Ingestão de dados com o Azure Data Factory
Neste artigo, você aprenderá sobre as opções disponíveis para criar um pipeline de ingestão de dados com o Azure Data Factory. Este pipeline do Azure Data Factory é usado para ingerir dados para uso com o Azure Machine Learning. O Data Factory permite extrair, transformar e carregar facilmente dados (ETL). Depois que os dados são transformados e carregados no armazenamento, eles podem ser usados para treinar seus modelos de aprendizado de máquina no Azure Machine Learning.
A transformação de dados simples pode ser tratada com atividades e instrumentos nativos do Data Factory, como fluxo de dados. Quando se trata de cenários mais complicados, os dados podem ser processados com algum código personalizado. Por exemplo, código Python ou R.
Comparar pipelines de ingestão de dados do Azure Data Factory
Existem várias técnicas comuns de utilização do Data Factory para transformar dados durante a ingestão. Cada técnica tem vantagens e desvantagens que ajudam a determinar se é adequada para um caso de uso específico:
| Técnica | Vantagens | Desvantagens |
|---|---|---|
| Data Factory + Azure Functions | Apenas bom para processamento de curta duração | |
| Data Factory + componente personalizado | ||
| Data Factory + notebook Azure Databricks |
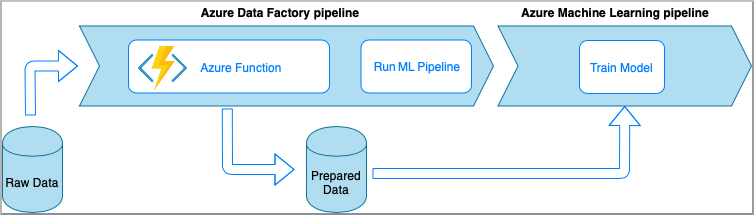
Azure Data Factory com funções do Azure
O Azure Functions permite que você execute pequenas partes de código (funções) sem se preocupar com a infraestrutura do aplicativo. Nesta opção, os dados são processados com código Python personalizado encapsulado em uma Função do Azure.
A função é invocada com a atividade Azure Data Factory Azure Function. Essa abordagem é uma boa opção para transformações de dados leves.
- Vantagens:
- Os dados são processados em uma computação sem servidor com uma latência relativamente baixa
- O pipeline do Data Factory pode invocar uma Função Durável do Azure que pode implementar um fluxo sofisticado de transformação de dados
- Os detalhes da transformação de dados são abstraídos pela Função do Azure que pode ser reutilizada e invocada de outros locais
- Desvantagens:
- O Azure Functions deve ser criado antes do uso com o ADF
- O Azure Functions é bom apenas para processamento de dados de curta duração
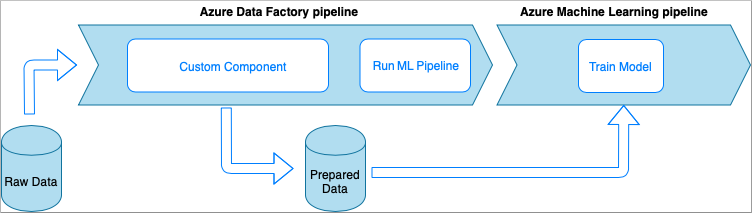
Azure Data Factory com atividade de componente personalizado
Nesta opção, os dados são processados com código Python personalizado encapsulado em um executável. Ele é invocado com uma atividade do Componente Personalizado do Azure Data Factory. Essa abordagem é mais adequada para dados grandes do que a técnica anterior.
- Vantagens:
- Os dados são processados no pool de lotes do Azure, que fornece computação paralela e de alto desempenho em grande escala
- Pode ser usado para executar algoritmos pesados e processar quantidades significativas de dados
- Desvantagens:
- O pool de lotes do Azure deve ser criado antes do uso com o Data Factory
- Sobre engenharia relacionada ao encapsulamento de código Python em um executável. Complexidade do tratamento de dependências e parâmetros de entrada/saída
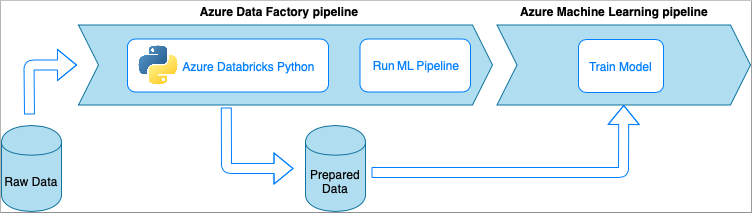
Azure Data Factory com bloco de notas Python do Azure Databricks
O Azure Databricks é uma plataforma de análise baseada no Apache Spark na nuvem da Microsoft.
