Usar o Azure Databricks na análise em escala de nuvem no Azure
O Azure Databricks é uma plataforma de análise de dados otimizada para a plataforma de Serviços de Nuvem do Microsoft Azure. O Azure Databricks oferece dois ambientes para desenvolver aplicativos com uso intensivo de dados:
Azure Databricks SQL, que permite executar consultas SQL ad-hoc rápidas no seu data lake.
O Azure Databricks Data Science & Engineering (às vezes chamado simplesmente de "Espaço de trabalho") é uma plataforma de análise baseada no Apache Spark. Ele é integrado ao Azure para fornecer configuração com um clique, fluxos de trabalho simplificados e um espaço de trabalho interativo que permite a colaboração entre engenheiros de dados, cientistas de dados e engenheiros de aprendizado de máquina.
Para análises em escala de nuvem, nos concentraremos no Azure Databricks Data Science & Engineering.
Descrição geral
Para cada zona de aterrissagem de dados implantada, você tem a opção de implantar dois espaços de trabalho compartilhados. Um para ingestão agnóstica de dados e outro para análises.
- O espaço de trabalho de engenharia do Azure Databricks para ingestão e processamento se conectaria ao Azure Data Lake por meio das entidades de serviço do Azure. É chamada pela ingestão agnóstica de dados.
- O espaço de trabalho de análise do Azure Databricks pode ser provisionado para todos os cientistas de dados e equipes de operações de dados. Esse espaço de trabalho se conectaria ao Azure Data Lake usando a autenticação de passagem do Microsoft Entra. Você compartilha o espaço de trabalho de análise e ciência de dados do Azure Databricks na zona de aterrissagem de dados com todos os usuários que têm acesso ao espaço de trabalho.
Se você tiver um mecanismo de ingestão agnóstica de dados automatizado, o espaço de trabalho de engenharia do Azure Databricks usará uma instância do Cofre da Chave do Azure criada no grupo de recursos do serviço de metadados do Azure para executar pipelines de ingestão de dados brutos para enriquecidos.
O espaço de trabalho de análise do Azure Databricks deve ter políticas de cluster que exijam que você crie clusters de alta simultaneidade. Esse tipo de cluster permite que o data lake seja explorado usando a passagem de credenciais do Microsoft Entra. Para obter mais informações, consulte Controle de acesso e configurações de data lake no Armazenamento do Azure Data Lake.
Configurar o Azure Databricks
A implantação do Azure Databricks é parcialmente baseada em parâmetros por meio de um modelo do Azure Resource Manager e scripts YAML, mas também requer alguma intervenção manual para configurar todos os espaços de trabalho.
Todos os espaços de trabalho do Azure Databricks devem usar o plano premium, que fornece os seguintes recursos necessários:
- Dimensionamento automático otimizado da computação
- Autenticação de passagem de credenciais do Microsoft Entra
- Autenticação condicional
- Controlo de acesso baseado em funções para blocos de notas, clusters, tarefas e tabelas
- Registos de auditoria
Para alinhar à análise em escala de nuvem, recomendamos que todos os espaços de trabalho tenham as seguintes opções de implantação padrão configuradas:
- Os espaços de trabalho do Azure Databricks se conectam a uma instância externa do metastore do Apache Hive na zona de aterrissagem de dados.
- Configure cada espaço de trabalho para enviar o log de diagnóstico do Databricks para o Azure Log Analytics no databricks-monitoring-rg
- Implemente políticas de cluster para limitar a capacidade de criar clusters com base em um conjunto de regras. Para obter mais informações, consulte Gerenciar políticas de cluster.
- Defina várias políticas de cluster. Como parte do processo de integração, atribua a cada grupo-alvo permissão para uso pela equipe de operações da zona de aterrissagem de dados. Por padrão, a permissão de criação de cluster é dada apenas à equipe de operações. Equipes ou grupos diferentes recebem permissão para usar políticas de cluster.
- Use políticas de cluster em combinação com pools do Azure Databricks para reduzir os tempos de início e dimensionamento automático do cluster mantendo um conjunto de instâncias ociosas e prontas para uso. Para obter mais informações, consulte Pools.
- Recupere todos os segredos operacionais do Azure Databricks, como credenciais SPN e cadeias de conexão, de uma instância do Azure Key Vault.
- Configure um aplicativo corporativo separado por espaço de trabalho para uso com SCIM (sistema para gerenciamento de identidades entre domínios). Vincule-se ao espaço de trabalho do Azure Databricks para controlar o acesso e as permissões para cada espaço de trabalho. Para obter mais informações, consulte Provisionar usuários e grupos usando SCIM e configurar o provisionamento SCIM para Microsoft Entra ID.
Aviso
A falha ao configurar o espaço de trabalho do Azure Databricks para usar a interface SCIM do Azure Databricks afeta a forma como você fornece controles de segurança. Ele passa de um processo automatizado para um processo manual e quebra todos os pipelines de CI/CD de implantação.
