Julho de 2019
Esses recursos e aprimoramentos da plataforma Azure Databricks foram lançados em julho de 2019.
Nota
Os lançamentos são encenados. Sua conta do Azure Databricks pode não ser atualizada até uma semana após a data de lançamento inicial.
Em breve: Databricks 6.0 não suportará Python 2
Em antecipação ao próximo fim da vida útil do Python 2, anunciado para 2020, o Python 2 não será suportado no Databricks Runtime 6.0. As versões anteriores do Databricks Runtime continuarão a suportar Python 2. Esperamos lançar o Databricks Runtime 6.0 ainda em 2019.
Pré-carregar a versão do Databricks Runtime em instâncias inativas do conjunto
30 de julho a 6 de agosto de 2019: Versão 2.103
Agora você pode acelerar as execuções de cluster com suporte de pool selecionando uma versão do Databricks Runtime a ser carregada em instâncias ociosas no pool. O campo na interface do usuário do pool é chamado Versão do Spark Pré-carregada.

As etiquetas personalizadas de clusters e as etiquetas de conjuntos funcionam melhor juntas
30 de julho a 6 de agosto de 2019: Versão 2.103
No início deste mês, o Azure Databricks apresentou pools, uma set de instâncias ociosas que ajudam você a criar clusters rapidamente. Na versão original, os clusters apoiados por pool herdavam tags padrão e personalizadas da configuração do pool, e você não podia modificar essas tags no nível do cluster. Agora você pode configurar marcas personalizadas específicas para um cluster com suporte de pool, e esse cluster aplicará todas as tags personalizadas, sejam herdadas do pool ou atribuídas a esse cluster especificamente. Não é possível adicionar uma marca personalizada