Migrar esquema de banco de dados normalizado do Banco de Dados SQL do Azure para o contêiner desnormalizado do Azure Cosmos DB
Este guia explica como pegar um esquema de banco de dados normalizado existente no Banco de Dados SQL do Azure e convertê-lo em um esquema desnormalizado do Azure Cosmos DB para carregar no Azure Cosmos DB.
Os esquemas SQL são normalmente modelados usando o terceiro formulário normal, resultando em esquemas normalizados que fornecem altos níveis de integridade de dados e menos valores de dados duplicados. As consultas podem unir entidades entre tabelas para leitura. O Azure Cosmos DB é otimizado para transações super-rápidas e consultas dentro de uma coleção ou contêiner por meio de esquemas desnormalizados com dados autônomos dentro de um documento.
Usando o Azure Data Factory, criamos um pipeline que usa um único Fluxo de Dados de Mapeamento para ler de duas tabelas normalizadas do Banco de Dados SQL do Azure que contêm chaves primárias e estrangeiras como o relacionamento de entidade. O data factory unirá essas tabelas em um único fluxo usando o mecanismo Spark de fluxo de dados, coletará linhas unidas em matrizes e produzirá documentos limpos individuais para inserção em um novo contêiner do Azure Cosmos DB.
Este guia cria um novo contêiner em tempo real chamado "pedidos" que usará as SalesOrderHeader tabelas e SalesOrderDetail do banco de dados de exemplo padrão do SQL Server Adventure Works. Estes quadros representam as operações de venda a que se juntou .SalesOrderID Cada registro de detalhe exclusivo tem sua própria chave primária de SalesOrderDetailID. A relação entre cabeçalho e detalhe é 1:M. Nós nos juntamos SalesOrderID no ADF e, em seguida, rolamos cada registro de detalhe relacionado em uma matriz chamada "detalhe".
A consulta SQL representativa para este guia é:
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
O contêiner resultante do Azure Cosmos DB incorpora a consulta interna em um único documento e tem esta aparência:

Criar um pipeline
Selecione +Novo pipeline para criar um novo pipeline.
Adicionar uma atividade de fluxo de dados
Na atividade de fluxo de dados, selecione Novo fluxo de dados de mapeamento.
Construímos este gráfico de fluxo de dados:
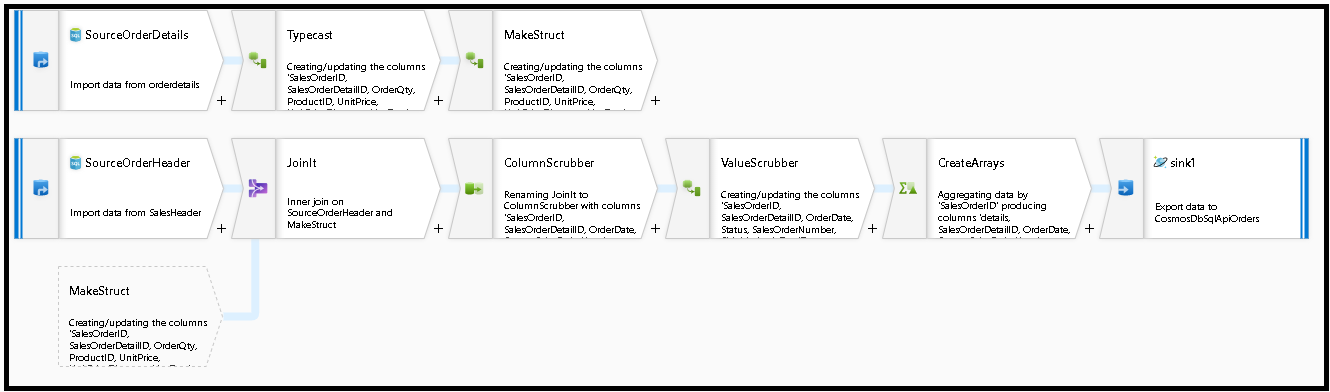
Defina a fonte para "SourceOrderDetails". Para o conjunto de dados, crie um novo conjunto de dados do Banco de Dados SQL do Azure que aponte para a
SalesOrderDetailtabela.Defina a origem para "SourceOrderHeader". Para o conjunto de dados, crie um novo conjunto de dados do Banco de Dados SQL do Azure que aponte para a
SalesOrderHeadertabela.Na fonte superior, adicione uma transformação de coluna derivada após "SourceOrderDetails". Chame a nova transformação de "TypeCast". Precisamos arredondar a coluna e convertê-la em um tipo de dados duplo para o
