Disponibilidade por meio de redundância local e de zona - Instância Gerenciada SQL do Azure
Aplica-se a:![]() Instância Gerida do SQL do Azure
Instância Gerida do SQL do Azure
Este artigo descreve a arquitetura da Instância Gerenciada SQL do Azure que alcança disponibilidade por meio de redundância local e alta disponibilidade por meio de redundância de zona.
Importante
A configuração com redundância de zona está em pré-visualização pública para a camada de serviço de Uso Geral e disponível de forma geral para a camada de serviço Crítica de Negócios.
Visão geral
A Instância Gerenciada SQL é executada na versão estável mais recente do mecanismo de banco de dados do SQL Server no sistema operacional Windows com todos os patches aplicáveis. A Instância Gerenciada SQL lida automaticamente com tarefas críticas de manutenção, como patches, backups, atualizações do mecanismo de banco de dados Windows e SQL e eventos não planejados, como falhas subjacentes de hardware, software ou rede. Quando uma instância é corrigida ou faz failover, o tempo de inatividade não é afetado se você empregar lógica de repetição em seu aplicativo. A Instância Gerenciada SQL pode se recuperar rapidamente mesmo nas circunstâncias mais críticas, garantindo que seus dados estejam sempre disponíveis. A maioria dos usuários não percebe que as atualizações são realizadas continuamente.
Por padrão, a Instância Gerenciada SQL do Azure alcança de disponibilidade por meio de redundância local, disponibilizando sua instância durante:
- Operações de gestão iniciadas pelo cliente que resultam numa breve interrupção
- Operações de manutenção de serviços
- Problemas e interrupções do data center com:
- Rack onde as máquinas que alimentam o seu serviço estão a funcionar.
- Máquina física que hospeda a VM que executa o mecanismo de banco de dados SQL.
- Máquina virtual que executa o mecanismo de banco de dados SQL
- Outros problemas com o mecanismo de banco de dados SQL
- Outras possíveis interrupções locais não planejadas
A solução de disponibilidade padrão foi projetada para garantir que os dados confirmados nunca sejam perdidos devido a falhas, que as operações de manutenção não afetem sua carga de trabalho e que a instância não seja um único ponto de falha em sua arquitetura de software.
No entanto, para minimizar o impacto em seus dados no caso de uma interrupção em uma zona inteira, você pode obter de alta disponibilidade habilitando a redundância de zona. Sem redundância de zona, os failovers acontecem localmente no mesmo data center, o que pode resultar na indisponibilidade da instância até que a interrupção seja resolvida - a única maneira de recuperar é por meio de uma solução de recuperação de desastres, como por meio de um grupo de failover
A alta disponibilidade aumenta a confiabilidade do seu serviço, protegendo-o do impacto sobre:
- Zona de disponibilidade que forma o data center
Existem dois modelos diferentes de arquitetura de disponibilidade com base na camada de serviço:
- O modelo de armazenamento remoto
baseia-se em uma separação de computação e armazenamento nas camadas de serviço de Uso Geral e de Uso Geral de Próxima Geração que depende da disponibilidade e confiabilidade do de armazenamento remoto e da disponibilidade de clusters de computação gerenciados pelodo Azure Service Fabric . Esse modelo de disponibilidade tem como alvo aplicativos de negócios orientados a orçamento que podem tolerar alguma degradação do desempenho durante as atividades de manutenção. - O modelo de armazenamento local é baseado num cluster de processos de motores de base de dados que dependem de um quórum de nós de motores de base de dados disponíveis no de camada de serviço Business Critical que têm armazenamento local. Esse modelo de armazenamento local tem como alvo aplicativos de missão crítica que têm uma alta taxa de transações e exigem alto desempenho de E/S. A arquitetura de alta disponibilidade garante um impacto mínimo no desempenho da sua carga de trabalho durante as atividades de manutenção.
