O que é Delta Live Tables?
Nota
O Delta Live Tables requer o plano Premium. Entre em contato com sua equipe de conta Databricks para obter mais informações.
O Delta Live Tables é uma estrutura declarativa projetada para simplificar a criação de pipelines de extração, transformação e carga (ETL) confiáveis e fáceis de manter. Você especifica quais dados ingerir e como transformá-los, e o Delta Live Tables automatiza os principais aspetos do gerenciamento de seu pipeline de dados, incluindo orquestração, gerenciamento de computação, monitoramento, imposição de qualidade de dados e tratamento de erros.
O Delta Live Tables é construído no Apache Spark, mas em vez de definir seus pipelines de dados usando uma série de tarefas separadas do Apache Spark, você define tables de streaming e materializou views que o sistema deve criar e as consultas necessárias para preencher e update esses tables de streaming e materializados views.
Para saber mais sobre os benefícios de construir e executar os seus pipelines de ETL com o Delta Live Tables, consulte a página do produto Delta Live Tables.
benefícios do Delta Live Tables em comparação com o Apache Spark
O Apache Spark é um mecanismo de análise unificado de código aberto versátil, incluindo ETL. O Delta Live Tables se baseia no Spark para lidar com tarefas específicas e comuns de processamento de ETL. O Delta Live Tables pode acelerar significativamente seu caminho para a produção quando seus requisitos incluem essas tarefas de processamento, incluindo:
- Ingerir dados de fontes típicas.
- Transformação incremental de dados.
- Realização de captura de dados de alteração (CDC).
No entanto, o Delta Live Tables é inadequado para implementar alguns tipos de lógica processual. Por exemplo, requisitos de processamento como gravar em um table externo ou incluir uma condicional que opera em armazenamento de arquivos externo ou banco de dados tables não podem ser executados dentro do código que define um conjunto de dados Delta Live Tables. Para implementar o processamento não suportado pelo Delta Live Tables, o Databricks recomenda usar o Apache Spark ou incluir o pipeline em um trabalho do Databricks que executa o processamento em uma tarefa de trabalho separada. Veja a tarefa de pipeline Delta Live Tables para os trabalhos.
O seguinte table compara o Delta Live Tables com o Apache Spark:
| Capacidade | Delta Live Tables | Apache Spark |
|---|---|---|
| Transformações de dados | Você pode transformar dados usando SQL ou Python. | Você pode transformar dados usando SQL, Python, Scala ou R. |
| Processamento incremental de dados | Muitas transformações de dados são processadas automaticamente de forma incremental. | Você deve determinar quais dados são novos para que possa processá-los incrementalmente. |
| Orquestração | As transformações são orquestradas automaticamente na ordem correta. | Você deve certificar-se de que as diferentes transformações sejam executadas na ordem correta. |
| Paralelismo | Todas as transformações são executadas com o nível correto de paralelismo. | Você deve usar threads ou um orquestrador externo para executar transformações não relacionadas em paralelo. |
| Tratamento de erros | As falhas são repetidas automaticamente. | Você deve decidir como lidar com erros e tentativas. |
| Monitorização | As métricas e eventos são registrados automaticamente. | Você deve escrever código para coletar métricas sobre execução ou qualidade de dados. |
Conceitos-chave do Delta Live Tables
A ilustração a seguir mostra os componentes importantes de um pipeline Delta Live Tables, seguido por uma explicação de cada um.
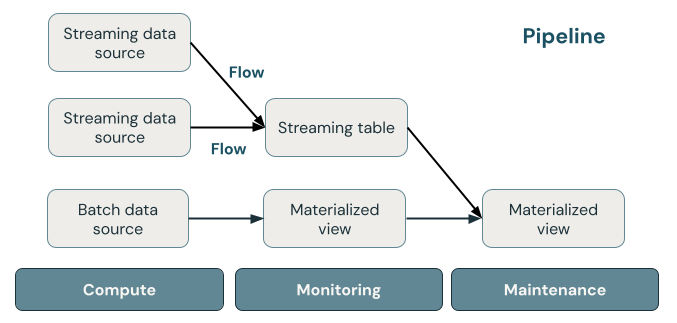
Streaming table
Um table em streaming é um table Delta que possui um ou mais fluxos a escrever para ele. Os tables de streaming são comumente usados para ingestão porque processam dados de entrada exatamente uma vez e podem processar grandes volumes de dados somente de acréscimo. Streaming tables também são úteis para a transformação de dados com baixa latência de fluxos de dados de grande volume.
