Criar e executar pipelines de aprendizado de máquina usando componentes com o estúdio de Aprendizado de Máquina do Azure
APLICA-SE A: Azure CLI ml extension v2 (atual)
Azure CLI ml extension v2 (atual)
Neste artigo, você aprenderá a criar e executar pipelines de aprendizado de máquina usando o estúdio e os Componentes do Azure Machine Learning. Você pode criar pipelines sem usar componentes, mas os componentes oferecem melhor flexibilidade e reutilização. Os Pipelines do Azure Machine Learning podem ser definidos em YAML e executados a partir da CLI, criados em Python ou compostos no Azure Machine Learning studio Designer com uma interface do usuário de arrastar e soltar. Este documento se concentra na interface do usuário do designer do estúdio do Azure Machine Learning.
Pré-requisitos
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
Um espaço de trabalho do Azure Machine Learning Crie recursos de espaço de trabalho.
Instale e configure a extensão da CLI do Azure para Machine Learning.
Clone o repositório de exemplos:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Nota
O Designer suporta dois tipos de componentes, componentes pré-construídos clássicos (v1) e componentes personalizados (v2). Estes dois tipos de componentes NÃO são compatíveis.
Os componentes pré-construídos clássicos fornecem componentes pré-construídos principalmente para processamento de dados e tarefas tradicionais de aprendizado de máquina, como regressão e classificação. Os componentes pré-construídos clássicos continuam a ser suportados, mas não terão novos componentes adicionados. Além disso, a implantação de componentes pré-construídos clássicos (v1) não oferece suporte a pontos de extremidade online gerenciados (v2).
Os componentes personalizados permitem que você envolva seu próprio código como um componente. Ele suporta o compartilhamento de componentes entre espaços de trabalho e a criação contínua entre interfaces de estúdio, CLI v2 e SDK v2.
Para novos projetos, sugerimos que você use o componente personalizado, que é compatível com o AzureML V2 e continuará recebendo novas atualizações.
Este artigo aplica-se a componentes personalizados.
Registrar componente em seu espaço de trabalho
Para criar pipeline usando componentes na interface do usuário, você precisa registrar componentes em seu espaço de trabalho primeiro. Você pode usar a interface do usuário, CLI ou SDK para registrar componentes em seu espaço de trabalho, para que você possa compartilhar e reutilizar o componente dentro do espaço de trabalho. Os componentes registrados suportam o controle de versão automático para que você possa atualizar o componente, mas garantir que os pipelines que exigem uma versão mais antiga continuem a funcionar.
O exemplo a seguir usa a interface do usuário para registrar componentes, e os arquivos de origem do componente estão no diretório do azureml-examples repositório.cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components Você precisa clonar o repositório para local primeiro.
- No seu espaço de trabalho do Azure Machine Learning, navegue até a página Componentes e selecione Novo Componente (uma das duas páginas de estilo aparecerá).


Este exemplo usa train.yml no diretório. O arquivo YAML define o nome, tipo, interface, incluindo entradas e saídas, código, ambiente e comando deste componente. O código deste componente train.py está em ./train_src pasta, que descreve a lógica de execução deste componente. Para saber mais sobre o esquema do componente, consulte a referência do esquema YAML do componente de comando.
Nota
Ao registrar componentes na interface do usuário, definidos no componente, code o arquivo YAML só pode apontar para a pasta atual onde o arquivo YAML localiza ou para as subpastas, o que significa que você não pode especificar ../ para code como a interface do usuário não pode reconhecer o diretório pai.
additional_includes só pode apontar para a pasta atual ou sub.
Atualmente, a interface do usuário suporta apenas o registro de componentes com command tipo.
- Selecione Carregar da pasta e selecione a
1b_e2e_registered_componentspasta a carregar. Selecionetrain.ymlna lista suspensa.

Selecione Avançar na parte inferior e você pode confirmar os detalhes desse componente. Depois de confirmar, selecione Criar para concluir o processo de registro.
Repita as etapas anteriores para registrar o componente Score e Eval usando
score.ymleeval.ymltambém.Depois de registrar os três componentes com êxito, você pode ver seus componentes na interface do usuário do estúdio.

Criar pipeline usando o componente registrado
Crie um novo pipeline no designer. Lembre-se de selecionar a opção Personalizar .

Dê ao pipeline um nome significativo selecionando o ícone de lápis ao lado do nome gerado automaticamente.

Na biblioteca de ativos do designer, você pode ver as guias Dados, Modelo e Componentes . Alterne para a guia Componentes , você pode ver os componentes registrados na seção anterior. Se houver muitos componentes, você pode pesquisar com o nome do componente.

Encontre os componentes de trem, pontuação e eval registrados na seção anterior e arraste-os e solte-os na tela. Por padrão, ele usa a versão padrão do componente e você pode alterar para uma versão específica no painel direito do componente. O painel direito do componente é invocado clicando duas vezes no componente.

Neste exemplo, usaremos os dados de exemplo sob esse caminho. Registre os dados em seu espaço de trabalho selecionando o ícone adicionar na biblioteca de ativos do designer -> guia dados, defina Type = Folder(uri_folder) e siga o assistente para registrar os dados. O tipo de dados precisa ser uri_folder para alinhar com a definição do componente do trem.

Em seguida, arraste e solte os dados na tela. Sua aparência de pipeline deve se parecer com a captura de tela a seguir agora.

Conecte os dados e componentes arrastando conexões na tela.
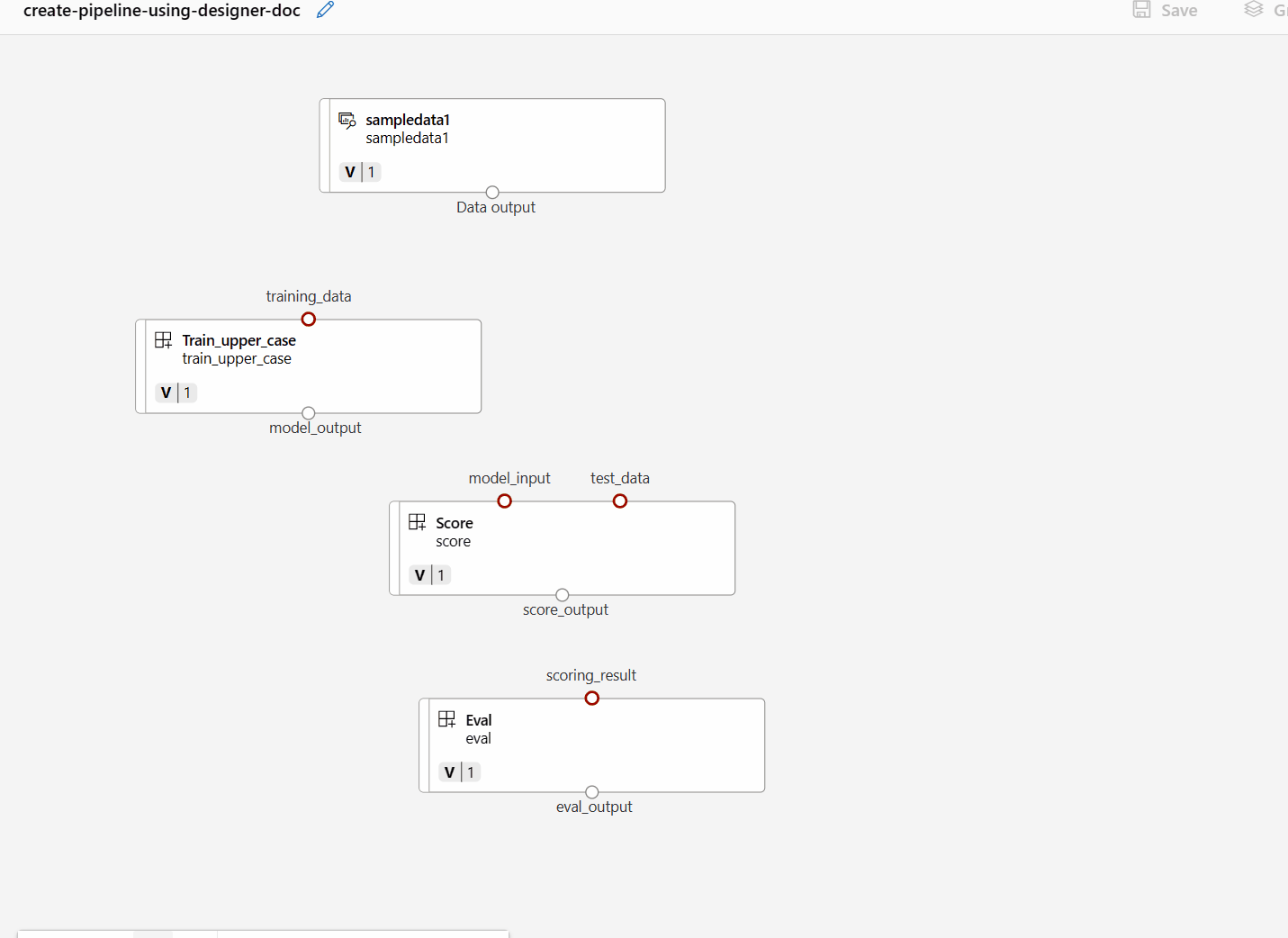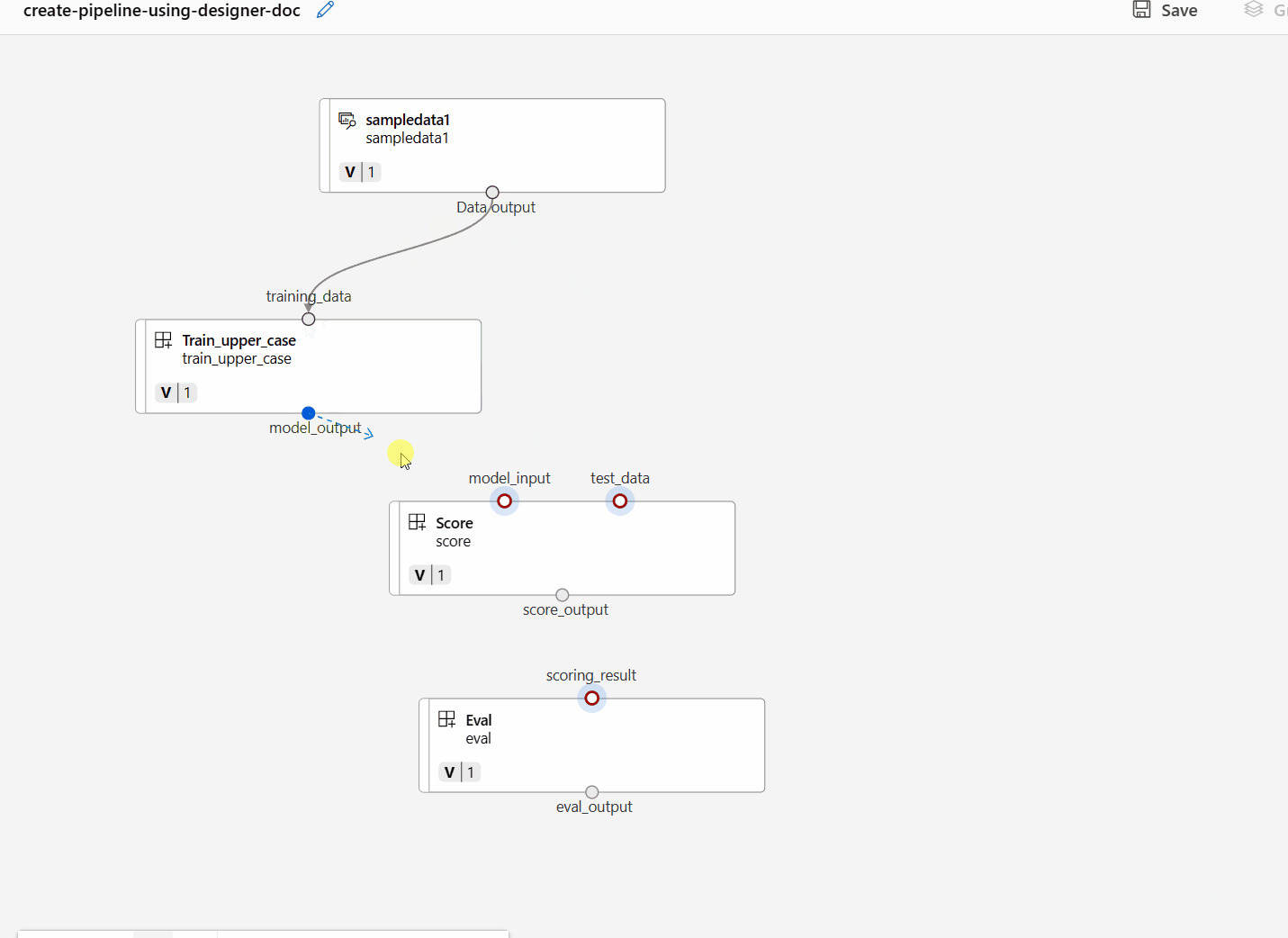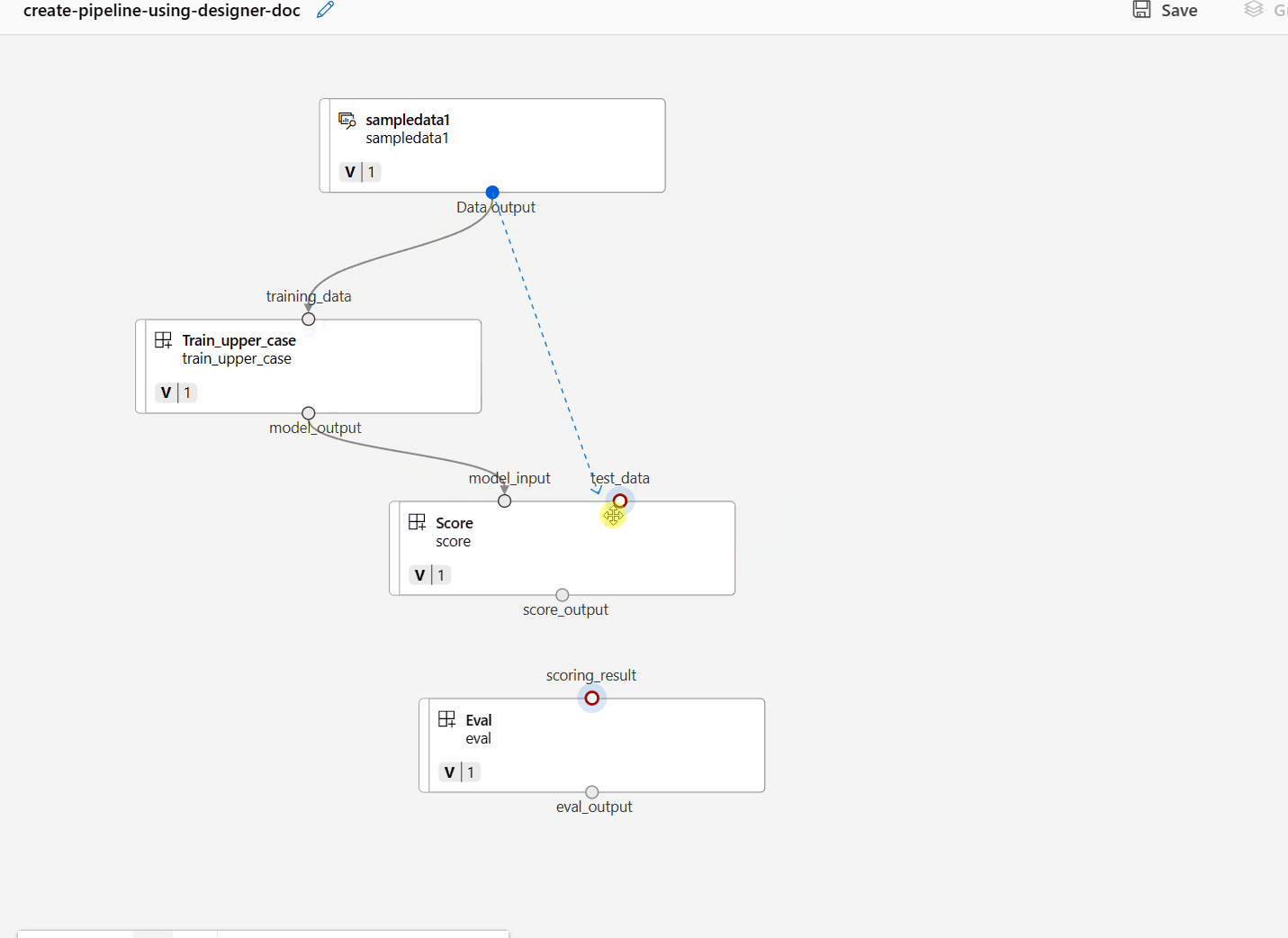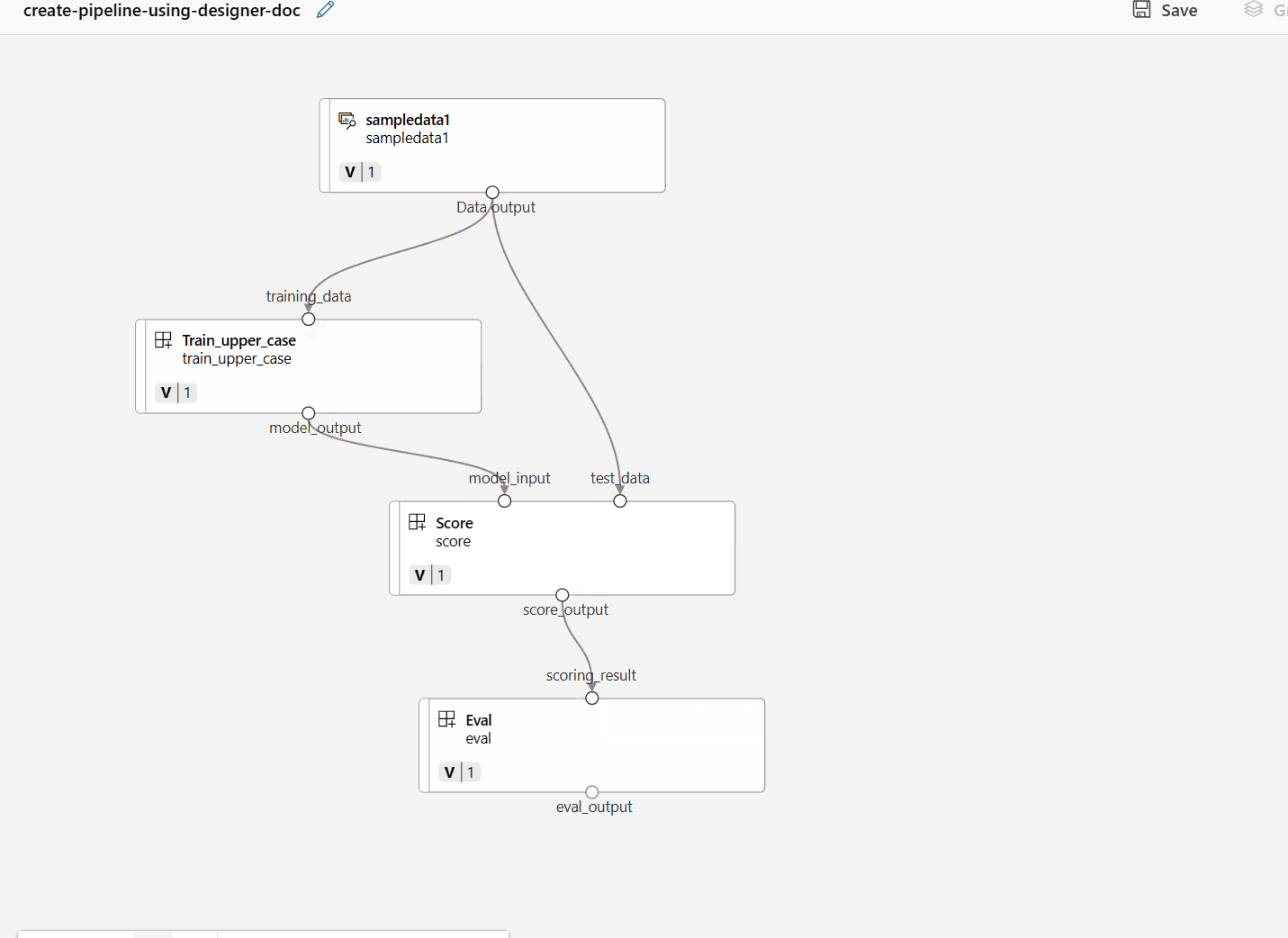
Clique duas vezes em um componente, você verá um painel direito onde você pode configurar o componente.

