Transformação agregada no mapeamento do fluxo de dados
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Os fluxos de dados estão disponíveis no Azure Data Factory e no Azure Synapse Pipelines. Este artigo aplica-se ao mapeamento de fluxos de dados. Se você é novo em transformações, consulte o artigo introdutório Transformar dados usando um fluxo de dados de mapeamento.
A transformação Agregar define agregações de colunas em seus fluxos de dados. Usando o Construtor de Expressões, você pode definir diferentes tipos de agregações, como SUM, MIN, MAX e COUNT agrupadas por colunas existentes ou computadas.
Agrupar por
Selecione uma coluna existente ou crie uma nova coluna computada para usar como uma cláusula de grupo por para sua agregação. Para usar uma coluna existente, selecione-a na lista suspensa. Para criar uma nova coluna computada, passe o mouse sobre a cláusula e clique em Coluna computada. Isso abre o construtor de expressões de fluxo de dados. Depois de criar a coluna computada, insira o nome da coluna de saída sob o campo Nome como . Se desejar adicionar um grupo adicional por cláusula, passe o mouse sobre uma cláusula existente e clique no ícone de mais.
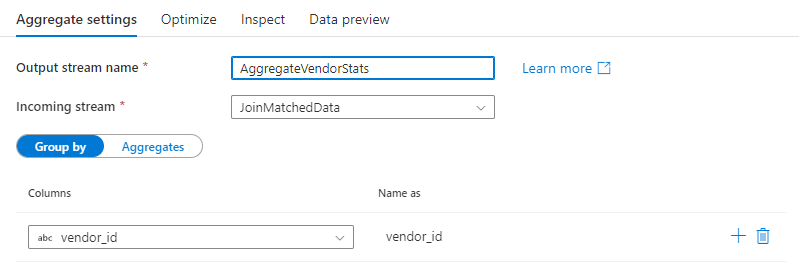
Um grupo por cláusula é opcional em uma transformação Agregada.
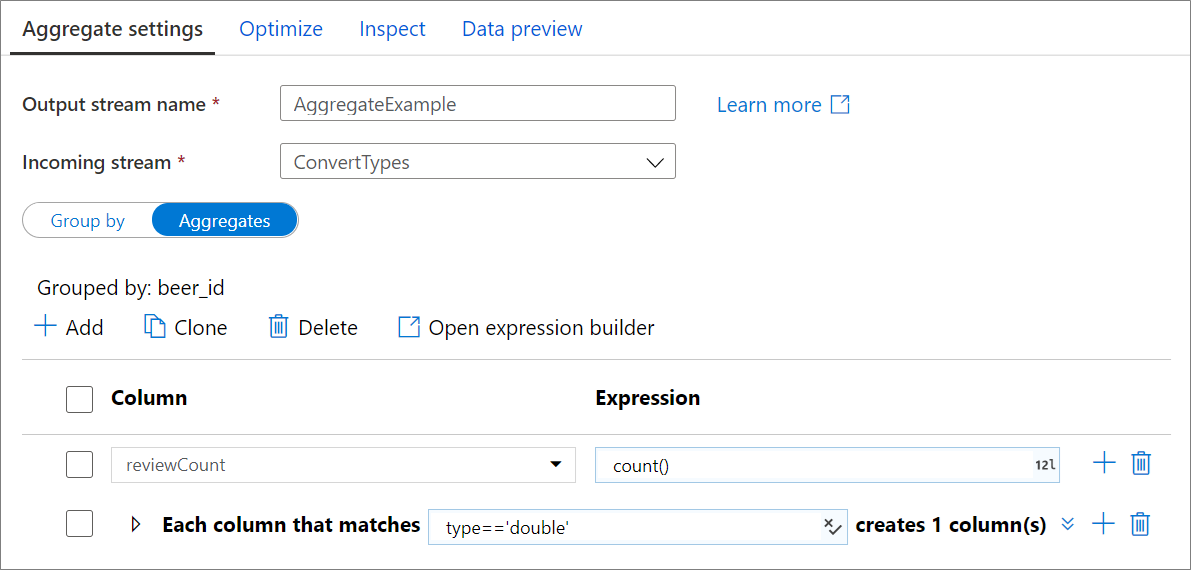
Agregar colunas
Vá para a guia Agregações para criar expressões de agregação. Você pode substituir uma coluna existente por uma agregação ou criar um novo campo com um novo nome. A expressão de agregação é inserida na caixa à direita ao lado do seletor de nome de coluna. Para editar a expressão, clique na caixa de texto e abra o construtor de expressões. Para adicionar mais colunas agregadas, clique em Adicionar acima da lista de colunas ou no ícone de adição ao lado de uma coluna agregada existente. Escolha Adicionar coluna ou Adicionar padrão de coluna. Cada expressão de agregação deve conter pelo menos uma função agregada.
