Copiar dados de ou para o Azure Data Explorer usando o Azure Data Factory ou o Synapse Analytics
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a atividade de cópia nos pipelines do Azure Data Factory e do Synapse Analytics para copiar dados de ou para o Azure Data Explorer. Ele se baseia no artigo de visão geral da atividade de cópia, que oferece uma visão geral da atividade de cópia.
Gorjeta
Para saber mais sobre a integração do Azure Data Explorer com o serviço em geral, leia Integrar o Azure Data Explorer.
Capacidades suportadas
Este conector do Azure Data Explorer tem suporte para os seguintes recursos:
| Capacidades suportadas | IR |
|---|---|
| Atividade de cópia (origem/coletor) | (1) (2) |
| Mapeando o fluxo de dados (origem/coletor) | (1) |
| Atividade de Pesquisa | (1) (2) |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Você pode copiar dados de qualquer armazenamento de dados de origem com suporte para o Azure Data Explorer. Você também pode copiar dados do Azure Data Explorer para qualquer armazenamento de dados de coletor com suporte. Para obter uma lista de armazenamentos de dados que a atividade de cópia suporta como fontes ou coletores, consulte a tabela Armazenamentos de dados suportados.
Nota
A cópia de dados de ou para o Azure Data Explorer por meio de um armazenamento de dados local usando o tempo de execução de integração auto-hospedado é suportada na versão 3.14 e posterior.
Com o conector do Azure Data Explorer, você pode fazer o seguinte:
- Copie dados usando a autenticação de token de aplicativo do Microsoft Entra com uma entidade de serviço.
- Como fonte, recupere dados usando uma consulta KQL (Kusto).
- Como um coletor, acrescente dados a uma tabela de destino.
Introdução
Gorjeta
Para obter um passo a passo do conector do Azure Data Explorer, consulte Copiar dados de/para o Azure Data Explorer e Copiar em massa de um banco de dados para o Azure Data Explorer.
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Azure Data Explorer usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Azure Data Explorer na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Procure o Explorer e selecione o conector do Azure Data Explorer (Kusto).
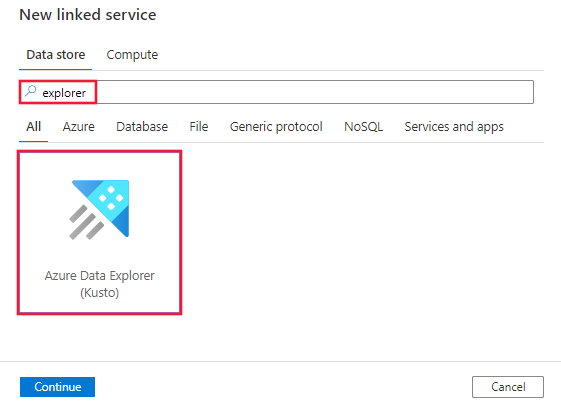
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
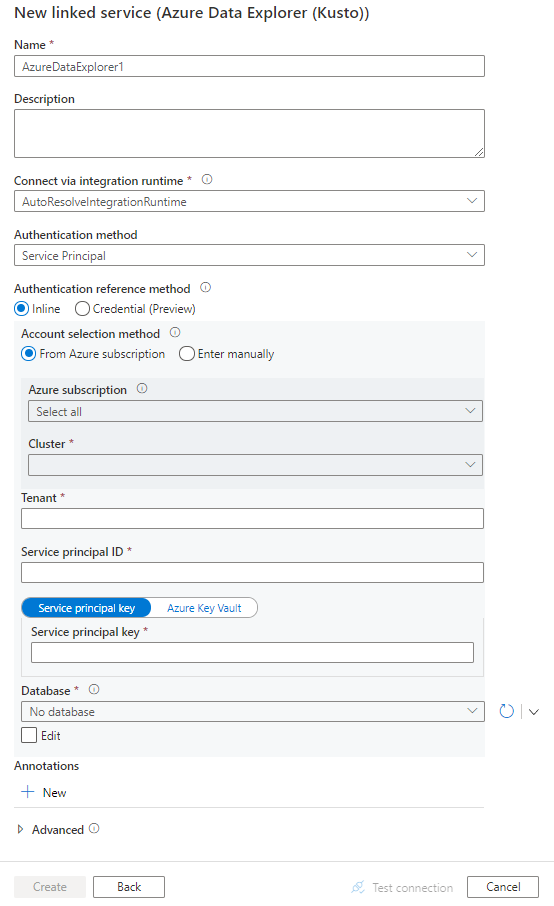
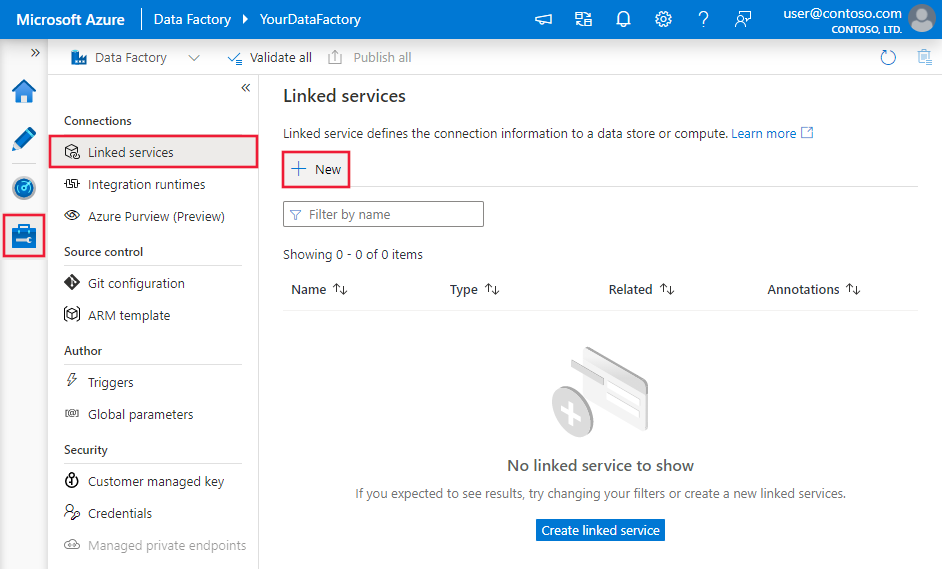
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades específicas para o conector do Azure Data Explorer.
Propriedades do serviço vinculado
O conector do Azure Data Explorer dá suporte aos seguintes tipos de autenticação. Consulte as seções correspondentes para obter detalhes:
- Autenticação do principal de serviço
- Autenticação de identidade gerenciada atribuída pelo sistema
- Autenticação de identidade gerenciada atribuída pelo usuário
Autenticação do principal de serviço
