Recuperação após desastre e distribuição geográfica no Azure Durable Functions
A Microsoft esforça-se por garantir que os serviços do Azure estão sempre disponíveis. No entanto, podem ocorrer falhas de serviço não planeadas. Se a sua aplicação necessitar de resiliência, a Microsoft recomenda a configuração da sua aplicação para georredundância. Além disso, os clientes devem ter um plano de recuperação após desastre implementado para lidar com uma falha do serviço regional. Uma parte importante de um plano de recuperação após desastre é preparar a ativação pós-falha para a réplica secundária da sua aplicação e armazenamento, caso a réplica primária fique indisponível.
No Durable Functions, todo o estado é mantido no Armazenamento do Azure por predefinição. Um hub de tarefas é um contentor lógico para recursos do Armazenamento do Azure que são utilizados para orquestrações e entidades. As funções de orquestrador, atividade e entidade só podem interagir entre si quando pertencem ao mesmo hub de tarefas. Este documento irá referir-se aos hubs de tarefas ao descrever cenários para manter estes recursos do Armazenamento do Azure altamente disponíveis.
Nota
A documentação de orientação neste artigo pressupõe que está a utilizar o fornecedor de Armazenamento do Azure predefinido para armazenar Durable Functions estado de runtime. No entanto, é possível configurar fornecedores de armazenamento alternativos que armazenam o estado noutro local, como uma base de dados SQL Server. Podem ser necessárias diferentes estratégias de recuperação após desastre e de distribuição geográfica para os fornecedores de armazenamento alternativos. Para obter mais informações sobre os fornecedores de armazenamento alternativos, veja a documentação Durable Functions fornecedores de armazenamento.
As orquestrações e entidades podem ser acionadas através de funções de cliente que são acionadas por HTTP ou um dos outros tipos de acionadores Funções do Azure suportados. Também podem ser acionadas com APIs HTTP incorporadas. Para simplificar, este artigo irá focar-se em cenários que envolvam acionadores de funções do Armazenamento do Microsoft Azure e baseados em HTTP e opções para aumentar a disponibilidade e minimizar o tempo de inatividade durante as atividades de recuperação após desastre. Outros tipos de acionadores, como o Service Bus ou os acionadores do Azure Cosmos DB, não serão explicitamente abrangidos.
Os cenários seguintes baseiam-se em configurações de Active-Passive, uma vez que são guiados pela utilização do Armazenamento do Azure. Este padrão consiste em implementar uma aplicação de função de cópia de segurança (passiva) numa região diferente. O Gestor de Tráfego monitorizará a aplicação de funções primária (ativa) para disponibilidade HTTP. A ativação pós-falha será efetuar a ativação pós-falha para a aplicação de funções de cópia de segurança se a principal falhar. Para obter mais informações, veja Método de Prioridade Traffic-Routing do Gestor de Tráfego do Azure.
Nota
- A configuração de Active-Passive proposta garante que um cliente é sempre capaz de acionar novas orquestrações através de HTTP. No entanto, como consequência de ter duas aplicações de funções a partilhar o mesmo hub de tarefas no armazenamento, algumas transações de armazenamento em segundo plano serão distribuídas entre ambas. Desta forma, esta configuração implica alguns custos de saída adicionados para a aplicação de funções secundárias.
- A conta de armazenamento subjacente e o hub de tarefas são criados na região primária e partilhados por ambas as aplicações de funções.
- Todas as aplicações de funções que são implementadas com redundância têm de partilhar as mesmas chaves de acesso de função no caso de serem ativadas através de HTTP. O Runtime de Funções expõe uma API de gestão que permite aos consumidores adicionar, eliminar e atualizar chaves de função programaticamente. A gestão de chaves também é possível com as APIs Resource Manager do Azure.
Cenário 1 – Computação com balanceamento de carga com armazenamento partilhado
Se a infraestrutura de computação no Azure falhar, a aplicação de funções poderá ficar indisponível. Para minimizar a possibilidade de um período de indisponibilidade, este cenário utiliza duas aplicações de funções implementadas em regiões diferentes. O Gestor de Tráfego está configurado para detetar problemas na aplicação de funções primária e redirecionar automaticamente o tráfego para a aplicação de funções na região secundária. Esta aplicação de funções partilha a mesma conta de Armazenamento do Azure e o Hub de Tarefas. Por conseguinte, o estado das aplicações de funções não é perdido e o trabalho pode ser retomado normalmente. Assim que o estado de funcionamento for restaurado para a região primária, o Gestor de Tráfego do Azure iniciará automaticamente o encaminhamento de pedidos para essa aplicação de funções.