Para componentes com entradas de tipo primitivo como número, inteiro, cadeia de caracteres e booleano, você pode alterar os valores dessas entradas no painel detalhado do componente, na seção Entradas .
Você também pode alterar as configurações de saída (onde armazenar a saída do componente) e executar as configurações (destino de computação para executar esse componente) no painel direito.
Agora vamos promover a entrada max_epocs do componente de trem para a entrada no nível do pipeline. Ao fazer isso, você pode atribuir um valor diferente a essa entrada sempre antes de enviar o pipeline.










Nota
Os componentes personalizados e os componentes pré-construídos clássicos do designer não podem ser usados juntos.
Enviar pipeline
Selecione Configurar & Enviar no canto superior direito para enviar o pipeline.

Em seguida, você verá um assistente passo a passo, siga o assistente para enviar o trabalho de pipeline.

Na etapa Noções básicas, você pode configurar o experimento, o nome de exibição do trabalho, a descrição do trabalho, etc.
Na etapa Inputs & Outputs , você pode configurar as Entradas/Saídas que são promovidas para o nível de pipeline. Na etapa anterior, promovemos a max_epocs do componente de trem para a entrada de tubulação, então você deve ser capaz de ver e atribuir valor a max_epocs aqui.
Nas configurações de tempo de execução, você pode configurar o armazenamento de dados padrão e a computação padrão do pipeline. É o armazenamento de dados/computação padrão para todos os componentes no pipeline. Mas observe que, se você definir uma computação ou armazenamento de dados diferente para um componente explicitamente, o sistema respeitará a configuração de nível de componente. Caso contrário, ele usa o valor padrão do pipeline.
A etapa Revisar + Enviar é a última etapa para revisar todas as configurações antes de enviar. O assistente se lembra da configuração da última vez se você enviar o pipeline.
Depois de enviar o trabalho de pipeline, haverá uma mensagem na parte superior com um link para os detalhes do trabalho. Você pode selecionar este link para revisar os detalhes da vaga.

Especificar identidade no trabalho de pipeline
Ao enviar o trabalho de pipeline, você pode especificar a identidade para acessar os dados em Run settings. A identidade padrão é AMLToken que não usou nenhuma identidade, enquanto isso, suportamos ambos e ManagedUserIdentity . Para UserIdentity, a identidade do remetente do trabalho é usada para acessar dados de entrada e gravar o resultado na pasta de saída. Se você especificar Managed, o sistema usará a identidade gerenciada para acessar os dados de entrada e gravar o resultado na pasta de saída.

Próximos passos
- Use esses notebooks Jupyter no GitHub para explorar ainda mais os pipelines de aprendizado de máquina
- Saiba como usar a CLI v2 para criar pipeline usando componentes.
- Saiba como usar o SDK v2 para criar pipeline usando componentes