Para usar a autenticação da entidade de serviço, siga estas etapas para obter uma entidade de serviço e conceder permissões:
Registre um aplicativo com a plataforma de identidade da Microsoft. Para saber como, consulte Guia de início rápido: registrar um aplicativo com a plataforma de identidade da Microsoft. Anote estes valores, que você usa para definir o serviço vinculado:
- ID da aplicação
- Chave de aplicação
- ID de Inquilino do
Conceda à entidade de serviço as permissões corretas no Azure Data Explorer. Consulte Gerenciar permissões de banco de dados do Azure Data Explorer para obter informações detalhadas sobre funções e permissões e sobre como gerenciar permissões. Em geral, deve:
- Como origem, conceda pelo menos a função de visualizador de banco de dados ao seu banco de dados
- Como coletor, conceda pelo menos a função de usuário Banco de Dados ao seu banco de dados
Nota
Quando você usa a interface do usuário para criar, por padrão, sua conta de usuário de logon é usada para listar clusters, bancos de dados e tabelas do Azure Data Explorer. Você pode optar por listar os objetos usando a entidade de serviço clicando na lista suspensa ao lado do botão de atualização ou inserir manualmente o nome se não tiver permissão para essas operações.
As seguintes propriedades têm suporte para o serviço vinculado do Azure Data Explorer:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureDataExplorer. | Sim |
| endpoint | URL do ponto de extremidade do cluster do Azure Data Explorer, com o formato como https://<clusterName>.<regionName>.kusto.windows.net. |
Sim |
| base de dados | Nome da base de dados. | Sim |
| tenant | Especifique as informações do locatário (nome de domínio ou ID do locatário) sob as quais seu aplicativo reside. Isso é conhecido como "ID de autoridade" na cadeia de conexão Kusto. Recupere-o passando o ponteiro do mouse no canto superior direito do portal do Azure. | Sim |
| servicePrincipalId | Especifique o ID do cliente do aplicativo. Isso é conhecido como "Microsoft Entra application client ID" na cadeia de conexão Kusto. | Sim |
| servicePrincipalKey | Especifique a chave do aplicativo. Isso é conhecido como "Microsoft Entra application key" na cadeia de conexão Kusto. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a dados seguros armazenados no Cofre de Chaves do Azure. | Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou um tempo de execução de integração auto-hospedado se seu armazenamento de dados estiver em uma rede privada. Se não for especificado, o tempo de execução de integração padrão do Azure será usado. | Não |
Exemplo: usando a autenticação de chave da entidade de serviço
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
Autenticação de identidade gerenciada atribuída pelo sistema
Para saber mais sobre identidades gerenciadas para recursos do Azure, consulte Identidades gerenciadas para recursos do Azure.