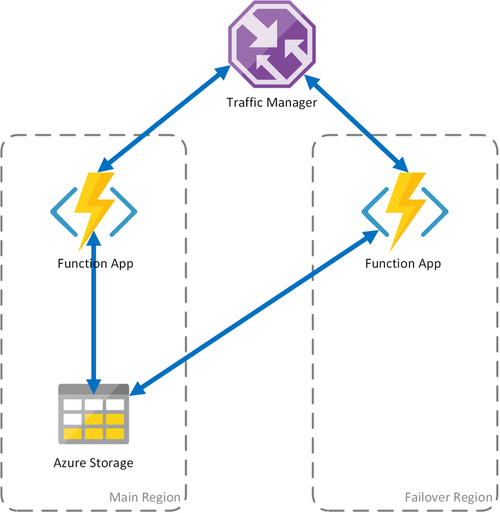
Existem várias vantagens ao utilizar este cenário de implementação:
- Se a infraestrutura de computação falhar, os trabalhos podem ser retomados na região de ativação pós-falha sem perda de dados.
- O Gestor de Tráfego trata automaticamente da ativação pós-falha automática para a aplicação de funções em bom estado de funcionamento.
- O Gestor de Tráfego restaure automaticamente o tráfego para a aplicação de função primária após a falha ter sido corrigida.
No entanto, ao utilizar este cenário, considere:
- Se a aplicação de funções for implementada com um plano de Serviço de Aplicações dedicado, replicar a infraestrutura de computação no datacenter de ativação pós-falha aumenta os custos.
- Este cenário abrange interrupções na infraestrutura de computação, mas a conta de armazenamento continua a ser o ponto único de falha para a aplicação de funções. Se ocorrer uma falha de armazenamento, a aplicação sofrerá um período de indisponibilidade.
- Se a aplicação de funções for efetuada a ativação pós-falha, haverá um aumento da latência, uma vez que acederá à respetiva conta de armazenamento entre regiões.
- O acesso ao serviço de armazenamento a partir de uma região diferente onde está localizado incorre em custos mais elevados devido ao tráfego de saída de rede.
- Este cenário depende do Gestor de Tráfego. Tendo em conta o funcionamento do Gestor de Tráfego, poderá demorar algum tempo até que uma aplicação cliente que consuma uma Função Durable tenha de consultar novamente o endereço da aplicação de funções do Gestor de Tráfego.
Nota
A partir da v2.3.0 da extensão Durable Functions, duas aplicações de funções podem ser executadas em segurança ao mesmo tempo com a mesma conta de armazenamento e configuração do hub de tarefas. A primeira aplicação a iniciar adquirirá uma concessão de blobs ao nível da aplicação que impede que outras aplicações roubem mensagens das filas do hub de tarefas. Se esta primeira aplicação deixar de ser executada, a concessão expirará e poderá ser adquirida por uma segunda aplicação, que irá, em seguida, prosseguir para processar mensagens do hub de tarefas.
Antes da v2.3.0, as aplicações de funções configuradas para utilizar a mesma conta de armazenamento processarão mensagens e atualizarão os artefactos de armazenamento em simultâneo, resultando em latências gerais e custos de saída muito mais elevados. Se as aplicações primárias e de réplica alguma vez tiverem código diferente implementado nas mesmas, mesmo temporariamente, as orquestrações também poderão não ser executadas corretamente devido a inconsistências das funções do orquestrador nas duas aplicações. Por conseguinte, é recomendado que todas as aplicações que necessitam de distribuição geográfica para fins de recuperação após desastre utilizem v2.3.0 ou superior da extensão Durable.
Cenário 2 – Computação com balanceamento de carga com armazenamento regional
O cenário anterior abrange apenas o caso de falha na infraestrutura de computação. Se o serviço de armazenamento falhar, resultará numa falha da aplicação de funções. Para garantir o funcionamento contínuo das funções duráveis, este cenário utiliza uma conta de armazenamento local em cada região para a qual as aplicações de funções são implementadas.
