Operacionalizar a malha de dados para engenharia de recursos orientada por domínio de IA/ML
A malha de dados ajuda as organizações a passar de um data lake ou data warehouse centralizado para uma descentralização orientada por domínio de dados analíticos, sublinhada por quatro princípios: Propriedade do Domínio, Dados como Produto, Plataforma de Dados de Autoatendimento e Governança Computacional Federada. A malha de dados fornece os benefícios da propriedade de dados distribuídos e da melhoria na qualidade e governança de dados, o que acelera os negócios e reduz o tempo até gerar valor para as organizações.
Implementação de malha de dados
Uma implementação típica de malha de dados inclui equipes de domínio com engenheiros de dados que criam pipelines de dados. A equipa mantém repositórios de dados operacionais e analíticos, como data lakes, data warehouses, ou data lakehouses. Eles disponibilizam os pipelines como produtos de dados para que outras equipas de domínio ou equipas de ciência de dados os possam utilizar. Outras equipes consomem os produtos de dados usando uma plataforma central de governança de dados, conforme mostrado no diagrama a seguir.
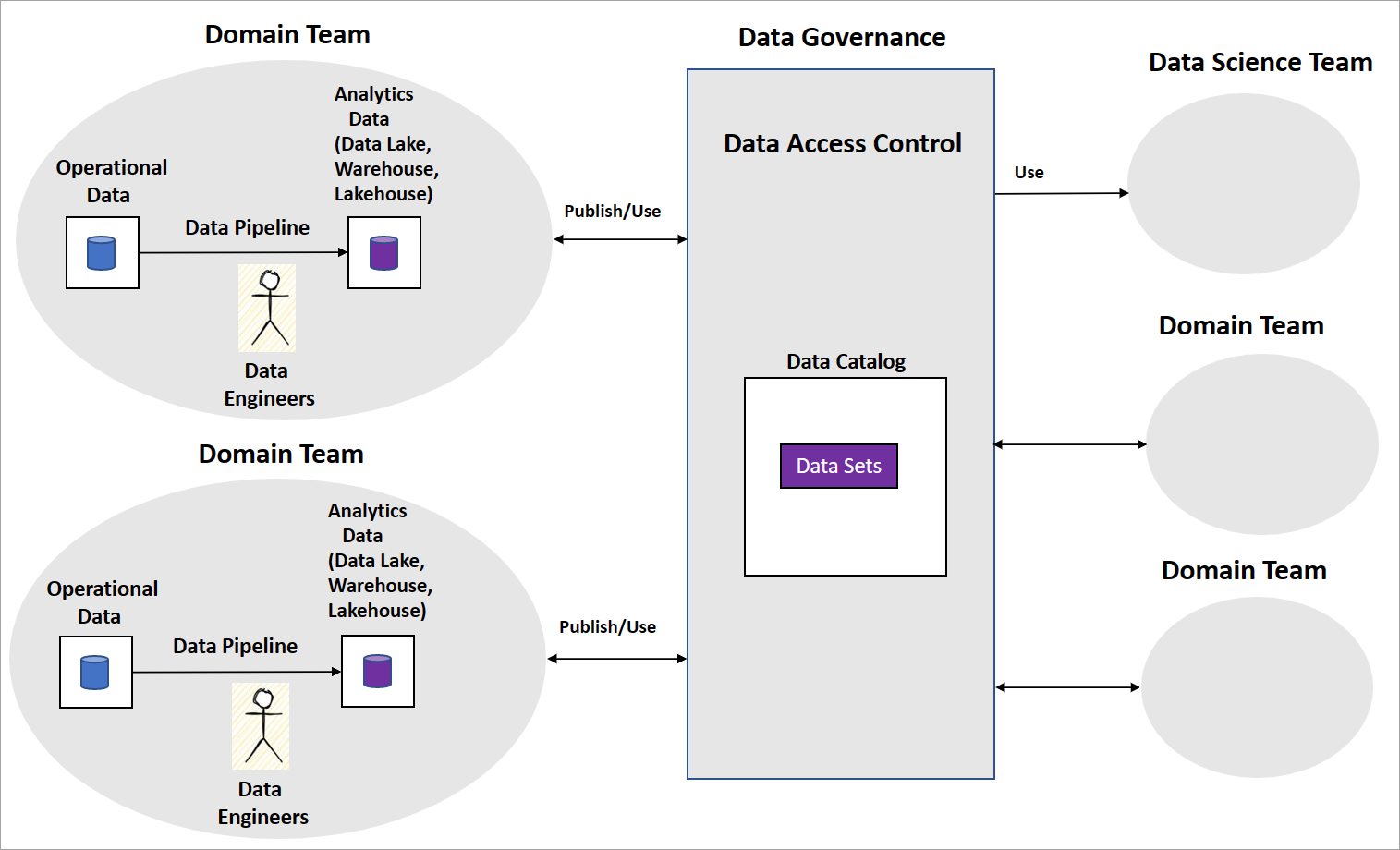
A malha de dados é clara sobre como os produtos de dados servem conjuntos de dados transformados e agregados para inteligência empresarial. Mas não é explícito sobre a abordagem que as organizações devem adotar para construir modelos de IA/ML. Também não há orientação sobre como estruturar suas equipes de ciência de dados, a governança do modelo de IA/ML e como compartilhar modelos ou recursos de IA/ML entre equipes de domínio.
