Gerenciar espaço de arquivo para bancos de dados na Instância Gerenciada SQL do Azure
Aplica-se a:![]() Instância Gerenciada SQL do Azure
Instância Gerenciada SQL do Azure
Este artigo aborda como monitorar e gerenciar arquivos em bancos de dados na Instância Gerenciada SQL do Azure. Analisamos como monitorar o tamanho do arquivo de banco de dados, reduzir o log de transações, ampliar um arquivo de log de transações e controlar o crescimento de um arquivo de log de transações.
Este artigo aplica-se à Instância Gerida SQL do Azure. Embora muito semelhante, para obter informações sobre como gerenciar o tamanho dos arquivos de log de transações no SQL Server, consulte Gerenciar o tamanho do arquivo de log de transações.
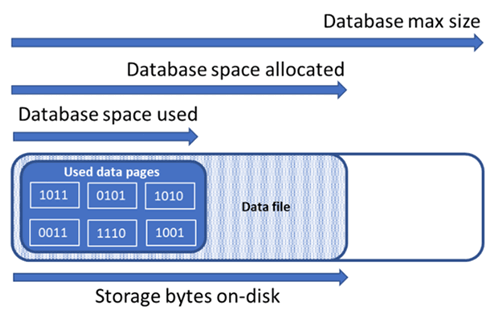
Compreender os tipos de espaço de armazenamento para um banco de dados
Compreender as seguintes quantidades de espaço de armazenamento é importante para gerenciar o espaço de arquivo de um banco de dados.
| Quantidade de bases de dados | Definição | Comentários |
|---|---|---|
| Espaço de dados utilizado | A quantidade de espaço usada para armazenar dados do banco de dados. | Geralmente, o espaço utilizado aumenta (diminui) nas inserções (elimina). Em alguns casos, o espaço utilizado não muda nas inserções ou exclusões dependendo da quantidade e padrão de dados envolvidos na operação e de qualquer fragmentação. Por exemplo, eliminar uma linha de cada página de dados não diminui necessariamente o espaço utilizado. |
| Espaço de dados alocado | A quantidade de espaço de ficheiros formatados disponibilizada para armazenar dados de bases de dados. | A quantidade de espaço alocado aumenta automaticamente, mas nunca diminui após eliminações. Esse comportamento garante que as inserções futuras sejam mais rápidas, já que o espaço não precisa ser reformatado. |
| Espaço de dados atribuído, mas não utilizado | A diferença entre a quantidade de espaço de dados alocado e o espaço de dados utilizado. | Essa quantidade representa a quantidade máxima de espaço livre que pode ser recuperada reduzindo os arquivos de dados do banco de dados. |
| Tamanho máximo dos dados | A quantidade máxima de espaço que pode ser usada para armazenar dados do banco de dados. | A quantidade de espaço de dados alocado não pode ultrapassar o tamanho máximo dos dados. |
O diagrama a seguir ilustra a relação entre os diferentes tipos de espaço de armazenamento para um banco de dados.
Consultar um único banco de dados para obter informações de espaço de arquivo
Use a consulta a seguir no sys.database_files para retornar a quantidade de espaço de arquivo de banco de dados alocado e a quantidade de espaço não utilizado alocado. As unidades do resultado da consulta estão em MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Monitorar o uso do espaço de log
Monitore o uso do espaço de log usando sys.dm_db_log_space_usage. Esse Detran retorna informações sobre a quantidade de espaço de log usado atualmente e indica quando o log de transações precisa de truncamento.
Para obter informações sobre o tamanho atual do arquivo de log, seu tamanho máximo e a opção de crescimento automático para o arquivo, você também pode usar as sizecolunas , max_sizee growth para esse arquivo de log no sys.database_files.
As métricas de espaço de armazenamento exibidas nas APIs de métricas baseadas no Azure Resource Manager medem apenas o tamanho das páginas de dados usadas. Para obter exemplos, consulte PowerShell get-metrics.
Reduzir o tamanho do arquivo de log
Para reduzir o tamanho físico de um arquivo de log físico removendo o espaço não utilizado, reduza o arquivo de log. Uma redução só faz diferença quando um arquivo de log de transações contém espaço não utilizado. Se o arquivo de log estiver cheio, provavelmente devido a transações abertas, investigue o que está impedindo o truncamento do log de transações.
Atenção
As operações de encolhimento não devem ser consideradas uma operação de manutenção regular. Os arquivos de dados e de log que crescem devido a operações comerciais regulares e recorrentes não exigem operações de redução. O comando de redução afeta o desempenho da base de dados durante a execução e, se possível, deve ser executado durante períodos de baixa utilização. Não é aconselhável encolher ficheiros de dados se a carga de trabalho regular das aplicações fizer com que os ficheiros voltem a aumentar para o mesmo tamanho alocado.