UnitPriceAzure Cosmos DB. Defina a fórmula para:toDouble(round(UnitPrice,2)).Adicione outra coluna derivada e chame-a de "MakeStruct". É aqui que criamos uma estrutura hierárquica para manter os valores da tabela de detalhes. Lembre-se, detalhes é uma
M:1relação com o cabeçalho. Nomeie a nova estruturaorderdetailsstructe crie a hierarquia desta forma, definindo cada subcoluna para o nome da coluna de entrada: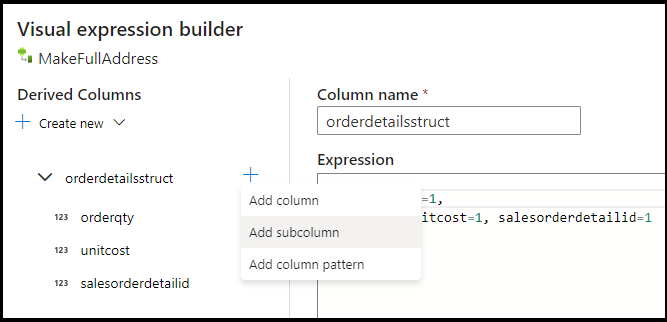
Agora, vamos para a fonte do cabeçalho de vendas. Adicione uma transformação Join (Ingressar). No lado direito, selecione "MakeStruct". Deixe-o definido como junção interna e escolha
SalesOrderIDpara ambos os lados da condição de junção.Selecione a guia Visualização de dados na nova associação que você adicionou para que você possa ver seus resultados até este ponto. Você deve ver todas as linhas de cabeçalho unidas com as linhas de detalhes. Este é o resultado da união que está sendo formada a partir do
SalesOrderID. Em seguida, combinamos os detalhes das linhas comuns nos detalhes struct e agregamos as linhas comuns.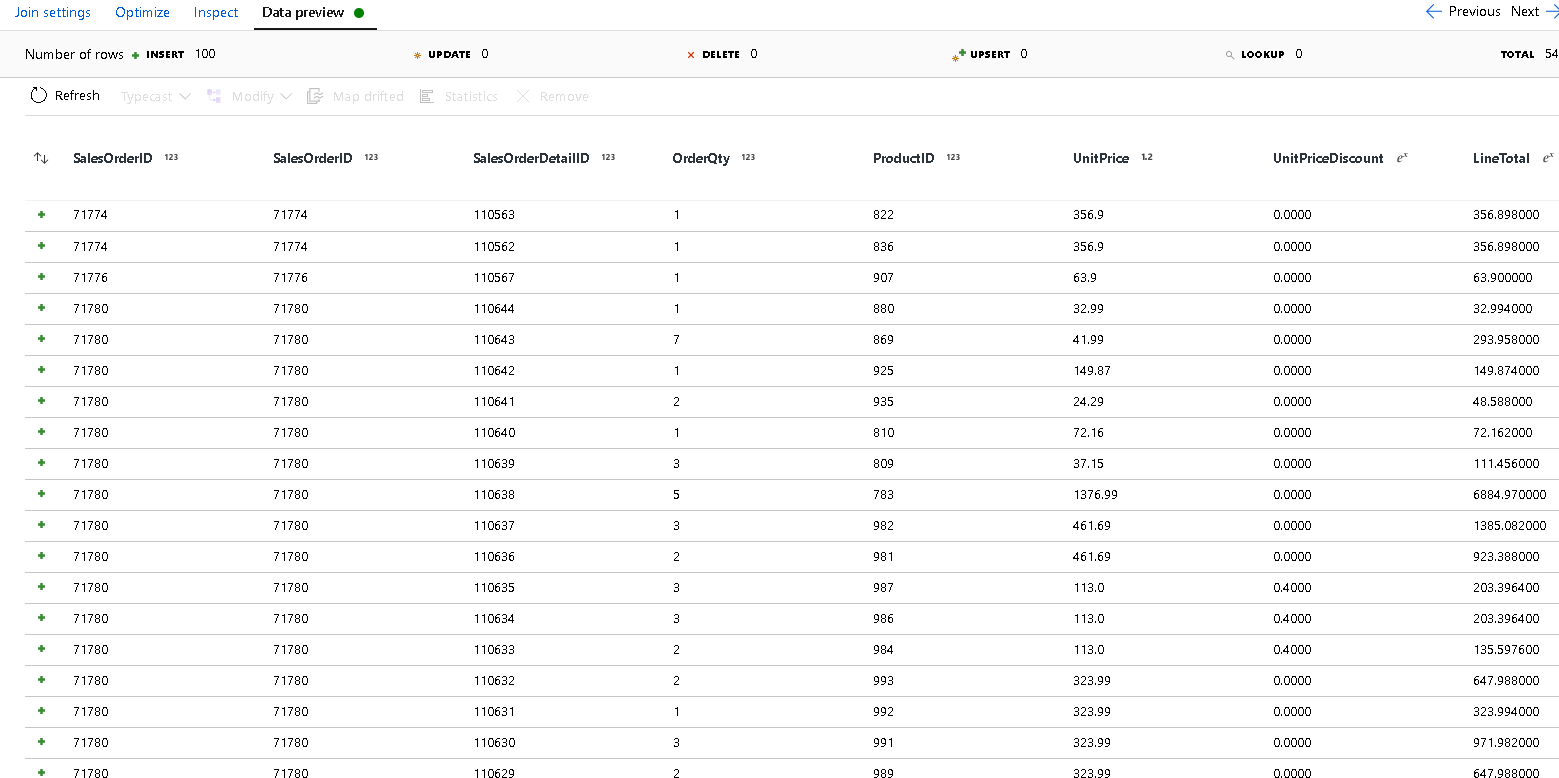
Antes de podermos criar as matrizes para desnormalizar essas linhas, primeiro precisamos remover colunas indesejadas e garantir que os valores de dados correspondam aos tipos de dados do Azure Cosmos DB.
Adicione uma transformação Select em seguida e defina o mapeamento de campo para ter esta aparência:
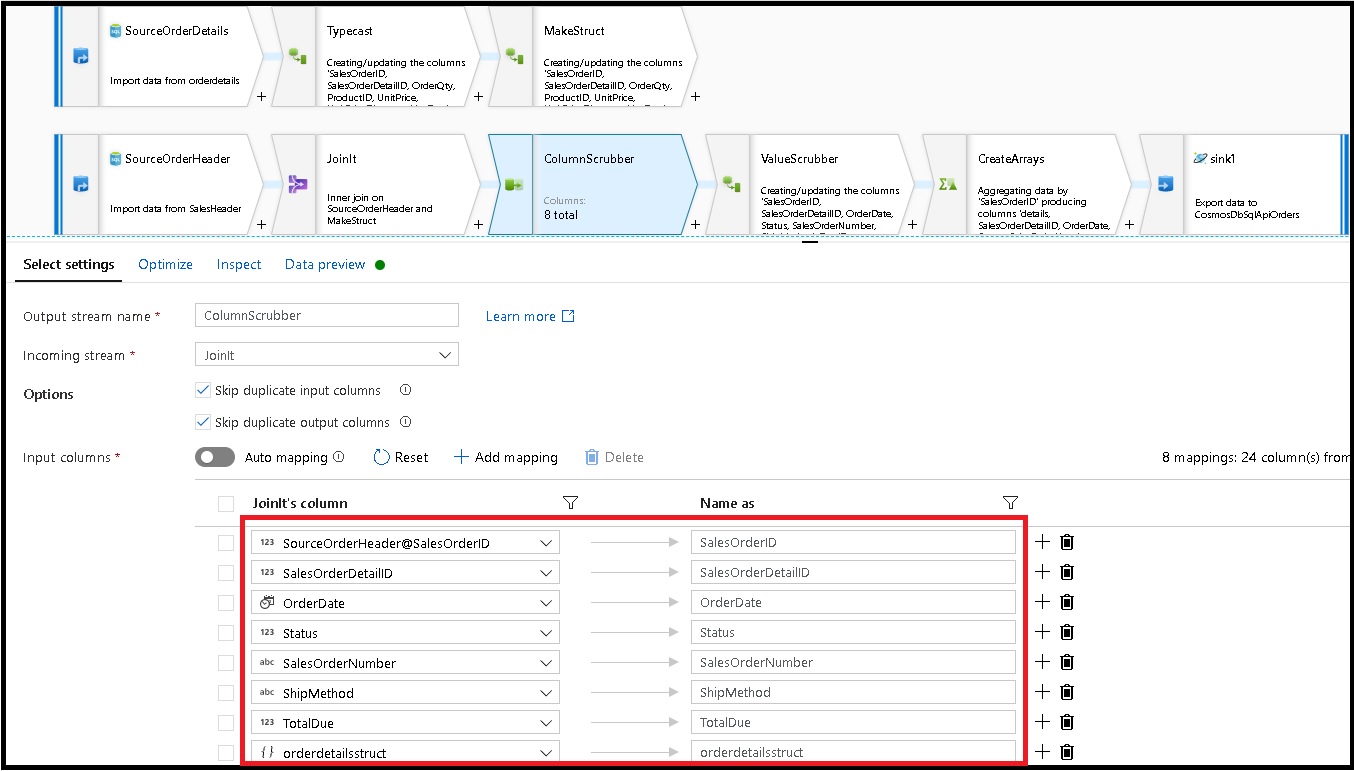
Agora vamos lançar novamente uma coluna de moeda, desta vez
