Descrição do pipeline de dados RAG e etapas de processamento
Neste artigo, você aprenderá sobre como preparar dados não estruturados para uso em aplicativos RAG. Dados não estruturados referem-se a dados sem uma estrutura ou organização específica, como documentos PDF que podem incluir texto e imagens, ou conteúdo multimídia, como áudio ou vídeos.
Os dados não estruturados carecem de um modelo ou esquema de dados predefinido, tornando impossível a consulta apenas com base na estrutura e nos metadados. Como resultado, os dados não estruturados requerem técnicas que possam compreender e extrair significado semântico de texto bruto, imagens, áudio ou outro conteúdo.
Durante a preparação dos dados, o pipeline de dados do aplicativo RAG usa dados brutos não estruturados e os transforma em partes discretas que podem ser consultadas com base em sua relevância para a consulta de um usuário. As principais etapas do pré-processamento de dados são descritas abaixo. Cada etapa tem uma variedade de botões que podem ser ajustados - para uma discussão mais profunda sobre esses botões, consulte Melhorar a qualidade do aplicativo RAG.
Preparar dados não estruturados para recuperação
No restante desta seção, descrevemos o processo de preparação de dados não estruturados para recuperação usando pesquisa semântica. A pesquisa semântica compreende o significado contextual e a intenção de uma consulta do usuário para fornecer resultados de pesquisa mais relevantes.
A pesquisa semântica é uma das várias abordagens que podem ser adotadas ao implementar o componente de recuperação de um aplicativo RAG sobre dados não estruturados. Esses documentos abrangem estratégias de recuperação alternativas na seção de botões de recuperação.
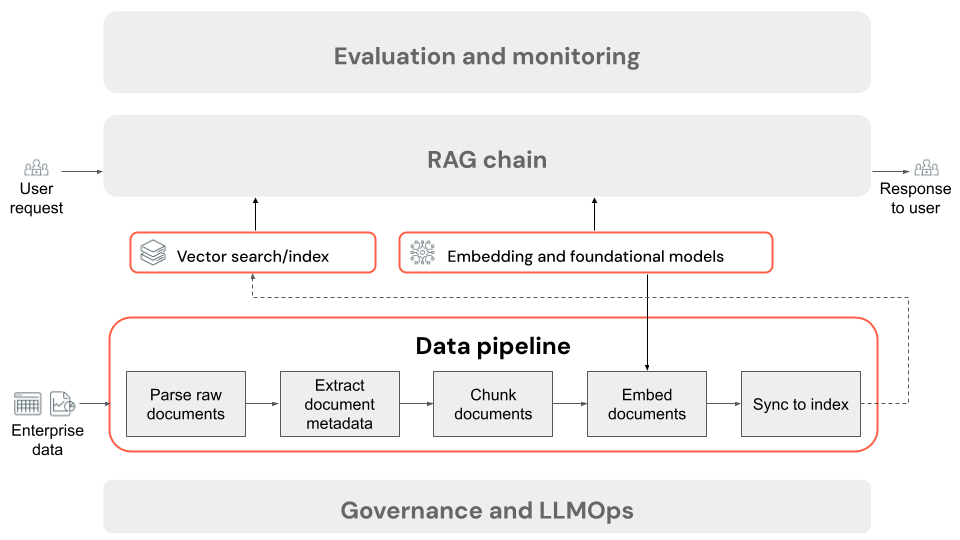
Etapas de um pipeline de dados de aplicativo RAG
A seguir estão as etapas típicas de um pipeline de dados em um aplicativo RAG usando dados não estruturados:
- Analise os documentos brutos: a etapa inicial envolve a transformação de dados brutos em um formato utilizável. Isso pode incluir a extração de texto, tabelas e imagens de uma coleção de PDFs ou o emprego de técnicas de reconhecimento ótico de caracteres (OCR) para extrair texto de imagens.
- Extrair metadados do documento (opcional): em alguns casos, extrair e usar metadados do documento, como títulos de documentos, números de página, URLs ou outras informações, pode ajudar a etapa de recuperação a consultar com mais precisão os dados corretos.
- Fragmentar documentos: Para garantir que os documentos analisados possam caber no modelo de incorporação e na janela de contexto do LLM, dividimos os documentos analisados em partes menores e discretas. Recuperar essas partes focadas, em vez de documentos inteiros, dá ao LLM um contexto mais direcionado a partir do qual gerar suas respostas.
- Incorporação de blocos: em um aplicativo RAG que usa pesquisa semântica, um tipo especial de modelo de linguagem chamado modelo de incorporação transforma cada um dos blocos da etapa anterior em vetores numéricos, ou listas de números, que encapsulam o significado de cada parte do conteúdo. Crucialmente, esses vetores representam o significado semântico do texto, não apenas palavras-chave de nível de superfície. Isso permite pesquisar com base no significado em vez de correspondências de texto literal.
- Blocos de índice em um banco de dados vetorial: A etapa final é carregar as representações vetoriais dos blocos, juntamente com o texto do bloco, em um banco de dados vetorial. Um banco de dados vetorial é um tipo especializado de banco de dados projetado para armazenar e pesquisar dados vetoriais de forma eficiente, como incorporações. Para manter o desempenho com um grande número de partes, os bancos de dados vetoriais geralmente incluem um índice vetorial que usa vários algoritmos para organizar e mapear as incorporações vetoriais de uma forma que otimiza a eficiência da pesquisa. No momento da consulta, a solicitação de um usuário é incorporada em um vetor e o banco de dados aproveita o índice vetorial para encontrar os vetores de bloco mais semelhantes, retornando os blocos de texto originais correspondentes.
O processo de semelhança computacional pode ser computacionalmente caro. Os índices vetoriais, como o Databricks Vetor Search, aceleram esse processo fornecendo um mecanismo para organizar e navegar de forma eficiente nas incorporações, muitas vezes por meio de métodos sofisticados de aproximação. Isso permite uma classificação rápida dos resultados mais relevantes sem comparar cada incorporação à consulta do usuário individualmente.
Cada etapa do pipeline de dados envolve decisões de engenharia que afetam a qualidade do aplicativo RAG. Por exemplo, escolher o tamanho de bloco certo na etapa 3 garante que o LLM receba informações específicas, mas contextualizadas, enquanto a seleção de um modelo de incorporação apropriado na etapa 4 determina a precisão das partes retornadas durante a recuperação.
Esse processo de preparação de dados é conhecido como preparação de dados offline, pois ocorre antes que o sistema responda às consultas, ao contrário das etapas online acionadas quando um usuário envia uma consulta.