Coletar dados de modelos em produção
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Este artigo mostra como coletar dados de um modelo do Azure Machine Learning implantado em um cluster do Serviço Kubernetes do Azure (AKS). Os dados coletados são armazenados no armazenamento de Blob do Azure.
Uma vez ativada a recolha, os dados recolhidos ajudam-no a:
Monitore desvios de dados nos dados de produção coletados.
Analisar dados coletados usando o Power BI ou o Azure Databricks
Tome melhores decisões sobre quando treinar novamente ou otimizar seu modelo.
Retreine seu modelo com os dados coletados.
Limitações
- O recurso de coleta de dados do modelo só pode funcionar com a imagem do Ubuntu 18.04.
Importante
A partir de 03/10/2023, a imagem do Ubuntu 18.04 foi preterida. O suporte para imagens do Ubuntu 18.04 será descartado a partir de janeiro de 2023, quando chegar ao EOL em 30 de abril de 2023.
O recurso MDC é incompatível com qualquer outra imagem que não seja o Ubuntu 18.04, que não está disponível depois que a imagem do Ubuntu 18.04 é preterida.
mMais informações você pode referir-se a:
Nota
O recurso de coleta de dados está atualmente em visualização, nenhum recurso de visualização é recomendado para cargas de trabalho de produção.
O que é recolhido e para onde vai
Podem ser recolhidos os seguintes dados:
Modele dados de entrada de serviços Web implantados em um cluster AKS. Áudio, imagens e vídeo de voz não são coletados.
Modele previsões usando dados de entrada de produção.
Nota
A pré-agregação e os pré-cálculos sobre estes dados não fazem atualmente parte do serviço de recolha.
A saída é salva no armazenamento de Blob. Como os dados são adicionados ao armazenamento de Blob, você pode escolher sua ferramenta favorita para executar a análise.
O caminho para os dados de saída no blob segue esta sintaxe:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Nota
Em versões do SDK do Azure Machine Learning para Python anteriores à versão 0.1.0a16, o designation argumento é chamado identifier. Se você desenvolveu seu código com uma versão anterior, você precisa atualizá-lo de acordo.
Pré-requisitos
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Um espaço de trabalho do Azure Machine Learning, um diretório local contendo seus scripts e o SDK do Azure Machine Learning para Python devem ser instalados. Para saber como instalá-los, consulte Como configurar um ambiente de desenvolvimento.
Você precisa de um modelo de aprendizado de máquina treinado para ser implantado no AKS. Se você não tiver um modelo, consulte o tutorial Modelo de classificação de imagem de trem.
Você precisa de um cluster AKS. Para obter informações sobre como criar um e implantá-lo, consulte Implantar modelos de aprendizado de máquina no Azure.
Configure o seu ambiente e instale o SDK de Monitorização do Azure Machine Learning.
Use uma imagem docker baseada no Ubuntu 18.04, que é fornecida com
libssl 1.0.0, a dependência essencial de modeldatacollector. Pode consultar as imagens pré-criadas.
Ativar a recolha de dados
Você pode habilitar a coleta de dados independentemente do modelo implantado por meio do Aprendizado de Máquina do Azure ou de outras ferramentas.
Para habilitar a coleta de dados, você precisa:
Abra o arquivo de pontuação.
Adicione o seguinte código na parte superior do ficheiro:
from azureml.monitoring import ModelDataCollectorDeclare suas variáveis de coleta de dados em sua
initfunção:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId é um parâmetro opcional. Você não precisa usá-lo se o seu modelo não exigir. O uso de CorrelationId ajuda você a mapear mais facilmente com outros dados, como LoanNumber ou CustomerId.
O parâmetro Identifier é usado posteriormente para criar a estrutura de pastas em seu blob. Você pode usá-lo para diferenciar dados brutos de dados processados.
Adicione as seguintes linhas de código à
run(input_df)função:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobA coleta de dados não é definida automaticamente como true quando você implanta um serviço no AKS. Atualize seu arquivo de configuração, como no exemplo a seguir:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)Você também pode habilitar o Application Insights para monitoramento de serviços alterando esta configuração:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Para criar uma nova imagem e implantar o modelo de aprendizado de máquina, consulte Implantar modelos de aprendizado de máquina no Azure.
Adicione o pacote pip 'Azure-Monitoring' às dependências conda do ambiente de serviço Web:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Desativar a recolha de dados
Você pode parar de coletar dados a qualquer momento. Use o código Python para desativar a coleta de dados.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Valide e analise os seus dados
Você pode escolher uma ferramenta de sua preferência para analisar os dados coletados em seu armazenamento de Blob.
Acesse rapidamente seus dados de blob
Inicie sessão no portal do Azure.
Abra o seu espaço de trabalho.
Selecione Armazenamento.

