Executar previsões em lote usando o designer do Azure Machine Learning
Neste artigo, você aprenderá a usar o designer para criar um pipeline de previsão em lote. A previsão em lote permite pontuar continuamente grandes conjuntos de dados sob demanda usando um serviço Web que pode ser acionado a partir de qualquer biblioteca HTTP.
Neste tutorial, você aprende a fazer as seguintes tarefas:
- Criar e publicar um pipeline de inferência em lote
- Consumir um ponto de extremidade de pipeline
- Gerenciar versões de endpoint
Para saber como configurar serviços de pontuação em lote usando o SDK, consulte o tutorial sobre pontuação em lote de pipeline.
Pré-requisitos
Este procedimento pressupõe que você já tenha um pipeline de treinamento. Para uma introdução guiada ao designer, conclua a primeira parte do tutorial do designer.
Importante
Se você não vir elementos gráficos mencionados neste documento, como botões no estúdio ou designer, talvez não tenha o nível correto de permissões para o espaço de trabalho. Entre em contato com o administrador da assinatura do Azure para verificar se você recebeu o nível correto de acesso. Para obter mais informações, veja Gerir utilizadores e funções.
Criar um pipeline de inferência em lote
Seu pipeline de treinamento deve ser executado pelo menos uma vez para poder criar um pipeline de inferência.
Vá para a guia Designer em seu espaço de trabalho.
Selecione o pipeline de treinamento que treina o modelo que você deseja usar para fazer a previsão.
