Gerenciar dados históricos em tabelas temporais com política de retenção
Aplica-se a:![]() Banco de Dados SQL do Azure Instância Gerenciada SQL
Banco de Dados SQL do Azure Instância Gerenciada SQL![]() do Azure
do Azure
As tabelas temporais podem aumentar o tamanho do banco de dados mais do que as tabelas regulares, especialmente se você retiver dados históricos por um período de tempo mais longo. Portanto, a política de retenção de dados históricos é um aspeto importante do planejamento e do gerenciamento do ciclo de vida de cada tabela temporal. As tabelas temporais no Banco de Dados SQL do Azure e na Instância Gerenciada SQL do Azure vêm com um mecanismo de retenção fácil de usar que ajuda você a realizar essa tarefa.
A retenção do histórico temporal pode ser configurada no nível da tabela individual, o que permite que os usuários criem políticas flexíveis de envelhecimento. A aplicação da retenção temporal é simples: requer que apenas um parâmetro seja definido durante a criação da tabela ou a alteração do esquema.
Depois de definir a política de retenção, o Banco de Dados SQL do Azure e a Instância Gerenciada SQL do Azure começam a verificar regularmente se há linhas históricas qualificadas para limpeza automática de dados. A identificação de linhas correspondentes e sua remoção da tabela de histórico ocorrem de forma transparente, na tarefa em segundo plano agendada e executada pelo sistema. A condição de idade para as linhas da tabela de histórico é verificada com base na coluna que representa o final de SYSTEM_TIME período. Se o período de retenção, por exemplo, for definido como seis meses, as linhas da tabela elegíveis para limpeza satisfazem a seguinte condição:
ValidTo < DATEADD (MONTH, -6, SYSUTCDATETIME())
No exemplo anterior, assumimos que a coluna ValidTo corresponde ao final de SYSTEM_TIME período.
Como configurar a política de retenção
Antes de configurar a política de retenção para uma tabela temporal, verifique primeiro se a retenção histórica temporal está habilitada no nível do banco de dados.
SELECT is_temporal_history_retention_enabled, name
FROM sys.databases
O sinalizador de banco de dados is_temporal_history_retention_enabled é definido como ON por padrão, mas os usuários podem alterá-lo com a instrução ALTER DATABASE. Ele também é automaticamente definido como OFF após a operação de restauração point-in-time. Para habilitar a limpeza de retenção de histórico temporal para seu banco de dados, execute a seguinte instrução:
ALTER DATABASE [<myDB>]
SET TEMPORAL_HISTORY_RETENTION ON
Importante
Você pode configurar a retenção para tabelas temporais mesmo que is_temporal_history_retention_enabled esteja DESATIVADO, mas a limpeza automática para linhas antigas não é acionada nesse caso.
A política de retenção é configurada durante a criação da tabela especificando o valor para o parâmetro HISTORY_RETENTION_PERIOD:
CREATE TABLE dbo.WebsiteUserInfo
(
[UserID] int NOT NULL PRIMARY KEY CLUSTERED
, [UserName] nvarchar(100) NOT NULL
, [PagesVisited] int NOT NULL
, [ValidFrom] datetime2 (0) GENERATED ALWAYS AS ROW START
, [ValidTo] datetime2 (0) GENERATED ALWAYS AS ROW END
, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)
)
WITH
(
SYSTEM_VERSIONING = ON
(
HISTORY_TABLE = dbo.WebsiteUserInfoHistory,
HISTORY_RETENTION_PERIOD = 6 MONTHS
)
);
O Banco de Dados SQL do Azure e a Instância Gerenciada SQL do Azure permitem especificar o período de retenção usando unidades de tempo diferentes: DIAS, SEMANAS, MESES e ANOS. Se HISTORY_RETENTION_PERIOD for omitido, a retenção INFINITA será assumida. Você também pode usar a palavra-chave INFINITE explicitamente.
Em alguns cenários, convém configurar a retenção após a criação da tabela ou alterar o valor configurado anteriormente. Nesse caso, use a instrução ALTER TABLE:
ALTER TABLE dbo.WebsiteUserInfo
SET (SYSTEM_VERSIONING = ON (HISTORY_RETENTION_PERIOD = 9 MONTHS));
Importante
Definir SYSTEM_VERSIONING como OFF não preserva o valor do período de retenção. Definir SYSTEM_VERSIONING como ON sem HISTORY_RETENTION_PERIOD especificado explicitamente resulta no período de retenção INFINITE.
