Conceitos fundamentais para dimensionamento no Azure Cosmos DB para PostgreSQL
APLICA-SE A: ![]() Azure Cosmos DB para PostgreSQL (alimentado pela extensão de banco de dados Citus para PostgreSQL)
Azure Cosmos DB para PostgreSQL (alimentado pela extensão de banco de dados Citus para PostgreSQL)
Antes de investigarmos as etapas de criação de um novo aplicativo, é útil ver uma rápida visão geral dos termos e conceitos envolvidos.
Descrição geral da arquitetura
O Azure Cosmos DB para PostgreSQL oferece o poder de distribuir tabelas e/ou esquemas em várias máquinas em um cluster e consultá-los de forma transparente da mesma forma que você consulta PostgreSQL simples:
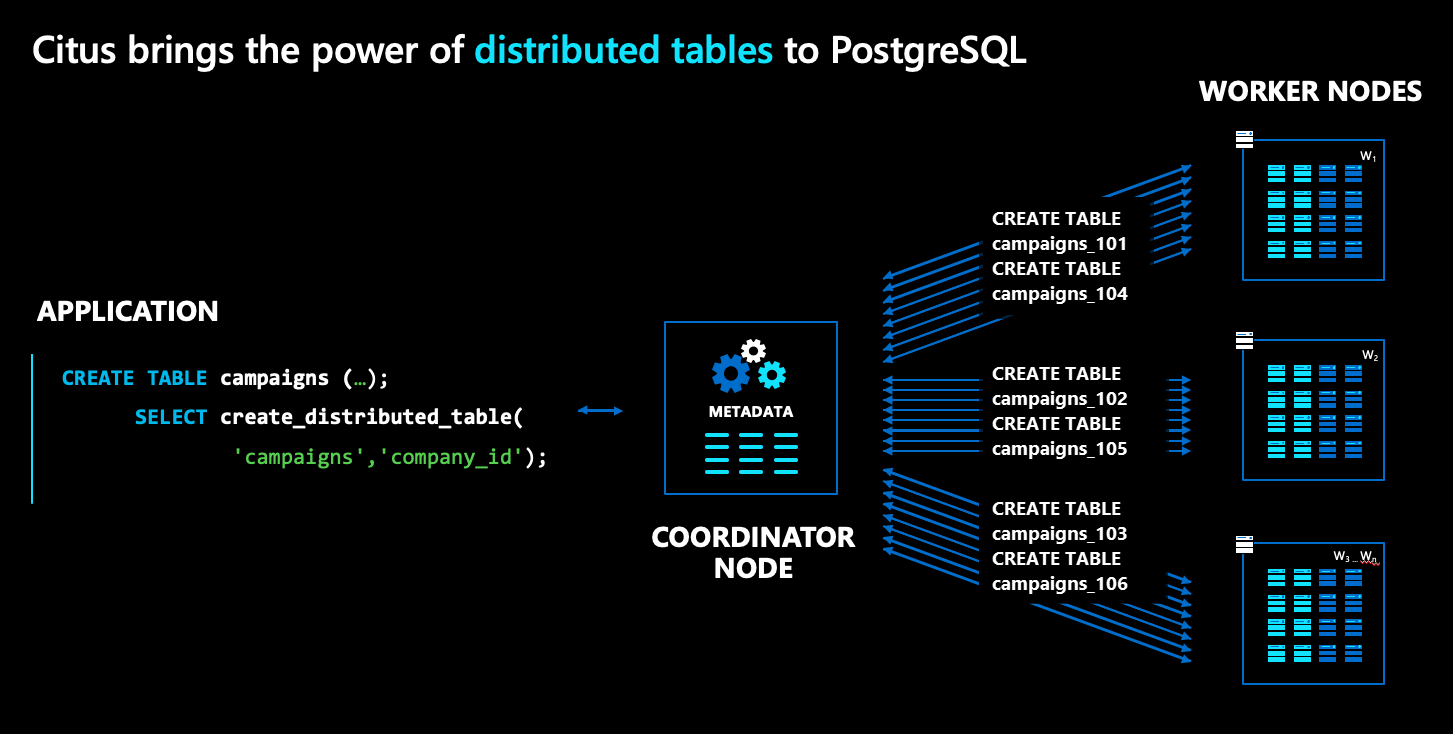
Na arquitetura do Azure Cosmos DB para PostgreSQL, há vários tipos de nós:
- O nó coordenador armazena metadados de tabela distribuída e é responsável pelo planejamento distribuído.
- Por outro lado, os nós de trabalho armazenam os dados reais, metadados e fazem o cálculo.
- Tanto o coordenador quanto os trabalhadores são bancos de dados PostgreSQL simples, com a
citusextensão carregada.