A seção a seguir descreve algumas estratégias que as organizações podem usar para desenvolver recursos de IA/ML dentro da malha de dados. E você vê uma proposta para uma estratégia de engenharia de recursos orientada por domínio ou malha de recursos.
Estratégias de IA/ML para malha de dados
Uma estratégia comum é que a organização adote equipes de ciência de dados como consumidores de dados. Estas equipas acedem a vários produtos de dados de domínio na malha de dados consoante o caso de uso. Eles realizam exploração de dados e engenharia de recursos para desenvolver e construir modelos de IA/ML. Em alguns casos, as equipes de domínio também desenvolvem seus próprios modelos de IA/ML usando seus dados e produtos de dados de outras equipes para estender e derivar novos recursos.
A engenharia de características é o núcleo da construção de modelos e normalmente é complexa e requer conhecimento especializado no domínio. Essa estratégia pode ser demorada, já que as equipes de ciência de dados precisam analisar vários produtos de dados. Eles podem não ter conhecimento completo do domínio para criar recursos de alta qualidade. A falta de conhecimento do domínio pode levar a esforços duplicados de engenharia de recursos entre as equipes de domínio. Além disso, problemas como a replicabilidade dos modelos de IA/ML devido a conjuntos de características inconsistentes entre as equipas. As equipes de ciência de dados ou de domínio precisam atualizar continuamente os recursos à medida que novas versões de produtos de dados são lançadas.
Outra estratégia é que as equipes de domínio liberem modelos de IA/ML em um formato como Open Neural Network Exchange (ONNX), mas esses resultados são caixas pretas e combinar modelos ou recursos de IA/ML entre domínios seria difícil.
Existe uma maneira de descentralizar a construção do modelo de IA/ML entre as equipes de domínio e ciência de dados para enfrentar os desafios? A engenharia de recursos orientada por domínio proposta ou a estratégia de malha de recursos é uma opção.
Engenharia de recursos orientada por domínio ou malha de recursos
A engenharia de recursos orientada por domínio ou a estratégia de malha de recursos oferece uma abordagem descentralizada para a construção de modelos de IA/ML em uma configuração de malha de dados. O diagrama a seguir mostra a estratégia e como ela aborda os quatro princípios principais da malha de dados.
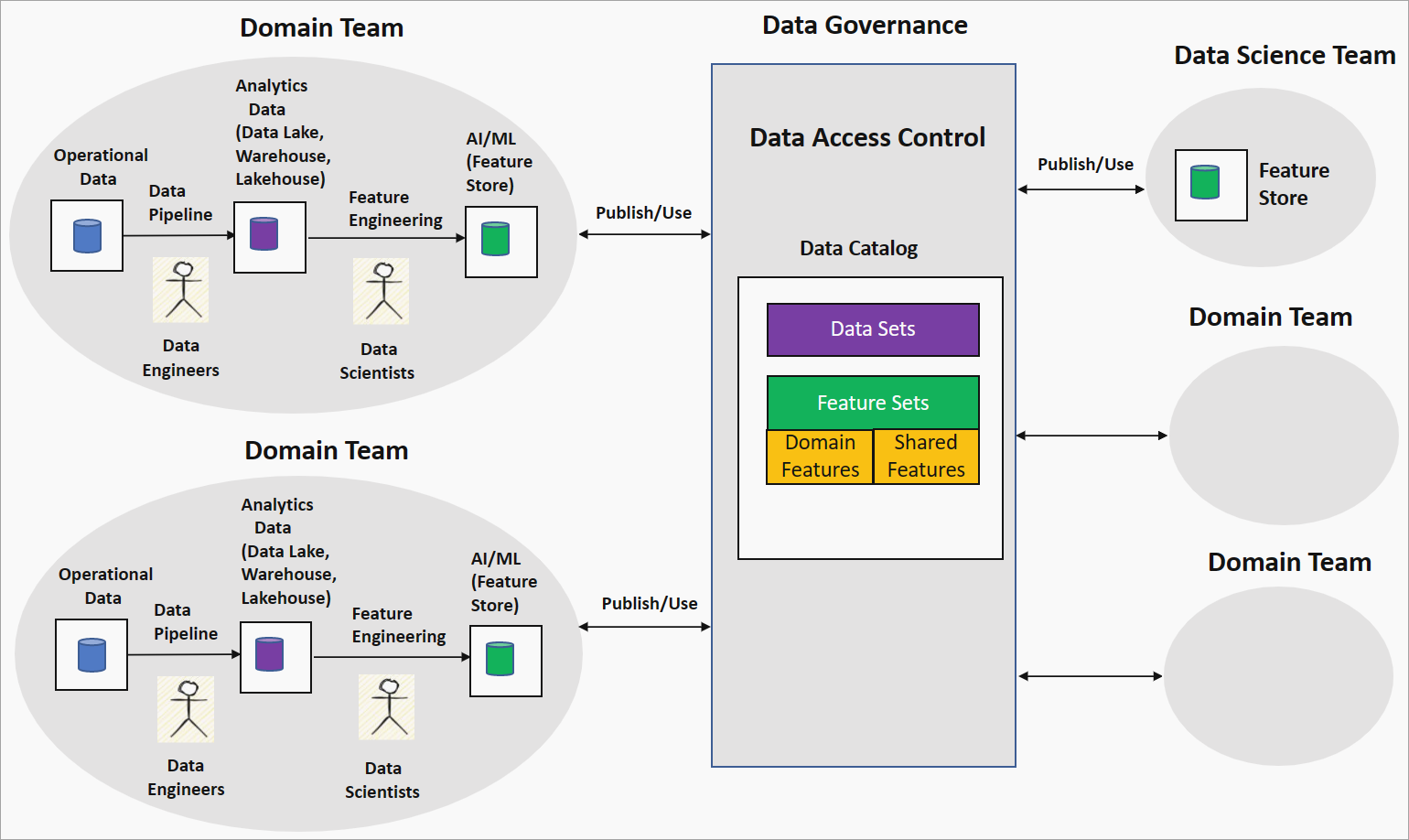
Engenharia de características de propriedade de domínio por equipas de domínio