Envie o pipeline.
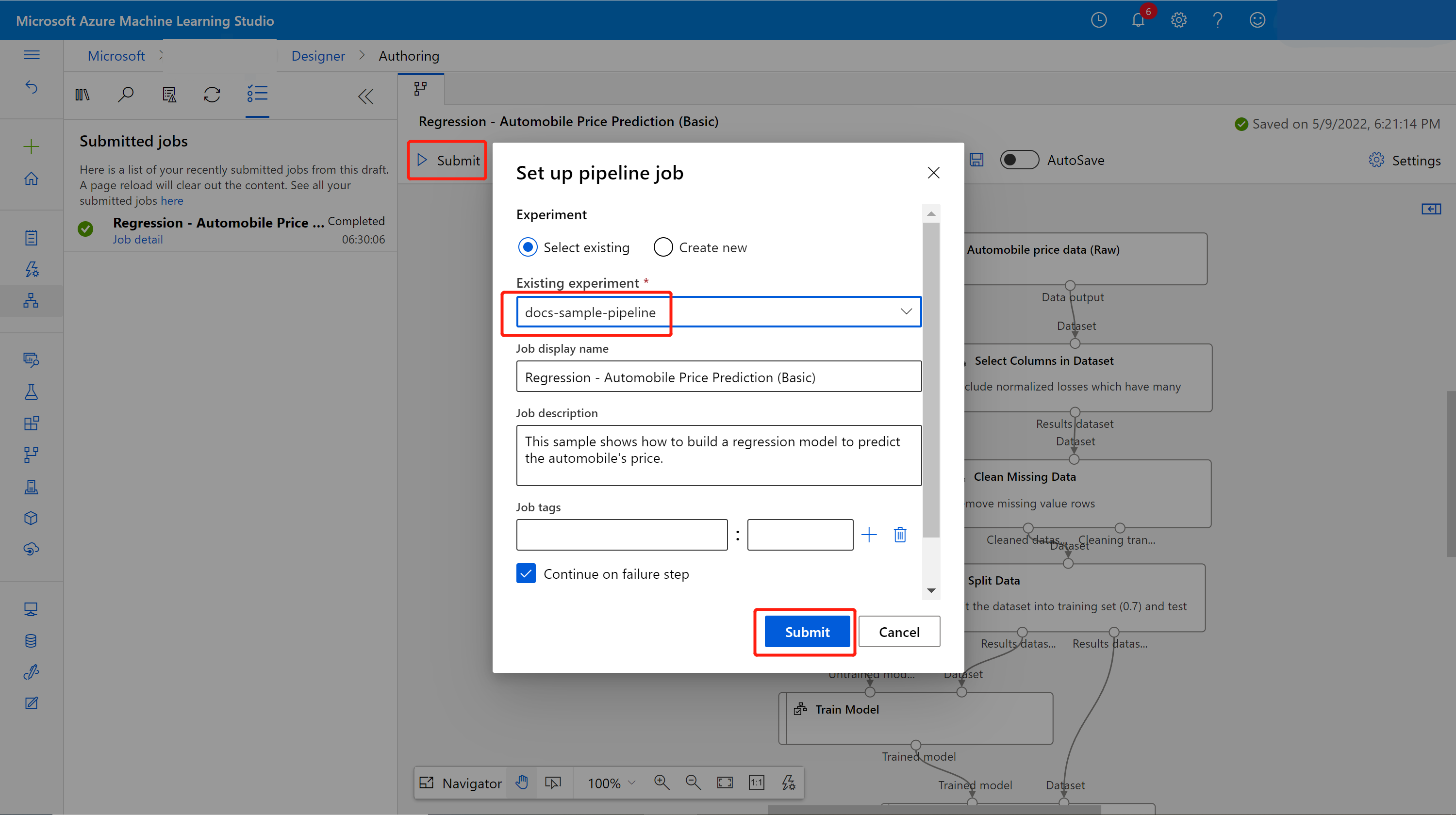

Você verá uma lista de envio à esquerda da tela. Você pode selecionar o link de detalhes do trabalho para ir para a página de detalhes do trabalho e, após a conclusão do trabalho do pipeline de treinamento, você pode criar um pipeline de inferência em lote.

Na página de detalhes do trabalho, acima da tela, selecione a lista suspensa Criar pipeline de inferência. Selecione Pipeline de inferência em lote.
Nota
Atualmente, o pipeline de inferência de geração automática só funciona para pipeline de treinamento construído exclusivamente pelos componentes internos do designer.
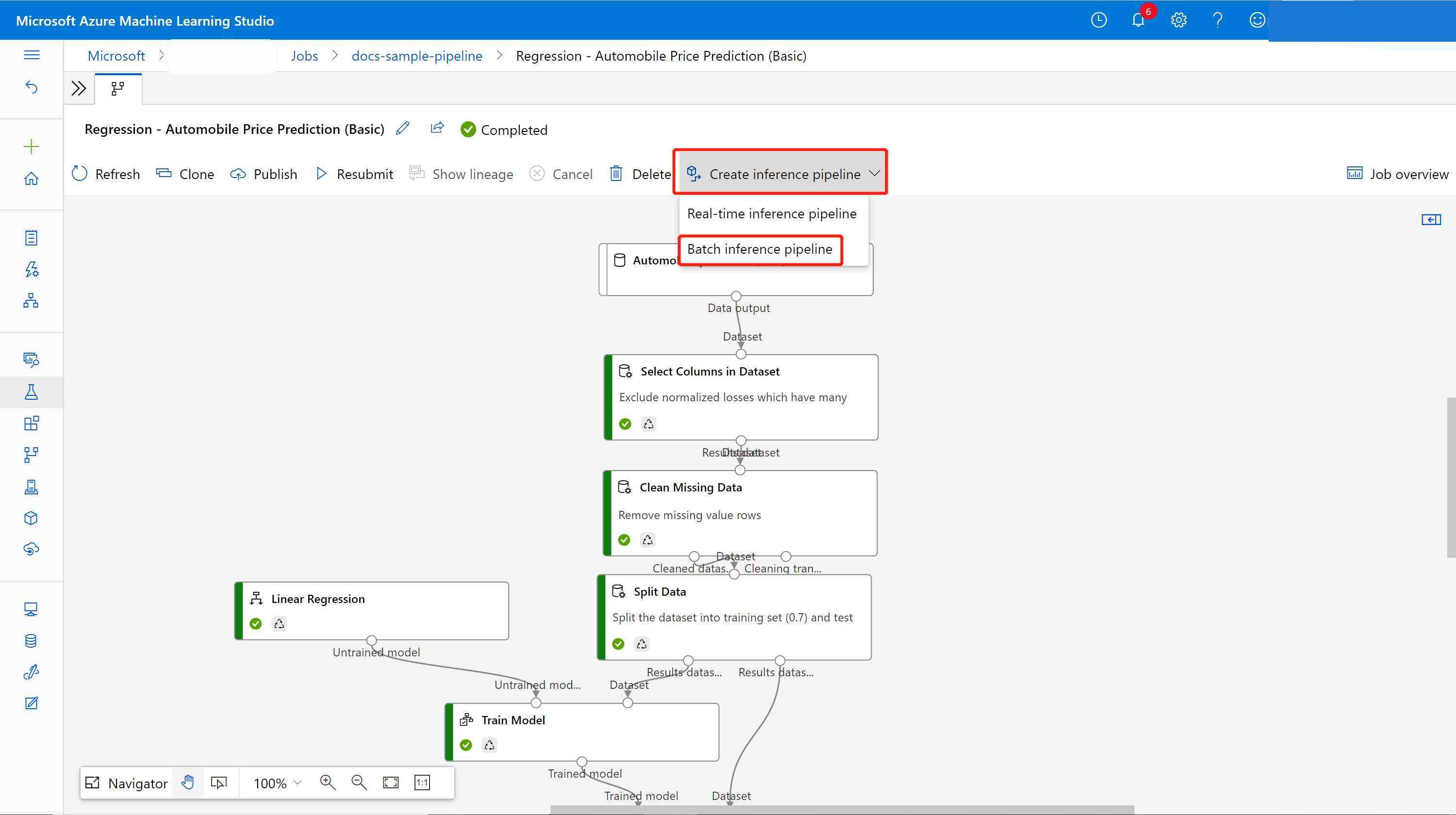
Ele criará um rascunho de pipeline de inferência em lote para você. O rascunho do pipeline de inferência em lote usa o modelo treinado como MD- nó e a transformação como TD- nó do trabalho do pipeline de treinamento.
Você também pode modificar esse rascunho de pipeline de inferência para lidar melhor com seus dados de entrada para inferência em lote.



Adicionar um parâmetro de pipeline
Para criar previsões sobre novos dados, você pode conectar manualmente um conjunto de dados diferente nesta exibição de rascunho de pipeline ou criar um parâmetro para seu conjunto de dados. Os parâmetros permitem alterar o comportamento do processo de inferência em lote em tempo de execução.
Nesta seção, você cria um parâmetro de conjunto de dados para especificar um conjunto de dados diferente para fazer previsões.
Selecione o componente do conjunto de dados.
Um painel aparecerá à direita da tela. Na parte inferior do painel, selecione Definir como parâmetro de pipeline.
Insira um nome para o parâmetro ou aceite o valor padrão.

Envie o pipeline de inferência em lote e vá para a página de detalhes do trabalho selecionando o link do trabalho no painel esquerdo.

Publique seu pipeline de inferência em lote
Agora você está pronto para implantar o pipeline de inferência. Isso implantará o pipeline e o disponibilizará para uso de outras pessoas.
Selecione o botão Publicar.
Na caixa de diálogo exibida, expanda a lista suspensa para PipelineEndpoint e selecione New PipelineEndpoint.
Forneça um nome de ponto de extremidade e uma descrição opcional.
Na parte inferior da caixa de diálogo, você pode ver o parâmetro configurado com um valor padrão do ID do conjunto de dados usado durante o treinamento.
Selecione Publicar.

Consumir um ponto de extremidade
Agora, você tem um pipeline publicado com um parâmetro de conjunto de dados. O pipeline usará o modelo treinado criado no pipeline de treinamento para pontuar o conjunto de dados fornecido como parâmetro.
Enviar um trabalho de pipeline
Nesta seção, você configurará um trabalho de pipeline manual e alterará o parâmetro de pipeline para pontuar novos dados.
Após a conclusão da implantação, vá para a seção Pontos de extremidade .
Selecione Pontos de extremidade de pipeline.
Selecione o nome do ponto de extremidade que você criou.