Para obter mais informações sobre SLAs específicos para diferentes camadas de serviço, consulte SLA para Instância Gerenciada SQL do Azure.
Disponibilidade através de redundância local
A disponibilidade localmente redundante baseia-se no armazenamento de nós de computação e dados em um único datacenter na região primária e protege seus dados em caso de falha local, como uma rede de pequena escala ou falha de energia. Se ocorrer um desastre de grande escala, como incêndio ou inundação, em uma região, todas as réplicas de uma conta de armazenamento ou dados nos nós de computação poderão ser perdidos ou irrecuperáveis. Como tal, para proteger ainda mais seus dados ao usar a opção de disponibilidade localmente redundante, considere usar uma opção de armazenamento mais resiliente para seus backups de banco de dados .
Nível de serviço de uso geral
A camada de serviço de uso geral usa a arquitetura de disponibilidade de armazenamento remoto. A figura a seguir mostra quatro nós diferentes com as camadas de computação e armazenamento separadas.
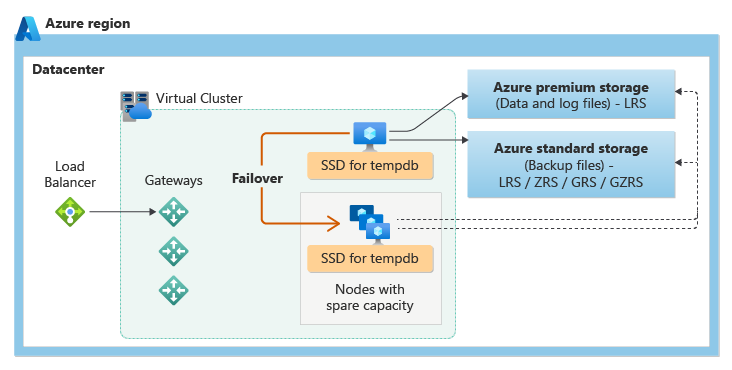
O modelo de disponibilidade de armazenamento remoto inclui duas camadas:
- Uma camada de computação sem estado que executa o processo do mecanismo de banco de dados e contém apenas dados transitórios e armazenados em cache, como os bancos de dados
tempdbemodelno SSD anexado, e cache de plano, pool de buffers e pool de columnstore na memória. Esse nó sem estado é operado pelo Azure Service Fabric, que inicializa o mecanismo de banco de dados, controla a integridade do nó e executa o failover para outro nó, se necessário. - Uma camada de dados com estado com os arquivos de banco de dados (
.mdfe.ldf) armazenados no Armazenamento de Blobs do Azure. O Armazenamento de Blobs do Azure tem recursos internos de disponibilidade e redundância de dados. A disponibilidade com redundância local baseia-se no armazenamento de dados em de armazenamento com redundância local (LRS) que copia os dados três vezes em um único datacenter na região principal. Ele garante que todos os registros no arquivo de log ou página no arquivo de dados serão preservados mesmo se o processo do mecanismo de banco de dados falhar.
Sempre que o mecanismo de banco de dados ou o sistema operacional for atualizado ou uma falha for detetada, o Azure Service Fabric moverá o processo do mecanismo de banco de dados sem estado para outro nó de computação sem estado com capacidade livre suficiente. Os dados no armazenamento de Blob do Azure não são afetados pela mudança e os arquivos de dados/log são anexados ao processo do mecanismo de banco de dados recém-inicializado. Esse processo garante alta disponibilidade, mas uma carga de trabalho pesada pode sofrer alguma degradação de desempenho durante a transição, já que o novo processo do mecanismo de banco de dados começa com cache frio.
Nível de serviço de uso geral de última geração
Observação
A atualização da camada de serviço de próxima geração de uso geral está atualmente em pré-visualização.
O Propósito Geral de Próxima Geração é uma atualização de arquitetura para a camada de serviço de Propósito Geral existente que usa uma camada de armazenamento remoto atualizada que armazena dados de instância e arquivos de log em discos gerenciados em vez de blobs de página e os mantém localmente.
