Tutorial: Configurar grupos de disponibilidade para o SQL Server em máquinas virtuais do Ubuntu no Azure
Neste tutorial, irá aprender a:
- Criar máquinas virtuais, colocá-las no conjunto de disponibilidade
- Habilitar alta disponibilidade (HA)
- Criar um cluster de marcapasso
- Configurar um agente de vedação criando um dispositivo STONITH
- Instale o SQL Server e mssql-tools no Ubuntu
- Configurar o grupo de disponibilidade Always On do SQL Server
- Configurar recursos do grupo de disponibilidade (AG) no cluster do Pacemaker
- Testar um failover e o agente de vedação
Nota
Comunicação sem preconceitos
Este artigo contém referências ao termo slave, um termo que a Microsoft considera ofensivo quando usado neste contexto. O termo aparece neste artigo porque aparece atualmente no software. Quando o termo for removido do software, iremos removê-lo do artigo.
Este tutorial usa a CLI do Azure para implantar recursos no Azure.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Use o ambiente Bash no Azure Cloud Shell. Para obter mais informações, consulte Guia de início rápido para Bash no Azure Cloud Shell.

Se preferir executar comandos de referência da CLI localmente, instale a CLI do Azure. Se estiver a utilizar o Windows ou macOS, considere executar a CLI do Azure num contentor Docker. Para obter mais informações, consulte Como executar a CLI do Azure em um contêiner do Docker.
Se estiver a utilizar uma instalação local, inicie sessão no CLI do Azure ao utilizar o comando az login. Para concluir o processo de autenticação, siga os passos apresentados no seu terminal. Para outras opções de entrada, consulte Entrar com a CLI do Azure.
Quando solicitado, instale a extensão da CLI do Azure na primeira utilização. Para obter mais informações sobre as extensões, veja Utilizar extensões com o CLI do Azure.
Execute o comando az version para localizar a versão e as bibliotecas dependentes instaladas. Para atualizar para a versão mais recente, execute o comando az upgrade.
- Este artigo requer a versão 2.0.30 ou posterior da CLI do Azure. Se estiver usando o Azure Cloud Shell, a versão mais recente já está instalada.
Criar um grupo de recursos
Se você tiver mais de uma assinatura, defina a assinatura para a qual deseja implantar esses recursos.
Use o comando a seguir para criar um grupo <resourceGroupName> de recursos em uma região. Substitua <resourceGroupName> por um nome de sua escolha. Este tutorial utiliza East US 2. Para obter mais informações, consulte o seguinte Guia de início rápido.
az group create --name <resourceGroupName> --location eastus2
Criar um conjunto de disponibilidade
A próxima etapa é criar um conjunto de disponibilidade. Execute o seguinte comando no Azure Cloud Shell e substitua <resourceGroupName> pelo nome do seu grupo de recursos. Escolha um nome para <availabilitySetName>.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
Você deve obter os seguintes resultados assim que o comando for concluído:
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Criar uma rede virtual e uma sub-rede
Crie uma sub-rede nomeada com um intervalo de endereços IP pré-atribuído. Substitua esses valores no seguinte comando:
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24O comando anterior cria uma VNet e uma sub-rede contendo um intervalo de IP personalizado.
Criar VMs do Ubuntu dentro do conjunto de disponibilidade
Obtenha uma lista de imagens de máquinas virtuais que oferecem o sistema operacional baseado no Ubuntu no Azure.
az vm image list --all --offer "sql2022-ubuntupro2004"Você verá os seguintes resultados ao pesquisar as imagens BYOS:
[ { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230808", "version": "16.0.230808" } ]Este tutorial utiliza
Ubuntu 20.04.Importante
Os nomes de máquina devem ter menos de 15 caracteres para configurar um grupo de disponibilidade. Os nomes de usuário não podem conter caracteres maiúsculos e as senhas devem ter entre 12 e 72 caracteres.
