Computação sem servidor para notebooks
Este artigo explica como usar a computação sem servidor para notebooks. Para obter informações sobre como usar a computação sem servidor para trabalhos, consulte Executar seu trabalho do Azure Databricks com computação sem servidor para fluxos de trabalho.
Para obter informações sobre preços, consulte Preços do Databricks.
Requisitos
- Seu espaço de trabalho deve estar habilitado para o Catálogo Unity.
- Seu espaço de trabalho deve estar em uma região suportada. Consulte Regiões do Azure Databricks.
- Sua conta deve estar habilitada para computação sem servidor. Consulte Ativar computação sem servidor.
Anexar um bloco de notas à computação sem servidor
Se o espaço de trabalho estiver habilitado para computação interativa sem servidor, todos os usuários no espaço de trabalho terão acesso à computação sem servidor para blocos de anotações. Não são necessárias permissões adicionais.
Para anexar à computação sem servidor, clique no menu suspenso Conectar no bloco de anotações e selecione Sem servidor. Para novos blocos de anotações, a computação anexada assume automaticamente como padrão serverless após a execução do código se nenhum outro recurso tiver sido selecionado.
Selecione uma política de orçamento para seu uso sem servidor
Importante
Esta funcionalidade está em Pré-visualização Pública.
As políticas de orçamento permitem que sua organização aplique tags personalizadas no uso sem servidor para atribuição de faturamento granular.
Se o espaço de trabalho usar políticas de orçamento para atribuir o uso sem servidor, você poderá selecionar a política de orçamento que deseja aplicar ao bloco de anotações. Se forem atribuídos apenas a uma política de orçamento, essa política será selecionada por padrão.
Para selecionar a política de orçamento antes de se conectar à computação sem servidor:
- Na interface do usuário do bloco de anotações, clique na lista suspensa Conectar.
- Clique em Mais ...
- Selecione Sem servidor e, em seguida, selecione a política de orçamento.
- Clique em Iniciar e anexar.
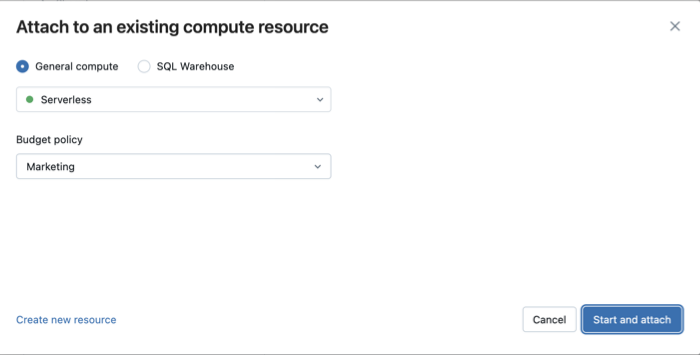
Você pode selecionar a política de orçamento depois que seu bloco de anotações estiver conectado à computação sem servidor usando o painel lateral Ambiente:
- Na interface do usuário do bloco de anotações, clique no painel
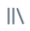 lateral Ambiente .
lateral Ambiente . - Em Política de orçamento , selecione a política de orçamento que pretende aplicar ao seu bloco de notas.
- Clique em Aplicar.
A partir desse ponto, todo o uso do seu bloco de anotações herdará as tags personalizadas da política de orçamento.
Nota
Se o seu bloco de anotações for originado de um repositório Git ou não tiver uma política de orçamento atribuída, ele será padronizado para a última política de orçamento escolhida na próxima vez que for anexado à computação sem servidor.
Ver informações de consulta
A computação sem servidor para blocos de anotações e trabalhos usa informações de consulta para avaliar o desempenho de execução do Spark. Depois de executar uma célula em um bloco de anotações, você pode exibir informações relacionadas a consultas SQL e Python clicando no link Ver desempenho .
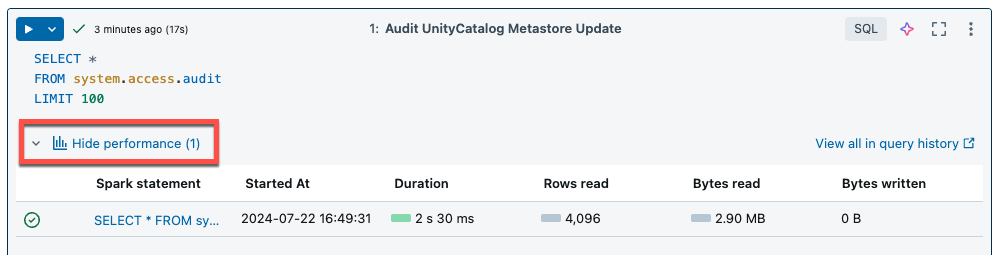
Você pode clicar em qualquer uma das instruções do Spark para visualizar as métricas de consulta. A partir daí, você pode clicar em Ver perfil de consulta para ver uma visualização da execução da consulta. Para obter mais informações sobre perfis de consulta, consulte Perfil de consulta.
Nota
Para exibir informações de desempenho para suas execuções de trabalho, consulte Exibir informações de consulta de execução de trabalho.
Histórico de consultas
Todas as consultas executadas em computação sem servidor também serão registradas na página de histórico de consultas do seu espaço de trabalho. Para obter informações sobre o histórico de consultas, consulte Histórico de consultas.
Limitações do insight de consulta
- O perfil de consulta só estará disponível após o término da execução da consulta.
- As métricas são atualizadas ao vivo, embora o perfil de consulta não seja mostrado durante a execução.
- Somente os seguintes status de consulta são cobertos: EXECUTANDO, CANCELADO, FALHADO, CONCLUÍDO.
- As consultas em execução não podem ser canceladas a partir da página de histórico de consultas. Eles podem ser cancelados em cadernos ou trabalhos.
- Métricas detalhadas não estão disponíveis.
- O download do Perfil de Consulta não está disponível.
- O acesso à interface do usuário do Spark não está disponível.
- O texto da instrução contém apenas a última linha que foi executada. No entanto, pode haver várias linhas que precedem essa linha que foram executadas como parte da mesma instrução.