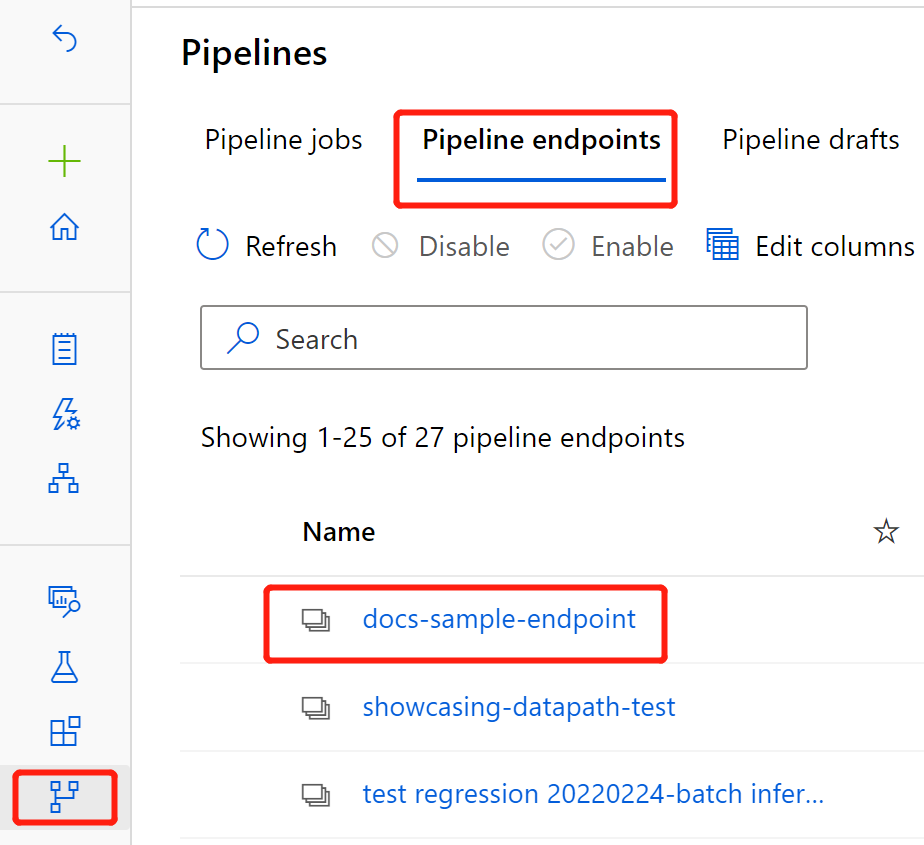
Selecione Pipelines publicados.
Esta tela mostra todos os pipelines publicados sob esse ponto de extremidade.
Selecione o pipeline que você publicou.
A página de detalhes do pipeline mostra um histórico de trabalho detalhado e informações de cadeia de conexão para seu pipeline.
Selecione Enviar para criar uma execução manual do pipeline.
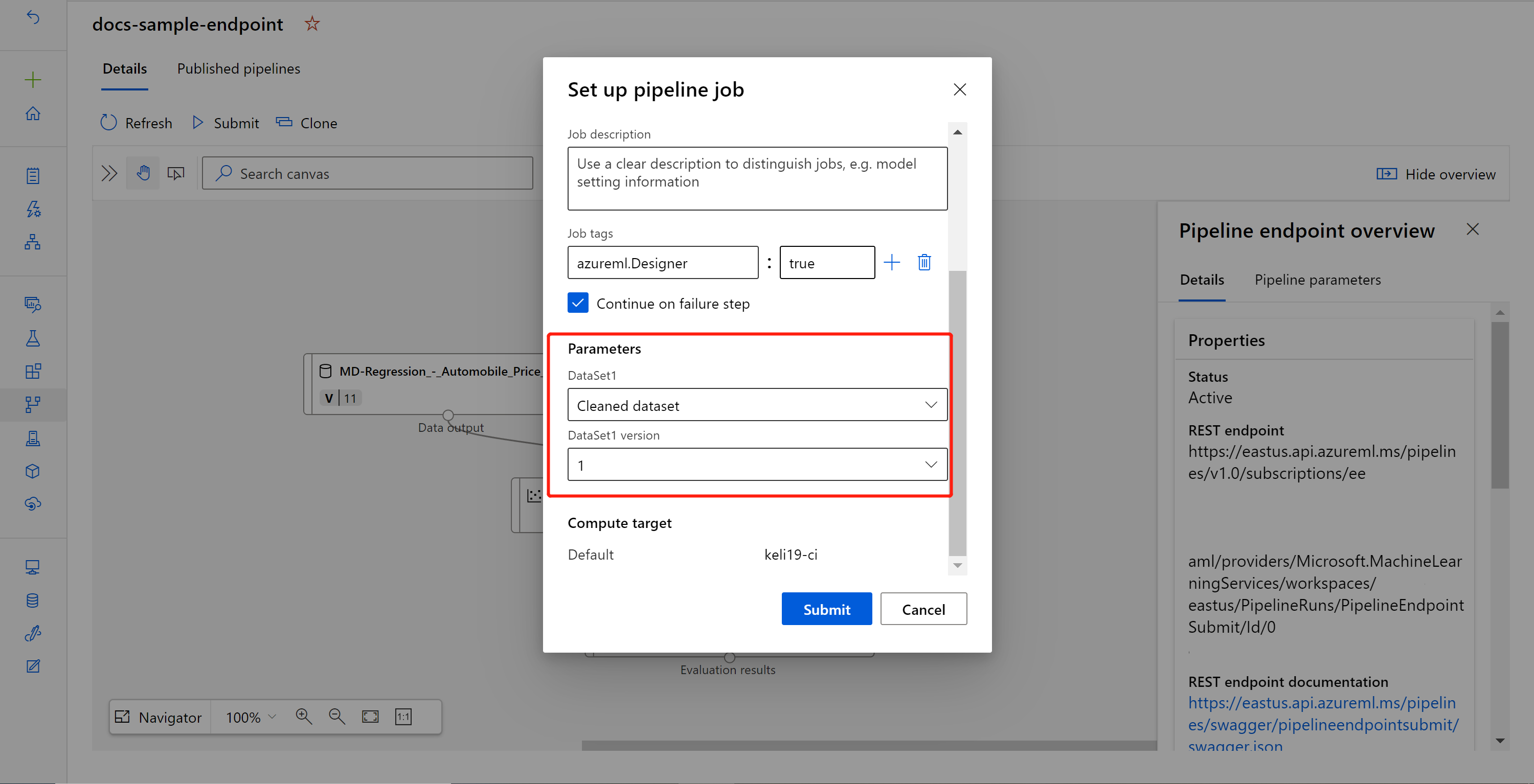
Altere o parâmetro para usar um conjunto de dados diferente.
Selecione Enviar para executar o pipeline.

Usar o ponto de extremidade REST
Você pode encontrar informações sobre como consumir pontos de extremidade de pipeline e pipeline publicado na seção Pontos de extremidade .
Você pode encontrar o ponto de extremidade REST de um ponto de extremidade de pipeline no painel de visão geral do trabalho. Ao chamar o ponto de extremidade, você está consumindo seu pipeline publicado padrão.
Você também pode consumir um pipeline publicado na página Pipelines publicados . Selecione um pipeline publicado e você pode encontrar o ponto de extremidade REST dele no painel Visão geral do pipeline publicado à direita do gráfico.
Para fazer uma chamada REST, você precisará de um cabeçalho de autenticação do tipo portador OAuth 2.0. Consulte a seção do tutorial a seguir para obter mais detalhes sobre como configurar a autenticação em seu espaço de trabalho e fazer uma chamada REST parametrizada.
Pontos de extremidade de controle de versão
O designer atribui uma versão a cada pipeline subsequente que você publica em um ponto de extremidade. Você pode especificar a versão do pipeline que deseja executar como um parâmetro em sua chamada REST. Se você não especificar um número de versão, o designer usará o pipeline padrão.
Ao publicar um pipeline, você pode optar por torná-lo o novo pipeline padrão para esse ponto de extremidade.
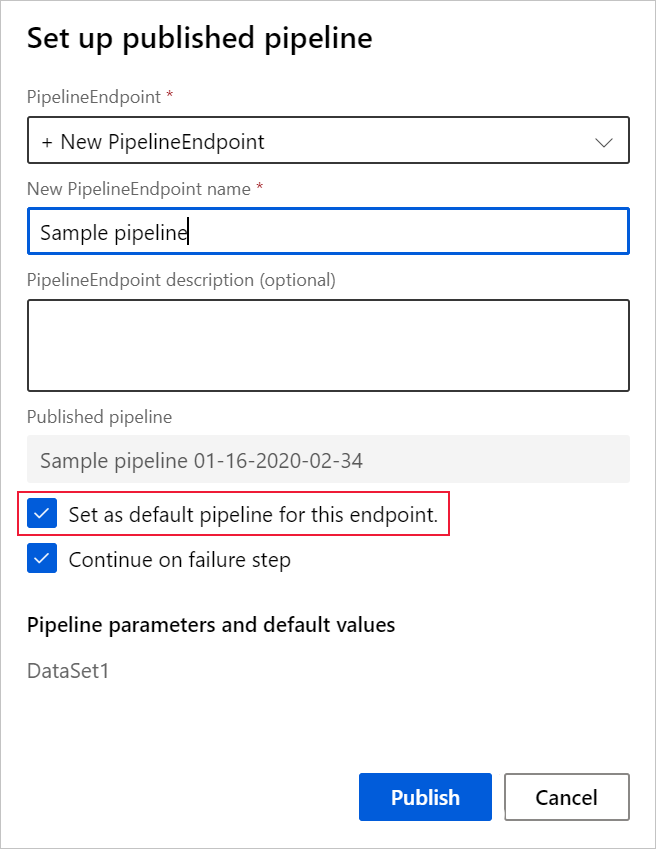
Você também pode definir um novo pipeline padrão na guia Pipelines publicados do seu ponto de extremidade.
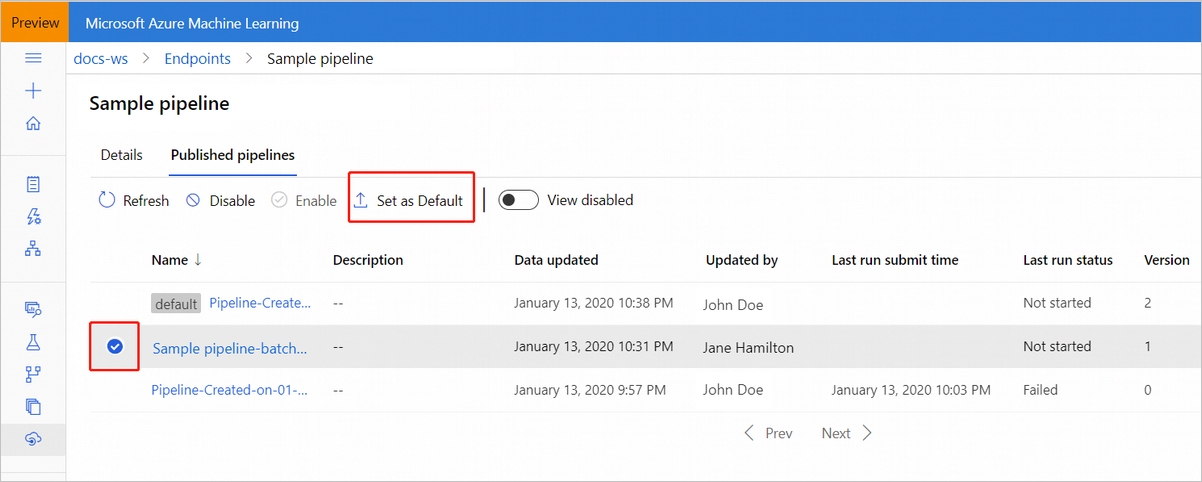
Atualizar ponto de extremidade do pipeline
Se você fizer algumas modificações em seu pipeline de treinamento, convém atualizar o modelo recém-treinado para o ponto de extremidade do pipeline.
Depois que o pipeline de treinamento modificado for concluído com êxito, vá para a página de detalhes do trabalho.