Crie três VMs no conjunto de disponibilidade. Substitua esses valores no seguinte comando:
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>- Um exemplo seria "Standard_D16s_v3"<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "Canonical:0001-com-ubuntu-server-jammy:20_04-lts-gen2:latest" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
O comando anterior cria as VMs usando a VNet definida anteriormente. Para obter mais informações sobre as diferentes configurações, consulte o artigo az vm create .
O comando também inclui o --os-disk-size-gb parâmetro para criar um tamanho de unidade de sistema operacional personalizado de 128 GB. Se você aumentar esse tamanho mais tarde, expanda os volumes de pasta apropriados para acomodar sua instalação, configure o LVM (Logical Volume Manager).
Você deve obter resultados semelhantes aos seguintes quando o comando for concluído para cada VM:
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/ubuntu1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Testar a conexão com as VMs criadas
Conecte-se a cada uma das VMs usando o seguinte comando no Azure Cloud Shell. Se você não conseguir encontrar seus IPs de VM, siga este Guia de início rápido no Azure Cloud Shell.
ssh <username>@<publicIPAddress>
Se a conexão for bem-sucedida, você verá a seguinte saída representando o terminal Linux:
[<username>@ubuntu1 ~]$
Digite exit para sair da sessão SSH.
Configurar acesso SSH sem senha entre nós
O acesso SSH sem senha permite que suas VMs se comuniquem entre si usando chaves públicas SSH. Você deve configurar chaves SSH em cada nó e copiá-las para cada nó.
Gerar novas chaves SSH
O tamanho de chave SSH necessário é de 4.096 bits. Em cada VM, altere para a /root/.ssh pasta e execute o seguinte comando:
ssh-keygen -t rsa -b 4096
Durante esta etapa, você pode ser solicitado a substituir um arquivo SSH existente. Você deve concordar com este prompt. Não é necessário introduzir uma frase secreta.
Copie as chaves SSH públicas
Em cada VM, você deve copiar a chave pública do nó que acabou de criar, usando o ssh-copy-id comando. Se desejar especificar o diretório de destino na VM de destino, você poderá usar o -i parâmetro.
No comando a seguir, a conta pode ser a mesma conta que você configurou para cada nó ao criar a <username> VM. Você também pode usar a root conta, mas essa opção não é recomendada em um ambiente de produção.
sudo ssh-copy-id <username>@ubuntu1
sudo ssh-copy-id <username>@ubuntu2
sudo ssh-copy-id <username>@ubuntu3
Verificar o acesso sem senha de cada nó
Para confirmar que a chave pública SSH foi copiada para cada nó, use o ssh comando de cada nó. Se você copiou as chaves corretamente, não será solicitada uma senha e a conexão será bem-sucedida.
Neste exemplo, estamos nos conectando ao segundo e terceiro nós da primeira VM (ubuntu1). Mais uma vez, a conta pode ser a mesma conta que você configurou para cada nó ao criar a <username> VM.
ssh <username>@ubuntu2
ssh <username>@ubuntu3
Repita esse processo dos três nós, para que cada nó possa se comunicar com os outros sem exigir senhas.
Configurar a resolução de nomes
Você pode configurar a resolução de nomes usando o DNS ou editando manualmente o etc/hosts arquivo em cada nó.
Para obter mais informações sobre DNS e Ative Directory, consulte Associar o SQL Server em um host Linux a um domínio do Ative Directory.
Importante
Recomendamos que utilize o seu endereço IP privado no exemplo anterior. Usar o endereço IP público nessa configuração fará com que a instalação falhe e exporá sua VM a redes externas.
As VMs e seus endereços IP usados neste exemplo estão listados da seguinte maneira:
ubuntu1: 10.0.0.85ubuntu2: 10.0.0.86ubuntu3: 10.0.0.87
Habilite a alta disponibilidade
Use ssh para se conectar a cada uma das 3 VMs e, uma vez conectado, execute os seguintes comandos para habilitar a alta disponibilidade.
