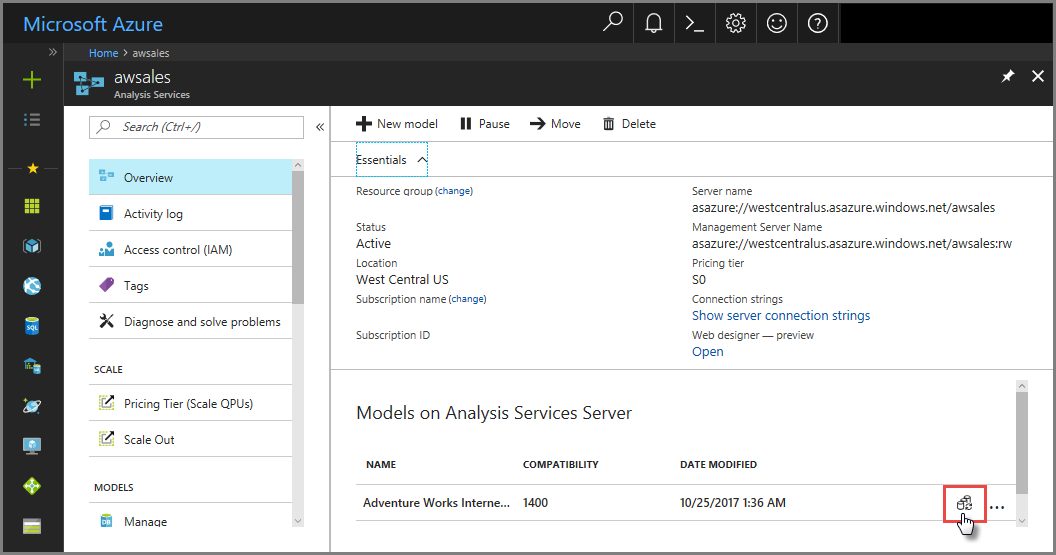
No portal do Azure
Em Visão geral> do modelo >Sincronize o modelo.
API REST
Use a operação de sincronização .
Sincronizar um modelo
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Obter status de sincronização
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Códigos de status de retorno:
| Código | Description |
|---|---|
| -1 | Inválido |
| 0 | Replicação |
| 1 | Reidratação |
| 2 | Concluído |
| 3 | Com falhas |
| 4 | Finalização |
PowerShell
Nota
Recomendamos que utilize o módulo Azure Az do PowerShell para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo do Az PowerShell, veja Migrar o Azure PowerShell do AzureRM para o Az.
Antes de usar o PowerShell, instale ou atualize o módulo mais recente do Azure PowerShell.
Para executar a sincronização, use Sync-AzAnalysisServicesInstance.
Para definir o número de réplicas de consulta, use Set-AzAnalysisServicesServer. Especifique o parâmetro opcional -ReadonlyReplicaCount .
Para separar o servidor de processamento do pool de consultas, use Set-AzAnalysisServicesServer. Especifique o parâmetro opcional -DefaultConnectionMode a ser usado Readonly.
Para saber mais, consulte Usando uma entidade de serviço com o módulo Az.AnalysisServices.
Ligações
Na página Visão geral do servidor, há dois nomes de servidor. Se você ainda não configurou a expansão para um servidor, ambos os nomes de servidor funcionam da mesma forma. Depois de configurar a expansão para um servidor, você precisa especificar o nome do servidor apropriado, dependendo do tipo de conexão.
Para conexões de cliente de usuário final, como Power BI Desktop, Excel e aplicativos personalizados, use Nome do servidor.
Para SSMS, Visual Studio e cadeias de conexão no PowerShell, aplicativos Azure Function e AMO, use o nome do servidor de gerenciamento. O nome do servidor de gerenciamento inclui um qualificador especial :rw (leitura-gravação). Todas as operações de processamento ocorrem no servidor de gerenciamento (principal).
Scale-up, Scale-down vs. Scale-out
Você pode alterar a camada de preços em um servidor com várias réplicas. O mesmo nível de preço se aplica a todas as réplicas. Uma operação de escala primeiro derruba todas as réplicas de uma só vez e, em seguida, exibe todas as réplicas no novo nível de preço.
Resolver problemas
Problema: os usuários recebem um erro que não conseguem encontrar a instância do servidor '<Nome do servidor>' no modo de conexão 'ReadOnly'.
Solução: Ao selecionar a opção Separar o servidor de processamento do pool de consultas, as conexões de cliente que usam a cadeia de conexão padrão (sem :rw) são redirecionadas para réplicas do pool de consultas. Se as réplicas no pool de consultas ainda não estiverem online porque a sincronização ainda não foi concluída, as conexões de cliente redirecionadas poderão falhar. Para evitar conexões com falha, deve haver pelo menos dois servidores no pool de consultas ao executar uma sincronização. Cada servidor é sincronizado individualmente, enquanto outros permanecem online. Se você optar por não ter o servidor de processamento no pool de consultas durante o processamento, poderá optar por removê-lo do pool para processamento e, em seguida, adicioná-lo novamente ao pool após a conclusão do processamento, mas antes da sincronização. Use métricas de memória e QPU para monitorar o status da sincronização.
Informações relacionadas
Monitorar o Azure Analysis ServicesGerenciar o Azure Analysis Services