Para usar a autenticação de identidade gerenciada atribuída pelo sistema, siga estas etapas para conceder permissões:
Recupere as informações de identidade gerenciadas copiando o valor do ID do objeto de identidade gerenciado gerado junto com sua fábrica ou espaço de trabalho Sinapse.
Conceda à identidade gerenciada as permissões corretas no Azure Data Explorer. Consulte Gerenciar permissões de banco de dados do Azure Data Explorer para obter informações detalhadas sobre funções e permissões e sobre como gerenciar permissões. Em geral, deve:
- Como origem, conceda a função Visualizador de banco de dados ao seu banco de dados.
- Como coletor, conceda as funções Ingestor de banco de dados e Visualizador de banco de dados ao seu banco de dados.
Nota
Quando você usa a interface do usuário para criar, sua conta de usuário de logon é usada para listar clusters, bancos de dados e tabelas do Azure Data Explorer. Introduza manualmente o nome se não tiver permissão para estas operações.
As seguintes propriedades têm suporte para o serviço vinculado do Azure Data Explorer:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureDataExplorer. | Sim |
| endpoint | URL do ponto de extremidade do cluster do Azure Data Explorer, com o formato como https://<clusterName>.<regionName>.kusto.windows.net. |
Sim |
| base de dados | Nome da base de dados. | Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou um tempo de execução de integração auto-hospedado se seu armazenamento de dados estiver em uma rede privada. Se não for especificado, o tempo de execução de integração padrão do Azure será usado. | Não |
Exemplo: usando autenticação de identidade gerenciada atribuída pelo sistema
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
Autenticação de identidade gerenciada atribuída pelo usuário
Para saber mais sobre identidades gerenciadas para recursos do Azure, consulte Identidades gerenciadas para recursos do Azure
Para usar a autenticação de identidade gerenciada atribuída pelo usuário, siga estas etapas:
Crie uma ou várias identidades gerenciadas atribuídas pelo usuário e conceda permissão no Azure Data Explorer. Consulte Gerenciar permissões de banco de dados do Azure Data Explorer para obter informações detalhadas sobre funções e permissões e sobre como gerenciar permissões. Em geral, deve:
- Como origem, conceda pelo menos a função de visualizador de banco de dados ao seu banco de dados
- Como coletor, conceda pelo menos a função de ingestor de banco de dados ao seu banco de dados
Atribua uma ou várias identidades gerenciadas atribuídas pelo usuário ao seu data factory ou espaço de trabalho Synapse e crie credenciais para cada identidade gerenciada atribuída pelo usuário.
As seguintes propriedades têm suporte para o serviço vinculado do Azure Data Explorer:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureDataExplorer. | Sim |
| endpoint | URL do ponto de extremidade do cluster do Azure Data Explorer, com o formato como https://<clusterName>.<regionName>.kusto.windows.net. |
Sim |
| base de dados | Nome da base de dados. | Sim |
| credenciais | Especifique a identidade gerenciada atribuída pelo usuário como o objeto de credencial. | Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou um tempo de execução de integração auto-hospedado se seu armazenamento de dados estiver em uma rede privada. Se não for especificado, o tempo de execução de integração padrão do Azure será usado. | Não |
Exemplo: usando a autenticação de identidade gerenciada atribuída pelo usuário
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte Conjuntos de dados. Esta seção lista as propriedades suportadas pelo conjunto de dados do Azure Data Explorer.
Para copiar dados para o Azure Data Explorer, defina a propriedade type do conjunto de dados como AzureDataExplorerTable.
As seguintes propriedades são suportadas:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureDataExplorerTable. | Sim |
| tabela | O nome da tabela à qual o serviço vinculado se refere. | Sim para pia; Não para a fonte |
Exemplo de propriedades de conjunto de dados:
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte Pipelines e atividades. Esta seção fornece uma lista de propriedades que as fontes e coletores do Azure Data Explorer suportam.
Azure Data Explorer como origem
Para copiar dados do Azure Data Explorer, defina a propriedade type na fonte de atividade Copy como AzureDataExplorerSource. As seguintes propriedades são suportadas na seção de origem da atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como: AzureDataExplorerSource | Sim |
| query | Uma solicitação somente leitura fornecida em um formato KQL. Use a consulta KQL personalizada como referência. | Sim |
| queryTimeout | O tempo de espera antes que a solicitação de consulta atinja o tempo limite. O valor padrão é 10 min (00:10:00); O valor máximo permitido é de 1 hora (01:00:00). | Não |
| noTruncamento | Indica se o conjunto de resultados retornado deve ser truncado. Por padrão, o resultado é truncado após 500.000 registros ou 64 megabytes (MB). O truncamento é altamente recomendado para garantir o comportamento correto da atividade. | Não |
Nota
Por padrão, a fonte do Azure Data Explorer tem um limite de tamanho de 500.000 registros ou 64 MB. Para recuperar todos os registros sem truncamento, você pode especificar set notruncation; no início da consulta. Para obter mais informações, consulte Limites de consulta.