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Instalar e configurar o cluster Pacemaker
Para começar a configurar o cluster Pacemaker, você precisa instalar os pacotes e agentes de recursos necessários. Execute os comandos abaixo em cada uma das suas VMs:
sudo apt-get install -y pacemaker pacemaker-cli-utils crmsh resource-agents fence-agents csync2 python3-azure
Agora prossiga para criar a chave de autenticação no servidor primário:
sudo corosync-keygen
O authkey é gerado no /etc/corosync/authkey local. Copie o authkey para servidores secundários neste local: /etc/corosync/authkey
sudo scp /etc/corosync/authkey username@ubuntu2:~
sudo scp /etc/corosync/authkey username@ubuntu3:~
Mova o authkey do diretório base para /etc/corosynco .
sudo mv authkey /etc/corosync/authkey
Prossiga para criar o cluster usando os seguintes comandos:
cd /etc/corosync/
sudo vi corosync.conf
Edite o arquivo Corosync para representar o conteúdo da seguinte maneira:
totem {
version: 2
secauth: off
cluster_name: demo
transport: udpu
}
nodelist {
node {
ring0_addr: 10.0.0.85
name: ubuntu1
nodeid: 1
}
node {
ring0_addr: 10.0.0.86
name: ubuntu2
nodeid: 2
}
node {
ring0_addr: 10.0.0.87
name: ubuntu3
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
two_node: 0
}
qb {
ipc_type: native
}
logging {
fileline: on
to_stderr: on
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: no
debug: off
}
Copie o corosync.conf arquivo para outros nós para /etc/corosync/corosync.conf:
sudo scp /etc/corosync/corosync.conf username@ubuntu2:~
sudo scp /etc/corosync/corosync.conf username@ubuntu3:~
sudo mv corosync.conf /etc/corosync/
Reinicie o Pacemaker e o Corosync e confirme o estado:
sudo systemctl restart pacemaker corosync
sudo crm status
A saída é semelhante ao exemplo a seguir:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by hacluster via crmd on ubuntu1
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* No resources
Configurar agente de esgrima
Configure a vedação no cluster. Vedação é o isolamento de nó com falha em um cluster. Ele reinicia o nó com falha, deixando-o descer, redefinir e voltar para cima, juntando-se novamente ao cluster.
Para configurar a vedação, execute as seguintes ações:
- Registrar um novo aplicativo no Microsoft Entra ID e criar um segredo
- Criar uma função personalizada a partir do arquivo json no powershell/CLI
- Atribuir a função e o aplicativo às VMs no cluster
- Definir as propriedades do agente de vedação
Registrar um novo aplicativo no Microsoft Entra ID e criar um segredo
- Vá para Microsoft Entra ID no portal e anote o ID do locatário.
- Selecione Registos de Aplicações no menu do lado esquerdo e, em seguida, selecione Novo Registo.
- Insira um Nome e selecione Contas somente neste diretório da organização.
- Em Tipo de Aplicativo, selecione Web, insira
http://localhostcomo uma URL de logon e selecione Registrar. - Selecione Certificados e segredos no menu do lado esquerdo e, em seguida, selecione Novo segredo do cliente.
- Insira uma descrição e selecione um período de validade.
- Anote o valor do segredo, ele é usado como a seguinte senha e o ID secreto, é usado como o seguinte nome de usuário.
- Selecione "Visão geral" e anote o ID do aplicativo. É usado como o seguinte login.
Crie um arquivo JSON chamado fence-agent-role.json e adicione o seguinte (adicionando sua ID de assinatura):
{
"Name": "Linux Fence Agent Role-ap-server-01-fence-agent",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [],
"AssignableScopes": [
"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
]
}
Criar uma função personalizada a partir do arquivo JSON no PowerShell/CLI
az role definition create --role-definition fence-agent-role.json
Atribuir a função e o aplicativo às VMs no cluster
- Para cada uma das VMs no cluster, selecione Controle de acesso (IAM) no menu lateral.
- Selecione Adicionar uma atribuição de função (use a experiência clássica).
- Selecione a função criada anteriormente.
- Na lista Selecionar, insira o nome do aplicativo criado anteriormente.