Nota
No modo de depuração, o construtor de expressões não pode produzir visualizações de dados com funções agregadas. Para visualizar visualizações de dados para transformações agregadas, feche o construtor de expressões e visualize os dados por meio da guia 'Visualização de dados'.
Padrões de coluna
Use padrões de coluna para aplicar a mesma agregação a um conjunto de colunas. Isso é útil se você deseja persistir muitas colunas do esquema de entrada à medida que elas são descartadas por padrão. Use uma heurística como first() para persistir colunas de entrada através da agregação.
Reconectar linhas e colunas
As transformações agregadas são semelhantes às consultas SQL aggregate select. As colunas que não estão incluídas no seu grupo por cláusula ou funções agregadas não fluirão para a saída da sua transformação agregada. Se desejar incluir outras colunas na saída agregada, siga um destes métodos:
- Use uma função agregada, como
last()oufirst()para incluir essa coluna adicional. - Rejunte as colunas ao seu fluxo de saída usando o padrão de auto-junção.
Remoção de linhas duplicadas
Um uso comum da transformação agregada é remover ou identificar entradas duplicadas nos dados de origem. Este processo é conhecido como desduplicação. Com base em um conjunto de grupos por chaves, use uma heurística de sua escolha para determinar qual linha duplicada deve ser mantida. As heurísticas comuns são first(), last(), max(), e min(). Use padrões de coluna para aplicar a regra a todas as colunas, exceto para o grupo por colunas.
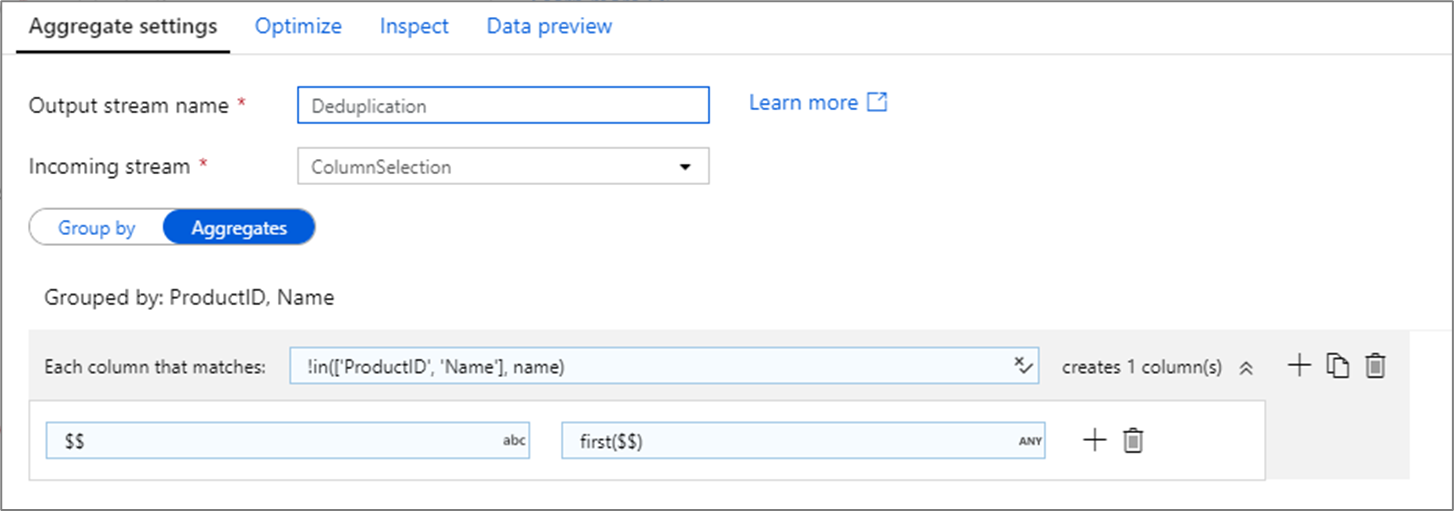
No exemplo acima, colunas ProductID e Name estão sendo usadas para agrupamento. Se duas linhas tiverem os mesmos valores para essas duas colunas, elas serão consideradas duplicadas. Nesta transformação agregada, os valores da primeira linha correspondida serão mantidos e todos os outros serão descartados. Usando a sintaxe do padrão de coluna, todas as colunas cujos nomes não ProductID são e Name são mapeadas para o nome da coluna existente e recebem o valor das primeiras linhas correspondentes. O esquema de saída é o mesmo que o esquema de entrada.