Exemplo:
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
Azure Data Explorer como coletor
Para copiar dados para o Azure Data Explorer, defina a propriedade type no coletor de atividade de cópia como AzureDataExplorerSink. As seguintes propriedades são suportadas na seção coletor de atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do coletor de atividade de cópia deve ser definida como: AzureDataExplorerSink. | Sim |
| ingestionMappingName | Nome de um mapeamento pré-criado em uma tabela Kusto. Para mapear as colunas da origem para o Azure Data Explorer (que se aplica a todos os armazenamentos e formatos de origem suportados, incluindo formatos CSV/JSON/Avro), você pode usar o mapeamento de coluna de atividade de cópia (implicitamente pelo nome ou explicitamente conforme configurado) e/ou mapeamentos do Azure Data Explorer. | Não |
| additionalProperties | Um pacote de propriedades que pode ser usado para especificar qualquer uma das propriedades de ingestão que ainda não estão sendo definidas pelo Coletor do Azure Data Explorer. Especificamente, pode ser útil para especificar etiquetas de ingestão. Saiba mais no documento de ingestão de dados do Azure Data Explore. | Não |
Exemplo:
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Mapeando propriedades de fluxo de dados
Ao transformar dados em mapeamento de fluxo de dados, você pode ler e gravar em tabelas no Azure Data Explorer. Para obter mais informações, consulte a transformação de origem e a transformação de coletor no mapeamento de fluxos de dados. Você pode optar por usar um conjunto de dados do Azure Data Explorer ou um conjunto de dados embutido como tipo de fonte e coletor.
Transformação da fonte
A tabela abaixo lista as propriedades suportadas pela origem do Azure Data Explorer. Você pode editar essas propriedades na guia Opções de origem .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Tabela | Se você selecionar Tabela como entrada, o fluxo de dados buscará todos os dados da tabela especificada no conjunto de dados do Azure Data Explorer ou nas opções de origem ao usar o conjunto de dados embutido. | Não | String | (apenas para conjunto de dados embutido) tableName |
| Query | Uma solicitação somente leitura fornecida em um formato KQL. Use a consulta KQL personalizada como referência. | Não | String | query |
| Limite de tempo excedido | O tempo de espera antes que a solicitação de consulta atinja o tempo limite. O padrão é '172000' (2 dias) | Não | Número inteiro | tempo limite |
Exemplos de script de origem do Azure Data Explorer
Quando você usa o conjunto de dados do Azure Data Explorer como tipo de origem, o script de fluxo de dados associado é:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
Se você usar o conjunto de dados embutido, o script de fluxo de dados associado será:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
Transformação do lavatório
A tabela abaixo lista as propriedades suportadas pelo coletor do Azure Data Explorer. Você pode editar essas propriedades na guia Configurações. Ao usar o conjunto de dados embutido, você verá configurações adicionais, que são as mesmas que as propriedades descritas na seção de propriedades do conjunto de dados.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Ação da tabela | Determina se todas as linhas da tabela de destino devem ser recriadas ou removidas antes da gravação. - Nenhuma: Nenhuma ação será feita para a mesa. - Recriar: A tabela será descartada e recriada. Necessário se criar uma nova tabela dinamicamente. - Truncate: Todas as linhas da tabela de destino serão removidas. |
Não | true ou false |
recriar truncate |
| Scripts pré e pós SQL | Especifique vários scripts de comandos de controle Kusto que serão executados antes (pré-processamento) e depois que os dados (pós-processamento) forem gravados no banco de dados do coletor. | Não | String | pré-SQLs; postSQLs |
| Limite de tempo excedido | O tempo de espera antes que a solicitação de consulta atinja o tempo limite. O padrão é '172000' (2 dias) | Não | Número inteiro | tempo limite |
Exemplos de script de coletor do Azure Data Explorer
Quando você usa o conjunto de dados do Azure Data Explorer como tipo de coletor, o script de fluxo de dados associado é:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Se você usar o conjunto de dados embutido, o script de fluxo de dados associado será:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Propriedades da atividade de pesquisa
Para obter mais informações sobre as propriedades, consulte Atividade de pesquisa.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados que a atividade de cópia suporta como fontes e coletores, consulte Armazenamentos de dados suportados.
Saiba mais sobre como copiar dados do Azure Data Factory e do Synapse Analytics para o Azure Data Explorer.