Agora podemos criar o recurso do agente de esgrima usando valores anteriores e seu ID de assinatura:
sudo crm configure primitive fence-vm stonith:fence_azure_arm \
params \
action=reboot \
resourceGroup="resourcegroupname" \
resourceGroup="$resourceGroup" \
username="$secretId" \
login="$applicationId" \
passwd="$password" \
tenantId="$tenantId" \
subscriptionId="$subscriptionId" \
pcmk_reboot_timeout=900 \
power_timeout=60 \
op monitor \
interval=3600 \
timeout=120
Definir as propriedades do agente de vedação
Execute os seguintes comandos para definir as propriedades do agente de esgrima:
sudo crm configure property cluster-recheck-interval=2min
sudo crm configure property start-failure-is-fatal=true
sudo crm configure property stonith-timeout=900
sudo crm configure property concurrent-fencing=true
sudo crm configure property stonith-enabled=true
E confirme o status do cluster:
sudo crm status
A saída é semelhante ao exemplo a seguir:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 1 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Instalar o SQL Server e mssql-tools
Os seguintes comandos são usados para instalar o SQL Server:
Importe as chaves GPG do repositório público:
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascRegistre o repositório do Ubuntu:
sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2022.list)"Execute os seguintes comandos para instalar o SQL Server:
sudo apt-get update sudo apt-get install -y mssql-serverApós a conclusão da instalação do pacote, execute
mssql-conf setupe siga as instruções para definir a senha SA e escolher sua edição. Como lembrete, as seguintes edições são licenciadas livremente: Evaluation, Developer e Express.sudo /opt/mssql/bin/mssql-conf setupUma vez feita a configuração, verifique se o serviço está em execução:
systemctl status mssql-server --no-pagerInstalar as ferramentas de linha de comando do SQL Server
Para criar um banco de dados, você precisa se conectar a uma ferramenta que possa executar instruções Transact-SQL no SQL Server. As etapas a seguir instalam as ferramentas de linha de comando do SQL Server: sqlcmd e bcp.
Use as etapas a seguir para instalar o mssql-tools18 no Ubuntu.
Nota
- O Ubuntu 18.04 é suportado a partir do SQL Server 2019 3.
- O Ubuntu 20.04 é suportado a partir do SQL Server 2019 10.
- O Ubuntu 22.04 é suportado a partir do SQL Server 2022 10.
Entre no modo de superusuário.
sudo suImporte as chaves GPG do repositório público.
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascRegistre o repositório do Microsoft Ubuntu.
Para o Ubuntu 22.04, use o seguinte comando:
curl https://packages.microsoft.com/config/ubuntu/22.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPara o Ubuntu 20.04, use o seguinte comando:
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPara o Ubuntu 18.04, use o seguinte comando:
curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPara o Ubuntu 16.04, use o seguinte comando:
curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
Saia do modo de superusuário.
exitAtualize a lista de fontes e execute o comando de instalação com o pacote do desenvolvedor unixODBC.
sudo apt-get update sudo apt-get install mssql-tools18 unixodbc-devNota
Para atualizar para a versão mais recente do mssql-tools, execute os seguintes comandos:
sudo apt-get update sudo apt-get install mssql-tools18Opcional: adicione
/opt/mssql-tools18/bin/à suaPATHvariável de ambiente em um shell bash.Para tornar o sqlcmd e o bcp acessíveis a partir do shell bash para sessões de login, modifique o seu
PATHno arquivo com o~/.bash_profileseguinte comando:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bash_profilePara tornar o sqlcmd e o bcp acessíveis a partir do shell bash para sessões interativas/não login, modifique o
PATH~/.bashrcno arquivo com o seguinte comando:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc source ~/.bashrc
Instalar o agente de alta disponibilidade do SQL Server
Execute o seguinte comando em todos os nós para instalar o pacote do agente de alta disponibilidade para o SQL Server:
sudo apt-get install mssql-server-ha
Configurar um grupo de disponibilidade
Use as etapas a seguir para configurar um grupo de disponibilidade Always On do SQL Server para suas VMs. Para obter mais informações, consulte Configurar grupos de disponibilidade Always On do SQL Server para alta disponibilidade no Linux.