específica do cluster com o mesmo nome de chave que uma marca personalizada herdada de um pool (ou seja, não é possível substituir uma tag personalizada herdada do pool). Para obter detalhes, consulte Tags de pool.
O MLflow 1.1 inclui vários melhoramentos à IU e à API
30 de julho a 6 de agosto de 2019: Versão 2.103
O MLflow 1.1 introduz vários novos recursos para melhorar a usabilidade da interface do usuário e da API:
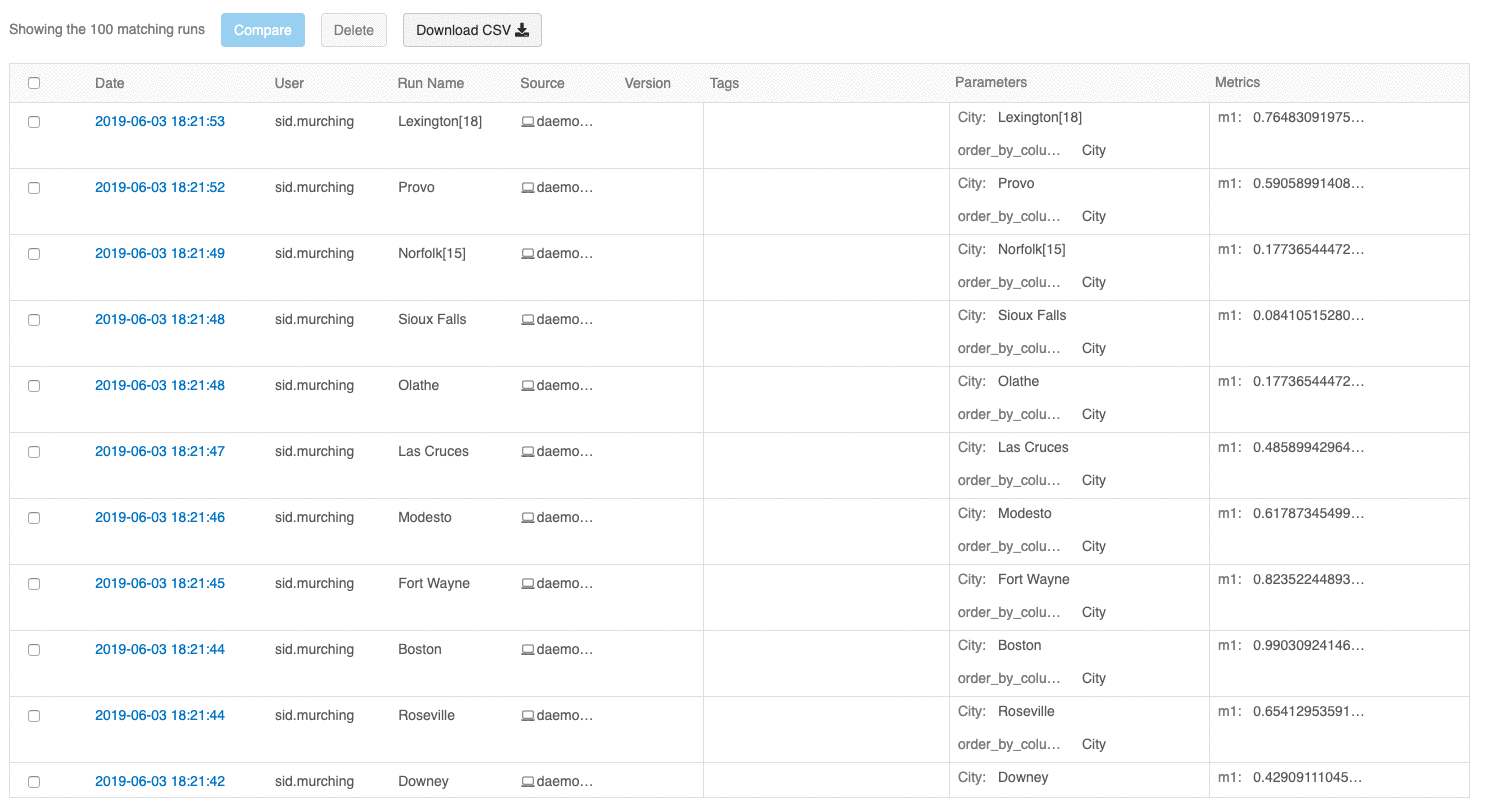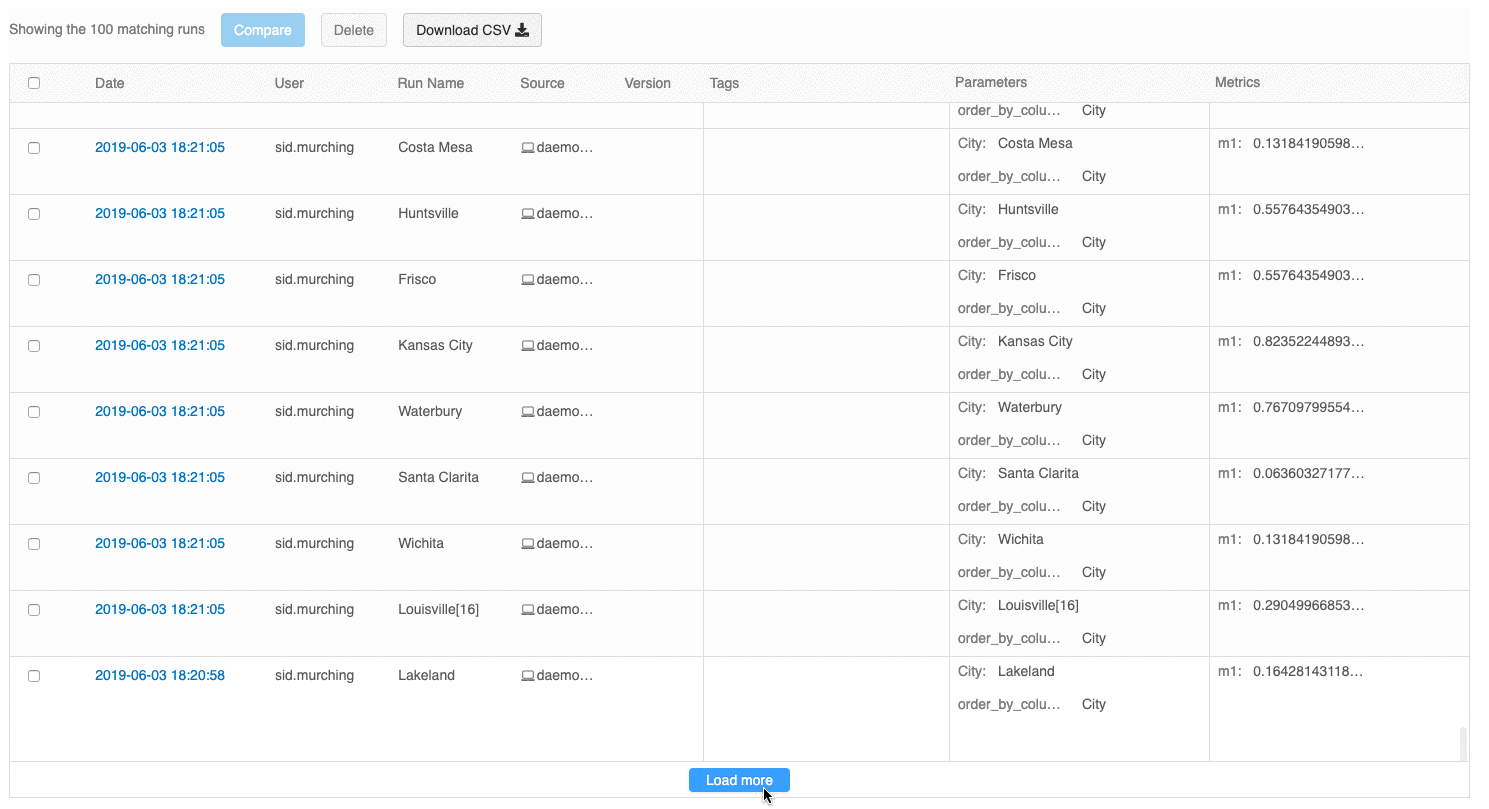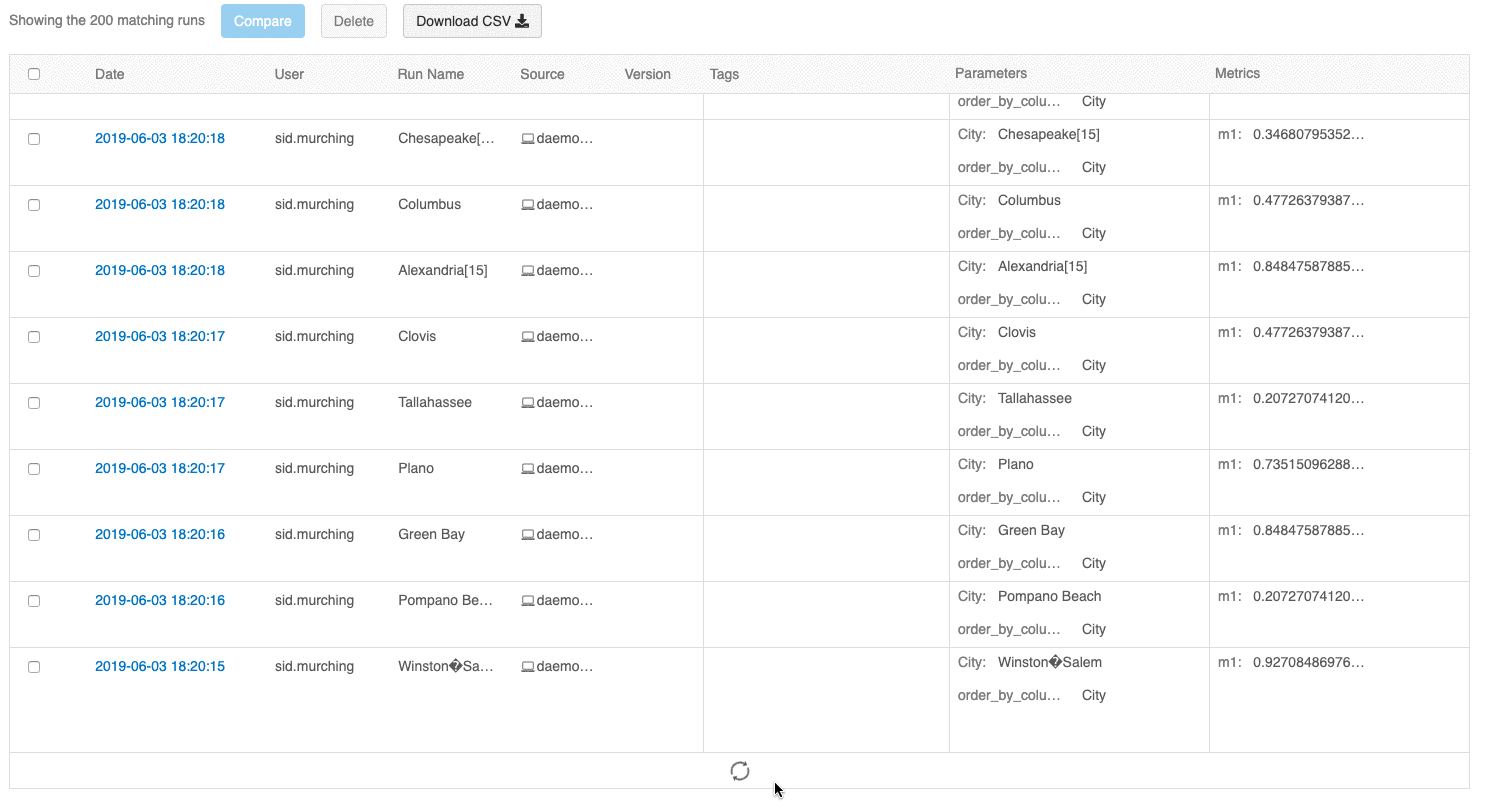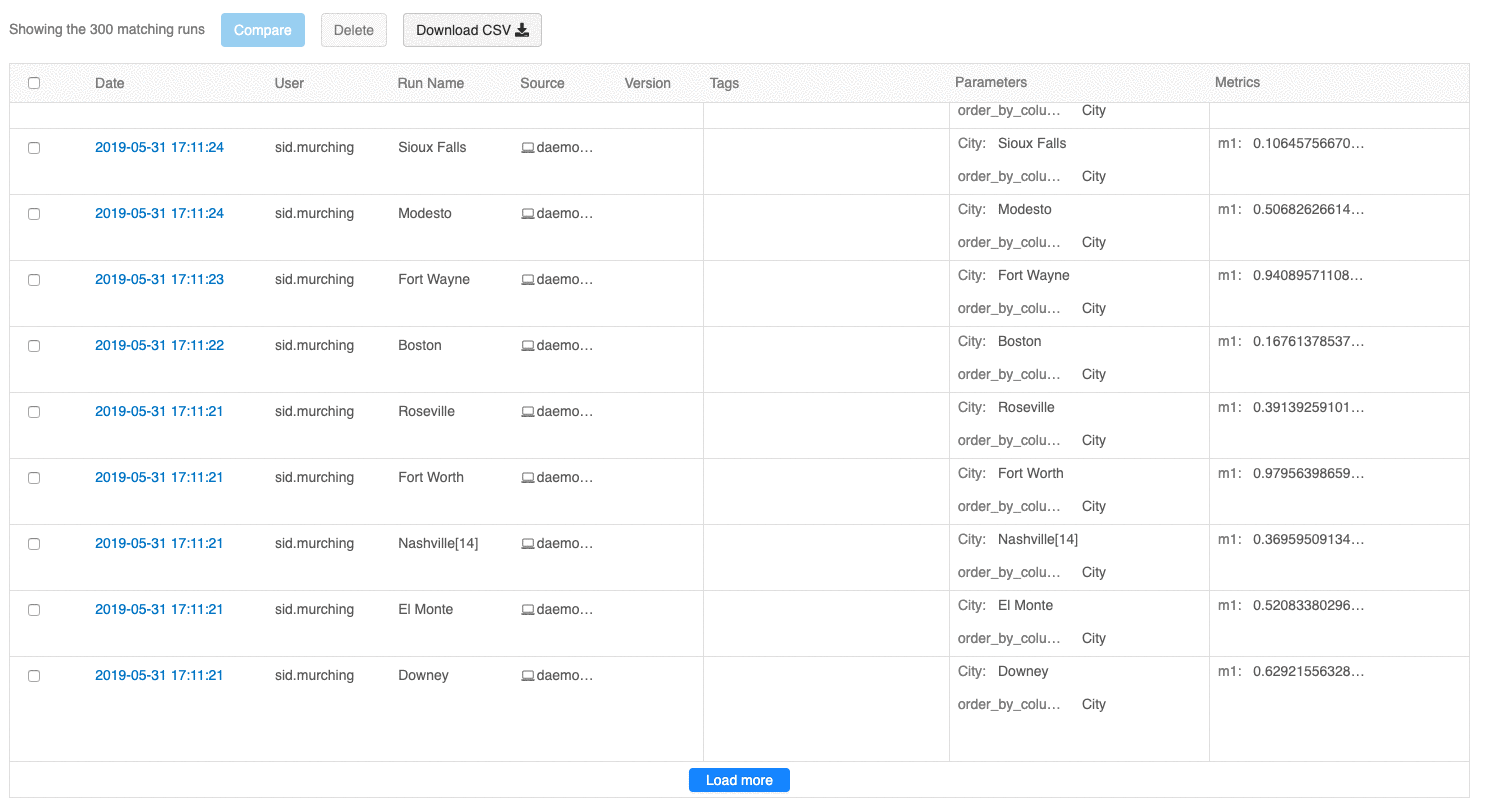
A interface do usuário de visão geral de execuções agora permite navegar por várias páginas de execuções se o número de execuções exceder 100. Após a 100ª execução, clique no botão Carregar mais para carregar as próximas 100 execuções.