Para revisar o estado atual da política de retenção, use a seguinte consulta que une o sinalizador de ativação de retenção temporal no nível do banco de dados com períodos de retenção para tabelas individuais:
SELECT DB.is_temporal_history_retention_enabled,
SCHEMA_NAME(T1.schema_id) AS TemporalTableSchema,
T1.name as TemporalTableName, SCHEMA_NAME(T2.schema_id) AS HistoryTableSchema,
T2.name as HistoryTableName,T1.history_retention_period,
T1.history_retention_period_unit_desc
FROM sys.tables T1
OUTER APPLY (select is_temporal_history_retention_enabled from sys.databases
where name = DB_NAME()) AS DB
LEFT JOIN sys.tables T2
ON T1.history_table_id = T2.object_id WHERE T1.temporal_type = 2
Como as linhas antigas são excluídas
O processo de limpeza depende do layout de índice da tabela de histórico. É importante observar que apenas as tabelas de histórico com um índice clusterizado (árvore B ou columnstore) podem ter a política de retenção finita configurada. Uma tarefa em segundo plano é criada para executar a limpeza de dados antigos para todas as tabelas temporais com período de retenção finito. A lógica de limpeza para o índice clusterizado rowstore (árvore B) exclui a linha envelhecida em blocos menores (até 10K), minimizando a pressão no log do banco de dados e no subsistema de E/S. Embora a lógica de limpeza utilize o índice de árvore B necessário, a ordem das exclusões para as linhas anteriores ao período de retenção não pode ser firmemente garantida. Portanto, não dependa da ordem de limpeza em seus aplicativos.
A tarefa de limpeza para o columnstore clusterizado remove grupos de linhas inteiros de uma só vez (normalmente contêm 1 milhão de linhas cada), o que é muito eficiente, especialmente quando os dados históricos são gerados em um ritmo alto.
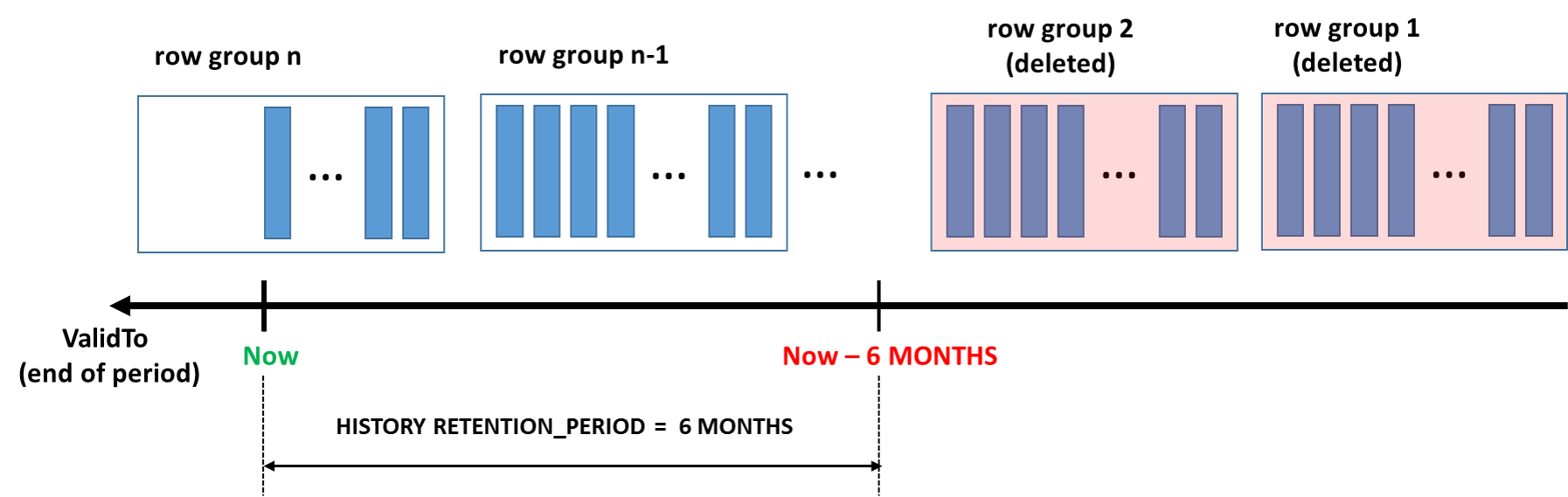
A excelente compactação de dados e a limpeza eficiente da retenção tornam o índice columnstore em cluster uma escolha perfeita para cenários em que sua carga de trabalho gera rapidamente uma grande quantidade de dados históricos. Esse padrão é típico para cargas de trabalho de processamento transacional intensivo que usam tabelas temporais para controle e auditoria de alterações, análise de tendências ou ingestão de dados de IoT.
Considerações sobre o índice
A tarefa de limpeza para tabelas com índice clusterizado de armazenamento de linhas requer que o índice comece com a coluna correspondente ao final de SYSTEM_TIME período. Se esse índice não existir, não será possível configurar um período de retenção finito:
Msg 13765, Nível 16, Estado 1
A definição do período de retenção finito falhou na tabela temporal com versão do sistema 'temporalstagetestdb.dbo.WebsiteUserInfo' porque a tabela de histórico 'temporalstagetestdb.dbo.WebsiteUserInfoHistory' não contém o índice clusterizado necessário. Considere a criação de um columnstore clusterizado ou um índice de árvore B começando com a coluna que corresponde ao final de SYSTEM_TIME período, na tabela de histórico.
