Guia de início rápido: criar cluster Apache Spark no Azure HDInsight usando o modelo ARM
Neste início rápido, você usa um modelo do Azure Resource Manager (modelo ARM) para criar um cluster Apache Spark no Azure HDInsight. Em seguida, crie um arquivo do Jupyter Notebook e use-o para executar consultas do Spark SQL em tabelas do Apache Hive. O Azure HDInsight é um serviço de análise gerido, de espectro completo e de código aberto para empresas. A estrutura Apache Spark para HDInsight permite análise de dados rápida e computação em cluster usando processamento na memória. O Jupyter Notebook permite que você interaja com seus dados, combine código com texto de marcação e faça visualizações simples.
Se você estiver usando vários clusters juntos, convém criar uma rede virtual e, se estiver usando um cluster do Spark, também desejará usar o Hive Warehouse Connector. Para obter mais informações, consulte Planejar uma rede virtual para o Azure HDInsight e Integrar o Apache Spark e o Apache Hive com o Hive Warehouse Connector.
Um modelo do Azure Resource Manager é um arquivo JSON (JavaScript Object Notation) que define a infraestrutura e a configuração do seu projeto. O modelo utiliza sintaxe declarativa. Você descreve a implantação pretendida sem escrever a sequência de comandos de programação para criar a implantação.
Se o seu ambiente cumpre os pré-requisitos e se está familiarizado com a utilização de modelos ARM, selecione o botão Implementar no Azure. O modelo será aberto no portal do Azure.

Pré-requisitos
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Rever o modelo
O modelo utilizado neste início rápido pertence aos Modelos de Início Rápido do Azure.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
Dois recursos do Azure são definidos no modelo:
- Microsoft.Storage/storageAccounts: crie uma Conta de Armazenamento do Azure.
- Microsoft.HDInsight/cluster: crie um cluster HDInsight.
Implementar o modelo
Selecione o botão Implementar no Azure, abaixo, para iniciar sessão no Azure e abrir o modelo do ARM.
Introduza ou selecione os seguintes valores:
Propriedade Descrição Subscrição Na lista suspensa, selecione a assinatura do Azure usada para o cluster. Grupo de recursos Na lista pendente, selecione o grupo de recursos existente ou selecione Criar novo. Localização O valor será preenchido automaticamente com a localização utilizada para o grupo de recursos. Nome do Cluster Introduza um nome globalmente exclusivo. Para este modelo, use apenas letras minúsculas e números. Nome de Utilizador de Início de Sessão do Cluster Forneça o nome de usuário, o padrão é admin.Palavra-passe de Início de Sessão do Cluster Forneça uma senha. A senha deve ter pelo menos 10 caracteres e deve conter pelo menos um dígito, uma letra maiúscula e uma letra minúscula, um caractere não alfanumérico (exceto caracteres ' ` ").Nome de utilizador SSH Forneça o nome de usuário, o padrão é sshuser.Palavra-passe SSH Forneça a senha. 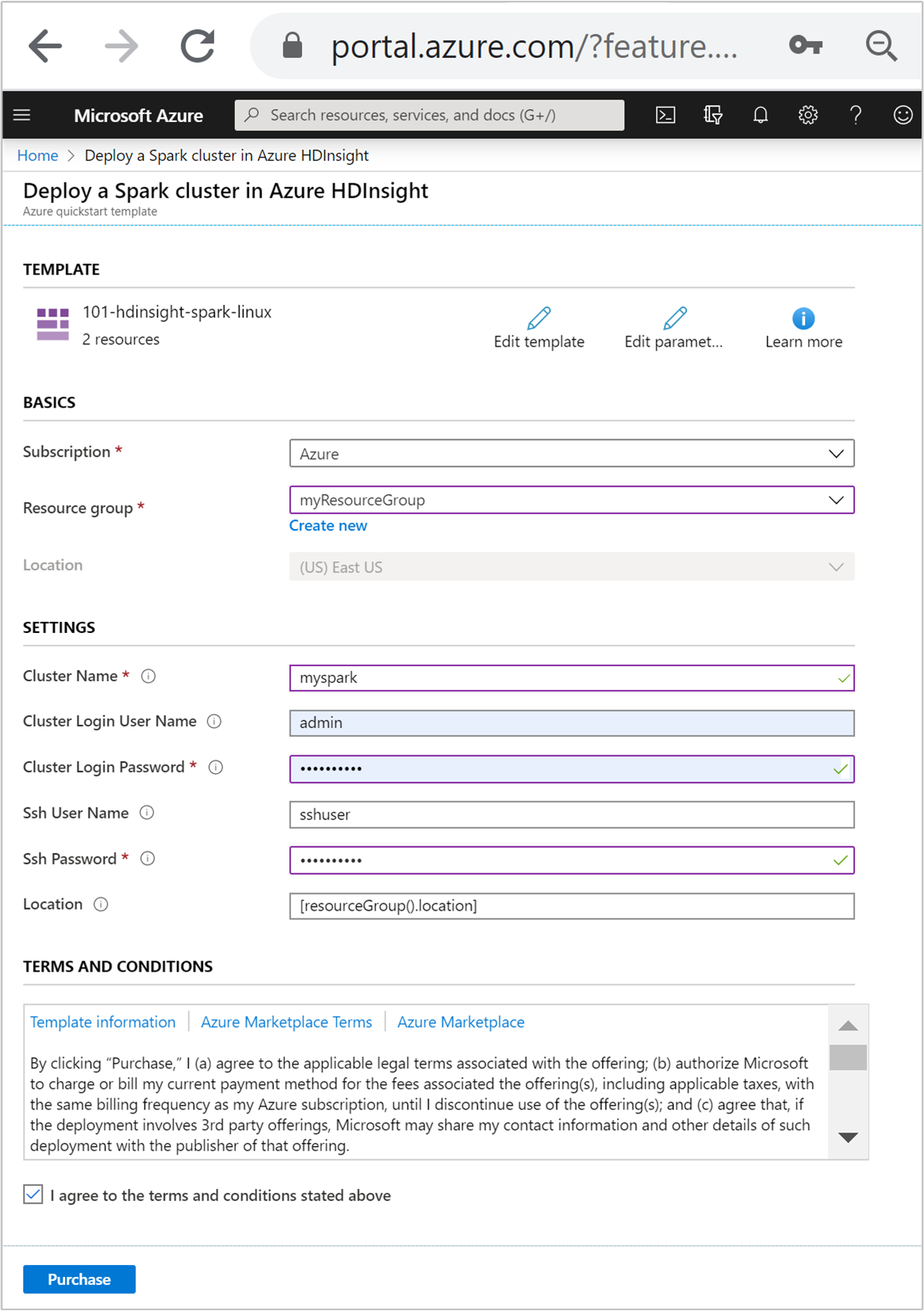
Reveja os TERMOS E CONDIÇÕES. Em seguida, selecione Concordo com os termos e condições mencionados acima e, em seguida , Comprar. Você receberá uma notificação de que sua implantação está em andamento. A criação de um cluster demora cerca de 20 minutos.
Se você tiver um problema com a criação de clusters HDInsight, pode ser que você não tenha as permissões certas para fazê-lo. Para obter mais informações, veja Access control requirements (Requisitos do controlo de acesso).
Rever os recursos implementados
Depois que o cluster for criado, você receberá uma notificação de implantação bem-sucedida com um link Ir para o recurso . A página Grupo de recursos listará o novo cluster HDInsight e o armazenamento padrão associado ao cluster. Cada cluster tem um Armazenamento do Azure ou uma Azure Data Lake Storage Gen2 dependência. É conhecida como a conta de armazenamento padrão. O cluster HDInsight e sua conta de armazenamento padrão devem ser colocalizados na mesma região do Azure. A exclusão de clusters não exclui a dependência da conta de armazenamento. É conhecida como a conta de armazenamento padrão. O cluster HDInsight e sua conta de armazenamento padrão devem ser colocalizados na mesma região do Azure. A exclusão de clusters não exclui a conta de armazenamento.
Criar um ficheiro do Jupyter Notebook
Jupyter Notebook é um ambiente de notebook interativo que suporta várias linguagens de programação. Você pode usar um arquivo do Jupyter Notebook para interagir com seus dados, combinar código com texto de marcação e executar visualizações simples.
Abra o portal do Azure.
Selecione Clusters do HDInsight e, em seguida, selecione o cluster que criou.