TotalDue. Como fizemos acima na etapa 7, defina a fórmula para:toDouble(round(TotalDue,2)).É aqui que desnormalizamos as linhas agrupando pela chave
SalesOrderIDcomum. Adicione uma transformação Agregar e defina o grupo comoSalesOrderID.Na fórmula agregada, adicione uma nova coluna chamada "detalhes" e use essa fórmula para coletar os valores na estrutura que criamos anteriormente chamada
orderdetailsstruct:collect(orderdetailsstruct).A transformação agregada só produzirá colunas que fazem parte da agregação ou agrupam por fórmulas. Então, precisamos incluir as colunas do cabeçalho de vendas também. Para fazer isso, adicione um padrão de coluna nessa mesma transformação agregada. Esse padrão inclui todas as outras colunas na saída, excluindo as colunas listadas abaixo (OrderQty, UnitPrice, SalesOrderID):
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
Use a sintaxe "this" ($$) nas outras propriedades para que mantenhamos os mesmos nomes de coluna e usemos a
first()função como uma agregação. Isso diz ao ADF para manter o primeiro valor correspondente encontrado: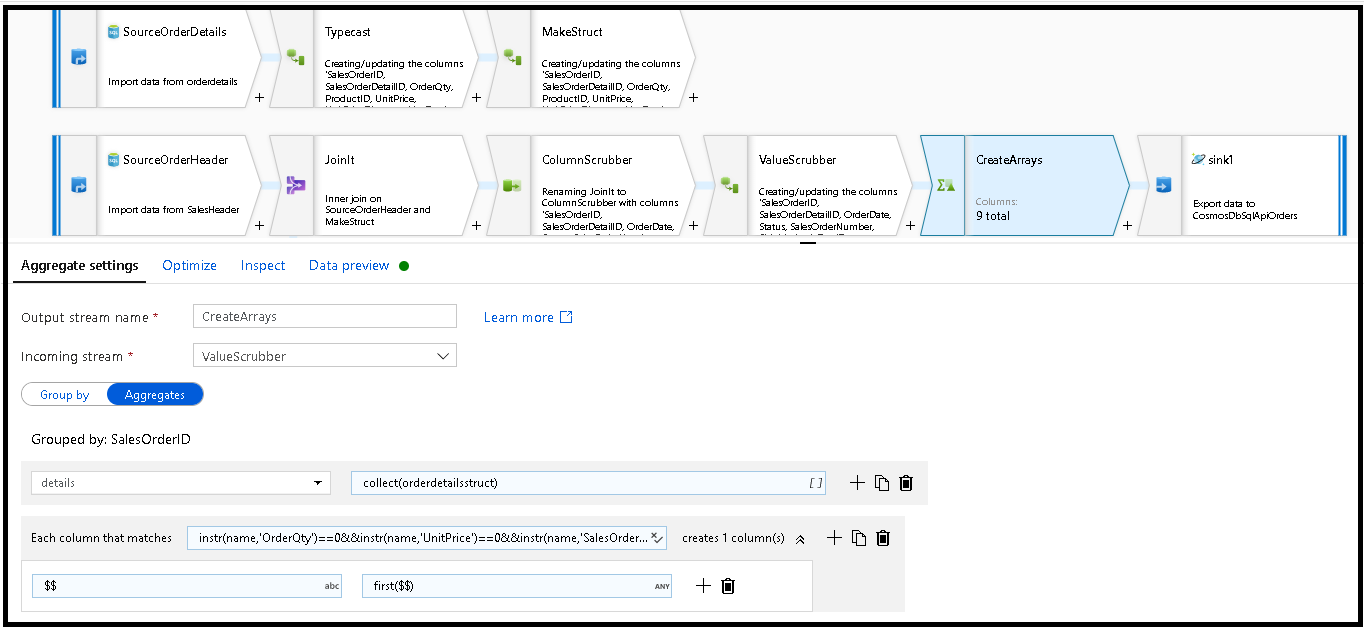
Estamos prontos para concluir o fluxo de migração adicionando uma transformação de coletor. Selecione "novo" ao lado do conjunto de dados e adicione um conjunto de dados do Azure Cosmos DB que aponte para seu banco de dados do Azure Cosmos DB. Para a coleção, chamamos de "pedidos" e ela não tem esquema nem documentos, pois será criada na hora.
Em Configurações do coletor, Chave de partição e
/SalesOrderIDação de coleta para "recriar". Verifique se a guia de mapeamento tem esta aparência: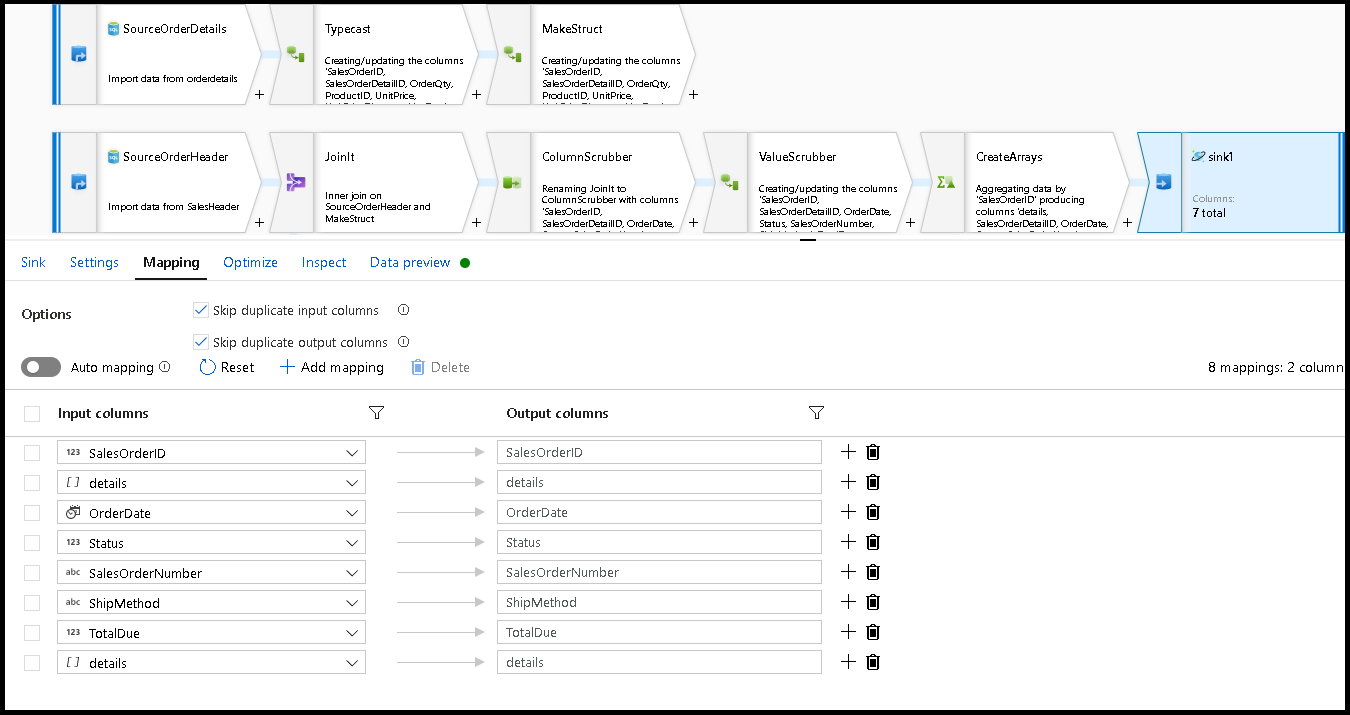
Selecione a pré-visualização de dados para se certificar de que está a ver estas 32 linhas definidas para inserir como novos documentos no seu novo contentor:
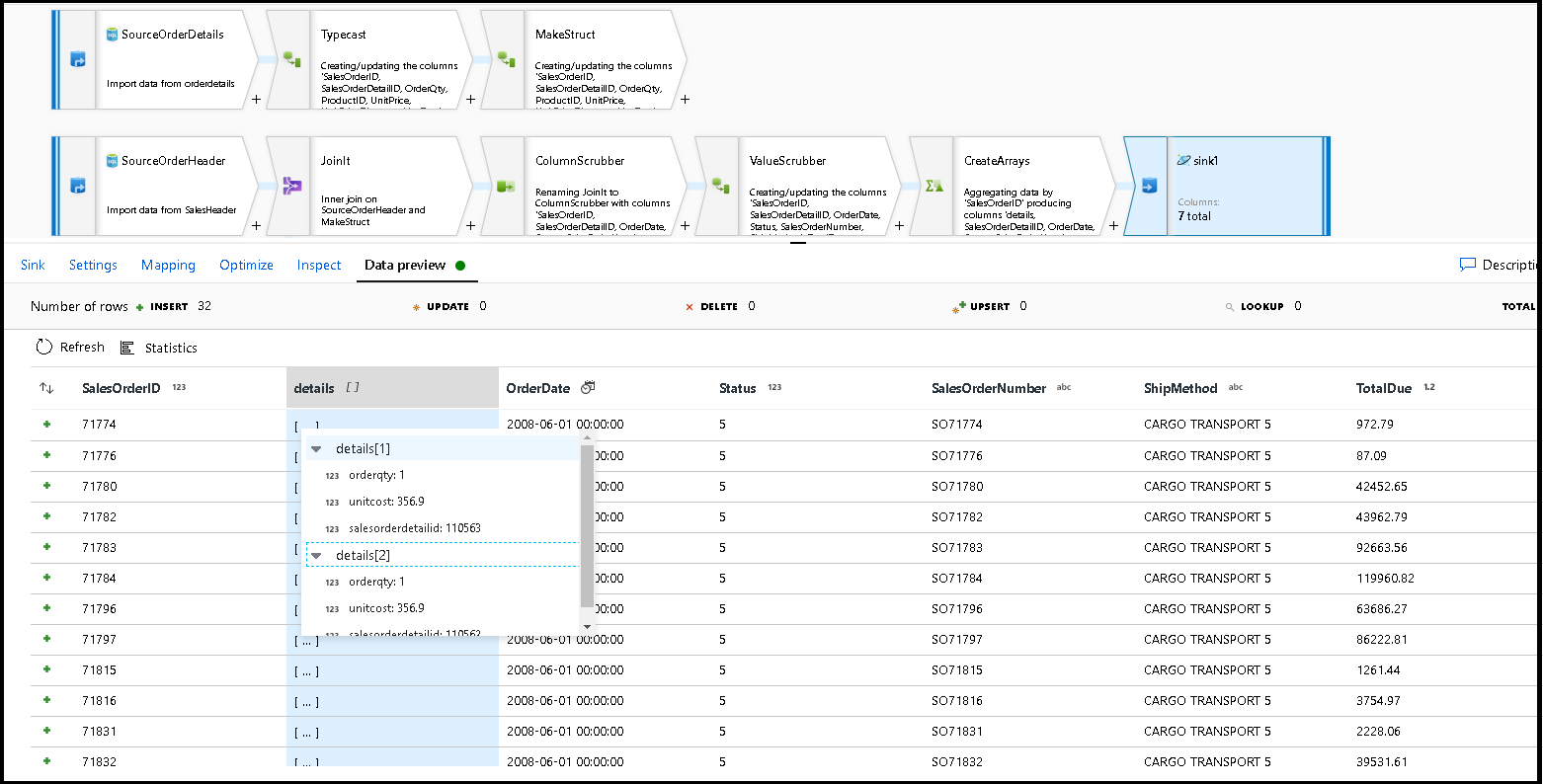
Se tudo parecer bom, agora você está pronto para criar um novo pipeline, adicionar essa atividade de fluxo de dados a esse pipeline e executá-lo. Você pode executar a partir da depuração ou de uma execução acionada. Após alguns minutos, você deve ter um novo contêiner desnormalizado de pedidos chamado "pedidos" em seu banco de dados do Azure Cosmos DB.
Conteúdos relacionados
- Crie o restante da lógica de fluxo de dados usando transformações de fluxos de dados de mapeamento.
- Baixe o modelo de pipeline concluído para este tutorial e importe o modelo para sua fábrica.