As seguintes opções de controle de acesso são definidas para todos os espaços de trabalho do Databricks:
- Controle de visibilidade do espaço de trabalho: ativado (padrão: desativado)
- Controle de visibilidade do cluster: ativado (padrão: desativado)
- Controle de visibilidade do trabalho: ativado (padrão: desativado)
Talvez você queira habilitar as seguintes opções para o espaço de trabalho de análise do Azure Databricks:
- Exportação de bloco de anotações: desabilitada (padrão: habilitada)
- Recursos da área de transferência da tabela do bloco de anotações: desativado (padrão: habilitado)
- Controle de acesso à tabela: ativado (padrão: desativado)
- Acesso condicional do Microsoft Entra
Implantar o Azure Databricks
Se você implantar os espaços de trabalho do Azure Databricks como parte de uma nova implantação de zona de aterrissagem de dados. Esta imagem a seguir mostra um fluxo de trabalho de exemplo de implantação de um ambiente do Azure Databricks em análises em escala de nuvem.
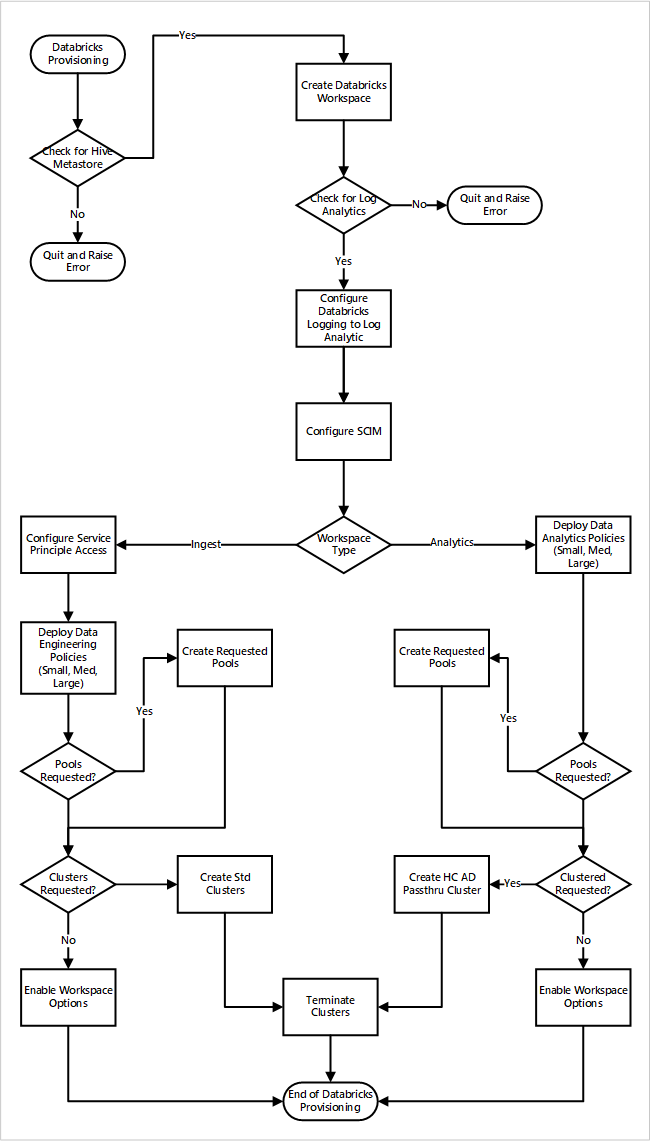
- O processo de provisionamento primeiro garante a existência de uma instância de metastore do Apache Hive na zona de aterrissagem de dados. Se ele não conseguir encontrar o metastore do Apache Hive, ele fecha e gera um erro.
- Ao encontrar com êxito o metastore do Apache Hive, um espaço de trabalho é criado.
- O processo verifica se há um espaço de trabalho do Log Analytics na zona de aterrissagem de dados. Se ele não conseguir encontrar o espaço de trabalho do Log Analytics, ele fechará e gerará um erro.
- Para cada espaço de trabalho, ele cria um aplicativo Microsoft Entra e configura o SCIM.
Para o espaço de trabalho de ingestão do Azure Databricks:
- O processo configura o espaço de trabalho com o acesso da entidade de serviço.
- As políticas de engenharia de dados que foram definidas pela equipe de operações da plataforma de dados são implantadas.
- Se a equipe de operações da zona de aterrissagem de dados tiver solicitado pools ou clusters do Databricks, eles poderão ser integrados ao processo de implantação.
- Ele habilita opções de espaço de trabalho específicas para o espaço de trabalho de engenharia do Azure Databricks.
Para o espaço de trabalho de análise do Azure Databricks:
- O processo implanta políticas de análise de dados que foram definidas pela equipe de operações da plataforma de dados.
- Se a equipe de operações da zona de aterrissagem de dados tiver solicitado pools ou clusters do Databricks, eles poderão ser integrados ao processo de implantação.
- Ele habilita opções de espaço de trabalho específicas para o espaço de trabalho de engenharia do Azure Databricks.
Metastore externo do Hive
Em uma implantação de espaço de trabalho do Azure Databricks:
- Um novo script de inicialização global define as configurações do metastore do Apache Hive para todos os clusters. Esse script é gerenciado pela nova API de scripts de inicialização global.
A nova API de scripts de inicialização global está em visualização pública. Os recursos de visualização pública no Azure Databricks estão prontos para ambientes de produção e são suportados pela equipe de suporte. Para obter mais informações, consulte Versões de visualização do Azure Databricks.
- Esta solução usa o Banco de Dados do Azure para MySQL para armazenar a instância do metastore do Apache Hive. Esta base de dados foi escolhida pela sua relação custo-eficácia e pela sua elevada compatibilidade com o Apache Hive.
Próximos passos
A análise em escala de nuvem leva em conta as seguintes diretrizes para integrar o Azure Databricks: