Instalar dependências do bloco de notas
Você pode instalar dependências Python para notebooks sem servidor usando o painel lateral Ambiente. Este painel fornece um único local para editar, visualizar e exportar os requisitos da biblioteca de um bloco de anotações. Essas dependências podem ser adicionadas usando um ambiente base ou individualmente.
Para tarefas que não sejam do bloco de anotações, consulte Configurar ambientes e dependências para tarefas que não sejam do bloco de anotações.
Importante
Não instale o PySpark ou qualquer biblioteca que instale o PySpark como uma dependência em seus notebooks sem servidor. Isso interromperá sua sessão e resultará em um erro. Se isso ocorrer, redefina seu ambiente.
Configurar um ambiente base
Um ambiente base é um arquivo YAML armazenado como um arquivo de espaço de trabalho ou em um volume do Catálogo Unity que especifica dependências de ambiente adicionais. Os ambientes básicos podem ser compartilhados entre notebooks. Para configurar um ambiente base:
Crie um arquivo YAML que define configurações para um ambiente virtual Python. O exemplo a seguir YAML, que é baseado na especificação de ambiente de projetos MLflow, define um ambiente base com algumas dependências de biblioteca:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - my-library==6.1 - "/Workspace/Shared/Path/To/simplejson-3.19.3-py3-none-any.whl" - git+https://github.com/databricks/databricks-cliCarregue o arquivo YAML como um arquivo de espaço de trabalho ou para um volume do Catálogo Unity. Consulte Importar um arquivo ou Carregar arquivos para um volume do Catálogo Unity.
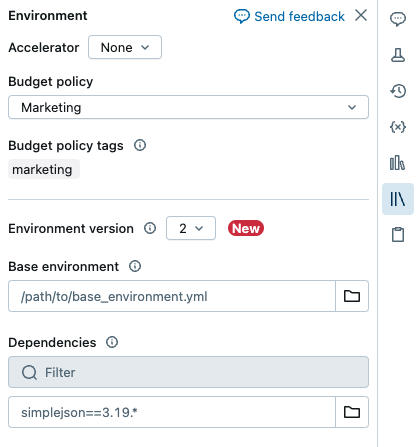
À direita do bloco de anotações, clique no
 botão para expandir o painel Ambiente . Esse botão só aparece quando um bloco de anotações está conectado à computação sem servidor.
botão para expandir o painel Ambiente . Esse botão só aparece quando um bloco de anotações está conectado à computação sem servidor.No campo Ambiente Base, insira o caminho do arquivo YAML carregado ou navegue até ele e selecione-o.
Clique em Aplicar. Isso instala as dependências no ambiente virtual do notebook e reinicia o processo do Python.
Os usuários podem substituir as dependências especificadas no ambiente base instalando dependências individualmente.
Configurar o ambiente do bloco de anotações
Você também pode instalar dependências em um bloco de anotações conectado à computação sem servidor usando a guia Dependências do painel Ambiente :
- À direita do bloco de anotações, clique no botão para expandir o painel Ambiente . Esse botão só aparece quando um bloco de anotações está conectado à computação sem servidor.
- Selecione a versão do ambiente na lista suspensa Versão do ambiente
. Consulte as versões do ambiente sem servidor . A Databricks recomenda escolher a versão mais recente para obter os recursos de notebook mais atualizados. - Na seção Dependências, clique em Adicionar Dependência e insira o caminho da dependência da biblioteca no campo. Você pode especificar uma dependência em qualquer formato que seja válido em um arquivo requirements.txt .
- Clique em Aplicar. Isso instala as dependências no ambiente virtual do notebook e reinicia o processo do Python.
Nota
Um trabalho usando computação sem servidor instalará a especificação de ambiente do bloco de anotações antes de executar o código do bloco de anotações. Isso significa que não há necessidade de adicionar dependências ao agendar blocos de anotações como trabalhos. Consulte Configurar ambientes e dependências.
Exibir dependências instaladas e logs pip
Para visualizar as dependências instaladas, clique em Instalado no painel lateral Ambientesde um bloco de anotações. Os registos de instalação do pip para o ambiente de notebook também estão disponíveis ao clicar em pip logs no fundo do painel.
Redefinir o ambiente
Se o seu bloco de notas estiver ligado a computação sem servidor, o Databricks armazenará automaticamente em cache o conteúdo do ambiente virtual do bloco de notas. Isso significa que você geralmente não precisa reinstalar as dependências Python especificadas no painel Ambiente quando abre um bloco de anotações existente, mesmo que ele tenha sido desconectado devido à inatividade.
O cache do ambiente virtual Python também se aplica a trabalhos. Isso significa que as execuções subsequentes de trabalhos são mais rápidas, pois as dependências necessárias já estão disponíveis.
Nota
Se você alterar a implementação de um pacote Python personalizado usado em um trabalho sem servidor, também deverá atualizar seu número de versão para que os trabalhos possam pegar a implementação mais recente.
Para limpar o cache do ambiente e executar uma nova instalação das dependências especificadas no painel Ambiente de um bloco de anotações conectado à computação sem servidor, clique na seta ao lado de Aplicar e, em seguida, clique em Redefinir ambiente.
Nota
Redefina o ambiente virtual se você instalar pacotes que quebram ou alteram o bloco de anotações principal ou o ambiente Apache Spark. Desanexar o notebook da computação sem servidor e reanexá-lo não necessariamente limpa todo o cache do ambiente.
Configurar ambientes e dependências para tarefas que não sejam do bloco de anotações
Para outros tipos de tarefas suportados, como script Python, roda Python ou tarefas dbt, um ambiente padrão inclui bibliotecas Python instaladas. Para ver a lista de bibliotecas instaladas, consulte a seção Bibliotecas Python instaladas da versão do cliente que você está usando. Consulte versões de ambiente sem servidor. Se uma tarefa exigir uma biblioteca Python que não esteja instalada, você poderá instalá-la a partir de arquivos de espaço de trabalho, volumes do Catálogo Unity ou repositórios de pacotes públicos. Para adicionar uma biblioteca ao criar ou editar uma tarefa:
No menu suspenso Ambiente e Bibliotecas, clique ao
 lado do Ambiente padrão ou clique em + Adicionar novo ambiente.
lado do Ambiente padrão ou clique em + Adicionar novo ambiente.
Selecione a versão do ambiente na lista suspensa Versão do ambiente
. Consulte versões de ambiente sem servidor. A Databricks recomenda escolher a versão mais recente para obter os recursos mais atualizados. Na caixa de diálogo Configurar ambiente, clique em + Adicionar biblioteca.
Selecione o tipo de dependência no menu suspenso em Bibliotecas.
Na caixa de texto Caminho do Arquivo , insira o caminho para a biblioteca.
Para uma roda Python em um arquivo de espaço de trabalho, o caminho deve ser absoluto e começar com
/Workspace/.Para uma roda Python em um volume do catálogo Unity, o caminho deve ser
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.Para um
requirements.txtarquivo, selecione PyPi e digite-r /path/to/requirements.txt.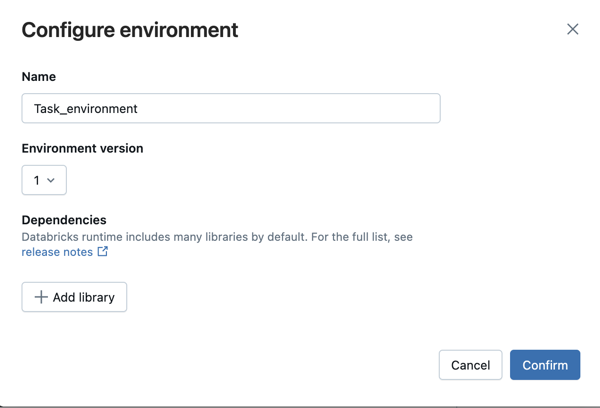
- Clique em Confirmar ou + Adicionar biblioteca para adicionar outra biblioteca.
- Se estiver a adicionar uma tarefa, clique em Criar tarefa. Se estiver editando uma tarefa, clique em Salvar tarefa.
Configurar repositórios de pacotes Python padrão
Importante
Este recurso está no Public Preview.
Os administradores podem configurar repositórios de pacotes privados ou autenticados em espaços de trabalho como a configuração padrão do pip para notebooks sem servidor e tarefas sem servidor. Isso permite que os usuários instalem pacotes de repositórios Python internos sem definir explicitamente index-url ou extra-index-url. No entanto, se esses valores forem especificados no código ou em um bloco de anotações, eles terão precedência sobre os padrões do espaço de trabalho.
Essa configuração aproveita segredos do Databricks para armazenar e gerenciar com segurança URLs e credenciais do repositório. Os administradores podem configurar a instalação usando um escopo secreto predefinido e os comandos secrets da CLI do Databricks ou a API REST .
Para configurar repositórios de pacotes Python padrão, crie um escopo secreto predefinido e configure permissões de acesso e, em seguida, adicione os segredos do repositório de pacotes.
Nome do escopo secreto predefinido
Os administradores de espaço de trabalho podem definir URLs de índice pip padrão ou URLs de índice extra, juntamente com tokens de autenticação e segredos em um escopo secreto designado sob chaves predefinidas:
- Nome do escopo secreto:
databricks-package-management - Chave secreta para index-url:
pip-index-url - Chave secreta para extra-index-urls:
pip-extra-index-urls - Chave secreta para conteúdo de certificação SSL:
pip-cert
Criar o escopo secreto
Um escopo secreto pode ser criado usando a CLI do Databricks comandos secrets ou o REST API. Depois de criar o escopo secreto, configure as ACLs para conceder acesso de leitura a todos os usuários do espaço de trabalho. Isso garante que o repositório permaneça seguro e não possa ser alterado por usuários individuais.
databricks secrets create-scope databricks-package-management
databricks secrets put-acl databricks-package-management admins MANAGE
databricks secrets put-acl databricks-package-management users READ
Adicionar segredos do repositório de pacotes Python
Adicione os detalhes do repositório de pacotes Python usando os nomes de chaves secretas predefinidos.
# Add index URL.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-index-url", "string_value":"<index-url-value>"}'
# Add extra index URLs. If you have multiple extra index URLs, separate them using white space.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-extra-index-urls", "string_value":"<extra-index-url-1 extra-index-url-2>"}'
# Add cert content. If you want to pip configure a custom SSL certificate, put the cert file content here.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-cert", "string_value":"<cert-content>"}'
Modificar ou excluir segredos privados do repositório PyPI
Para modificar segredos do repositório PyPI, use o comando put-secret. Para excluir segredos do repositório PyPI, use delete-secret como mostrado abaixo:
# delete secret
databricks secrets delete-secret databricks-package-management pip-index-url
databricks secrets delete-secret databricks-package-management pip-extra-index-urls
databricks secrets delete-secret databricks-package-management pip-cert
# delete scope
databricks secrets delete-scope databricks-package-management
Nota
Modificações ou exclusões em segredos são aplicadas depois de um utilizador reconectar a computação sem servidor aos seus notebooks ou executar novamente as tarefas sem servidor.