Previsão (sem servidor) com AutoML
Este artigo mostra como executar um experimento de previsão sem servidor utilizando a Interface de Treino do Mosaic AI Model.
Treinamento de modelo de IA em mosaico - a previsão simplifica a previsão de dados de séries cronológicas selecionando automaticamente o melhor algoritmo e hiperparâmetros, tudo isso enquanto é executado em recursos de computação totalmente gerenciados.
Para entender a diferença entre previsão sem servidor e previsão de computação clássica, consulte Previsão sem servidor versus previsão de computação clássica.
Requerimentos
Dados de formação com uma coluna de série temporal, guardada como uma tabela do Catálogo Unity.
Se o espaço de trabalho tiver o Secure Egress Gateway (SEG) ativado,
pypi.orgdeverá ser adicionado à lista de domínios permitidos . Consulte Gerenciando políticas de rede para controle de saída sem servidor.
Criar uma experiência de previsão com a interface do usuário
Vá para a landing page do seu Azure Databricks e clique em Experimentos na barra lateral.
No bloco de Previsão, selecione Iniciar formação.
Selecione a de dados de treinamento
em uma lista de tabelas do Catálogo Unity que você pode acessar. -
Coluna de Tempo: Selecione a coluna que contém os períodos para a série temporal. As colunas devem ser do tipo
timestampoudate. - Frequência de previsão: Selecione a unidade de tempo que representa a frequência dos dados de entrada. Por exemplo, minutos, horas, dias, meses. Isso determina a granularidade da sua série temporal.
- Horizonte de previsão: Especifique quantas unidades da frequência selecionada devem ser previstas no futuro. Juntamente com a frequência de previsão, isto define as unidades de tempo e o número de unidades de tempo a prever.
Observação
Para usar o algoritmo de Auto-ARIMA
, a série temporal deve ter uma frequência regular onde o intervalo entre quaisquer dois pontos deve ser o mesmo em toda a série temporal. O AutoML lida com as etapas de tempo ausentes preenchendo esses valores com o valor anterior. -
Coluna de Tempo: Selecione a coluna que contém os períodos para a série temporal. As colunas devem ser do tipo
Selecione uma coluna de destino Previsão que você deseja que o modelo preveja.
Opcionalmente, especifique uma tabela do Catálogo Unity e o caminho de dados de previsão para armazenar as previsões de saída.
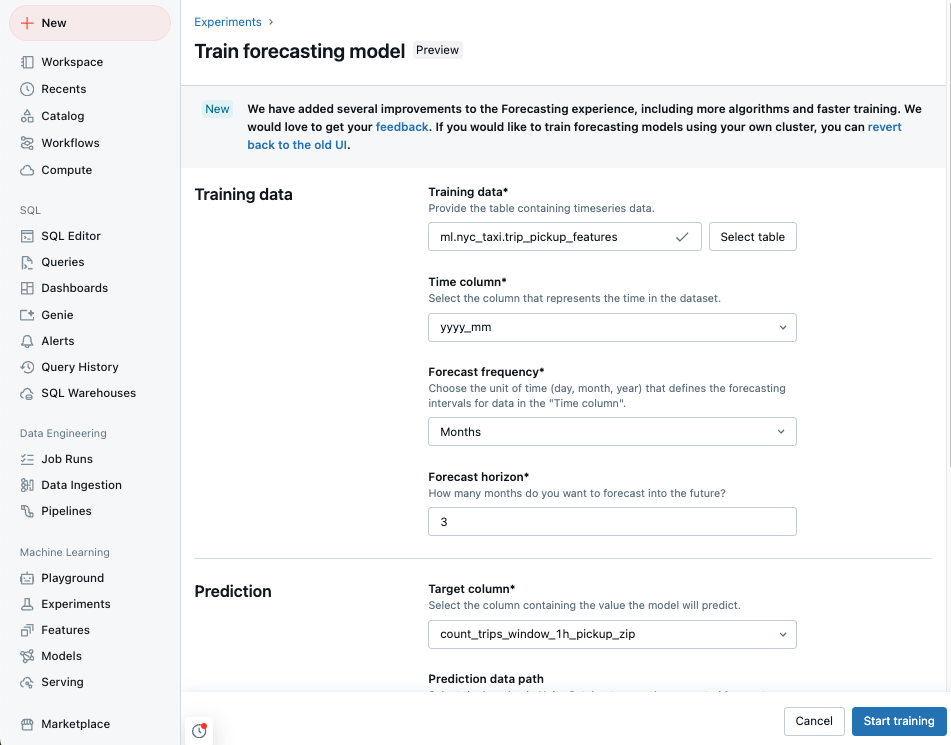
Selecione um Registro de modelo local e nome do Catálogo Unity.
Opcionalmente, defina Opções avançadas:
- Nome do experimento: Forneça um nome de experimento MLflow.
- Colunas de identificador de séries cronológicas - Para previsões multisséries, selecione a(s) coluna(s) que identificam as séries cronológicas individuais. O Databricks agrupa os dados por essas colunas como séries temporais diferentes e treina um modelo para cada série de forma independente.
- Métrica primária: Escolha a métrica primária usada para avaliar e selecionar o melhor modelo.
- Estrutura de treinamento: Escolha as estruturas para o AutoML explorar.
- Dividir coluna: Selecione a coluna que contém a divisão de dados personalizada. Os valores devem ser "treinar", "validar", "testar"
- Coluna Peso: Especifique a coluna a ser usada para atribuir peso às séries temporais. Todas as amostras de uma dada série cronológica devem ter o mesmo peso. O peso deve estar na faixa [0, 10000].
- Região de férias: Selecione a região de férias a utilizar como covariáveis na formação de modelos.
- Tempo limite: defina uma duração máxima para o experimento AutoML.
Execute o experimento e monitore os resultados
Para iniciar o experimento AutoML, clique em Iniciar treinamento. Na página de treinamento de experimentos, você pode fazer o seguinte:
- Pare a experiência a qualquer momento.
- Executa-se o monitor.
- Navegue até a página de execução para qualquer execução.
Veja os resultados ou use o melhor modelo
Após a conclusão do treinamento, os resultados da previsão são armazenados na tabela Delta especificada e o melhor modelo é registrado no Unity Catalog.
Na página de experimentos, você escolhe uma das seguintes etapas seguintes:
- Selecione Exibir previsões para ver a tabela de resultados de previsão.
- Selecione o notebook de inferência por lotes para abrir um notebook automaticamente gerado para inferências por lotes, utilizando o modelo mais eficaz.
- Selecione Criar ponto de extremidade de serviço para implantar o melhor modelo em um ponto de extremidade de serviço de Model Serving.
Previsão sem servidor versus previsão de computação clássica
A tabela a seguir resume as diferenças entre a computação sem servidor para previsão e a previsão com computação clássica.
| Funcionalidade | Previsão sem servidor | Previsão de computação clássica |
|---|---|---|
| Infraestrutura de computação | O Azure Databricks gerencia a configuração de computação e otimiza automaticamente o custo e o desempenho. | Computação configurada pelo usuário |
| Governação | Modelos e artefatos registrados no Catálogo Unity | Armazenamento de arquivos de espaço de trabalho configurado pelo usuário |
| Seleção de algoritmos | Modelos estatísticos mais o algoritmo de rede neural de aprendizagem profunda DeepAR | Modelos estatísticos |
| Integração com a loja de recursos | Não suportado | suportados |
| Notebooks gerados automaticamente | Caderno de inferência em lote | Código fonte de todas as versões experimentais |
| Modelo de implantação de serviço com um clique | Suportado | Sem suporte |
| Divisões de treino/validação/teste personalizadas | Suportado | Não suportado |
| Pesos personalizados para séries cronológicas individuais | Suportado | Não suportado |