Nessa técnica, a transformação de dados é executada por um bloco de anotações Python, executado em um cluster do Azure Databricks. Esta é, provavelmente, a abordagem mais comum que usa todo o poder de um serviço Azure Databricks. Ele foi projetado para processamento de dados distribuídos em escala.
- Vantagens:
- Os dados são transformados no serviço de processamento de dados mais poderoso do Azure, cujo backup é feito pelo ambiente Apache Spark
- Suporte nativo de Python juntamente com estruturas e bibliotecas de ciência de dados, incluindo TensorFlow, PyTorch e scikit-learn
- Não há necessidade de envolver o código Python em funções ou módulos executáveis. O código funciona como está.
- Desvantagens:
- A infraestrutura do Azure Databricks deve ser criada antes do uso com o Data Factory
- Pode ser caro dependendo da configuração do Azure Databricks
- Girar clusters de computação a partir do modo "frio" leva algum tempo que traz alta latência para a solução
Consumir dados no Azure Machine Learning
O pipeline do Data Factory salva os dados preparados em seu armazenamento em nuvem (como o Blob do Azure ou o Azure Data Lake).
Consuma seus dados preparados no Azure Machine Learning ao,
- Invocando um pipeline do Azure Machine Learning a partir do seu pipeline do Data Factory.
OU - Criando um armazenamento de dados do Azure Machine Learning.
Invoque o pipeline do Azure Machine Learning a partir do Data Factory
Esse método é recomendado para fluxos de trabalho de Operações de Aprendizado de Máquina (MLOps). Se você não quiser configurar um pipeline do Azure Machine Learning, consulte Ler dados diretamente do armazenamento.
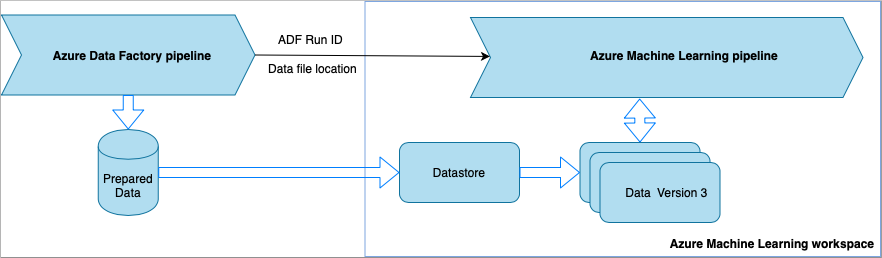
Cada vez que o pipeline do Data Factory é executado,
- Os dados são salvos em um local diferente no armazenamento.
- Para passar o local para o Azure Machine Learning, o pipeline do Data Factory chama um pipeline do Azure Machine Learning. Quando o pipeline do Data Factory chama o pipeline do Azure Machine Learning, o local dos dados e a ID do trabalho são enviados como parâmetros.
- O pipeline de ML pode criar um armazenamento de dados e um conjunto de dados do Azure Machine Learning com o local dos dados. Saiba mais em Executar pipelines do Azure Machine Learning no Data Factory.
Gorjeta
Os conjuntos de dados oferecem suporte ao controle de versão, para que o pipeline de ML possa registrar uma nova versão do conjunto de dados que aponte para os dados mais recentes do pipeline do ADF.
Quando os dados estiverem acessíveis por meio de um armazenamento de dados ou conjunto de dados, você poderá usá-los para treinar um modelo de ML. O processo de treinamento pode fazer parte do mesmo pipeline de ML chamado do ADF. Ou pode ser um processo separado, como a experimentação em um caderno Jupyter.
Como os conjuntos de dados suportam controle de versão e cada trabalho do pipeline cria uma nova versão, é fácil entender qual versão dos dados foi usada para treinar um modelo.
Ler dados diretamente do armazenamento
Se não quiser criar um pipeline de ML, você pode acessar os dados diretamente da conta de armazenamento onde os dados preparados são salvos com um armazenamento de dados e um conjunto de dados do Azure Machine Learning.
O código Python a seguir demonstra como criar um armazenamento de dados que se conecta ao armazenamento do Azure DataLake Geração 2. Saiba mais sobre armazenamentos de dados e onde encontrar permissões de entidade de serviço.
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
Em seguida, crie um conjunto de dados para fazer referência aos arquivos que você deseja usar em sua tarefa de aprendizado de máquina.
O código a seguir cria um TabularDataset a partir de um arquivo csv, prepared-data.csv. Saiba mais sobre tipos de conjunto de dados e formatos de arquivo aceitos.
APLICA-SE A: Python SDK azureml v1
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
A partir daqui, use prepared_dataset para referenciar seus dados preparados, como em seus scripts de treinamento. Saiba como treinar modelos com conjuntos de dados no Azure Machine Learning.