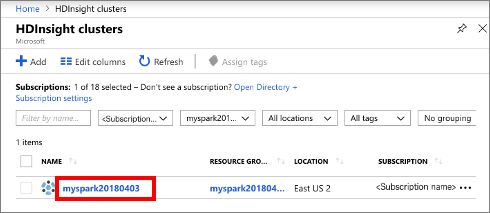
No portal, na seção Painéis de cluster, selecione Jupyter Notebook. Se lhe for pedido, introduza as credenciais de início de sessão do cluster.
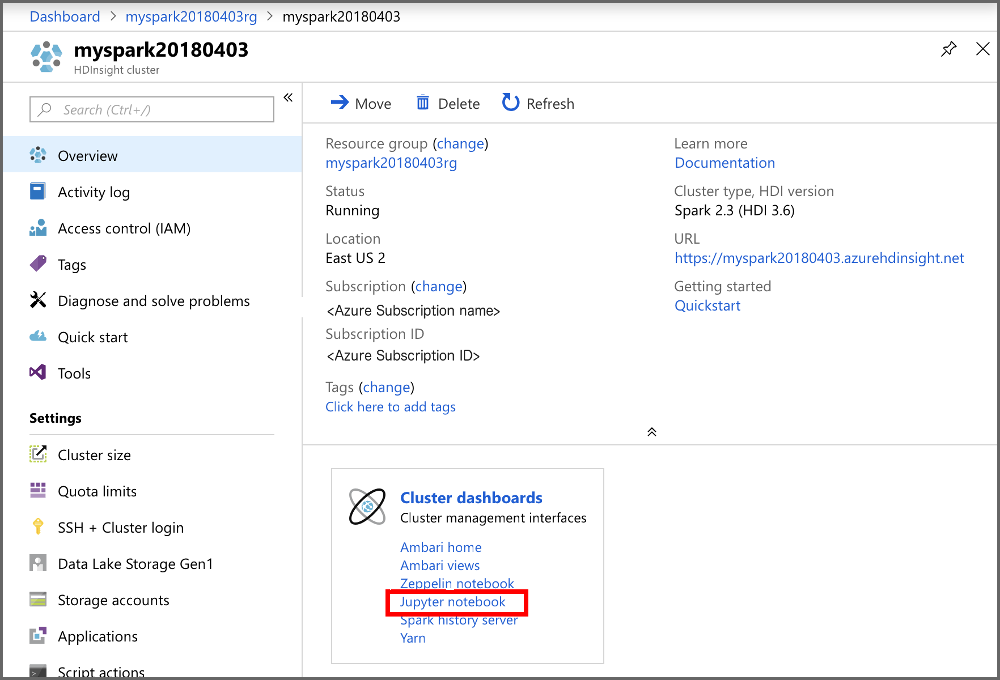
Selecione New (Novo)>PySpark para criar um bloco de notas.
É criado e aberto um novo bloco de notas com o nome Untitled (Untitled.pynb).
Executar instruções SQL do Apache Spark
SQL (Structured Query Language) é a linguagem mais comum e mais utilizada para consultar e transformar dados. O Spark SQL funciona como uma extensão do Apache Spark para o processamento de dados estruturados e utiliza a sintaxe familiar do SQL Server.
Verifique se o kernel está pronto. O kernel está pronto quando vir um círculo hollow junto ao nome do kernel no bloco de notas. O círculo sólido indica que o kernel está ocupado.
 alt-text="Status do kernel." border="true":::
alt-text="Status do kernel." border="true":::Quando inicia o bloco de notas pela primeira vez, o kernel efetua algumas tarefas em segundo plano. Aguarde que o kernel esteja preparado.