A interface do usuário de execução de comparação agora fornece um gráfico de coordenadas paralelas. O gráfico permite observar relações entre uma n-dimensional set de parameters e as métricas. Ele visualiza todas as execuções como linhas codificadas por cores com base no valor de uma métrica (por exemplo, precisão) e mostra o parâmetro values que cada execução assumiu.

Agora você pode adicionar e editar tags da interface do usuário de visão geral de execução e exibir tags na visualização de pesquisa de experimentos.
A nova API MLflowContext permite criar e registrar execuções de log de forma semelhante à API do Python. Essa API contrasta com a API de baixo nível
MlflowClientexistente, que simplesmente encapsula as APIs REST.Agora você pode excluir tags de execuções MLflow usando a API DeleteTag.
Para obter detalhes, consulte a postagem do blog MLflow 1.1. Para obter a list completa de recursos e correções, consulte o MLflow Changelog.
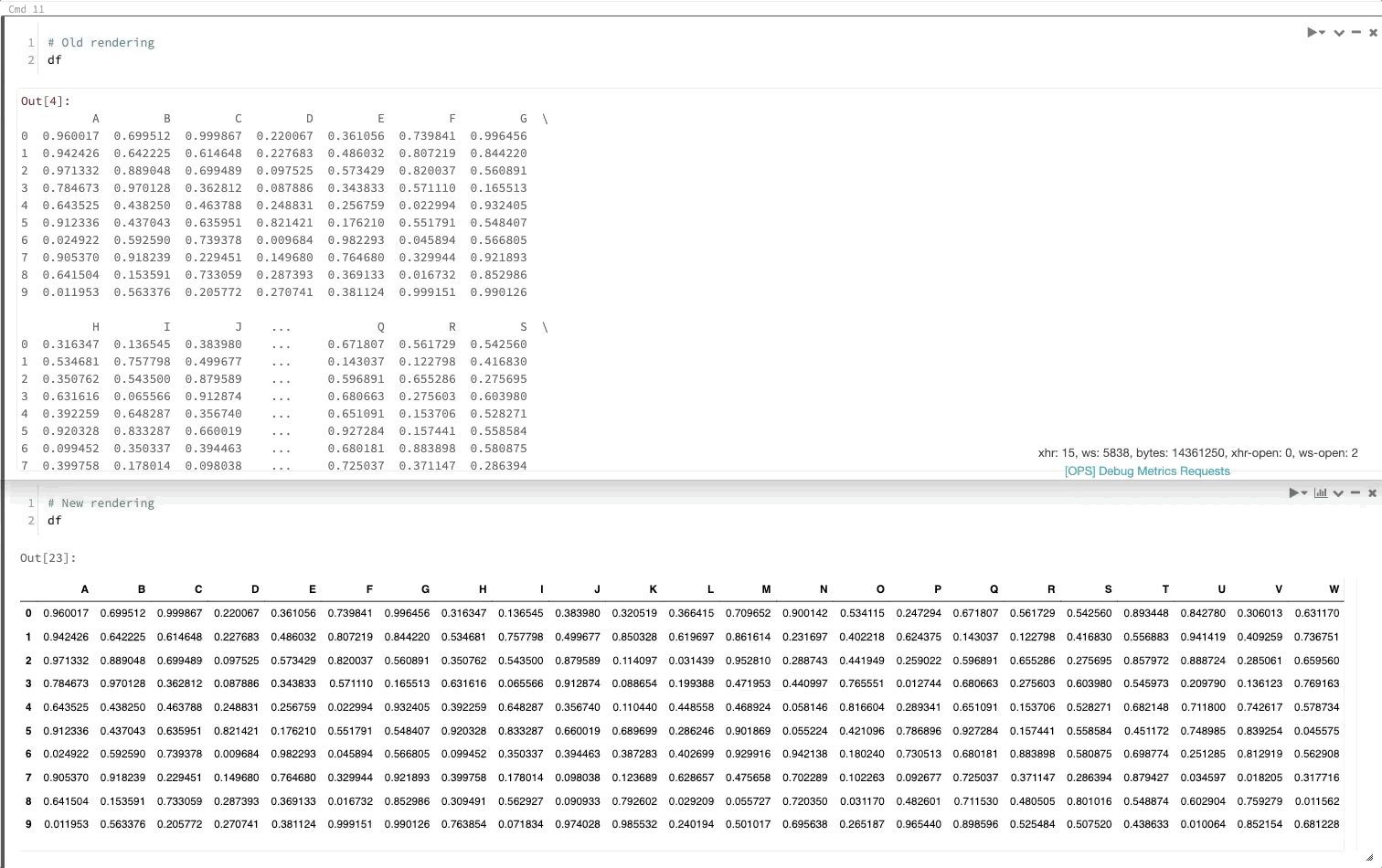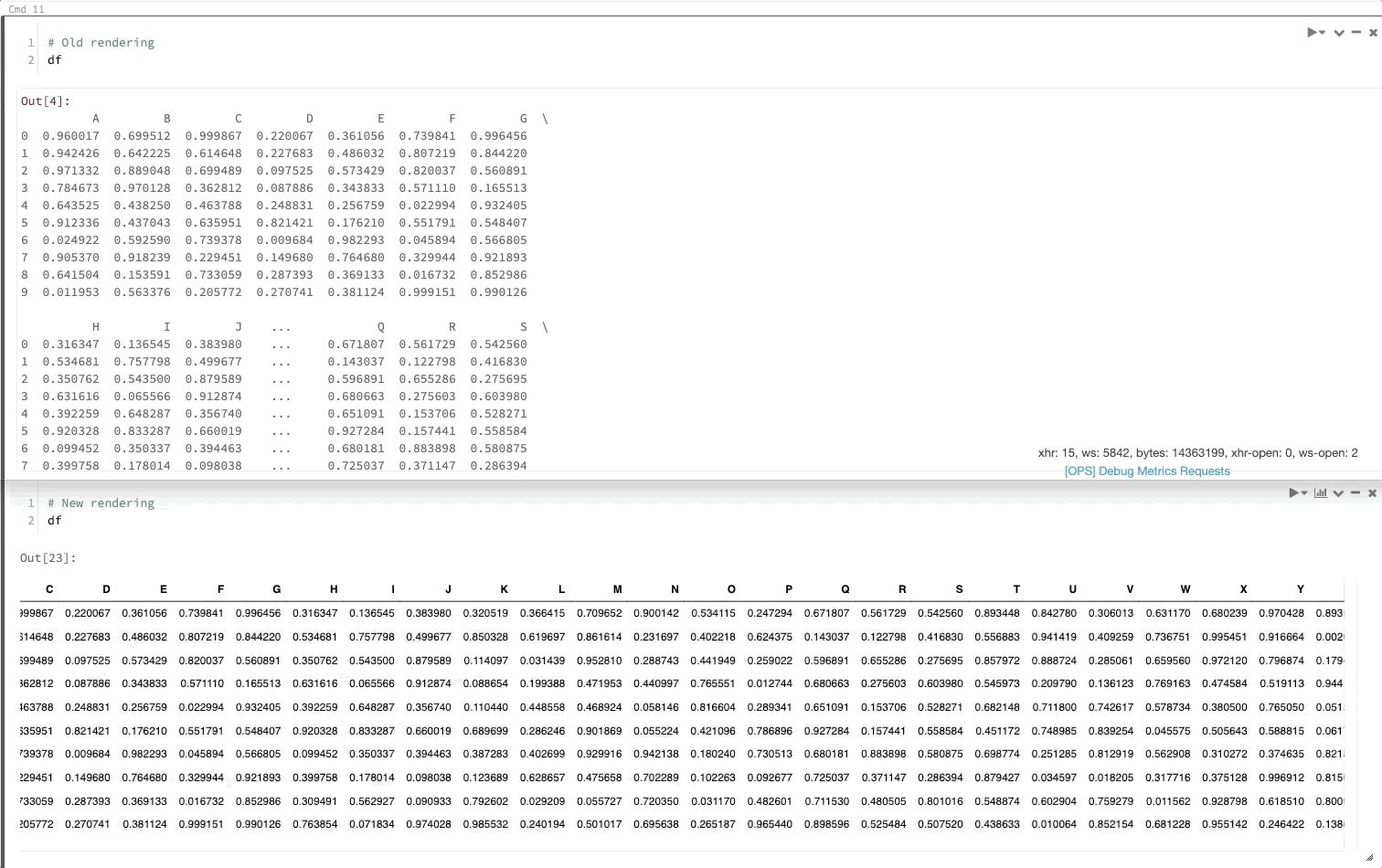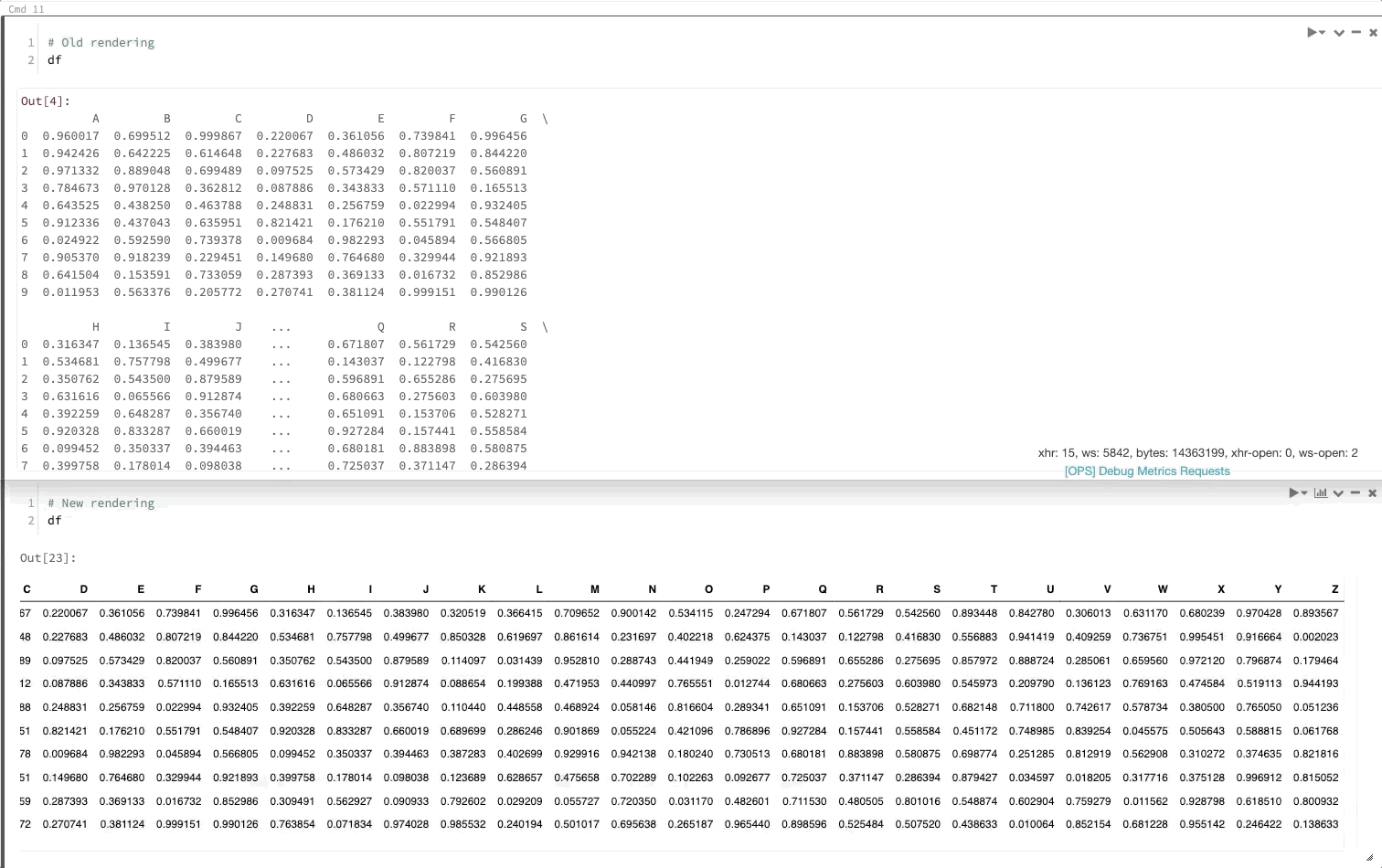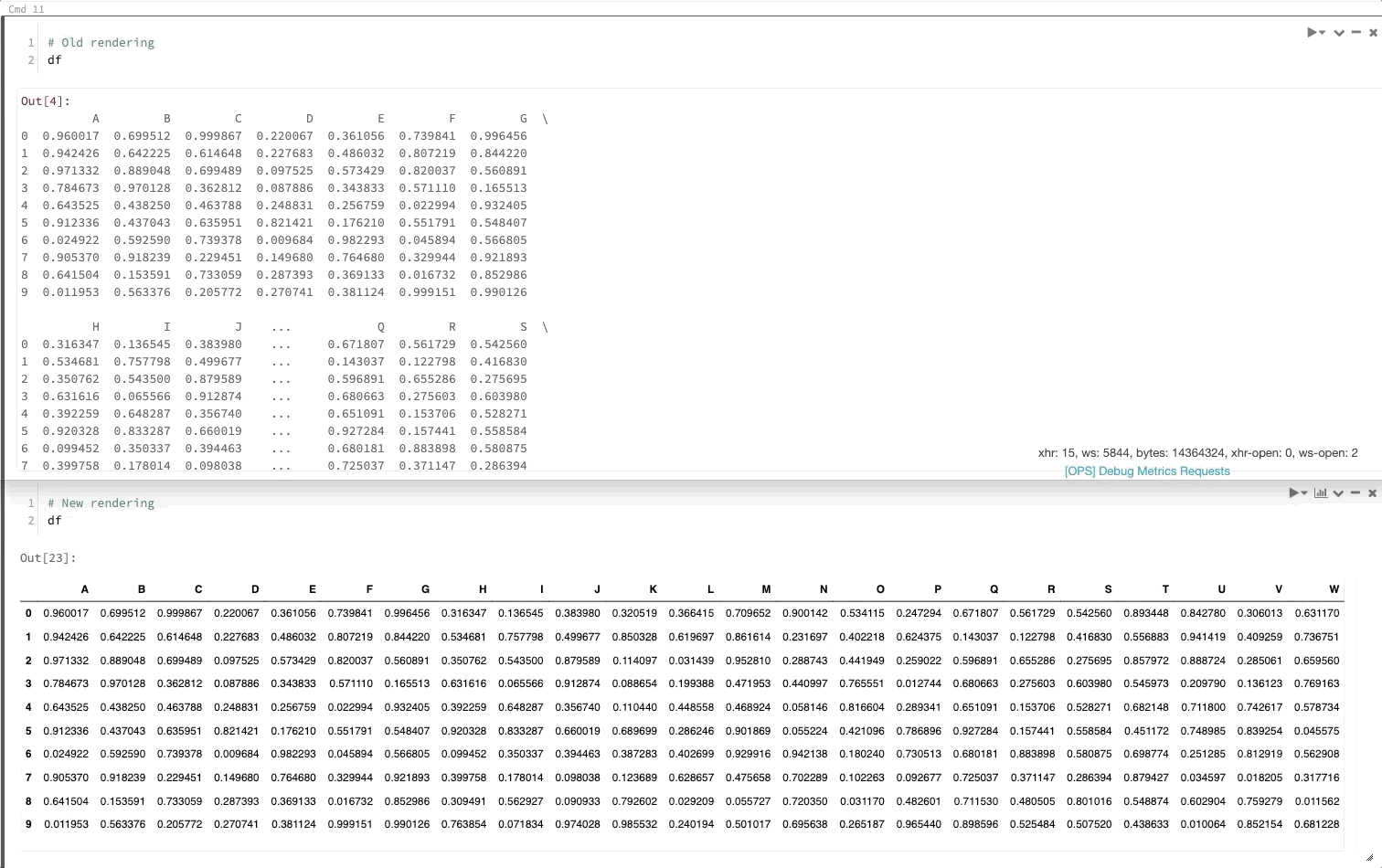
A apresentação de DataFrames pandas é composta tal como em Jupyter
30 de julho a 6 de agosto de 2019: Versão 2.103
Agora, quando você chama um DataFrame pandas, ele será renderizado da mesma maneira que no Jupyter.