Para cenários de validação de dados, a count() função pode ser usada para contar quantas duplicatas existem.
Script de fluxo de dados
Sintaxe
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Exemplo
O exemplo abaixo usa um fluxo MoviesYear de entrada e agrupa linhas por coluna year. A transformação cria uma coluna avgrating agregada que é avaliada de acordo com a média da coluna Rating. Essa transformação agregada é chamada AvgComedyRatingsByYearde .
Na interface do usuário, essa transformação se parece com a imagem abaixo:
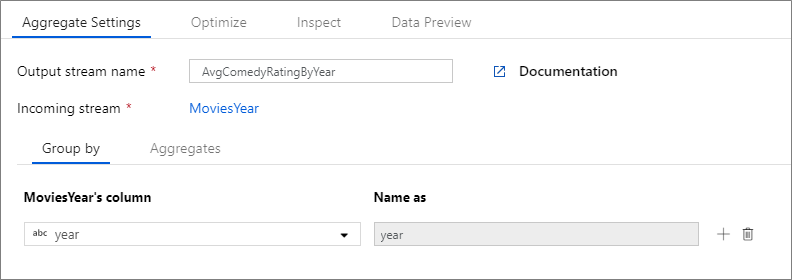
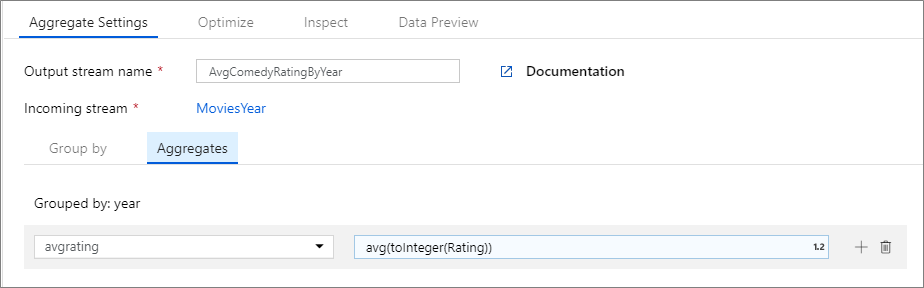
O script de fluxo de dados para essa transformação está no trecho abaixo.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
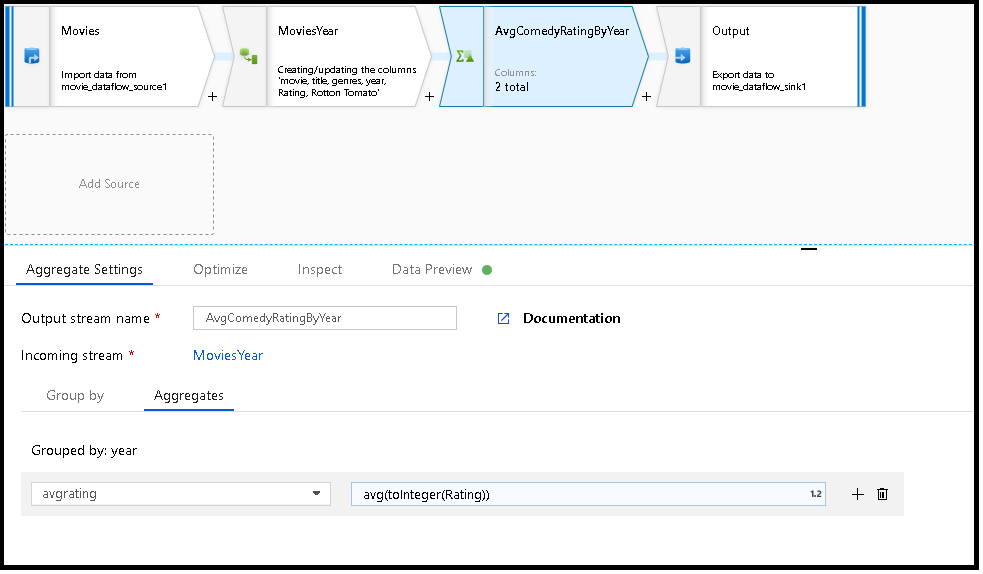
MoviesYear: Coluna derivada que define as colunas AvgComedyRatingByYearde ano e título : Transformação agregada para a classificação média das comédias agrupadas por ano avgrating: Nome da nova coluna que está a ser criada para manter o valor agregado
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Conteúdos relacionados
- Definir agregação baseada em janela usando a transformação Window