Esteja ciente do potencial impacto negativo no desempenho da redução de arquivos de banco de dados, consulte Manutenção do índice após a redução. Em casos raros, as operações de redução podem ser afetadas por backups automatizados de banco de dados. Se necessário, tente novamente a operação de redução.
Antes de reduzir o log de transações, lembre-se de Fatores que podem atrasar o truncamento do log. Se o espaço de armazenamento for necessário novamente após uma redução de log, o log de transações crescerá novamente e, ao fazer isso, introduzirá sobrecarga de desempenho durante as operações de crescimento de log. Para obter mais informações, consulte as Recomendações.
Você pode reduzir um arquivo de log somente enquanto o banco de dados estiver online e pelo menos um arquivo de log virtual (VLF) estiver livre. Em alguns casos, reduzir o log pode não ser possível até depois do próximo truncamento de log.
Fatores, como uma transação de longa duração, podem manter os VLFs ativos por um longo período, podem restringir a redução do log ou até mesmo impedir que o log diminua. Para obter informações, consulte Fatores que podem atrasar o truncamento do log.
A redução de um arquivo de log remove um ou mais VLFs que não contêm nenhuma parte do log lógico (ou seja, VLFs inativos). Quando você reduz um arquivo de log de transações, VLFs inativos são removidos do final do arquivo de log para reduzir o log para aproximadamente o tamanho de destino.
Para obter mais informações sobre operações de redução, analise o seguinte:
Reduzir um arquivo de log (sem reduzir os arquivos do banco de dados)
Monitorar eventos de redução de arquivos de log
- Classe de evento Auto Shrink do arquivo de log.
Monitorar o espaço de log
sys.database_files (Transact-SQL) (Consulte as
sizecolunas ,max_sizee para o(s) arquivo(s) degrowthlog ou arquivos.)
Manutenção do índice após a redução
Depois que uma operação de redução é concluída em relação aos arquivos de dados, os índices podem ficar fragmentados. Isso reduz a eficácia da otimização de desempenho para determinadas cargas de trabalho, como consultas usando verificações grandes. Se ocorrer degradação do desempenho após a conclusão da operação de redução, considere a manutenção do índice para reconstruir os índices. Tenha em mente que as reconstruções de índice exigem espaço livre no banco de dados e, portanto, podem fazer com que o espaço alocado aumente, neutralizando o efeito de encolhimento.
Para obter mais informações sobre a manutenção do índice, consulte Otimizar a manutenção do índice para melhorar o desempenho da consulta e reduzir o consumo de recursos.
Avaliar a densidade da página de índice
Se truncar arquivos de dados não resultou em uma redução suficiente no espaço alocado, você pode decidir reduzir os arquivos de dados do banco de dados para recuperar o espaço não utilizado desses arquivos. No entanto, como uma etapa opcional, mas recomendada, você deve primeiro determinar a densidade média de páginas para índices no banco de dados. Para a mesma quantidade de dados, a redução será concluída mais rapidamente se a densidade da página for alta, porque terá que mover menos páginas. Se a densidade de página for baixa para alguns índices, considere executar a manutenção nesses índices para aumentar a densidade de página antes de reduzir os arquivos de dados. Isso também permitirá que o shrink obtenha uma redução mais profunda no espaço de armazenamento alocado.
Para determinar a densidade de página para todos os índices no banco de dados, use a consulta a seguir. A densidade da página é relatada avg_page_space_used_in_percent na coluna.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Se houver índices com alta contagem de páginas com densidade de página inferior a 60-70%, considere reconstruir ou reorganizar esses índices antes de reduzir os arquivos de dados.
Nota
Para bancos de dados maiores, a consulta para determinar a densidade da página pode levar muito tempo (horas) para ser concluída. Além disso, reconstruir ou reorganizar grandes índices também requer tempo substancial e uso de recursos. Há uma compensação entre gastar tempo extra no aumento da densidade de páginas, por um lado, e reduzir a duração da redução e obter maiores economias de espaço, por outro.
Se houver vários índices com baixa densidade de página, você poderá reconstruí-los em paralelo em várias sessões de banco de dados para acelerar o processo. No entanto, certifique-se de que você não está se aproximando dos limites de recursos do banco de dados fazendo isso e deixe espaço suficiente para cargas de trabalho de aplicativos que possam estar em execução. Monitore o consumo de recursos (CPU, E/S de Dados, E/S de Log) no portal do Azure ou usando o modo de exibição sys.dm_db_resource_stats e inicie reconstruções paralelas adicionais somente se a utilização de recursos em cada uma dessas dimensões permanecer substancialmente inferior a 100%. Se a utilização de CPU, E/S de dados ou E/S de log estiver em 100%, você poderá dimensionar o banco de dados para ter mais núcleos de CPU e aumentar a taxa de transferência de E/S. Isso pode permitir reconstruções paralelas adicionais para concluir o processo mais rapidamente.