Novas regiões
Julho 30, 2019
O Azure Databricks agora está disponível nas seguintes regiões adicionais:
- Coreia do Sul Central
- Norte da África do Sul
Conexão de metastore atualizada limit
16 a 23 de julho de 2019: Versão 2.102
Os novos espaços de trabalho do Azure Databricks em eastus, eastus2, centralus, westus, westus2, westeurope, northeurope terão uma conexão metastore superior com limit de 250. Os espaços de trabalho existentes continuarão a utilizar o metastore atual sem alterações e manterão uma ligação limit de 100.
Set permissões em pools (Visualização pública)
16 a 23 de julho de 2019: Versão 2.102
A interface do usuário do pool agora oferece suporte à definição de permissões sobre quem pode gerenciar pools e quem pode anexar clusters a pools.
Para obter detalhes, consulte Permissões de pool.
Databricks Runtime 5.5 para Machine Learning
Julho 15, 2019
O Databricks Runtime 5.5 ML é construído sobre o Databricks Runtime 5.5 LTS (EoS). Ele contém muitas bibliotecas populares de aprendizado de máquina, incluindo TensorFlow, PyTorch, Keras e XGBoost, e fornece treinamento distribuído do TensorFlow usando Horovod.
Esta versão inclui os seguintes novos recursos e melhorias:
- Adicionado o pacote Python MLflow 1.0
- Bibliotecas de aprendizado de máquina atualizadas
- TensorFlow atualizado de 1.12.0 para 1.13.1
- PyTorch atualizado de 0.4.1 para 1.1.0
- scikit-learn atualizado de 0.19.1 para 0.20.3
- Operação de nó único para HorovodRunner
Para obter detalhes, consulte Databricks Runtime 5.5 LTS for ML (EoS).
Databricks Runtime 5.5
Julho 15, 2019
O Databricks Runtime 5.5 já está disponível. O Databricks Runtime 5.5 inclui o Apache Spark 2.4.3, bibliotecas Python, R, Java e Scala atualizadas e os seguintes novos recursos:
- Delta Lake no Azure Databricks Auto Optimize GA
- Delta Lake no Azure Databricks melhorou o desempenho da consulta de agregação min, max e count
- Pipelines de inferência de modelo mais rápidos com fonte de dados de arquivo binário aprimorada e iterador escalar pandas UDF (Public Preview)
- API de segredos em notebooks R
Para obter detalhes, consulte Databricks Runtime 5.5 LTS (EoS).
Manter um conjunto de instâncias em espera para iniciar os clusters mais depressa (Pré-visualização Pública)
9 a 11 de julho de 2019: Versão 2.101
Para reduzir o tempo de início do cluster, o Azure Databricks agora oferece suporte à anexação de um cluster a um pool predefinido de instâncias ociosas. Quando anexado a um pool, um cluster aloca seus nós de driver e de trabalho do pool. Se o pool não tiver recursos ociosos suficientes para acomodar a solicitação do cluster, o pool será expandido alocando novas instâncias do provedor de nuvem. Quando um cluster anexado é encerrado, as instâncias usadas são retornadas ao pool e podem ser reutilizadas por um cluster diferente.
O Azure Databricks não cobra DBUs quando as instâncias estão inativas no conjunto. A cobrança do provedor de instância se aplica. Veja os preços.
Para obter detalhes, consulte Referência de configuração do pool.
Métricas do Ganglia
9 a 11 de julho de 2019: Versão 2.101
O Ganglia é um sistema de monitoramento distribuído escalável que agora está disponível em clusters do Azure Databricks. As métricas de gânglios ajudam a monitorar o desempenho e a integridade do cluster. Você pode acessar as métricas do Ganglia na página de detalhes do cluster:
Para obter detalhes sobre como usar e configurar métricas, consulte Métricas de gânglios.