Habilitar grupos de disponibilidade e reiniciar o SQL Server
Habilite grupos de disponibilidade em cada nó que hospeda uma instância do SQL Server. Em seguida, reinicie o mssql-server serviço. Execute os seguintes comandos em cada nó:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Criar um certificado
A Microsoft não oferece suporte à autenticação do Ative Directory para o ponto de extremidade AG. Portanto, você deve usar um certificado para criptografia de ponto de extremidade AG.
Conecte-se a todos os nós usando o SQL Server Management Studio (SSMS) ou sqlcmd. Execute os seguintes comandos para habilitar uma sessão AlwaysOn_health e criar uma chave mestra:
Importante
Se você estiver se conectando remotamente à sua instância do SQL Server, precisará ter a porta 1433 aberta no firewall. Você também precisará permitir conexões de entrada para a porta 1433 em seu NSG para cada VM. Para obter mais informações, consulte Criar uma regra de segurança para criar uma regra de segurança de entrada.
- Substitua a
<MasterKeyPassword>por sua própria senha.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GO- Substitua a
Conecte-se à réplica primária usando SSMS ou sqlcmd. Os comandos abaixo criam um certificado em e uma chave privada em
/var/opt/mssql/data/dbm_certificate.cersua réplica principal dovar/opt/mssql/data/dbm_certificate.pvkSQL Server:- Substitua a
<PrivateKeyPassword>por sua própria senha.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO- Substitua a
Saia da sessão sqlcmd executando o exit comando e retorne à sua sessão SSH.
Copie o certificado para as réplicas secundárias e crie os certificados no servidor
Copie os dois arquivos que foram criados para o mesmo local em todos os servidores que hospedarão réplicas de disponibilidade.
No servidor primário, execute o seguinte
scpcomando para copiar o certificado para os servidores de destino:- Substitua
<username>e pelo nome de usuário esles2nome da VM de destino que você está usando. - Execute este comando para todas as réplicas secundárias.
Nota
Você não precisa executar
sudo -i, o que lhe dá o ambiente raiz. Em vez disso, você pode executar osudocomando na frente de cada comando.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>- Substitua
No servidor de destino, execute o seguinte comando:
- Substitua
<username>pelo seu nome de usuário. - O
mvcomando move os arquivos ou diretório de um lugar para outro. - O
chowncomando é usado para alterar o proprietário e o grupo de arquivos, diretórios ou links. - Execute esses comandos para todas as réplicas secundárias.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Substitua
O script Transact-SQL a seguir cria um certificado do backup que você criou na réplica primária do SQL Server. Atualize o script com senhas fortes. A palavra-passe de desencriptação é a mesma palavra-passe que usou para criar o ficheiro .pvk no passo anterior. Para criar o certificado, execute o seguinte script usando sqlcmd ou SSMS em todos os servidores secundários:
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
Criar os pontos de extremidade de espelhamento de banco de dados em todas as réplicas
Execute o seguinte script em todas as instâncias do SQL Server usando sqlcmd ou SSMS:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Criar o grupo de disponibilidade
Conecte-se à instância do SQL Server que hospeda a réplica primária usando sqlcmd ou SSMS. Execute o seguinte comando para criar o grupo de disponibilidade:
- Substitua
ag1pelo nome AG desejado. - Substitua os
ubuntu1valores ,ubuntu2e eubuntu3pelos nomes das instâncias do SQL Server que hospedam as réplicas.
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'ubuntu1'
WITH (
ENDPOINT_URL = N'tcp://ubuntu1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu2'
WITH (
ENDPOINT_URL = N'tcp://ubuntu2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu3'
WITH (
ENDPOINT_URL = N'tcp://ubuntu3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Criar um logon do SQL Server para o Pacemaker
Em todas as instâncias do SQL Server, crie um logon do SQL Server para o Pacemaker. O Transact-SQL a seguir cria um logon.