Siga o caminho para os dados de saída do blob com esta sintaxe:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Analisar dados do modelo usando o Power BI
Transfira e abra o Power BI Desktop.
Selecione Obter Dados e selecione Armazenamento de Blobs do Azure.

Adicione o nome da sua conta de armazenamento e introduza a sua chave de armazenamento. Você pode encontrar essas informações selecionando Configurações>Teclas de acesso em seu blob.
Selecione o contêiner de dados do modelo e selecione Editar.

No editor de consultas, clique na coluna Nome e adicione sua conta de armazenamento.
Insira o caminho do modelo no filtro. Se você quiser examinar apenas arquivos de um ano ou mês específico, basta expandir o caminho do filtro. Por exemplo, para examinar apenas os dados de março, use este caminho de filtro:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year/3>
Filtre os dados relevantes para você com base nos valores Name . Se você armazenou previsões e entradas, precisará criar uma consulta para cada uma.
Selecione as setas duplas para baixo ao lado do título da coluna Conteúdo para combinar os arquivos.

Selecione OK. Os dados são pré-carregados.
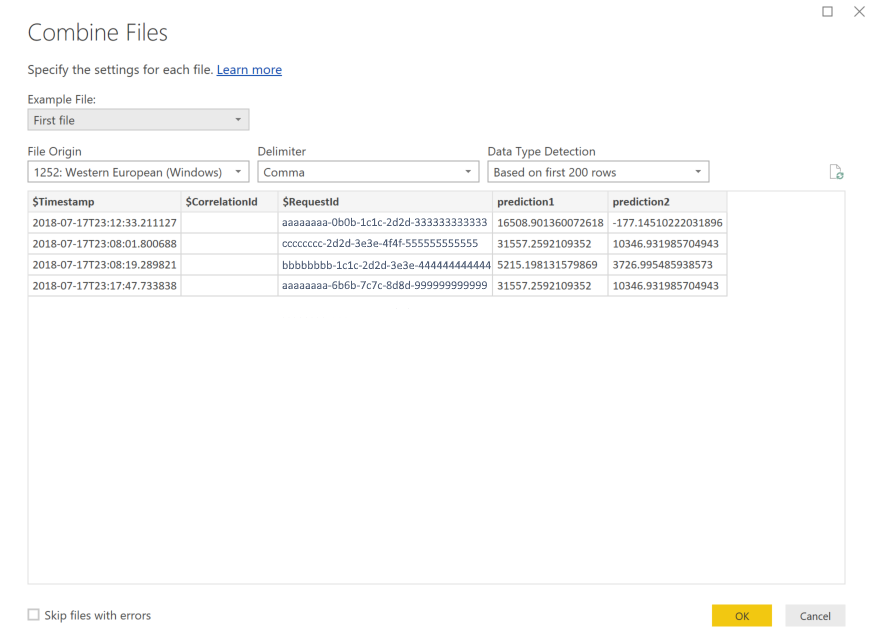
Selecione Fechar e Aplicar.
Se você adicionou entradas e previsões, suas tabelas serão ordenadas automaticamente por valores RequestId .
Comece a criar seus relatórios personalizados nos dados do modelo.




Analisar dados de modelo usando o Azure Databricks
Crie um espaço de trabalho do Azure Databricks.
Vá para o seu espaço de trabalho Databricks.
No espaço de trabalho Databricks, selecione Carregar dados.

Selecione Criar Nova Tabela e selecione Outras Fontes de Dados>Azure Blob Storage>Create Table in Notebook.
Atualize a localização dos seus dados. Segue-se um exemplo:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"
Siga as etapas no modelo para visualizar e analisar seus dados.



Próximos passos
Detete desvio de dados nos dados coletados.