Nível de serviço crítico para os negócios
A camada de serviço Business Critical usa o modelo de disponibilidade de armazenamento local, que integra recursos de computação (processo do mecanismo de banco de dados) e armazenamento (SSD conectado localmente) em um único nó. A alta disponibilidade é obtida replicando a computação e o armazenamento para nós adicionais.
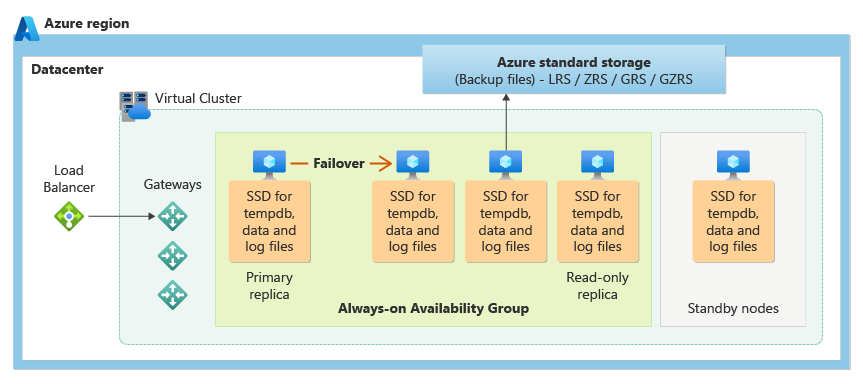
Os arquivos de banco de dados subjacentes (.mdf/.ldf) são colocados no armazenamento SSD conectado para fornecer E/S de latência muito baixa para sua carga de trabalho. A alta disponibilidade é implementada usando uma tecnologia semelhante aos grupos de disponibilidade do SQL Server Always On. O cluster inclui uma única réplica primária acessível para cargas de trabalho de clientes de leitura-gravação e até três réplicas secundárias (computação e armazenamento) que contêm cópias de dados. A réplica primária envia constantemente as alterações para as réplicas secundárias sequencialmente para garantir que os dados persistam em um número suficiente de réplicas secundárias antes de confirmar cada transação. Esse processo garante que, se a réplica primária ou uma réplica secundária legível ficar indisponível por qualquer motivo, uma réplica totalmente sincronizada estará sempre disponível para failover. O failover é iniciado pelo Azure Service Fabric. Quando uma réplica secundária se torna a nova réplica primária, outra réplica secundária é criada para garantir que o cluster tenha um número suficiente de réplicas para manter o quórum. Após a conclusão do failover, as conexões SQL do Azure são redirecionadas automaticamente para a nova réplica primária (ou réplica secundária legível com base na cadeia de conexão).
Como benefício adicional, o modelo de disponibilidade de armazenamento local inclui a capacidade de redirecionar conexões do Azure SQL somente leitura para uma das réplicas secundárias. Esse recurso é chamado de de expansão de leitura. Ele fornece 100% capacidade de computação adicional sem custo adicional para descarregar operações somente leitura, como cargas de trabalho analíticas, da réplica principal.
Alta disponibilidade através de redundância de zona
A disponibilidade redundante por zona baseia-se na colocação de réplicas em três zonas de disponibilidade do Azure na região primária. Cada zona de disponibilidade é um local físico separado com alimentação, refrigeração e rede independentes.
Por padrão, o cluster de nós para o modelo de disponibilidade de armazenamento local é criado no mesmo datacenter. Com a introdução do Azure Availability Zones, a Instância Gerenciada SQL coloca réplicas diferentes em diferentes zonas de disponibilidade na mesma região. Para eliminar um único ponto de falha, o anel de controle também é duplicado em várias zonas. O tráfego do plano de controle é então roteado para um balanceador de carga que também é implantado em zonas de disponibilidade. O roteamento de tráfego do plano de controle para o balanceador de carga é controlado pelo Gerenciador de Tráfego do Azure (ATM).