É importante observar que a tabela de histórico padrão criada pelo Banco de Dados SQL do Azure e pela Instância Gerenciada SQL do Azure já tem índice clusterizado, que é compatível com a política de retenção. Se você tentar remover esse índice em uma tabela com período de retenção finito, a operação falhará com o seguinte erro:
Msg 13766, Nível 16, Estado 1
Não é possível descartar o índice clusterizado 'WebsiteUserInfoHistory.IX_WebsiteUserInfoHistory' porque ele está sendo usado para limpeza automática de dados antigos. Considere definir HISTORY_RETENTION_PERIOD como INFINITE na tabela temporal correspondente com versão do sistema se precisar descartar esse índice.
A limpeza no índice columnstore clusterizado funciona perfeitamente se as linhas históricas forem inseridas na ordem crescente (ordenadas pela coluna final do período), o que é sempre o caso quando a tabela de histórico é preenchida exclusivamente pelo mecanismo SYSTEM_VERSIONIOING. Se as linhas na tabela de histórico não forem ordenadas por coluna de fim de período (o que pode ser o caso se você migrou dados históricos existentes), você deverá recriar o índice columnstore clusterizado sobre o índice rowstore da árvore B que está ordenado corretamente, para obter o desempenho ideal.
Evite reconstruir o índice columnstore clusterizado na tabela de histórico com o período de retenção finito, pois ele pode alterar a ordem nos grupos de linhas naturalmente impostos pela operação de controle de versão do sistema. Se você precisar reconstruir o índice columnstore clusterizado na tabela de histórico, faça isso recriando-o sobre o índice de árvore B compatível, preservando a ordem nos grupos de linhas necessários para a limpeza regular de dados. A mesma abordagem deve ser adotada se você criar uma tabela temporal com a tabela de histórico existente que tenha índice de colunas clusterizadas sem ordem de dados garantida:
/*Create B-tree ordered by the end of period column*/
CREATE CLUSTERED INDEX IX_WebsiteUserInfoHistory ON WebsiteUserInfoHistory (ValidTo)
WITH (DROP_EXISTING = ON);
GO
/*Re-create clustered columnstore index*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_WebsiteUserInfoHistory ON WebsiteUserInfoHistory
WITH (DROP_EXISTING = ON);
Quando o período de retenção finito é configurado para a tabela de histórico com o índice columnstore clusterizado, não é possível criar índices adicionais de árvore B não clusterizados nessa tabela:
CREATE NONCLUSTERED INDEX IX_WebHistNCI ON WebsiteUserInfoHistory ([UserName])
Uma tentativa de executar a instrução acima falha com o seguinte erro:
Msg 13772, Nível 16, Estado 1
Não é possível criar um índice não clusterizado em uma tabela de histórico temporal 'WebsiteUserInfoHistory', pois ele tem um período de retenção finito e um índice columnstore clusterizado definido.
Consultando tabelas com política de retenção
Todas as consultas na tabela temporal filtram automaticamente as linhas históricas correspondentes à política de retenção finita, para evitar resultados imprevisíveis e inconsistentes, uma vez que as linhas antigas podem ser excluídas pela tarefa de limpeza, a qualquer momento e em ordem arbitrária.