Nessa estratégia, a organização emparelha cientistas de dados com engenheiros de dados em uma equipe de domínio para executar a exploração de dados em dados limpos e transformados em, por exemplo, um data lake. Engineering gera recursos que são armazenados em um repositório de recursos. Um repositório de recursos é um repositório de dados que serve recursos para treinamento e inferência e ajuda a rastrear versões de recursos, metadados e estatísticas. Esse recurso permite que os cientistas de dados da equipe de domínio trabalhem em estreita colaboração com especialistas de domínio e mantenham os recursos atualizados à medida que os dados mudam no domínio.
Dados como produto: Conjuntos de recursos
Os recursos gerados pela equipe de domínio, conhecidos como recursos locais ou de domínio, são publicados no catálogo de dados na plataforma de governança de dados como conjuntos de recursos. Esses conjuntos de recursos são consumidos por equipes de ciência de dados ou outras equipes de domínio para criar modelos de IA/ML. Durante o desenvolvimento do modelo de IA/ML, as equipes de ciência de dados ou domínio podem combinar recursos de domínio para produzir novos recursos, chamados de recursos compartilhados ou globais. Esses recursos compartilhados são publicados de volta no catálogo de conjuntos de recursos para consumo.
Plataforma de dados de autoatendimento e governança de computação federada: padronização e qualidade de funcionalidades
Essa estratégia pode levar à adoção de uma pilha de tecnologia diferente para pipelines de engenharia de recursos e definições de recursos inconsistentes entre equipes de domínio. Os princípios da plataforma de dados de autoatendimento garantem que as equipes de domínio estejam usando infraestrutura e ferramentas comuns para criar os pipelines de engenharia de recursos e impor o controle de acesso. O princípio de Governança Computacional Federada garante a interoperabilidade dos conjuntos de recursos por meio de padronização global e verificações da qualidade dos recursos.
O uso da engenharia de recursos orientada por domínio ou da estratégia de malha de recursos oferece uma abordagem descentralizada de construção de modelos de IA/ML para que as organizações ajudem a reduzir o tempo no desenvolvimento de modelos de IA/ML. Esta estratégia ajuda a manter os recursos consistentes entre as equipas de domínio. Isso evita a duplicação de esforços e resulta em recursos de alta qualidade para modelos de IA/ML mais precisos, que aumentam o valor para o negócio.
Implementação de malha de dados no Azure
Este artigo descreve os conceitos sobre a operacionalização de IA/ML em uma malha de dados e não abrange ferramentas ou arquiteturas para criar essas estratégias. O Azure tem ofertas de feature store, como a feature store do Azure Databricks e Feathr do LinkedIn. Você pode desenvolver Microsoft Purview conectores personalizados para gerenciar e controlar repositórios de recursos.