Usando uma configuração com redundância de zona, você pode tornar suas instâncias críticas para os negócios ou de uso geral resilientes a um conjunto muito maior de falhas, incluindo interrupções catastróficas do datacenter, sem alterações na lógica do aplicativo. Você pode converter qualquer instância crítica de negócios ou de uso geral existente para a configuração redundante de zona.
Como as instâncias com redundância de zona têm réplicas em diferentes datacenters com alguma distância entre elas, o aumento da latência da rede pode aumentar o tempo de confirmação da transação e, portanto, afetar o desempenho de algumas cargas de trabalho OLTP. Você sempre pode retornar à configuração de zona única desativando a configuração de redundância de zona. Esse processo é uma operação on-line semelhante à atualização regular do objetivo da camada de serviço. No final do processo, a instância é migrada de um anel redundante de zona para um anel de zona única ou vice-versa.
Para começar a usar a redundância de zona para a sua instância gerida do SQL, consulte Configurar redundância de zona.
Nível de serviço de uso geral
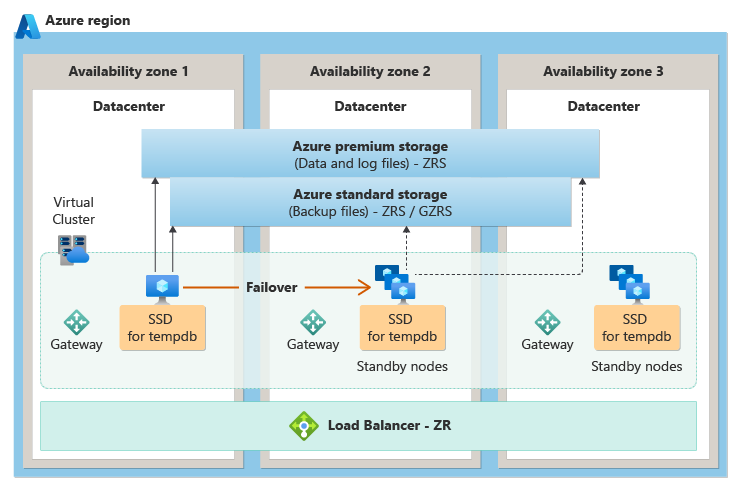
Na camada de serviço de uso geral, a redundância de zona é obtida colocando nós de computação sem estado em diferentes zonas de disponibilidade e, em seguida, depende de um de armazenamento redundante de zona
O diagrama a seguir demonstra a arquitetura de redundância de zona para a camada de serviço de uso geral:
Observação
A redundância de zona está atualmente em fase de testes para o nível de serviço de finalidade geral.
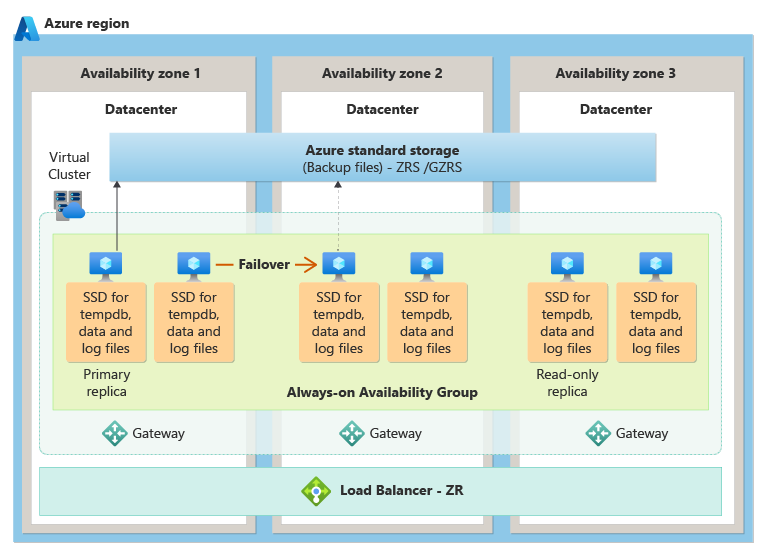
Nível de serviço crítico para os negócios
Na camada de serviço Crítica para os Negócios, a redundância de zona é obtida colocando réplicas de computação e armazenamento em diferentes zonas de disponibilidade e, em seguida, usando a tecnologia de grupo de disponibilidade Always On subjacente para replicar alterações de dados da instância principal para réplicas em espera em outras zonas de disponibilidade. No caso de uma interrupção, há um failover automático que faz a transição perfeita de uma das réplicas em espera para a principal.