Clique com o botão direito do mouse no componente Train Model e selecione Registrar dados
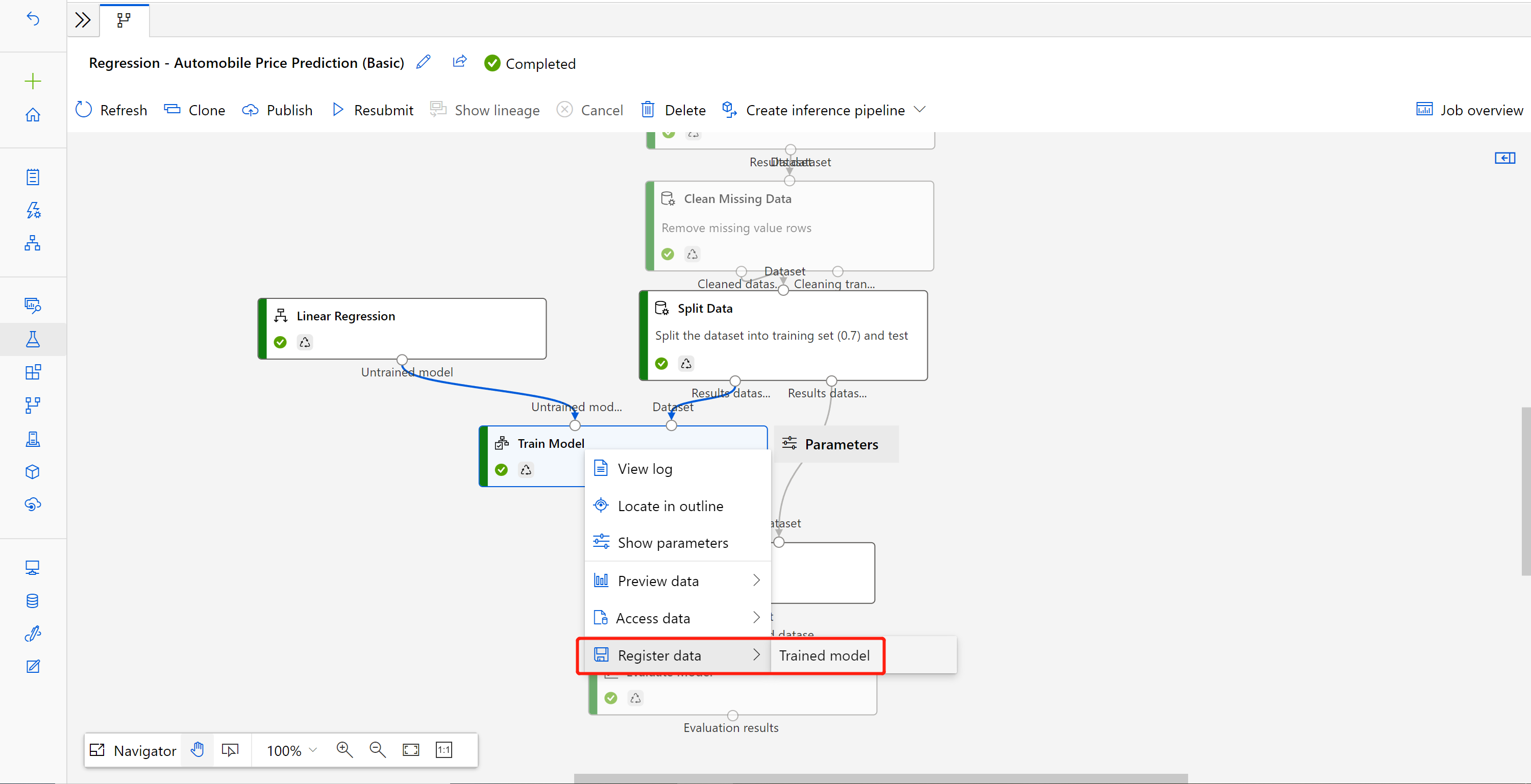
Insira o nome e selecione Tipo de arquivo .

Encontre o rascunho do pipeline de inferência em lote anterior ou você pode simplesmente clonar o pipeline publicado em um novo rascunho.
Substitua o nó MD- no rascunho do pipeline de inferência pelos dados registrados na etapa acima.