- Substitua por sua própria senha complexa
<password>.
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
Em todas as instâncias do SQL Server, salve as credenciais usadas para o logon do SQL Server.
Crie o arquivo:
sudo vi /var/opt/mssql/secrets/passwdAdicione as duas linhas seguintes ao ficheiro:
pacemakerLogin <password>Para sair do editor vi , primeiro pressione a tecla Esc e, em seguida, digite o comando
:wqpara gravar o arquivo e sair.Torne o arquivo legível apenas pela raiz:
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Associar réplicas secundárias ao grupo de disponibilidade
Em suas réplicas secundárias, execute os seguintes comandos para associá-las ao AG:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOExecute o seguinte script Transact-SQL na réplica primária e em cada réplica secundária:
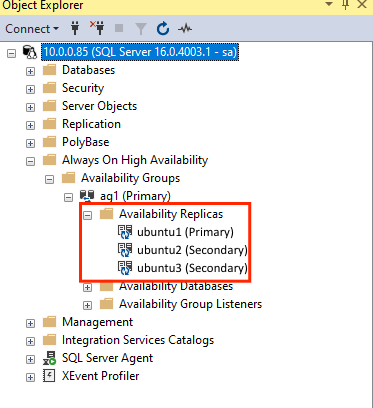
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GODepois que as réplicas secundárias forem unidas, você poderá vê-las no Pesquisador de Objetos do SSMS expandindo o nó Always On High Availability :
Adicionar um banco de dados ao grupo de disponibilidade
Esta seção segue o artigo para adicionar um banco de dados a um grupo de disponibilidade.
Os seguintes comandos Transact-SQL são usados nesta etapa. Execute estes comandos na réplica primária:
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery mode
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Verifique se o banco de dados foi criado nos servidores secundários
Em cada réplica secundária do SQL Server, execute a seguinte consulta para ver se o banco de dados db1 foi criado e está em um estado SINCRONIZADO:
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
Se as synchronization_state_desc listas SINCRONIZADAS para db1, isso significa que as réplicas estão sincronizadas. Os secundários são mostrados db1 na réplica primária.
Criar recursos de grupo de disponibilidade no cluster do Pacemaker
Para criar o recurso de grupo de disponibilidade no Pacemaker, execute os seguintes comandos:
sudo crm
configure
primitive ag1_cluster \
ocf:mssql:ag \
params ag_name="ag1" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag1 ag1_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
Este comando acima cria o recurso ag1_cluster, ou seja, o recurso do grupo de disponibilidade. Em seguida, ele cria o recurso ms-ag1 (recurso primário/secundário no Pacemaker e, em seguida, adiciona o recurso AG a ele. Isso garante que o recurso AG seja executado em todos os três nós no cluster, mas apenas um desses nós é primário.)
Para exibir o recurso de grupo AG e verificar o status do cluster:
sudo crm resource status ms-ag1
sudo crm status
A saída é semelhante ao exemplo a seguir:
resource ms-ag1 is running on: ubuntu1 Master
resource ms-ag1 is running on: ubuntu3
resource ms-ag1 is running on: ubuntu2
A saída é semelhante ao exemplo a seguir. Para adicionar restrições de colocation e promoção, consulte Tutorial: Configurar um ouvinte de grupo de disponibilidade em máquinas virtuais Linux.
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 4 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Execute o seguinte comando para criar um recurso de grupo, para que as restrições de colocation e promoção aplicadas ao ouvinte e ao balanceador de carga não precisem ser aplicadas individualmente.
sudo crm configure group virtualip-group azure-load-balancer virtualip
A saída de será semelhante ao exemplo a crm status seguir:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 6 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* Resource Group: virtual ip-group:
* azure-load-balancer (ocf :: heartbeat:azure-lb): Started ubuntu1
* virtualip (ocf :: heartbeat: IPaddr2): Started ubuntu1
* fence-vm (stonith:fence_azure_arm): Started ubuntu1