O diagrama a seguir demonstra a arquitetura de redundância de zona para a camada de serviço Crítica de Negócios:
Testar a resiliência a falhas do aplicativo
A disponibilidade é uma parte fundamental da plataforma SQL Managed Instance que funciona de forma transparente para seu aplicativo de banco de dados. No entanto, reconhecemos que talvez você queira testar como as operações automáticas de failover iniciadas durante eventos planejados ou não planejados afetariam um aplicativo antes de implantá-lo na produção. Você pode iniciar manualmente um failover chamando uma API especial para reiniciar uma instância gerenciada. Como a operação de reinicialização é intrusiva e um grande número delas pode sobrecarregar a plataforma, apenas uma chamada de failover é permitida a cada 15 minutos para cada instância gerenciada.
Durante um failover real, as conexões com a instância falham enquanto o serviço SQL assume o papel de primário em um nó diferente. Para simular um failover, invoque o comando que reinicia o processo SQL para simular o início do serviço como se houvesse um failover. No entanto, as conexões podem falhar por um período mais longo durante um failover verdadeiro em comparação com um failover simulado, já que durante um failover verdadeiro, o processo SQL se torna o principal em outra máquina virtual dentro do cluster (localmente ou em outra zona se a redundância de zona estiver habilitada) e durante um failover simulado, o processo SQL é reiniciado na máquina virtual existente.
O comando de failover manual nesta seção normalmente se comporta da mesma maneira em configurações localmente redundantes e com redundância de zona - ele apenas reinicia o processo SQL localmente e não inicia um failover para outro nó, embora algumas exceções se apliquem. Este failover local é diferente de um failover que ocorre num grupo de failover.
Um failover local pode ser iniciado usando PowerShell, API REST ou CLI do Azure:
| PowerShell | REST API | Azure CLI |
|---|---|---|
| Invoke-AzSqlInstanceFailover | SQL Managed Instance - Instância Gerida SQL - Failover | az sql mi failover pode ser usado para invocar uma chamada de API REST no Azure CLI |
Conclusão
A Instância Gerenciada SQL do Azure apresenta uma solução interna de alta disponibilidade que é profundamente integrada à plataforma Azure. O serviço depende do Service Fabric para detetar falhas e recuperar, do armazenamento de Blob do Azure para proteger dados e das Zonas de Disponibilidade para maior tolerância a falhas. E para a camada de serviço Business Critical, a Instância Gerenciada SQL usa a tecnologia de grupo de disponibilidade Always On do SQL Server para replicação e failover de banco de dados. A combinação dessas tecnologias permite que os aplicativos aproveitem plenamente os benefícios de um modelo de armazenamento misto e ofereça suporte aos SLAs mais exigentes.
Próximos passos
- Ativar redundância de zona para a Instância Gerenciada SQL do Azure.
- Saiba mais sobre Zonas de Disponibilidade do Azure
- Saiba mais sobre Service Fabric
- Saiba mais sobre o Azure Traffic Manager
- Saiba Como iniciar um failover manual no SQL Managed Instance
- Para mais opções de alta disponibilidade e recuperação de desastres, consulte Continuidade de Negócios.