Exemplo de comando de reconstrução de índice
A seguir está um comando de exemplo para reconstruir um índice e aumentar sua densidade de página, usando a instrução ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Este comando inicia uma reconstrução de índice online e retomável. Isso permite que cargas de trabalho simultâneas continuem usando a tabela enquanto a reconstrução está em andamento e permite que você retome a reconstrução se ela for interrompida por qualquer motivo. No entanto, esse tipo de reconstrução é mais lento do que uma reconstrução offline, que bloqueia o acesso à tabela. Se nenhuma outra carga de trabalho precisar acessar a tabela durante a reconstrução, defina as ONLINE opções e para OFF e RESUMABLE remova a WAIT_AT_LOW_PRIORITY cláusula.
Para saber mais sobre a manutenção do índice, consulte Otimizar a manutenção do índice para melhorar o desempenho da consulta e reduzir o consumo de recursos.
Reduzir vários arquivos de dados
Como observado anteriormente, reduzir com a movimentação de dados é um processo de longa duração. Se o banco de dados tiver vários arquivos de dados, você pode acelerar o processo reduzindo vários arquivos de dados em paralelo. Para fazer isso, abra várias sessões de banco de dados e use DBCC SHRINKFILE em cada sessão com um valor diferente file_id . Semelhante à reconstrução de índices anteriormente, certifique-se de ter espaço suficiente para recursos (CPU, E/S de dados, E/S de log) antes de iniciar cada novo comando de redução paralela.
O comando de exemplo a seguir reduz o arquivo de dados com file_id 4, tentando reduzir seu tamanho alocado para 52.000 MB movendo páginas dentro do arquivo:
DBCC SHRINKFILE (4, 52000);
Se você quiser reduzir o espaço alocado para o arquivo ao mínimo possível, execute a instrução sem especificar o tamanho de destino:
DBCC SHRINKFILE (4);
Se uma carga de trabalho estiver sendo executada simultaneamente com a redução, ela poderá começar a usar o espaço de armazenamento liberado pela redução antes que a redução seja concluída e trunce o arquivo. Nesse caso, a redução não será capaz de reduzir o espaço alocado para o destino especificado.
Você pode atenuar isso reduzindo cada arquivo em etapas menores. Isso significa que, no DBCC SHRINKFILE comando, você define o destino que é um pouco menor do que o espaço alocado atual para o arquivo. Por exemplo, se o espaço alocado para o arquivo com file_id 4 for de 200.000 MB e você quiser reduzi-lo para 100.000 MB, você pode primeiro definir o destino para 170.000 MB:
DBCC SHRINKFILE (4, 170000);
Quando esse comando for concluído, ele terá truncado o arquivo e reduzido seu tamanho alocado para 170.000 MB. Em seguida, você pode repetir esse comando, definindo o destino primeiro para 140.000 MB, depois para 110.000 MB, etc., até que o arquivo seja reduzido para o tamanho desejado. Se o comando for concluído, mas o arquivo não estiver truncado, use etapas menores, por exemplo, 15.000 MB em vez de 30.000 MB.
Para monitorar o progresso da redução para todas as sessões de redução em execução simultânea, você pode usar a seguinte consulta:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Nota
O progresso da redução pode ser não-linear, e o valor na coluna pode permanecer praticamente inalterado por longos períodos de tempo, mesmo que a percent_complete redução ainda esteja em andamento.
Quando a redução for concluída para todos os arquivos de dados, use a consulta de uso de espaço para determinar a redução resultante no tamanho de armazenamento alocado. Se ainda houver uma grande diferença entre o espaço usado e o espaço alocado, você poderá reconstruir índices. Isso pode aumentar temporariamente o espaço alocado ainda mais, no entanto, reduzir os arquivos de dados novamente após a reconstrução dos índices deve resultar em uma redução mais profunda no espaço alocado.
Ampliar um arquivo de log
Na Instância Gerenciada SQL do Azure, adicione espaço a um arquivo de log ampliando o arquivo de log existente (se o espaço em disco permitir). Não há suporte para a adição de um arquivo de log ao banco de dados. Um arquivo de log de transações é suficiente, a menos que o espaço de log esteja se esgotando e o espaço em disco também esteja se esgotando no volume que contém o arquivo de log.
Para ampliar o arquivo de log, use a MODIFY FILE ALTER DATABASE cláusula da instrução, especificando a SIZE sintaxe e MAXSIZE . Para obter mais informações, consulte Opções de arquivo e grupo de arquivos ALTER DATABASE (Transact-SQL).