Cole o seguinte código numa célula vazia e, em seguida, prima SHIFT + ENTER para o executar. O comando lista as tabelas do Hive no cluster:
%%sql SHOW TABLESAo usar um arquivo do Jupyter Notebook com o cluster HDInsight, você obtém uma sessão predefinida
sparkque pode ser usada para executar consultas do Hive usando o Spark SQL.%%sqlindica ao Bloco de Notas do Jupyter que utilize a sessãosparkpredefinida para executar a consulta do Hive. A consulta devolve as primeiras dez linhas de uma tabela do Hive (hivesampletable) que vem em todos os clusters do HDInsight por predefinição. Na primeira vez que você enviar a consulta, o Jupyter criará um aplicativo Spark para o bloco de anotações. São precisos cerca de 30 segundos para concluir. Quando o aplicativo Spark estiver pronto, a consulta será executada em cerca de um segundo e produzirá os resultados. O resultado tem o seguinte aspeto: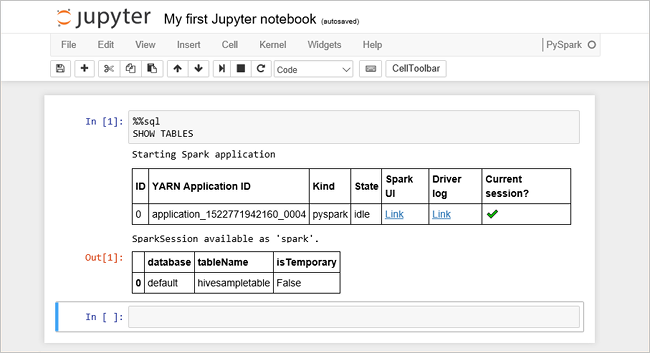 y no HDInsight" border="true":::
y no HDInsight" border="true":::Sempre que executar uma consulta no Jupyter, o título da janela do browser apresenta o estado (Ocupado) juntamente com o título do bloco de notas. Também vê um círculo sólido junto ao texto do PySpark no canto superior direito.
Execute outra consulta para ver os dados no
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10O ecrã deve atualizar-se e mostrar o resultado da consulta.
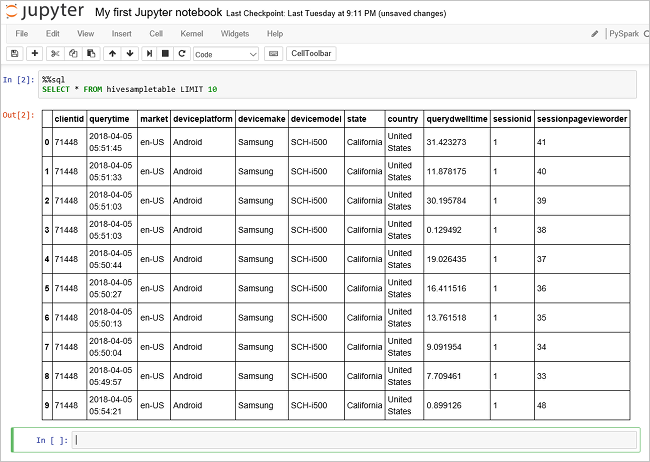 Insight" border="true":::
Insight" border="true":::No menu File (Ficheiro) do bloco de notas, selecione Close and Halt (Fechar e Parar). Desligar o bloco de anotações libera os recursos do cluster, incluindo o aplicativo Spark.
Clean up resources (Limpar recursos)
Depois de concluir o início rápido, convém excluir o cluster. Com o HDInsight, seus dados são armazenados no Armazenamento do Azure, para que você possa excluir com segurança um cluster quando ele não estiver em uso. Você também é cobrado por um cluster HDInsight, mesmo quando ele não está em uso. Como as cobranças para o cluster são muitas vezes mais do que as taxas para armazenamento, faz sentido econômico excluir clusters quando eles não estão em uso.
No portal do Azure, navegue até o cluster e selecione Excluir.
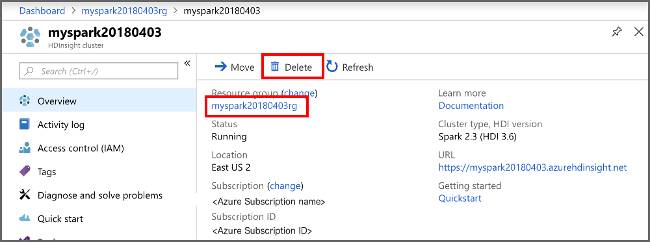 sight cluster" border="true":::
sight cluster" border="true":::
Também pode selecionar o nome do grupo de recursos para abrir a página do grupo de recursos e, em seguida, selecionar Eliminar grupo de recursos. Ao excluir o grupo de recursos, você exclui o cluster HDInsight e a conta de armazenamento padrão.
Próximos passos
Neste início rápido, você aprendeu como criar um cluster Apache Spark no HDInsight e executar uma consulta básica do Spark SQL. Avance para o próximo tutorial para saber como usar um cluster HDInsight para executar consultas interativas em dados de exemplo.