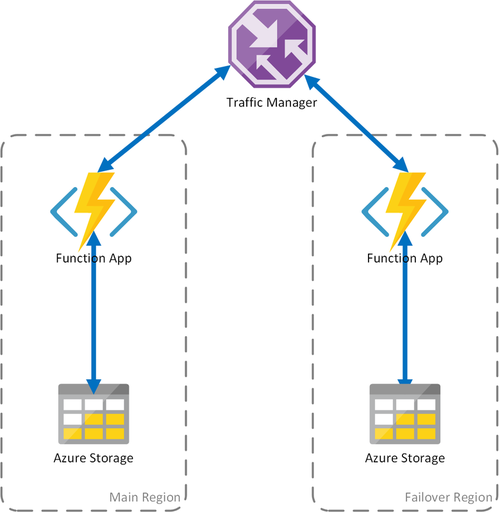
Esta abordagem adiciona melhorias no cenário anterior:
- Se a aplicação de funções falhar, o Gestor de Tráfego trata da ativação pós-falha para a região secundária. No entanto, como a aplicação de funções depende da sua própria conta de armazenamento, as funções duráveis continuam a funcionar.
- Durante uma ativação pós-falha, não existe latência adicional na região de ativação pós-falha, uma vez que a aplicação de funções e a conta de armazenamento estão colocadas.
- A falha da camada de armazenamento causará falhas nas funções duráveis, o que, por sua vez, irá acionar um redirecionamento para a região de ativação pós-falha. Uma vez que a aplicação de funções e o armazenamento estão isolados por região, as funções duráveis continuarão a funcionar.
Considerações importantes para este cenário:
- Se a aplicação de funções for implementada com um plano de Serviço de Aplicações dedicado, replicar a infraestrutura de computação no datacenter de ativação pós-falha aumenta os custos.
- O estado atual não é ativado com falhas, o que implica que as orquestrações e entidades existentes serão efetivamente colocadas em pausa e indisponíveis até que a região primária recupere.
Resumindo, a contrapartida entre o primeiro e o segundo cenário é que a latência é preservada e os custos de saída são minimizados, mas as orquestrações e entidades existentes ficarão indisponíveis durante o período de indisponibilidade. Se estas trocas são aceitáveis depende dos requisitos da aplicação.
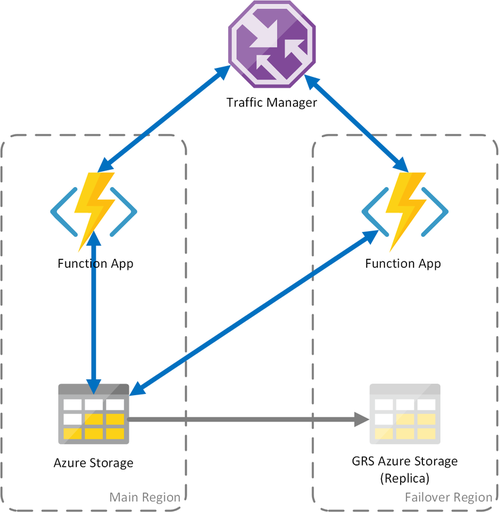
Cenário 3 – Computação com balanceamento de carga com armazenamento partilhado GRS
Este cenário é uma modificação ao longo do primeiro cenário, ao implementar uma conta de armazenamento partilhada. A principal diferença é que a conta de armazenamento é criada com a georreplicação ativada. Funcionalmente, este cenário fornece as mesmas vantagens que o Cenário 1, mas permite vantagens adicionais de recuperação de dados:
- O armazenamento georredundante (GRS) e o GRS de acesso de leitura (RA-GRS) maximizam a disponibilidade da sua conta de armazenamento.
- Se ocorrer uma indisponibilidade regional do serviço de Armazenamento, pode iniciar manualmente uma ativação pós-falha para a réplica secundária. Em circunstâncias extremas em que uma região se perde devido a um desastre significativo, a Microsoft pode iniciar uma ativação pós-falha regional. Neste caso, não é necessária nenhuma ação da sua parte.
- Quando ocorre uma ativação pós-falha, o estado das funções duráveis será preservado até à última replicação da conta de armazenamento, que normalmente ocorre a cada poucos minutos.
Tal como acontece com os outros cenários, existem considerações importantes:
- Uma ativação pós-falha para a réplica pode demorar algum tempo. Até que a ativação pós-falha seja concluída e os registos DNS do Armazenamento do Azure tenham sido atualizados, a aplicação de funções sofrerá uma falha.
- Existe um custo acrescido para a utilização de contas de armazenamento georreplicadas.
- A replicação GRS copia os seus dados de forma assíncrona. Algumas das transações mais recentes podem ser perdidas devido à latência do processo de replicação.
Nota
Conforme descrito no Cenário 1, recomenda-se vivamente que as aplicações de funções implementadas com esta estratégia utilizem v2.3.0 ou superior da extensão Durable Functions.
Para obter mais informações, veja a documentação de ativação pós-falha da conta de armazenamento e recuperação após desastre do Armazenamento do Azure .