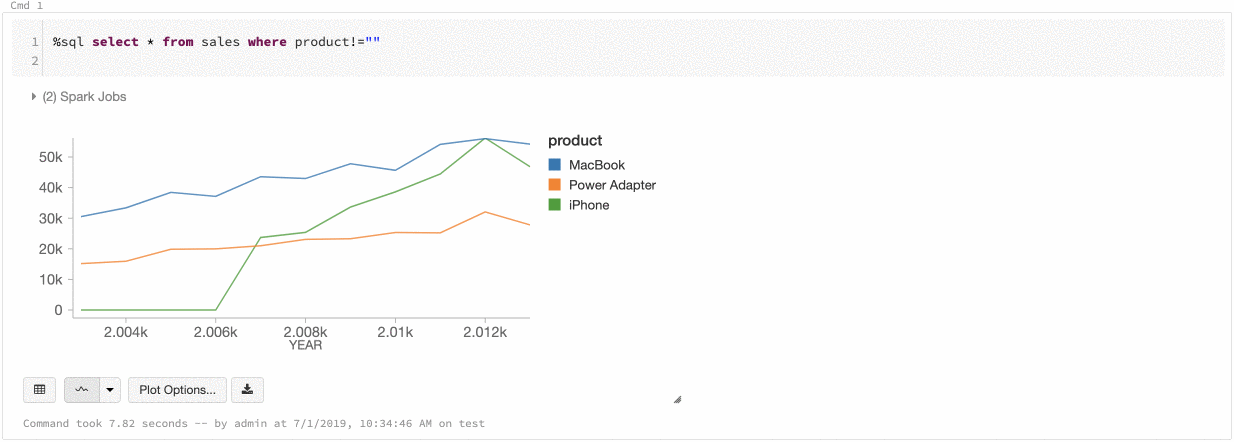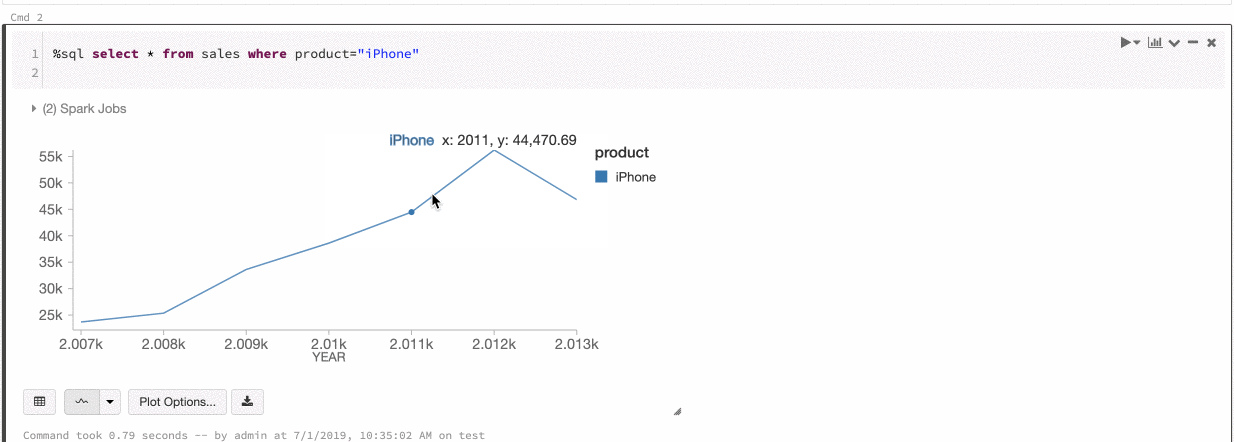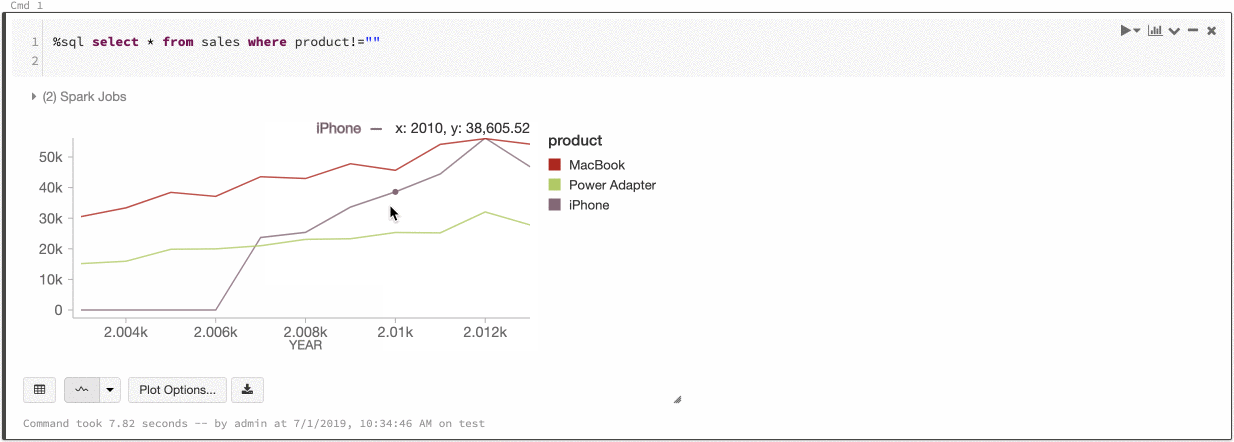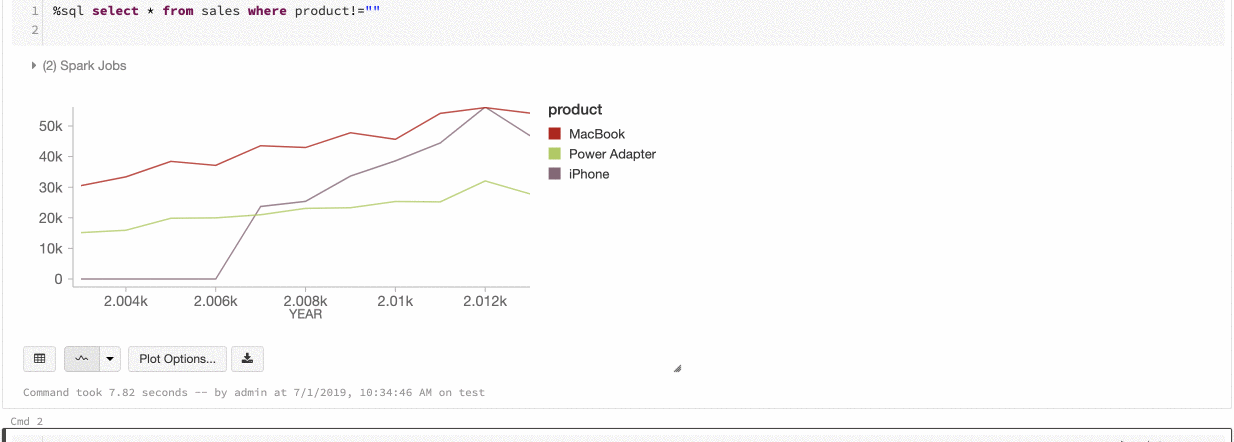
Cor global nas séries
9 a 11 de julho de 2019: Versão 2.101
Agora você pode especificar que as cores de uma série devem ser consistentes em todos os gráficos do seu bloco de anotações. Consulte Consistência de cores nos gráficos.