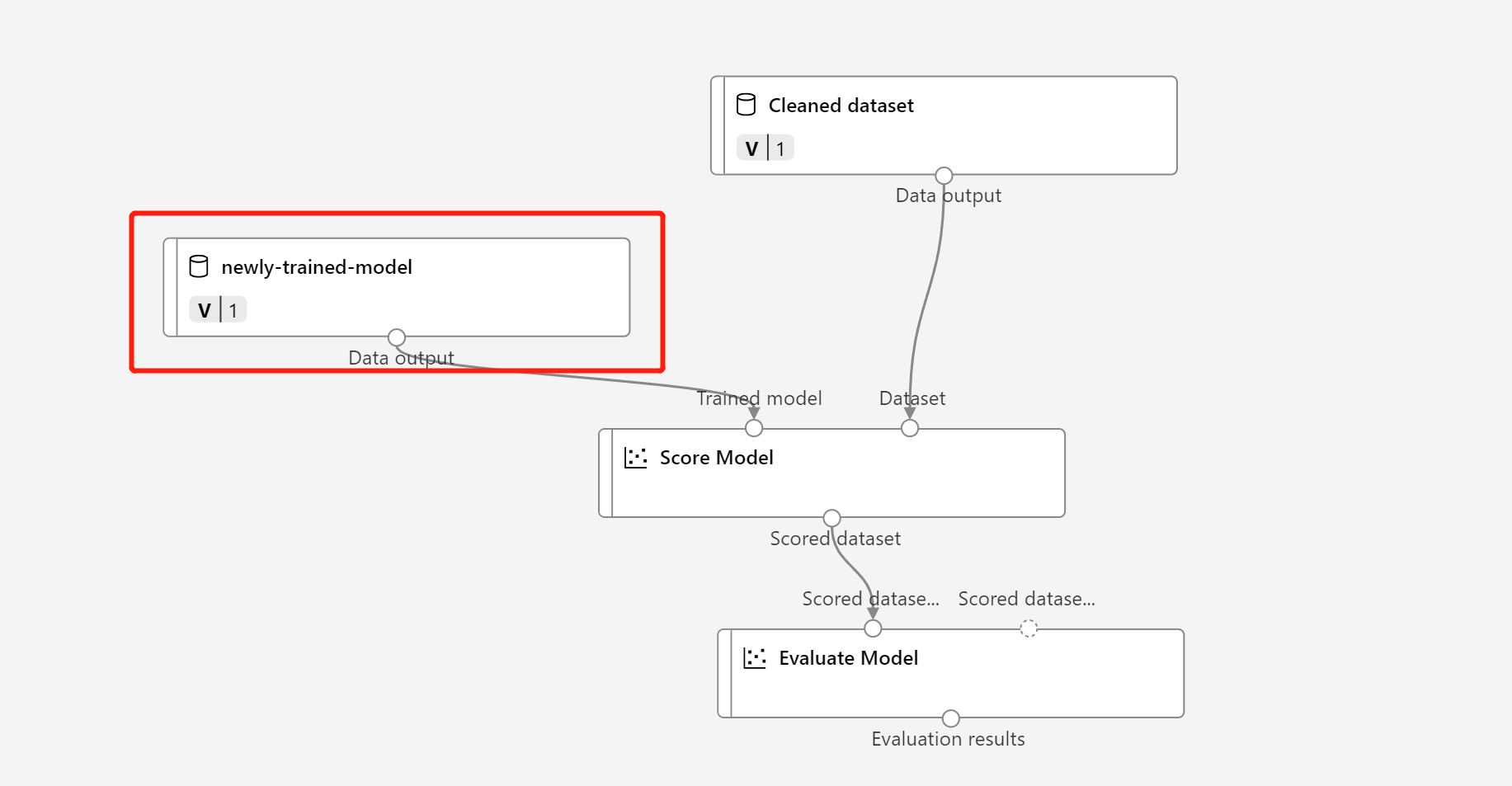
A atualização do nó de transformação de dados TD- é o mesmo que o modelo treinado.
Em seguida, você pode enviar o pipeline de inferência com o modelo e a transformação atualizados e publicar novamente.


Próximos passos
- Siga o tutorial do designer para treinar e implantar um modelo de regressão.
- Para saber como publicar e executar um pipeline publicado usando o SDK v1, consulte o artigo Como implantar pipelines .