Para obter mais informações, consulte as Recomendações.
Controlar o crescimento do arquivo de log de transações
Use a instrução ALTER DATABASE (Transact-SQL) File and Filegroup options para gerenciar o crescimento de um arquivo de log de transações. Tenha em atenção o seguinte:
- Para alterar o tamanho atual do arquivo em unidades KB, MB, GB e TB, use a
SIZEopção. - Para alterar o incremento de crescimento, use a
FILEGROWTHopção. Um valor 0 indica que o crescimento automático está desativado e não é permitido espaço adicional. - Para controlar o tamanho máximo de um arquivo de log em unidades KB, MB, GB e TB ou para definir o crescimento como UNLIMITED, use a
MAXSIZEopção.
Recomendações
A seguir estão algumas recomendações gerais quando você estiver trabalhando com arquivos de log de transações:
O incremento de crescimento automático (crescimento automático) do log de transações, conforme definido pela
FILEGROWTHopção, deve ser grande o suficiente para ficar à frente das necessidades das transações de carga de trabalho. O incremento de crescimento de arquivo em um arquivo de log deve ser suficientemente grande para evitar expansão frequente. Um bom ponteiro para dimensionar corretamente um log de transações é monitorar a quantidade de log ocupado durante:- O tempo necessário para executar um backup completo, porque os backups de log não podem ocorrer até que ele seja concluído.
- O tempo necessário para as maiores operações de manutenção do índice.
- O tempo necessário para executar o maior lote em um banco de dados.
Ao definir o crescimento automático para dados e arquivos de log usando a opção, pode ser preferível defini-lo em
sizevez de , para permitir um melhor controle sobre a taxa depercentagecrescimento, já que aFILEGROWTHporcentagem é uma quantidade cada vez maior.- Na Instância Gerenciada SQL do Azure, a inicialização instantânea de arquivos pode beneficiar eventos de crescimento do log de transações de até 64 MB. O incremento de tamanho de crescimento automático padrão para novos bancos de dados é de 64 MB. Os eventos de crescimento automático do arquivo de log de transações maiores que 64 MB não podem se beneficiar da inicialização instantânea do arquivo.
- Como prática recomendada, não defina o valor da
FILEGROWTHopção acima de 1.024 MB para logs de transações.
Um pequeno incremento de crescimento automático pode gerar muitos VLFs pequenos e pode reduzir o desempenho. Para determinar a distribuição VLF ideal para o tamanho atual do log de transações de todos os bancos de dados em uma determinada instância e os incrementos de crescimento necessários para atingir o tamanho necessário, consulte este script para analisar e corrigir VLFs, fornecido pela Equipe SQL Tiger.
Um grande incremento de crescimento automático pode causar dois problemas:
- Um grande incremento de crescimento automático pode fazer com que o banco de dados pause enquanto o novo espaço é alocado, potencialmente causando tempos limite de consulta.
- Um grande incremento de crescimento automático pode gerar poucos e grandes VLFs e também pode afetar o desempenho. Para determinar a distribuição VLF ideal para o tamanho atual do log de transações de todos os bancos de dados em uma determinada instância e os incrementos de crescimento necessários para atingir o tamanho necessário, consulte este script para analisar e corrigir VLFs, fornecido pela Equipe SQL Tiger.
Mesmo com o crescimento automático ativado, você pode receber uma mensagem informando que o log de transações está cheio, se ele não puder crescer rápido o suficiente para satisfazer as necessidades da sua consulta. Para obter mais informações sobre como alterar o incremento de crescimento, consulte Opções de arquivo e grupo de arquivos ALTER DATABASE (Transact-SQL).
Os arquivos de log podem ser configurados para diminuir automaticamente. No entanto, isso não é recomendado e a propriedade de banco de dados auto_shrink é definida como FALSE por padrão. Se auto_shrink estiver definido como TRUE, a redução automática reduz o tamanho de um arquivo somente quando mais de 25% de seu espaço não é utilizado.
- O arquivo é reduzido para o tamanho no qual apenas 25% do arquivo é espaço não utilizado ou para o tamanho original do arquivo, o que for maior.
- Para obter informações sobre como alterar a configuração da propriedade auto_shrink, consulte Exibir ou alterar as propriedades de um banco de dados e ALTER DATABASE SET Options (Transact-SQL).
Próximos passos
- Backups automatizados na Instância Gerenciada SQL do Azure
- ALTER DATABASE (Transact-SQL) File and Filegroup options (Opções ALTER DATABASE (Transact-SQL) dos Ficheiros e Grupos de Ficheiros)
- Descrição geral dos limites de recursos do Azure SQL Managed Instance
- Solucionar erros de log de transações com a Instância Gerenciada SQL do Azure