Para distribuir uma tabela PostgreSQL normal, como campaigns no diagrama acima, execute um comando chamado create_distributed_table(). Depois de executar esse comando, o Azure Cosmos DB para PostgreSQL cria fragmentos transparentes para a tabela nos nós de trabalho. No diagrama, os fragmentos são representados como caixas azuis.
Para distribuir um esquema PostgreSQL normal, execute o citus_schema_distribute() comando. Depois de executar esse comando, o Azure Cosmos DB para PostgreSQL transforma de forma transparente as tabelas nesses esquemas em uma única tabela colocalizada de fragmento que pode ser movida como uma unidade entre nós do cluster.
Nota
Em um cluster sem nós de trabalho, fragmentos de tabelas distribuídas estão no nó coordenador.
Os fragmentos são tabelas PostgreSQL simples (mas especialmente nomeadas) que contêm fatias dos seus dados. No nosso exemplo, porque distribuímos campaigns pela company_id, os shards realizam campanhas, onde as campanhas de diferentes empresas são atribuídas a diferentes estilhaços.
Coluna de distribuição (também conhecida como chave de estilhaço)
create_distributed_table() é a função mágica que o Azure Cosmos DB para PostgreSQL fornece para distribuir tabelas e usar recursos em várias máquinas.
SELECT create_distributed_table(
'table_name',
'distribution_column');
O segundo argumento acima escolhe uma coluna da tabela como uma coluna de distribuição. Pode ser qualquer coluna com um tipo PostgreSQL nativo (com inteiro e texto sendo mais comuns). O valor da coluna de distribuição determina quais linhas entram em quais fragmentos, e é por isso que a coluna de distribuição também é chamada de chave de estilhaço.
O Azure Cosmos DB para PostgreSQL decide como executar consultas com base no uso da chave de estilhaço:
| A consulta envolve | Onde corre |
|---|---|
| apenas uma chave de fragmento | no nó de trabalho que mantém o estilhaço |
| várias teclas de estilhaços | paralelizado em vários nós |
A escolha da chave de estilhaço dita o desempenho e a escalabilidade das suas aplicações.
- A distribuição desigual de dados por chaves de estilhaço (também conhecida como distorção de dados) não é ideal para o desempenho. Por exemplo, não escolha uma coluna para a qual um único valor represente 50% dos dados.
- Chaves de estilhaço com baixa cardinalidade podem afetar a escalabilidade. Você pode usar apenas quantos fragmentos houver valores de chave distintos. Escolha uma chave com cardinalidade entre centenas e milhares.
- Juntar duas grandes mesas com teclas de estilhaços diferentes pode ser lento. Escolha uma chave de fragmento comum em mesas grandes. Saiba mais em colocation.
Colocalização
Outro conceito intimamente relacionado com a chave de estilhaço é o colocation. As tabelas fragmentadas pelos mesmos valores de coluna de distribuição são colocalizadas - Os fragmentos das tabelas colocalizadas são armazenados juntos nos mesmos trabalhadores.
Abaixo estão duas tabelas fragmentadas pela mesma chave, site_id. Eles são colocalizados.
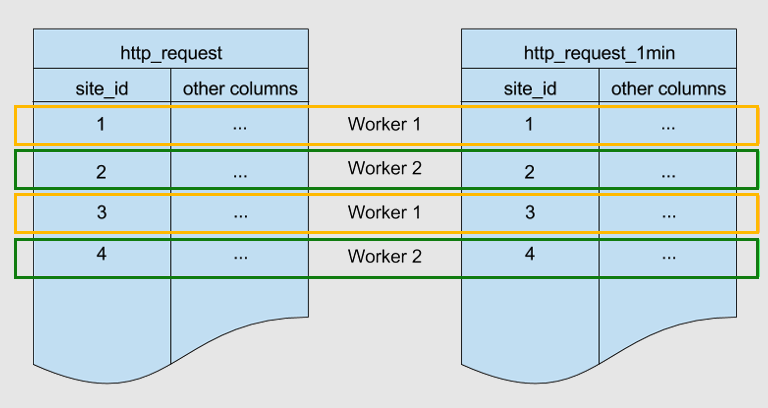
O Azure Cosmos DB para PostgreSQL garante que as linhas com um valor correspondente site_id em ambas as tabelas sejam armazenadas no mesmo nó de trabalho. Você pode ver que, para ambas as tabelas, as linhas com site_id=1 são armazenadas no trabalhador 1. Da mesma forma para outros IDs de site.
O colocation ajuda a otimizar as JOINs nessas tabelas. Se você unir as duas tabelas no site_id, o Azure Cosmos DB para PostgreSQL poderá executar a junção localmente em nós de trabalho sem embaralhar dados entre nós.
As tabelas dentro de um esquema distribuído são sempre colocalizadas entre si.