Vista materializada
Uma vista materializada é uma vista que contém registos pré-calculados com base na consulta que define a vista materializada. Os registos na visualização materializada são automaticamente mantidos atualizados pelo Delta Live Tables com base na agenda update ou nos gatilhos do pipeline. Cada vez que uma vista materializada é atualizada, é garantido que terá os mesmos resultados que executar a consulta definidora sobre os dados mais recentes disponíveis. No entanto, isso geralmente é feito sem recalcular o resultado completo do zero, usando e refreshincremental. Os views materializados são comumente usados para transformações.
Views
Todos os views no Azure Databricks computam resultados de conjuntos de dados de origem à medida que são consultados, aproveitando otimizações de cache quando disponíveis. O Delta Live Tables não publica views para o catalog, então views pode ser referenciado somente no pipeline onde está definido. Views são úteis como consultas intermediárias que não devem ser expostas a usuários finais ou sistemas. O Databricks recomenda o uso de views para impor restrições de qualidade de dados ou transformar e enriquecer conjuntos de dados que geram várias consultas downstream.
Gasoduto
Um pipeline é uma coleção de tables de streaming e views materializados que são atualizados juntos. Esses tables de streaming e views materializados são declarados em arquivos de origem Python ou SQL. Um pipeline também inclui uma configuração que define o processamento usado para update o streaming tables e o materializado views quando o pipeline é executado. Semelhante a como um modelo Terraform define a infraestrutura em sua conta de nuvem, um pipeline Delta Live Tables define os conjuntos de dados e transformações para seu processamento de dados.
Como os conjuntos de dados Delta Live Tables processam dados?
A seguinte table descreve como os dados de viewsmaterializados, de tablesem streaming, e de views são processados:
| Tipo de conjunto de dados | Como os registros são processados por meio de consultas definidas? |
|---|---|
| Streaming table | Cada registo é processado exatamente uma vez. Isso pressupõe uma fonte somente de acréscimo. |
| Vista materializada | Os registros são processados conforme necessário para retornar resultados precisos para o estado atual dos dados. Os views materializados devem ser usados para tarefas de processamento de dados, como transformações, agregações ou consultas lentas de pré-computação e cálculos usados com frequência. |
| Vista | Os registros são processados sempre que a exibição é consultada. Use views para transformações intermediárias e verificações de qualidade de dados que não devem ser publicadas em conjuntos de dados públicos. |
Declare os seus primeiros conjuntos de dados no Delta Live Tables
O Delta Live Tables introduz uma nova sintaxe para Python e SQL. Para aprender as noções básicas da sintaxe de pipeline, consulte Desenvolver código de pipeline com Python e Desenvolver código de pipeline com SQL.
Nota
O Delta Live Tables separa as definições de conjunto de dados do processamento de update, e os notebooks Delta Live Tables não se destinam à execução interativa.
Como você configura os pipelines Delta Live Tables?
As configurações para os pipelines do Delta Live Tables enquadram-se em duas categorias principais.
- Configurações que definem uma coleção de blocos de anotações ou arquivos (conhecidos como código-fonte) que usam a sintaxe Delta Live Tables para declarar conjuntos de dados.
- Configurações que controlam a infraestrutura do pipeline, o gerenciamento de dependências, como as atualizações são processadas e como tables é salvo no espaço de trabalho.
A maioria das configurações é opcional, mas algumas exigem atenção cuidadosa, especialmente ao configurar pipelines de produção. Estas incluem o seguinte:
- Para disponibilizar dados fora do pipeline, você deve declarar um
de destino publicar no metastore do Hive ou um de destino e . - As permissões de acesso a dados são configuradas através do cluster usado para execução. Verifique se o cluster tem as permissões apropriadas configuradas para as fontes de dados e para o local de armazenamento de destino , caso especificado.
Para obter detalhes sobre como usar Python e SQL para escrever código-fonte para pipelines, consulte de referência da linguagem Delta Live Tables SQL e de referência da linguagem Delta Live Tables Python .
Para obter mais informações sobre definições e configurações de pipeline, consulte Configurar um pipeline Delta Live Tables.
Implante seu primeiro pipeline e acione atualizações
Antes de processar dados com o Delta Live Tables, você deve configurar um pipeline. Depois que um pipeline é configurado, você pode acionar um update para calcular resultados para cada conjunto de dados em seu pipeline. Para get começou a usar pipelines Delta Live Tables, consulte Tutorial: Execute seu primeiro pipeline Delta Live Tables.
O que é um pipeline update?
Os pipelines implementam a infraestrutura e recalculam o estado dos dados quando inicias um update. Um update faz o seguinte:
- Inicia um cluster com a configuração correta.
- Descobre todos os tables e views definidos e verifica se há erros de análise, como nomes de column inválidos, dependências ausentes e erros de sintaxe.
- Cria ou atualiza tables e views com os dados mais recentes disponíveis.
Os pipelines podem ser executados continuamente ou em um cronograma, dependendo dos requisitos de custo e latência do seu caso de uso. Consulte Executar um update em um pipeline Delta Live Tables.
Ingerir dados com o Delta Live Tables
O Delta Live Tables dá suporte a todas as fontes de dados disponíveis no Azure Databricks.
A Databricks recomenda o uso de streaming tables para a maioria dos casos de uso de ingestão. Para arquivos que chegam no armazenamento de objetos na nuvem, a Databricks recomenda o Auto Loader. Você pode integrar dados diretamente com o Delta Live Tables a partir da maioria dos barramentos de mensagens.
Para obter mais informações sobre como configurar o acesso ao armazenamento em nuvem, consulte Configuração de armazenamento em nuvem.
Para formatos não suportados pelo Auto Loader, você pode usar Python ou SQL para consultar qualquer formato suportado pelo Apache Spark. Consulte Carregar dados com o Delta Live Tables.
Monitorar e impor a qualidade dos dados
Você pode usar expectativas para especificar controles de qualidade de dados no conteúdo de um conjunto de dados. Ao contrário de um CHECKconstraint em um banco de dados tradicional, que impede a adição de registros que falham no constraint, as expectativas fornecem flexibilidade ao processar dados que não cumprem os requisitos de qualidade de dados. Essa flexibilidade permite que você processe e armazene dados que você espera que sejam confusos e dados que devem atender a rigorosos requisitos de qualidade. Consulte Gerenciar a qualidade dos dados com o Delta Live Tables.
Como o Delta Live Tables e o Delta Lake estão relacionados?
O Delta Live Tables amplia a funcionalidade do Delta Lake. Uma vez que tables, criados e geridos pela Delta Live Tables, são Delta tables, eles têm as mesmas garantias e características fornecidas pelo Delta Lake. Veja O que é Delta Lake?.
O Delta Live Tables adiciona várias propriedades table, além das muitas propriedades table que podem ser set no Lago Delta. Consulte a referência de propriedades Delta Live Tables e a referência de propriedades Delta table.
Como tables são criados e gerenciados pelo Delta Live Tables
O Azure Databricks gerencia automaticamente tables criados com o Delta Live Tables, determinando como as atualizações precisam ser processadas para calcular corretamente o estado atual de um table e executando várias tarefas de manutenção e otimização.
Para a maioria das operações, deves permitir que o Delta Live Tables processe todas as atualizações, inserções e eliminações no tablede destino. Para obter detalhes e limitações, consulte Reter exclusões ou atualizações manuais.
Tarefas de manutenção realizadas pela Delta Live Tables
O Delta Live Tables executa tarefas de manutenção dentro de 24 horas após a atualização de um table. A manutenção pode melhorar o desempenho da consulta e reduzir os custos removendo versões antigas do tables. Por padrão, o sistema executa uma operação de OPTIMIZE completa seguida por VACUUM. Você pode desativar OPTIMIZE para table definindo pipelines.autoOptimize.managed = false nas propriedadestable de do table. As tarefas de manutenção são executadas somente se um update de pipeline tiver sido executado nas 24 horas anteriores ao agendamento das tarefas de manutenção.
Limitações
Para limitações de list, consulte Delta Live Tables Limitações.
Para obter uma list de requisitos e limitações específicos para usar o Delta Live Tables com o Unity Catalog, consulte Usar o Unity Catalog com seus pipelines do Delta Live Tables
Recursos adicionais
- O Delta Live Tables tem suporte total na API REST do Databricks. Consulte API DLT.
- Para obter as configurações de pipeline e table, consulte de referência de propriedades do Delta Live Tables .
- Referência da linguagem Delta Live Tables SQL.
- Referência da linguagem Delta Live Tables Python.