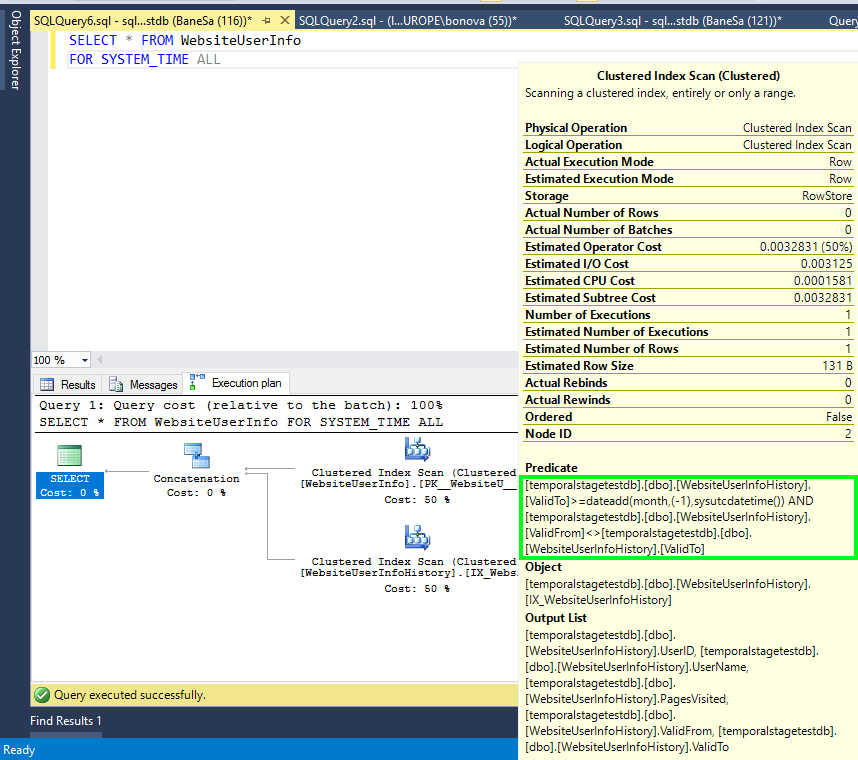
A imagem a seguir mostra o plano de consulta para uma consulta simples:
SELECT * FROM dbo.WebsiteUserInfo FOR SYSTEM_TIME ALL;
O plano de consulta inclui filtro adicional aplicado à coluna de fim de período (ValidTo) no operador Verificação de Índice Clusterizado na tabela de histórico (realçado). Este exemplo pressupõe que um período de retenção MONTH foi definido na tabela WebsiteUserInfo.
No entanto, se você consultar a tabela de histórico diretamente, poderá ver linhas mais antigas do que o período de retenção especificado, mas sem qualquer garantia de resultados de consulta repetíveis. A imagem a seguir mostra o plano de execução da consulta na tabela de histórico sem filtros adicionais aplicados:
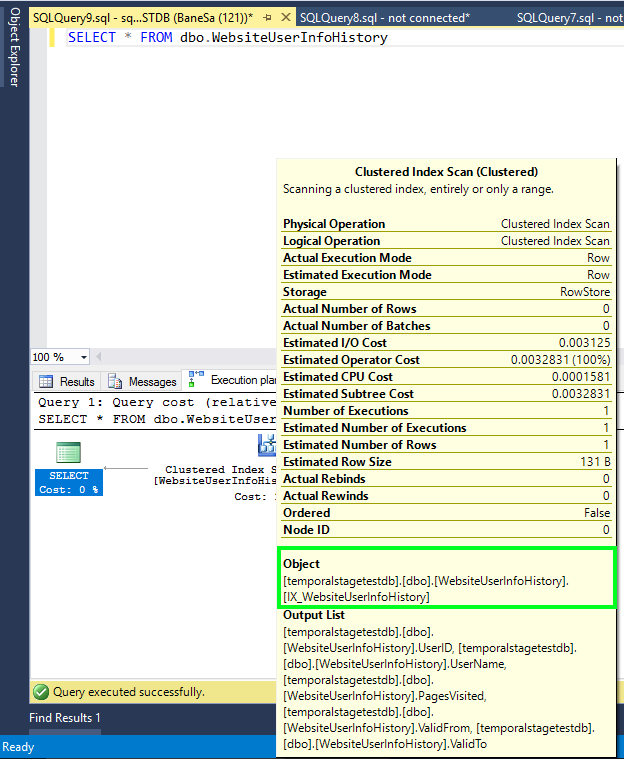
Não confie em sua lógica de negócios na leitura da tabela de histórico além do período de retenção, pois você pode obter resultados inconsistentes ou inesperados. Recomendamos que você use consultas temporais com a cláusula FOR SYSTEM_TIME para analisar dados em tabelas temporais.
Considerações sobre restauração point-in-time
Quando você cria um novo banco de dados restaurando o banco de dados existente para um point-in-time específico, ele tem a retenção temporal desabilitada no nível do banco de dados. (is_temporal_history_retention_enabled sinalizador definido como OFF). Essa funcionalidade permite que você examine todas as linhas históricas após a restauração, sem se preocupar que as linhas antigas sejam removidas antes de você consultá-las. Você pode usá-lo para inspecionar dados históricos além do período de retenção configurado.
Digamos que uma tabela temporal tenha um período de retenção de MÊS especificado. Se o banco de dados tiver sido criado na camada de Serviço Premium, você poderá criar uma cópia do banco de dados com o estado do banco de dados até 35 dias atrás. Isso efetivamente permitiria que você analisasse linhas históricas com até 65 dias consultando diretamente a tabela de histórico.
Se você quiser ativar a limpeza de retenção temporal, execute a seguinte instrução Transact-SQL após a restauração point-in-time:
ALTER DATABASE [<myDB>]
SET TEMPORAL_HISTORY_RETENTION ON
Próximos passos
Para saber como usar tabelas temporais em seus aplicativos, confira Introdução às tabelas temporais.
Para obter informações detalhadas sobre tabelas temporais, consulte Tabelas temporais.